 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Video Demoireing with Relation-Based Temporal Consistency
Apr 06, 2022

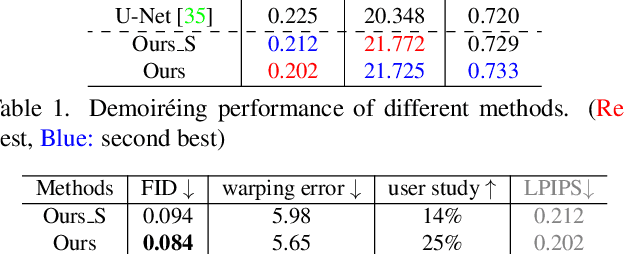

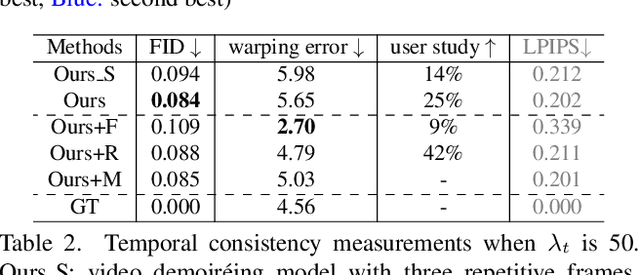
Moire patterns, appearing as color distortions, severely degrade image and video qualities when filming a screen with digital cameras. Considering the increasing demands for capturing videos, we study how to remove such undesirable moire patterns in videos, namely video demoireing. To this end, we introduce the first hand-held video demoireing dataset with a dedicated data collection pipeline to ensure spatial and temporal alignments of captured data. Further, a baseline video demoireing model with implicit feature space alignment and selective feature aggregation is developed to leverage complementary information from nearby frames to improve frame-level video demoireing. More importantly, we propose a relation-based temporal consistency loss to encourage the model to learn temporal consistency priors directly from ground-truth reference videos, which facilitates producing temporally consistent predictions and effectively maintains frame-level qualities. Extensive experiments manifest the superiority of our model. Code is available at \url{https://daipengwa.github.io/VDmoire_ProjectPage/}.
Koopman-based spectral clustering of directed and time-evolving graphs
Apr 06, 2022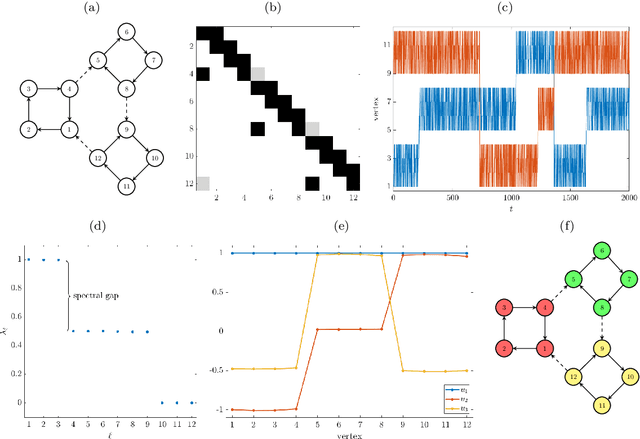
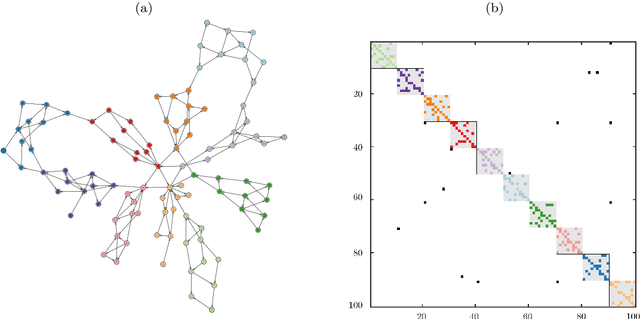
While spectral clustering algorithms for undirected graphs are well established and have been successfully applied to unsupervised machine learning problems ranging from image segmentation and genome sequencing to signal processing and social network analysis, clustering directed graphs remains notoriously difficult. Two of the main challenges are that the eigenvalues and eigenvectors of graph Laplacians associated with directed graphs are in general complex-valued and that there is no universally accepted definition of clusters in directed graphs. We first exploit relationships between the graph Laplacian and transfer operators and in particular between clusters in undirected graphs and metastable sets in stochastic dynamical systems and then use a generalization of the notion of metastability to derive clustering algorithms for directed and time-evolving graphs. The resulting clusters can be interpreted as coherent sets, which play an important role in the analysis of transport and mixing processes in fluid flows.
Detecting out-of-context objects using contextual cues
Feb 11, 2022



This paper presents an approach to detect out-of-context (OOC) objects in an image. Given an image with a set of objects, our goal is to determine if an object is inconsistent with the scene context and detect the OOC object with a bounding box. In this work, we consider commonly explored contextual relations such as co-occurrence relations, the relative size of an object with respect to other objects, and the position of the object in the scene. We posit that contextual cues are useful to determine object labels for in-context objects and inconsistent context cues are detrimental to determining object labels for out-of-context objects. To realize this hypothesis, we propose a graph contextual reasoning network (GCRN) to detect OOC objects. GCRN consists of two separate graphs to predict object labels based on the contextual cues in the image: 1) a representation graph to learn object features based on the neighboring objects and 2) a context graph to explicitly capture contextual cues from the neighboring objects. GCRN explicitly captures the contextual cues to improve the detection of in-context objects and identify objects that violate contextual relations. In order to evaluate our approach, we create a large-scale dataset by adding OOC object instances to the COCO images. We also evaluate on recent OCD benchmark. Our results show that GCRN outperforms competitive baselines in detecting OOC objects and correctly detecting in-context objects.
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
Mar 31, 2022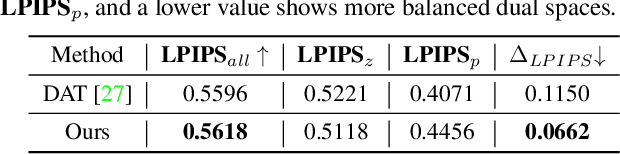
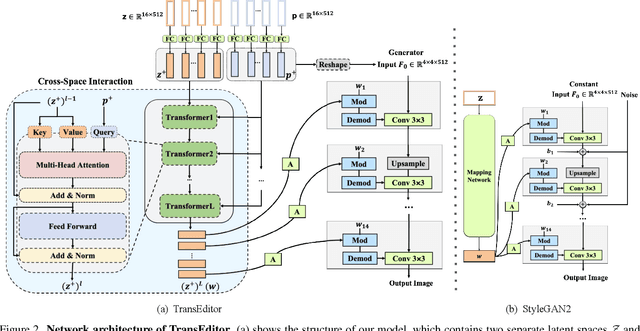

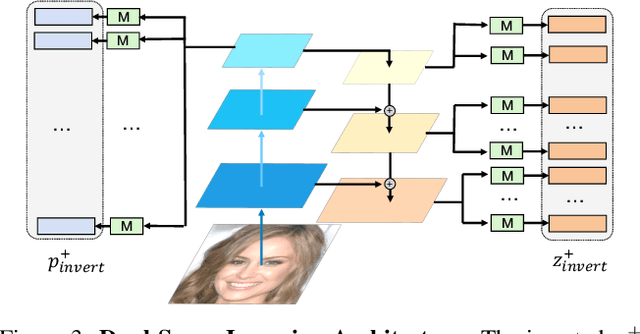
Recent advances like StyleGAN have promoted the growth of controllable facial editing. To address its core challenge of attribute decoupling in a single latent space, attempts have been made to adopt dual-space GAN for better disentanglement of style and content representations. Nonetheless, these methods are still incompetent to obtain plausible editing results with high controllability, especially for complicated attributes. In this study, we highlight the importance of interaction in a dual-space GAN for more controllable editing. We propose TransEditor, a novel Transformer-based framework to enhance such interaction. Besides, we develop a new dual-space editing and inversion strategy to provide additional editing flexibility. Extensive experiments demonstrate the superiority of the proposed framework in image quality and editing capability, suggesting the effectiveness of TransEditor for highly controllable facial editing.
NUQ: A Noise Metric for Diffusion MRI via Uncertainty Discrepancy Quantification
Mar 04, 2022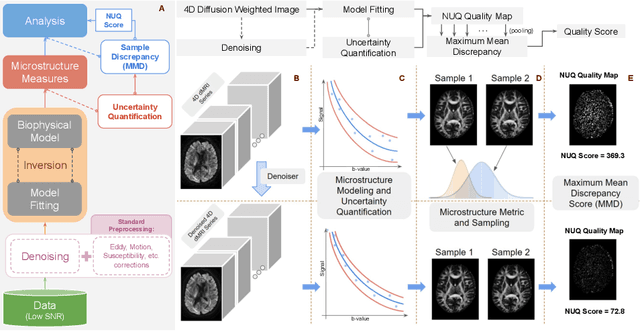
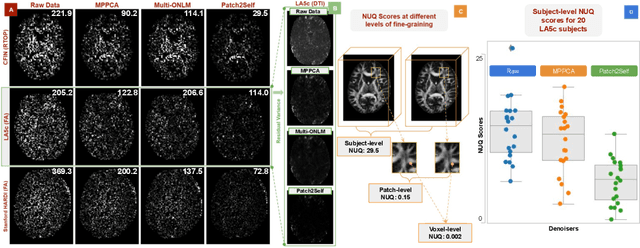
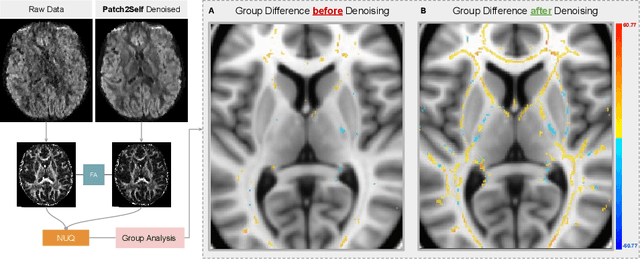
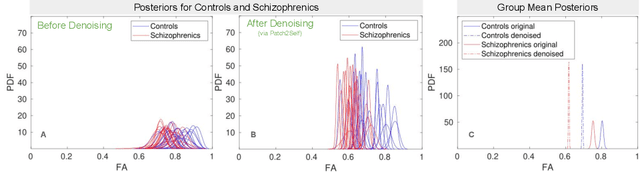
Diffusion MRI (dMRI) is the only non-invasive technique sensitive to tissue micro-architecture, which can, in turn, be used to reconstruct tissue microstructure and white matter pathways. The accuracy of such tasks is hampered by the low signal-to-noise ratio in dMRI. Today, the noise is characterized mainly by visual inspection of residual maps and estimated standard deviation. However, it is hard to estimate the impact of noise on downstream tasks based only on such qualitative assessments. To address this issue, we introduce a novel metric, Noise Uncertainty Quantification (NUQ), for quantitative image quality analysis in the absence of a ground truth reference image. NUQ uses a recent Bayesian formulation of dMRI models to estimate the uncertainty of microstructural measures. Specifically, NUQ uses the maximum mean discrepancy metric to compute a pooled quality score by comparing samples drawn from the posterior distribution of the microstructure measures. We show that NUQ allows a fine-grained analysis of noise, capturing details that are visually imperceptible. We perform qualitative and quantitative comparisons on real datasets, showing that NUQ generates consistent scores across different denoisers and acquisitions. Lastly, by using NUQ on a cohort of schizophrenics and controls, we quantify the substantial impact of denoising on group differences.
Simulation-Driven Training of Vision Transformers Enabling Metal Segmentation in X-Ray Images
Mar 17, 2022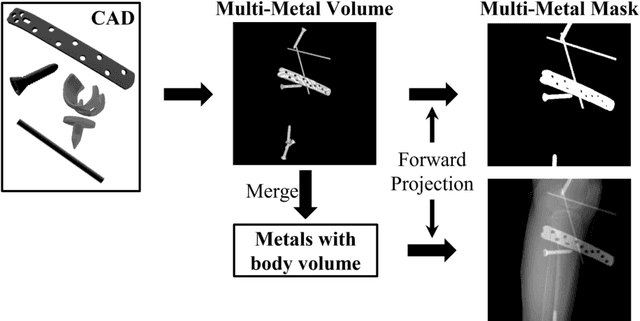
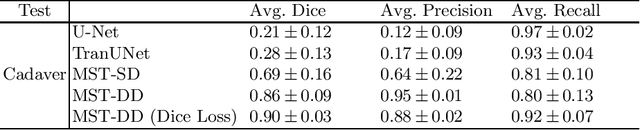
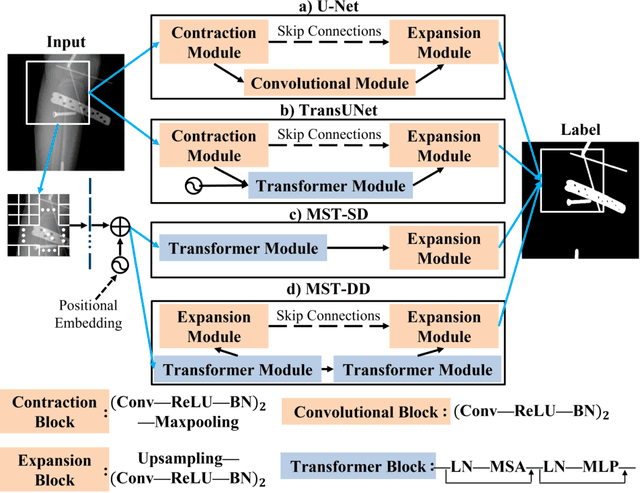
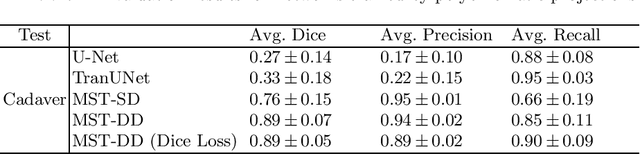
In several image acquisition and processing steps of X-ray radiography, knowledge of the existence of metal implants and their exact position is highly beneficial (e.g. dose regulation, image contrast adjustment). Another application which would benefit from an accurate metal segmentation is cone beam computed tomography (CBCT) which is based on 2D X-ray projections. Due to the high attenuation of metals, severe artifacts occur in the 3D X-ray acquisitions. The metal segmentation in CBCT projections usually serves as a prerequisite for metal artifact avoidance and reduction algorithms. Since the generation of high quality clinical training is a constant challenge, this study proposes to generate simulated X-ray images based on CT data sets combined with self-designed computer aided design (CAD) implants and make use of convolutional neural network (CNN) and vision transformer (ViT) for metal segmentation. Model test is performed on accurately labeled X-ray test datasets obtained from specimen scans. The CNN encoder-based network like U-Net has limited performance on cadaver test data with an average dice score below 0.30, while the metal segmentation transformer with dual decoder (MST-DD) shows high robustness and generalization on the segmentation task, with an average dice score of 0.90. Our study indicates that the CAD model-based data generation has high flexibility and could be a way to overcome the problem of shortage in clinical data sampling and labelling. Furthermore, the MST-DD approach generates a more reliable neural network in case of training on simulated data.
Fitting an immersed submanifold to data via Sussmann's orbit theorem
Apr 03, 2022This paper describes an approach for fitting an immersed submanifold of a finite-dimensional Euclidean space to random samples. The reconstruction mapping from the ambient space to the desired submanifold is implemented as a composition of an encoder that maps each point to a tuple of (positive or negative) times and a decoder given by a composition of flows along finitely many vector fields starting from a fixed initial point. The encoder supplies the times for the flows. The encoder-decoder map is obtained by empirical risk minimization, and a high-probability bound is given on the excess risk relative to the minimum expected reconstruction error over a given class of encoder-decoder maps. The proposed approach makes fundamental use of Sussmann's orbit theorem, which guarantees that the image of the reconstruction map is indeed contained in an immersed submanifold.
Quantum Compressive Sensing: Mathematical Machinery, Quantum Algorithms, and Quantum Circuitry
Apr 27, 2022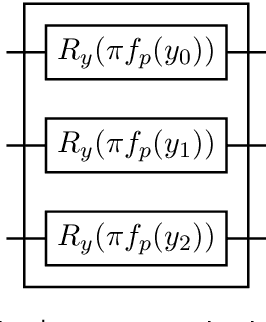
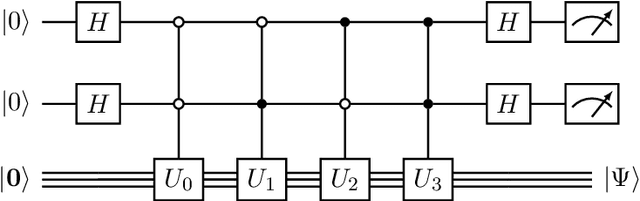
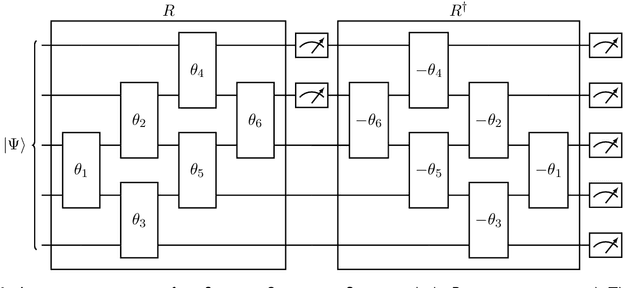
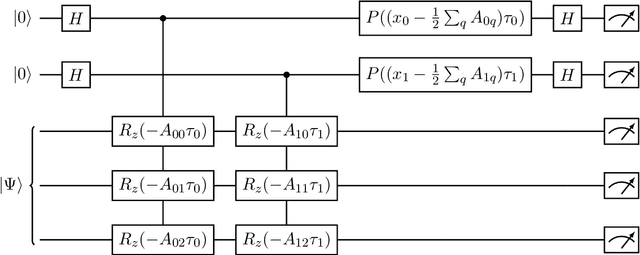
Compressive sensing is a sensing protocol that facilitates reconstruction of large signals from relatively few measurements by exploiting known structures of signals of interest, typically manifested as signal sparsity. Compressive sensing's vast repertoire of applications in areas such as communications and image reconstruction stems from the traditional approach of utilizing non-linear optimization to exploit the sparsity assumption by selecting the lowest-weight (i.e. maximum sparsity) signal consistent with all acquired measurements. Recent efforts in the literature consider instead a data-driven approach, training tensor networks to learn the structure of signals of interest. The trained tensor network is updated to "project" its state onto one consistent with the measurements taken, and is then sampled site by site to "guess" the original signal. In this paper, we take advantage of this computing protocol by formulating an alternative "quantum" protocol, in which the state of the tensor network is a quantum state over a set of entangled qubits. Accordingly, we present the associated algorithms and quantum circuits required to implement the training, projection, and sampling steps on a quantum computer. We supplement our theoretical results by simulating the proposed circuits with a small, qualitative model of LIDAR imaging of earth forests. Our results indicate that a quantum, data-driven approach to compressive sensing, may have significant promise as quantum technology continues to make new leaps.
Deep Unfolded Recovery of Sub-Nyquist Sampled Ultrasound Image
Mar 01, 2021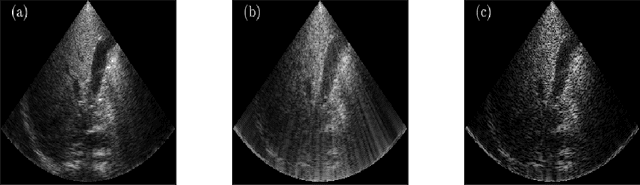
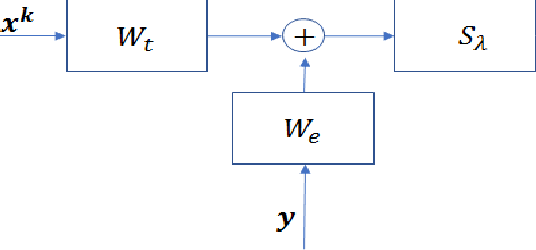
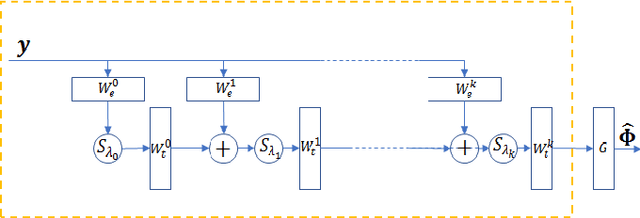
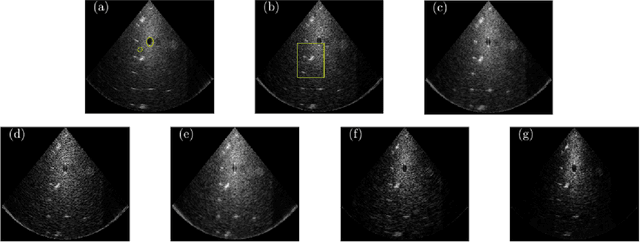
The most common technique for generating B-mode ultrasound (US) images is delay and sum (DAS) beamforming, where the signals received at the transducer array are sampled before an appropriate delay is applied. This necessitates sampling rates exceeding the Nyquist rate and the use of a large number of antenna elements to ensure sufficient image quality. Recently we proposed methods to reduce the sampling rate and the array size relying on image recovery using iterative algorithms, based on compressed sensing (CS) and the finite rate of innovation (FRI) frameworks. Iterative algorithms typically require a large number of iterations, making them difficult to use in real-time. Here, we propose a reconstruction method from sub-Nyquist samples in the time and spatial domain, that is based on unfolding the ISTA algorithm, resulting in an efficient and interpretable deep network. The inputs to our network are the subsampled beamformed signals after summation and delay in the frequency domain, requiring only a subset of the US signal to be stored for recovery. Our method allows reducing the number of array elements, sampling rate, and computational time while ensuring high quality imaging performance. Using \emph{in vivo} data we demonstrate that the proposed method yields high-quality images while reducing the data volume traditionally used up to 36 times. In terms of image resolution and contrast, our technique outperforms previously suggested methods as well as DAS and minimum-variance (MV) beamforming, paving the way to real-time applicable recovery methods.
Depth-Aware Generative Adversarial Network for Talking Head Video Generation
Mar 13, 2022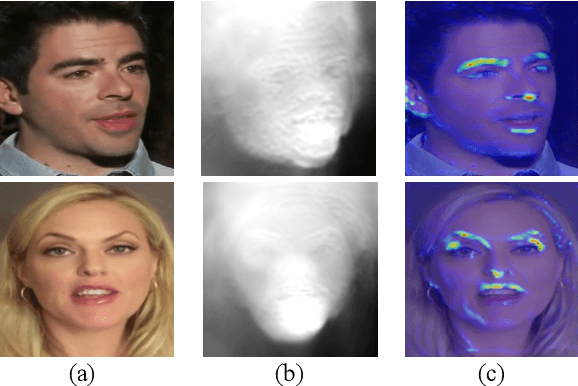
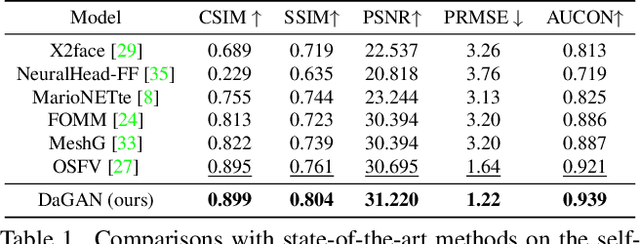
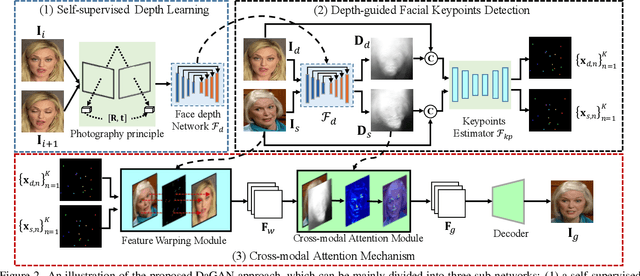
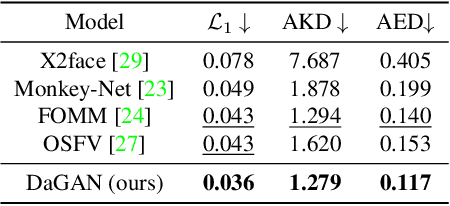
Talking head video generation aims to produce a synthetic human face video that contains the identity and pose information respectively from a given source image and a driving video.Existing works for this task heavily rely on 2D representations (e.g. appearance and motion) learned from the input images. However, dense 3D facial geometry (e.g. pixel-wise depth) is extremely important for this task as it is particularly beneficial for us to essentially generate accurate 3D face structures and distinguish noisy information from the possibly cluttered background. Nevertheless, dense 3D geometry annotations are prohibitively costly for videos and are typically not available for this video generation task. In this paper, we first introduce a self-supervised geometry learning method to automatically recover the dense 3D geometry (i.e.depth) from the face videos without the requirement of any expensive 3D annotation data. Based on the learned dense depth maps, we further propose to leverage them to estimate sparse facial keypoints that capture the critical movement of the human head. In a more dense way, the depth is also utilized to learn 3D-aware cross-modal (i.e. appearance and depth) attention to guide the generation of motion fields for warping source image representations. All these contributions compose a novel depth-aware generative adversarial network (DaGAN) for talking head generation. Extensive experiments conducted demonstrate that our proposed method can generate highly realistic faces, and achieve significant results on the unseen human faces.