 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Longer Version for "Deep Context-Encoding Network for Retinal Image Captioning"
May 30, 2021
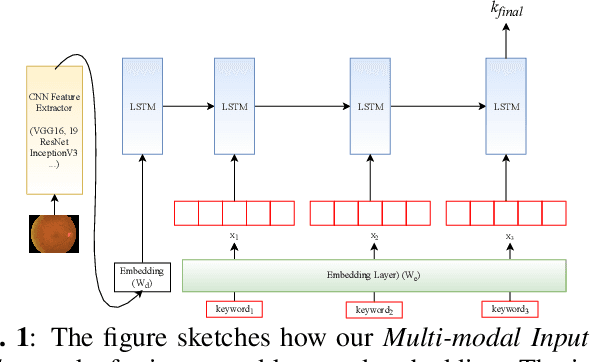
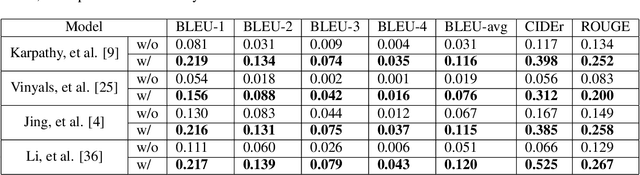
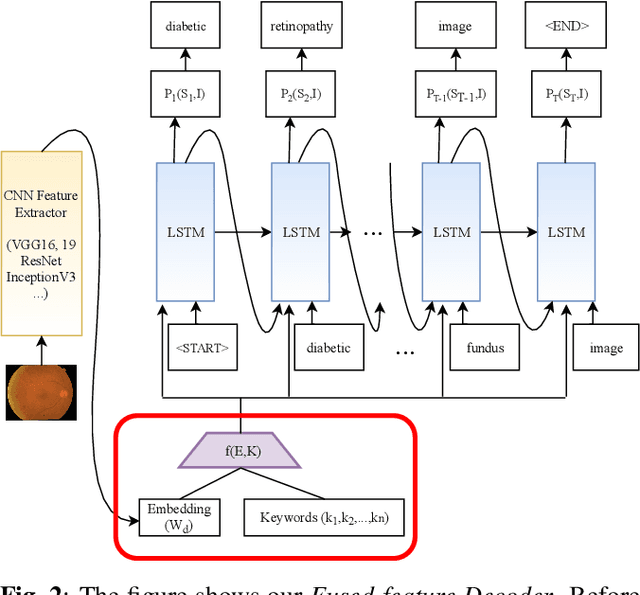

Automatically generating medical reports for retinal images is one of the promising ways to help ophthalmologists reduce their workload and improve work efficiency. In this work, we propose a new context-driven encoding network to automatically generate medical reports for retinal images. The proposed model is mainly composed of a multi-modal input encoder and a fused-feature decoder. Our experimental results show that our proposed method is capable of effectively leveraging the interactive information between the input image and context, i.e., keywords in our case. The proposed method creates more accurate and meaningful reports for retinal images than baseline models and achieves state-of-the-art performance. This performance is shown in several commonly used metrics for the medical report generation task: BLEU-avg (+16%), CIDEr (+10.2%), and ROUGE (+8.6%).
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022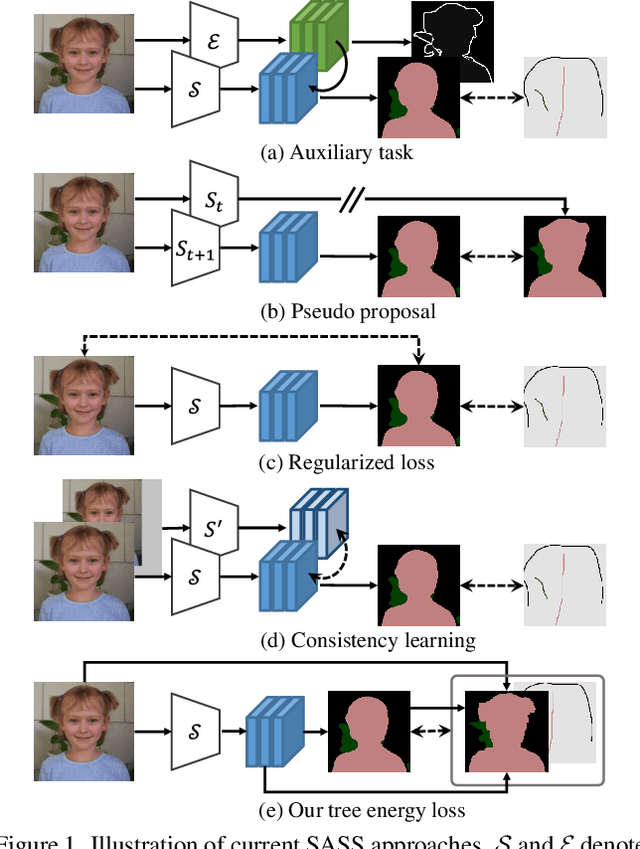
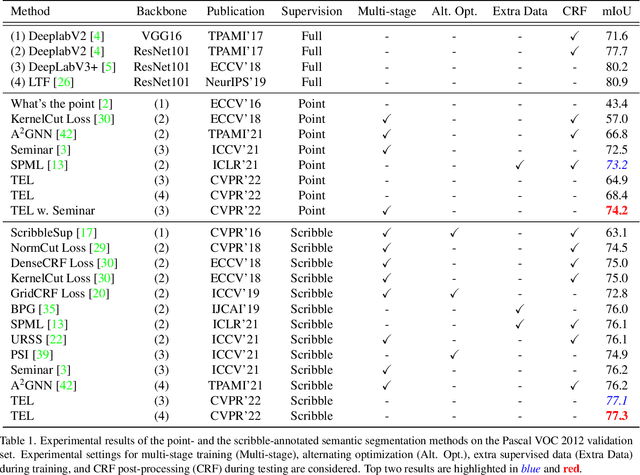

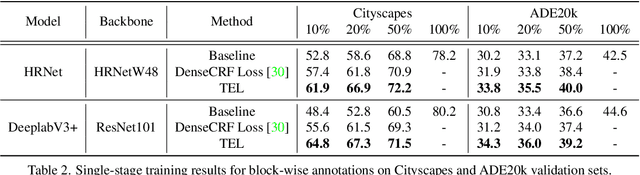
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.
DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion
Mar 20, 2020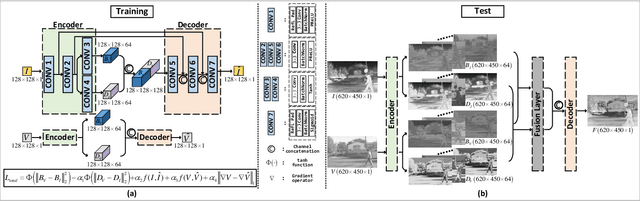
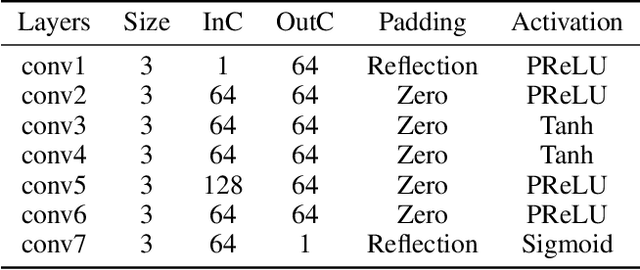
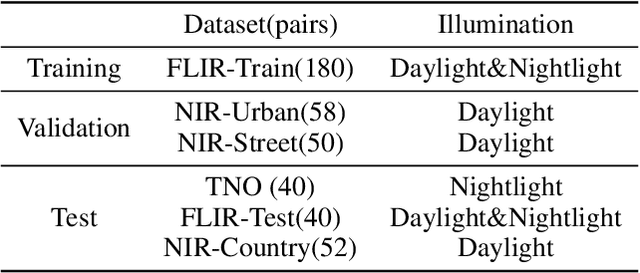
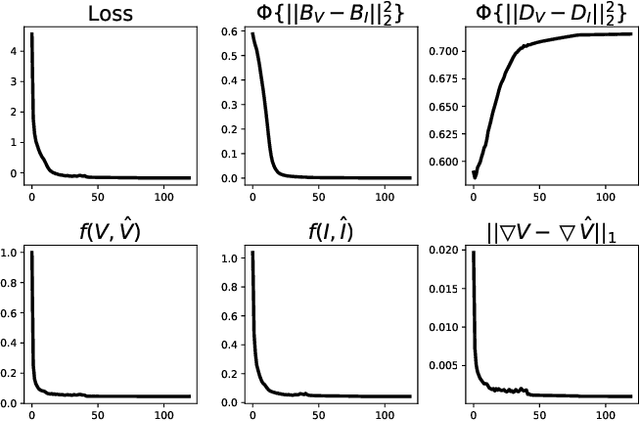
Infrared and visible image fusion, a hot topic in the field of image processing, aims at obtaining fused images keeping the advantages of source images. This paper proposes a novel auto-encoder (AE) based fusion network. The core idea is that the encoder decomposes an image into background and detail feature maps with low- and high-frequency information, respectively, and that the decoder recovers the original image. To this end, the loss function makes the background/detail feature maps of source images similar/dissimilar. In the test phase, background and detail feature maps are respectively merged via a fusion module, and the fused image is recovered by the decoder. Qualitative and quantitative results illustrate that our method can generate fusion images containing highlighted targets and abundant detail texture information with strong robustness and meanwhile surpass state-of-the-art (SOTA) approaches.
Fusing Local Similarities for Retrieval-based 3D Orientation Estimation of Unseen Objects
Mar 16, 2022
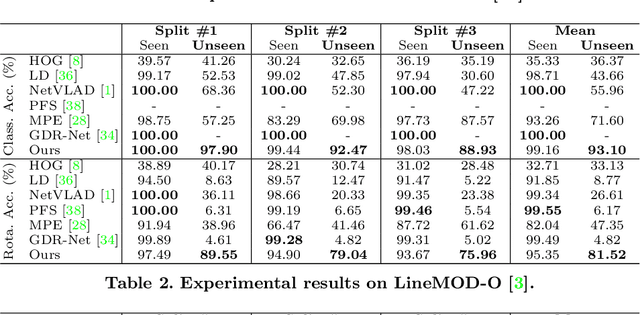
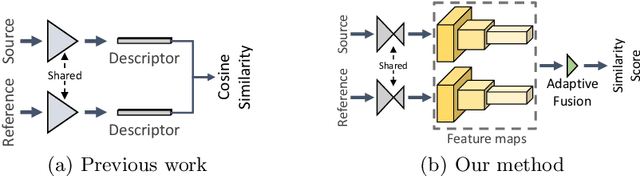
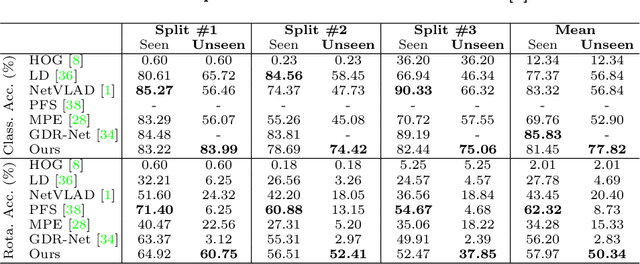
In this paper, we tackle the task of estimating the 3D orientation of previously-unseen objects from monocular images. This task contrasts with the one considered by most existing deep learning methods which typically assume that the testing objects have been observed during training. To handle the unseen objects, we follow a retrieval-based strategy and prevent the network from learning object-specific features by computing multi-scale local similarities between the query image and synthetically-generated reference images. We then introduce an adaptive fusion module that robustly aggregates the local similarities into a global similarity score of pairwise images. Furthermore, we speed up the retrieval process by developing a fast clustering-based retrieval strategy. Our experiments on the LineMOD, LineMOD-Occluded, and T-LESS datasets show that our method yields a significantly better generalization to unseen objects than previous works.
Image Segmentation Methods for Non-destructive testing Applications
Mar 13, 2021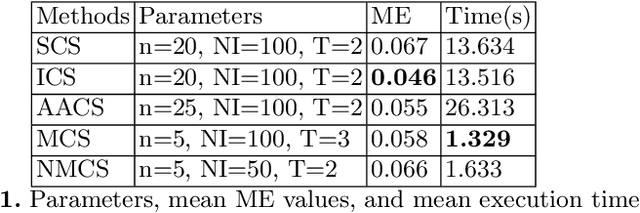
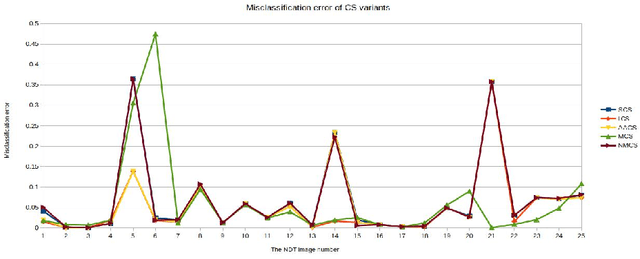
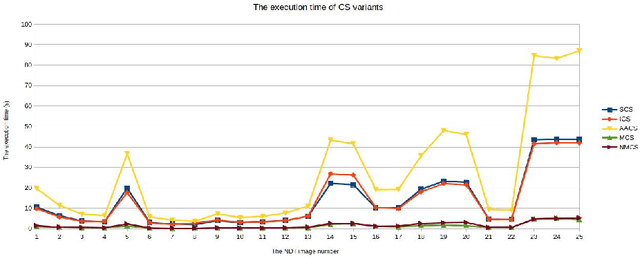

In this paper, we present new image segmentation methods based on hidden Markov random fields (HMRFs) and cuckoo search (CS) variants. HMRFs model the segmentation problem as a minimization of an energy function. CS algorithm is one of the recent powerful optimization techniques. Therefore, five variants of the CS algorithm are used to compute a solution. Through tests, we conduct a study to choose the CS variant with parameters that give good results (execution time and quality of segmentation). CS variants are evaluated and compared with non-destructive testing (NDT) images using a misclassification error (ME) criterion.
CNN Filter DB: An Empirical Investigation of Trained Convolutional Filters
Apr 09, 2022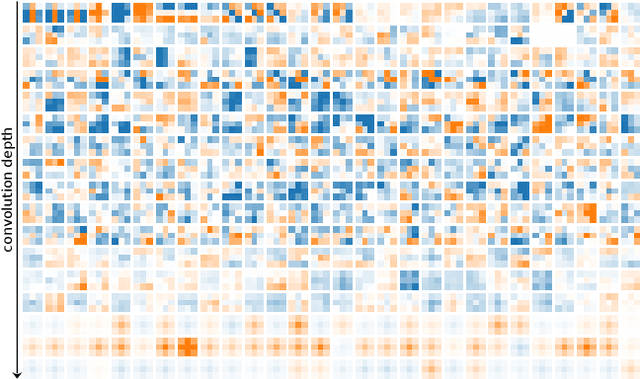

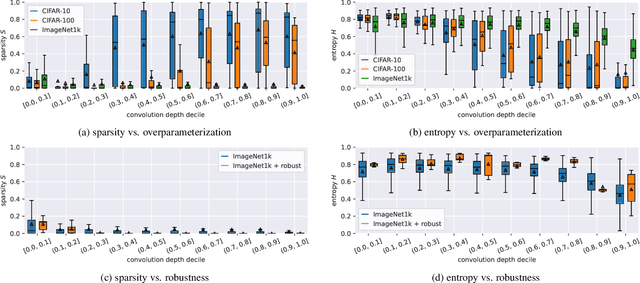
Currently, many theoretical as well as practically relevant questions towards the transferability and robustness of Convolutional Neural Networks (CNNs) remain unsolved. While ongoing research efforts are engaging these problems from various angles, in most computer vision related cases these approaches can be generalized to investigations of the effects of distribution shifts in image data. In this context, we propose to study the shifts in the learned weights of trained CNN models. Here we focus on the properties of the distributions of dominantly used 3x3 convolution filter kernels. We collected and publicly provide a dataset with over 1.4 billion filters from hundreds of trained CNNs, using a wide range of datasets, architectures, and vision tasks. In a first use case of the proposed dataset, we can show highly relevant properties of many publicly available pre-trained models for practical applications: I) We analyze distribution shifts (or the lack thereof) between trained filters along different axes of meta-parameters, like visual category of the dataset, task, architecture, or layer depth. Based on these results, we conclude that model pre-training can succeed on arbitrary datasets if they meet size and variance conditions. II) We show that many pre-trained models contain degenerated filters which make them less robust and less suitable for fine-tuning on target applications. Data & Project website: https://github.com/paulgavrikov/cnn-filter-db
The artificial synesthete: Image-melody translations with variational autoencoders
Dec 06, 2021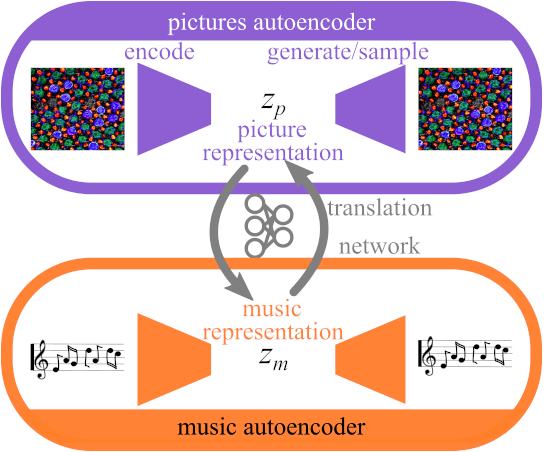
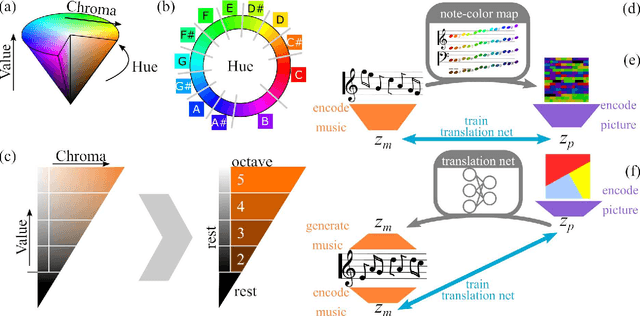
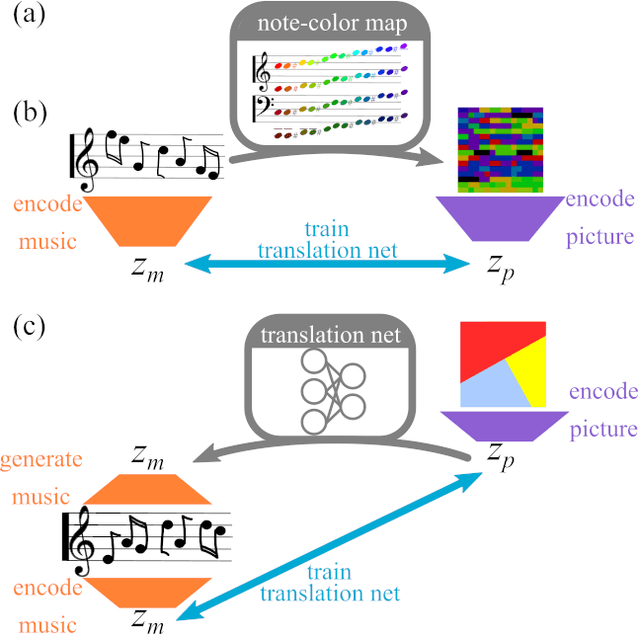
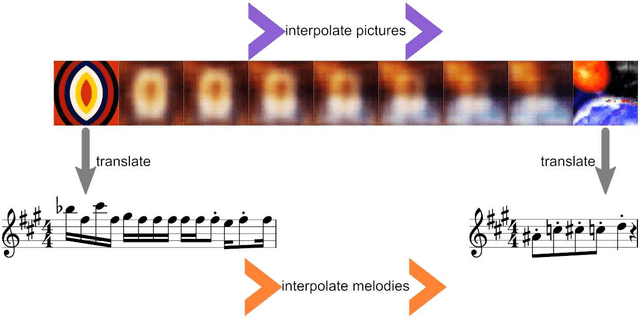
Abstract This project presents a system of neural networks to translate between images and melodies. Autoencoders compress the information in samples to abstract representation. A translation network learns a set of correspondences between musical and visual concepts from repeated joint exposure. The resulting "artificial synesthete" generates simple melodies inspired by images, and images from music. These are novel interpretation (not transposed data), expressing the machine' perception and understanding. Observing the work, one explores the machine's perception and thus, by contrast, one's own.
Survival Analysis for Idiopathic Pulmonary Fibrosis using CT Images and Incomplete Clinical Data
Mar 21, 2022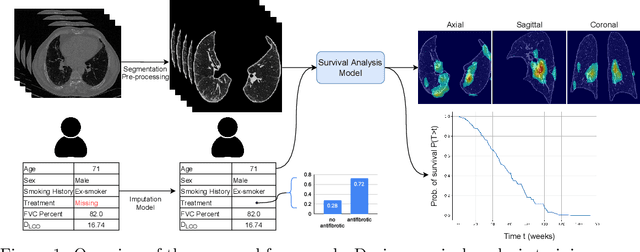
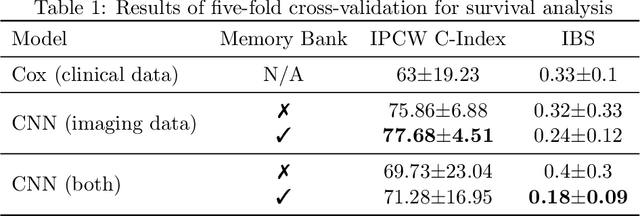
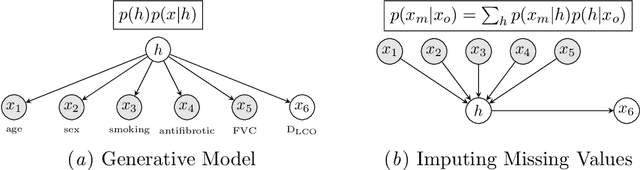

Idiopathic Pulmonary Fibrosis (IPF) is an inexorably progressive fibrotic lung disease with a variable and unpredictable rate of progression. CT scans of the lungs inform clinical assessment of IPF patients and contain pertinent information related to disease progression. In this work, we propose a multi-modal method that uses neural networks and memory banks to predict the survival of IPF patients using clinical and imaging data. The majority of clinical IPF patient records have missing data (e.g. missing lung function tests). To this end, we propose a probabilistic model that captures the dependencies between the observed clinical variables and imputes missing ones. This principled approach to missing data imputation can be naturally combined with a deep survival analysis model. We show that the proposed framework yields significantly better survival analysis results than baselines in terms of concordance index and integrated Brier score. Our work also provides insights into novel image-based biomarkers that are linked to mortality.
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Dec 13, 2021


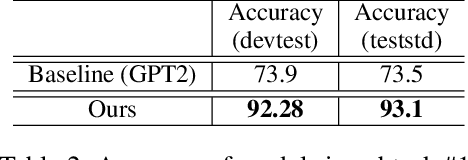
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
Fast Neural Architecture Search for Lightweight Dense Prediction Networks
Mar 09, 2022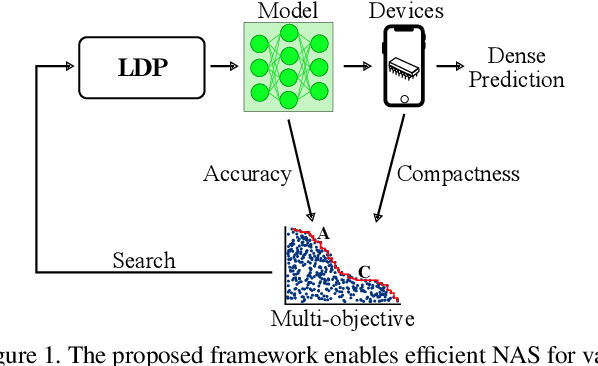
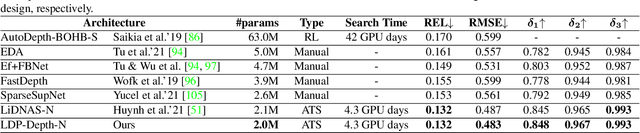
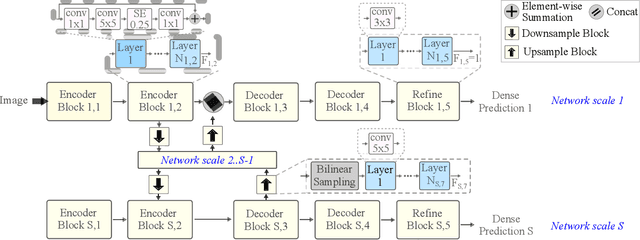
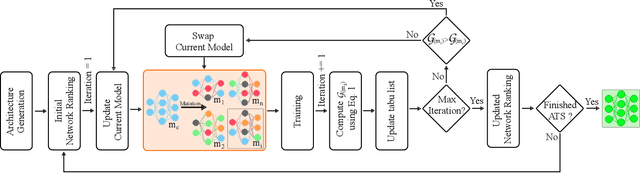
We present LDP, a lightweight dense prediction neural architecture search (NAS) framework. Starting from a pre-defined generic backbone, LDP applies the novel Assisted Tabu Search for efficient architecture exploration. LDP is fast and suitable for various dense estimation problems, unlike previous NAS methods that are either computational demanding or deployed only for a single subtask. The performance of LPD is evaluated on monocular depth estimation, semantic segmentation, and image super-resolution tasks on diverse datasets, including NYU-Depth-v2, KITTI, Cityscapes, COCO-stuff, DIV2K, Set5, Set14, BSD100, Urban100. Experiments show that the proposed framework yields consistent improvements on all tested dense prediction tasks, while being $5\%-315\%$ more compact in terms of the number of model parameters than prior arts.