 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021
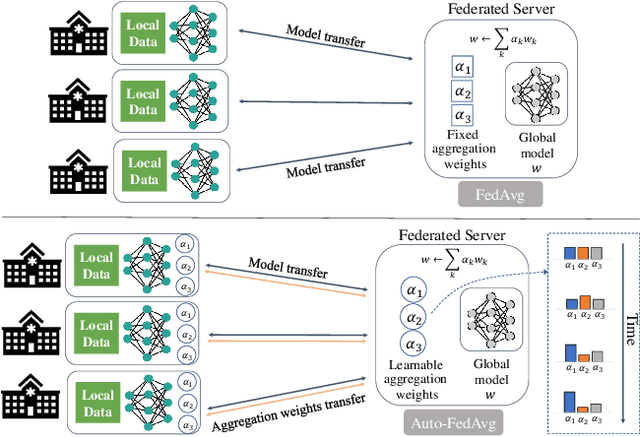
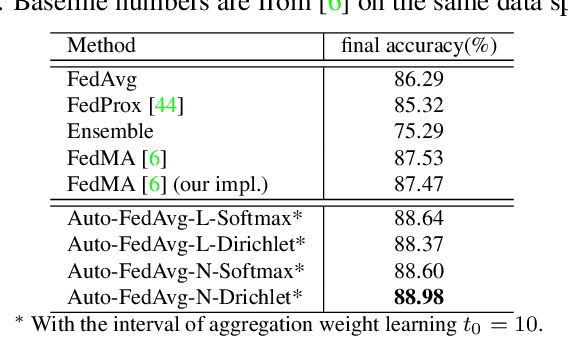
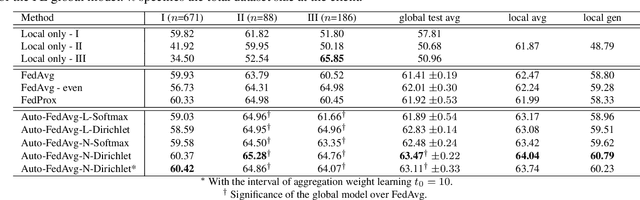
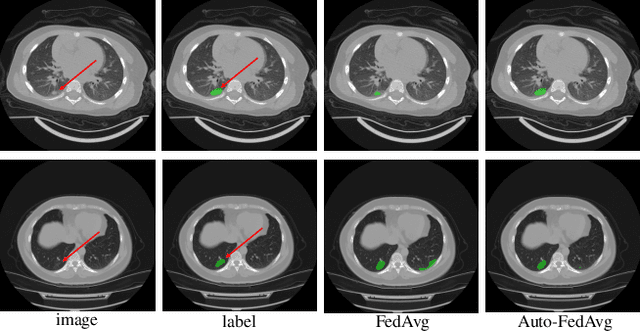
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Rayleigh EigenDirections (REDs): GAN latent space traversals for multidimensional features
Jan 25, 2022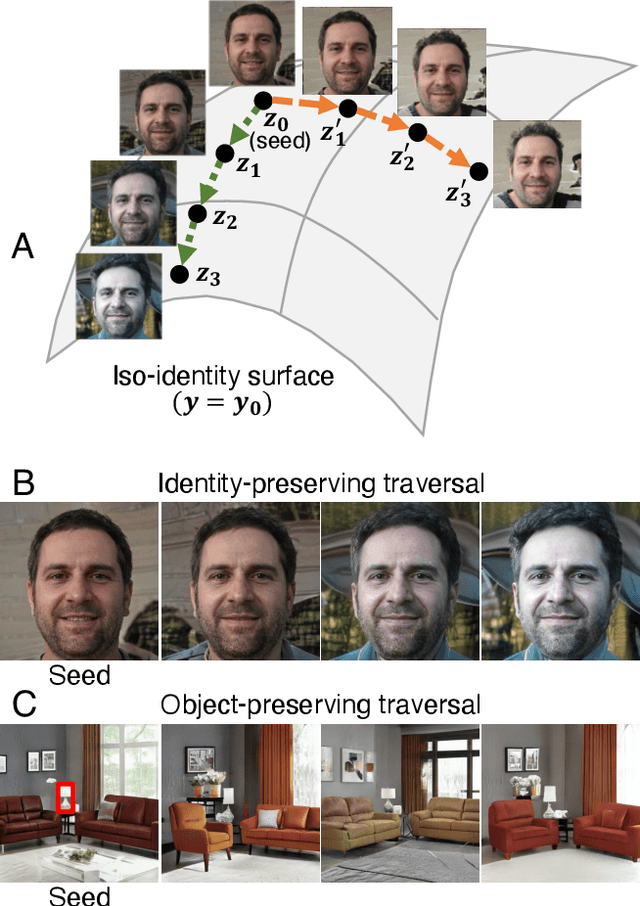

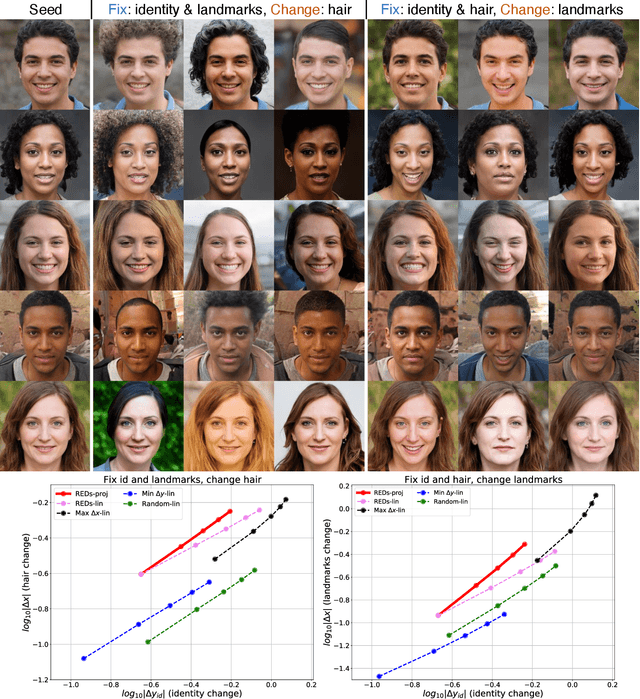

We present a method for finding paths in a deep generative model's latent space that can maximally vary one set of image features while holding others constant. Crucially, unlike past traversal approaches, ours can manipulate multidimensional features of an image such as facial identity and pixels within a specified region. Our method is principled and conceptually simple: optimal traversal directions are chosen by maximizing differential changes to one feature set such that changes to another set are negligible. We show that this problem is nearly equivalent to one of Rayleigh quotient maximization, and provide a closed-form solution to it based on solving a generalized eigenvalue equation. We use repeated computations of the corresponding optimal directions, which we call Rayleigh EigenDirections (REDs), to generate appropriately curved paths in latent space. We empirically evaluate our method using StyleGAN2 on two image domains: faces and living rooms. We show that our method is capable of controlling various multidimensional features out of the scope of previous latent space traversal methods: face identity, spatial frequency bands, pixels within a region, and the appearance and position of an object. Our work suggests that a wealth of opportunities lies in the local analysis of the geometry and semantics of latent spaces.
Adversarial samples for deep monocular 6D object pose estimation
Mar 05, 2022


Estimating 6D object pose from an RGB image is important for many real-world applications such as autonomous driving and robotic grasping. Recent deep learning models have achieved significant progress on this task but their robustness received little research attention. In this work, for the first time, we study adversarial samples that can fool deep learning models with imperceptible perturbations to input image. In particular, we propose a Unified 6D pose estimation Attack, namely U6DA, which can successfully attack several state-of-the-art (SOTA) deep learning models for 6D pose estimation. The key idea of our U6DA is to fool the models to predict wrong results for object instance localization and shape that are essential for correct 6D pose estimation. Specifically, we explore a transfer-based black-box attack to 6D pose estimation. We design the U6DA loss to guide the generation of adversarial examples, the loss aims to shift the segmentation attention map away from its original position. We show that the generated adversarial samples are not only effective for direct 6D pose estimation models, but also are able to attack two-stage models regardless of their robust RANSAC modules. Extensive experiments were conducted to demonstrate the effectiveness, transferability, and anti-defense capability of our U6DA on large-scale public benchmarks. We also introduce a new U6DA-Linemod dataset for robustness study of the 6D pose estimation task. Our codes and dataset will be available at \url{https://github.com/cuge1995/U6DA}.
A Dual-branch Network for Infrared and Visible Image Fusion
Jan 24, 2021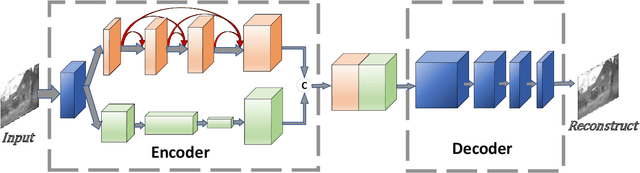
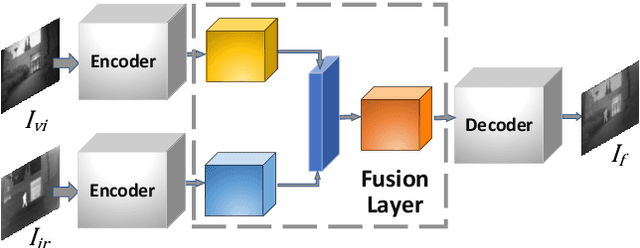
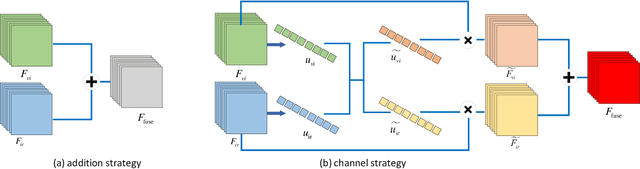

Deep learning is a rapidly developing approach in the field of infrared and visible image fusion. In this context, the use of dense blocks in deep networks significantly improves the utilization of shallow information, and the combination of the Generative Adversarial Network (GAN) also improves the fusion performance of two source images. We propose a new method based on dense blocks and GANs , and we directly insert the input image-visible light image in each layer of the entire network. We use SSIM and gradient loss functions that are more consistent with perception instead of mean square error loss. After the adversarial training between the generator and the discriminator, we show that a trained end-to-end fusion network -- the generator network -- is finally obtained. Our experiments show that the fused images obtained by our approach achieve good score based on multiple evaluation indicators. Further, our fused images have better visual effects in multiple sets of contrasts, which are more satisfying to human visual perception.
Conditional Variational Image Deraining
Apr 23, 2020
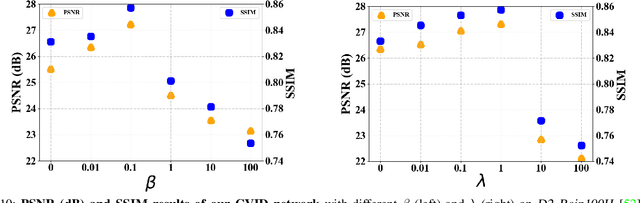
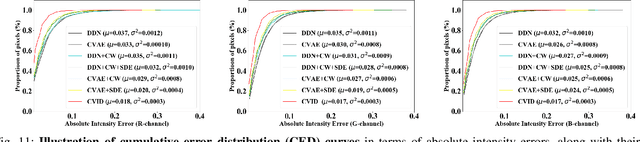
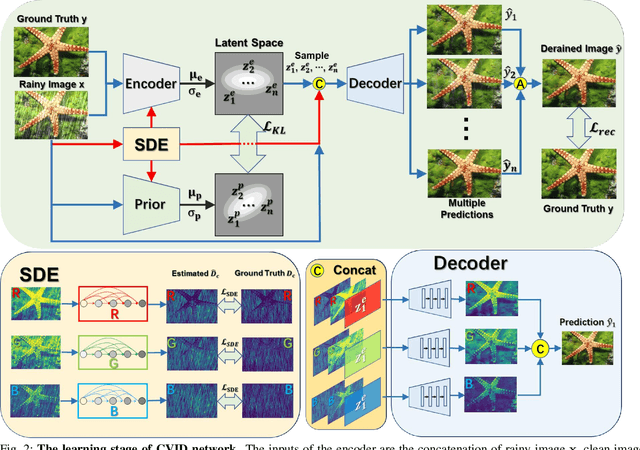
Image deraining is an important yet challenging image processing task. Though deterministic image deraining methods are developed with encouraging performance, they are infeasible to learn flexible representations for probabilistic inference and diverse predictions. Besides, rain intensity varies both in spatial locations and across color channels, making this task more difficult. In this paper, we propose a Conditional Variational Image Deraining (CVID) network for better deraining performance, leveraging the exclusive generative ability of Conditional Variational Auto-Encoder (CVAE) on providing diverse predictions for the rainy image. To perform spatially adaptive deraining, we propose a spatial density estimation (SDE) module to estimate a rain density map for each image. Since rain density varies across different color channels, we also propose a channel-wise (CW) deraining scheme. Experiments on synthesized and real-world datasets show that the proposed CVID network achieves much better performance than previous deterministic methods on image deraining. Extensive ablation studies validate the effectiveness of the proposed SDE module and CW scheme in our CVID network. The code is available at \url{https://github.com/Yingjun-Du/VID}.
NBNet: Noise Basis Learning for Image Denoising with Subspace Projection
Dec 30, 2020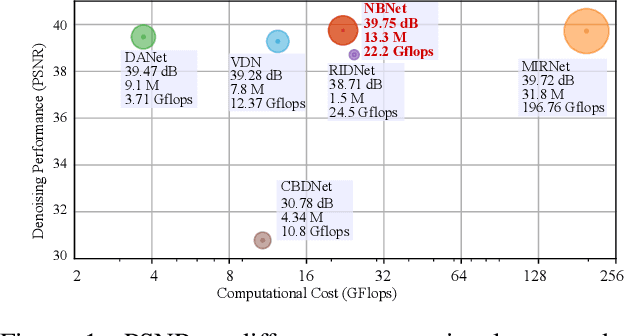
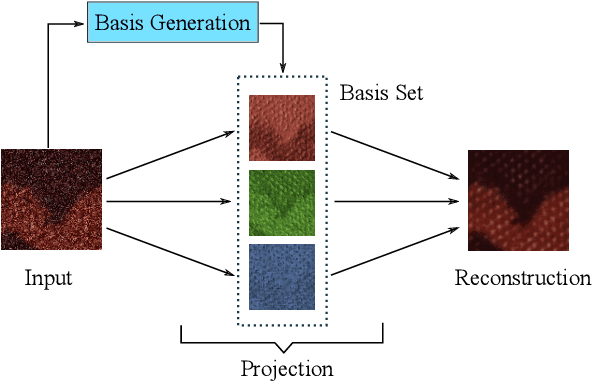
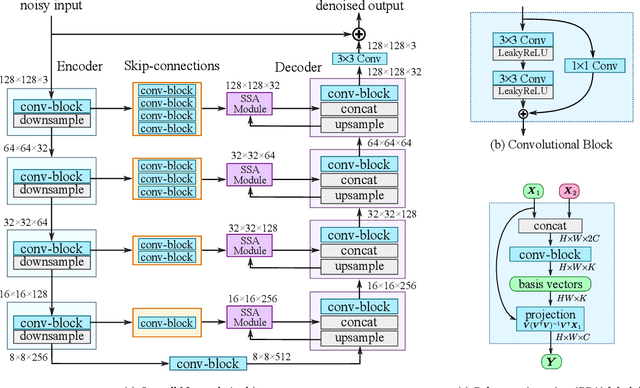
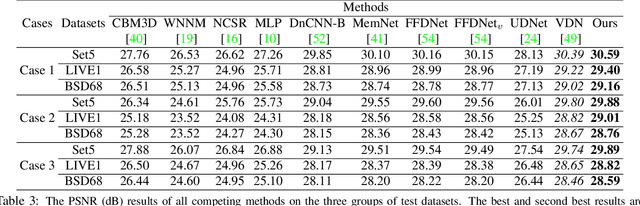
In this paper, we introduce NBNet, a novel framework for image denoising. Unlike previous works, we propose to tackle this challenging problem from a new perspective: noise reduction by image-adaptive projection. Specifically, we propose to train a network that can separate signal and noise by learning a set of reconstruction basis in the feature space. Subsequently, image denosing can be achieved by selecting corresponding basis of the signal subspace and projecting the input into such space. Our key insight is that projection can naturally maintain the local structure of input signal, especially for areas with low light or weak textures. Towards this end, we propose SSA, a non-local subspace attention module designed explicitly to learn the basis generation as well as the subspace projection. We further incorporate SSA with NBNet, a UNet structured network designed for end-to-end image denosing. We conduct evaluations on benchmarks, including SIDD and DND, and NBNet achieves state-of-the-art performance on PSNR and SSIM with significantly less computational cost.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022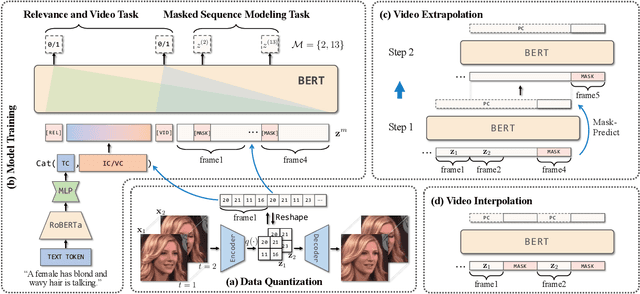
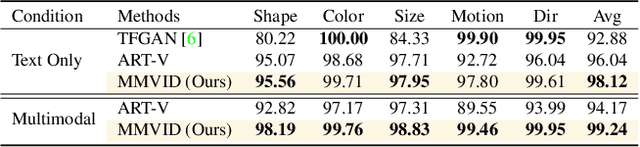


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
Robust Representation Learning with Feedback for Single Image Deraining
Feb 03, 2021

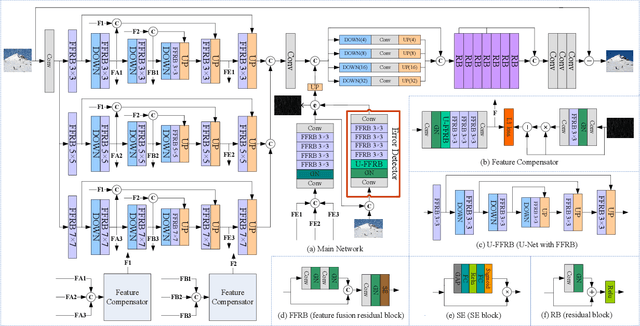
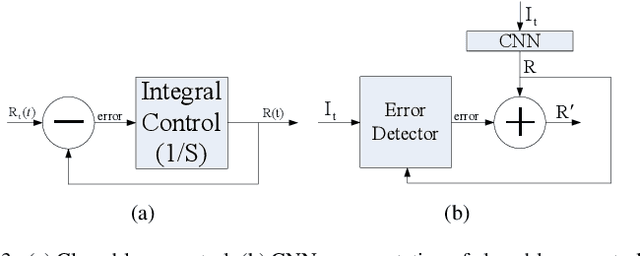
A deraining network may be interpreted as a condition generator. Image degradation generated by the deraining network can be attributed to defective embedding features that serve as conditions. Existing image deraining methods usually ignore uncertainty-caused model errors that lower embedding quality and embed low-quality features into the model directly. In contrast, we replace low-quality features by latent high-quality features. The spirit of closed-loop feedback in the automatic control field is borrowed to obtain latent high-quality features. A new method for error detection and feature compensation is proposed to address model errors. Extensive experiments on benchmark datasets as well as specific real datasets demonstrate the advantage of the proposed method over recent state-of-the-art methods.
Category-Aware Transformer Network for Better Human-Object Interaction Detection
Apr 11, 2022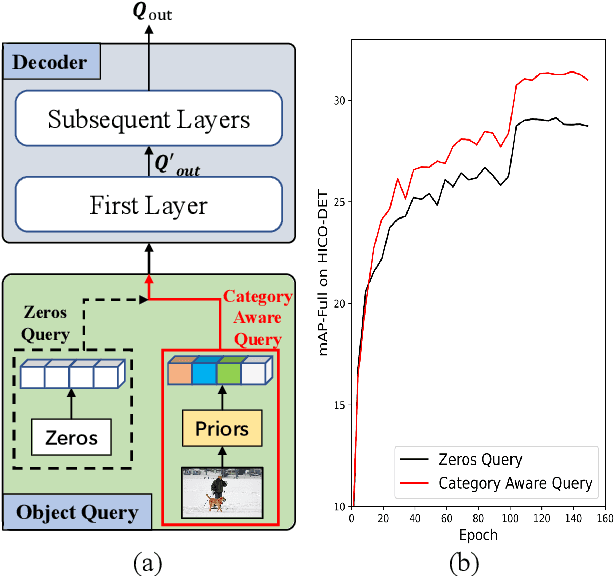
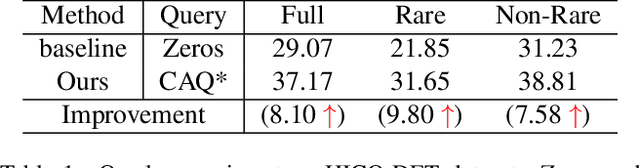
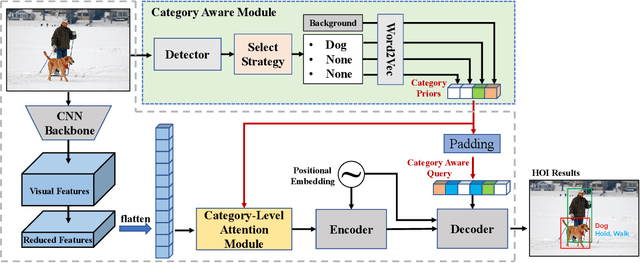
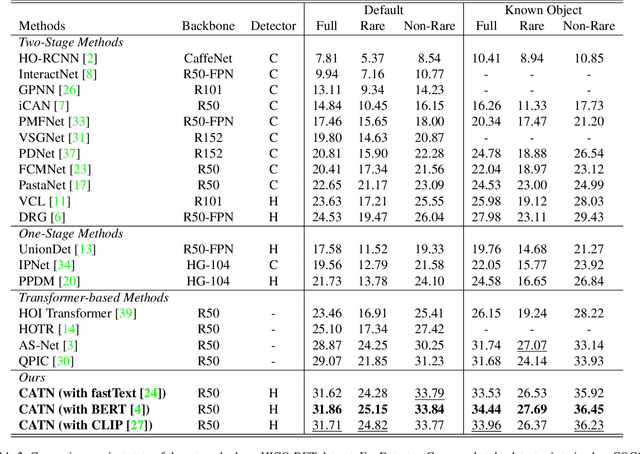
Human-Object Interactions (HOI) detection, which aims to localize a human and a relevant object while recognizing their interaction, is crucial for understanding a still image. Recently, transformer-based models have significantly advanced the progress of HOI detection. However, the capability of these models has not been fully explored since the Object Query of the model is always simply initialized as just zeros, which would affect the performance. In this paper, we try to study the issue of promoting transformer-based HOI detectors by initializing the Object Query with category-aware semantic information. To this end, we innovatively propose the Category-Aware Transformer Network (CATN). Specifically, the Object Query would be initialized via category priors represented by an external object detection model to yield better performance. Moreover, such category priors can be further used for enhancing the representation ability of features via the attention mechanism. We have firstly verified our idea via the Oracle experiment by initializing the Object Query with the groundtruth category information. And then extensive experiments have been conducted to show that a HOI detection model equipped with our idea outperforms the baseline by a large margin to achieve a new state-of-the-art result.
Multi-pooled Inception features for no-reference image quality assessment
Nov 10, 2020
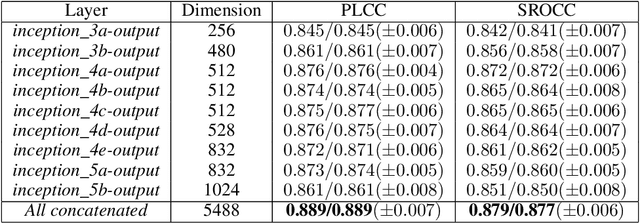
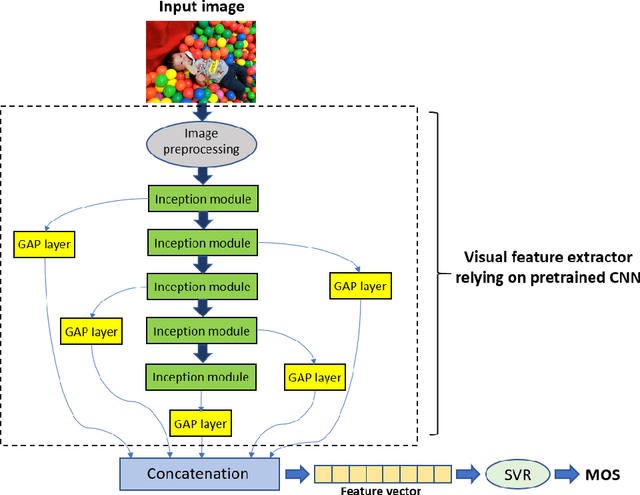
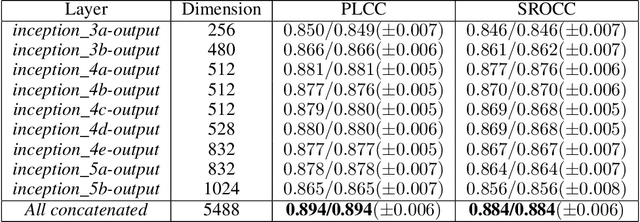
Image quality assessment (IQA) is an important element of a broad spectrum of applications ranging from automatic video streaming to display technology. Furthermore, the measurement of image quality requires a balanced investigation of image content and features. Our proposed approach extracts visual features by attaching global average pooling (GAP) layers to multiple Inception modules of on an ImageNet database pretrained convolutional neural network (CNN). In contrast to previous methods, we do not take patches from the input image. Instead, the input image is treated as a whole and is run through a pretrained CNN body to extract resolution-independent, multi-level deep features. As a consequence, our method can be easily generalized to any input image size and pretrained CNNs. Thus, we present a detailed parameter study with respect to the CNN base architectures and the effectiveness of different deep features. We demonstrate that our best proposal - called MultiGAP-NRIQA - is able to provide state-of-the-art results on three benchmark IQA databases. Furthermore, these results were also confirmed in a cross database test using the LIVE In the Wild Image Quality Challenge database.