 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Picosecond Hyperspectral Fringe Pattern Projection for 3D Surface Measurement
Mar 18, 2022
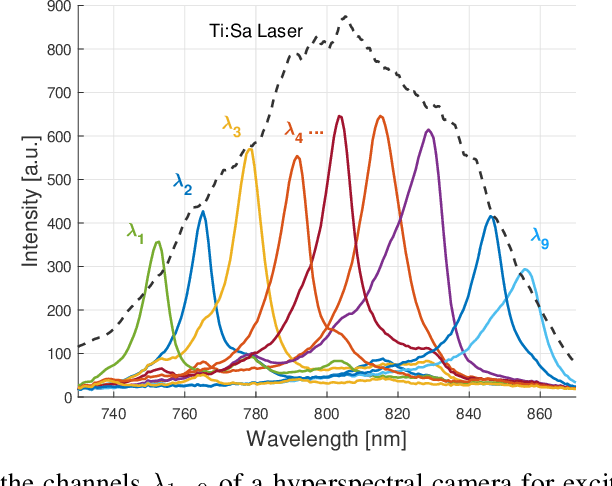
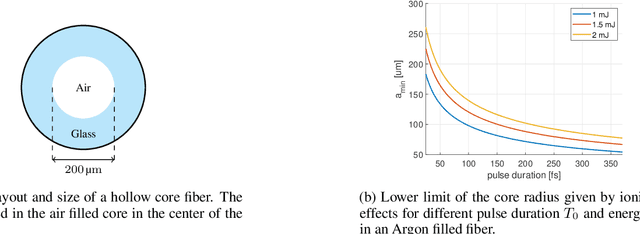
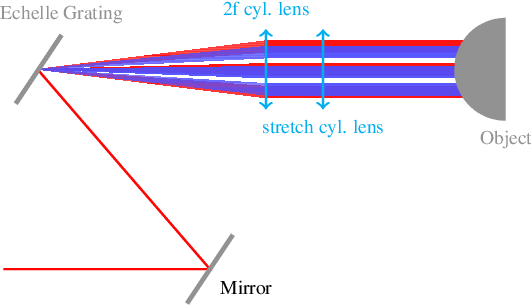

Active stereovision systems for the 3D measurement of surfaces rely on the sequential projection of different fringe patterns onto the scene to robustly and accurately generate 3D surface data. This limits the temporal resolution to the time by which a sufficiently high number of patterns can be projected and recorded. By encoding patterns spectrally and recording them with a hyperspectral imager, it is possible to record several patterns in a single image, limiting the temporal resolution to only the duration of the illumination. A picosecond 3D surface measurement was demonstrated using a high pulse energy femtosecond Ti:Sa laser, spectrally broadened in a hollow core fiber, and two hyperspectral cameras recording the patterns generated by diffraction at an Echelle grating.
Optical Flow Estimation from a Single Motion-blurred Image
Mar 10, 2021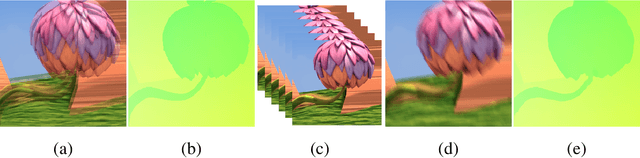

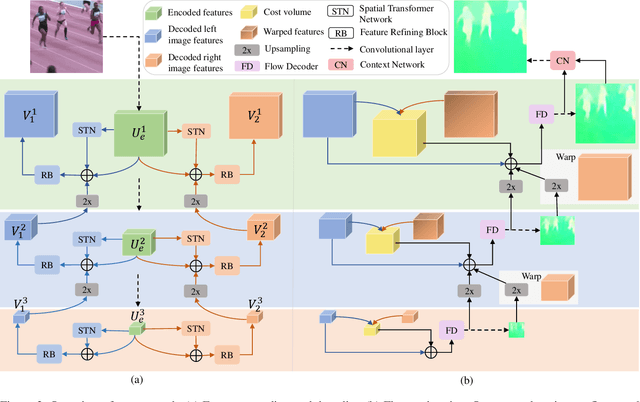
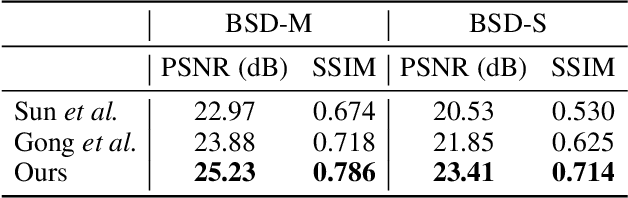
In most of computer vision applications, motion blur is regarded as an undesirable artifact. However, it has been shown that motion blur in an image may have practical interests in fundamental computer vision problems. In this work, we propose a novel framework to estimate optical flow from a single motion-blurred image in an end-to-end manner. We design our network with transformer networks to learn globally and locally varying motions from encoded features of a motion-blurred input, and decode left and right frame features without explicit frame supervision. A flow estimator network is then used to estimate optical flow from the decoded features in a coarse-to-fine manner. We qualitatively and quantitatively evaluate our model through a large set of experiments on synthetic and real motion-blur datasets. We also provide in-depth analysis of our model in connection with related approaches to highlight the effectiveness and favorability of our approach. Furthermore, we showcase the applicability of the flow estimated by our method on deblurring and moving object segmentation tasks.
An Extendable, Efficient and Effective Transformer-based Object Detector
Apr 17, 2022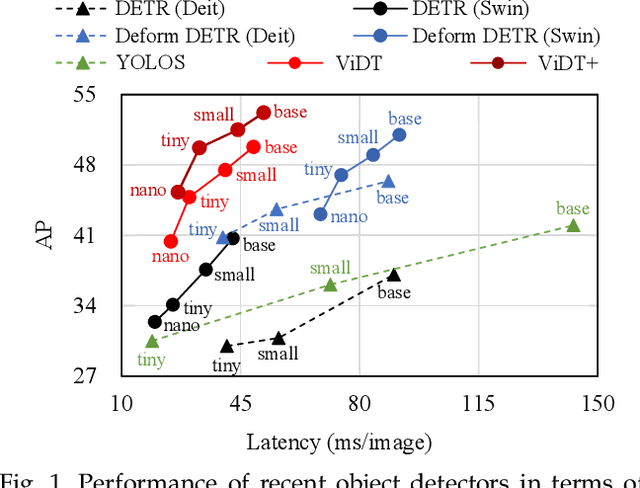
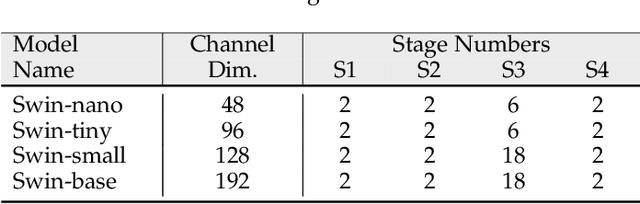
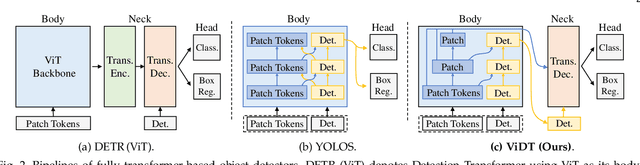
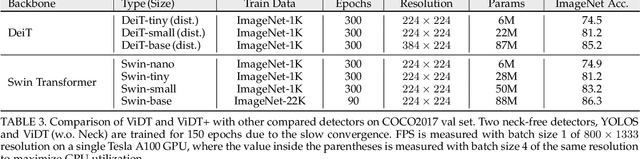
Transformers have been widely used in numerous vision problems especially for visual recognition and detection. Detection transformers are the first fully end-to-end learning systems for object detection, while vision transformers are the first fully transformer-based architecture for image classification. In this paper, we integrate Vision and Detection Transformers (ViDT) to construct an effective and efficient object detector. ViDT introduces a reconfigured attention module to extend the recent Swin Transformer to be a standalone object detector, followed by a computationally efficient transformer decoder that exploits multi-scale features and auxiliary techniques essential to boost the detection performance without much increase in computational load. In addition, we extend it to ViDT+ to support joint-task learning for object detection and instance segmentation. Specifically, we attach an efficient multi-scale feature fusion layer and utilize two more auxiliary training losses, IoU-aware loss and token labeling loss. Extensive evaluation results on the Microsoft COCO benchmark dataset demonstrate that ViDT obtains the best AP and latency trade-off among existing fully transformer-based object detectors, and its extended ViDT+ achieves 53.2AP owing to its high scalability for large models. The source code and trained models are available at https://github.com/naver-ai/vidt.
You Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
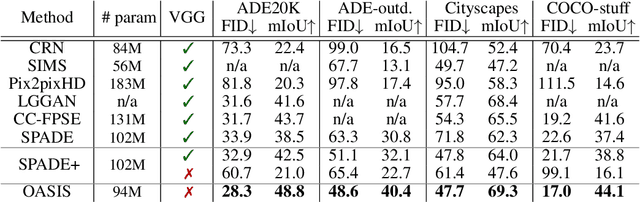

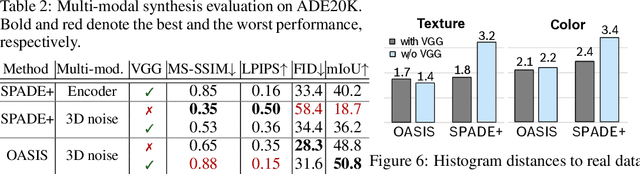
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.
Unitary rotation of pixellated polychromatic images
Mar 11, 2022
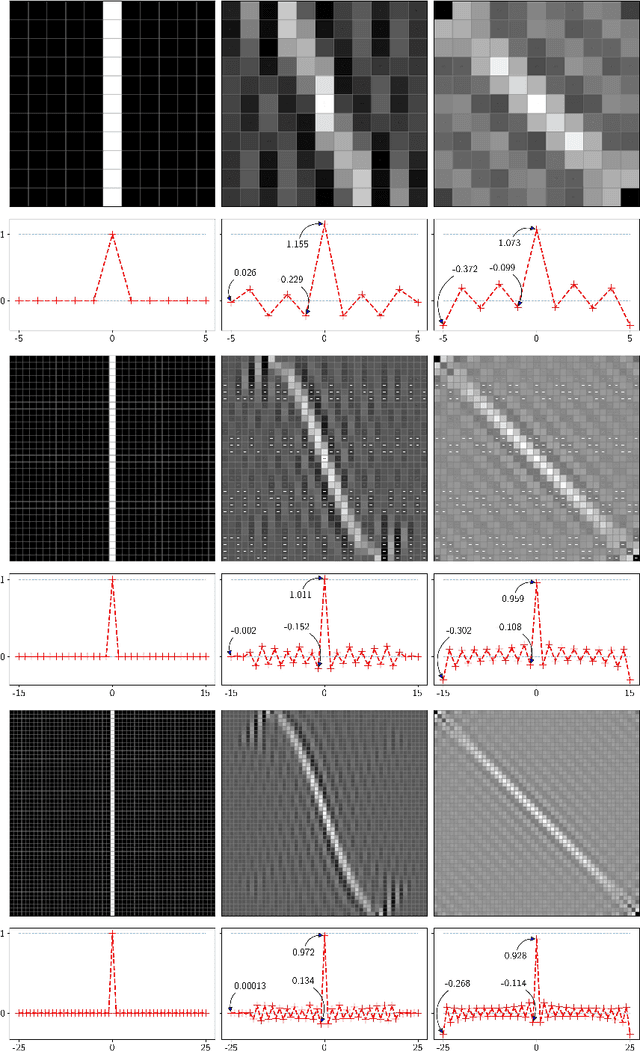
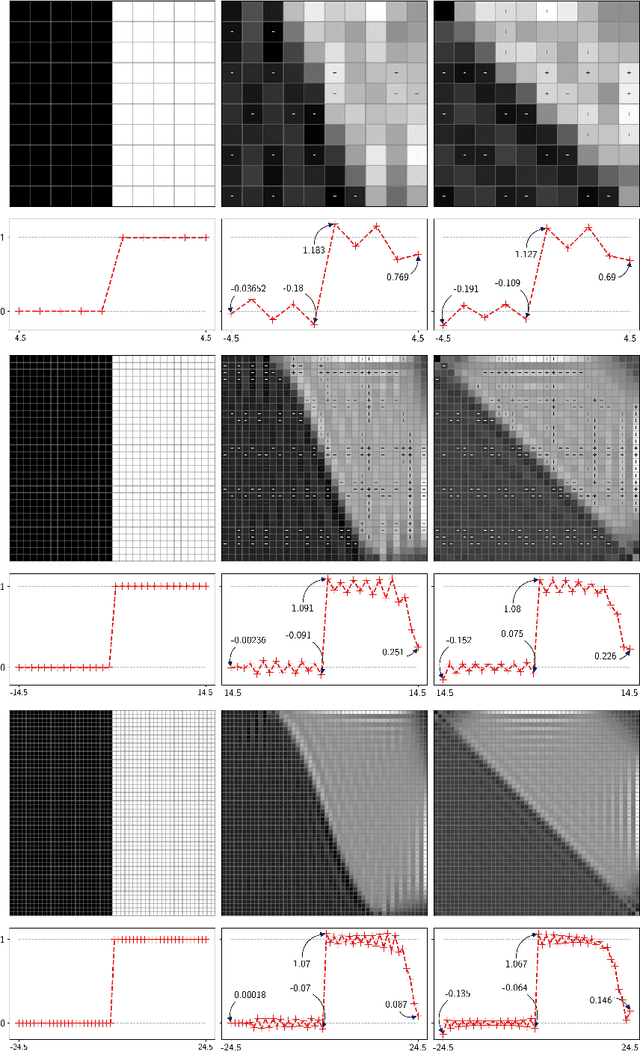

Unitary rotations of polychromatic images on finite two-dimensional pixellated screens provide invertibility, group composition, and thus conservation of information. Rotations have been applied on monochromatic image data sets, where we now examine closer the Gibbs-like oscillations that appear due to discrete "discontinuities" of the input images under unitary transformations. Extended to three-color images we examine here the display of color at the pixels where, due to the oscillations, some pixel color values may fall outside their required common numerical range [0, 1], between absence and saturation of the red, green, and blue formant color images.
Ultrasound Image Classification using ACGAN with Small Training Dataset
Jan 31, 2021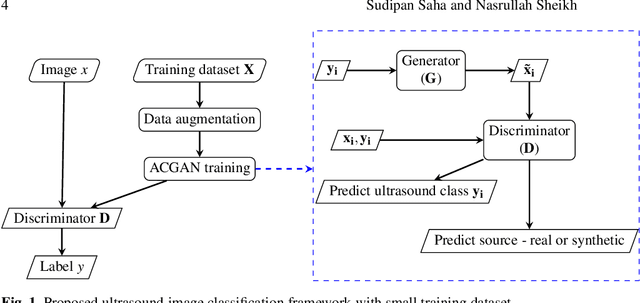
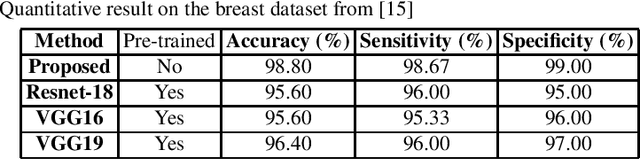
B-mode ultrasound imaging is a popular medical imaging technique. Like other image processing tasks, deep learning has been used for analysis of B-mode ultrasound images in the last few years. However, training deep learning models requires large labeled datasets, which is often unavailable for ultrasound images. The lack of large labeled data is a bottleneck for the use of deep learning in ultrasound image analysis. To overcome this challenge, in this work we exploit Auxiliary Classifier Generative Adversarial Network (ACGAN) that combines the benefits of data augmentation and transfer learning in the same framework. We conduct experiment on a dataset of breast ultrasound images that shows the effectiveness of the proposed approach.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
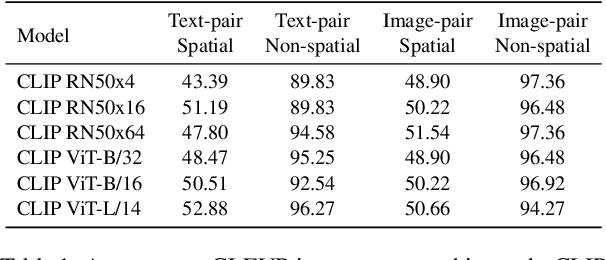
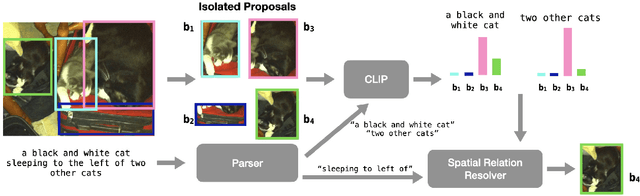
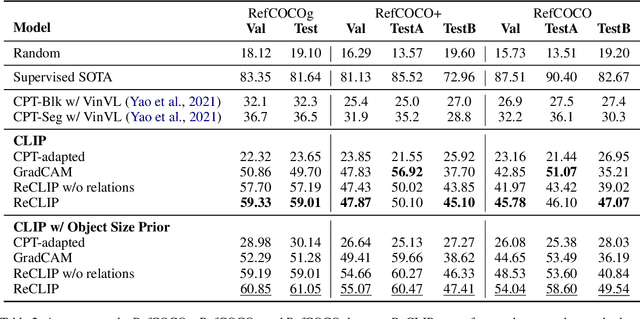
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.
Benchmarking Robustness of Deep Learning Classifiers Using Two-Factor Perturbation
Mar 02, 2022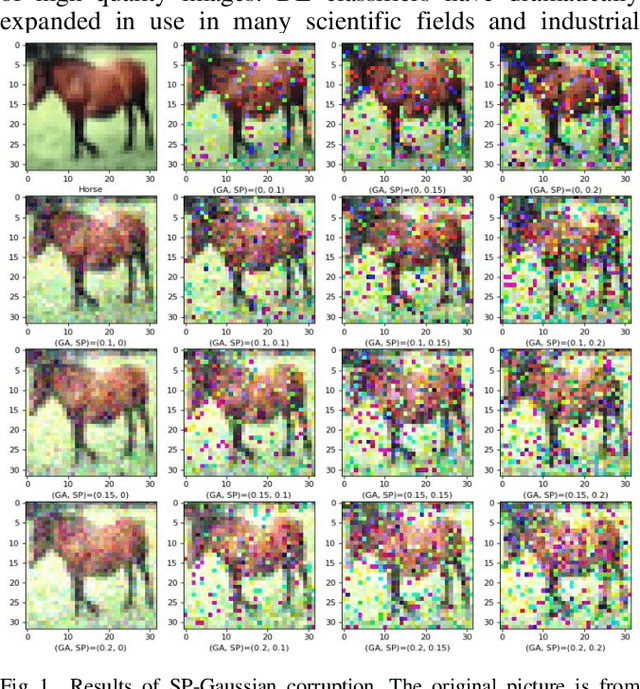

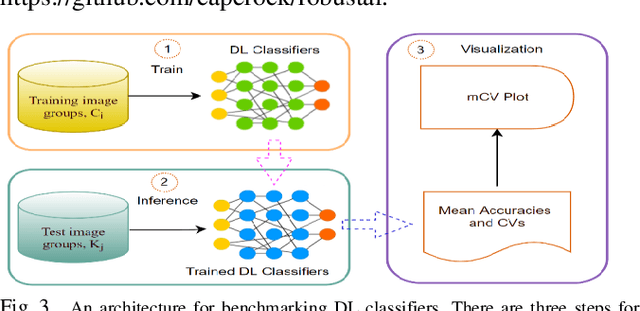
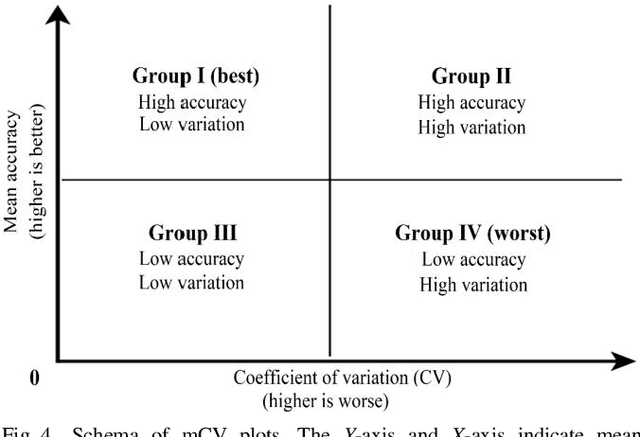
Accuracies of deep learning (DL) classifiers are often unstable in that they may change significantly when retested on adversarial images, imperfect images, or perturbed images. This paper adds to the fundamental body of work on benchmarking the robustness of DL classifiers on defective images. To measure robust DL classifiers, previous research reported on single-factor corruption. We created comprehensive 69 benchmarking image sets, including a clean set, sets with single factor perturbations, and sets with two-factor perturbation conditions. The state-of-the-art two-factor perturbation includes (a) two digital perturbations (salt & pepper noise and Gaussian noise) applied in both sequences, and (b) one digital perturbation (salt & pepper noise) and a geometric perturbation (rotation) applied in both sequences. Previous research evaluating DL classifiers has often used top-1/top-5 accuracy. We innovate a new two-dimensional, statistical matrix to evaluating robustness of DL classifiers. Also, we introduce a new visualization tool, including minimum accuracy, maximum accuracy, mean accuracies, and coefficient of variation (CV), for benchmarking robustness of DL classifiers. Comparing with single factor corruption, we first report that using two-factor perturbed images improves both robustness and accuracy of DL classifiers. All source codes and related image sets are shared on the Website at http://cslinux.semo.edu/david/data to support future academic research and industry projects.
Feature-Style Encoder for Style-Based GAN Inversion
Feb 04, 2022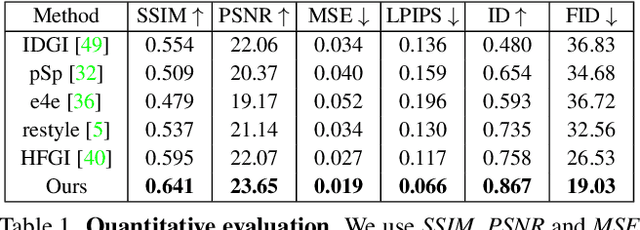
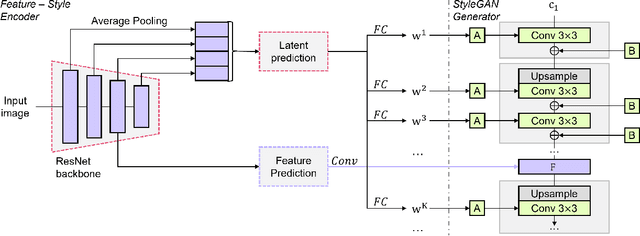
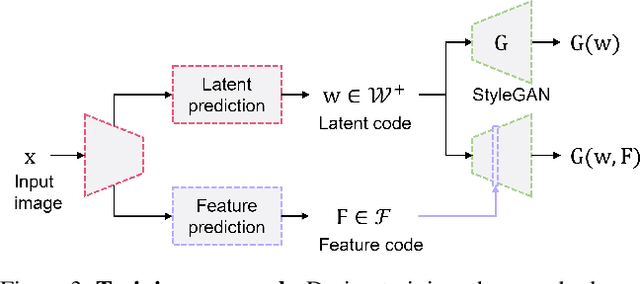
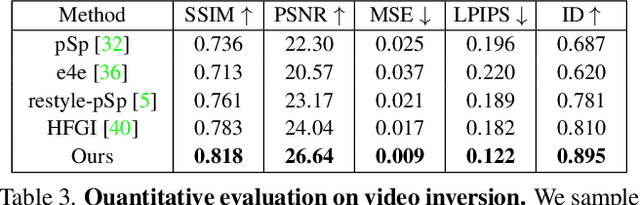
We propose a novel architecture for GAN inversion, which we call Feature-Style encoder. The style encoder is key for the manipulation of the obtained latent codes, while the feature encoder is crucial for optimal image reconstruction. Our model achieves accurate inversion of real images from the latent space of a pre-trained style-based GAN model, obtaining better perceptual quality and lower reconstruction error than existing methods. Thanks to its encoder structure, the model allows fast and accurate image editing. Additionally, we demonstrate that the proposed encoder is especially well-suited for inversion and editing on videos. We conduct extensive experiments for several style-based generators pre-trained on different data domains. Our proposed method yields state-of-the-art results for style-based GAN inversion, significantly outperforming competing approaches. Source codes are available at https://github.com/InterDigitalInc/FeatureStyleEncoder .
BigEarthNet-MM: A Large Scale Multi-Modal Multi-Label Benchmark Archive for Remote Sensing Image Classification and Retrieval
May 17, 2021
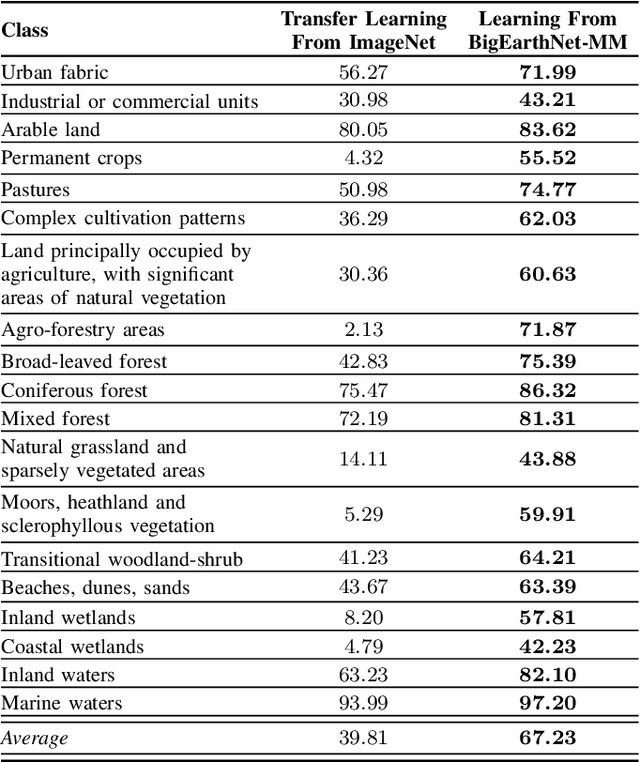
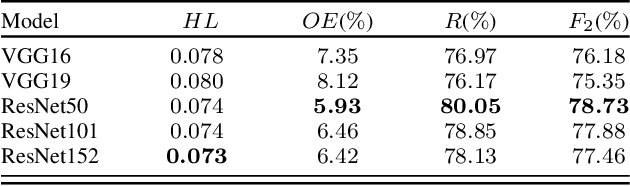
This paper presents the multi-modal BigEarthNet (BigEarthNet-MM) benchmark archive made up of 590,326 pairs of Sentinel-1 and Sentinel-2 image patches to support the deep learning (DL) studies in multi-modal multi-label remote sensing (RS) image retrieval and classification. Each pair of patches in BigEarthNet-MM is annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its thematically most detailed Level-3 class nomenclature. Our initial research demonstrates that some CLC classes are challenging to be accurately described by only considering (single-date) BigEarthNet-MM images. In this paper, we also introduce an alternative class-nomenclature as an evolution of the original CLC labels to address this problem. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of BigEarthNet-MM images in a new nomenclature of 19 classes. In our experiments, we show the potential of BigEarthNet-MM for multi-modal multi-label image retrieval and classification problems by considering several state-of-the-art DL models. We also demonstrate that the DL models trained from scratch on BigEarthNet-MM outperform those pre-trained on ImageNet, especially in relation to some complex classes, including agriculture and other vegetated and natural environments. We make all the data and the DL models publicly available at https://bigearth.net, offering an important resource to support studies on multi-modal image scene classification and retrieval problems in RS.