 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022
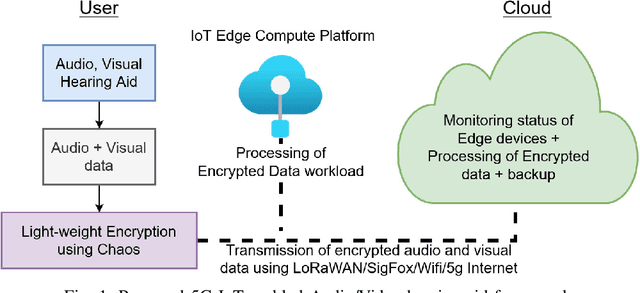

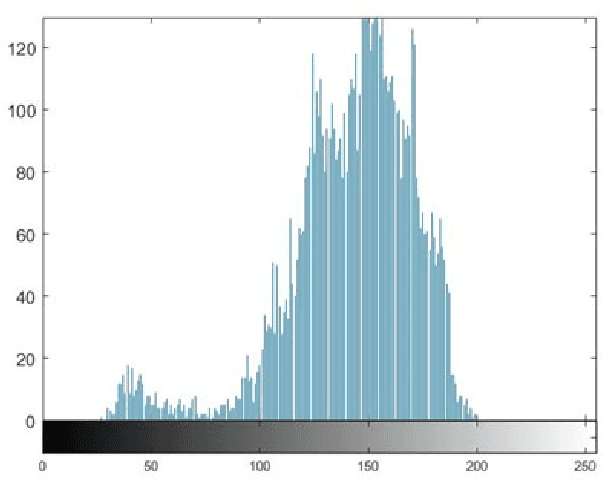
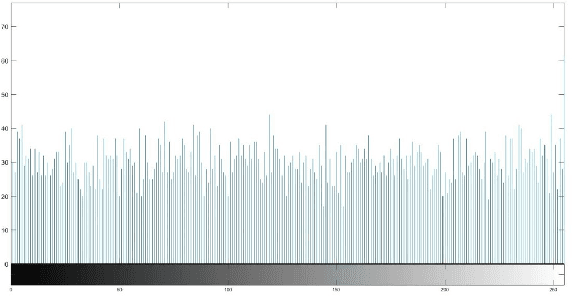
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
One-shot Federated Learning without Server-side Training
Apr 26, 2022
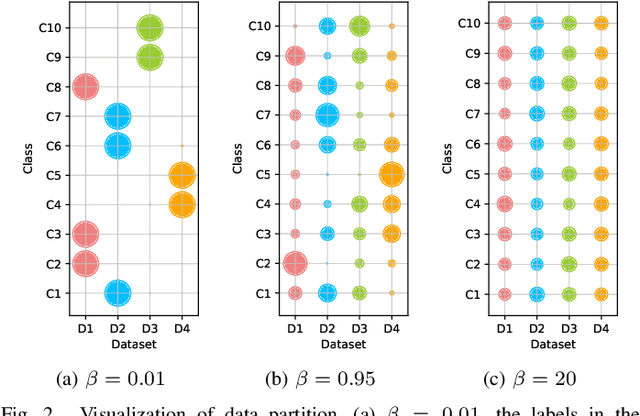
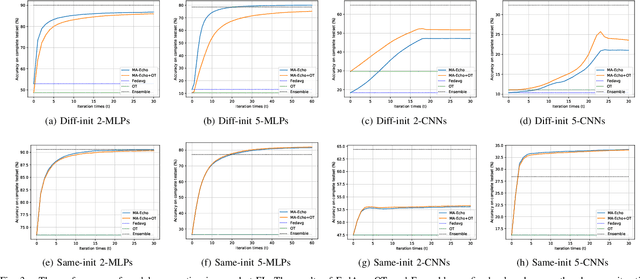
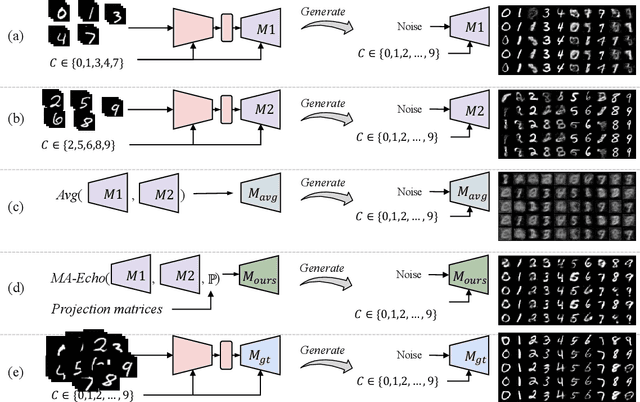
Federated Learning (FL) has recently made significant progress as a new machine learning paradigm for privacy protection. Due to the high communication cost of traditional FL, one-shot federated learning is gaining popularity as a way to reduce communication cost between clients and the server. Most of the existing one-shot FL methods are based on Knowledge Distillation; however, distillation based approach requires an extra training phase and depends on publicly available data sets. In this work, we consider a novel and challenging setting: performing a single round of parameter aggregation on the local models without server-side training on a public data set. In this new setting, we propose an effective algorithm for Model Aggregation via Exploring Common Harmonized Optima (MA-Echo), which iteratively updates the parameters of all local models to bring them close to a common low-loss area on the loss surface, without harming performance on their own data sets at the same time. Compared to the existing methods, MA-Echo can work well even in extremely non-identical data distribution settings where the support categories of each local model have no overlapped labels with those of the others. We conduct extensive experiments on two popular image classification data sets to compare the proposed method with existing methods and demonstrate the effectiveness of MA-Echo, which clearly outperforms the state-of-the-arts.
Consolidated Dataset and Metrics for High-Dynamic-Range Image Quality
Dec 19, 2020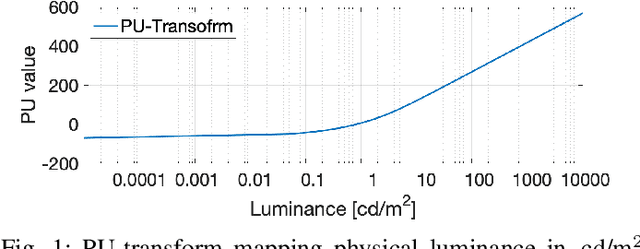
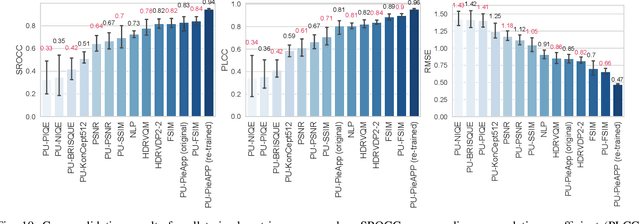
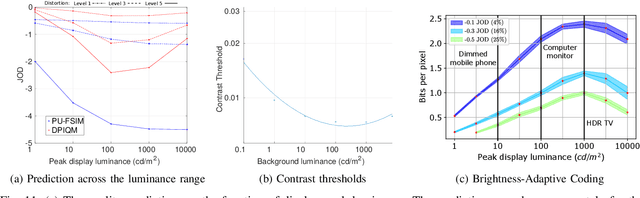
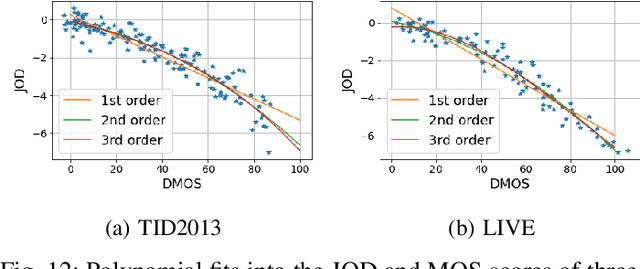
Increasing popularity of high-dynamic-range (HDR) image and video content brings the need for metrics that could predict the severity of image impairments as seen on displays of different brightness levels and dynamic range. Such metrics should be trained and validated on a sufficiently large subjective image quality dataset to ensure robust performance. As the existing HDR quality datasets are limited in size, we created a Unified Photometric Image Quality dataset (UPIQ) with over 4,000 images by realigning and merging existing HDR and standard-dynamic-range (SDR) datasets. The realigned quality scores share the same unified quality scale across all datasets. Such realignment was achieved by collecting additional cross-dataset quality comparisons and re-scaling data with a psychometric scaling method. Images in the proposed dataset are represented in absolute photometric and colorimetric units, corresponding to light emitted from a display. We use the new dataset to retrain existing HDR metrics and show that the dataset is sufficiently large for training deep architectures. We show the utility of the dataset on brightness aware image compression.
On the Unreasonable Effectiveness of Centroids in Image Retrieval
Apr 28, 2021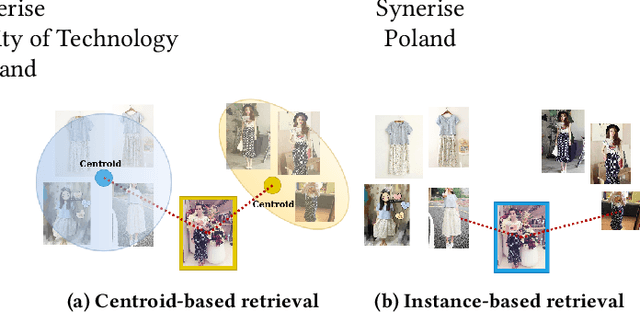
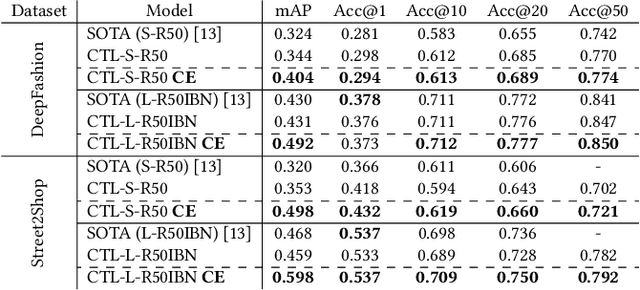
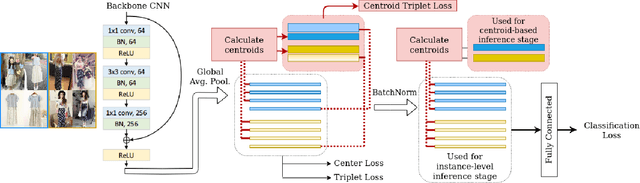
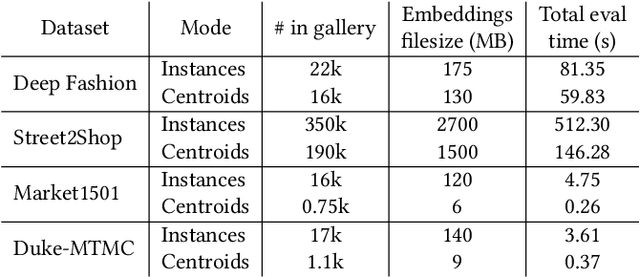
Image retrieval task consists of finding similar images to a query image from a set of gallery (database) images. Such systems are used in various applications e.g. person re-identification (ReID) or visual product search. Despite active development of retrieval models it still remains a challenging task mainly due to large intra-class variance caused by changes in view angle, lighting, background clutter or occlusion, while inter-class variance may be relatively low. A large portion of current research focuses on creating more robust features and modifying objective functions, usually based on Triplet Loss. Some works experiment with using centroid/proxy representation of a class to alleviate problems with computing speed and hard samples mining used with Triplet Loss. However, these approaches are used for training alone and discarded during the retrieval stage. In this paper we propose to use the mean centroid representation both during training and retrieval. Such an aggregated representation is more robust to outliers and assures more stable features. As each class is represented by a single embedding - the class centroid - both retrieval time and storage requirements are reduced significantly. Aggregating multiple embeddings results in a significant reduction of the search space due to lowering the number of candidate target vectors, which makes the method especially suitable for production deployments. Comprehensive experiments conducted on two ReID and Fashion Retrieval datasets demonstrate effectiveness of our method, which outperforms the current state-of-the-art. We propose centroid training and retrieval as a viable method for both Fashion Retrieval and ReID applications.
Biologically Inspired Hexagonal Deep Learning for Hexagonal Image Generation
Jan 01, 2021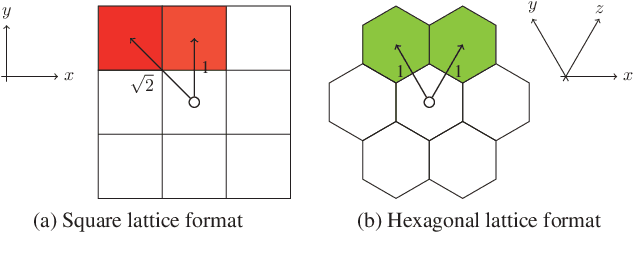
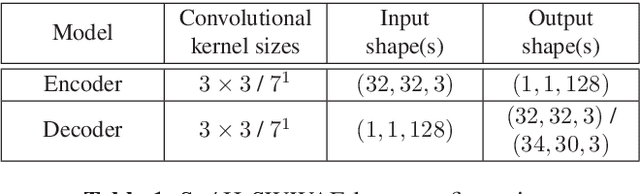
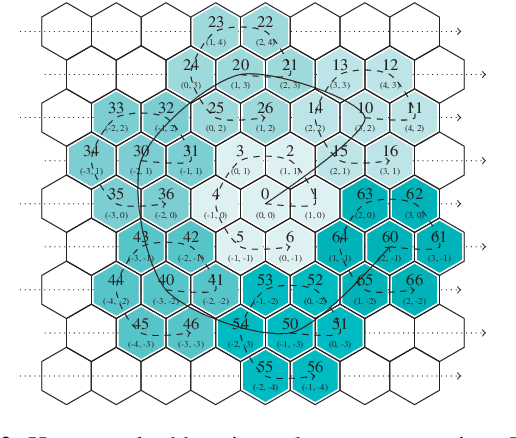
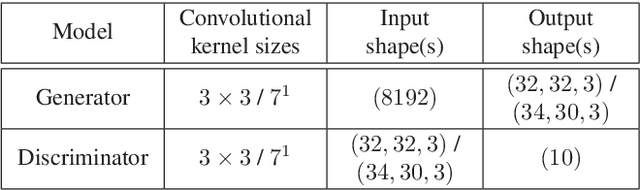
Whereas conventional state-of-the-art image processing systems of recording and output devices almost exclusively utilize square arranged methods, biological models, however, suggest an alternative, evolutionarily-based structure. Inspired by the human visual perception system, hexagonal image processing in the context of machine learning offers a number of key advantages that can benefit both researchers and users alike. The hexagonal deep learning framework Hexnet leveraged in this contribution serves therefore the generation of hexagonal images by utilizing hexagonal deep neural networks (H-DNN). As the results of our created test environment show, the proposed models can surpass current approaches of conventional image generation. While resulting in a reduction of the models' complexity in the form of trainable parameters, they furthermore allow an increase of test rates in comparison to their square counterparts.
DSSIM: a structural similarity index for floating-point data
Feb 05, 2022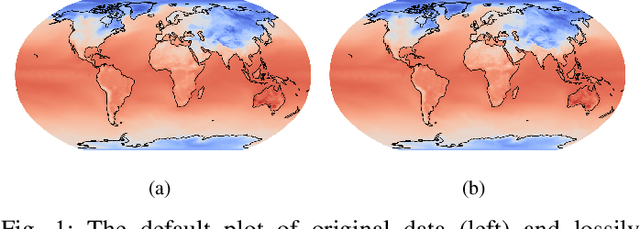
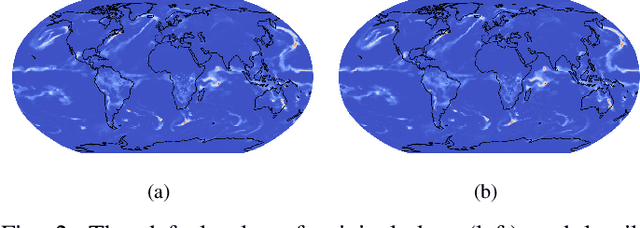
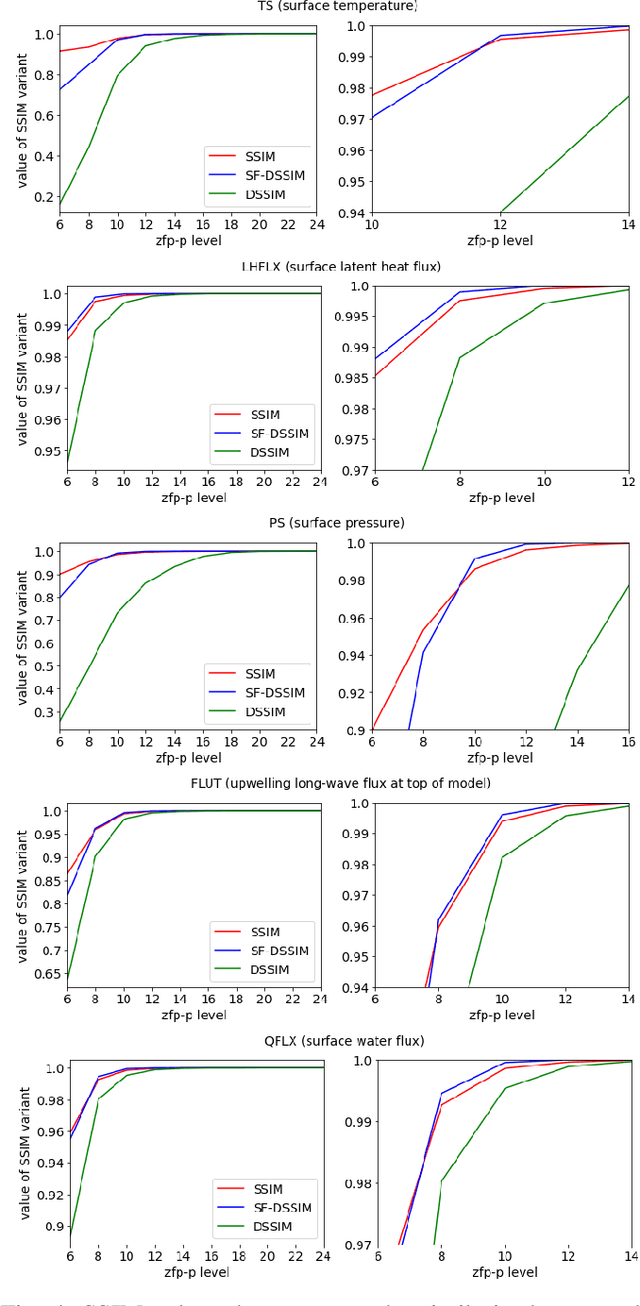
Data visualization is a critical component in terms of interacting with floating-point output data from large model simulation codes. Indeed, postprocessing analysis workflows on simulation data often generate a large number of images from the raw data, many of which are then compared to each other or to specified reference images. In this image-comparison scenario, image quality assessment (IQA) measures are quite useful, and the Structural Similarity Index (SSIM) continues to be a popular choice. However, generating large numbers of images can be costly, and plot-specific (but data independent) choices can affect the SSIM value. A natural question is whether we can apply the SSIM directly to the floating-point simulation data and obtain an indication of whether differences in the data are likely to impact a visual assessment, effectively bypassing the creation of a specific set of images from the data. To this end, we propose an alternative to the popular SSIM that can be applied directly to the floating point data, which we refer to as the Data SSIM (DSSIM). While we demonstrate the usefulness of the DSSIM in the context of evaluating differences due to lossy compression on large volumes of simulation data from a popular climate model, the DSSIM may prove useful for many other applications involving simulation or image data.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
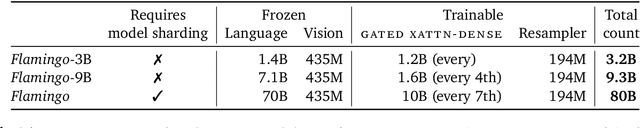
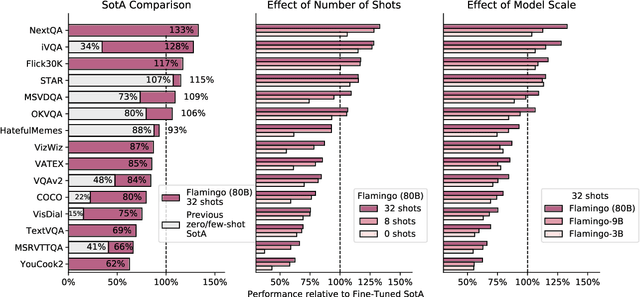
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
A Feasibility Study on Real-Time High Resolution Imaging of the Brain Using Electrical Impedance Tomography
Mar 07, 2022
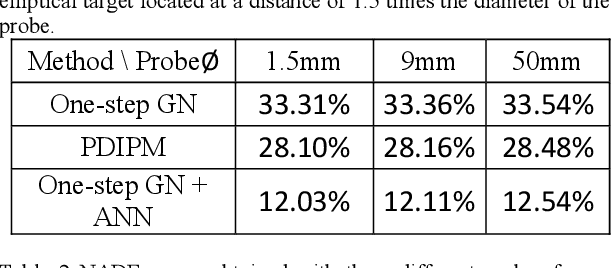


Objective: The strengths of Electrical Impedance Tomography (EIT) are its capability of imaging the internal body by using a noninvasive, radiation safe technique, and the absence of known hazards. In this paper we introduce a novel idea of using EIT in microelectrodes during Deep Brain Stimulation (DBS) surgery in order to obtain an image of the electrical conductivities of the brain tissues surrounding the microelectrodes. DBS is a surgical treatment involving the implantation of a medical probe inside the brain. For such application, the EIT reconstruction method has to offer both high quality and robustness against noise. Methods: A post-processing method for open-domain EIT is introduced in this paper, which combines linear and nonlinear methods in order to use the advantages of both with limited drawbacks. The reconstruction method is a two-steps method, the first solves the inverse problem with a linear algorithm and the second brings the nonlinear aspects back into the image. Results: The proposed method is tested on both simulation and phantom data, and compared to three widely used method for EIT imaging. Resulting images and errors gives a strong advantage to the proposed solution. Conclusion: High quality reconstruction from phantom data validates the efficiency of the novel reconstruction method. Significance: This feasibility study presents an efficient method for open domain EIT and opens the way to clinical trials.
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
Jan 14, 2021
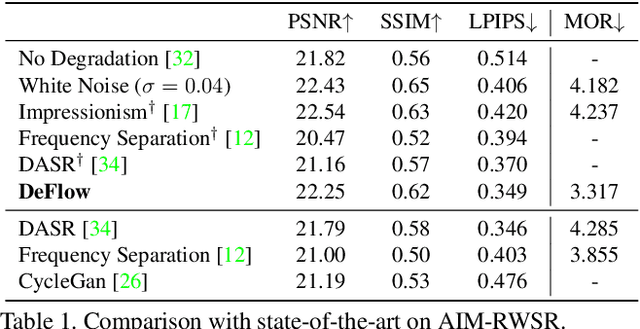
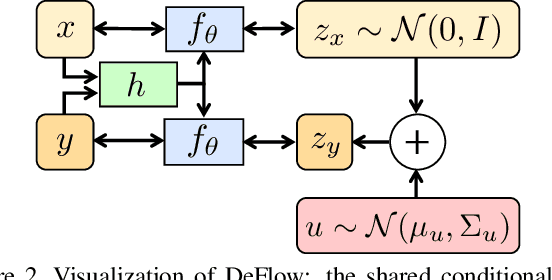
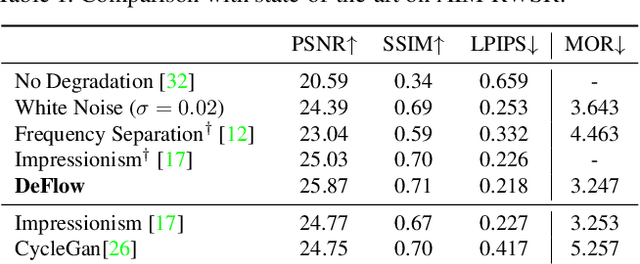
The difficulty of obtaining paired data remains a major bottleneck for learning image restoration and enhancement models for real-world applications. Current strategies aim to synthesize realistic training data by modeling noise and degradations that appear in real-world settings. We propose DeFlow, a method for learning stochastic image degradations from unpaired data. Our approach is based on a novel unpaired learning formulation for conditional normalizing flows. We model the degradation process in the latent space of a shared flow encoder-decoder network. This allows us to learn the conditional distribution of a noisy image given the clean input by solely minimizing the negative log-likelihood of the marginal distributions. We validate our DeFlow formulation on the task of joint image restoration and super-resolution. The models trained with the synthetic data generated by DeFlow outperform previous learnable approaches on all three datasets.
Image Classification with Consistent Supporting Evidence
Nov 13, 2021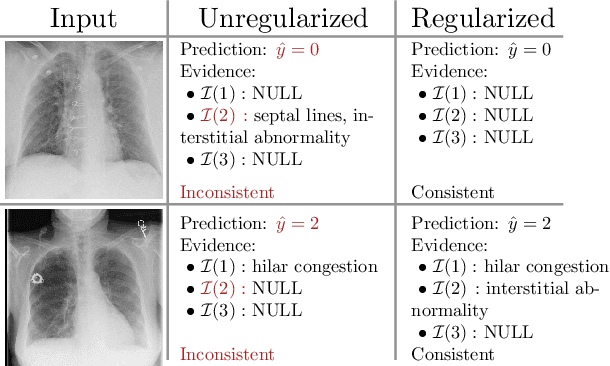


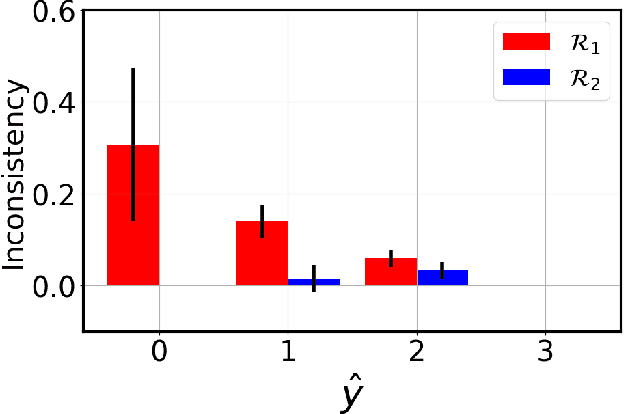
Adoption of machine learning models in healthcare requires end users' trust in the system. Models that provide additional supportive evidence for their predictions promise to facilitate adoption. We define consistent evidence to be both compatible and sufficient with respect to model predictions. We propose measures of model inconsistency and regularizers that promote more consistent evidence. We demonstrate our ideas in the context of edema severity grading from chest radiographs. We demonstrate empirically that consistent models provide competitive performance while supporting interpretation.