 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Underwater Image Color Correction by Complementary Adaptation
Oct 21, 2020

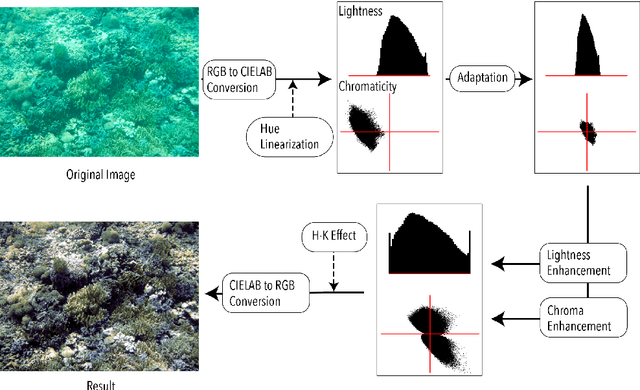
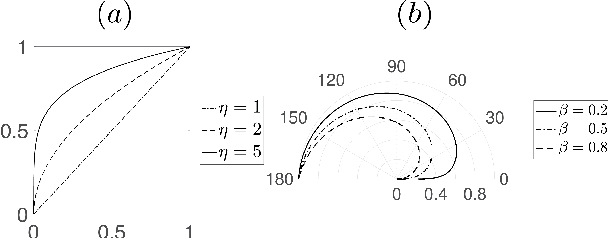

In this paper, we propose a novel approach for underwater image color correction based on a Tikhonov type optimization model in the CIELAB color space. It presents a new variational interpretation of the complementary adaptation theory in psychophysics, which establishes the connection between colorimetric notions and color constancy of the human visual system (HVS). Understood as a long-term adaptive process, our method effectively removes the underwater color cast and yields a balanced color distribution. For visualization purposes, we enhance the image contrast by properly rescaling both lightness and chroma without trespassing the CIELAB gamut. The magnitude of the enhancement is hue-selective and image-based, thus our method is robust for different underwater imaging environments. To improve the uniformity of CIELAB, we include an approximate hue-linearization as the pre-processing and an inverse transform of the Helmholtz-Kohlrausch effect as the post-processing. We analyze and validate the proposed model by various numerical experiments. Based on image quality metrics designed for underwater conditions, we compare with some state-of-art approaches to show that the proposed method has consistently superior performances.
Virtual Coil Augmentation Technology for MRI via Deep Learning
Jan 19, 2022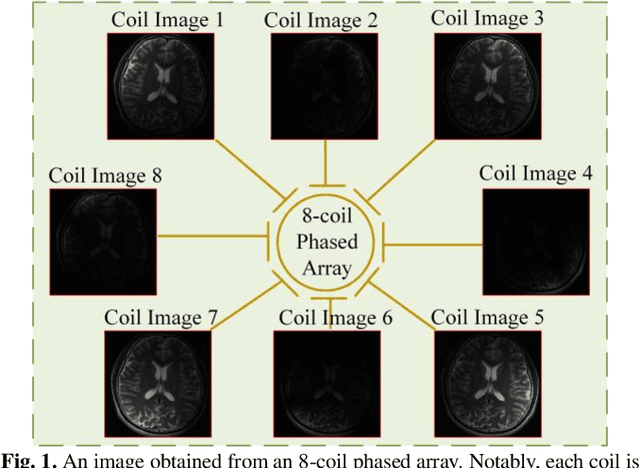
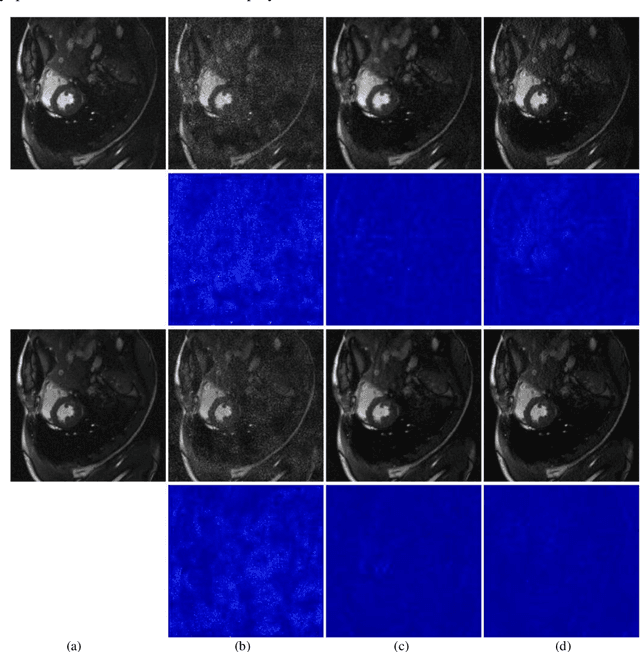
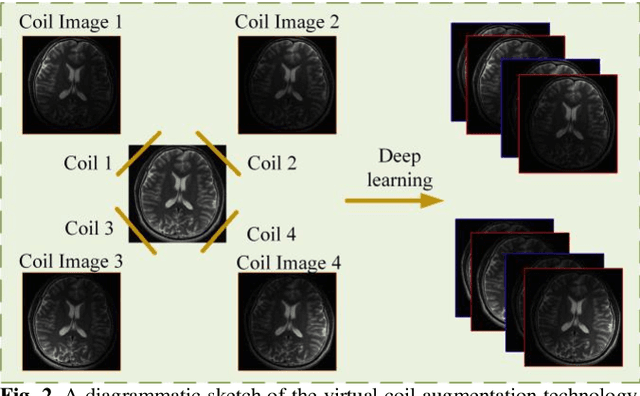
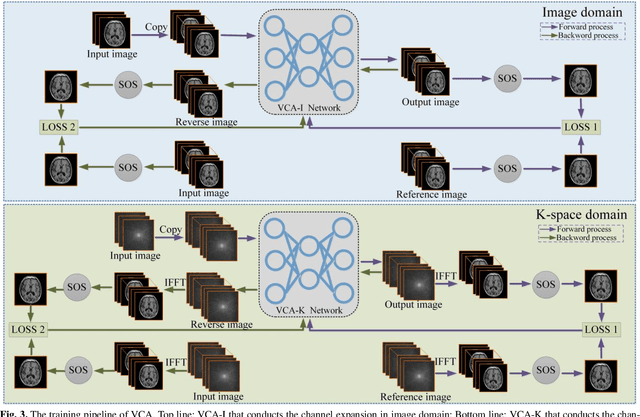
Magnetic resonance imaging (MRI) is a widely used medical imaging modality. However, due to the limitations in hardware, scan time, and throughput, it is often clinically challenging to obtain high-quality MR images. In this article, we propose a method of using artificial intelligence to expand the channel to achieve the effect of increasing the virtual coil. The main feature of our work is utilizing dummy variable technology to expand the channel in both the image and k-space domains. The high-dimensional information formed by channel expansion is used as the prior information of parallel imaging to improve the reconstruction effect of parallel imaging. Two features are introduced, namely variable enhancement and sum of squares (SOS) objective function. Variable argumentation provides the network with more high-dimensional prior information, which is helpful for the network to extract the deep feature in-formation of the image. The SOS objective function is employed to solve the problem that k-space data is difficult to train while speeding up the convergence speed. Ablation studies and experimental results demonstrate that our method achieves significantly higher image reconstruction performance than current state-of-the-art techniques.
Editorial: Introduction to the Issue on Deep Learning for Image/Video Restoration and Compression
Feb 09, 2021Recent works have shown that learned models can achieve significant performance gains, especially in terms of perceptual quality measures, over traditional methods. Hence, the state of the art in image restoration and compression is getting redefined. This special issue covers the state of the art in learned image/video restoration and compression to promote further progress in innovative architectures and training methods for effective and efficient networks for image/video restoration and compression.
Unseen Object Instance Segmentation with Fully Test-time RGB-D Embeddings Adaptation
Apr 21, 2022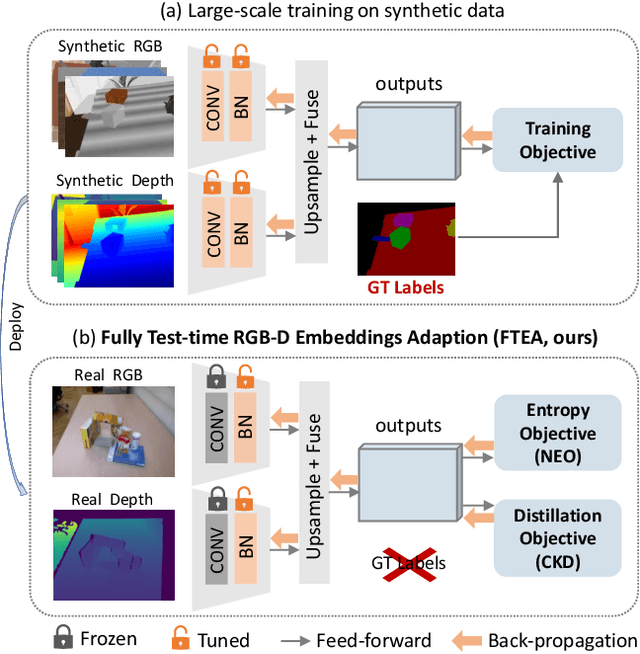
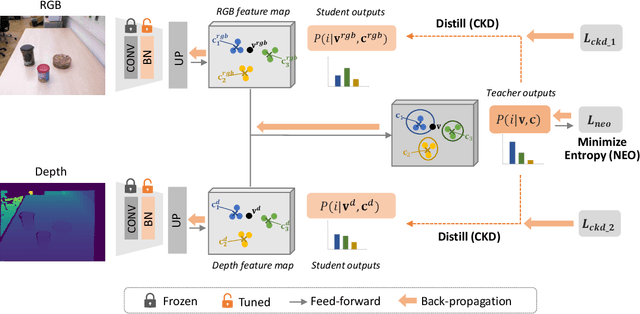
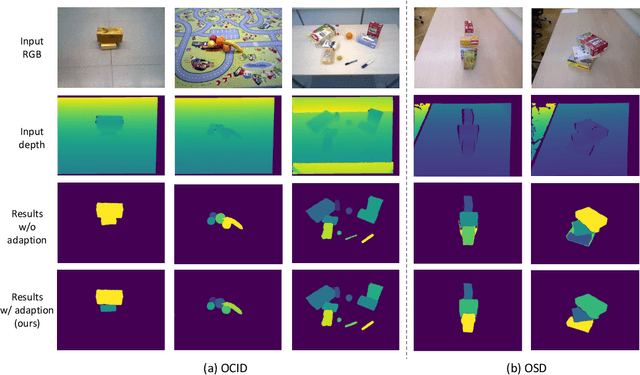
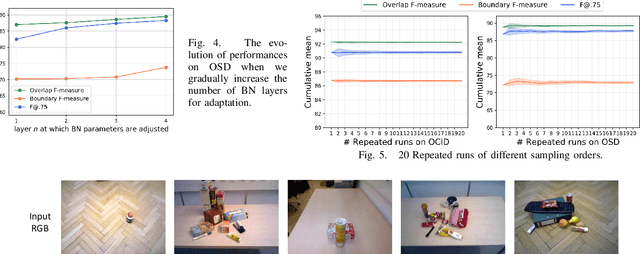
Segmenting unseen objects is a crucial ability for the robot since it may encounter new environments during the operation. Recently, a popular solution is leveraging RGB-D features of large-scale synthetic data and directly applying the model to unseen real-world scenarios. However, even though depth data have fair generalization ability, the domain shift due to the Sim2Real gap is inevitable, which presents a key challenge to the unseen object instance segmentation (UOIS) model. To tackle this problem, we re-emphasize the adaptation process across Sim2Real domains in this paper. Specifically, we propose a framework to conduct the Fully Test-time RGB-D Embeddings Adaptation (FTEA) based on parameters of the BatchNorm layer. To construct the learning objective for test-time back-propagation, we propose a novel non-parametric entropy objective that can be implemented without explicit classification layers. Moreover, we design a cross-modality knowledge distillation module to encourage the information transfer during test time. The proposed method can be efficiently conducted with test-time images, without requiring annotations or revisiting the large-scale synthetic training data. Besides significant time savings, the proposed method consistently improves segmentation results on both overlap and boundary metrics, achieving state-of-the-art performances on two real-world RGB-D image datasets. We hope our work could draw attention to the test-time adaptation and reveal a promising direction for robot perception in unseen environments.
GroupGazer: A Tool to Compute the Gaze per Participant in Groups with integrated Calibration to Map the Gaze Online to a Screen or Beamer Projection
Jan 19, 2022

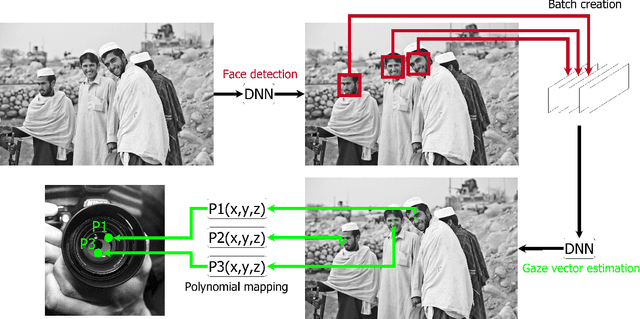

In this paper we present GroupGaze. It is a tool that can be used to calculate the gaze direction and the gaze position of whole groups. GroupGazer calculates the gaze direction of every single person in the image and allows to map these gaze vectors to a projection like a projector. In addition to the person-specific gaze direction, the person affiliation of each gaze vector is stored based on the position in the image. Also, it is possible to save the group attention after a calibration. The software is free to use and requires a simple webcam as well as an NVIDIA GPU and the operating system Windows or Linux.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022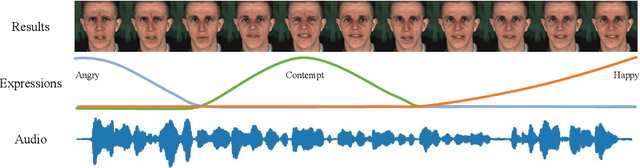
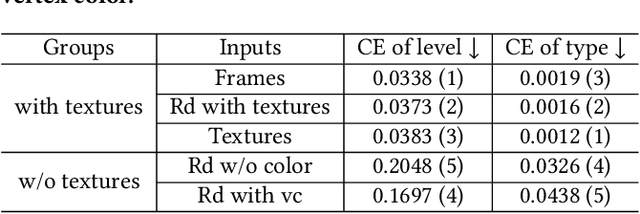
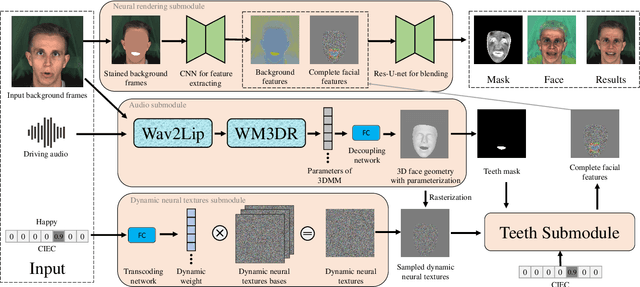
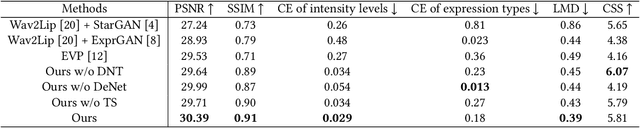
Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.
MDMMT-2: Multidomain Multimodal Transformer for Video Retrieval, One More Step Towards Generalization
Mar 14, 2022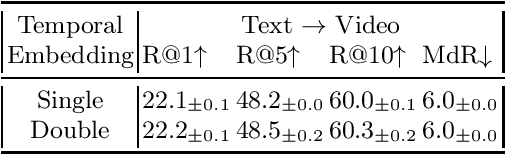
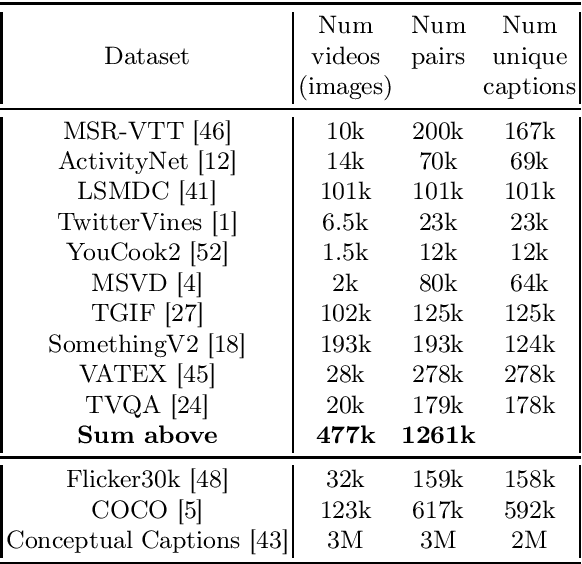


In this work we present a new State-of-The-Art on the text-to-video retrieval task on MSR-VTT, LSMDC, MSVD, YouCook2 and TGIF obtained by a single model. Three different data sources are combined: weakly-supervised videos, crowd-labeled text-image pairs and text-video pairs. A careful analysis of available pre-trained networks helps to choose the best prior-knowledge ones. We introduce three-stage training procedure that provides high transfer knowledge efficiency and allows to use noisy datasets during training without prior knowledge degradation. Additionally, double positional encoding is used for better fusion of different modalities and a simple method for non-square inputs processing is suggested.
Dual Transfer Learning for Event-based End-task Prediction via Pluggable Event to Image Translation
Sep 04, 2021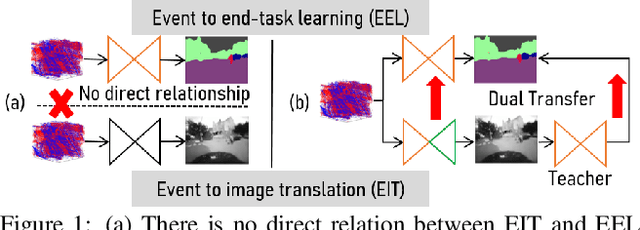



Event cameras are novel sensors that perceive the per-pixel intensity changes and output asynchronous event streams with high dynamic range and less motion blur. It has been shown that events alone can be used for end-task learning, \eg, semantic segmentation, based on encoder-decoder-like networks. However, as events are sparse and mostly reflect edge information, it is difficult to recover original details merely relying on the decoder. Moreover, most methods resort to pixel-wise loss alone for supervision, which might be insufficient to fully exploit the visual details from sparse events, thus leading to less optimal performance. In this paper, we propose a simple yet flexible two-stream framework named Dual Transfer Learning (DTL) to effectively enhance the performance on the end-tasks without adding extra inference cost. The proposed approach consists of three parts: event to end-task learning (EEL) branch, event to image translation (EIT) branch, and transfer learning (TL) module that simultaneously explores the feature-level affinity information and pixel-level knowledge from the EIT branch to improve the EEL branch. This simple yet novel method leads to strong representation learning from events and is evidenced by the significant performance boost on the end-tasks such as semantic segmentation and depth estimation.
Strategies in JPEG compression using Convolutional Neural Network (CNN)
Dec 06, 2021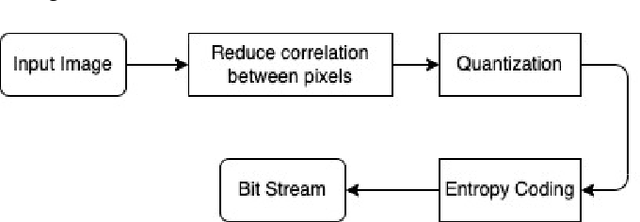
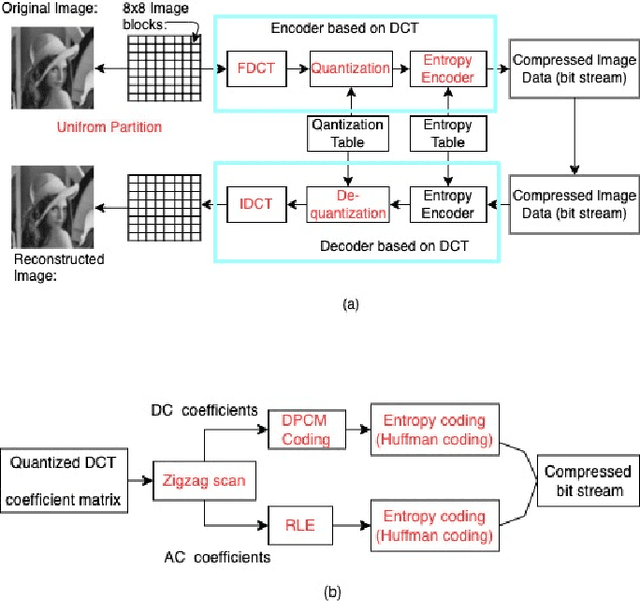
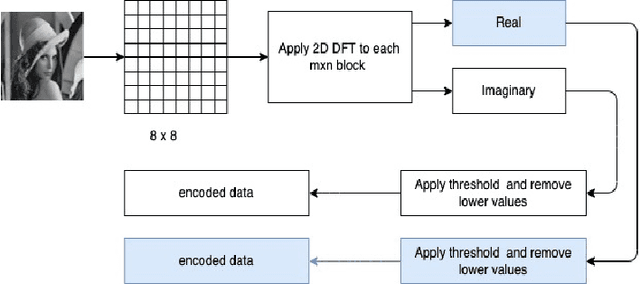

Interests in digital image processing are growing enormously in recent decades. As a result, different data compression techniques have been proposed which are concerned mostly with the minimization of information used for the representation of images. With the advances of deep neural networks, image compression can be achieved to a higher degree. This paper describes an overview of JPEG Compression, Discrete Fourier Transform (DFT), Convolutional Neural Network (CNN), quality metrics to measure the performance of image compression and discuss the advancement of deep learning for image compression mostly focused on JPEG, and suggests that adaptation of model improve the compression.
Generative and Discriminative Learning for Distorted Image Restoration
Nov 12, 2020
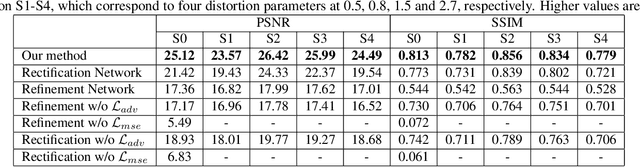
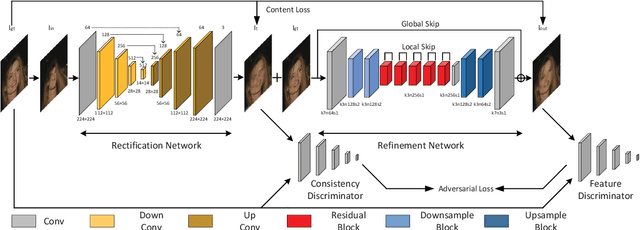

Liquify is a common technique for image editing, which can be used for image distortion. Due to the uncertainty in the distortion variation, restoring distorted images caused by liquify filter is a challenging task. To edit images in an efficient way, distorted images are expected to be restored automatically. This paper aims at the distorted image restoration, which is characterized by seeking the appropriate warping and completion of a distorted image. Existing methods focus on the hardware assistance or the geometric principle to solve the specific regular deformation caused by natural phenomena, but they cannot handle the irregularity and uncertainty of artificial distortion in this task. To address this issue, we propose a novel generative and discriminative learning method based on deep neural networks, which can learn various reconstruction mappings and represent complex and high-dimensional data. This method decomposes the task into a rectification stage and a refinement stage. The first stage generative network predicts the mapping from the distorted images to the rectified ones. The second stage generative network then further optimizes the perceptual quality. Since there is no available dataset or benchmark to explore this task, we create a Distorted Face Dataset (DFD) by forward distortion mapping based on CelebA dataset. Extensive experimental evaluation on the proposed benchmark and the application demonstrates that our method is an effective way for distorted image restoration.