 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Annotation-Free Evaluation of Cross-Lingual Image Captioning
Dec 09, 2020
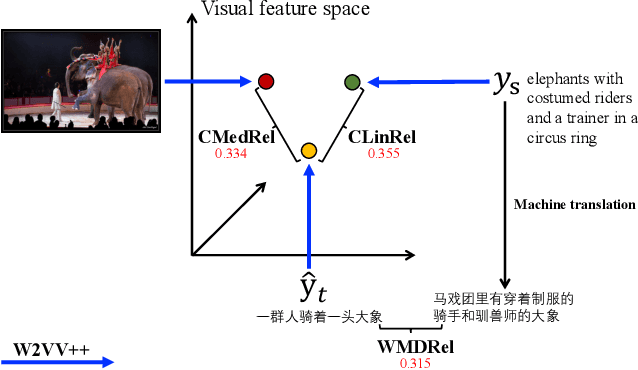
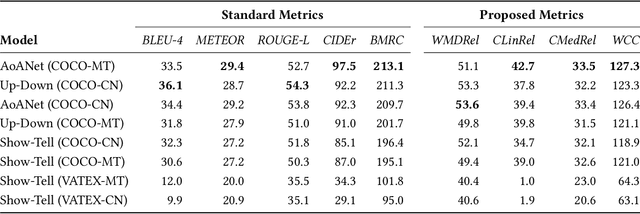
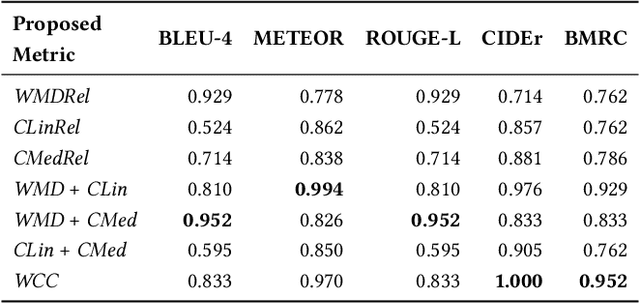
Cross-lingual image captioning, with its ability to caption an unlabeled image in a target language other than English, is an emerging topic in the multimedia field. In order to save the precious human resource from re-writing reference sentences per target language, in this paper we make a brave attempt towards annotation-free evaluation of cross-lingual image captioning. Depending on whether we assume the availability of English references, two scenarios are investigated. For the first scenario with the references available, we propose two metrics, i.e., WMDRel and CLinRel. WMDRel measures the semantic relevance between a model-generated caption and machine translation of an English reference using their Word Mover's Distance. By projecting both captions into a deep visual feature space, CLinRel is a visual-oriented cross-lingual relevance measure. As for the second scenario, which has zero reference and is thus more challenging, we propose CMedRel to compute a cross-media relevance between the generated caption and the image content, in the same visual feature space as used by CLinRel. The promising results show high potential of the new metrics for evaluation with no need of references in the target language.
RealNet: Combining Optimized Object Detection with Information Fusion Depth Estimation Co-Design Method on IoT
Apr 24, 2022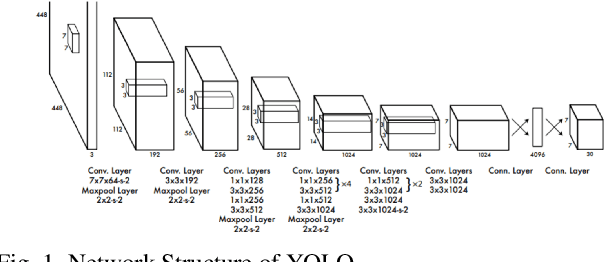

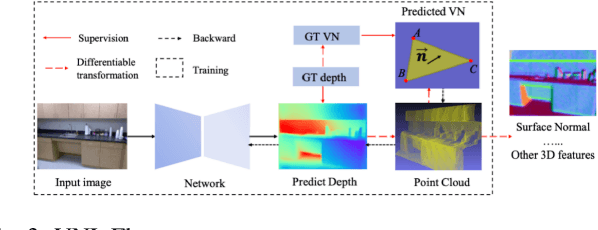

Depth Estimation and Object Detection Recognition play an important role in autonomous driving technology under the guidance of deep learning artificial intelligence. We propose a hybrid structure called RealNet: a co-design method combining the model-streamlined recognition algorithm, the depth estimation algorithm with information fusion, and deploying them on the Jetson-Nano for unmanned vehicles with monocular vision sensors. We use ROS for experiment. The method proposed in this paper is suitable for mobile platforms with high real-time request. Innovation of our method is using information fusion to compensate the problem of insufficient frame rate of output image, and improve the robustness of target detection and depth estimation under monocular vision.Object Detection is based on YOLO-v5. We have simplified the network structure of its DarkNet53 and realized a prediction speed up to 0.01s. Depth Estimation is based on the VNL Depth Estimation, which considers multiple geometric constraints in 3D global space. It calculates the loss function by calculating the deviation of the virtual normal vector VN and the label, which can obtain deeper depth information. We use PnP fusion algorithm to solve the problem of insufficient frame rate of depth map output. It solves the motion estimation depth from three-dimensional target to two-dimensional point based on corner feature matching, which is faster than VNL calculation. We interpolate VNL output and PnP output to achieve information fusion. Experiments show that this can effectively eliminate the jitter of depth information and improve robustness. At the control end, this method combines the results of target detection and depth estimation to calculate the target position, and uses a pure tracking control algorithm to track it.
Optimizing Ghost Imaging via Analysis and Design of Speckle Patterns
Mar 10, 2022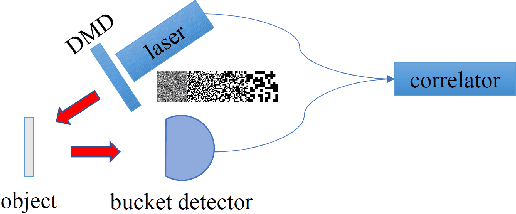



We study the influence rules of the speckle size of light source on ghost imaging, and propose a new type of speckle patterns to improve the quality of ghost imaging. The results show that the image quality will first increase and then decrease with the increase of the speckle size, and there is an optimal speckle size for a specific object. Moreover, by using the random distribution of speckle positions, a new type of displacement speckle patterns is designed, and the imaging quality is better than that of the random speckle patterns. These results are of great significances for finding the best speckle patterns suitable for detecting targets, which further promotes the practical applications of ghost imaging.
MiCE: Mixture of Contrastive Experts for Unsupervised Image Clustering
May 05, 2021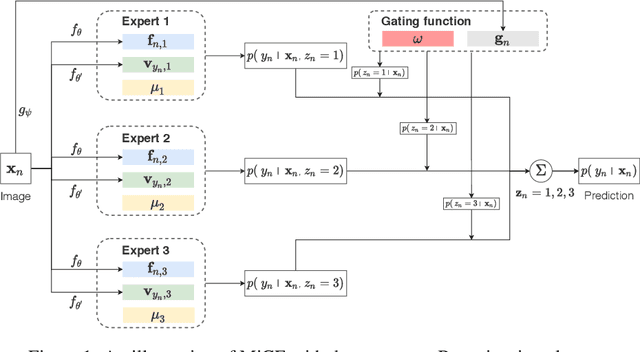
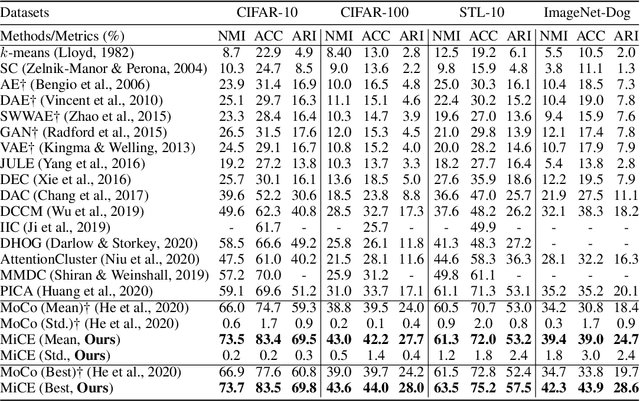

We present Mixture of Contrastive Experts (MiCE), a unified probabilistic clustering framework that simultaneously exploits the discriminative representations learned by contrastive learning and the semantic structures captured by a latent mixture model. Motivated by the mixture of experts, MiCE employs a gating function to partition an unlabeled dataset into subsets according to the latent semantics and multiple experts to discriminate distinct subsets of instances assigned to them in a contrastive learning manner. To solve the nontrivial inference and learning problems caused by the latent variables, we further develop a scalable variant of the Expectation-Maximization (EM) algorithm for MiCE and provide proof of the convergence. Empirically, we evaluate the clustering performance of MiCE on four widely adopted natural image datasets. MiCE achieves significantly better results than various previous methods and a strong contrastive learning baseline.
Carotid artery wall segmentation in ultrasound image sequences using a deep convolutional neural network
Jan 28, 2022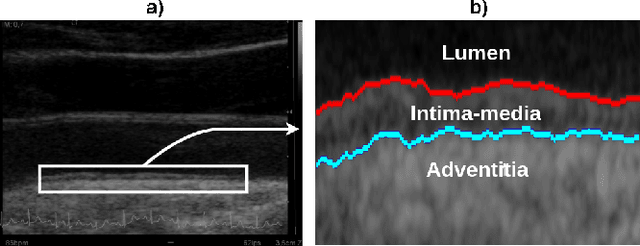
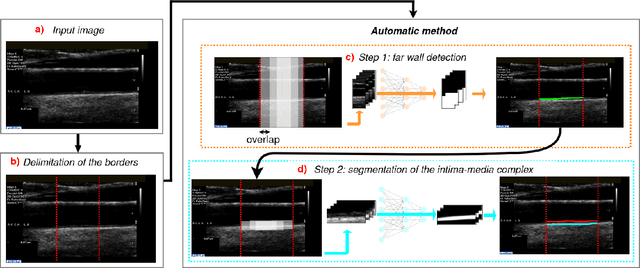
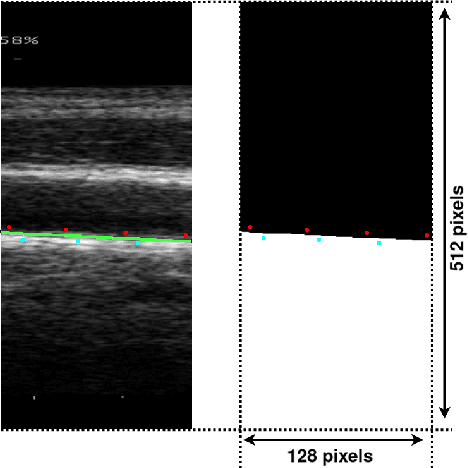
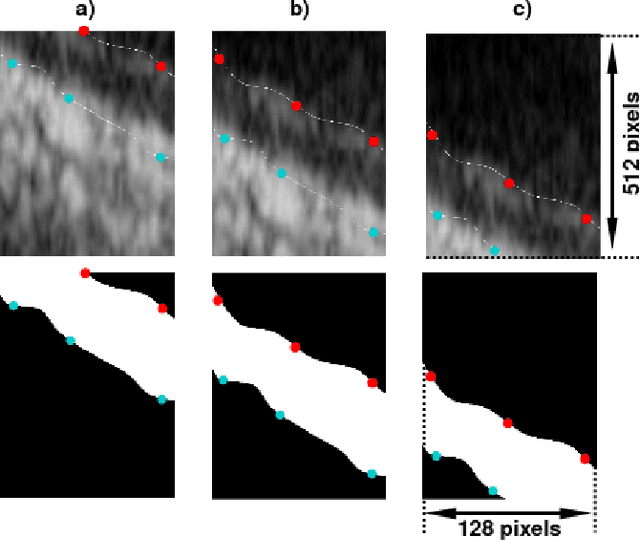
The objective of this study is the segmentation of the intima-media complex of the common carotid artery, on longitudinal ultrasound images, to measure its thickness. We propose a fully automatic region-based segmentation method, involving a supervised region-based deep-learning approach based on a dilated U-net network. It was trained and evaluated using a 5-fold cross-validation on a multicenter database composed of 2176 images annotated by two experts. The resulting mean absolute difference (<120 um) compared to reference annotations was less than the inter-observer variability (180 um). With a 98.7% success rate, i.e., only 1.3% cases requiring manual correction, the proposed method has been shown to be robust and thus may be recommended for use in clinical practice.
Deep transfer learning for partial differential equations under conditional shift with DeepONet
Apr 20, 2022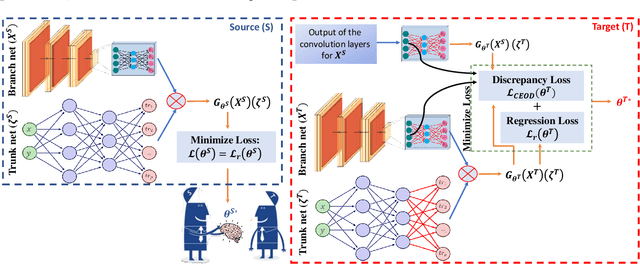
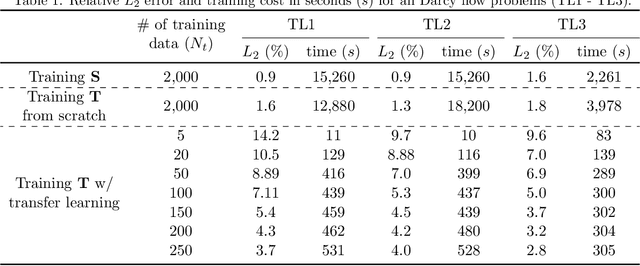
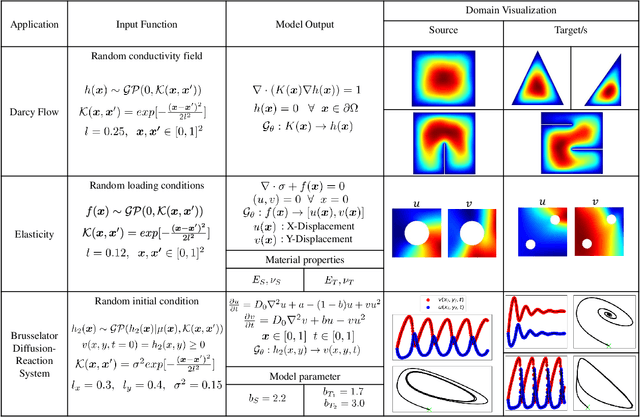
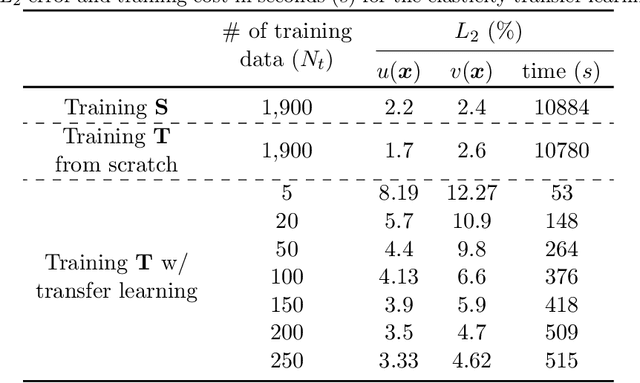
Traditional machine learning algorithms are designed to learn in isolation, i.e. address single tasks. The core idea of transfer learning (TL) is that knowledge gained in learning to perform one task (source) can be leveraged to improve learning performance in a related, but different, task (target). TL leverages and transfers previously acquired knowledge to address the expense of data acquisition and labeling, potential computational power limitations, and the dataset distribution mismatches. Although significant progress has been made in the fields of image processing, speech recognition, and natural language processing (for classification and regression) for TL, little work has been done in the field of scientific machine learning for functional regression and uncertainty quantification in partial differential equations. In this work, we propose a novel TL framework for task-specific learning under conditional shift with a deep operator network (DeepONet). Inspired by the conditional embedding operator theory, we measure the statistical distance between the source domain and the target feature domain by embedding conditional distributions onto a reproducing kernel Hilbert space. Task-specific operator learning is accomplished by fine-tuning task-specific layers of the target DeepONet using a hybrid loss function that allows for the matching of individual target samples while also preserving the global properties of the conditional distribution of target data. We demonstrate the advantages of our approach for various TL scenarios involving nonlinear PDEs under conditional shift. Our results include geometry domain adaptation and show that the proposed TL framework enables fast and efficient multi-task operator learning, despite significant differences between the source and target domains.
On Guiding Visual Attention with Language Specification
Feb 17, 2022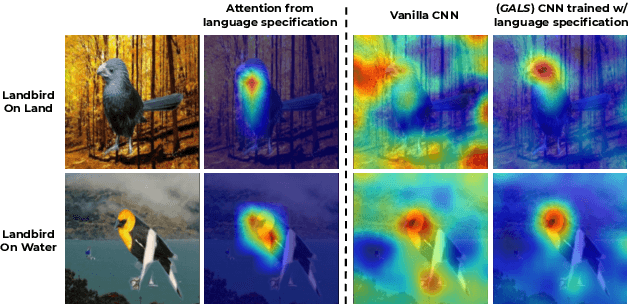

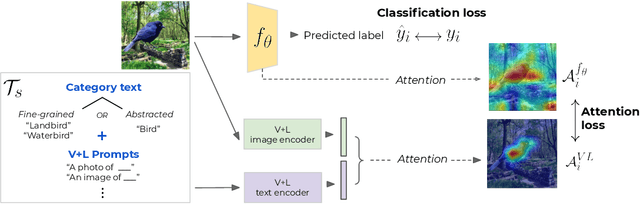
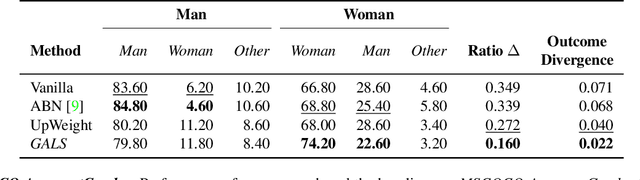
While real world challenges typically define visual categories with language words or phrases, most visual classification methods define categories with numerical indices. However, the language specification of the classes provides an especially useful prior for biased and noisy datasets, where it can help disambiguate what features are task-relevant. Recently, large-scale multimodal models have been shown to recognize a wide variety of high-level concepts from a language specification even without additional image training data, but they are often unable to distinguish classes for more fine-grained tasks. CNNs, in contrast, can extract subtle image features that are required for fine-grained discrimination, but will overfit to any bias or noise in datasets. Our insight is to use high-level language specification as advice for constraining the classification evidence to task-relevant features, instead of distractors. To do this, we ground task-relevant words or phrases with attention maps from a pretrained large-scale model. We then use this grounding to supervise a classifier's spatial attention away from distracting context. We show that supervising spatial attention in this way improves performance on classification tasks with biased and noisy data, including about 3-15% worst-group accuracy improvements and 41-45% relative improvements on fairness metrics.
On the Ability of a CNN to Realize Image-to-Image Language Conversion
Jun 22, 2020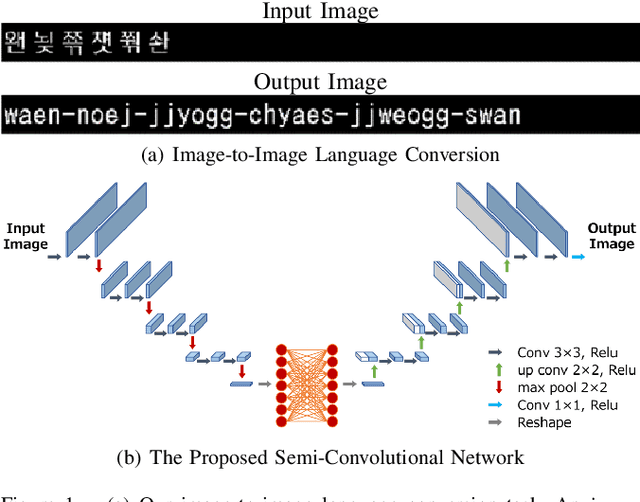



The purpose of this paper is to reveal the ability that Convolutional Neural Networks (CNN) have on the novel task of image-to-image language conversion. We propose a new network to tackle this task by converting images of Korean Hangul characters directly into images of the phonetic Latin character equivalent. The conversion rules between Hangul and the phonetic symbols are not explicitly provided. The results of the proposed network show that it is possible to perform image-to-image language conversion. Moreover, it shows that it can grasp the structural features of Hangul even from limited learning data. In addition, it introduces a new network to use when the input and output have significantly different features.
Plug & Play Attacks: Towards Robust and Flexible Model Inversion Attacks
Feb 02, 2022
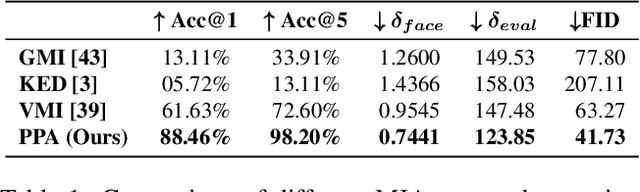

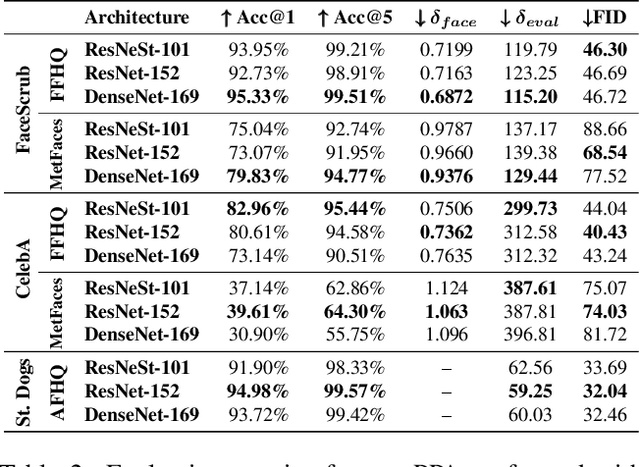
Model inversion attacks (MIAs) aim to create synthetic images that reflect the class-wise characteristics from a target classifier's training data by exploiting the model's learned knowledge. Previous research has developed generative MIAs using generative adversarial networks (GANs) as image priors that are tailored to a specific target model. This makes the attacks time- and resource-consuming, inflexible, and susceptible to distributional shifts between datasets. To overcome these drawbacks, we present Plug & Play Attacks that loosen the dependency between the target model and image prior and enable the use of a single trained GAN to attack a broad range of targets with only minor attack adjustments needed. Moreover, we show that powerful MIAs are possible even with publicly available pre-trained GANs and under strong distributional shifts, whereas previous approaches fail to produce meaningful results. Our extensive evaluation confirms the improved robustness and flexibility of Plug & Play Attacks and their ability to create high-quality images revealing sensitive class characteristics.
Learning Omni-frequency Region-adaptive Representations for Real Image Super-Resolution
Jan 10, 2021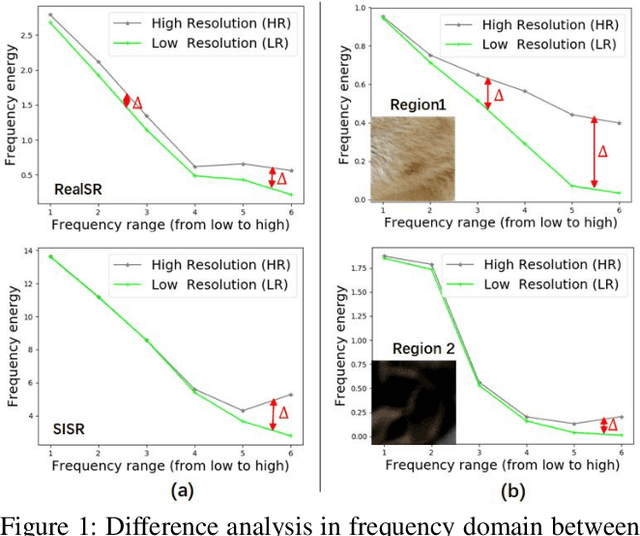
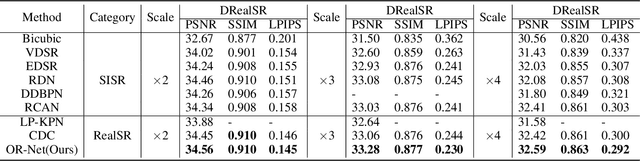
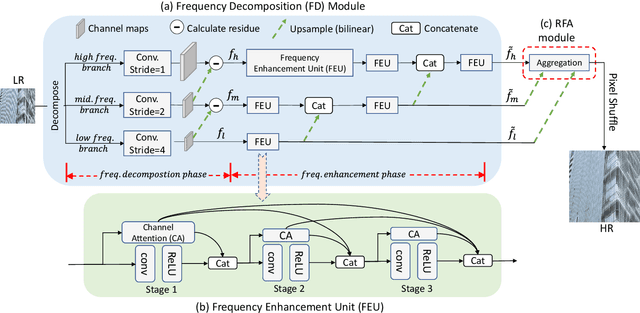
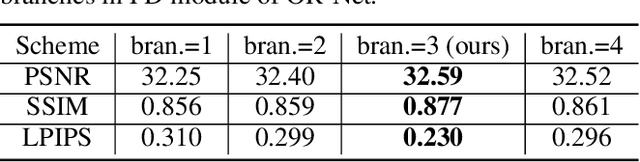
Traditional single image super-resolution (SISR) methods that focus on solving single and uniform degradation (i.e., bicubic down-sampling), typically suffer from poor performance when applied into real-world low-resolution (LR) images due to the complicated realistic degradations. The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. In this paper, we propose an Omni-frequency Region-adaptive Network (ORNet) to address both challenges, here we call features of all low, middle and high frequencies omni-frequency features. Specifically, we start from the frequency perspective and design a Frequency Decomposition (FD) module to separate different frequency components to comprehensively compensate the information lost for real LR image. Then, considering the different regions of real LR image have different frequency information lost, we further design a Region-adaptive Frequency Aggregation (RFA) module by leveraging dynamic convolution and spatial attention to adaptively restore frequency components for different regions. The extensive experiments endorse the effective, and scenario-agnostic nature of our OR-Net for RealSR.