 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
Jul 06, 2021
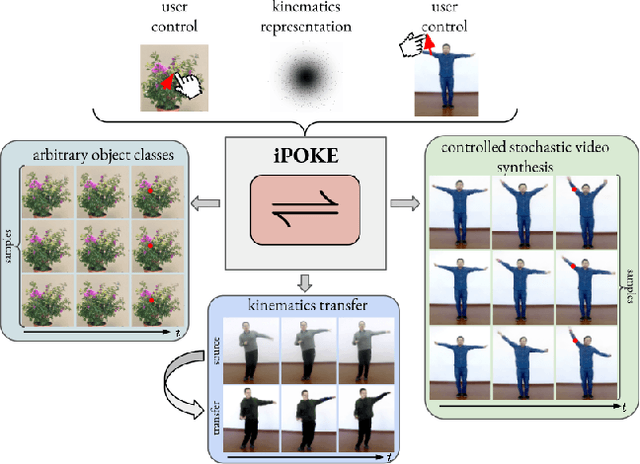
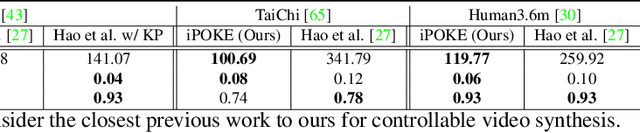
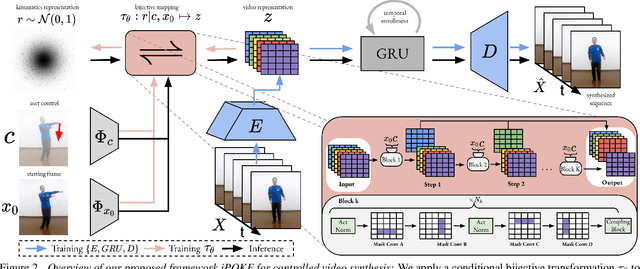

How would a static scene react to a local poke? What are the effects on other parts of an object if you could locally push it? There will be distinctive movement, despite evident variations caused by the stochastic nature of our world. These outcomes are governed by the characteristic kinematics of objects that dictate their overall motion caused by a local interaction. Conversely, the movement of an object provides crucial information about its underlying distinctive kinematics and the interdependencies between its parts. This two-way relation motivates learning a bijective mapping between object kinematics and plausible future image sequences. Therefore, we propose iPOKE - invertible Prediction of Object Kinematics - that, conditioned on an initial frame and a local poke, allows to sample object kinematics and establishes a one-to-one correspondence to the corresponding plausible videos, thereby providing a controlled stochastic video synthesis. In contrast to previous works, we do not generate arbitrary realistic videos, but provide efficient control of movements, while still capturing the stochastic nature of our environment and the diversity of plausible outcomes it entails. Moreover, our approach can transfer kinematics onto novel object instances and is not confined to particular object classes. Project page is available at https://bit.ly/3dJN4Lf
Seeing without Looking: Analysis Pipeline for Child Sexual Abuse Datasets
Apr 29, 2022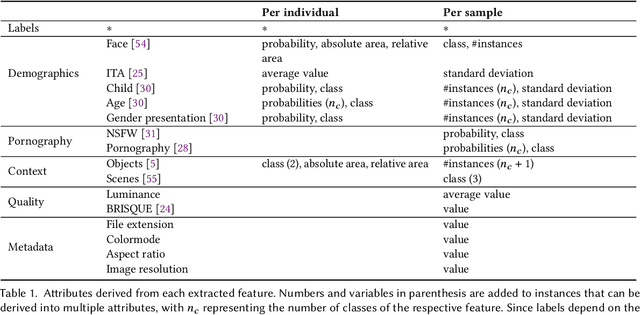
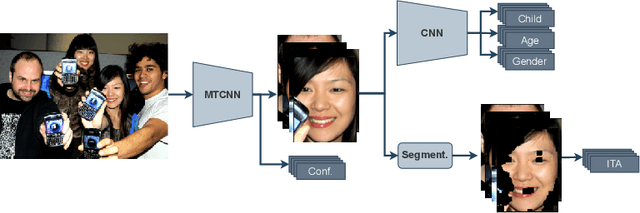
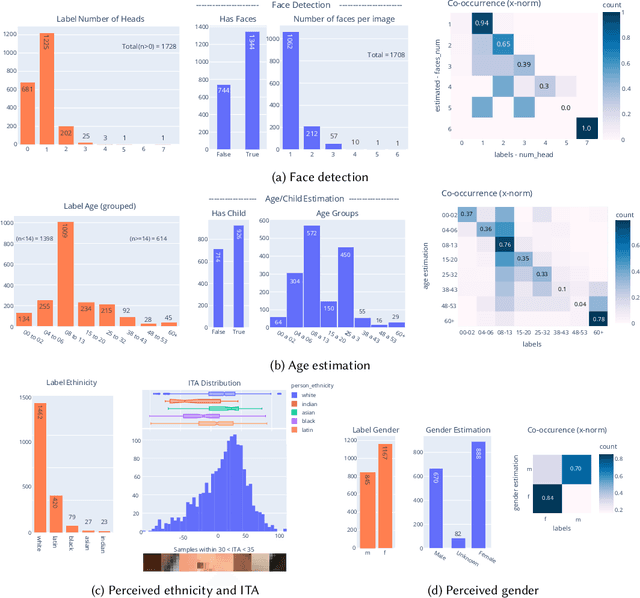
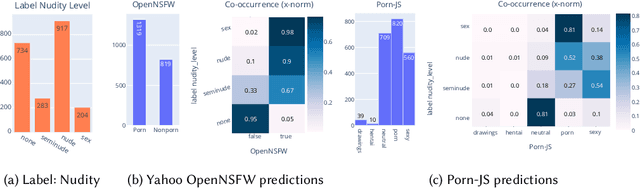
The online sharing and viewing of Child Sexual Abuse Material (CSAM) are growing fast, such that human experts can no longer handle the manual inspection. However, the automatic classification of CSAM is a challenging field of research, largely due to the inaccessibility of target data that is - and should forever be - private and in sole possession of law enforcement agencies. To aid researchers in drawing insights from unseen data and safely providing further understanding of CSAM images, we propose an analysis template that goes beyond the statistics of the dataset and respective labels. It focuses on the extraction of automatic signals, provided both by pre-trained machine learning models, e.g., object categories and pornography detection, as well as image metrics such as luminance and sharpness. Only aggregated statistics of sparse signals are provided to guarantee the anonymity of children and adolescents victimized. The pipeline allows filtering the data by applying thresholds to each specified signal and provides the distribution of such signals within the subset, correlations between signals, as well as a bias evaluation. We demonstrated our proposal on the Region-based annotated Child Pornography Dataset (RCPD), one of the few CSAM benchmarks in the literature, composed of over 2000 samples among regular and CSAM images, produced in partnership with Brazil's Federal Police. Although noisy and limited in several senses, we argue that automatic signals can highlight important aspects of the overall distribution of data, which is valuable for databases that can not be disclosed. Our goal is to safely publicize the characteristics of CSAM datasets, encouraging researchers to join the field and perhaps other institutions to provide similar reports on their benchmarks.
ROOD-MRI: Benchmarking the robustness of deep learning segmentation models to out-of-distribution and corrupted data in MRI
Mar 11, 2022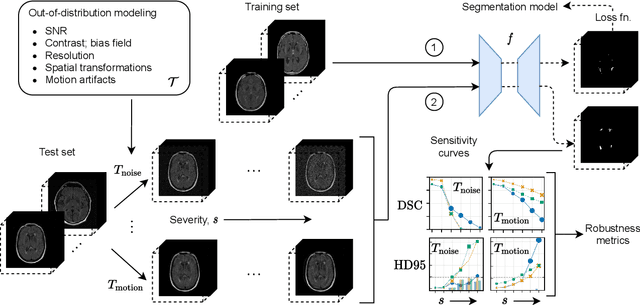
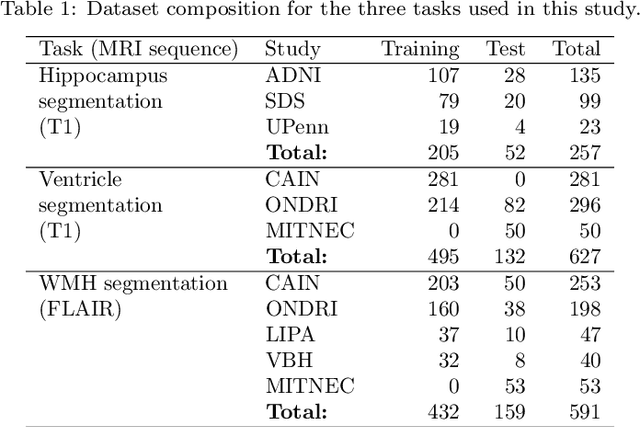
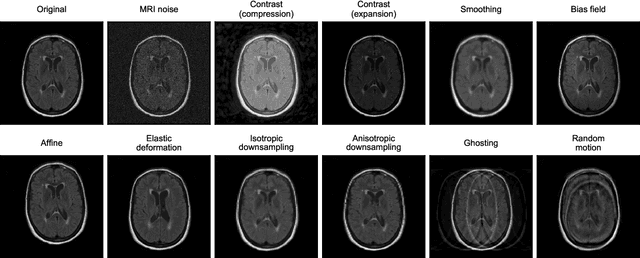
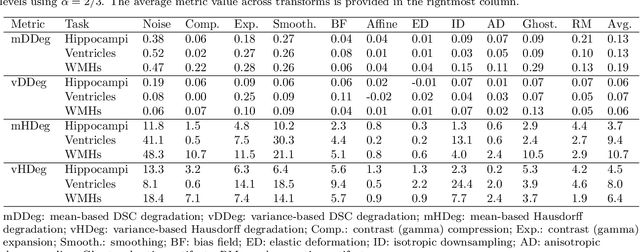
Deep artificial neural networks (DNNs) have moved to the forefront of medical image analysis due to their success in classification, segmentation, and detection challenges. A principal challenge in large-scale deployment of DNNs in neuroimage analysis is the potential for shifts in signal-to-noise ratio, contrast, resolution, and presence of artifacts from site to site due to variances in scanners and acquisition protocols. DNNs are famously susceptible to these distribution shifts in computer vision. Currently, there are no benchmarking platforms or frameworks to assess the robustness of new and existing models to specific distribution shifts in MRI, and accessible multi-site benchmarking datasets are still scarce or task-specific. To address these limitations, we propose ROOD-MRI: a platform for benchmarking the Robustness of DNNs to Out-Of-Distribution (OOD) data, corruptions, and artifacts in MRI. The platform provides modules for generating benchmarking datasets using transforms that model distribution shifts in MRI, implementations of newly derived benchmarking metrics for image segmentation, and examples for using the methodology with new models and tasks. We apply our methodology to hippocampus, ventricle, and white matter hyperintensity segmentation in several large studies, providing the hippocampus dataset as a publicly available benchmark. By evaluating modern DNNs on these datasets, we demonstrate that they are highly susceptible to distribution shifts and corruptions in MRI. We show that while data augmentation strategies can substantially improve robustness to OOD data for anatomical segmentation tasks, modern DNNs using augmentation still lack robustness in more challenging lesion-based segmentation tasks. We finally benchmark U-Nets and transformer-based models, finding consistent differences in robustness to particular classes of transforms across architectures.
ReconResNet: Regularised Residual Learning for MR Image Reconstruction of Undersampled Cartesian and Radial Data
Mar 16, 2021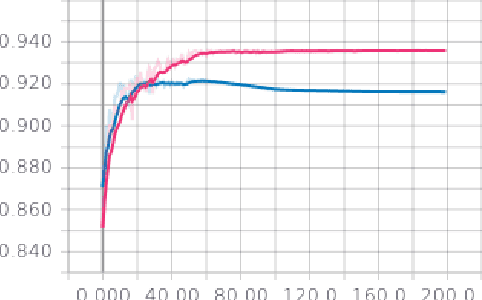
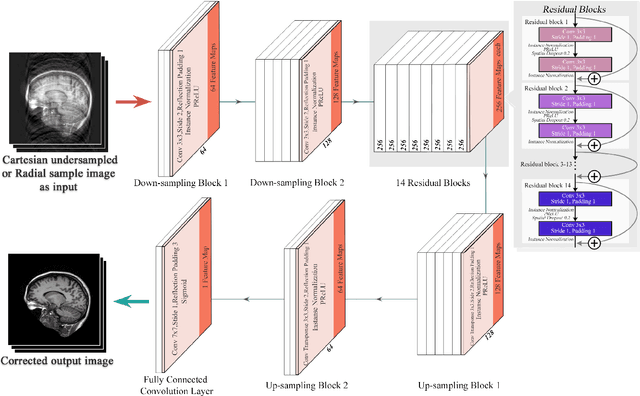
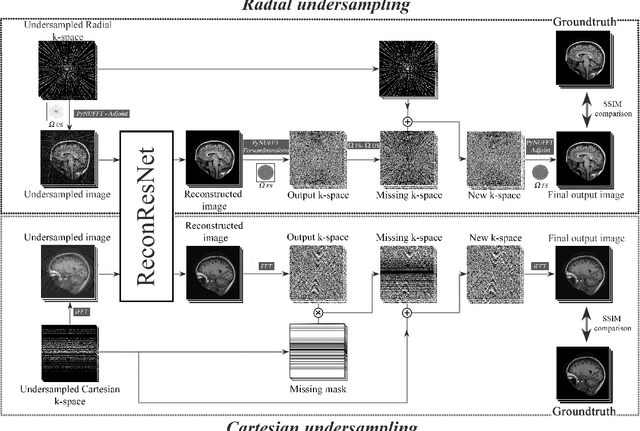
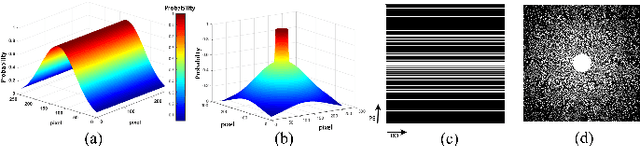
MRI is an inherently slow process, which leads to long scan time for high-resolution imaging. The speed of acquisition can be increased by ignoring parts of the data (undersampling). Consequently, this leads to the degradation of image quality, such as loss of resolution or introduction of image artefacts. This work aims to reconstruct highly undersampled Cartesian or radial MR acquisitions, with better resolution and with less to no artefact compared to conventional techniques like compressed sensing. In recent times, deep learning has emerged as a very important area of research and has shown immense potential in solving inverse problems, e.g. MR image reconstruction. In this paper, a deep learning based MR image reconstruction framework is proposed, which includes a modified regularised version of ResNet as the network backbone to remove artefacts from the undersampled image, followed by data consistency steps that fusions the network output with the data already available from undersampled k-space in order to further improve reconstruction quality. The performance of this framework for various undersampling patterns has also been tested, and it has been observed that the framework is robust to deal with various sampling patterns, even when mixed together while training, and results in very high quality reconstruction, in terms of high SSIM (highest being 0.990$\pm$0.006 for acceleration factor of 3.5), while being compared with the fully sampled reconstruction. It has been shown that the proposed framework can successfully reconstruct even for an acceleration factor of 20 for Cartesian (0.968$\pm$0.005) and 17 for radially (0.962$\pm$0.012) sampled data. Furthermore, it has been shown that the framework preserves brain pathology during reconstruction while being trained on healthy subjects.
3D Hierarchical Refinement and Augmentation for Unsupervised Learning of Depth and Pose from Monocular Video
Dec 06, 2021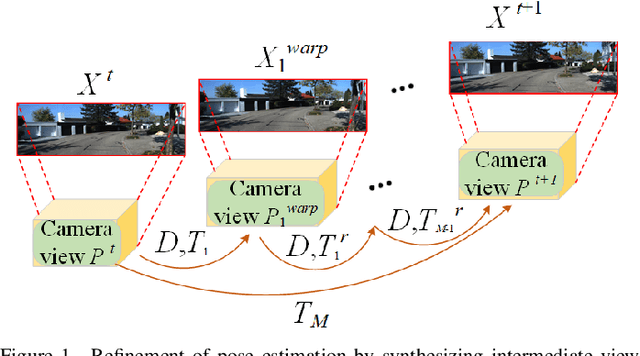
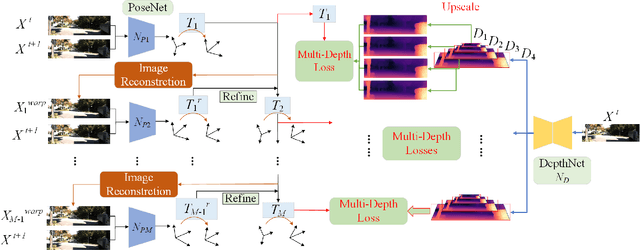
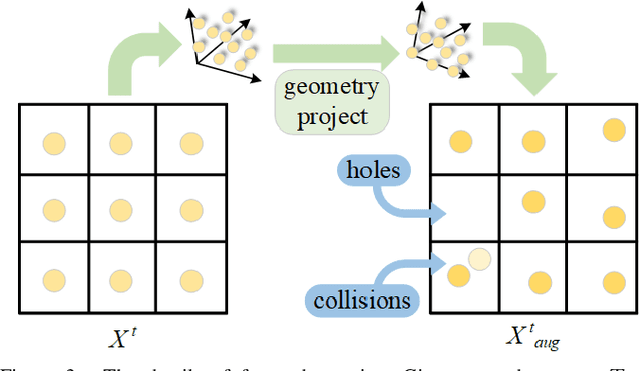

Depth and ego-motion estimations are essential for the localization and navigation of autonomous robots and autonomous driving. Recent studies make it possible to learn the per-pixel depth and ego-motion from the unlabeled monocular video. A novel unsupervised training framework is proposed with 3D hierarchical refinement and augmentation using explicit 3D geometry. In this framework, the depth and pose estimations are hierarchically and mutually coupled to refine the estimated pose layer by layer. The intermediate view image is proposed and synthesized by warping the pixels in an image with the estimated depth and coarse pose. Then, the residual pose transformation can be estimated from the new view image and the image of the adjacent frame to refine the coarse pose. The iterative refinement is implemented in a differentiable manner in this paper, making the whole framework optimized uniformly. Meanwhile, a new image augmentation method is proposed for the pose estimation by synthesizing a new view image, which creatively augments the pose in 3D space but gets a new augmented 2D image. The experiments on KITTI demonstrate that our depth estimation achieves state-of-the-art performance and even surpasses recent approaches that utilize other auxiliary tasks. Our visual odometry outperforms all recent unsupervised monocular learning-based methods and achieves competitive performance to the geometry-based method, ORB-SLAM2 with back-end optimization.
Improving Unsupervised Image Clustering With Robust Learning
Dec 21, 2020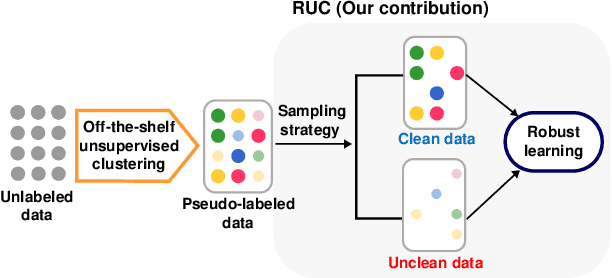
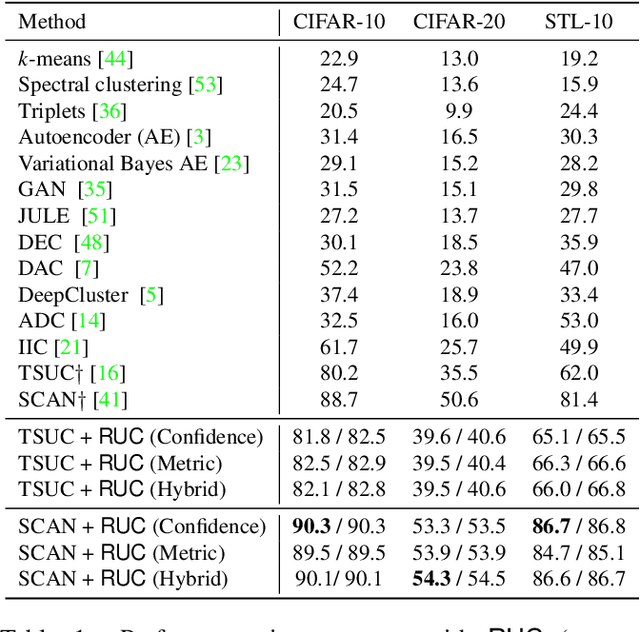
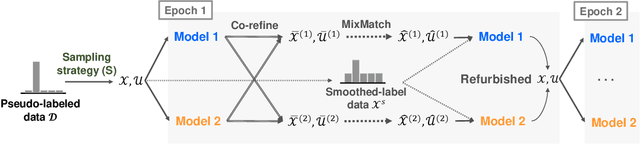

Unsupervised image clustering methods often introduce alternative objectives to indirectly train the model and are subject to faulty predictions and overconfident results. To overcome these challenges, the current research proposes an innovative model RUC that is inspired by robust learning. RUC's novelty is at utilizing pseudo-labels of existing image clustering models as a noisy dataset that may include misclassified samples. Its retraining process can revise misaligned knowledge and alleviate the overconfidence problem in predictions. This model's flexible structure makes it possible to be used as an add-on module to state-of-the-art clustering methods and helps them achieve better performance on multiple datasets. Extensive experiments show that the proposed model can adjust the model confidence with better calibration and gain additional robustness against adversarial noise.
Know your sensORs -- A Modality Study For Surgical Action Classification
Mar 22, 2022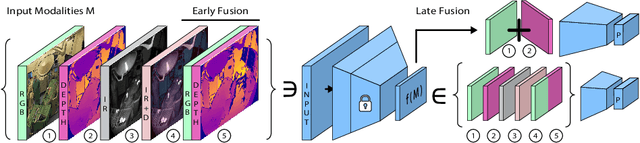
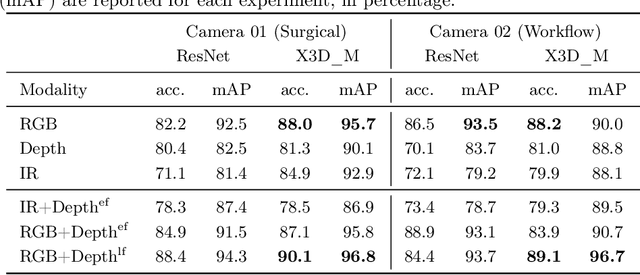
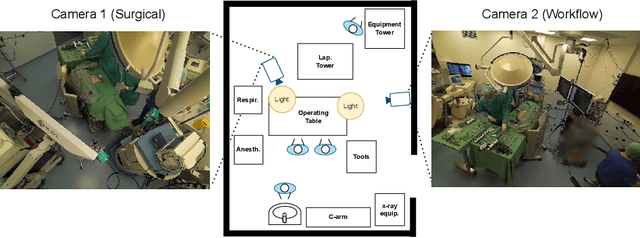
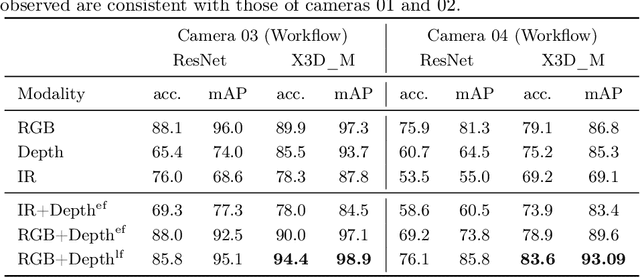
The surgical operating room (OR) presents many opportunities for automation and optimization. Videos from various sources in the OR are becoming increasingly available. The medical community seeks to leverage this wealth of data to develop automated methods to advance interventional care, lower costs, and improve overall patient outcomes. Existing datasets from OR room cameras are thus far limited in size or modalities acquired, leaving it unclear which sensor modalities are best suited for tasks such as recognizing surgical action from videos. This study demonstrates that surgical action recognition performance can vary depending on the image modalities used. We perform a methodical analysis on several commonly available sensor modalities, presenting two fusion approaches that improve classification performance. The analyses are carried out on a set of multi-view RGB-D video recordings of 18 laparoscopic procedures.
Field-of-View IoU for Object Detection in 360° Images
Feb 07, 2022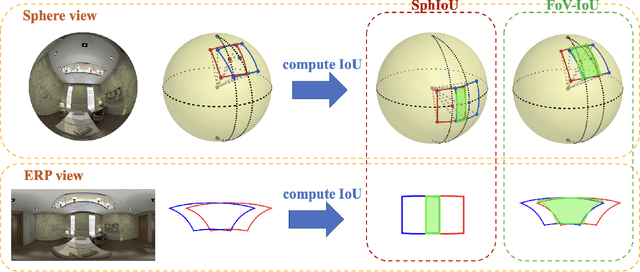
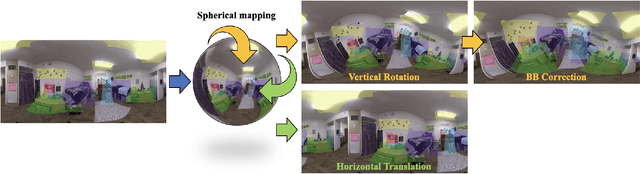
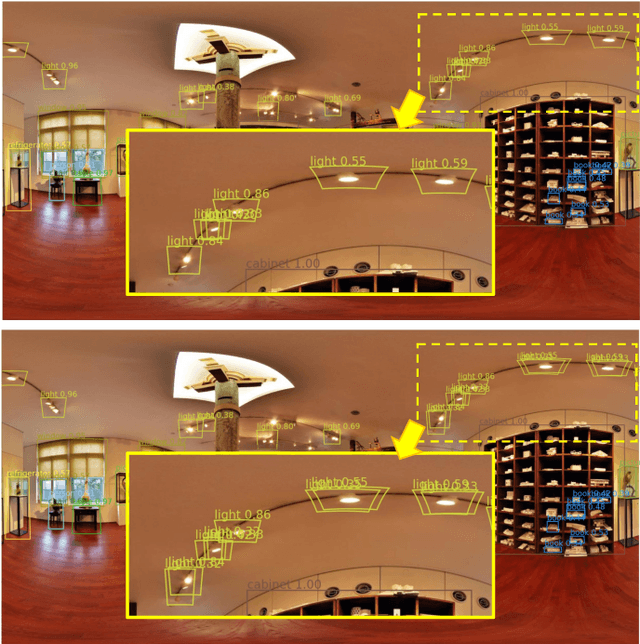

360{\deg} cameras have gained popularity over the last few years. In this paper, we propose two fundamental techniques -- Field-of-View IoU (FoV-IoU) and 360Augmentation for object detection in 360{\deg} images. Although most object detection neural networks designed for the perspective images are applicable to 360{\deg} images in equirectangular projection (ERP) format, their performance deteriorates owing to the distortion in ERP images. Our method can be readily integrated with existing perspective object detectors and significantly improves the performance. The FoV-IoU computes the intersection-over-union of two Field-of-View bounding boxes in a spherical image which could be used for training, inference, and evaluation while 360Augmentation is a data augmentation technique specific to 360{\deg} object detection task which randomly rotates a spherical image and solves the bias due to the sphere-to-plane projection. We conduct extensive experiments on the 360indoor dataset with different types of perspective object detectors and show the consistent effectiveness of our method.
InfraredTags: Embedding Invisible AR Markers and Barcodes Using Low-Cost, Infrared-Based 3D Printing and Imaging Tools
Feb 12, 2022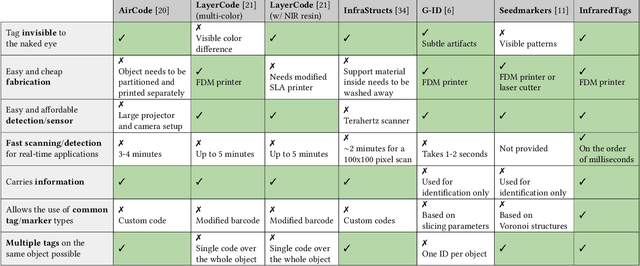
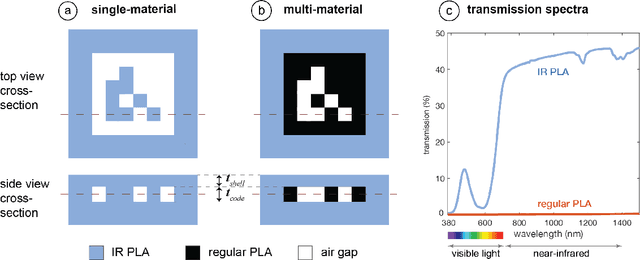
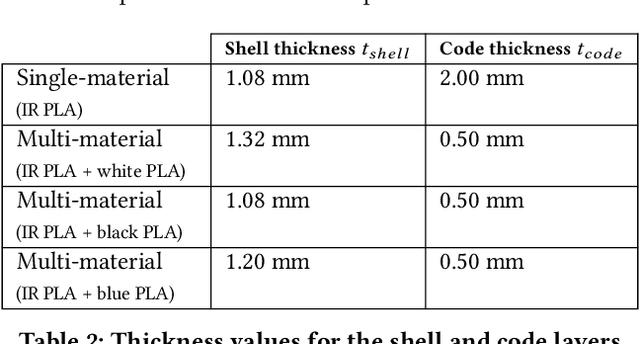
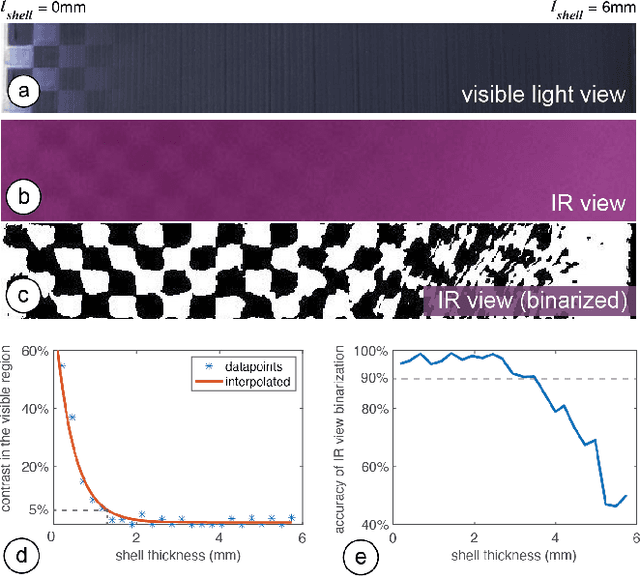
Existing approaches for embedding unobtrusive tags inside 3D objects require either complex fabrication or high-cost imaging equipment. We present InfraredTags, which are 2D markers and barcodes imperceptible to the naked eye that can be 3D printed as part of objects, and detected rapidly by low-cost near-infrared cameras. We achieve this by printing objects from an infrared-transmitting filament, which infrared cameras can see through, and by having air gaps inside for the tag's bits, which appear at a different intensity in the infrared image. We built a user interface that facilitates the integration of common tags (QR codes, ArUco markers) with the object geometry to make them 3D printable as InfraredTags. We also developed a low-cost infrared imaging module that augments existing mobile devices and decodes tags using our image processing pipeline. Our evaluation shows that the tags can be detected with little near-infrared illumination (0.2lux) and from distances as far as 250cm. We demonstrate how our method enables various applications, such as object tracking and embedding metadata for augmented reality and tangible interactions.
Artificial Perceptual Learning: Image Categorization with Weak Supervision
Jun 02, 2021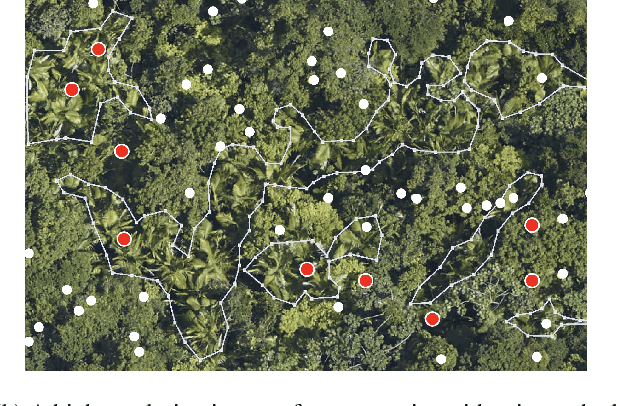
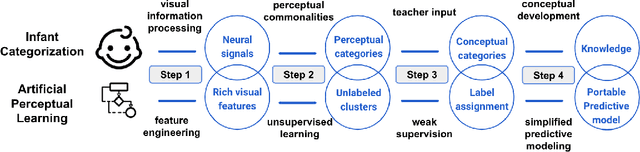

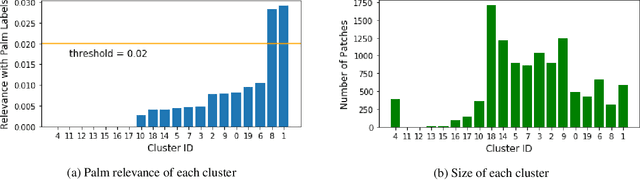
Machine learning has achieved much success on supervised learning tasks with large sets of well-annotated training samples. However, in many practical situations, such strong and high-quality supervision provided by training data is unavailable due to the expensive and labor-intensive labeling process. Automatically identifying and recognizing object categories in a large volume of unlabeled images with weak supervision remains an important, yet unsolved challenge in computer vision. In this paper, we propose a novel machine learning framework, artificial perceptual learning (APL), to tackle the problem of weakly supervised image categorization. The proposed APL framework is constructed using state-of-the-art machine learning algorithms as building blocks to mimic the cognitive development process known as infant categorization. We develop and illustrate the proposed framework by implementing a wide-field fine-grain ecological survey of tree species over an 8,000-hectare area of the El Yunque rainforest in Puerto Rico. It is based on unlabeled high-resolution aerial images of the tree canopy. Misplaced ground-based labels were available for less than 1% of these images, which serve as the only weak supervision for this learning framework. We validate the proposed framework using a small set of images with high quality human annotations and show that the proposed framework attains human-level cognitive economy.