 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransVPR: Transformer-based place recognition with multi-level attention aggregation
Jan 06, 2022
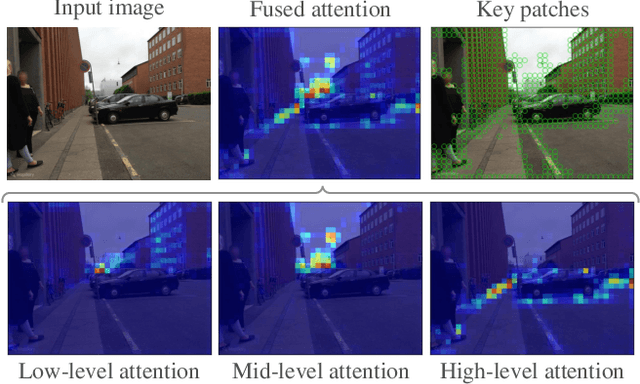

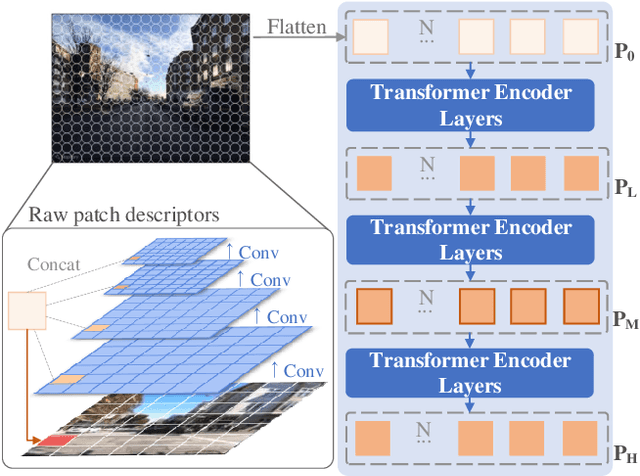
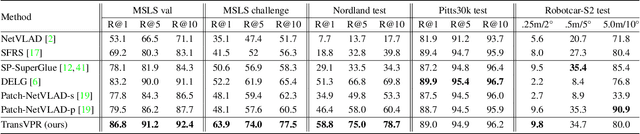
Visual place recognition is a challenging task for applications such as autonomous driving navigation and mobile robot localization. Distracting elements presenting in complex scenes often lead to deviations in the perception of visual place. To address this problem, it is crucial to integrate information from only task-relevant regions into image representations. In this paper, we introduce a novel holistic place recognition model, TransVPR, based on vision Transformers. It benefits from the desirable property of the self-attention operation in Transformers which can naturally aggregate task-relevant features. Attentions from multiple levels of the Transformer, which focus on different regions of interest, are further combined to generate a global image representation. In addition, the output tokens from Transformer layers filtered by the fused attention mask are considered as key-patch descriptors, which are used to perform spatial matching to re-rank the candidates retrieved by the global image features. The whole model allows end-to-end training with a single objective and image-level supervision. TransVPR achieves state-of-the-art performance on several real-world benchmarks while maintaining low computational time and storage requirements.
An application of a pseudo-parabolic modeling to texture image recognition
Feb 09, 2021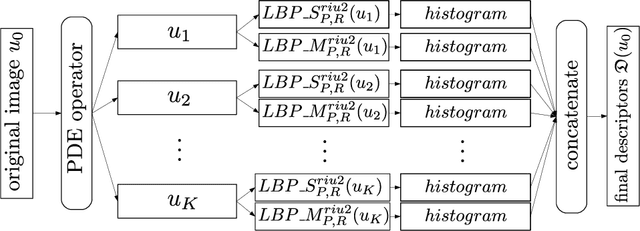
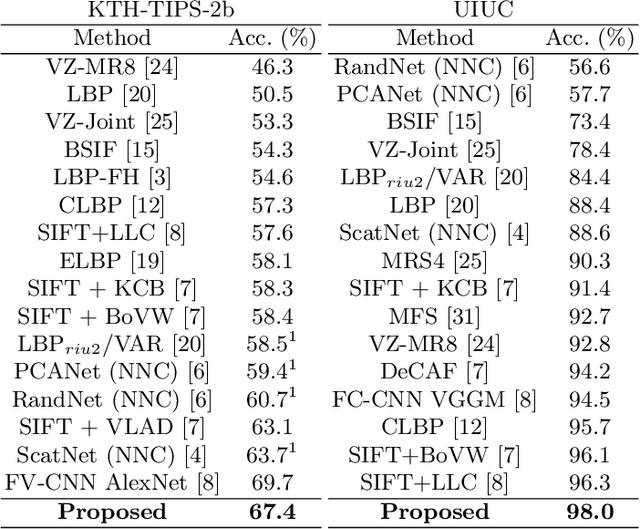
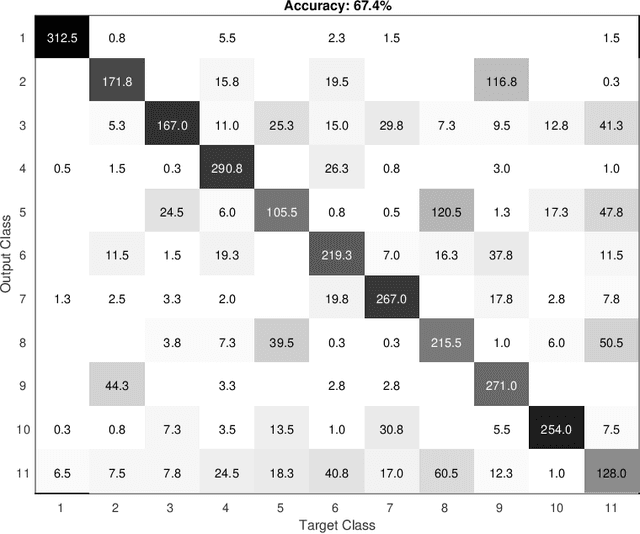
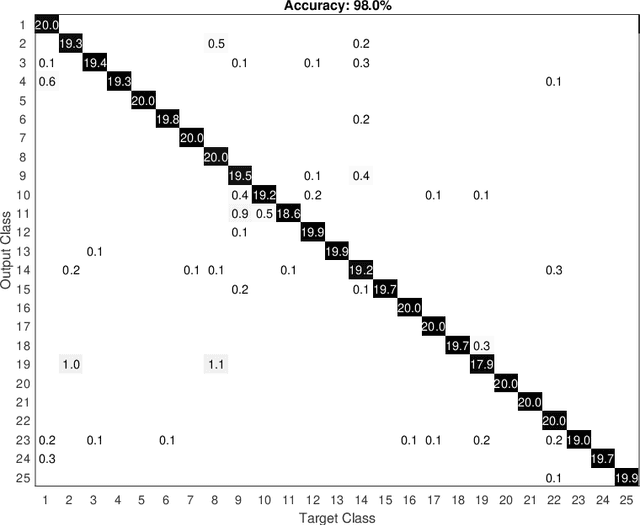
In this work, we present a novel methodology for texture image recognition using a partial differential equation modeling. More specifically, we employ the pseudo-parabolic Buckley-Leverett equation to provide a dynamics to the digital image representation and collect local descriptors from those images evolving in time. For the local descriptors we employ the magnitude and signal binary patterns and a simple histogram of these features was capable of achieving promising results in a classification task. We compare the accuracy over well established benchmark texture databases and the results demonstrate competitiveness, even with the most modern deep learning approaches. The achieved results open space for future investigation on this type of modeling for image analysis, especially when there is no large amount of data for training deep learning models and therefore model-based approaches arise as suitable alternatives.
Single-shot self-supervised particle tracking
Feb 28, 2022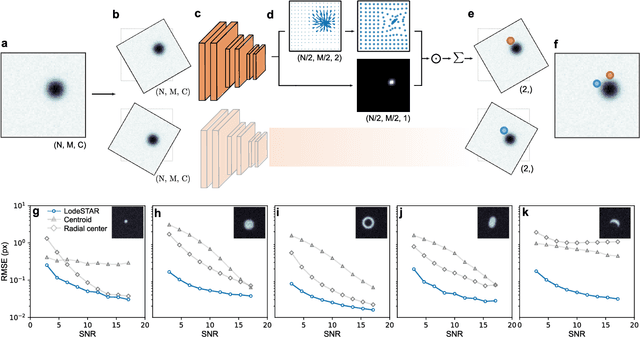
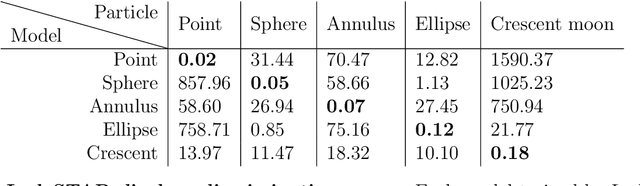
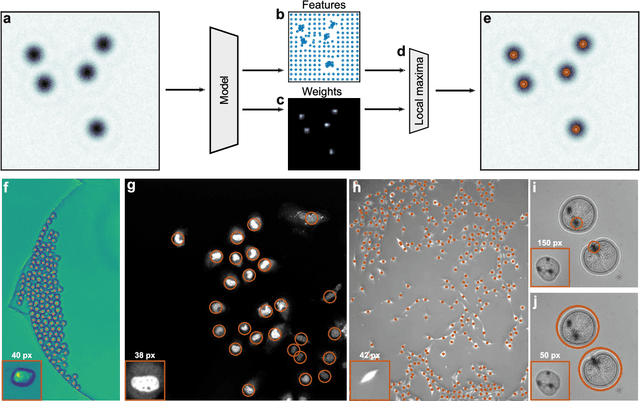
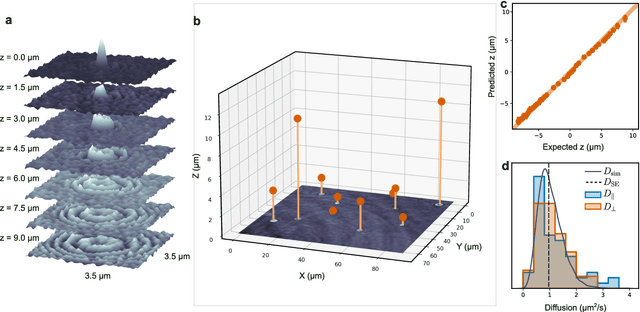
Particle tracking is a fundamental task in digital microscopy. Recently, machine-learning approaches have made great strides in overcoming the limitations of more classical approaches. The training of state-of-the-art machine-learning methods almost universally relies on either vast amounts of labeled experimental data or the ability to numerically simulate realistic datasets. However, the data produced by experiments are often challenging to label and cannot be easily reproduced numerically. Here, we propose a novel deep-learning method, named LodeSTAR (Low-shot deep Symmetric Tracking And Regression), that learns to tracks objects with sub-pixel accuracy from a single unlabeled experimental image. This is made possible by exploiting the inherent roto-translational symmetries of the data. We demonstrate that LodeSTAR outperforms traditional methods in terms of accuracy. Furthermore, we analyze challenging experimental data containing densely packed cells or noisy backgrounds. We also exploit additional symmetries to extend the measurable particle properties to the particle's vertical position by propagating the signal in Fourier space and its polarizability by scaling the signal strength. Thanks to the ability to train deep-learning models with a single unlabeled image, LodeSTAR can accelerate the development of high-quality microscopic analysis pipelines for engineering, biology, and medicine.
DDoS-UNet: Incorporating temporal information using Dynamic Dual-channel UNet for enhancing super-resolution of dynamic MRI
Feb 10, 2022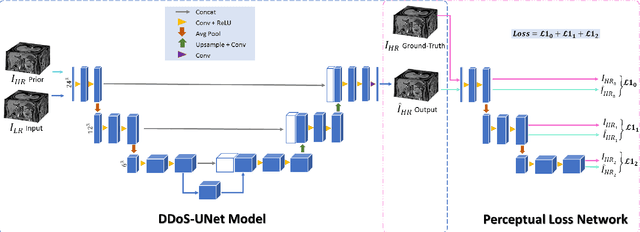
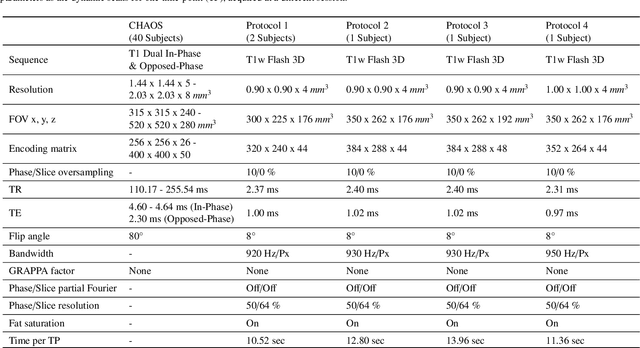

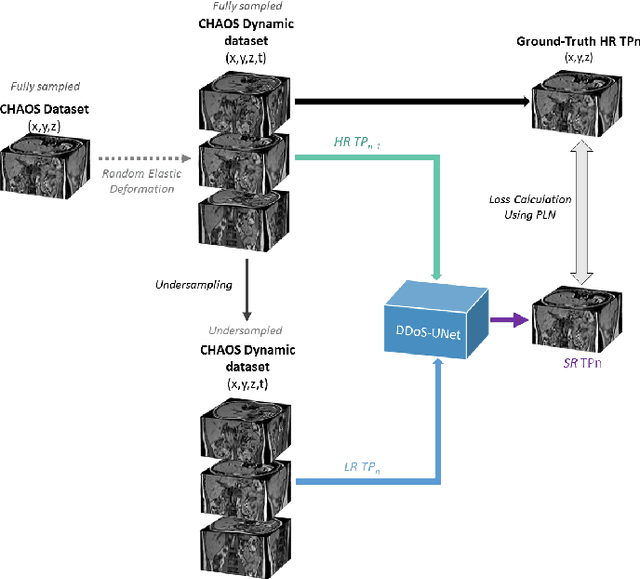
Magnetic resonance imaging (MRI) provides high spatial resolution and excellent soft-tissue contrast without using harmful ionising radiation. Dynamic MRI is an essential tool for interventions to visualise movements or changes of the target organ. However, such MRI acquisition with high temporal resolution suffers from limited spatial resolution - also known as the spatio-temporal trade-off of dynamic MRI. Several approaches, including deep learning based super-resolution approaches, have been proposed to mitigate this trade-off. Nevertheless, such an approach typically aims to super-resolve each time-point separately, treating them as individual volumes. This research addresses the problem by creating a deep learning model which attempts to learn both spatial and temporal relationships. A modified 3D UNet model, DDoS-UNet, is proposed - which takes the low-resolution volume of the current time-point along with a prior image volume. Initially, the network is supplied with a static high-resolution planning scan as the prior image along with the low-resolution input to super-resolve the first time-point. Then it continues step-wise by using the super-resolved time-points as the prior image while super-resolving the subsequent time-points. The model performance was tested with 3D dynamic data that was undersampled to different in-plane levels. The proposed network achieved an average SSIM value of 0.951$\pm$0.017 while reconstructing the lowest resolution data (i.e. only 4\% of the k-space acquired) - which could result in a theoretical acceleration factor of 25. The proposed approach can be used to reduce the required scan-time while achieving high spatial resolution.
Sparse Optical Flow-Based Line Feature Tracking
Apr 15, 2022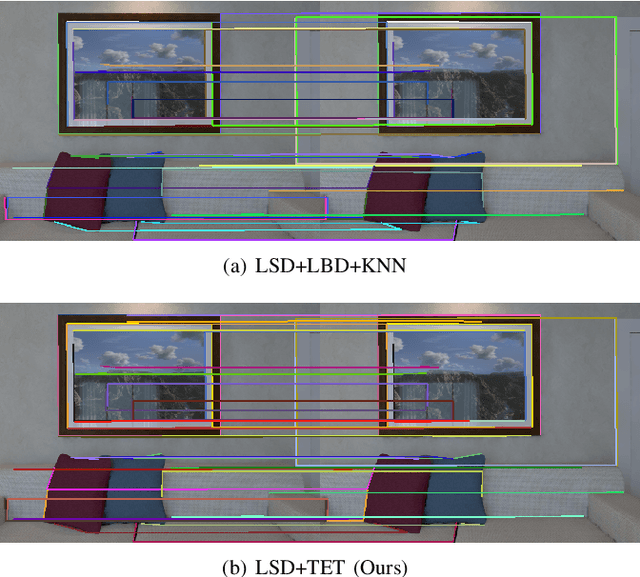
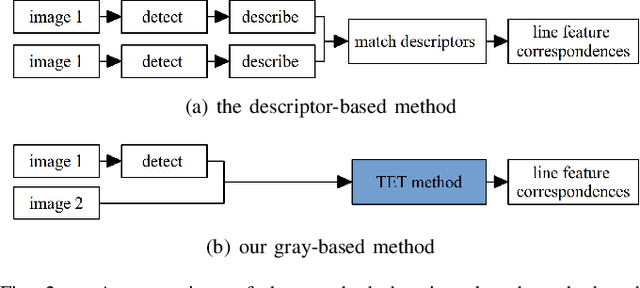
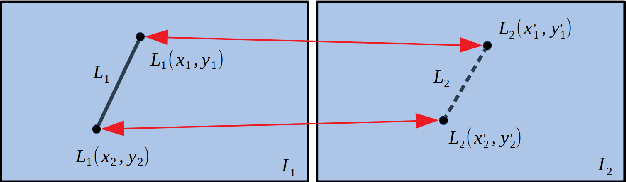
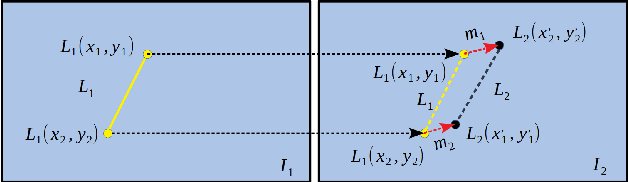
In this paper we propose a novel sparse optical flow (SOF)-based line feature tracking method for the camera pose estimation problem. This method is inspired by the point-based SOF algorithm and developed based on an observation that two adjacent images in time-varying image sequences satisfy brightness invariant. Based on this observation, we re-define the goal of line feature tracking: track two endpoints of a line feature instead of the entire line based on gray value matching instead of descriptor matching. To achieve this goal, an efficient two endpoint tracking (TET) method is presented: first, describe a given line feature with its two endpoints; next, track the two endpoints based on SOF to obtain two new tracked endpoints by minimizing a pixel-level grayscale residual function; finally, connect the two tracked endpoints to generate a new line feature. The correspondence is established between the given and the new line feature. Compared with current descriptor-based methods, our TET method needs not to compute descriptors and detect line features repeatedly. Naturally, it has an obvious advantage over computation. Experiments in several public benchmark datasets show our method yields highly competitive accuracy with an obvious advantage over speed.
An Energy-Based Prior for Generative Saliency
Apr 19, 2022
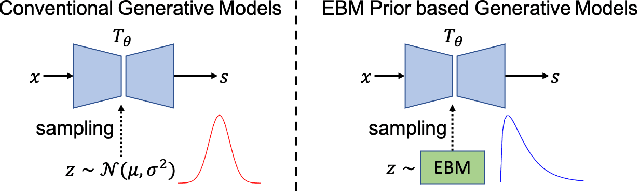
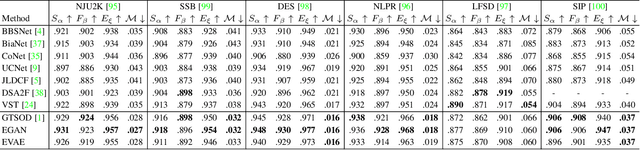

We propose a novel energy-based prior for generative saliency prediction, where the latent variables follow an informative energy-based prior. Both the saliency generator and the energy-based prior are jointly trained via Markov chain Monte Carlo-based maximum likelihood estimation, in which the sampling from the intractable posterior and prior distributions of the latent variables are performed by Langevin dynamics. With the generative saliency model, we can obtain a pixel-wise uncertainty map from an image, indicating model confidence in the saliency prediction. Different from existing generative models, which define the prior distribution of the latent variable as a simple isotropic Gaussian distribution, our model uses an energy-based informative prior which can be more expressive in capturing the latent space of the data. With the informative energy-based prior, we extend the Gaussian distribution assumption of generative models to achieve a more representative distribution of the latent space, leading to more reliable uncertainty estimation. We apply the proposed frameworks to both RGB and RGB-D salient object detection tasks with both transformer and convolutional neural network backbones. Experimental results show that our generative saliency model with an energy-based prior can achieve not only accurate saliency predictions but also reliable uncertainty maps that are consistent with human perception.
OSOP: A Multi-Stage One Shot Object Pose Estimation Framework
Mar 30, 2022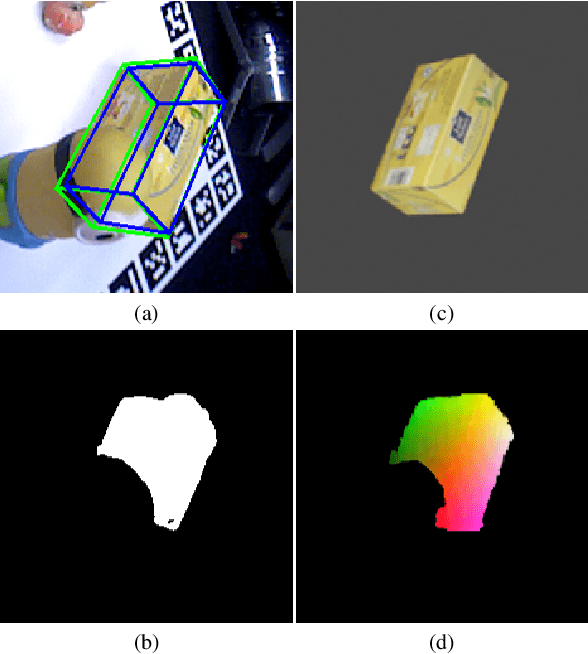
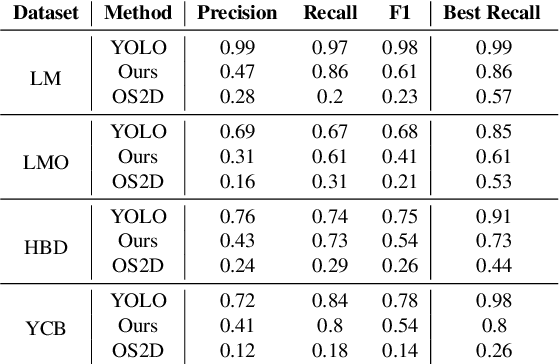
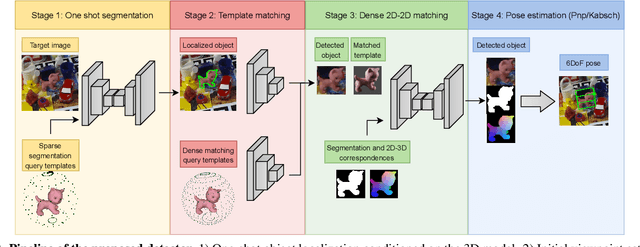
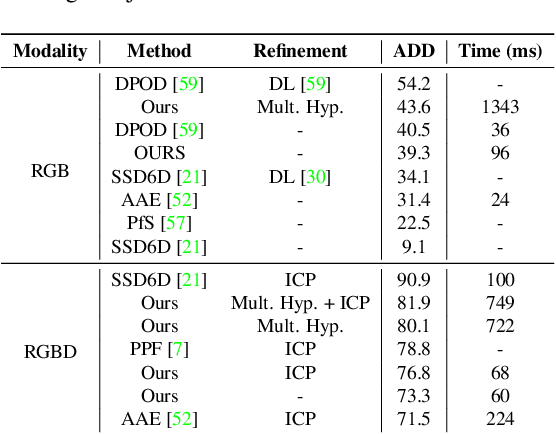
We present a novel one-shot method for object detection and 6 DoF pose estimation, that does not require training on target objects. At test time, it takes as input a target image and a textured 3D query model. The core idea is to represent a 3D model with a number of 2D templates rendered from different viewpoints. This enables CNN-based direct dense feature extraction and matching. The object is first localized in 2D, then its approximate viewpoint is estimated, followed by dense 2D-3D correspondence prediction. The final pose is computed with PnP. We evaluate the method on LineMOD, Occlusion, Homebrewed, YCB-V and TLESS datasets and report very competitive performance in comparison to the state-of-the-art methods trained on synthetic data, even though our method is not trained on the object models used for testing.
simCrossTrans: A Simple Cross-Modality Transfer Learning for Object Detection with ConvNets or Vision Transformers
Mar 20, 2022

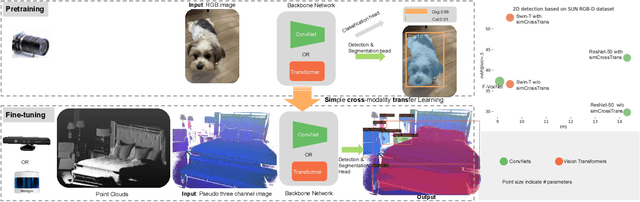

Transfer learning is widely used in computer vision (CV), natural language processing (NLP) and achieves great success. Most transfer learning systems are based on the same modality (e.g. RGB image in CV and text in NLP). However, the cross-modality transfer learning (CMTL) systems are scarce. In this work, we study CMTL from 2D to 3D sensor to explore the upper bound performance of 3D sensor only systems, which play critical roles in robotic navigation and perform well in low light scenarios. While most CMTL pipelines from 2D to 3D vision are complicated and based on Convolutional Neural Networks (ConvNets), ours is easy to implement, expand and based on both ConvNets and Vision transformers(ViTs): 1) By converting point clouds to pseudo-images, we can use an almost identical network from pre-trained models based on 2D images. This makes our system easy to implement and expand. 2) Recently ViTs have been showing good performance and robustness to occlusions, one of the key reasons for poor performance of 3D vision systems. We explored both ViT and ConvNet with similar model sizes to investigate the performance difference. We name our approach simCrossTrans: simple cross-modality transfer learning with ConvNets or ViTs. Experiments on SUN RGB-D dataset show: with simCrossTrans we achieve $13.2\%$ and $16.1\%$ absolute performance gain based on ConvNets and ViTs separately. We also observed the ViTs based performs $9.7\%$ better than the ConvNets one, showing the power of simCrossTrans with ViT. simCrossTrans with ViTs surpasses the previous state-of-the-art (SOTA) by a large margin of $+15.4\%$ mAP50. Compared with the previous 2D detection SOTA based RGB images, our depth image only system only has a $1\%$ gap. The code, training/inference logs and models are publicly available at https://github.com/liketheflower/simCrossTrans
Multi-scale Information Assembly for Image Matting
Jan 07, 2021Image matting is a long-standing problem in computer graphics and vision, mostly identified as the accurate estimation of the foreground in input images. We argue that the foreground objects can be represented by different-level information, including the central bodies, large-grained boundaries, refined details, etc. Based on this observation, in this paper, we propose a multi-scale information assembly framework (MSIA-matte) to pull out high-quality alpha mattes from single RGB images. Technically speaking, given an input image, we extract advanced semantics as our subject content and retain initial CNN features to encode different-level foreground expression, then combine them by our well-designed information assembly strategy. Extensive experiments can prove the effectiveness of the proposed MSIA-matte, and we can achieve state-of-the-art performance compared to most existing matting networks.
Towards Data-Free Model Stealing in a Hard Label Setting
Apr 23, 2022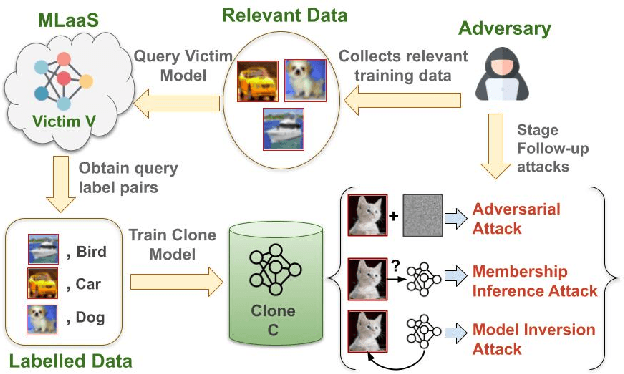
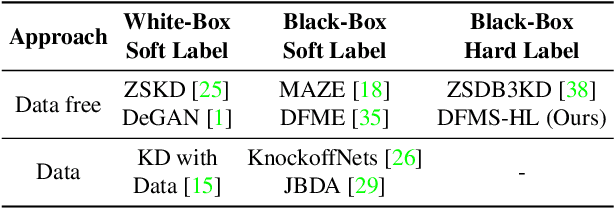
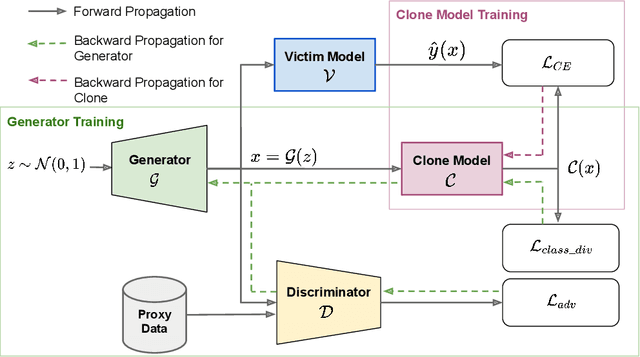

Machine learning models deployed as a service (MLaaS) are susceptible to model stealing attacks, where an adversary attempts to steal the model within a restricted access framework. While existing attacks demonstrate near-perfect clone-model performance using softmax predictions of the classification network, most of the APIs allow access to only the top-1 labels. In this work, we show that it is indeed possible to steal Machine Learning models by accessing only top-1 predictions (Hard Label setting) as well, without access to model gradients (Black-Box setting) or even the training dataset (Data-Free setting) within a low query budget. We propose a novel GAN-based framework that trains the student and generator in tandem to steal the model effectively while overcoming the challenge of the hard label setting by utilizing gradients of the clone network as a proxy to the victim's gradients. We propose to overcome the large query costs associated with a typical Data-Free setting by utilizing publicly available (potentially unrelated) datasets as a weak image prior. We additionally show that even in the absence of such data, it is possible to achieve state-of-the-art results within a low query budget using synthetically crafted samples. We are the first to demonstrate the scalability of Model Stealing in a restricted access setting on a 100 class dataset as well.