 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quaternion-based dynamic mode decomposition for background modeling in color videos
Dec 28, 2021

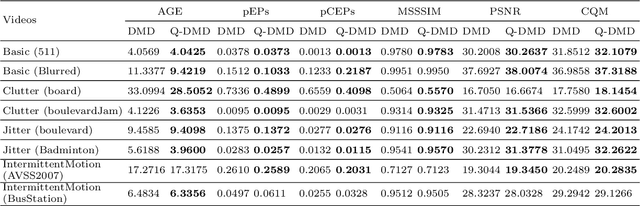
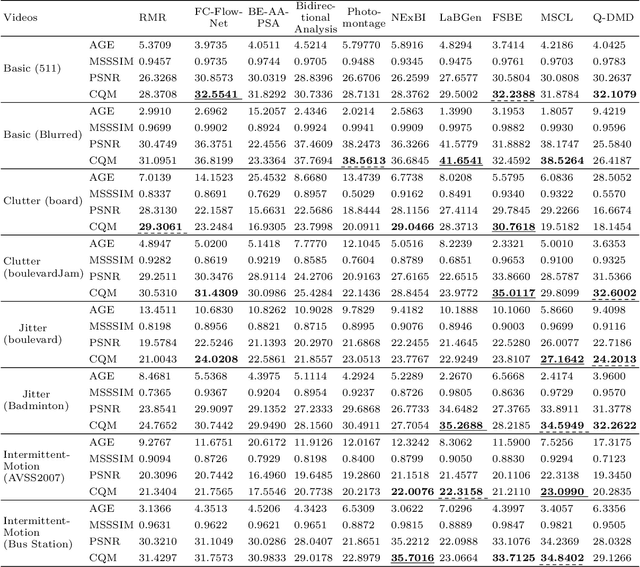

Scene Background Initialization (SBI) is one of the challenging problems in computer vision. Dynamic mode decomposition (DMD) is a recently proposed method to robustly decompose a video sequence into the background model and the corresponding foreground part. However, this method needs to convert the color image into the grayscale image for processing, which leads to the neglect of the coupling information between the three channels of the color image. In this study, we propose a quaternion-based DMD (Q-DMD), which extends the DMD by quaternion matrix analysis, so as to completely preserve the inherent color structure of the color image and the color video. We exploit the standard eigenvalues of the quaternion matrix to compute its spectral decomposition and calculate the corresponding Q-DMD modes and eigenvalues. The results on the publicly available benchmark datasets prove that our Q-DMD outperforms the exact DMD method, and experiment results also demonstrate that the performance of our approach is comparable to that of the state-of-the-art ones.
Block Scrambling Image Encryption Used in Combination with Data Augmentation for Privacy-Preserving DNNs
Apr 03, 2021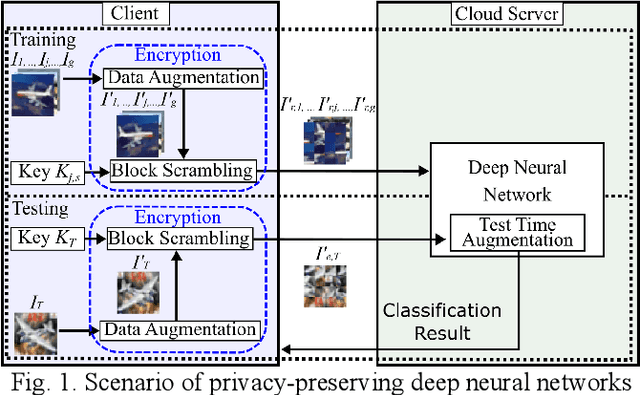
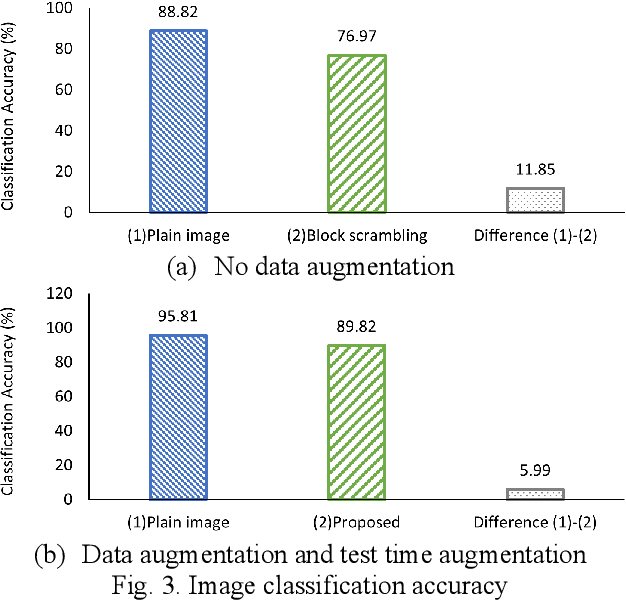
In this paper, we propose a novel learnable image encryption method for privacy-preserving deep neural networks (DNNs). The proposed method is carried out on the basis of block scrambling used in combination with data augmentation techniques such as random cropping, horizontal flip and grid mask. The use of block scrambling enhances robustness against various attacks, and in contrast, the combination with data augmentation enables us to maintain a high classification accuracy even when using encrypted images. In an image classification experiment, the proposed method is demonstrated to be effective in privacy-preserving DNNs.
Active Phase-Encode Selection for Slice-Specific Fast MR Scanning Using a Transformer-Based Deep Reinforcement Learning Framework
Mar 11, 2022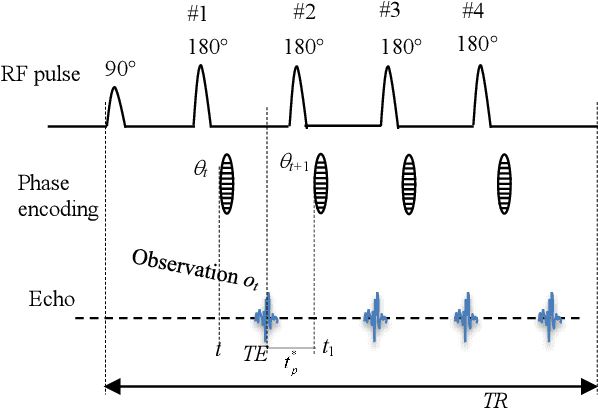
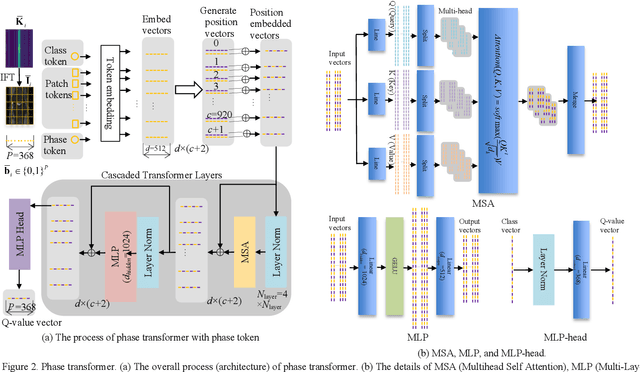
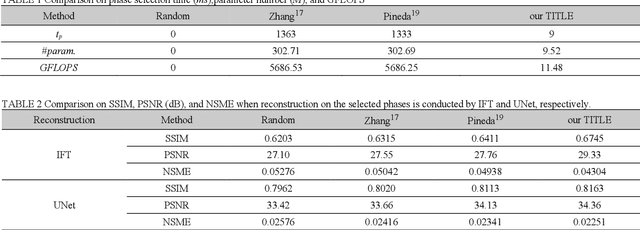
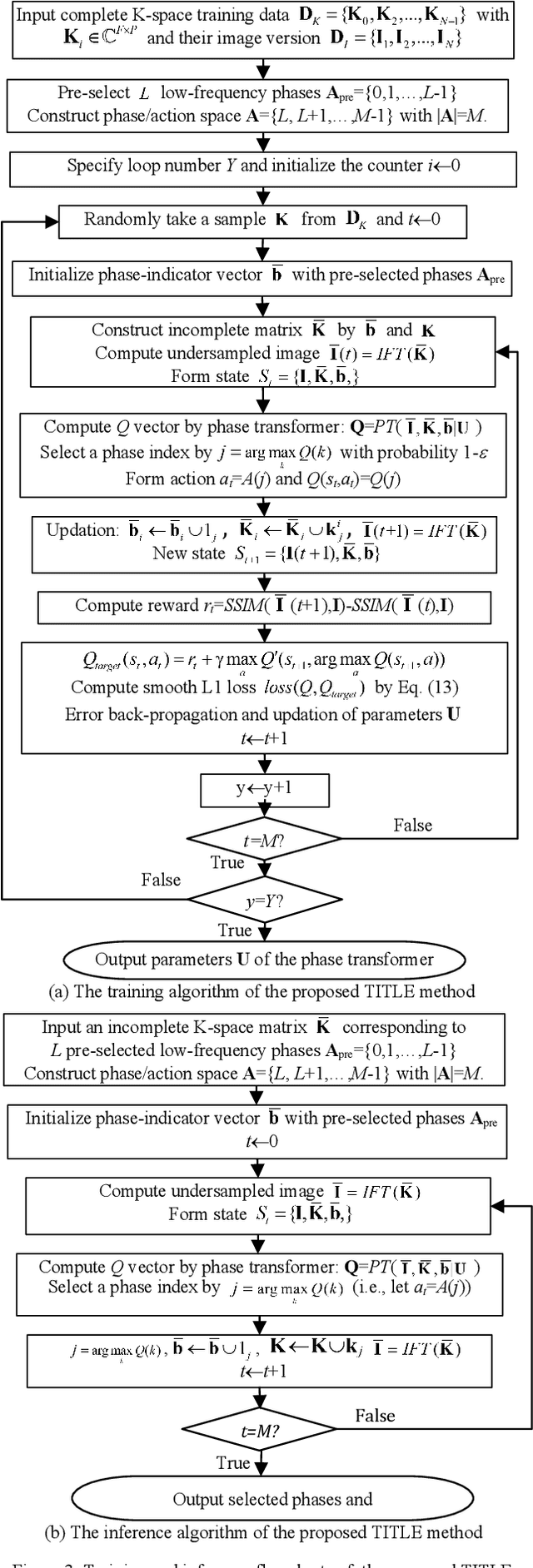
Purpose: Long scan time in phase encoding for forming complete K-space matrices is a critical drawback of MRI, making patients uncomfortable and wasting important time for diagnosing emergent diseases. This paper aims to reducing the scan time by actively and sequentially selecting partial phases in a short time so that a slice can be accurately reconstructed from the resultant slice-specific incomplete K-space matrix. Methods: A transformer based deep reinforcement learning framework is proposed for actively determining a sequence of partial phases according to reconstruction-quality based Q-value (a function of reward), where the reward is the improvement degree of reconstructed image quality. The Q-value is efficiently predicted from binary phase-indicator vectors, incomplete K-space matrices and their corresponding undersampled images with a light-weight transformer so that the sequential information of phases and global relationship in images can be used. The inverse Fourier transform is employed for efficiently computing the undersampled images and hence gaining the rewards of selecting phases. Results: Experimental results on the fastMRI dataset with original K-space data accessible demonstrate the efficiency and accuracy superiorities of proposed method. Compared with the state-of-the-art reinforcement learning based method proposed by Pineda et al., the proposed method is roughly 150 times faster and achieves significant improvement in reconstruction accuracy. Conclusions: We have proposed a light-weight transformer based deep reinforcement learning framework for generating high-quality slice-specific trajectory consisting of a small number of phases. The proposed method, called TITLE (Transformer Involved Trajectory LEarning), has remarkable superiority in phase-encode selection efficiency and image reconstruction accuracy.
PEGG-Net: Background Agnostic Pixel-Wise Efficient Grasp Generation Under Closed-Loop Conditions
Mar 30, 2022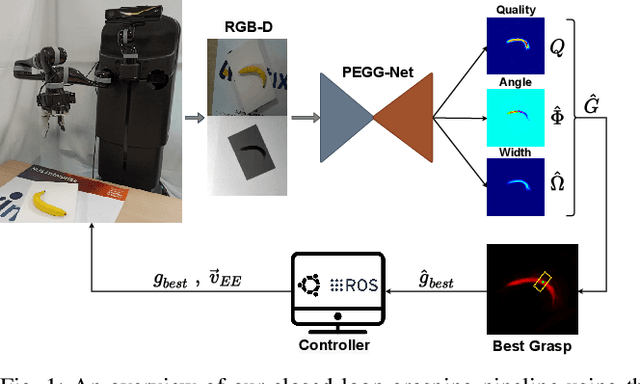
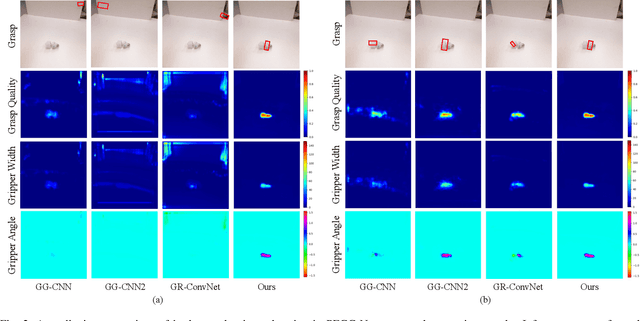
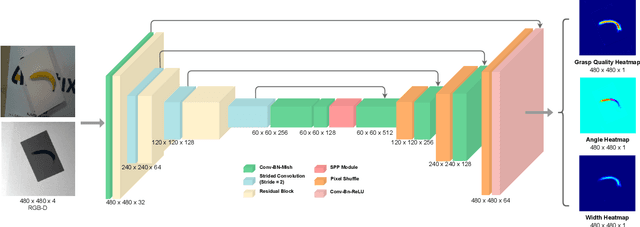

Performing closed-loop grasping at close proximity to an object requires a large field of view. However, such images will inevitably bring large amounts of unnecessary background information, especially when the camera is far away from the target object at the initial stage, resulting in performance degradation of the grasping network. To address this problem, we design a novel PEGG-Net, a real-time, pixel-wise, robotic grasp generation network. The proposed lightweight network is inherently able to learn to remove background noise that can reduce grasping accuracy. Our proposed PEGG-Net achieves improved state-of-the-art performance on both Cornell dataset (98.9%) and Jacquard dataset (93.8%). In the real-world tests, PEGG-Net can support closed-loop grasping at up to 50Hz using an image size of 480x480 in dynamic environments. The trained model also generalizes to previously unseen objects with complex geometrical shapes, household objects and workshop tools and achieved an overall grasp success rate of 91.2% in our real-world grasping experiments.
Learning with Free Object Segments for Long-Tailed Instance Segmentation
Feb 22, 2022
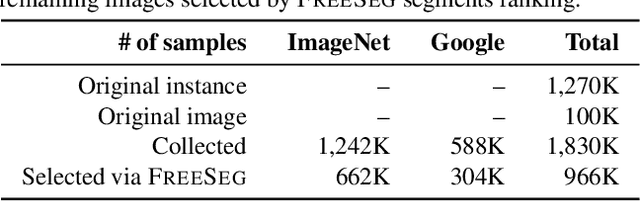
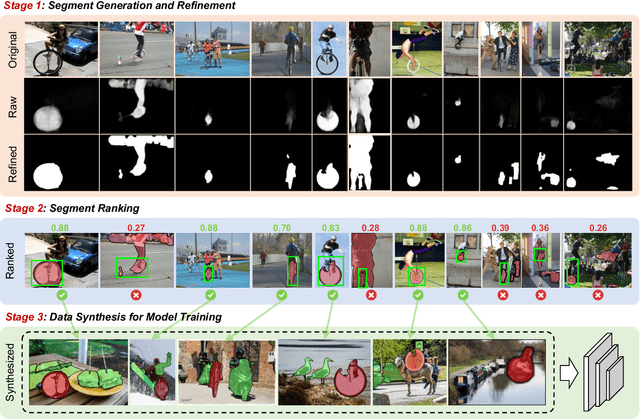
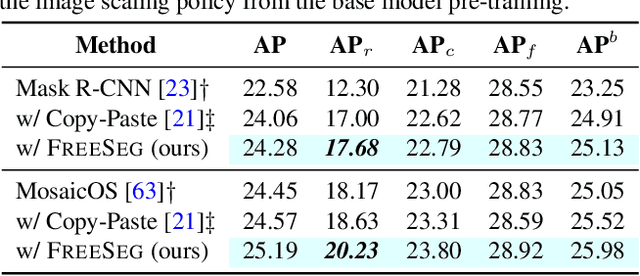
One fundamental challenge in building an instance segmentation model for a large number of classes in complex scenes is the lack of training examples, especially for rare objects. In this paper, we explore the possibility to increase the training examples without laborious data collection and annotation. We find that an abundance of instance segments can potentially be obtained freely from object-centric im-ages, according to two insights: (i) an object-centric image usually contains one salient object in a simple background; (ii) objects from the same class often share similar appearances or similar contrasts to the background. Motivated by these insights, we propose a simple and scalable framework FreeSeg for extracting and leveraging these "free" object foreground segments to facilitate model training in long-tailed instance segmentation. Concretely, we employ off-the-shelf object foreground extraction techniques (e.g., image co-segmentation) to generate instance mask candidates, followed by segments refinement and ranking. The resulting high-quality object segments can be used to augment the existing long-tailed dataset, e.g., by copying and pasting the segments onto the original training images. On the LVIS benchmark, we show that FreeSeg yields substantial improvements on top of strong baselines and achieves state-of-the-art accuracy for segmenting rare object categories.
Neural Radiance Projection
Mar 15, 2022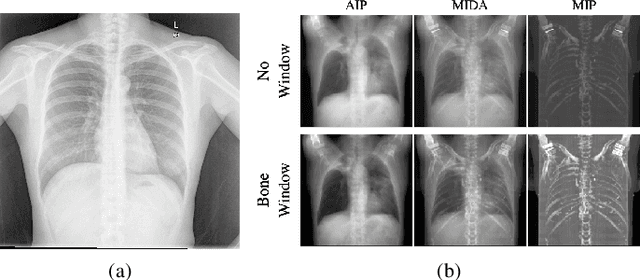
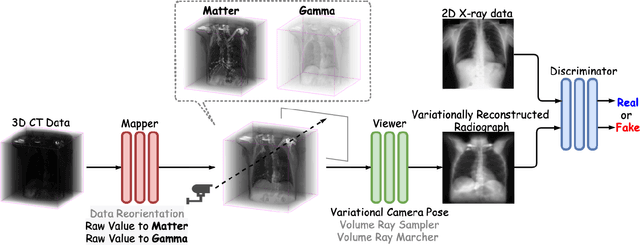
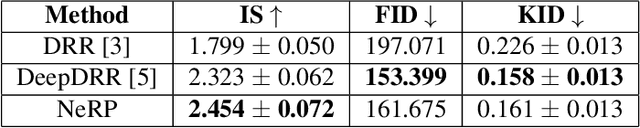
The proposed method, Neural Radiance Projection (NeRP), addresses the three most fundamental shortages of training such a convolutional neural network on X-ray image segmentation: dealing with missing/limited human-annotated datasets; ambiguity on the per-pixel label; and the imbalance across positive- and negative- classes distribution. By harnessing a generative adversarial network, we can synthesize a massive amount of physics-based X-ray images, so-called Variationally Reconstructed Radiographs (VRRs), alongside their segmentation from more accurate labeled 3D Computed Tomography data. As a result, VRRs present more faithfully than other projection methods in terms of photo-realistic metrics. Adding outputs from NeRP also surpasses the vanilla UNet models trained on the same pairs of X-ray images.
Unsupervised Domain Adaptation for Nighttime Aerial Tracking
Mar 30, 2022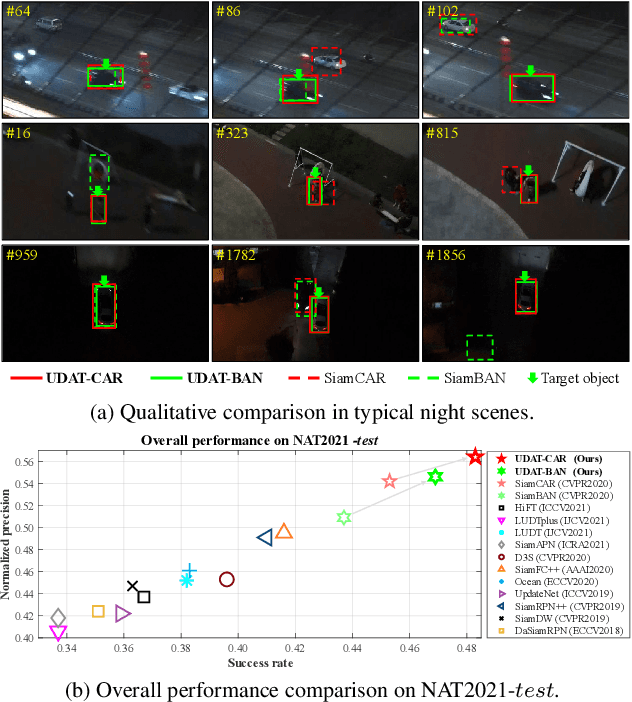
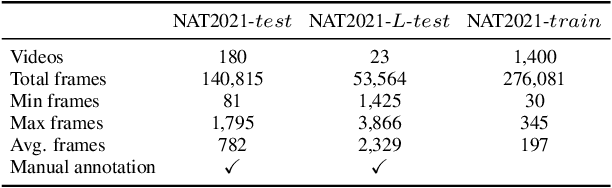
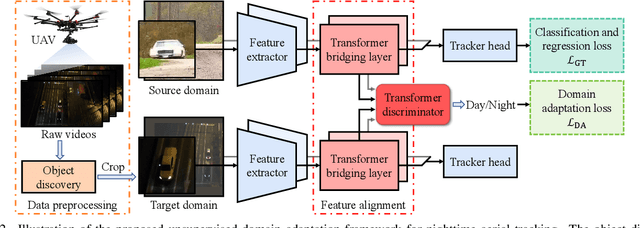
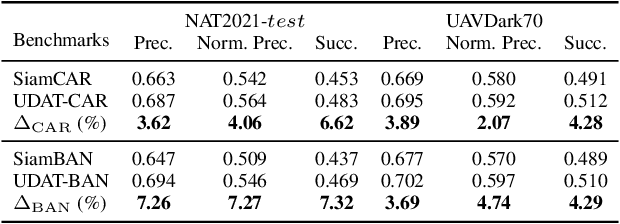
Previous advances in object tracking mostly reported on favorable illumination circumstances while neglecting performance at nighttime, which significantly impeded the development of related aerial robot applications. This work instead develops a novel unsupervised domain adaptation framework for nighttime aerial tracking (named UDAT). Specifically, a unique object discovery approach is provided to generate training patches from raw nighttime tracking videos. To tackle the domain discrepancy, we employ a Transformer-based bridging layer post to the feature extractor to align image features from both domains. With a Transformer day/night feature discriminator, the daytime tracking model is adversarially trained to track at night. Moreover, we construct a pioneering benchmark namely NAT2021 for unsupervised domain adaptive nighttime tracking, which comprises a test set of 180 manually annotated tracking sequences and a train set of over 276k unlabelled nighttime tracking frames. Exhaustive experiments demonstrate the robustness and domain adaptability of the proposed framework in nighttime aerial tracking. The code and benchmark are available at https://github.com/vision4robotics/UDAT.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022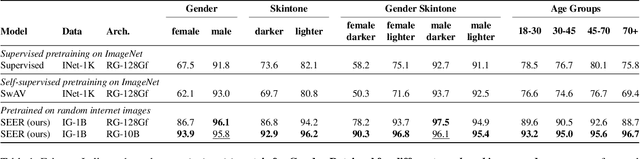
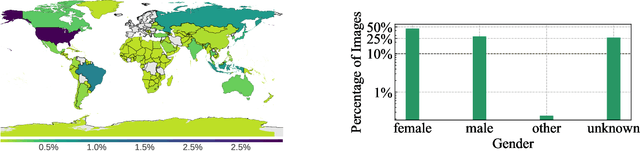
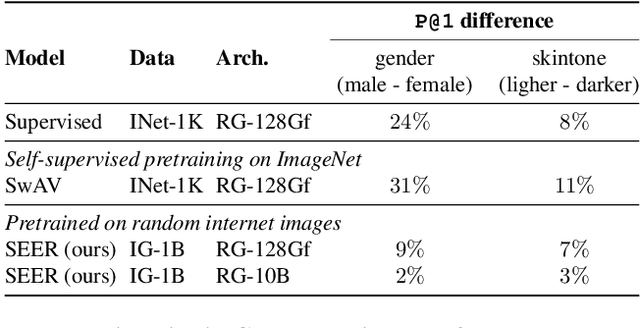
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
Deep Learning for Regularization Prediction in Diffeomorphic Image Registration
Nov 28, 2020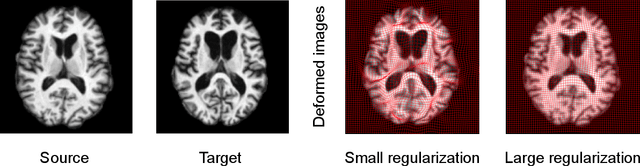

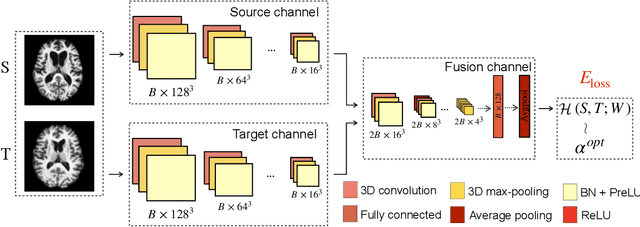
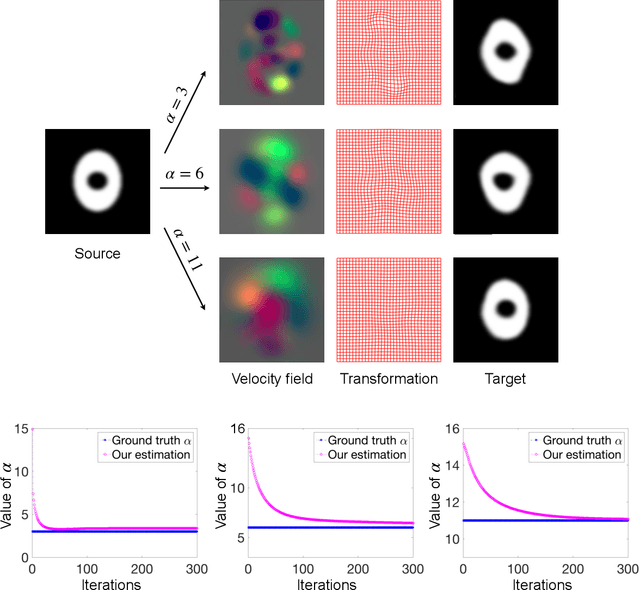
This paper presents a predictive model for estimating regularization parameters of diffeomorphic image registration. We introduce a novel framework that automatically determines the parameters controlling the smoothness of diffeomorphic transformations. Our method significantly reduces the effort of parameter tuning, which is time and labor-consuming. To achieve the goal, we develop a predictive model based on deep convolutional neural networks (CNN) that learns the mapping between pairwise images and the regularization parameter of image registration. In contrast to previous methods that estimate such parameters in a high-dimensional image space, our model is built in an efficient bandlimited space with much lower dimensions. We demonstrate the effectiveness of our model on both 2D synthetic data and 3D real brain images. Experimental results show that our model not only predicts appropriate regularization parameters for image registration, but also improving the network training in terms of time and memory efficiency.
Acknowledging the Unknown for Multi-label Learning with Single Positive Labels
Mar 30, 2022
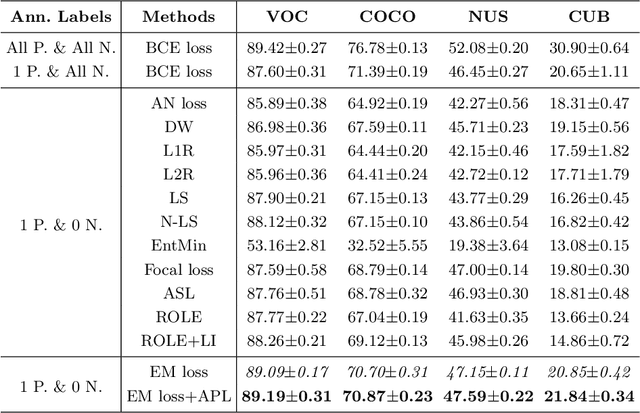
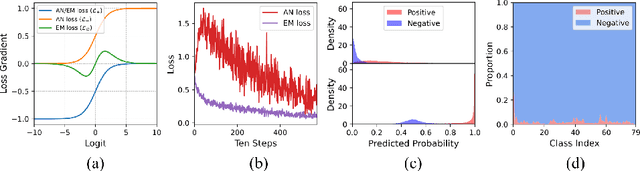

Due to the difficulty of collecting exhaustive multi-label annotations, multi-label training data often contains partial labels. We consider an extreme of this problem, called single positive multi-label learning (SPML), where each multi-label training image has only one positive label. Traditionally, all unannotated labels are assumed as negative labels in SPML, which would introduce false negative labels and make model training be dominated by assumed negative labels. In this work, we choose to treat all unannotated labels from a different perspective, \textit{i.e.} acknowledging they are unknown. Hence, we propose entropy-maximization (EM) loss to maximize the entropy of predicted probabilities for all unannotated labels. Considering the positive-negative label imbalance of unannotated labels, we propose asymmetric pseudo-labeling (APL) with asymmetric-tolerance strategies and a self-paced procedure to provide more precise supervision. Experiments show that our method significantly improves performance and achieves state-of-the-art results on all four benchmarks.