 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lensless coherent diffraction imaging based on spatial light modulator with unknown modulation curve
Apr 08, 2022
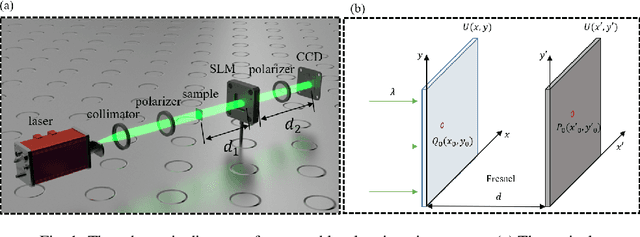


Lensless imaging is a popular research field for the advantages of small size, wide field-of-view and low aberration in recent years. However, some traditional lensless imaging methods suffer from slow convergence, mechanical errors and conjugate solution interference, which limit its further application and development. In this work, we proposed a lensless imaging method based on spatial light modulator (SLM) with unknown modulation curve. In our imaging system, we use SLM to modulate the wavefront of object, and introduce the ptychographic scanning algorithm that is able to recover the complex amplitude information even the SLM modulation curve is inaccurate or unknown. In addition, we also design a split-beam interference experiment to calibrate the modulation curve of SLM, and using the calibrated modulation function as the initial value of the expended ptychography iterative engine (ePIE) algorithm can improve the convergence speed. We further analyze the effect of modulation function, algorithm parameters and the characteristics of the coherent light source on the quality of reconstructed image. The simulated and real experiments show that the proposed method is superior to traditional mechanical scanning methods in terms of recovering speed and accuracy, with the recovering resolution up to 14 um.
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 05, 2020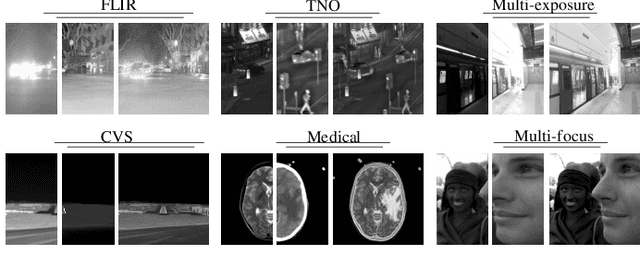
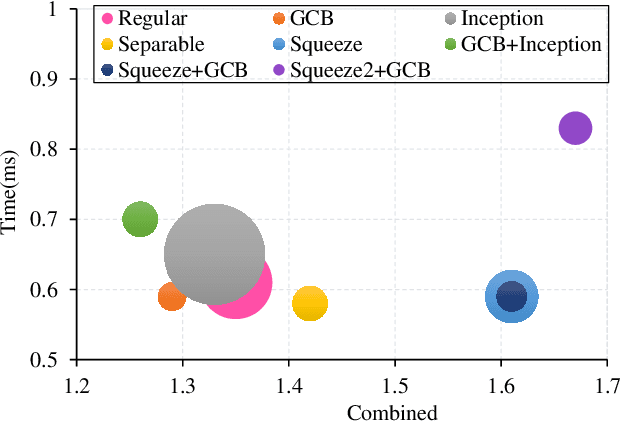

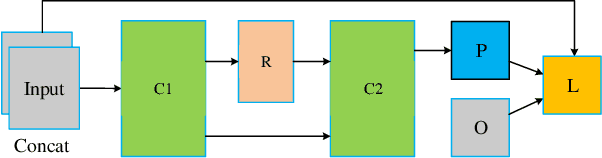
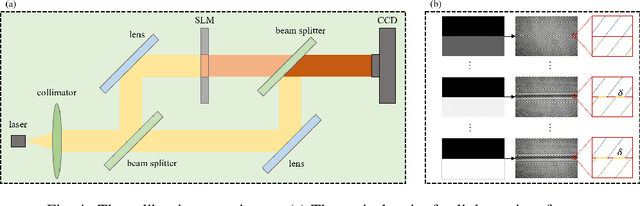
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
Pattern Based Multivariable Regression using Deep Learning (PBMR-DP)
Mar 09, 2022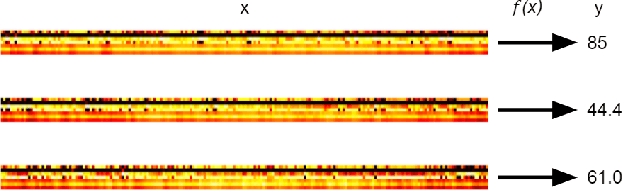
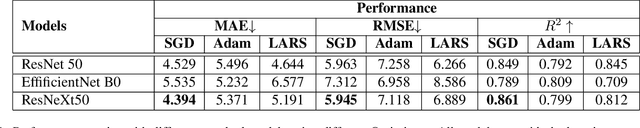
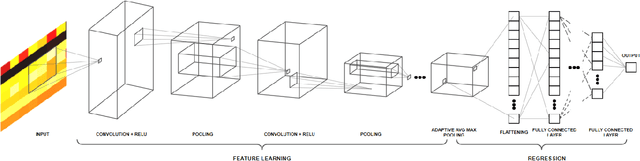

We propose a deep learning methodology for multivariate regression that is based on pattern recognition that triggers fast learning over sensor data. We used a conversion of sensors-to-image which enables us to take advantage of Computer Vision architectures and training processes. In addition to this data preparation methodology, we explore the use of state-of-the-art architectures to generate regression outputs to predict agricultural crop continuous yield information. Finally, we compare with some of the top models reported in MLCAS2021. We found that using a straightforward training process, we were able to accomplish an MAE of 4.394, RMSE of 5.945, and R^2 of 0.861.
FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset
Mar 29, 2022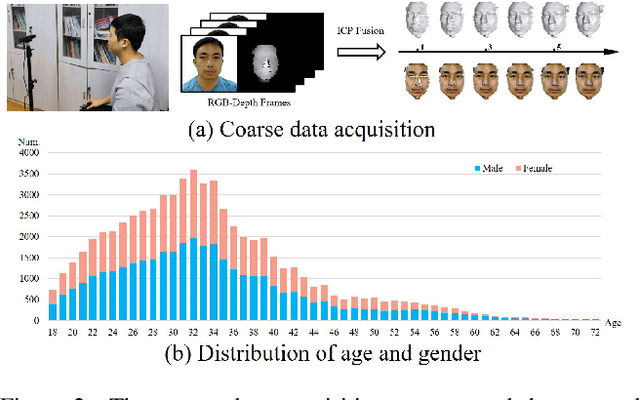
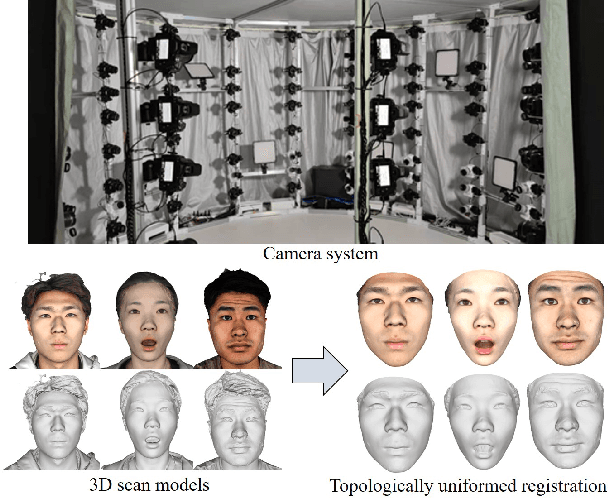
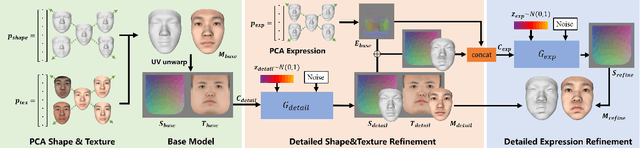
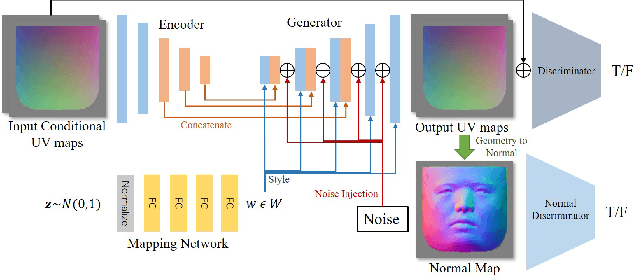
We present FaceVerse, a fine-grained 3D Neural Face Model, which is built from hybrid East Asian face datasets containing 60K fused RGB-D images and 2K high-fidelity 3D head scan models. A novel coarse-to-fine structure is proposed to take better advantage of our hybrid dataset. In the coarse module, we generate a base parametric model from large-scale RGB-D images, which is able to predict accurate rough 3D face models in different genders, ages, etc. Then in the fine module, a conditional StyleGAN architecture trained with high-fidelity scan models is introduced to enrich elaborate facial geometric and texture details. Note that different from previous methods, our base and detailed modules are both changeable, which enables an innovative application of adjusting both the basic attributes and the facial details of 3D face models. Furthermore, we propose a single-image fitting framework based on differentiable rendering. Rich experiments show that our method outperforms the state-of-the-art methods.
GIID-Net: Generalizable Image Inpainting Detection via Neural Architecture Search and Attention
Jan 19, 2021


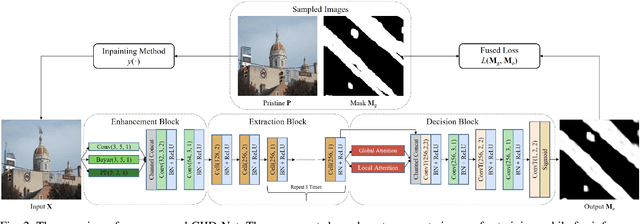
Deep learning (DL) has demonstrated its powerful capabilities in the field of image inpainting, which could produce visually plausible results. Meanwhile, the malicious use of advanced image inpainting tools (e.g. removing key objects to report fake news) has led to increasing threats to the reliability of image data. To fight against the inpainting forgeries, in this work, we propose a novel end-to-end Generalizable Image Inpainting Detection Network (GIID-Net), to detect the inpainted regions at pixel accuracy. The proposed GIID-Net consists of three sub-blocks: the enhancement block, the extraction block and the decision block. Specifically, the enhancement block aims to enhance the inpainting traces by using hierarchically combined special layers. The extraction block, automatically designed by Neural Architecture Search (NAS) algorithm, is targeted to extract features for the actual inpainting detection tasks. In order to further optimize the extracted latent features, we integrate global and local attention modules in the decision block, where the global attention reduces the intra-class differences by measuring the similarity of global features, while the local attention strengthens the consistency of local features. Furthermore, we thoroughly study the generalizability of our GIID-Net, and find that different training data could result in vastly different generalization capability. Extensive experimental results are presented to validate the superiority of the proposed GIID-Net, compared with the state-of-the-art competitors. Our results would suggest that common artifacts are shared across diverse image inpainting methods. Finally, we build a public inpainting dataset of 10K image pairs for the future research in this area.
Comprehensive Saliency Fusion for Object Co-segmentation
Jan 30, 2022Object co-segmentation has drawn significant attention in recent years, thanks to its clarity on the expected foreground, the shared object in a group of images. Saliency fusion has been one of the promising ways to carry it out. However, prior works either fuse saliency maps of the same image or saliency maps of different images to extract the expected foregrounds. Also, they rely on hand-crafted saliency extraction and correspondence processes in most cases. This paper revisits the problem and proposes fusing saliency maps of both the same image and different images. It also leverages advances in deep learning for the saliency extraction and correspondence processes. Hence, we call it comprehensive saliency fusion. Our experiments reveal that our approach achieves much-improved object co-segmentation results compared to prior works on important benchmark datasets such as iCoseg, MSRC, and Internet Images.
* Published in IEEE ISM 2021. Please cite this paper in the following manner. H. S. Chhabra and K. Rao Jerripothula, "Comprehensive Saliency Fusion for Object Co-segmentation," 2021 IEEE International Symposium on Multimedia (ISM), 2021, pp. 107-110, doi: 10.1109/ISM52913.2021.00026
JoJoGAN: One Shot Face Stylization
Dec 22, 2021
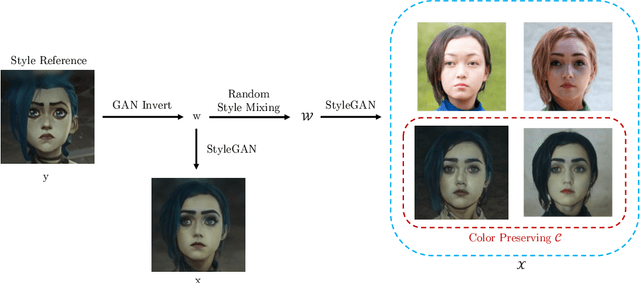


While there have been recent advances in few-shot image stylization, these methods fail to capture stylistic details that are obvious to humans. Details such as the shape of the eyes, the boldness of the lines, are especially difficult for a model to learn, especially so under a limited data setting. In this work, we aim to perform one-shot image stylization that gets the details right. Given a reference style image, we approximate paired real data using GAN inversion and finetune a pretrained StyleGAN using that approximate paired data. We then encourage the StyleGAN to generalize so that the learned style can be applied to all other images.
A Field of Experts Prior for Adapting Neural Networks at Test Time
Feb 10, 2022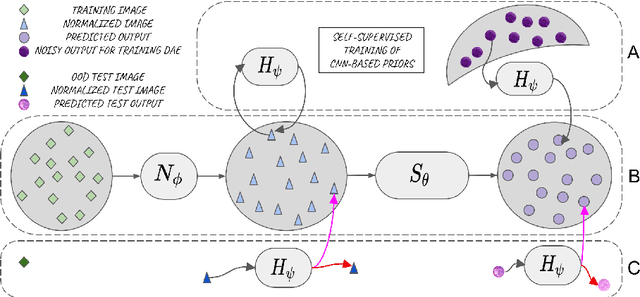
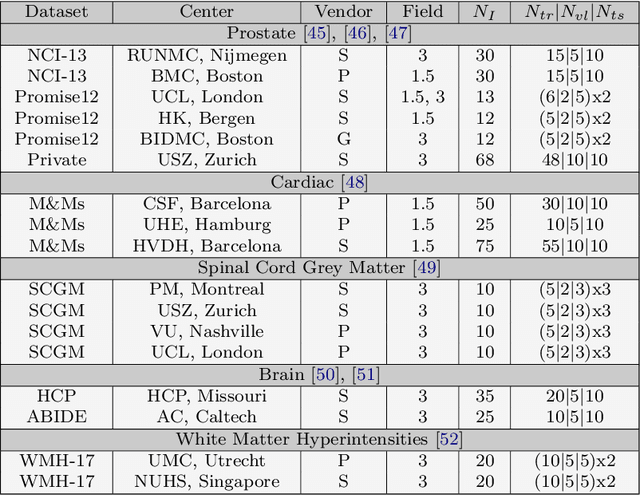
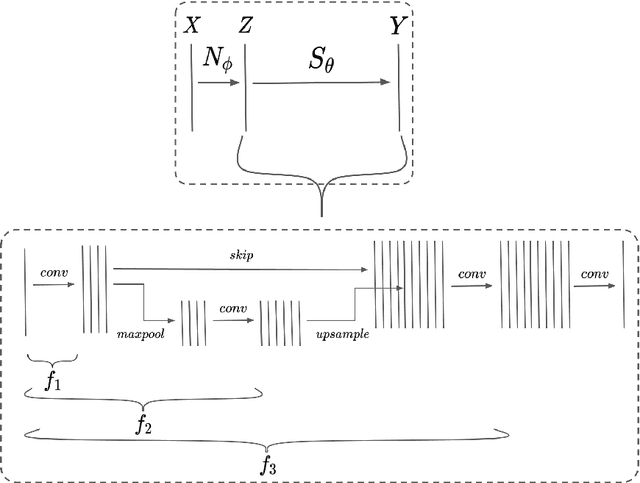
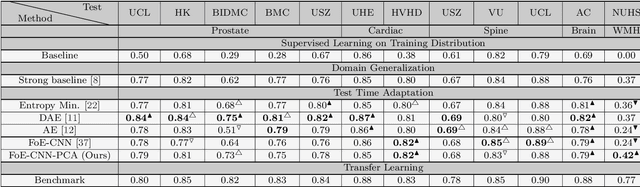
Performance of convolutional neural networks (CNNs) in image analysis tasks is often marred in the presence of acquisition-related distribution shifts between training and test images. Recently, it has been proposed to tackle this problem by fine-tuning trained CNNs for each test image. Such test-time-adaptation (TTA) is a promising and practical strategy for improving robustness to distribution shifts as it requires neither data sharing between institutions nor annotating additional data. Previous TTA methods use a helper model to increase similarity between outputs and/or features extracted from a test image with those of the training images. Such helpers, which are typically modeled using CNNs, can be task-specific and themselves vulnerable to distribution shifts in their inputs. To overcome these problems, we propose to carry out TTA by matching the feature distributions of test and training images, as modelled by a field-of-experts (FoE) prior. FoEs model complicated probability distributions as products of many simpler expert distributions. We use 1D marginal distributions of a trained task CNN's features as experts in the FoE model. Further, we compute principal components of patches of the task CNN's features, and consider the distributions of PCA loadings as additional experts. We validate the method on 5 MRI segmentation tasks (healthy tissues in 4 anatomical regions and lesions in 1 one anatomy), using data from 17 clinics, and on a MRI registration task, using data from 3 clinics. We find that the proposed FoE-based TTA is generically applicable in multiple tasks, and outperforms all previous TTA methods for lesion segmentation. For healthy tissue segmentation, the proposed method outperforms other task-agnostic methods, but a previous TTA method which is specifically designed for segmentation performs the best for most of the tested datasets. Our code is publicly available.
TricycleGAN: Unsupervised Image Synthesis and Segmentation Based on Shape Priors
Feb 04, 2021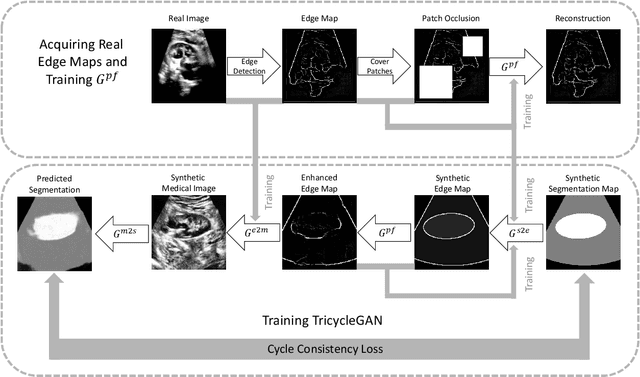

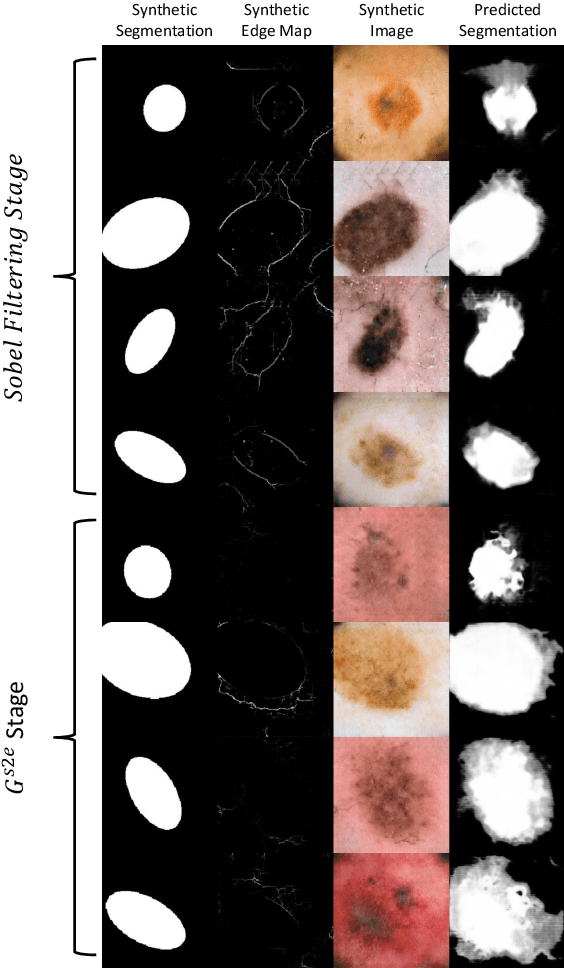
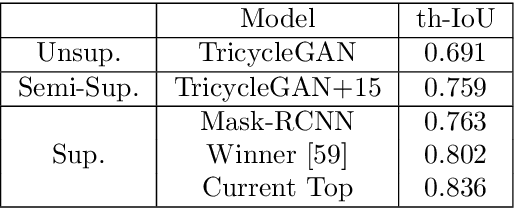
Medical image segmentation is routinely performed to isolate regions of interest, such as organs and lesions. Currently, deep learning is the state of the art for automatic segmentation, but is usually limited by the need for supervised training with large datasets that have been manually segmented by trained clinicians. The goal of semi-superised and unsupervised image segmentation is to greatly reduce, or even eliminate, the need for training data and therefore to minimze the burden on clinicians when training segmentation models. To this end we introduce a novel network architecture for capable of unsupervised and semi-supervised image segmentation called TricycleGAN. This approach uses three generative models to learn translations between medical images and segmentation maps using edge maps as an intermediate step. Distinct from other approaches based on generative networks, TricycleGAN relies on shape priors rather than colour and texture priors. As such, it is particularly well-suited for several domains of medical imaging, such as ultrasound imaging, where commonly used visual cues may be absent. We present experiments with TricycleGAN on a clinical dataset of kidney ultrasound images and the benchmark ISIC 2018 skin lesion dataset.
Muscle Vision: Real Time Keypoint Based Pose Classification of Physical Exercises
Mar 23, 2022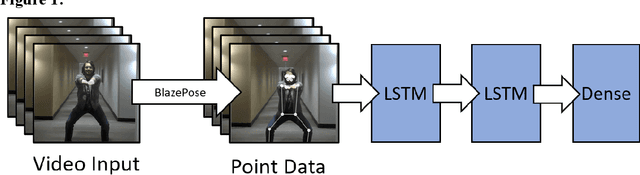
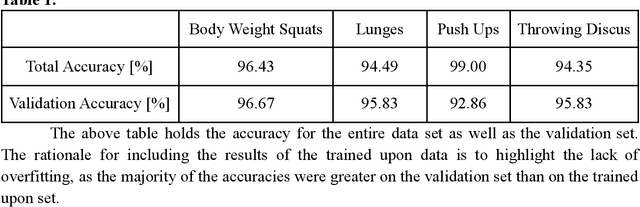
Recent advances in machine learning technology have enabled highly portable and performant models for many common tasks, especially in image recognition. One emerging field, 3D human pose recognition extrapolated from video, has now advanced to the point of enabling real-time software applications with robust enough output to support downstream machine learning tasks. In this work we propose a new machine learning pipeline and web interface that performs human pose recognition on a live video feed to detect when common exercises are performed and classify them accordingly. We present a model interface capable of webcam input with live display of classification results. Our main contributions include a keypoint and time series based lightweight approach for classifying a selected set of fitness exercises and a web-based software application for obtaining and visualizing the results in real time.