 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffractive all-optical computing for quantitative phase imaging
Jan 22, 2022
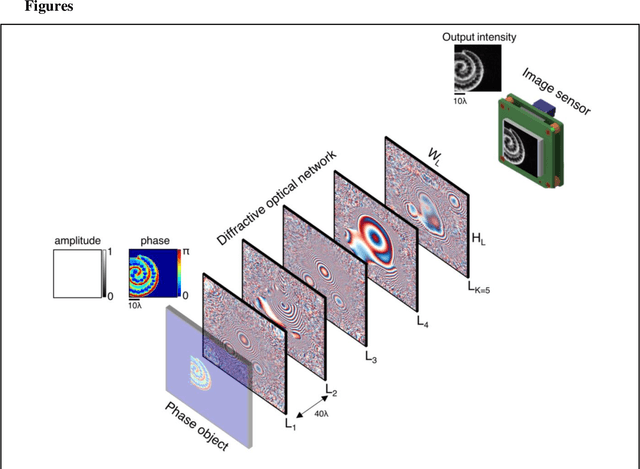

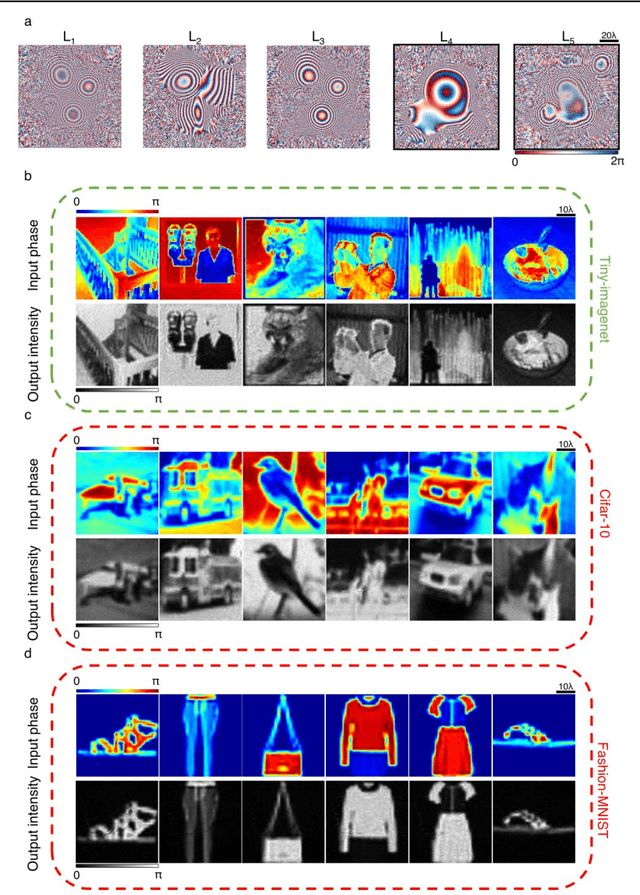
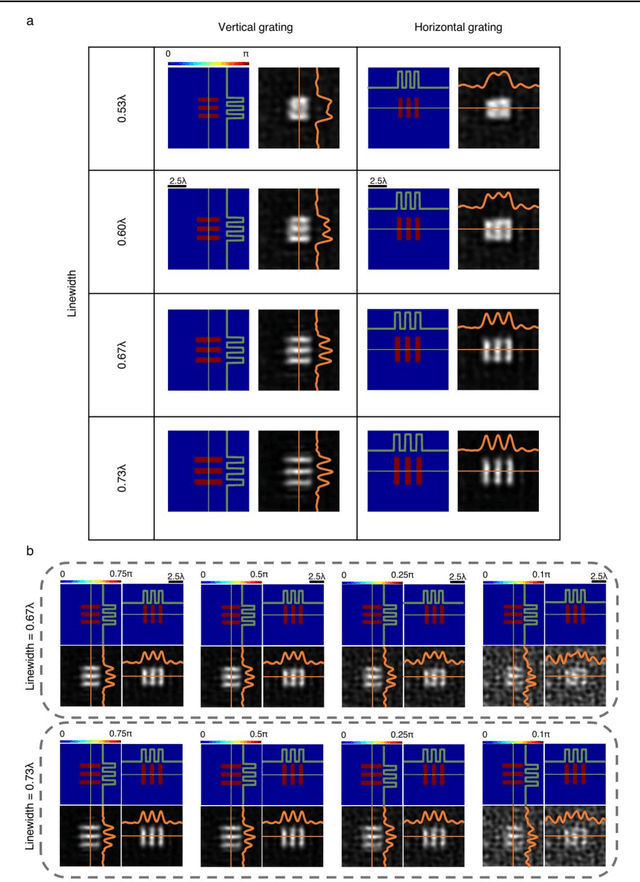
Quantitative phase imaging (QPI) is a label-free computational imaging technique that provides optical path length information of specimens. In modern implementations, the quantitative phase image of an object is reconstructed digitally through numerical methods running in a computer, often using iterative algorithms. Here, we demonstrate a diffractive QPI network that can synthesize the quantitative phase image of an object by converting the input phase information of a scene into intensity variations at the output plane. A diffractive QPI network is a specialized all-optical processor designed to perform a quantitative phase-to-intensity transformation through passive diffractive surfaces that are spatially engineered using deep learning and image data. Forming a compact, all-optical network that axially extends only ~200-300 times the illumination wavelength, this framework can replace traditional QPI systems and related digital computational burden with a set of passive transmissive layers. All-optical diffractive QPI networks can potentially enable power-efficient, high frame-rate and compact phase imaging systems that might be useful for various applications, including, e.g., on-chip microscopy and sensing.
Hierarchical Similarity Learning for Language-based Product Image Retrieval
Feb 18, 2021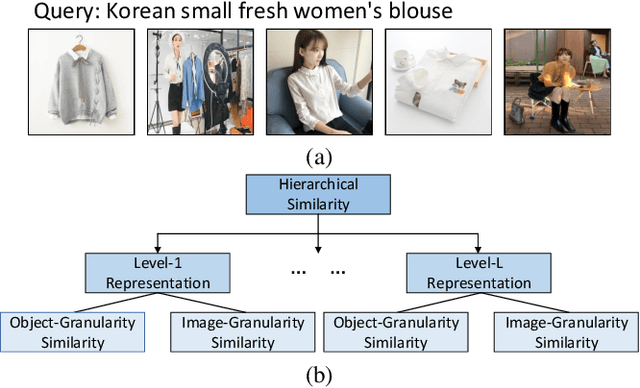
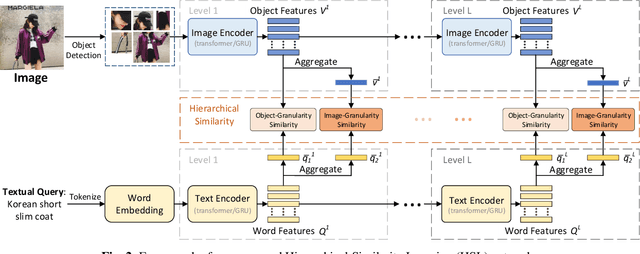
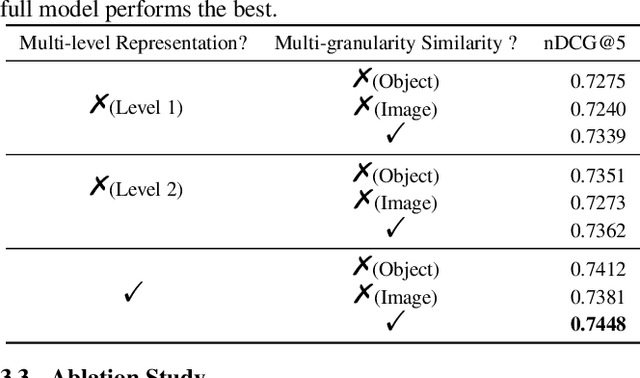
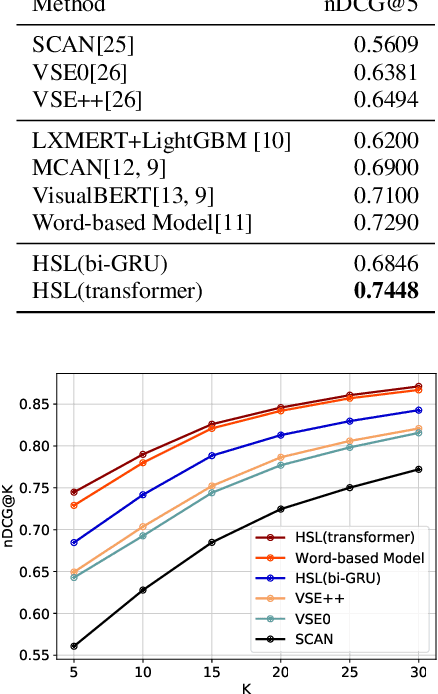
This paper aims for the language-based product image retrieval task. The majority of previous works have made significant progress by designing network structure, similarity measurement, and loss function. However, they typically perform vision-text matching at certain granularity regardless of the intrinsic multiple granularities of images. In this paper, we focus on the cross-modal similarity measurement, and propose a novel Hierarchical Similarity Learning (HSL) network. HSL first learns multi-level representations of input data by stacked encoders, and object-granularity similarity and image-granularity similarity are computed at each level. All the similarities are combined as the final hierarchical cross-modal similarity. Experiments on a large-scale product retrieval dataset demonstrate the effectiveness of our proposed method. Code and data are available at https://github.com/liufh1/hsl.
How to Listen? Rethinking Visual Sound Localization
Apr 11, 2022
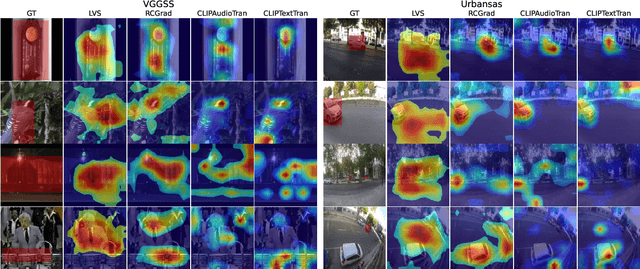

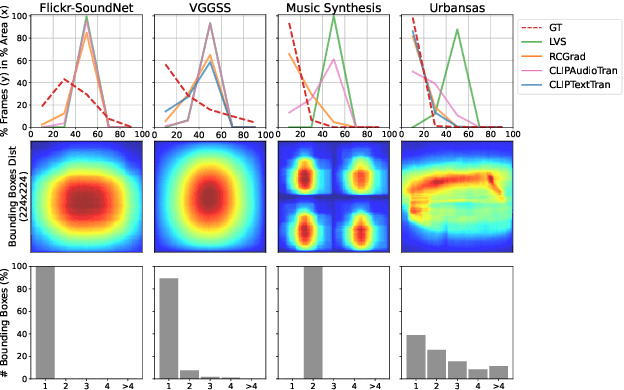
Localizing visual sounds consists on locating the position of objects that emit sound within an image. It is a growing research area with potential applications in monitoring natural and urban environments, such as wildlife migration and urban traffic. Previous works are usually evaluated with datasets having mostly a single dominant visible object, and proposed models usually require the introduction of localization modules during training or dedicated sampling strategies, but it remains unclear how these design choices play a role in the adaptability of these methods in more challenging scenarios. In this work, we analyze various model choices for visual sound localization and discuss how their different components affect the model's performance, namely the encoders' architecture, the loss function and the localization strategy. Furthermore, we study the interaction between these decisions, the model performance, and the data, by digging into different evaluation datasets spanning different difficulties and characteristics, and discuss the implications of such decisions in the context of real-world applications. Our code and model weights are open-sourced and made available for further applications.
Language-Grounded Indoor 3D Semantic Segmentation in the Wild
Apr 16, 2022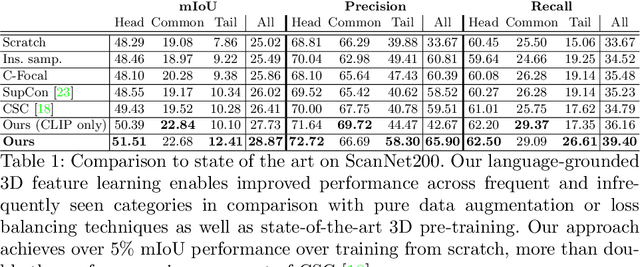
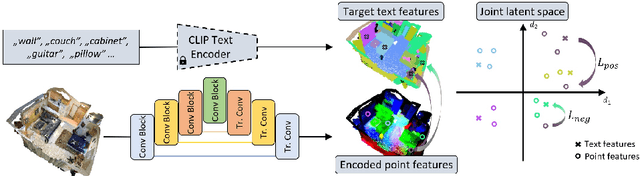
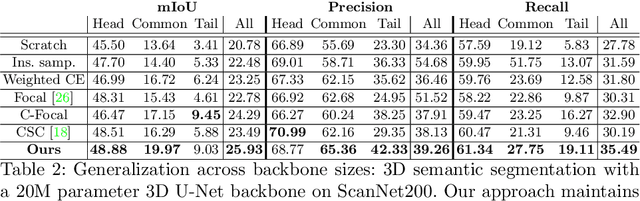
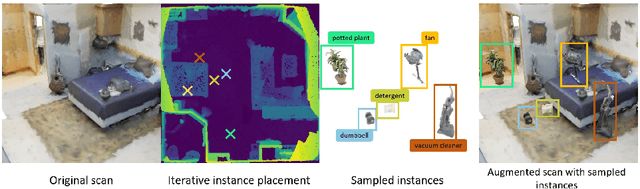
Recent advances in 3D semantic segmentation with deep neural networks have shown remarkable success, with rapid performance increase on available datasets. However, current 3D semantic segmentation benchmarks contain only a small number of categories -- less than 30 for ScanNet and SemanticKITTI, for instance, which are not enough to reflect the diversity of real environments (e.g., semantic image understanding covers hundreds to thousands of classes). Thus, we propose to study a larger vocabulary for 3D semantic segmentation with a new extended benchmark on ScanNet data with 200 class categories, an order of magnitude more than previously studied. This large number of class categories also induces a large natural class imbalance, both of which are challenging for existing 3D semantic segmentation methods. To learn more robust 3D features in this context, we propose a language-driven pre-training method to encourage learned 3D features that might have limited training examples to lie close to their pre-trained text embeddings. Extensive experiments show that our approach consistently outperforms state-of-the-art 3D pre-training for 3D semantic segmentation on our proposed benchmark (+9% relative mIoU), including limited-data scenarios with +25% relative mIoU using only 5% annotations.
UFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Jan 12, 2021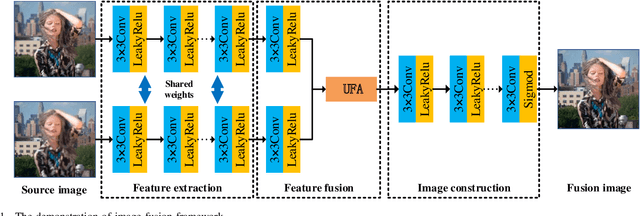
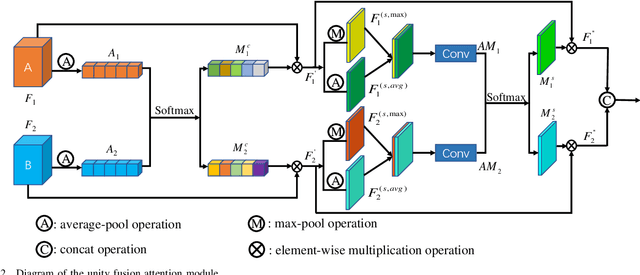


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.
CM3: A Causal Masked Multimodal Model of the Internet
Jan 19, 2022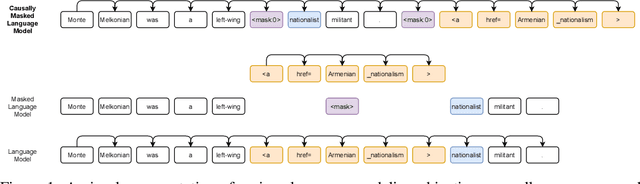
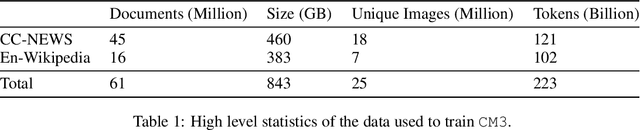
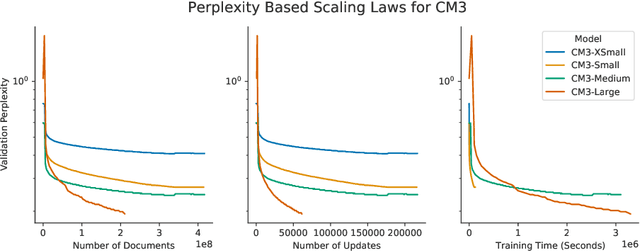
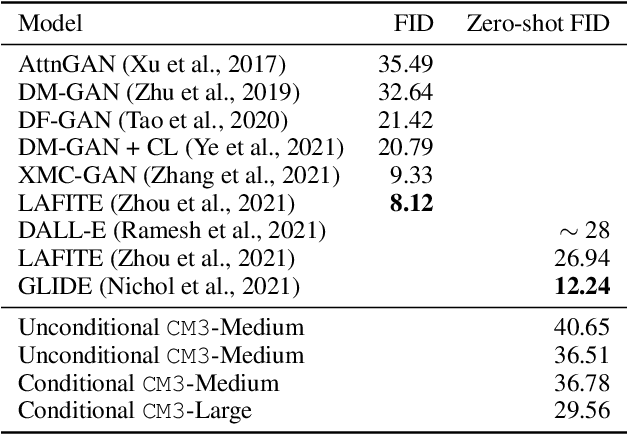
We introduce CM3, a family of causally masked generative models trained over a large corpus of structured multi-modal documents that can contain both text and image tokens. Our new causally masked approach generates tokens left to right while also masking out a small number of long token spans that are generated at the end of the string, instead of their original positions. The casual masking object provides a type of hybrid of the more common causal and masked language models, by enabling full generative modeling while also providing bidirectional context when generating the masked spans. We train causally masked language-image models on large-scale web and Wikipedia articles, where each document contains all of the text, hypertext markup, hyperlinks, and image tokens (from a VQVAE-GAN), provided in the order they appear in the original HTML source (before masking). The resulting CM3 models can generate rich structured, multi-modal outputs while conditioning on arbitrary masked document contexts, and thereby implicitly learn a wide range of text, image, and cross modal tasks. They can be prompted to recover, in a zero-shot fashion, the functionality of models such as DALL-E, GENRE, and HTLM. We set the new state-of-the-art in zero-shot summarization, entity linking, and entity disambiguation while maintaining competitive performance in the fine-tuning setting. We can generate images unconditionally, conditioned on text (like DALL-E) and do captioning all in a zero-shot setting with a single model.
On Hyperbolic Embeddings in 2D Object Detection
Mar 18, 2022



Object detection, for the most part, has been formulated in the euclidean space, where euclidean or spherical geodesic distances measure the similarity of an image region to an object class prototype. In this work, we study whether a hyperbolic geometry better matches the underlying structure of the object classification space. We incorporate a hyperbolic classifier in two-stage, keypoint-based, and transformer-based object detection architectures and evaluate them on large-scale, long-tailed, and zero-shot object detection benchmarks. In our extensive experimental evaluations, we observe categorical class hierarchies emerging in the structure of the classification space, resulting in lower classification errors and boosting the overall object detection performance.
A Multi-Task Cross-Task Learning Architecture for Ad-hoc Uncertainty Estimation in 3D Cardiac MRI Image Segmentation
Sep 16, 2021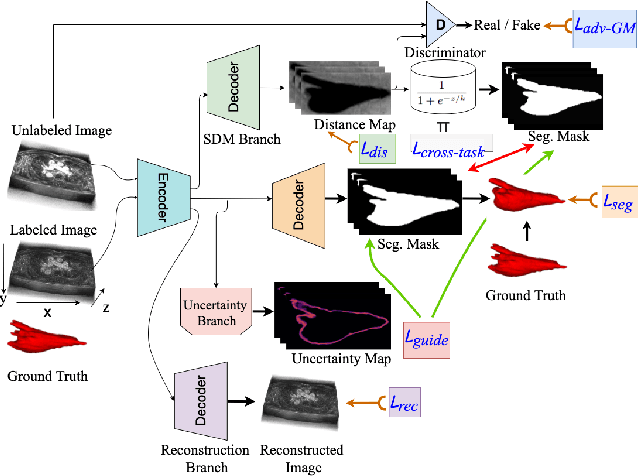

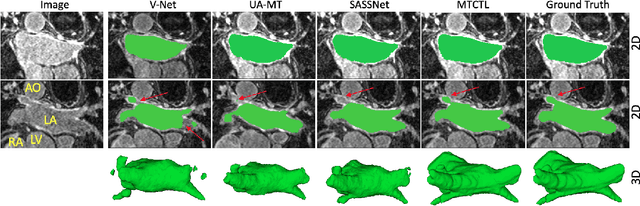
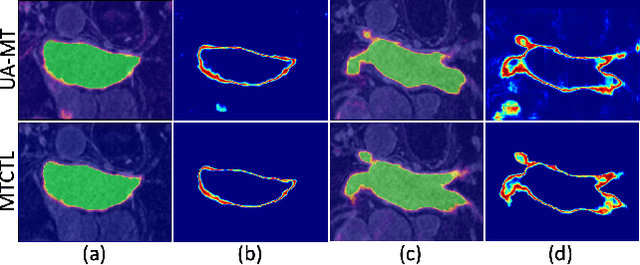
Medical image segmentation has significantly benefitted thanks to deep learning architectures. Furthermore, semi-supervised learning (SSL) has recently been a growing trend for improving a model's overall performance by leveraging abundant unlabeled data. Moreover, learning multiple tasks within the same model further improves model generalizability. To generate smoother and accurate segmentation masks from 3D cardiac MR images, we present a Multi-task Cross-task learning consistency approach to enforce the correlation between the pixel-level (segmentation) and the geometric-level (distance map) tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justifies the effectiveness of our model for the segmentation of the left atrial cavity from Gadolinium-enhanced magnetic resonance (GE-MR) images. With the incorporation of uncertainty estimates to detect failures in the segmentation masks generated by CNNs, our study further showcases the potential of our model to flag low-quality segmentation from a given model.
Six-channel Image Representation for Cross-domain Object Detection
Jan 03, 2021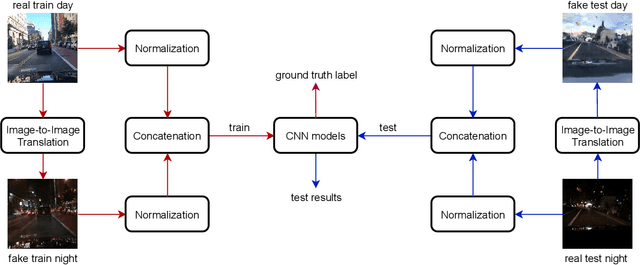



Most deep learning models are data-driven and the excellent performance is highly dependent on the abundant and diverse datasets. However, it is very hard to obtain and label the datasets of some specific scenes or applications. If we train the detector using the data from one domain, it cannot perform well on the data from another domain due to domain shift, which is one of the big challenges of most object detection models. To address this issue, some image-to-image translation techniques are employed to generate some fake data of some specific scenes to train the models. With the advent of Generative Adversarial Networks (GANs), we could realize unsupervised image-to-image translation in both directions from a source to a target domain and from the target to the source domain. In this study, we report a new approach to making use of the generated images. We propose to concatenate the original 3-channel images and their corresponding GAN-generated fake images to form 6-channel representations of the dataset, hoping to address the domain shift problem while exploiting the success of available detection models. The idea of augmented data representation may inspire further study on object detection and other applications.
On the Pitfalls of Using the Residual Error as Anomaly Score
Feb 08, 2022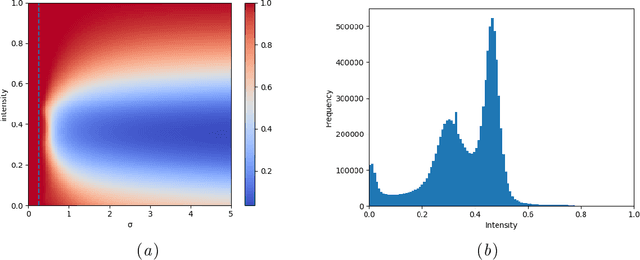
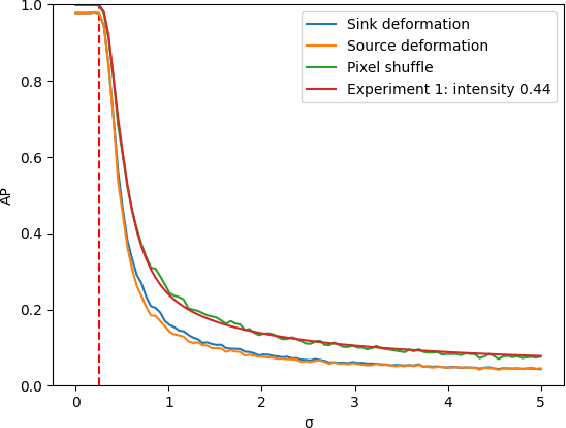
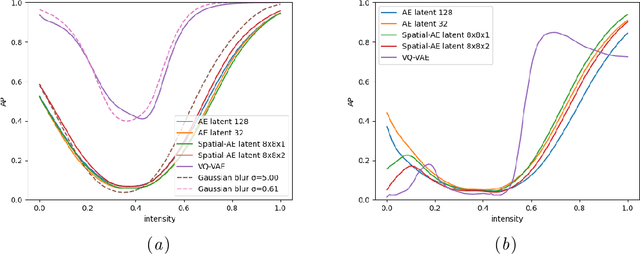
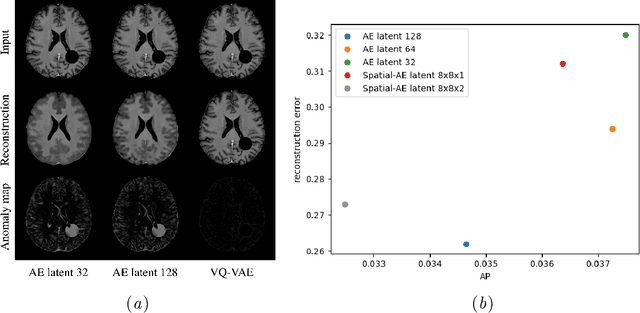
Many current state-of-the-art methods for anomaly localization in medical images rely on calculating a residual image between a potentially anomalous input image and its "healthy" reconstruction. As the reconstruction of the unseen anomalous region should be erroneous, this yields large residuals as a score to detect anomalies in medical images. However, this assumption does not take into account residuals resulting from imperfect reconstructions of the machine learning models used. Such errors can easily overshadow residuals of interest and therefore strongly question the use of residual images as scoring function. Our work explores this fundamental problem of residual images in detail. We theoretically define the problem and thoroughly evaluate the influence of intensity and texture of anomalies against the effect of imperfect reconstructions in a series of experiments. Code and experiments are available under https://github.com/FeliMe/residual-score-pitfalls