 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A high-order tensor completion algorithm based on Fully-Connected Tensor Network weighted optimization
Apr 06, 2022
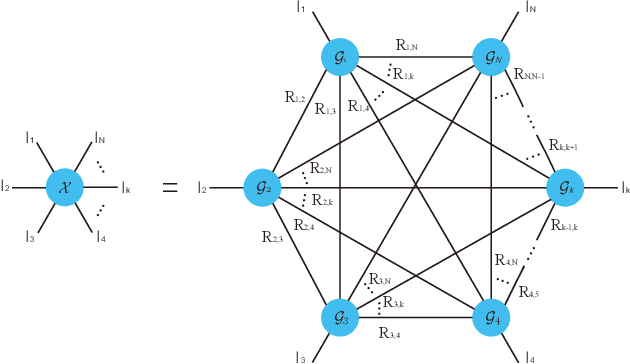
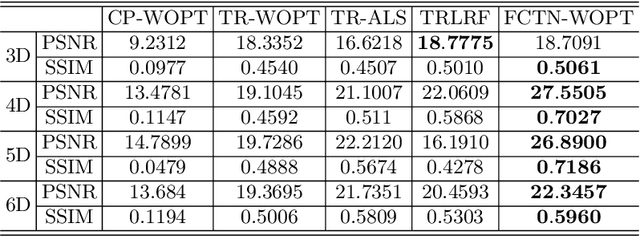
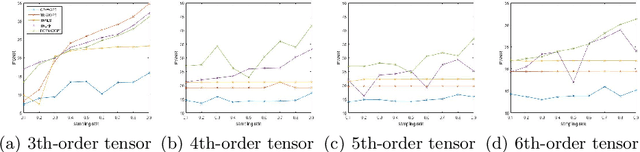

Tensor completion aimes at recovering missing data, and it is one of the popular concerns in deep learning and signal processing. Among the higher-order tensor decomposition algorithms, the recently proposed fully-connected tensor network decomposition (FCTN) algorithm is the most advanced. In this paper, by leveraging the superior expression of the fully-connected tensor network (FCTN) decomposition, we propose a new tensor completion method named the fully connected tensor network weighted optization(FCTN-WOPT). The algorithm performs a composition of the completed tensor by initialising the factors from the FCTN decomposition. We build a loss function with the weight tensor, the completed tensor and the incomplete tensor together, and then update the completed tensor using the lbfgs gradient descent algorithm to reduce the spatial memory occupation and speed up iterations. Finally we test the completion with synthetic data and real data (both image data and video data) and the results show the advanced performance of our FCTN-WOPT when it is applied to higher-order tensor completion.
HUMUS-Net: Hybrid unrolled multi-scale network architecture for accelerated MRI reconstruction
Mar 15, 2022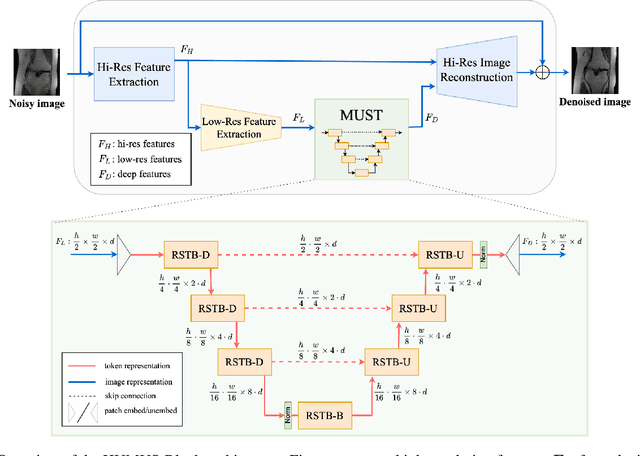

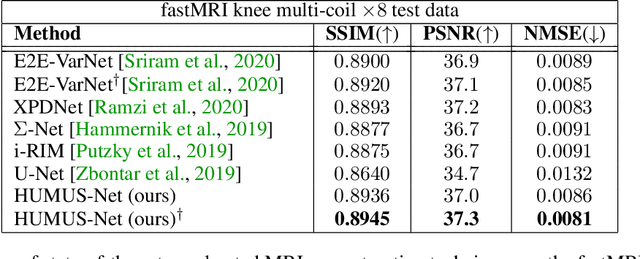
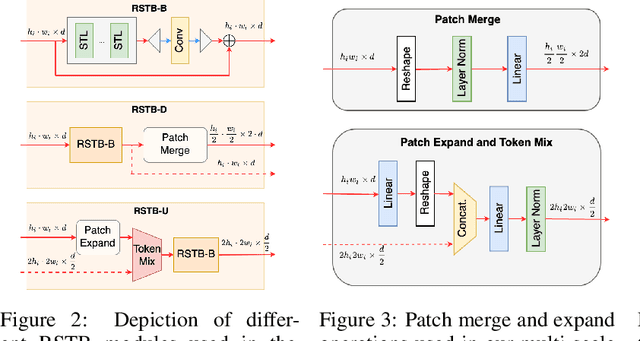
In accelerated MRI reconstruction, the anatomy of a patient is recovered from a set of under-sampled and noisy measurements. Deep learning approaches have been proven to be successful in solving this ill-posed inverse problem and are capable of producing very high quality reconstructions. However, current architectures heavily rely on convolutions, that are content-independent and have difficulties modeling long-range dependencies in images. Recently, Transformers, the workhorse of contemporary natural language processing, have emerged as powerful building blocks for a multitude of vision tasks. These models split input images into non-overlapping patches, embed the patches into lower-dimensional tokens and utilize a self-attention mechanism that does not suffer from the aforementioned weaknesses of convolutional architectures. However, Transformers incur extremely high compute and memory cost when 1) the input image resolution is high and 2) when the image needs to be split into a large number of patches to preserve fine detail information, both of which are typical in low-level vision problems such as MRI reconstruction, having a compounding effect. To tackle these challenges, we propose HUMUS-Net, a hybrid architecture that combines the beneficial implicit bias and efficiency of convolutions with the power of Transformer blocks in an unrolled and multi-scale network. HUMUS-Net extracts high-resolution features via convolutional blocks and refines low-resolution features via a novel Transformer-based multi-scale feature extractor. Features from both levels are then synthesized into a high-resolution output reconstruction. Our network establishes new state of the art on the largest publicly available MRI dataset, the fastMRI dataset. We further demonstrate the performance of HUMUS-Net on two other popular MRI datasets and perform fine-grained ablation studies to validate our design.
Do Vision-Language Pretrained Models Learn Primitive Concepts?
Mar 31, 2022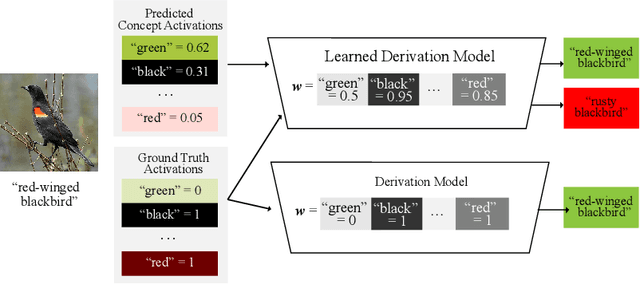
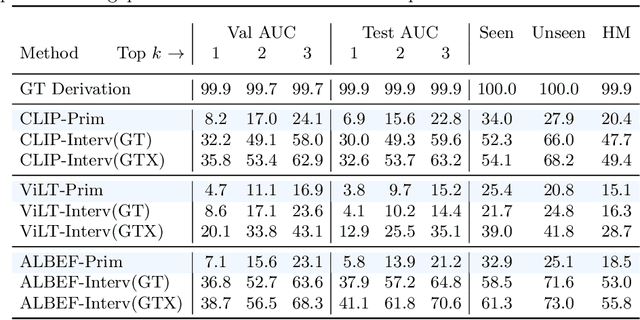
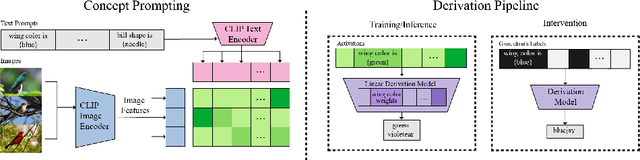
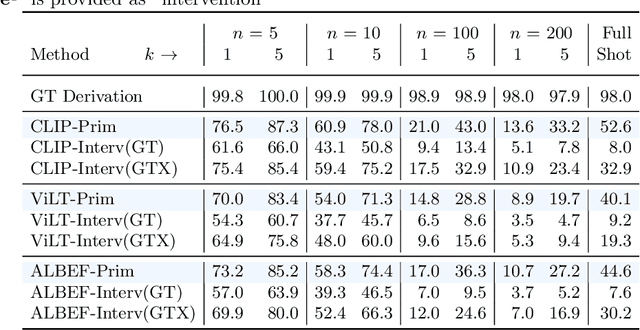
Vision-language pretrained models have achieved impressive performance on multimodal reasoning and zero-shot recognition tasks. Many of these VL models are pretrained on unlabeled image and caption pairs from the internet. In this paper, we study whether the notion of primitive concepts, such as color and shape attributes, emerges automatically from these pretrained VL models. We propose to learn compositional derivations that map primitive concept activations into composite concepts, a task which we demonstrate to be straightforward given true primitive concept annotations. This compositional derivation learning (CompDL) framework allows us to quantitively measure the usefulness and interpretability of the learned derivations, by jointly considering the entire set of candidate primitive concepts. Our study reveals that state-of-the-art VL pretrained models learn primitive concepts that are highly useful as visual descriptors, as demonstrated by their strong performance on fine-grained visual recognition tasks, but those concepts struggle to provide interpretable compositional derivations, which highlights limitations of existing VL models. Code and models will be released.
Crowd counting with crowd attention convolutional neural network
Apr 15, 2022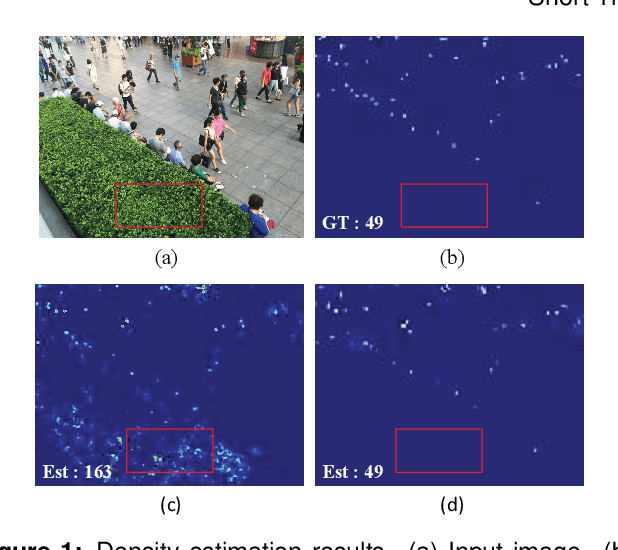

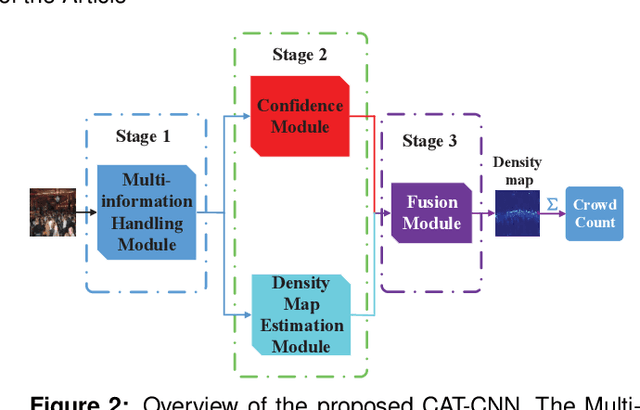
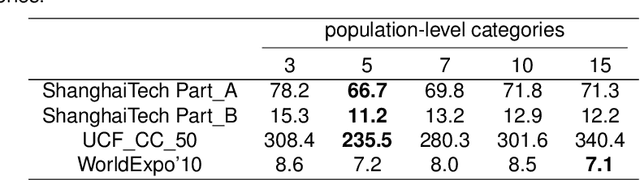
Crowd counting is a challenging problem due to the scene complexity and scale variation. Although deep learning has achieved great improvement in crowd counting, scene complexity affects the judgement of these methods and they usually regard some objects as people mistakenly; causing potentially enormous errors in the crowd counting result. To address the problem, we propose a novel end-to-end model called Crowd Attention Convolutional Neural Network (CAT-CNN). Our CAT-CNN can adaptively assess the importance of a human head at each pixel location by automatically encoding a confidence map. With the guidance of the confidence map, the position of human head in estimated density map gets more attention to encode the final density map, which can avoid enormous misjudgements effectively. The crowd count can be obtained by integrating the final density map. To encode a highly refined density map, the total crowd count of each image is classified in a designed classification task and we first explicitly map the prior of the population-level category to feature maps. To verify the efficiency of our proposed method, extensive experiments are conducted on three highly challenging datasets. Results establish the superiority of our method over many state-of-the-art methods.
* Accepted by Neurocomputing
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets
Apr 26, 2021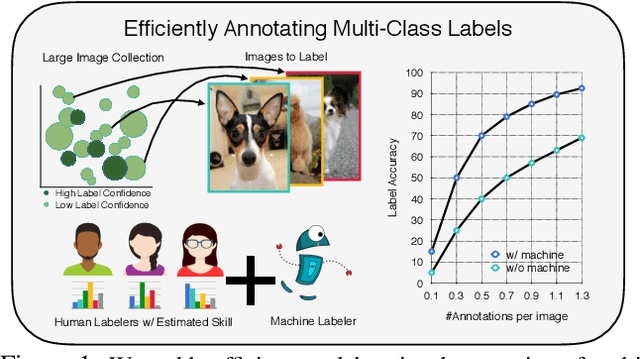

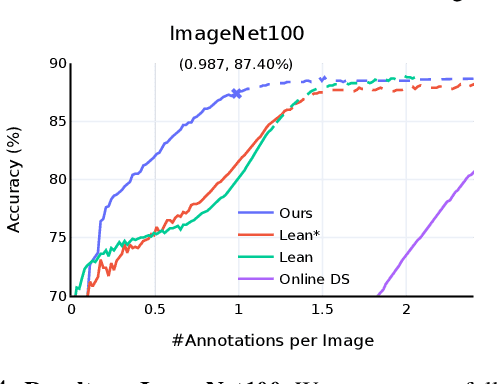
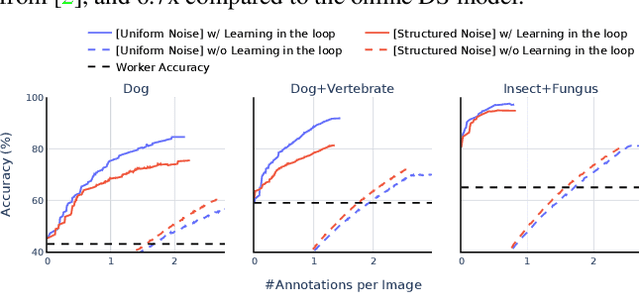
Data is the engine of modern computer vision, which necessitates collecting large-scale datasets. This is expensive, and guaranteeing the quality of the labels is a major challenge. In this paper, we investigate efficient annotation strategies for collecting multi-class classification labels for a large collection of images. While methods that exploit learnt models for labeling exist, a surprisingly prevalent approach is to query humans for a fixed number of labels per datum and aggregate them, which is expensive. Building on prior work on online joint probabilistic modeling of human annotations and machine-generated beliefs, we propose modifications and best practices aimed at minimizing human labeling effort. Specifically, we make use of advances in self-supervised learning, view annotation as a semi-supervised learning problem, identify and mitigate pitfalls and ablate several key design choices to propose effective guidelines for labeling. Our analysis is done in a more realistic simulation that involves querying human labelers, which uncovers issues with evaluation using existing worker simulation methods. Simulated experiments on a 125k image subset of the ImageNet100 show that it can be annotated to 80% top-1 accuracy with 0.35 annotations per image on average, a 2.7x and 6.7x improvement over prior work and manual annotation, respectively. Project page: https://fidler-lab.github.io/efficient-annotation-cookbook
Strategies in JPEG compression using Convolutional Neural Network (CNN)
Dec 06, 2021
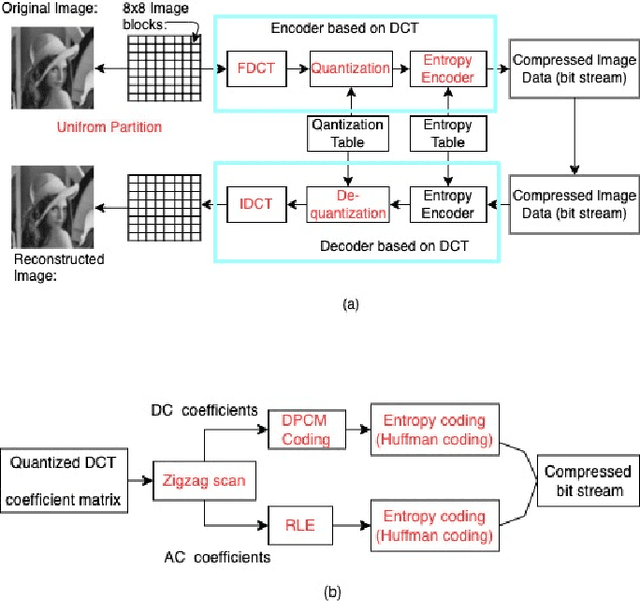
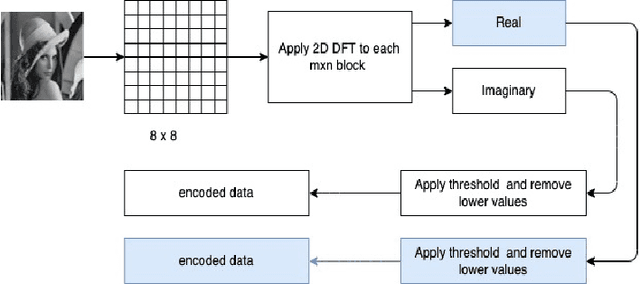

Interests in digital image processing are growing enormously in recent decades. As a result, different data compression techniques have been proposed which are concerned mostly with the minimization of information used for the representation of images. With the advances of deep neural networks, image compression can be achieved to a higher degree. This paper describes an overview of JPEG Compression, Discrete Fourier Transform (DFT), Convolutional Neural Network (CNN), quality metrics to measure the performance of image compression and discuss the advancement of deep learning for image compression mostly focused on JPEG, and suggests that adaptation of model improve the compression.
Scale-Adv: A Joint Attack on Image-Scaling and Machine Learning Classifiers
Apr 18, 2021

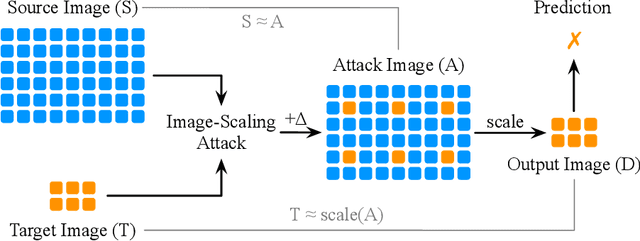
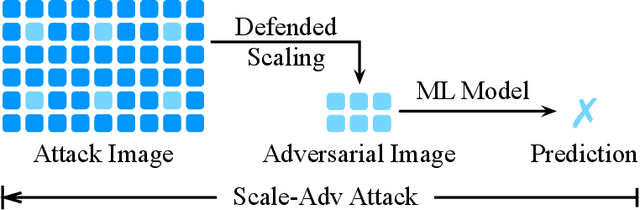
As real-world images come in varying sizes, the machine learning model is part of a larger system that includes an upstream image scaling algorithm. In this system, the model and the scaling algorithm have become attractive targets for numerous attacks, such as adversarial examples and the recent image-scaling attack. In response to these attacks, researchers have developed defense approaches that are tailored to attacks at each processing stage. As these defenses are developed in isolation, their underlying assumptions become questionable when viewing them from the perspective of an end-to-end machine learning system. In this paper, we investigate whether defenses against scaling attacks and adversarial examples are still robust when an adversary targets the entire machine learning system. In particular, we propose Scale-Adv, a novel attack framework that jointly targets the image-scaling and classification stages. This framework packs several novel techniques, including novel representations of the scaling defenses. It also defines two integrations that allow for attacking the machine learning system pipeline in the white-box and black-box settings. Based on this framework, we evaluate cutting-edge defenses at each processing stage. For scaling attacks, we show that Scale-Adv can evade four out of five state-of-the-art defenses by incorporating adversarial examples. For classification, we show that Scale-Adv can significantly improve the performance of machine learning attacks by leveraging weaknesses in the scaling algorithm. We empirically observe that Scale-Adv can produce adversarial examples with less perturbation and higher confidence than vanilla black-box and white-box attacks. We further demonstrate the transferability of Scale-Adv on a commercial online API.
MultiRes-NetVLAD: Augmenting Place Recognition Training with Low-Resolution Imagery
Feb 18, 2022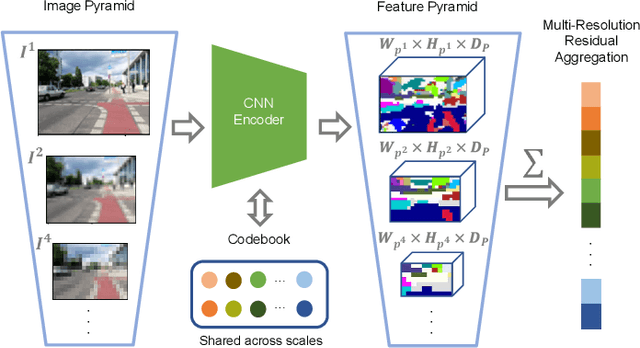
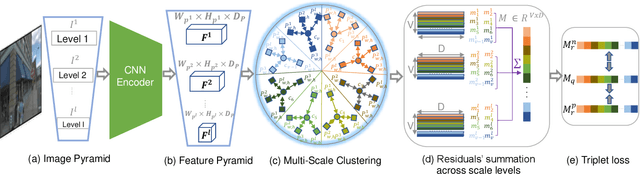
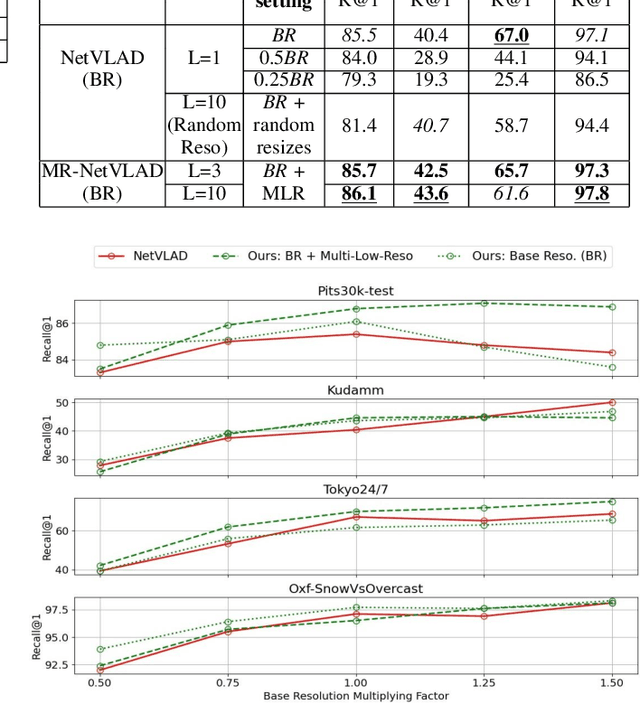

Visual Place Recognition (VPR) is a crucial component of 6-DoF localization, visual SLAM and structure-from-motion pipelines, tasked to generate an initial list of place match hypotheses by matching global place descriptors. However, commonly-used CNN-based methods either process multiple image resolutions after training or use a single resolution and limit multi-scale feature extraction to the last convolutional layer during training. In this paper, we augment NetVLAD representation learning with low-resolution image pyramid encoding which leads to richer place representations. The resultant multi-resolution feature pyramid can be conveniently aggregated through VLAD into a single compact representation, avoiding the need for concatenation or summation of multiple patches in recent multi-scale approaches. Furthermore, we show that the underlying learnt feature tensor can be combined with existing multi-scale approaches to improve their baseline performance. Evaluation on 15 viewpoint-varying and viewpoint-consistent benchmarking datasets confirm that the proposed MultiRes-NetVLAD leads to state-of-the-art Recall@N performance for global descriptor based retrieval, compared against 11 existing techniques. Source code is publicly available at https://github.com/Ahmedest61/MultiRes-NetVLAD.
* 12 pages, 6 Figures, Accepted for publication in IEEE RA-L 2022 and ICRA 2022, includes supplementary material
Dual Transfer Learning for Event-based End-task Prediction via Pluggable Event to Image Translation
Sep 04, 2021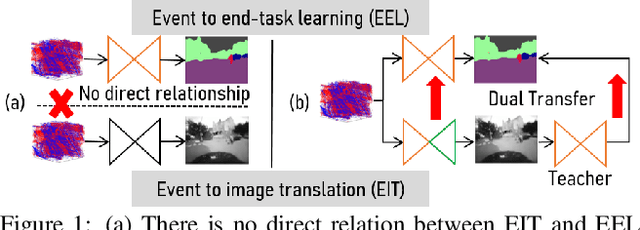



Event cameras are novel sensors that perceive the per-pixel intensity changes and output asynchronous event streams with high dynamic range and less motion blur. It has been shown that events alone can be used for end-task learning, \eg, semantic segmentation, based on encoder-decoder-like networks. However, as events are sparse and mostly reflect edge information, it is difficult to recover original details merely relying on the decoder. Moreover, most methods resort to pixel-wise loss alone for supervision, which might be insufficient to fully exploit the visual details from sparse events, thus leading to less optimal performance. In this paper, we propose a simple yet flexible two-stream framework named Dual Transfer Learning (DTL) to effectively enhance the performance on the end-tasks without adding extra inference cost. The proposed approach consists of three parts: event to end-task learning (EEL) branch, event to image translation (EIT) branch, and transfer learning (TL) module that simultaneously explores the feature-level affinity information and pixel-level knowledge from the EIT branch to improve the EEL branch. This simple yet novel method leads to strong representation learning from events and is evidenced by the significant performance boost on the end-tasks such as semantic segmentation and depth estimation.
Ghost projection. II. Beam shaping using realistic spatially-random masks
Feb 18, 2022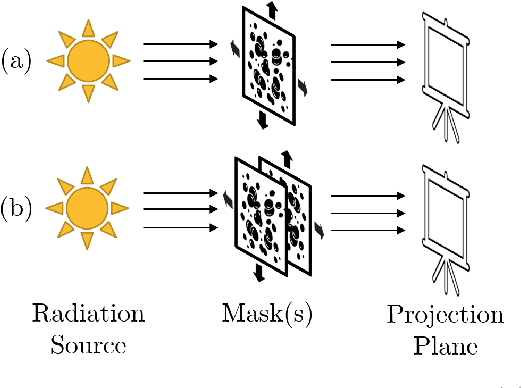
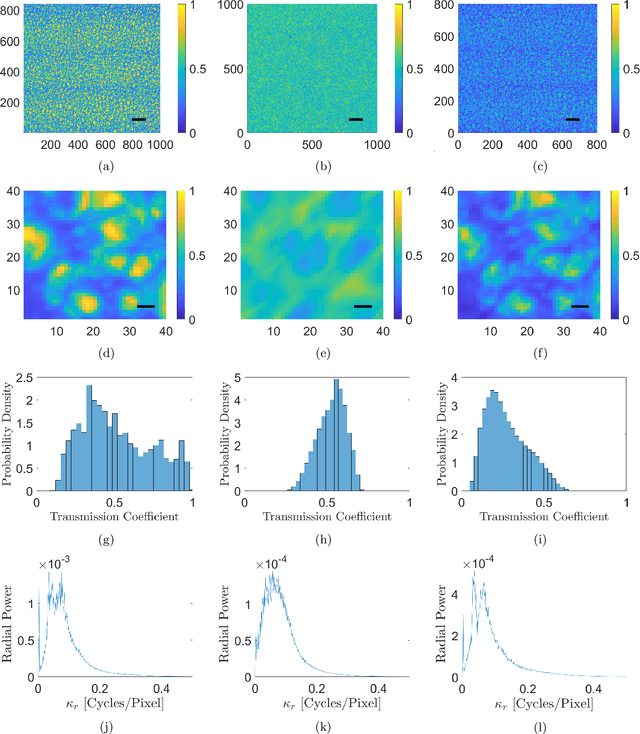
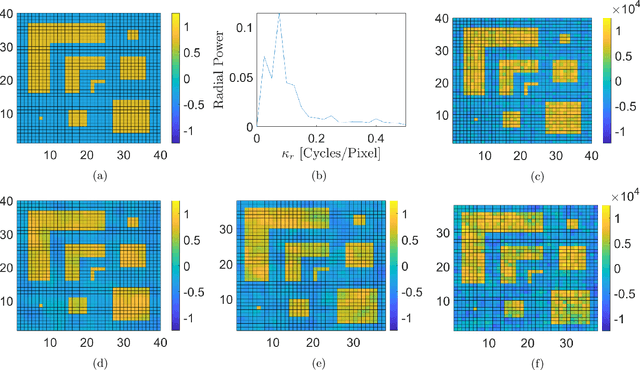
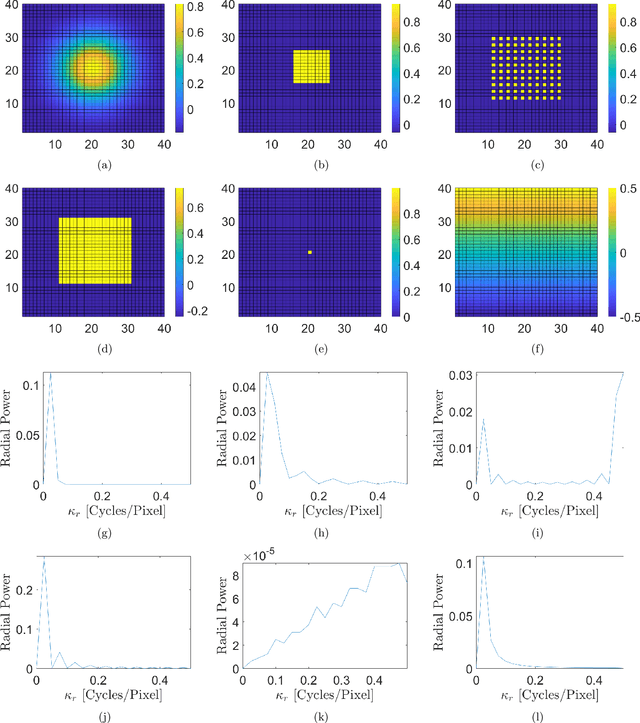
The spatial light modulator and optical data projector both rely on precisely configurable optical elements to shape a light beam. Here we explore an image-projection approach which does not require a configurable beam-shaping element. We term this approach {\em ghost projection} on account of its conceptual relation to computational ghost imaging. Instead of a configurable beam shaping element, the method transversely displaces a single illuminated mask, such as a spatially-random screen, to create specified distributions of radiant exposure. The method has potential applicability to image projection employing a variety of radiation and matter wave fields, such as hard x rays, neutrons, muons, atomic beams and molecular beams. Building on our previous theoretical and computational studies, we here seek to understand the effects, sensitivity, and tolerance of some key experimental limitations of the method. Focusing on the case of hard x rays, we employ experimentally acquired masks to numerically study the deleterious effects of photon shot noise, inaccuracies in random-mask exposure time, and inaccuracies in mask positioning, as well as adapting to spatially non-uniform illumination. Understanding the influence of these factors will assist in optimizing experimental design and work towards achieving ghost projection in practice.