 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models
Mar 28, 2024
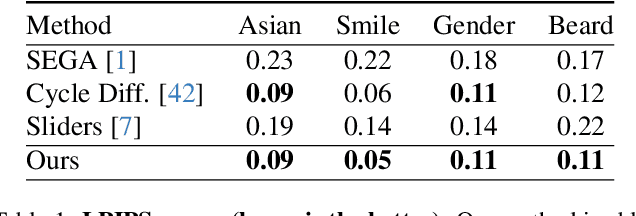
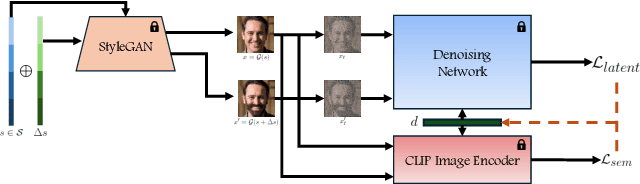
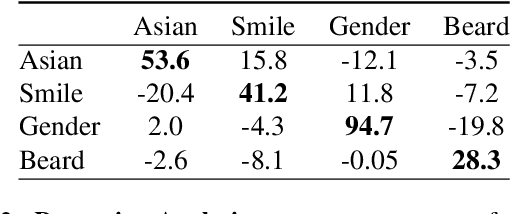

The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.
Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Apr 13, 2024Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Apr 08, 2024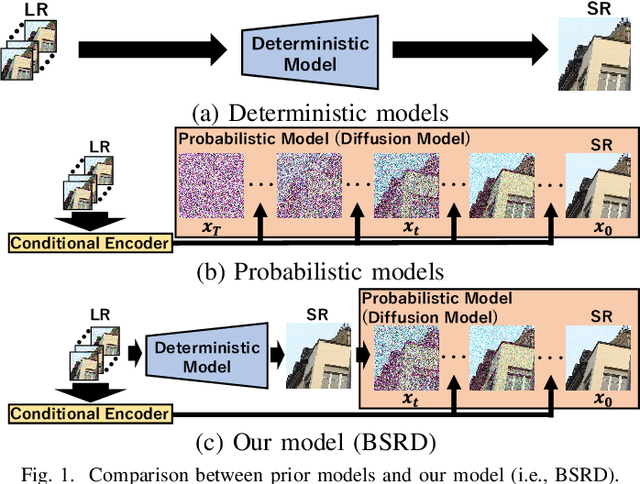
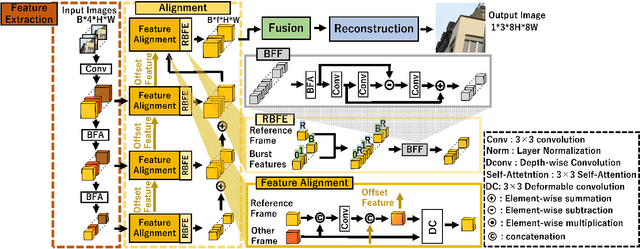
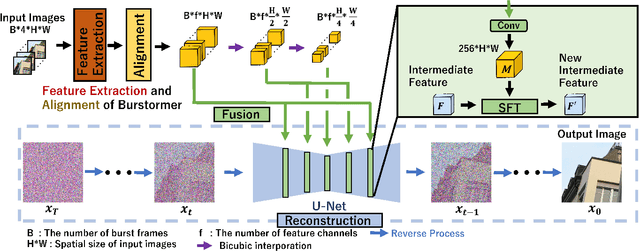
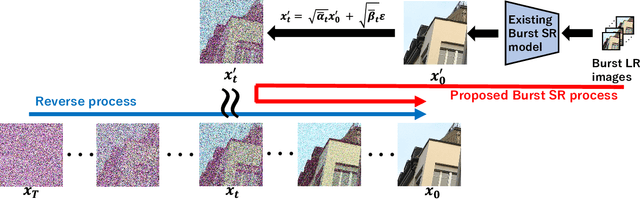
While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD
Balanced Mixed-Type Tabular Data Synthesis with Diffusion Models
Apr 12, 2024Diffusion models have emerged as a robust framework for various generative tasks, such as image and audio synthesis, and have also demonstrated a remarkable ability to generate mixed-type tabular data comprising both continuous and discrete variables. However, current approaches to training diffusion models on mixed-type tabular data tend to inherit the imbalanced distributions of features present in the training dataset, which can result in biased sampling. In this research, we introduce a fair diffusion model designed to generate balanced data on sensitive attributes. We present empirical evidence demonstrating that our method effectively mitigates the class imbalance in training data while maintaining the quality of the generated samples. Furthermore, we provide evidence that our approach outperforms existing methods for synthesizing tabular data in terms of performance and fairness.
Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Apr 05, 2024With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented against few weak baselines by correlation to human Likert scores over a set of easy-to-discriminate images. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.
Centered Masking for Language-Image Pre-Training
Mar 27, 2024We introduce Gaussian masking for Language-Image Pre-Training (GLIP) a novel, straightforward, and effective technique for masking image patches during pre-training of a vision-language model. GLIP builds on Fast Language-Image Pre-Training (FLIP), which randomly masks image patches while training a CLIP model. GLIP replaces random masking with centered masking, that uses a Gaussian distribution and is inspired by the importance of image patches at the center of the image. GLIP retains the same computational savings as FLIP, while improving performance across a range of downstream datasets and tasks, as demonstrated by our experimental results. We show the benefits of GLIP to be easy to obtain, requiring no delicate tuning of the Gaussian, and also applicable to data sets containing images without an obvious center focus.
Driver Attention Tracking and Analysis
Apr 11, 2024We propose a novel method to estimate a driver's points-of-gaze using a pair of ordinary cameras mounted on the windshield and dashboard of a car. This is a challenging problem due to the dynamics of traffic environments with 3D scenes of unknown depths. This problem is further complicated by the volatile distance between the driver and the camera system. To tackle these challenges, we develop a novel convolutional network that simultaneously analyzes the image of the scene and the image of the driver's face. This network has a camera calibration module that can compute an embedding vector that represents the spatial configuration between the driver and the camera system. This calibration module improves the overall network's performance, which can be jointly trained end to end. We also address the lack of annotated data for training and evaluation by introducing a large-scale driving dataset with point-of-gaze annotations. This is an in situ dataset of real driving sessions in an urban city, containing synchronized images of the driving scene as well as the face and gaze of the driver. Experiments on this dataset show that the proposed method outperforms various baseline methods, having the mean prediction error of 29.69 pixels, which is relatively small compared to the $1280{\times}720$ resolution of the scene camera.
Seeing the Unseen: A Frequency Prompt Guided Transformer for Image Restoration
Mar 30, 2024How to explore useful features from images as prompts to guide the deep image restoration models is an effective way to solve image restoration. In contrast to mining spatial relations within images as prompt, which leads to characteristics of different frequencies being neglected and further remaining subtle or undetectable artifacts in the restored image, we develop a Frequency Prompting image restoration method, dubbed FPro, which can effectively provide prompt components from a frequency perspective to guild the restoration model address these differences. Specifically, we first decompose input features into separate frequency parts via dynamically learned filters, where we introduce a gating mechanism for suppressing the less informative elements within the kernels. To propagate useful frequency information as prompt, we then propose a dual prompt block, consisting of a low-frequency prompt modulator (LPM) and a high-frequency prompt modulator (HPM), to handle signals from different bands respectively. Each modulator contains a generation process to incorporate prompting components into the extracted frequency maps, and a modulation part that modifies the prompt feature with the guidance of the decoder features. Experimental results on commonly used benchmarks have demonstrated the favorable performance of our pipeline against SOTA methods on 5 image restoration tasks, including deraining, deraindrop, demoir\'eing, deblurring, and dehazing. The source code and pre-trained models will be available at https://github.com/joshyZhou/FPro.
Accelerating Cardiac MRI Reconstruction with CMRatt: An Attention-Driven Approach
Apr 10, 2024Cine cardiac magnetic resonance (CMR) imaging is recognised as the benchmark modality for the comprehensive assessment of cardiac function. Nevertheless, the acquisition process of cine CMR is considered as an impediment due to its prolonged scanning time. One commonly used strategy to expedite the acquisition process is through k-space undersampling, though it comes with a drawback of introducing aliasing effects in the reconstructed image. Lately, deep learning-based methods have shown remarkable results over traditional approaches in rapidly achieving precise CMR reconstructed images. This study aims to explore the untapped potential of attention mechanisms incorporated with a deep learning model within the context of the CMR reconstruction problem. We are motivated by the fact that attention has proven beneficial in downstream tasks such as image classification and segmentation, but has not been systematically analysed in the context of CMR reconstruction. Our primary goal is to identify the strengths and potential limitations of attention algorithms when integrated with a convolutional backbone model such as a U-Net. To achieve this, we benchmark different state-of-the-art spatial and channel attention mechanisms on the CMRxRecon dataset and quantitatively evaluate the quality of reconstruction using objective metrics. Furthermore, inspired by the best performing attention mechanism, we propose a new, simple yet effective, attention pipeline specifically optimised for the task of cardiac image reconstruction that outperforms other state-of-the-art attention methods. The layer and model code will be made publicly available.
Matching 2D Images in 3D: Metric Relative Pose from Metric Correspondences
Apr 09, 2024Given two images, we can estimate the relative camera pose between them by establishing image-to-image correspondences. Usually, correspondences are 2D-to-2D and the pose we estimate is defined only up to scale. Some applications, aiming at instant augmented reality anywhere, require scale-metric pose estimates, and hence, they rely on external depth estimators to recover the scale. We present MicKey, a keypoint matching pipeline that is able to predict metric correspondences in 3D camera space. By learning to match 3D coordinates across images, we are able to infer the metric relative pose without depth measurements. Depth measurements are also not required for training, nor are scene reconstructions or image overlap information. MicKey is supervised only by pairs of images and their relative poses. MicKey achieves state-of-the-art performance on the Map-Free Relocalisation benchmark while requiring less supervision than competing approaches.