 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MetaHDR: Model-Agnostic Meta-Learning for HDR Image Reconstruction
Mar 20, 2021
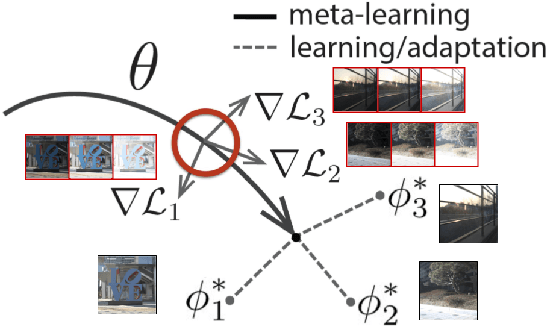
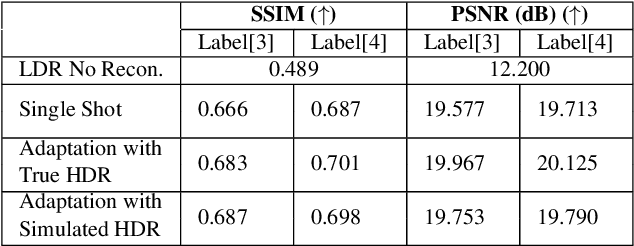

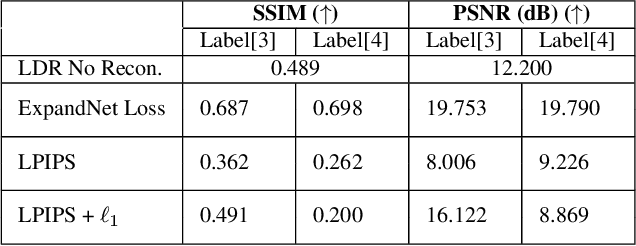
Capturing scenes with a high dynamic range is crucial to reproducing images that appear similar to those seen by the human visual system. Despite progress in developing data-driven deep learning approaches for converting low dynamic range images to high dynamic range images, existing approaches are limited by the assumption that all conversions are governed by the same nonlinear mapping. To address this problem, we propose "Model-Agnostic Meta-Learning for HDR Image Reconstruction" (MetaHDR), which applies meta-learning to the LDR-to-HDR conversion problem using existing HDR datasets. Our key novelty is the reinterpretation of LDR-to-HDR conversion scenes as independently sampled tasks from a common LDR-to-HDR conversion task distribution. Naturally, we use a meta-learning framework that learns a set of meta-parameters which capture the common structure consistent across all LDR-to-HDR conversion tasks. Finally, we perform experimentation with MetaHDR to demonstrate its capacity to tackle challenging LDR-to-HDR image conversions. Code and pretrained models are available at https://github.com/edwin-pan/MetaHDR.
Self-Organized Residual Blocks for Image Super-Resolution
May 31, 2021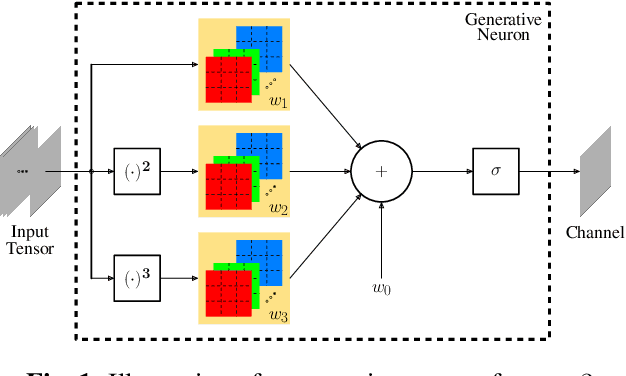
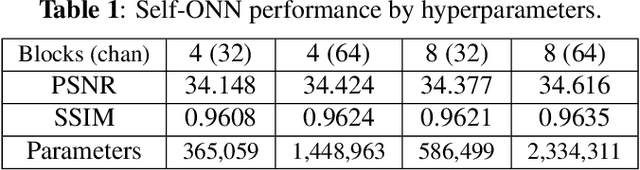
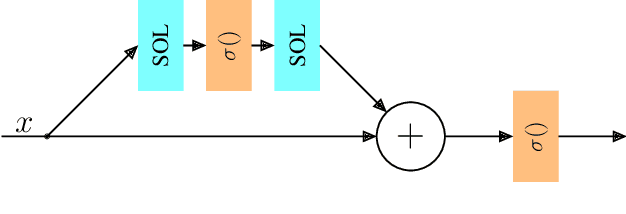
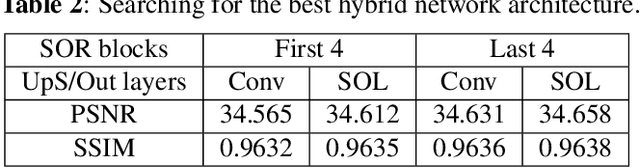
It has become a standard practice to use the convolutional networks (ConvNet) with RELU non-linearity in image restoration and super-resolution (SR). Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks (ONNs) that choose the best non-linearity from a set of alternatives, and their "self-organized" variants (Self-ONN) that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this paper, we propose the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results demonstrate that the~proposed architectures yield performance improvements in both PSNR and perceptual metrics.
Deep network for rolling shutter rectification
Dec 12, 2021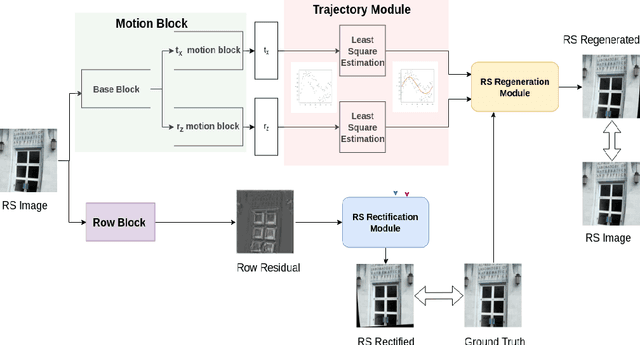



CMOS sensors employ row-wise acquisition mechanism while imaging a scene, which can result in undesired motion artifacts known as rolling shutter (RS) distortions in the captured image. Existing single image RS rectification methods attempt to account for these distortions by either using algorithms tailored for specific class of scenes which warrants information of intrinsic camera parameters or a learning-based framework with known ground truth motion parameters. In this paper, we propose an end-to-end deep neural network for the challenging task of single image RS rectification. Our network consists of a motion block, a trajectory module, a row block, an RS rectification module and an RS regeneration module (which is used only during training). The motion block predicts camera pose for every row of the input RS distorted image while the trajectory module fits estimated motion parameters to a third-order polynomial. The row block predicts the camera motion that must be associated with every pixel in the target i.e, RS rectified image. Finally, the RS rectification module uses motion trajectory and the output of row block to warp the input RS image to arrive at a distortionfree image. For faster convergence during training, we additionally use an RS regeneration module which compares the input RS image with the ground truth image distorted by estimated motion parameters. The end-to-end formulation in our model does not constrain the estimated motion to ground-truth motion parameters, thereby successfully rectifying the RS images with complex real-life camera motion. Experiments on synthetic and real datasets reveal that our network outperforms prior art both qualitatively and quantitatively.
Image interpretation by iterative bottom-up top-down processing
May 12, 2021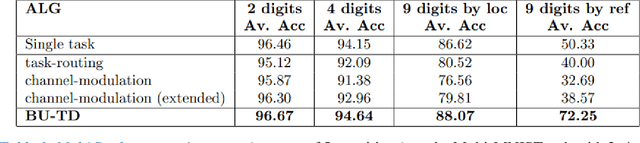
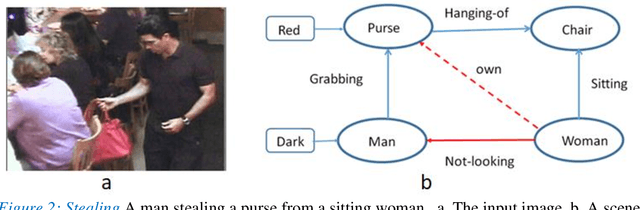

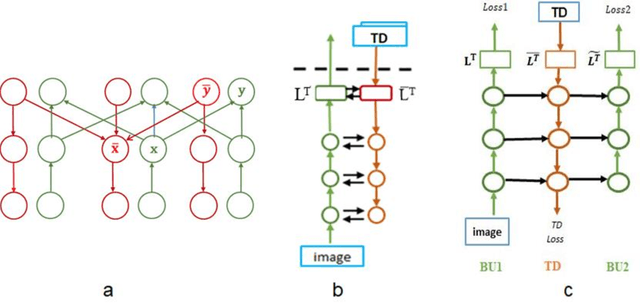
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
MDT-Net: Multi-domain Transfer by Perceptual Supervision for Unpaired Images in OCT Scan
Mar 12, 2022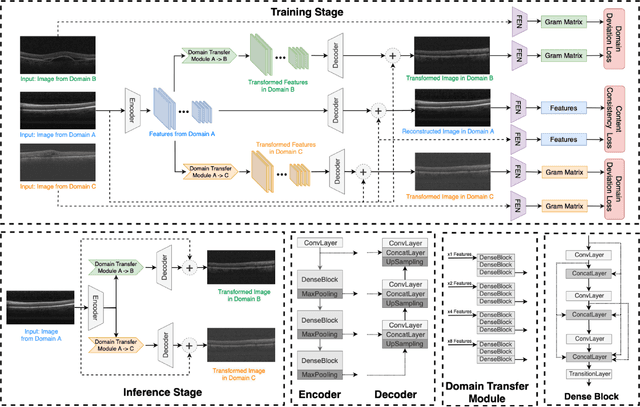
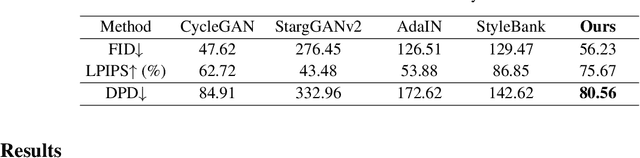
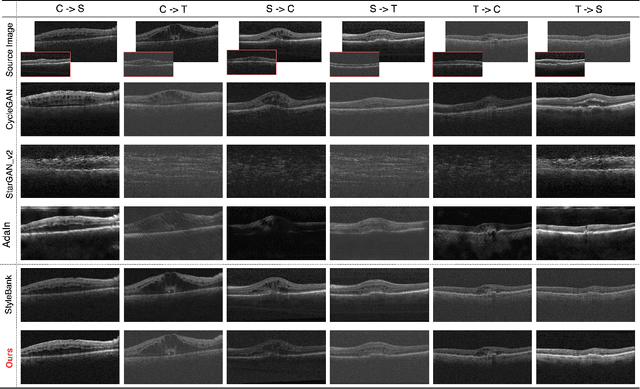
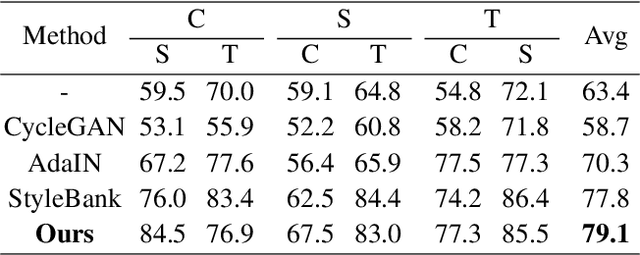
Deep learning models tend to underperform in the presence of domain shifts. Domain transfer has recently emerged as a promising approach wherein images exhibiting a domain shift are transformed into other domains for augmentation or adaptation. However, with the absence of paired and annotated images, most domain transfer methods mainly rely on adversarial networks and weak cycle consistency, which could result in incomplete domain transfer or poor adherence to the original image content. In this paper, we introduce MDT-Net to address the limitations above through a multi-domain transfer model based on perceptual supervision. Specifically, our model consists of an encoder-decoder network, which aims to preserve anatomical structures, and multiple domain-specific transfer modules, which guide the domain transition through feature transformation. During the inference, MDT-Net can directly transfer images from the source domain to multiple target domains at one time without any reference image. To demonstrate the performance of MDT-Net, we evaluate it on RETOUCH dataset, comprising OCT scans from three different scanner devices (domains), for multi-domain transfer. We also take the transformed results as additional training images for fluid segmentation in OCT scans in the tasks of domain adaptation and data augmentation. Experimental results show that MDT-Net can outperform other domain transfer models qualitatively and quantitatively. Furthermore, the significant improvement in dice scores over multiple segmentation models also demonstrates the effectiveness and efficiency of our proposed method.
Image Captioning using Deep Stacked LSTMs, Contextual Word Embeddings and Data Augmentation
Feb 22, 2021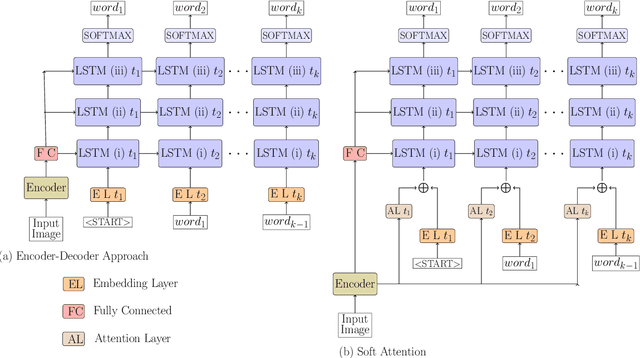
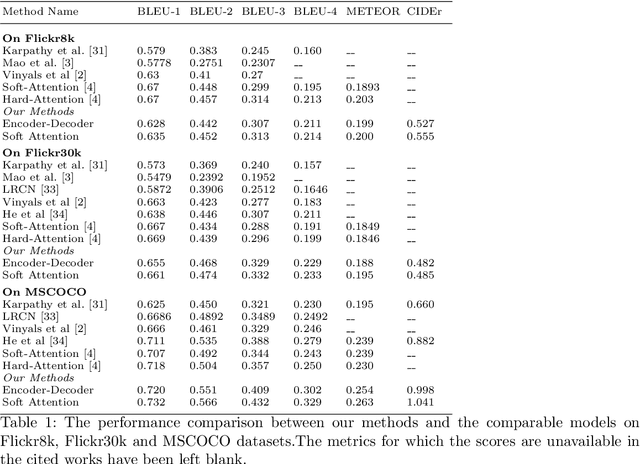
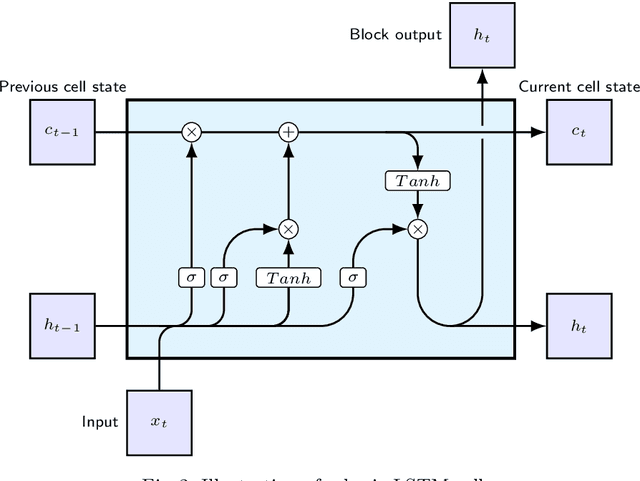

Image Captioning, or the automatic generation of descriptions for images, is one of the core problems in Computer Vision and has seen considerable progress using Deep Learning Techniques. We propose to use Inception-ResNet Convolutional Neural Network as encoder to extract features from images, Hierarchical Context based Word Embeddings for word representations and a Deep Stacked Long Short Term Memory network as decoder, in addition to using Image Data Augmentation to avoid over-fitting. For data Augmentation, we use Horizontal and Vertical Flipping in addition to Perspective Transformations on the images. We evaluate our proposed methods with two image captioning frameworks- Encoder-Decoder and Soft Attention. Evaluation on widely used metrics have shown that our approach leads to considerable improvement in model performance.
Feature-level augmentation to improve robustness of deep neural networks to affine transformations
Feb 10, 2022
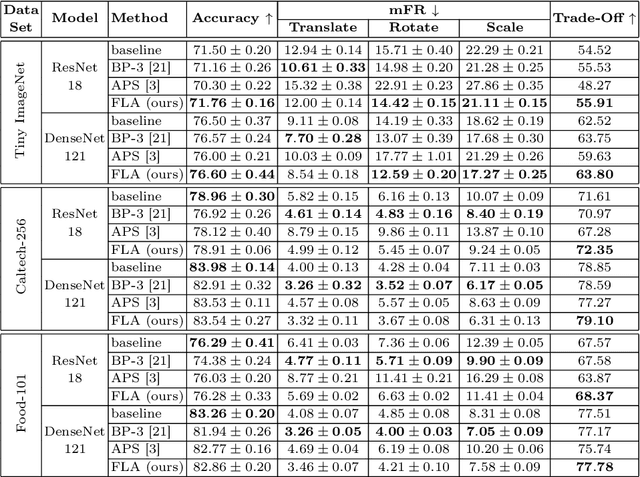

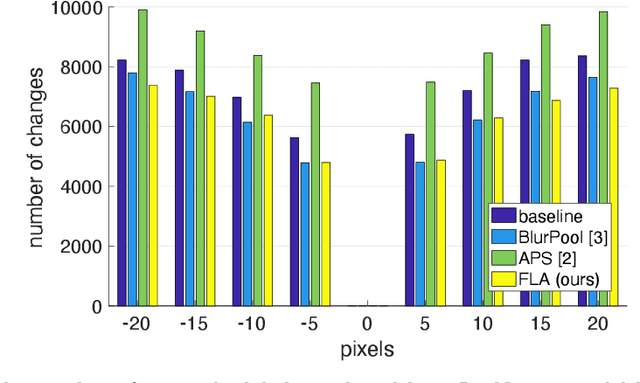
Recent studies revealed that convolutional neural networks do not generalize well to small image transformations, e.g. rotations by a few degrees or translations of a few pixels. To improve the robustness to such transformations, we propose to introduce data augmentation at intermediate layers of the neural architecture, in addition to the common data augmentation applied on the input images. By introducing small perturbations to activation maps (features) at various levels, we develop the capacity of the neural network to cope with such transformations. We conduct experiments on three image classification benchmarks (Tiny ImageNet, Caltech-256 and Food-101), considering two different convolutional architectures (ResNet-18 and DenseNet-121). When compared with two state-of-the-art methods, the empirical results show that our approach consistently attains the best trade-off between accuracy and mean flip rate.
Enhancement of damaged-image prediction through Cahn-Hilliard Image Inpainting
Jul 21, 2020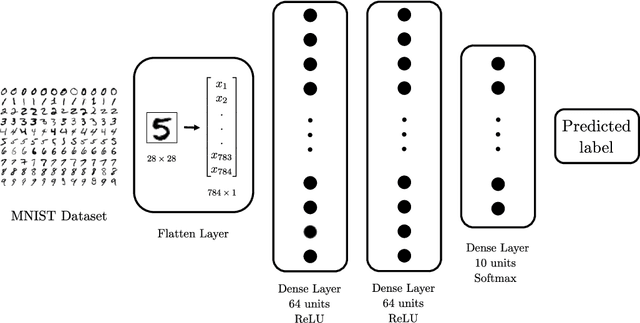
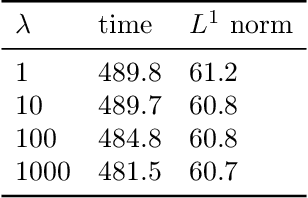
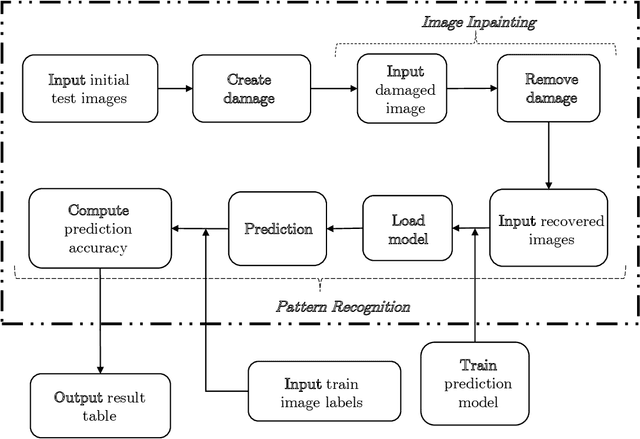

We assess the benefit of including an image inpainting filter before passing damaged images into a classification neural network. For this we employ a modified Cahn-Hilliard equation as an image inpainting filter, which is solved via a finite volume scheme with reduced computational cost and adequate properties for energy stability and boundedness. The benchmark dataset employed here is the MNIST dataset, which consists in binary images of digits. We train a neural network based of dense layers with the training set of MNIST, and subsequently we contaminate the test set with damage of different types and intensities. We then compare the prediction accuracy of the neural network with and without applying the Cahn-Hilliard filter to the damaged images test. Our results quantify the significant improvement of damaged-image prediction due to applying the Cahn-Hilliard filter, which for specific damages can increase up to 50% and is in general advantageous for low to moderate damage.
More Grounded Image Captioning by Distilling Image-Text Matching Model
Apr 01, 2020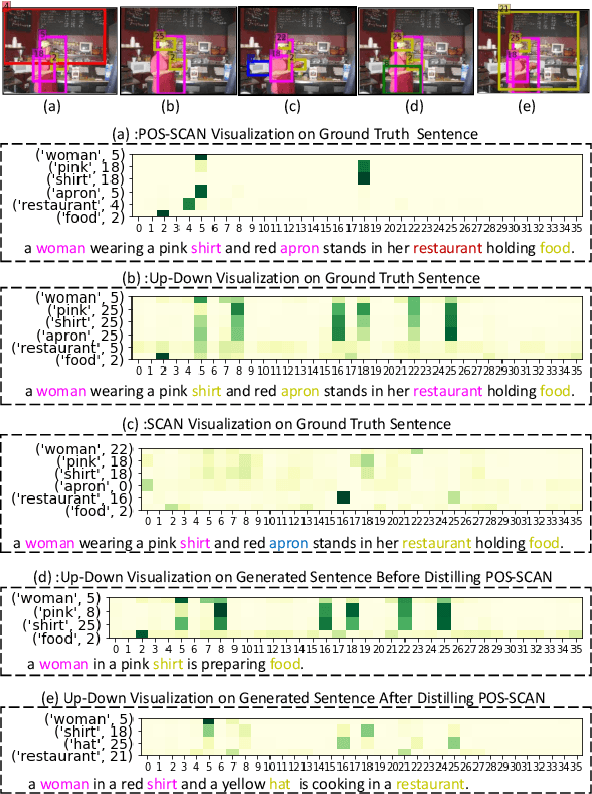

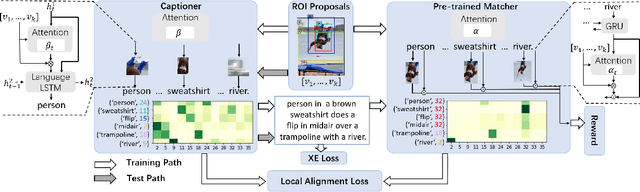
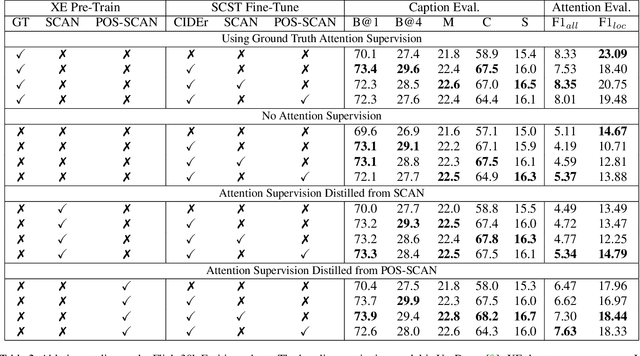
Visual attention not only improves the performance of image captioners, but also serves as a visual interpretation to qualitatively measure the caption rationality and model transparency. Specifically, we expect that a captioner can fix its attentive gaze on the correct objects while generating the corresponding words. This ability is also known as grounded image captioning. However, the grounding accuracy of existing captioners is far from satisfactory. To improve the grounding accuracy while retaining the captioning quality, it is expensive to collect the word-region alignment as strong supervision. To this end, we propose a Part-of-Speech (POS) enhanced image-text matching model (SCAN \cite{lee2018stacked}): POS-SCAN, as the effective knowledge distillation for more grounded image captioning. The benefits are two-fold: 1) given a sentence and an image, POS-SCAN can ground the objects more accurately than SCAN; 2) POS-SCAN serves as a word-region alignment regularization for the captioner's visual attention module. By showing benchmark experimental results, we demonstrate that conventional image captioners equipped with POS-SCAN can significantly improve the grounding accuracy without strong supervision. Last but not the least, we explore the indispensable Self-Critical Sequence Training (SCST) \cite{Rennie_2017_CVPR} in the context of grounded image captioning and show that the image-text matching score can serve as a reward for more grounded captioning \footnote{https://github.com/YuanEZhou/Grounded-Image-Captioning}.
Learning a Weight Map for Weakly-Supervised Localization
Nov 28, 2021
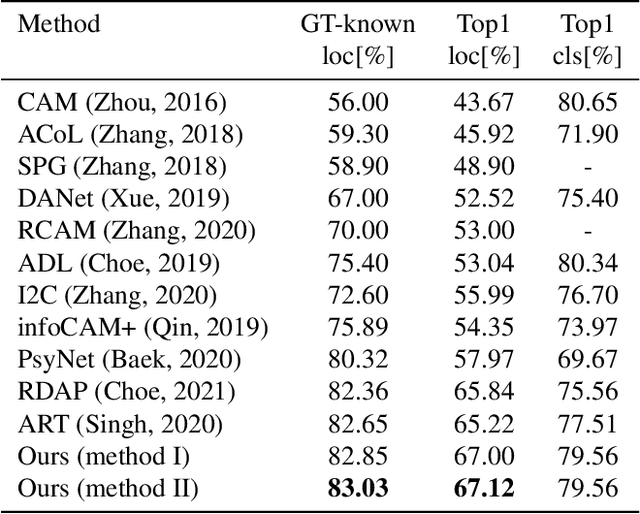
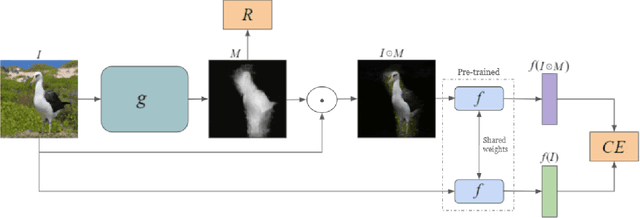
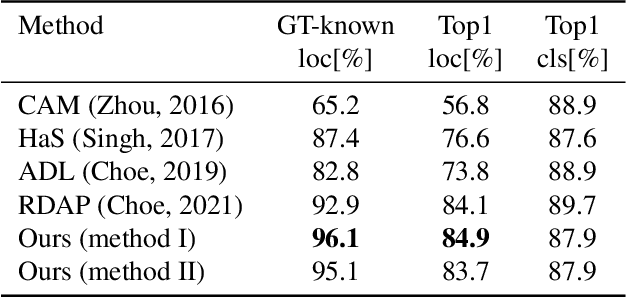
In the weakly supervised localization setting, supervision is given as an image-level label. We propose to employ an image classifier $f$ and to train a generative network $g$ that outputs, given the input image, a per-pixel weight map that indicates the location of the object within the image. Network $g$ is trained by minimizing the discrepancy between the output of the classifier $f$ on the original image and its output given the same image weighted by the output of $g$. The scheme requires a regularization term that ensures that $g$ does not provide a uniform weight, and an early stopping criterion in order to prevent $g$ from over-segmenting the image. Our results indicate that the method outperforms existing localization methods by a sizable margin on the challenging fine-grained classification datasets, as well as a generic image recognition dataset. Additionally, the obtained weight map is also state-of-the-art in weakly supervised segmentation in fine-grained categorization datasets.