 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SeeingGAN: Galactic image deblurring with deep learning for better morphological classification of galaxies
Mar 17, 2021
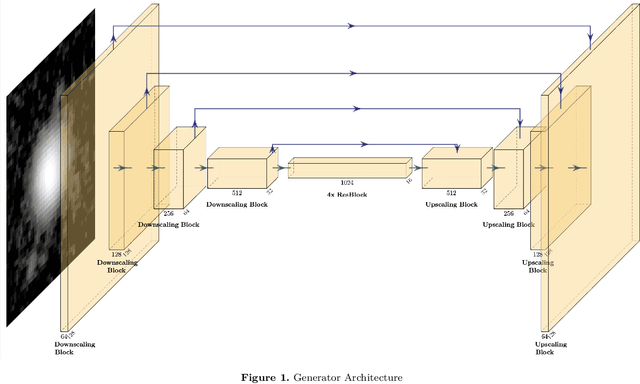


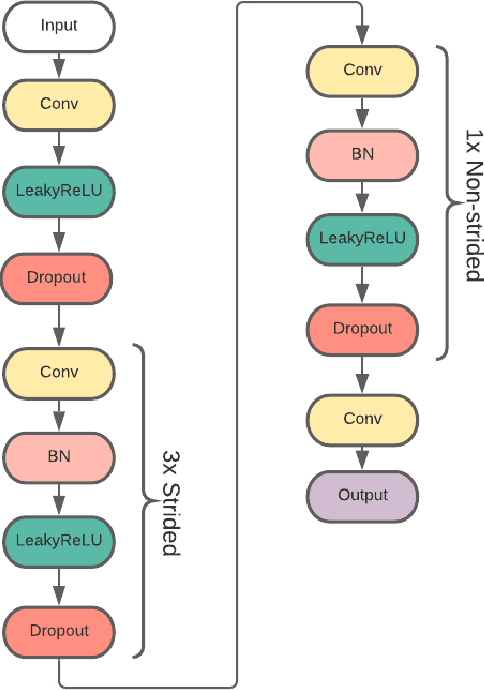
Classification of galactic morphologies is a crucial task in galactic astronomy, and identifying fine structures of galaxies (e.g., spiral arms, bars, and clumps) is an essential ingredient in such a classification task. However, seeing effects can cause images we obtain to appear blurry, making it difficult for astronomers to derive galaxies' physical properties and, in particular, distant galaxies. Here, we present a method that converts blurred images obtained by the ground-based Subaru Telescope into quasi Hubble Space Telescope (HST) images via machine learning. Using an existing deep learning method called generative adversarial networks (GANs), we can eliminate seeing effects, effectively resulting in an image similar to an image taken by the HST. Using multiple Subaru telescope image and HST telescope image pairs, we demonstrate that our model can augment fine structures present in the blurred images in aid for better and more precise galactic classification. Using our first of its kind machine learning-based deblurring technique on space images, we can obtain up to 18% improvement in terms of CW-SSIM (Complex Wavelet Structural Similarity Index) score when comparing the Subaru-HST pair versus SeeingGAN-HST pair. With this model, we can generate HST-like images from relatively less capable telescopes, making space exploration more accessible to the broader astronomy community. Furthermore, this model can be used not only in professional morphological classification studies of galaxies but in all citizen science for galaxy classifications.
Multi-focus Image Fusion for Visual Sensor Networks
Oct 02, 2020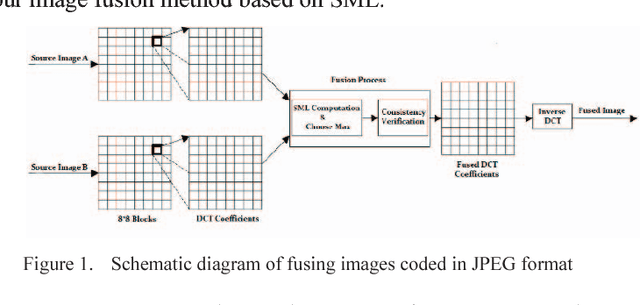



Image fusion in visual sensor networks (VSNs) aims to combine information from multiple images of the same scene in order to transform a single image with more information. Image fusion methods based on discrete cosine transform (DCT) are less complex and time-saving in DCT based standards of image and video which makes them more suitable for VSN applications. In this paper, an efficient algorithm for the fusion of multi-focus images in the DCT domain is proposed. The Sum of modified laplacian (SML) of corresponding blocks of source images is used as a contrast criterion and blocks with the larger value of SML are absorbed to output images. The experimental results on several images show the improvement of the proposed algorithm in terms of both subjective and objective quality of fused image relative to other DCT based techniques.
Continual Contrastive Self-supervised Learning for Image Classification
Jul 06, 2021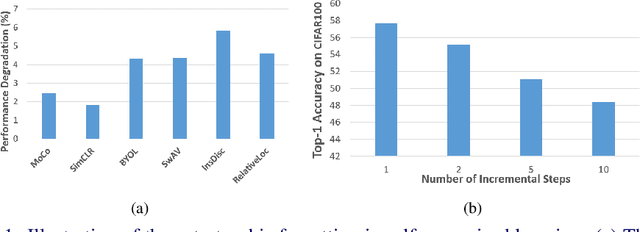
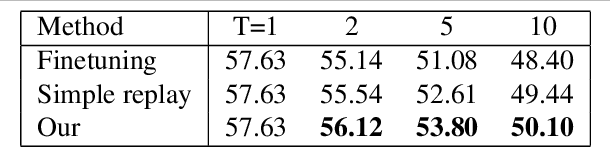

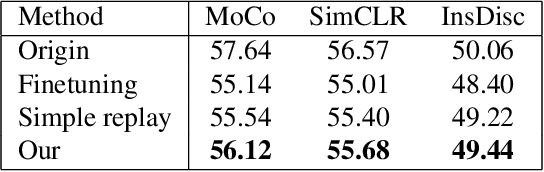
For artificial learning systems, continual learning over time from a stream of data is essential. The burgeoning studies on supervised continual learning have achieved great progress, while the study of catastrophic forgetting in unsupervised learning is still blank. Among unsupervised learning methods, self-supervise learning method shows tremendous potential on visual representation without any labeled data at scale. To improve the visual representation of self-supervised learning, larger and more varied data is needed. In the real world, unlabeled data is generated at all times. This circumstance provides a huge advantage for the learning of the self-supervised method. However, in the current paradigm, packing previous data and current data together and training it again is a waste of time and resources. Thus, a continual self-supervised learning method is badly needed. In this paper, we make the first attempt to implement the continual contrastive self-supervised learning by proposing a rehearsal method, which keeps a few exemplars from the previous data. Instead of directly combining saved exemplars with the current data set for training, we leverage self-supervised knowledge distillation to transfer contrastive information among previous data to the current network by mimicking similarity score distribution inferred by the old network over a set of saved exemplars. Moreover, we build an extra sample queue to assist the network to distinguish between previous and current data and prevent mutual interference while learning their own feature representation. Experimental results show that our method performs well on CIFAR100 and ImageNet-Sub. Compared with the baselines, which learning tasks without taking any technique, we improve the image classification top-1 accuracy by 1.60% on CIFAR100, 2.86% on ImageNet-Sub and 1.29% on ImageNet-Full under 10 incremental steps setting.
Rolling Colors: Adversarial Laser Exploits against Traffic Light Recognition
Apr 06, 2022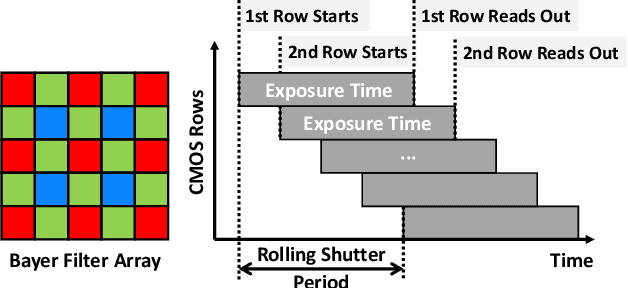


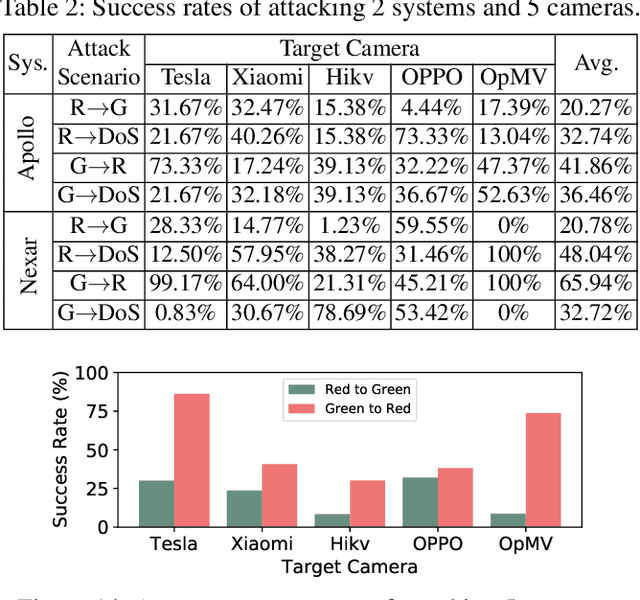
Traffic light recognition is essential for fully autonomous driving in urban areas. In this paper, we investigate the feasibility of fooling traffic light recognition mechanisms by shedding laser interference on the camera. By exploiting the rolling shutter of CMOS sensors, we manage to inject a color stripe overlapped on the traffic light in the image, which can cause a red light to be recognized as a green light or vice versa. To increase the success rate, we design an optimization method to search for effective laser parameters based on empirical models of laser interference. Our evaluation in emulated and real-world setups on 2 state-of-the-art recognition systems and 5 cameras reports a maximum success rate of 30% and 86.25% for Red-to-Green and Green-to-Red attacks. We observe that the attack is effective in continuous frames from more than 40 meters away against a moving vehicle, which may cause end-to-end impacts on self-driving such as running a red light or emergency stop. To mitigate the threat, we propose redesigning the rolling shutter mechanism.
Federated Learning for the Classification of Tumor Infiltrating Lymphocytes
Apr 01, 2022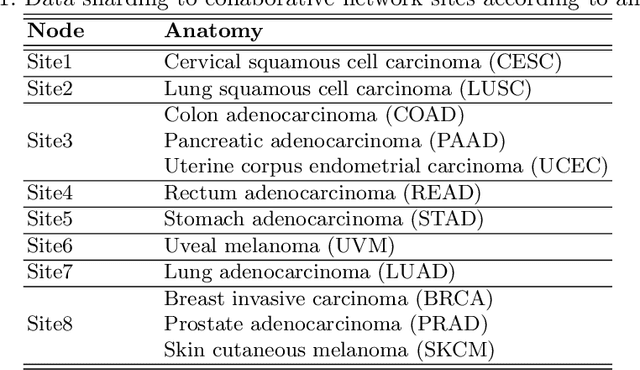
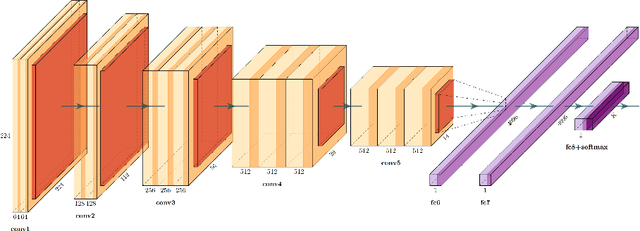

We evaluate the performance of federated learning (FL) in developing deep learning models for analysis of digitized tissue sections. A classification application was considered as the example use case, on quantifiying the distribution of tumor infiltrating lymphocytes within whole slide images (WSIs). A deep learning classification model was trained using 50*50 square micron patches extracted from the WSIs. We simulated a FL environment in which a dataset, generated from WSIs of cancer from numerous anatomical sites available by The Cancer Genome Atlas repository, is partitioned in 8 different nodes. Our results show that the model trained with the federated training approach achieves similar performance, both quantitatively and qualitatively, to that of a model trained with all the training data pooled at a centralized location. Our study shows that FL has tremendous potential for enabling development of more robust and accurate models for histopathology image analysis without having to collect large and diverse training data at a single location.
Multi-layered tensor networks for image classification
Nov 13, 2020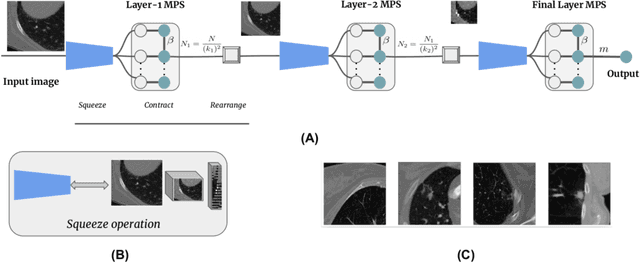

The recently introduced locally orderless tensor network (LoTeNet) for supervised image classification uses matrix product state (MPS) operations on grids of transformed image patches. The resulting patch representations are combined back together into the image space and aggregated hierarchically using multiple MPS blocks per layer to obtain the final decision rules. In this work, we propose a non-patch based modification to LoTeNet that performs one MPS operation per layer, instead of several patch-level operations. The spatial information in the input images to MPS blocks at each layer is squeezed into the feature dimension, similar to LoTeNet, to maximise retained spatial correlation between pixels when images are flattened into 1D vectors. The proposed multi-layered tensor network (MLTN) is capable of learning linear decision boundaries in high dimensional spaces in a multi-layered setting, which results in a reduction in the computation cost compared to LoTeNet without any degradation in performance.
Unsupervised Image Segmentation using Mutual Mean-Teaching
Dec 16, 2020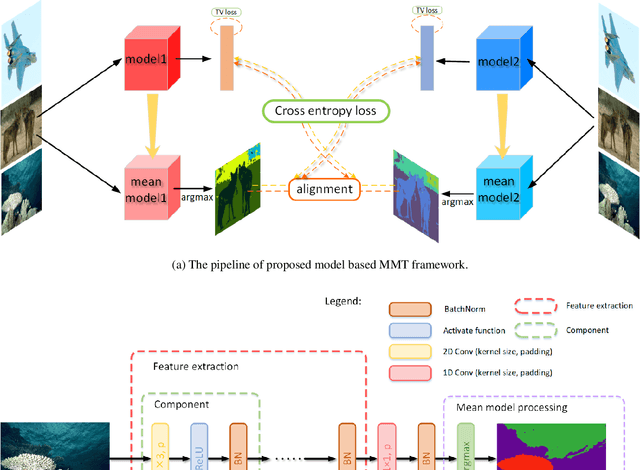
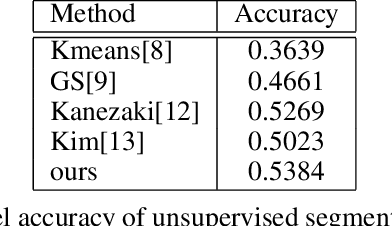
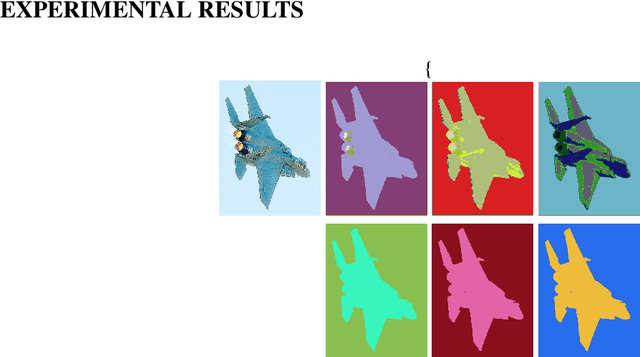

Unsupervised image segmentation aims at assigning the pixels with similar feature into a same cluster without annotation, which is an important task in computer vision. Due to lack of prior knowledge, most of existing model usually need to be trained several times to obtain suitable results. To address this problem, we propose an unsupervised image segmentation model based on the Mutual Mean-Teaching (MMT) framework to produce more stable results. In addition, since the labels of pixels from two model are not matched, a label alignment algorithm based on the Hungarian algorithm is proposed to match the cluster labels. Experimental results demonstrate that the proposed model is able to segment various types of images and achieves better performance than the existing methods.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022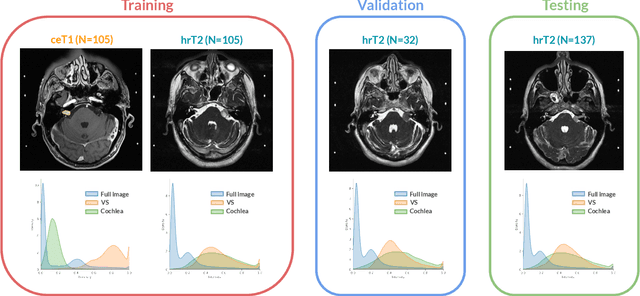
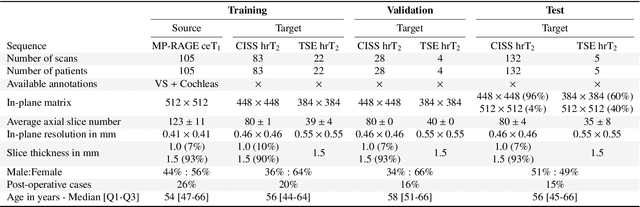
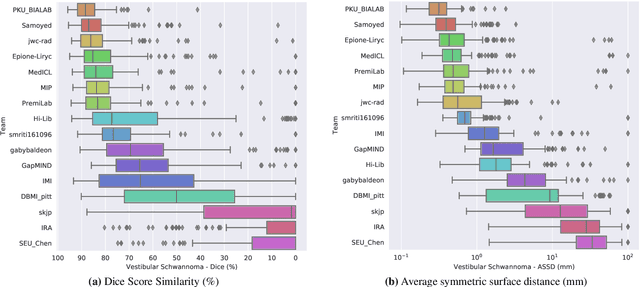
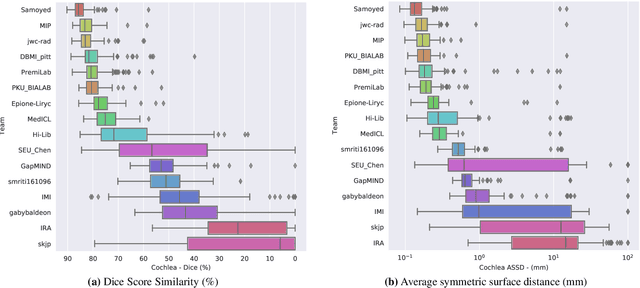
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.
Quaternion-based dynamic mode decomposition for background modeling in color videos
Dec 28, 2021
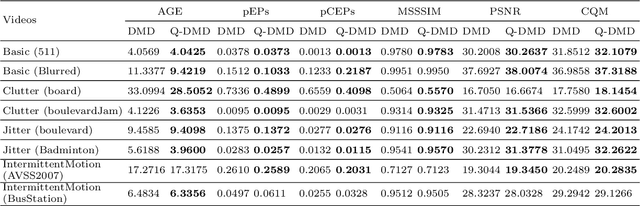
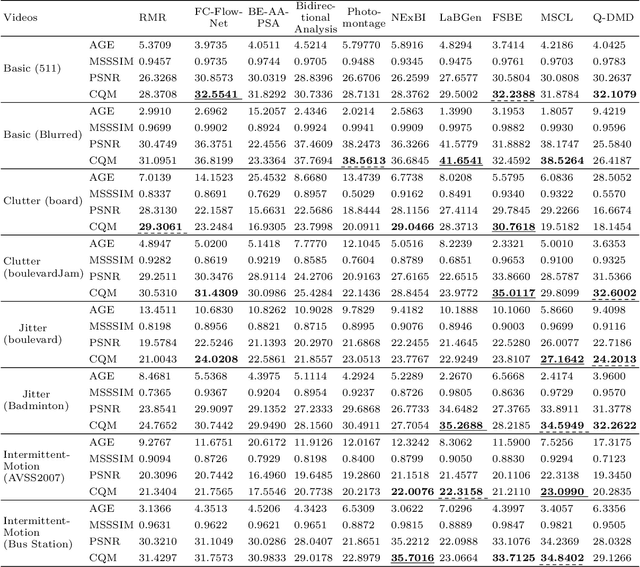

Scene Background Initialization (SBI) is one of the challenging problems in computer vision. Dynamic mode decomposition (DMD) is a recently proposed method to robustly decompose a video sequence into the background model and the corresponding foreground part. However, this method needs to convert the color image into the grayscale image for processing, which leads to the neglect of the coupling information between the three channels of the color image. In this study, we propose a quaternion-based DMD (Q-DMD), which extends the DMD by quaternion matrix analysis, so as to completely preserve the inherent color structure of the color image and the color video. We exploit the standard eigenvalues of the quaternion matrix to compute its spectral decomposition and calculate the corresponding Q-DMD modes and eigenvalues. The results on the publicly available benchmark datasets prove that our Q-DMD outperforms the exact DMD method, and experiment results also demonstrate that the performance of our approach is comparable to that of the state-of-the-art ones.
MalNet: A Large-Scale Cybersecurity Image Database of Malicious Software
Jan 31, 2021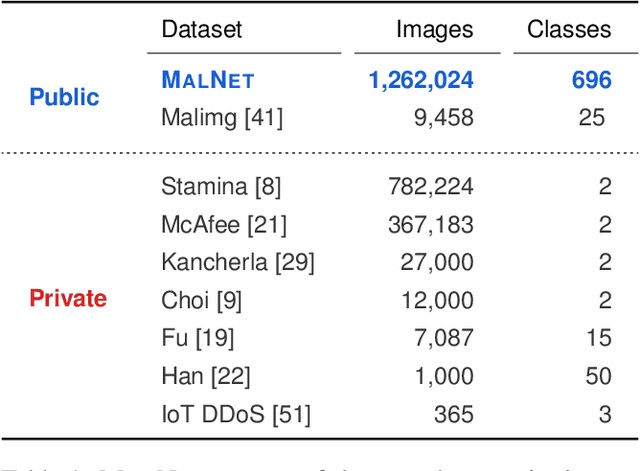
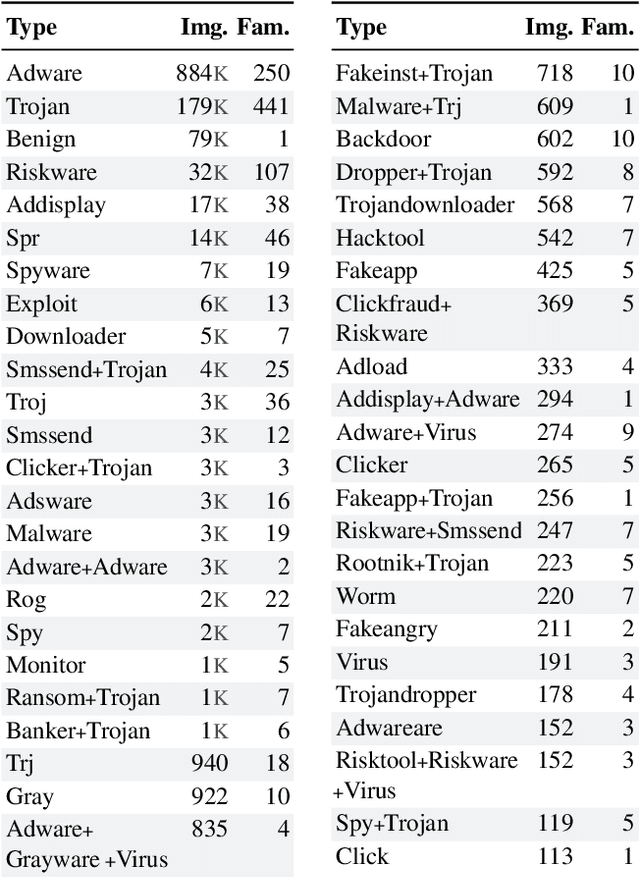
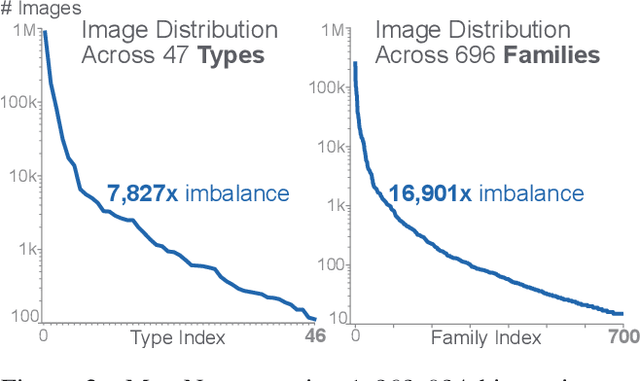
Computer vision is playing an increasingly important role in automated malware detection with to the rise of the image-based binary representation. These binary images are fast to generate, require no feature engineering, and are resilient to popular obfuscation methods. Significant research has been conducted in this area, however, it has been restricted to small-scale or private datasets that only a few industry labs and research teams have access to. This lack of availability hinders examination of existing work, development of new research, and dissemination of ideas. We introduce MalNet, the largest publicly available cybersecurity image database, offering 133x more images and 27x more classes than the only other public binary-image database. MalNet contains over 1.2 million images across a hierarchy of 47 types and 696 families. We provide extensive analysis of MalNet, discussing its properties and provenance. The scale and diversity of MalNet unlocks new and exciting cybersecurity opportunities to the computer vision community--enabling discoveries and research directions that were previously not possible. The database is publicly available at www.mal-net.org.