 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
Apr 14, 2022
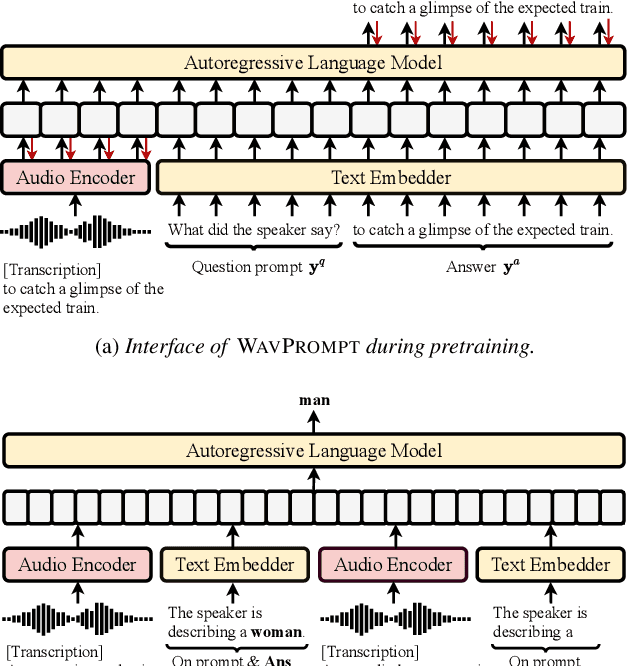
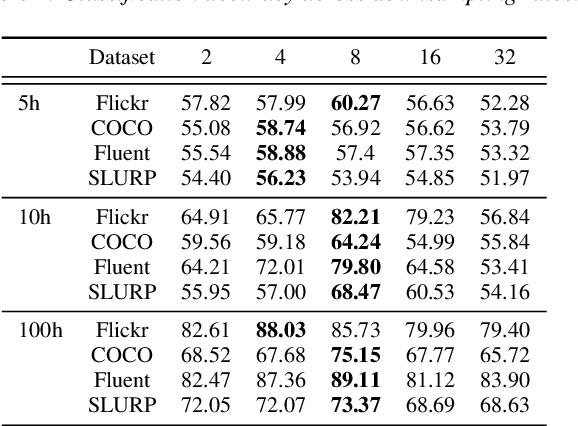

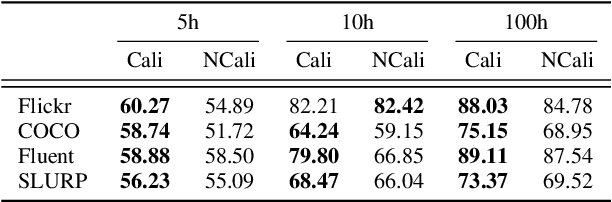
Large-scale auto-regressive language models pretrained on massive text have demonstrated their impressive ability to perform new natural language tasks with only a few text examples, without the need for fine-tuning. Recent studies further show that such a few-shot learning ability can be extended to the text-image setting by training an encoder to encode the images into embeddings functioning like the text embeddings of the language model. Interested in exploring the possibility of transferring the few-shot learning ability to the audio-text setting, we propose a novel speech understanding framework, WavPrompt, where we finetune a wav2vec model to generate a sequence of audio embeddings understood by the language model. We show that WavPrompt is a few-shot learner that can perform speech understanding tasks better than a naive text baseline. We conduct detailed ablation studies on different components and hyperparameters to empirically identify the best model configuration. In addition, we conduct a non-speech understanding experiment to show WavPrompt can extract more information than just the transcriptions. Code is available at https://github.com/Hertin/WavPrompt
TerrainMesh: Metric-Semantic Terrain Reconstruction from Aerial Images Using Joint 2D-3D Learning
Apr 23, 2022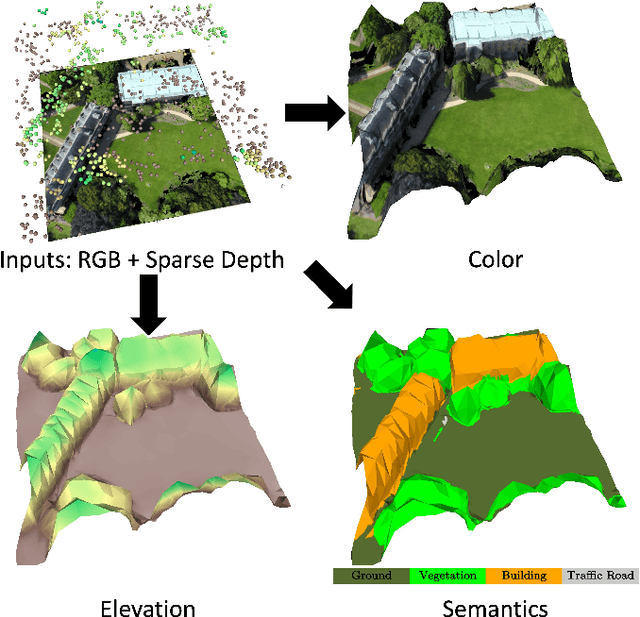

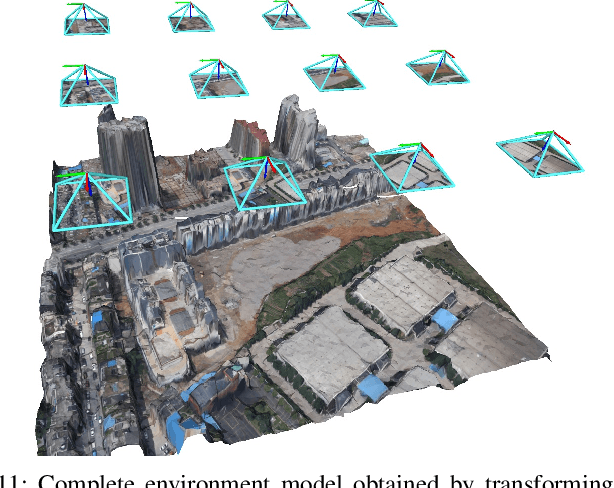
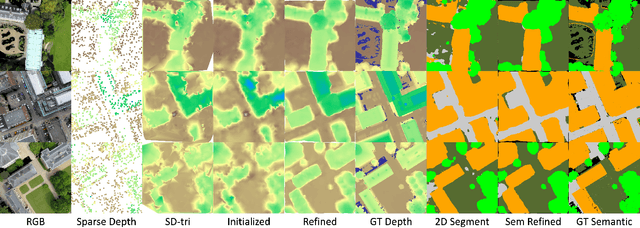
This paper considers outdoor terrain mapping using RGB images obtained from an aerial vehicle. While feature-based localization and mapping techniques deliver real-time vehicle odometry and sparse keypoint depth reconstruction, a dense model of the environment geometry and semantics (vegetation, buildings, etc.) is usually recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct a local metric-semantic mesh at each camera keyframe maintained by a visual odometry algorithm. Given the estimated camera trajectory, the local meshes can be assembled into a global environment model to capture the terrain topology and semantics during online operation. A local mesh is reconstructed using an initialization and refinement stage. In the initialization stage, we estimate the mesh vertex elevation by solving a least squares problem relating the vertex barycentric coordinates to the sparse keypoint depth measurements. In the refinement stage, we associate 2D image and semantic features with the 3D mesh vertices using camera projection and apply graph convolution to refine the mesh vertex spatial coordinates and semantic features based on joint 2D and 3D supervision. Quantitative and qualitative evaluation using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.
Attribute-guided image generation from layout
Aug 27, 2020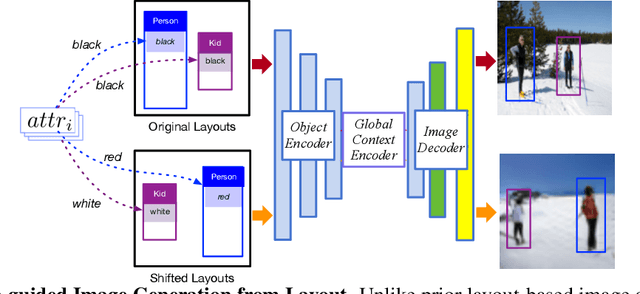
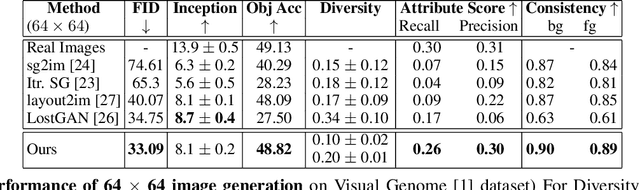
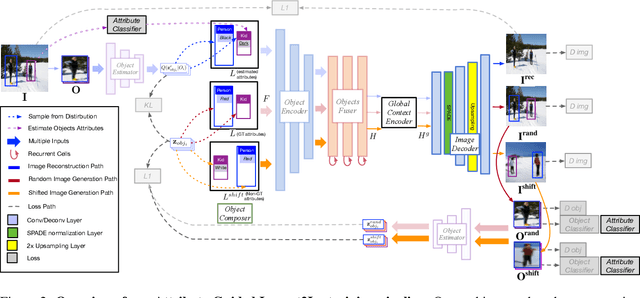

Recent approaches have achieved great success in image generation from structured inputs, e.g., semantic segmentation, scene graph or layout. Although these methods allow specification of objects and their locations at image-level, they lack the fidelity and semantic control to specify visual appearance of these objects at an instance-level. To address this limitation, we propose a new image generation method that enables instance-level attribute control. Specifically, the input to our attribute-guided generative model is a tuple that contains: (1) object bounding boxes, (2) object categories and (3) an (optional) set of attributes for each object. The output is a generated image where the requested objects are in the desired locations and have prescribed attributes. Several losses work collaboratively to encourage accurate, consistent and diverse image generation. Experiments on Visual Genome dataset demonstrate our model's capacity to control object-level attributes in generated images, and validate plausibility of disentangled object-attribute representation in the image generation from layout task. Also, the generated images from our model have higher resolution, object classification accuracy and consistency, as compared to the previous state-of-the-art.
StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Apr 30, 2021
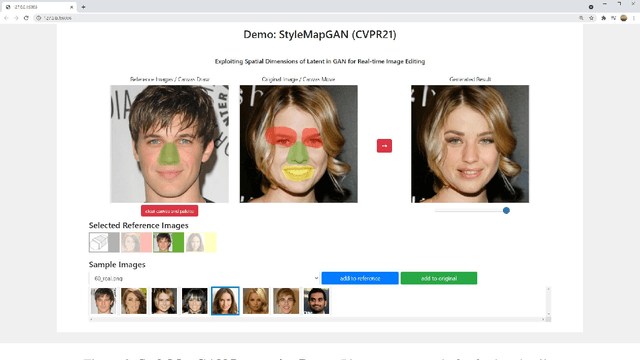
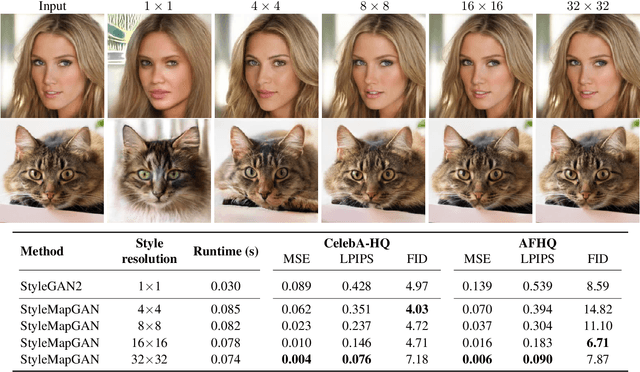
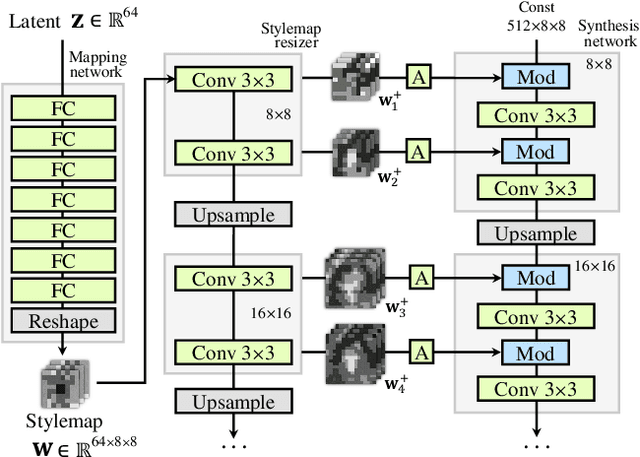
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) time-consuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/StyleMapGAN.
Reproducing BowNet: Learning Representations by Predicting Bags of Visual Words
Jan 14, 2022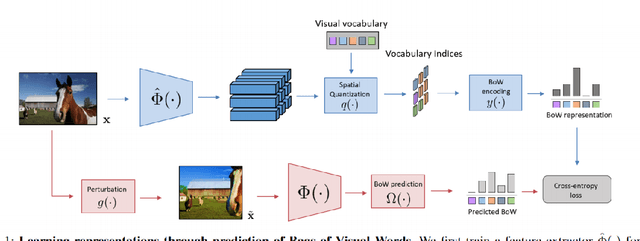
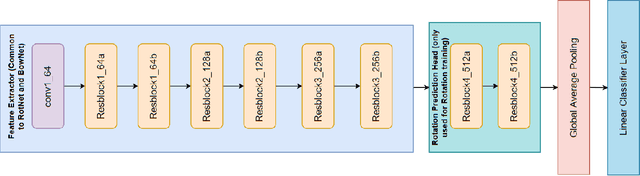
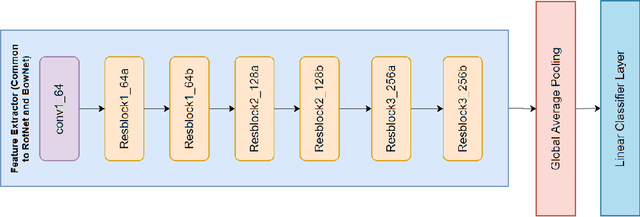
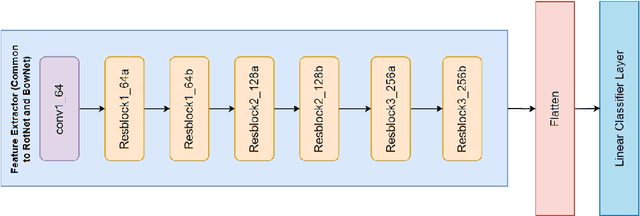
This work aims to reproduce results from the CVPR 2020 paper by Gidaris et al. Self-supervised learning (SSL) is used to learn feature representations of an image using an unlabeled dataset. This work proposes to use bag-of-words (BoW) deep feature descriptors as a self-supervised learning target to learn robust, deep representations. BowNet is trained to reconstruct the histogram of visual words (ie. the deep BoW descriptor) of a reference image when presented a perturbed version of the image as input. Thus, this method aims to learn perturbation-invariant and context-aware image features that can be useful for few-shot tasks or supervised downstream tasks. In the paper, the author describes BowNet as a network consisting of a convolutional feature extractor $\Phi(\cdot)$ and a Dense-softmax layer $\Omega(\cdot)$ trained to predict BoW features from images. After BoW training, the features of $\Phi$ are used in downstream tasks. For this challenge we were trying to build and train a network that could reproduce the CIFAR-100 accuracy improvements reported in the original paper. However, we were unsuccessful in reproducing an accuracy improvement comparable to what the authors mentioned. This could be for a variety of factors and we believe that time constraints were the primary bottleneck.
Typography-MNIST (TMNIST): an MNIST-Style Image Dataset to Categorize Glyphs and Font-Styles
Feb 12, 2022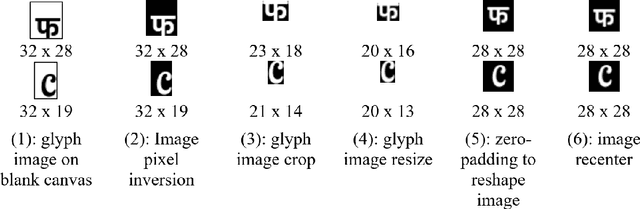
We present Typography-MNIST (TMNIST), a dataset comprising of 565,292 MNIST-style grayscale images representing 1,812 unique glyphs in varied styles of 1,355 Google-fonts. The glyph-list contains common characters from over 150 of the modern and historical language scripts with symbol sets, and each font-style represents varying subsets of the total unique glyphs. The dataset has been developed as part of the CognitiveType project which aims to develop eye-tracking tools for real-time mapping of type to cognition and to create computational tools that allow for the easy design of typefaces with cognitive properties such as readability. The dataset and scripts to generate MNIST-style images for glyphs in different font styles are freely available at https://github.com/aiskunks/CognitiveType.
Self-supervised learning unveils morphological clusters behind lung cancer types and prognosis
May 04, 2022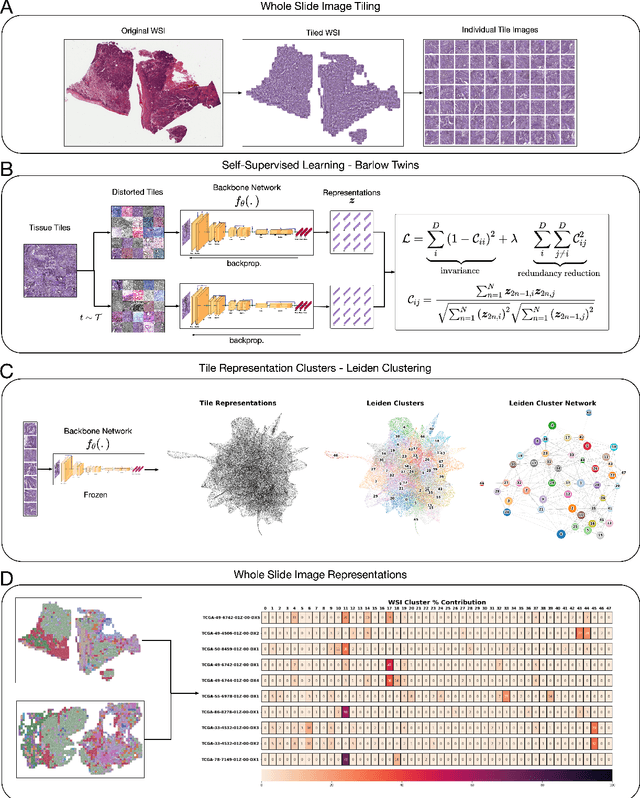
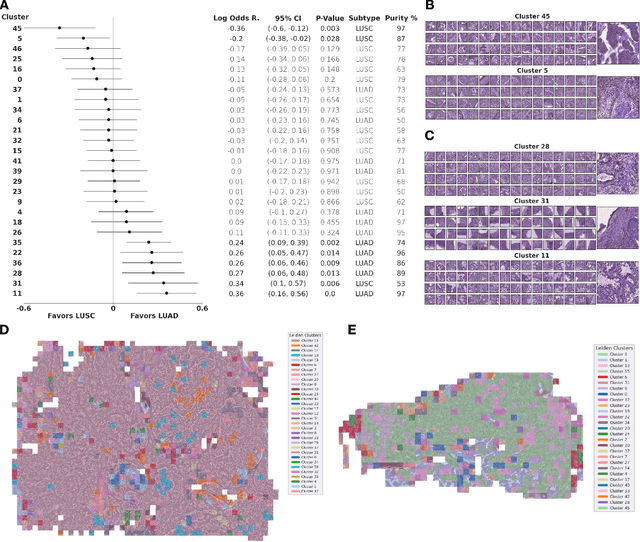
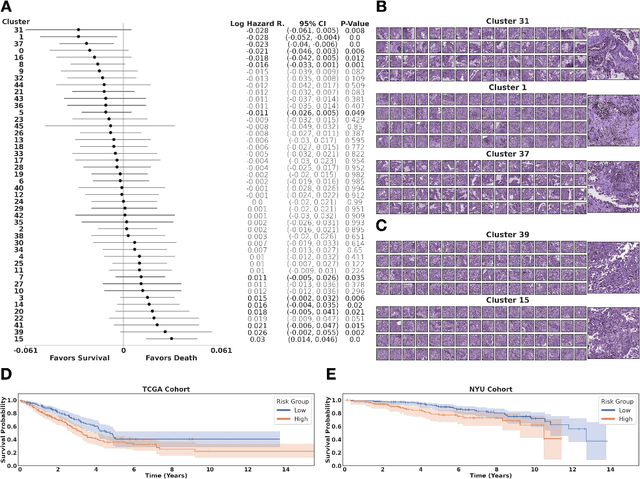
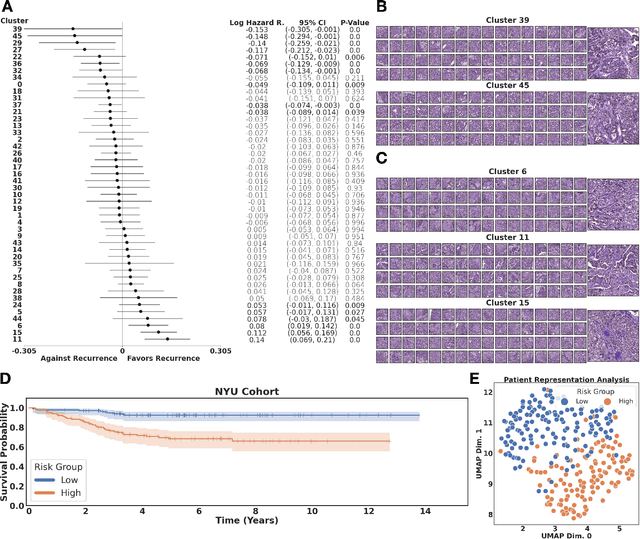
Histopathological images of tumors contain abundant information about how tumors grow and how they interact with their micro-environment. Characterizing and improving our understanding of phenotypes could reveal factors related to tumor progression and their underpinning biological processes, ultimately improving diagnosis and treatment. In recent years, the field of histological deep learning applications has seen great progress, yet most of these applications focus on a supervised approach, relating tissue and associated sample annotations. Supervised approaches have their impact limited by two factors. Firstly, high-quality labels are expensive in time and effort, which makes them not easily scalable. Secondly, these methods focus on predicting annotations from histological images, fundamentally restricting the discovery of new tissue phenotypes. These limitations emphasize the importance of using new methods that can characterize tissue by the features enclosed in the image, without pre-defined annotation or supervision. We present Phenotype Representation Learning (PRL), a methodology to extract histomorphological phenotypes through self-supervised learning and community detection. PRL creates phenotype clusters by identifying tissue patterns that share common morphological and cellular features, allowing to describe whole slide images through compositional representations of cluster contributions. We used this framework to analyze histopathology slides of LUAD and LUSC lung cancer subtypes from TCGA and NYU cohorts. We show that PRL achieves a robust lung subtype prediction providing statistically relevant phenotypes for each lung subtype. We further demonstrate the significance of these phenotypes in lung adenocarcinoma overall and recurrence free survival, relating clusters with patient outcomes, cell types, grown patterns, and omic-based immune signatures.
Image Inpainting with Learnable Feature Imputation
Nov 02, 2020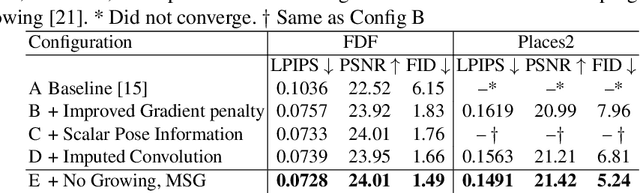
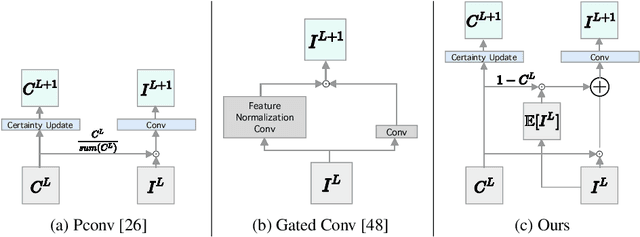

A regular convolution layer applying a filter in the same way over known and unknown areas causes visual artifacts in the inpainted image. Several studies address this issue with feature re-normalization on the output of the convolution. However, these models use a significant amount of learnable parameters for feature re-normalization, or assume a binary representation of the certainty of an output. We propose (layer-wise) feature imputation of the missing input values to a convolution. In contrast to learned feature re-normalization, our method is efficient and introduces a minimal number of parameters. Furthermore, we propose a revised gradient penalty for image inpainting, and a novel GAN architecture trained exclusively on adversarial loss. Our quantitative evaluation on the FDF dataset reflects that our revised gradient penalty and alternative convolution improves generated image quality significantly. We present comparisons on CelebA-HQ and Places2 to current state-of-the-art to validate our model.
Self Supervised Lesion Recognition For Breast Ultrasound Diagnosis
Apr 18, 2022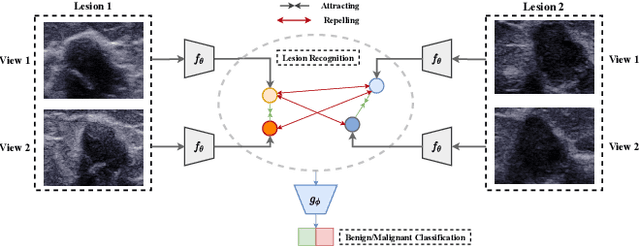


Previous deep learning based Computer Aided Diagnosis (CAD) system treats multiple views of the same lesion as independent images. Since an ultrasound image only describes a partial 2D projection of a 3D lesion, such paradigm ignores the semantic relationship between different views of a lesion, which is inconsistent with the traditional diagnosis where sonographers analyze a lesion from at least two views. In this paper, we propose a multi-task framework that complements Benign/Malignant classification task with lesion recognition (LR) which helps leveraging relationship among multiple views of a single lesion to learn a complete representation of the lesion. To be specific, LR task employs contrastive learning to encourage representation that pulls multiple views of the same lesion and repels those of different lesions. The task therefore facilitates a representation that is not only invariant to the view change of the lesion, but also capturing fine-grained features to distinguish between different lesions. Experiments show that the proposed multi-task framework boosts the performance of Benign/Malignant classification as two sub-tasks complement each other and enhance the learned representation of ultrasound images.
Self-Training Vision Language BERTs with a Unified Conditional Model
Jan 06, 2022
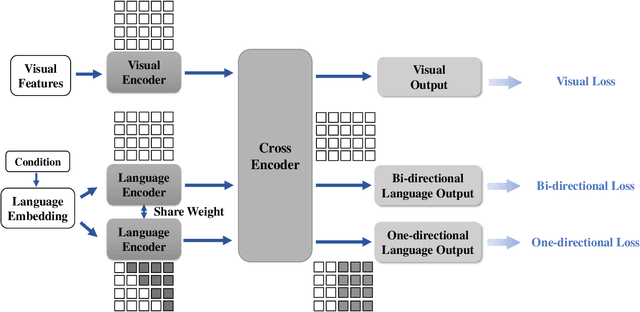
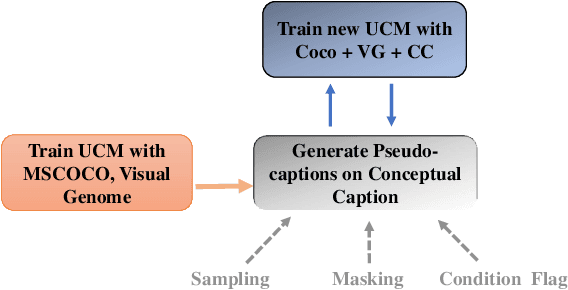

Natural language BERTs are trained with language corpus in a self-supervised manner. Unlike natural language BERTs, vision language BERTs need paired data to train, which restricts the scale of VL-BERT pretraining. We propose a self-training approach that allows training VL-BERTs from unlabeled image data. The proposed method starts with our unified conditional model -- a vision language BERT model that can perform zero-shot conditional generation. Given different conditions, the unified conditional model can generate captions, dense captions, and even questions. We use the labeled image data to train a teacher model and use the trained model to generate pseudo captions on unlabeled image data. We then combine the labeled data and pseudo labeled data to train a student model. The process is iterated by putting the student model as a new teacher. By using the proposed self-training approach and only 300k unlabeled extra data, we are able to get competitive or even better performances compared to the models of similar model size trained with 3 million extra image data.