 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BOAT: Bilateral Local Attention Vision Transformer
Jan 31, 2022
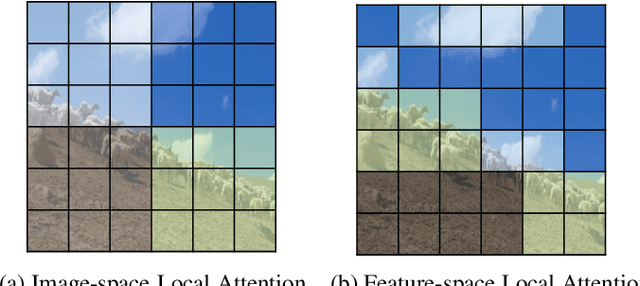
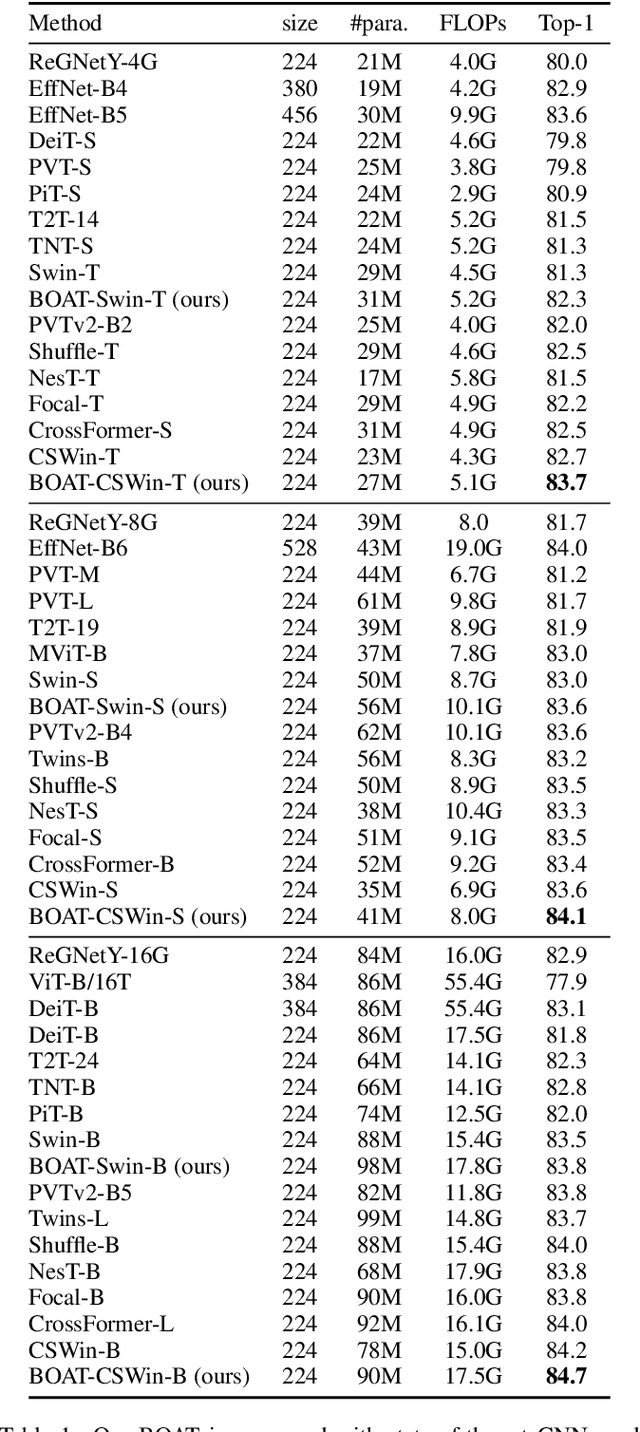

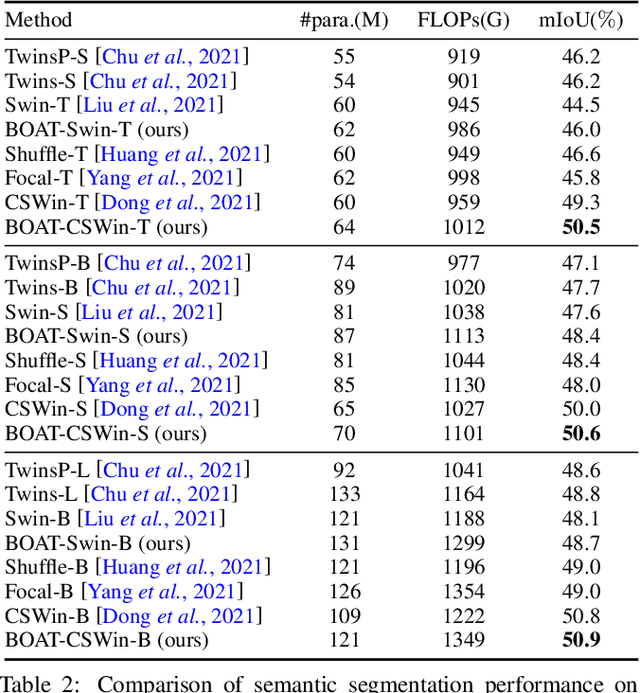
Vision Transformers achieved outstanding performance in many computer vision tasks. Early Vision Transformers such as ViT and DeiT adopt global self-attention, which is computationally expensive when the number of patches is large. To improve efficiency, recent Vision Transformers adopt local self-attention mechanisms, where self-attention is computed within local windows. Despite the fact that window-based local self-attention significantly boosts efficiency, it fails to capture the relationships between distant but similar patches in the image plane. To overcome this limitation of image-space local attention, in this paper, we further exploit the locality of patches in the feature space. We group the patches into multiple clusters using their features, and self-attention is computed within every cluster. Such feature-space local attention effectively captures the connections between patches across different local windows but still relevant. We propose a Bilateral lOcal Attention vision Transformer (BOAT), which integrates feature-space local attention with image-space local attention. We further integrate BOAT with both Swin and CSWin models, and extensive experiments on several benchmark datasets demonstrate that our BOAT-CSWin model clearly and consistently outperforms existing state-of-the-art CNN models and vision Transformers.
Subjective Opinions Matter: Controllable Image Quality Assessment Using Pseudo Reference Images
May 06, 2021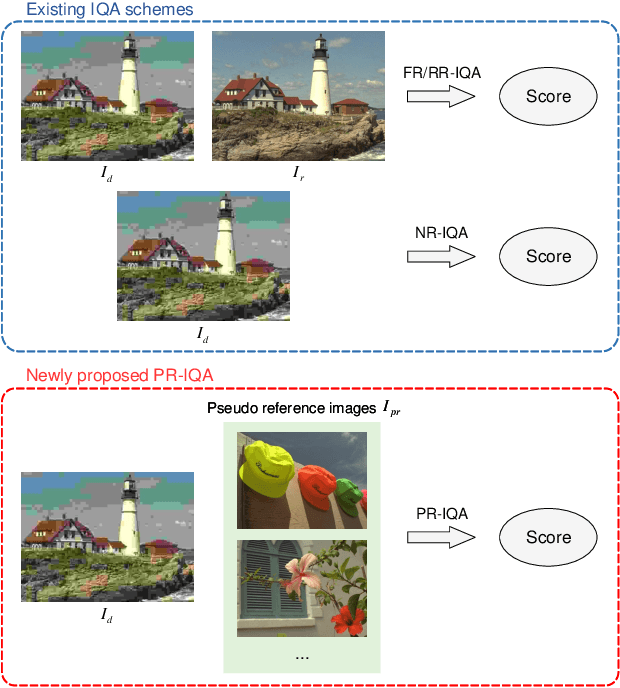
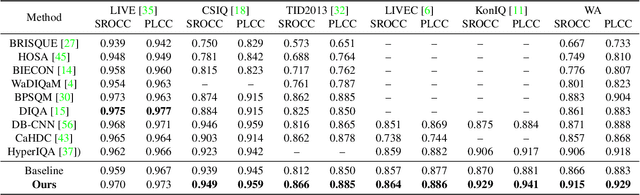
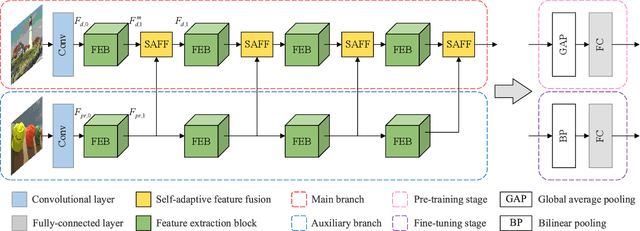
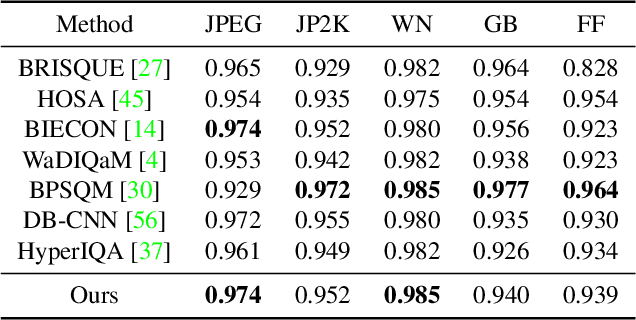
Recently, image quality assessment (IQA) has achieved remarkable progress with the success of deep learning. However, existing IQA methods are practically troublesome. With the strict pre-condition of full-reference (FR) methods limiting its application in real scenarios, the no-reference (NR) scheme is also inconvenient due to its unsatisfying performance and the lack of flexibility or controllability. In this paper, we aim to bridge the gap between FR and NR-IQA and introduce a brand new scheme, namely pseudo-reference image quality assessment (PR-IQA), by introducing pseudo reference images. As the first implementation of PR-IQA, we propose a novel baseline, i.e., Unpaired-IQA, from the perspective of subjective opinion-aware IQA. A self-adaptive feature fusion (SAFF) module is well-designed for the unpaired features in PR-IQA, with which the model can extract quality-discriminative features from distorted images and content variability-robust features from pseudo reference ones, respectively. Extensive experiments demonstrate that the proposed model outperforms the state-of-the-art NR-IQA methods, verifying the effectiveness of PR-IQA and demonstrating that a user-friendly, controllable IQA is feasible and successfully realized.
Unsupervised Manga Character Re-identification via Face-body and Spatial-temporal Associated Clustering
Apr 10, 2022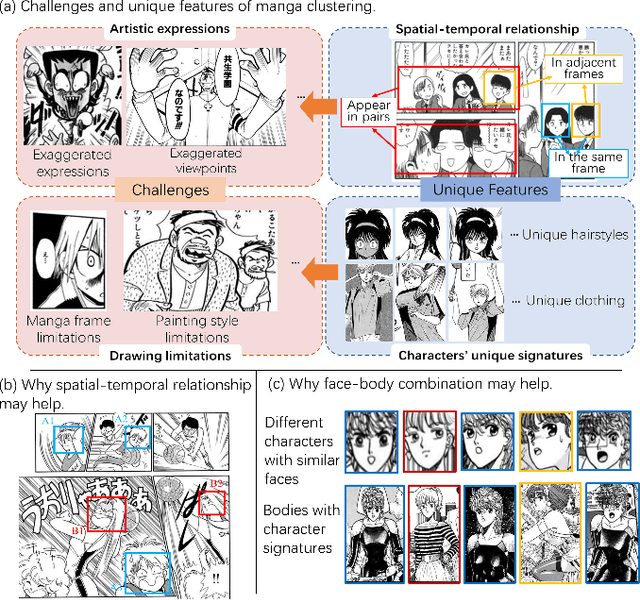

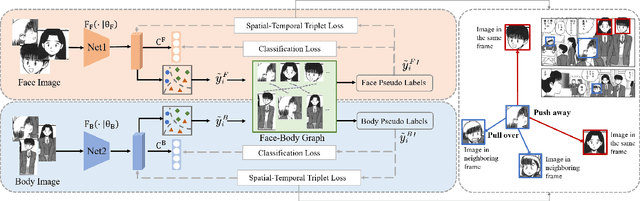

In the past few years, there has been a dramatic growth in e-manga (electronic Japanese-style comics). Faced with the booming demand for manga research and the large amount of unlabeled manga data, we raised a new task, called unsupervised manga character re-identification. However, the artistic expression and stylistic limitations of manga pose many challenges to the re-identification problem. Inspired by the idea that some content-related features may help clustering, we propose a Face-body and Spatial-temporal Associated Clustering method (FSAC). In the face-body combination module, a face-body graph is constructed to solve problems such as exaggeration and deformation in artistic creation by using the integrity of the image. In the spatial-temporal relationship correction module, we analyze the appearance features of characters and design a temporal-spatial-related triplet loss to fine-tune the clustering. Extensive experiments on a manga book dataset with 109 volumes validate the superiority of our method in unsupervised manga character re-identification.
ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022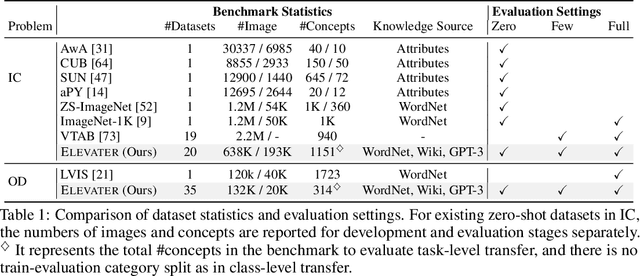

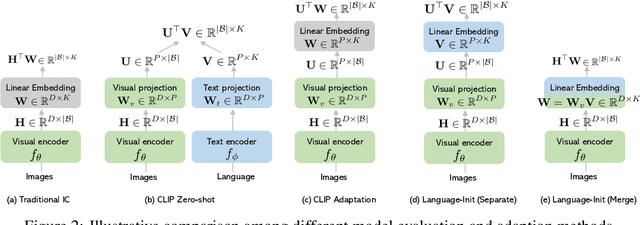
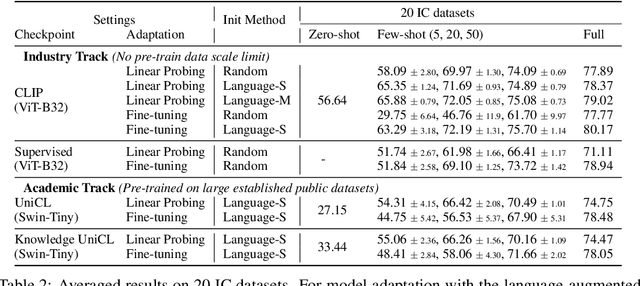
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020
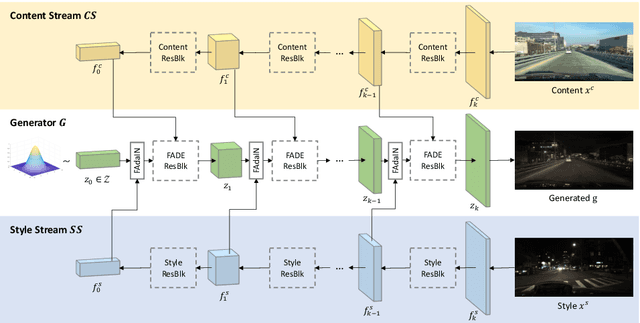
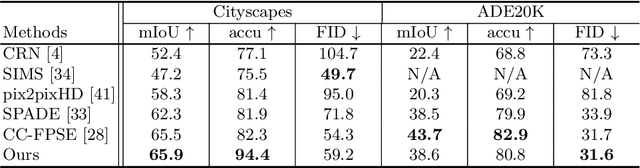
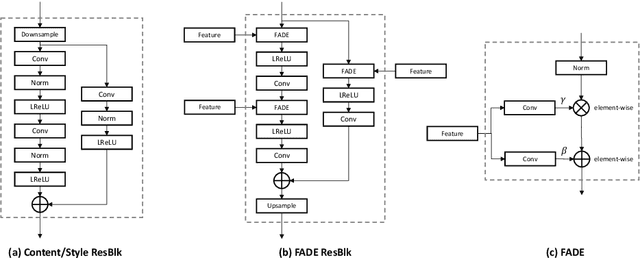
We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.
Compositional Learning of Image-Text Query for Image Retrieval
Jun 19, 2020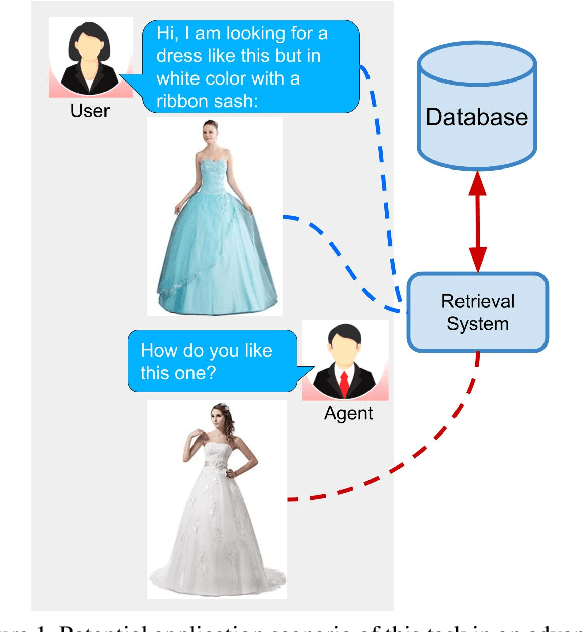
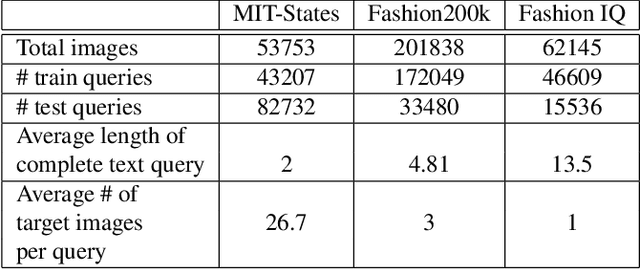
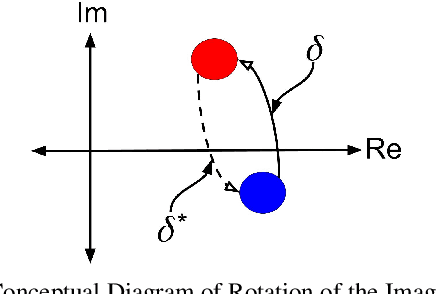
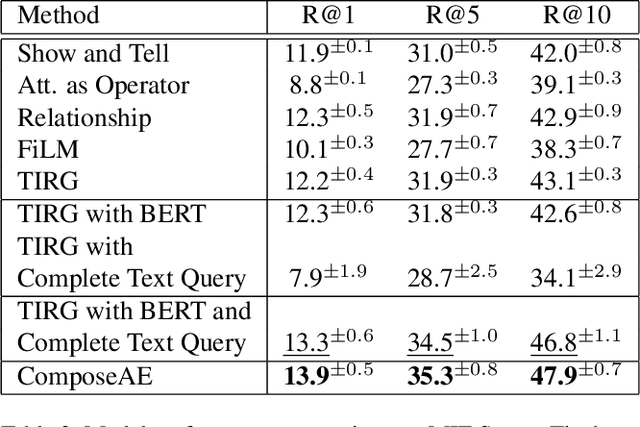
In this paper, we investigate the problem of retrieving images from a database based on a multi-modal (image-text) query. Specifically, the query text prompts some modification in the query image and the task is to retrieve images with the desired modifications. For instance, a user of an E-Commerce platform is interested in buying a dress, which should look similar to her friend's dress, but the dress should be of white color with a ribbon sash. In this case, we would like the algorithm to retrieve some dresses with desired modifications in the query dress. We propose an autoencoder based model, ComposeAE, to learn the composition of image and text query for retrieving images. We adopt a deep metric learning approach and learn a metric that pushes composition of source image and text query closer to the target images. We also propose a rotational symmetry constraint on the optimization problem. Our approach is able to outperform the state-of-the-art method TIRG \cite{TIRG} on three benchmark datasets, namely: MIT-States, Fashion200k and Fashion IQ. In order to ensure fair comparison, we introduce strong baselines by enhancing TIRG method. To ensure reproducibility of the results, we publish our code here: \url{https://anonymous.4open.science/r/d1babc3c-0e72-448a-8594-b618bae876dc/}.
Imposing Temporal Consistency on Deep Monocular Body Shape and Pose Estimation
Feb 08, 2022Accurate and temporally consistent modeling of human bodies is essential for a wide range of applications, including character animation, understanding human social behavior and AR/VR interfaces. Capturing human motion accurately from a monocular image sequence is still challenging and the modeling quality is strongly influenced by the temporal consistency of the captured body motion. Our work presents an elegant solution for the integration of temporal constraints in the fitting process. This does not only increase temporal consistency but also robustness during the optimization. In detail, we derive parameters of a sequence of body models, representing shape and motion of a person, including jaw poses, facial expressions, and finger poses. We optimize these parameters over the complete image sequence, fitting one consistent body shape while imposing temporal consistency on the body motion, assuming linear body joint trajectories over a short time. Our approach enables the derivation of realistic 3D body models from image sequences, including facial expression and articulated hands. In extensive experiments, we show that our approach results in accurately estimated body shape and motion, also for challenging movements and poses. Further, we apply it to the special application of sign language analysis, where accurate and temporal consistent motion modelling is essential, and show that the approach is well-suited for this kind of application.
PRMI: A Dataset of Minirhizotron Images for Diverse Plant Root Study
Jan 20, 2022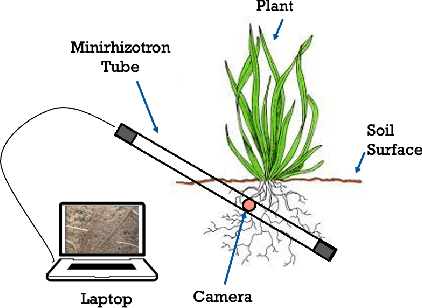
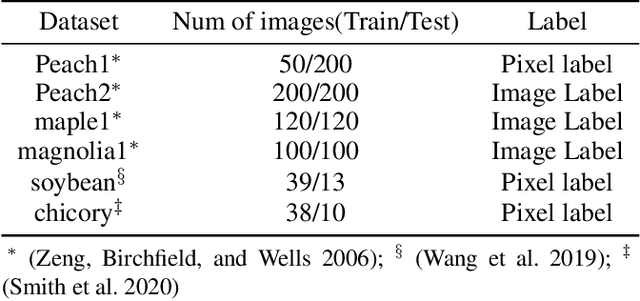

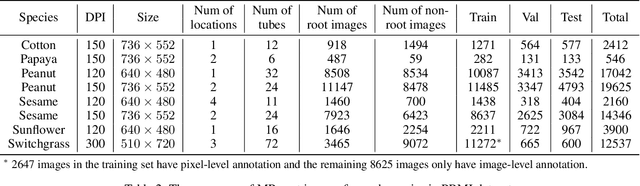
Understanding a plant's root system architecture (RSA) is crucial for a variety of plant science problem domains including sustainability and climate adaptation. Minirhizotron (MR) technology is a widely-used approach for phenotyping RSA non-destructively by capturing root imagery over time. Precisely segmenting roots from the soil in MR imagery is a critical step in studying RSA features. In this paper, we introduce a large-scale dataset of plant root images captured by MR technology. In total, there are over 72K RGB root images across six different species including cotton, papaya, peanut, sesame, sunflower, and switchgrass in the dataset. The images span a variety of conditions including varied root age, root structures, soil types, and depths under the soil surface. All of the images have been annotated with weak image-level labels indicating whether each image contains roots or not. The image-level labels can be used to support weakly supervised learning in plant root segmentation tasks. In addition, 63K images have been manually annotated to generate pixel-level binary masks indicating whether each pixel corresponds to root or not. These pixel-level binary masks can be used as ground truth for supervised learning in semantic segmentation tasks. By introducing this dataset, we aim to facilitate the automatic segmentation of roots and the research of RSA with deep learning and other image analysis algorithms.
Temporally and Spatially variant-resolution illumination patterns in computational ghost imaging
May 05, 2022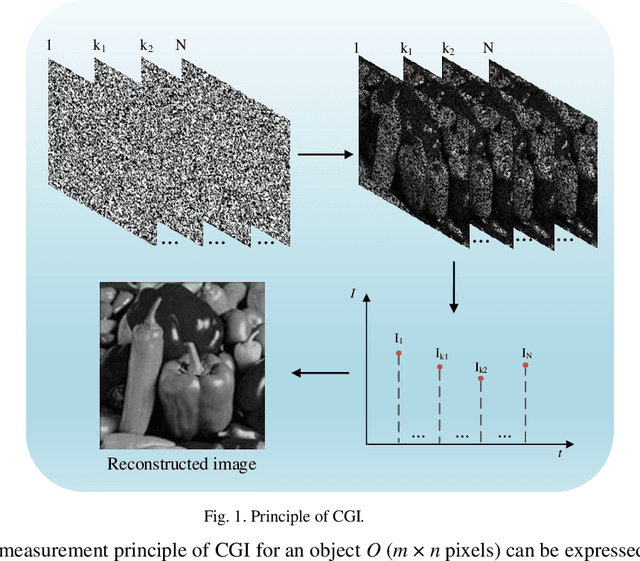
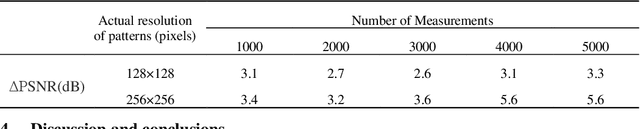
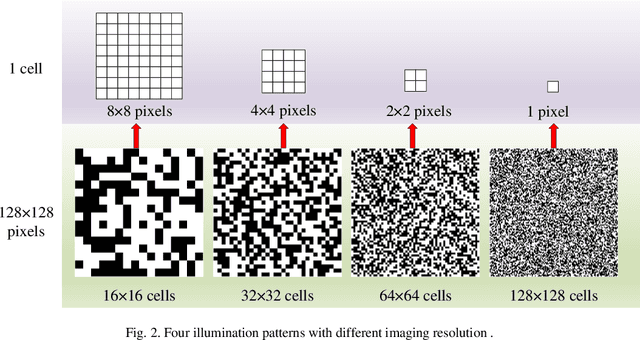
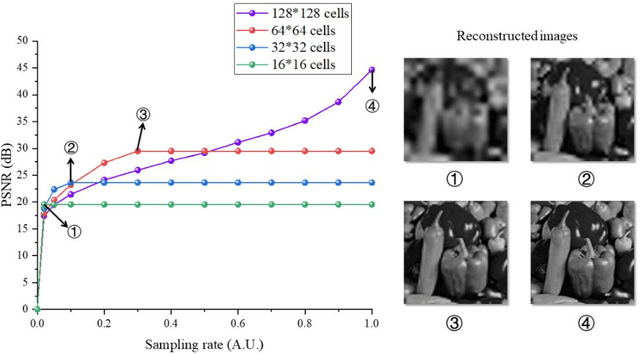
Conventional computational ghost imaging (CGI) uses light carrying a sequence of patterns with uniform-resolution to illuminate the object, then performs correlation calculation based on the light intensity value reflected by the target and the preset patterns to obtain object image. It requires a large number of measurements to obtain high-quality images, especially if high-resolution images are to be obtained. To solve this problem, we developed temporally variable-resolution illumination patterns, replacing the conventional uniform-resolution illumination patterns with a sequence of patterns of different imaging resolutions. In addition, we propose to combine temporally variable-resolution illumination patterns and spatially variable-resolution structure to develop temporally and spatially variable-resolution (TSV) illumination patterns, which not only improve the imaging quality of the region of interest (ROI) but also improve the robustness to noise. The methods using proposed illumination patterns are verified by simulations and experiments compared with CGI. For the same number of measurements, the method using temporally variable-resolution illumination patterns has better imaging quality than CGI, but it is less robust to noise. The method using TSV illumination patterns has better imaging quality in ROI than the method using temporally variable-resolution illumination patterns and CGI under the same number of measurements. We also experimentally verify that the method using TSV patterns have better imaging performance when applied to higher resolution imaging. The proposed methods are expected to solve the current computational ghost imaging that is difficult to achieve high-resolution and high-quality imaging.
Anomaly Detection in Image Datasets Using Convolutional Neural Networks, Center Loss, and Mahalanobis Distance
Apr 13, 2021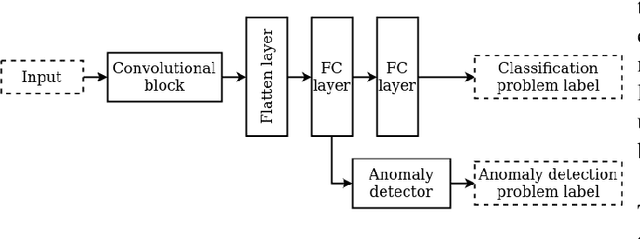
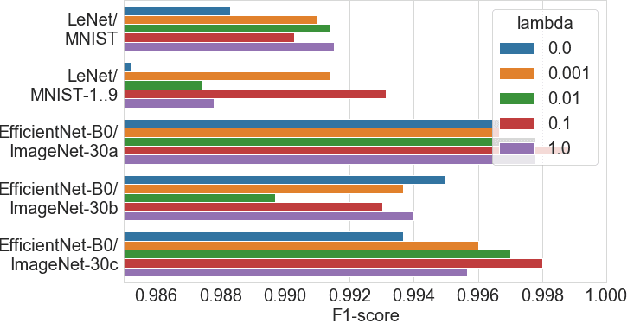
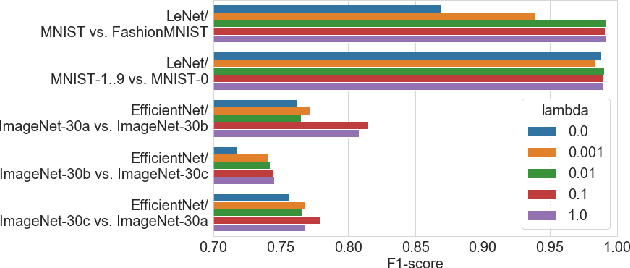
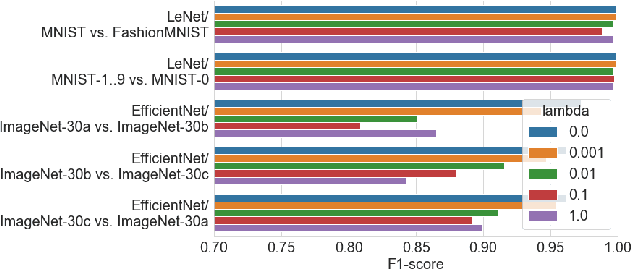
User activities generate a significant number of poor-quality or irrelevant images and data vectors that cannot be processed in the main data processing pipeline or included in the training dataset. Such samples can be found with manual analysis by an expert or with anomalous detection algorithms. There are several formal definitions for the anomaly samples. For neural networks, the anomalous is usually defined as out-of-distribution samples. This work proposes methods for supervised and semi-supervised detection of out-of-distribution samples in image datasets. Our approach extends a typical neural network that solves the image classification problem. Thus, one neural network after extension can solve image classification and anomalous detection problems simultaneously. Proposed methods are based on the center loss and its effect on a deep feature distribution in a last hidden layer of the neural network. This paper provides an analysis of the proposed methods for the LeNet and EfficientNet-B0 on the MNIST and ImageNet-30 datasets.