 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instance-aware Exploration-Verification-Exploitation for Instance ImageGoal Navigation
Feb 25, 2024
As a new embodied vision task, Instance ImageGoal Navigation (IIN) aims to navigate to a specified object depicted by a goal image in an unexplored environment. The main challenge of this task lies in identifying the target object from different viewpoints while rejecting similar distractors. Existing ImageGoal Navigation methods usually adopt the simple Exploration-Exploitation framework and ignore the identification of specific instance during navigation. In this work, we propose to imitate the human behaviour of ``getting closer to confirm" when distinguishing objects from a distance. Specifically, we design a new modular navigation framework named Instance-aware Exploration-Verification-Exploitation (IEVE) for instance-level image goal navigation. Our method allows for active switching among the exploration, verification, and exploitation actions, thereby facilitating the agent in making reasonable decisions under different situations. On the challenging HabitatMatterport 3D semantic (HM3D-SEM) dataset, our method surpasses previous state-of-the-art work, with a classical segmentation model (0.684 vs. 0.561 success) or a robust model (0.702 vs. 0.561 success). Our code will be made publicly available at https://github.com/XiaohanLei/IEVE.
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Feb 06, 2024Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster
Training-Free Consistent Text-to-Image Generation
Feb 05, 2024Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.
Enhancing Embodied Object Detection through Language-Image Pre-training and Implicit Object Memory
Feb 06, 2024Deep-learning and large scale language-image training have produced image object detectors that generalise well to diverse environments and semantic classes. However, single-image object detectors trained on internet data are not optimally tailored for the embodied conditions inherent in robotics. Instead, robots must detect objects from complex multi-modal data streams involving depth, localisation and temporal correlation, a task termed embodied object detection. Paradigms such as Video Object Detection (VOD) and Semantic Mapping have been proposed to leverage such embodied data streams, but existing work fails to enhance performance using language-image training. In response, we investigate how an image object detector pre-trained using language-image data can be extended to perform embodied object detection. We propose a novel implicit object memory that uses projective geometry to aggregate the features of detected objects across long temporal horizons. The spatial and temporal information accumulated in memory is then used to enhance the image features of the base detector. When tested on embodied data streams sampled from diverse indoor scenes, our approach improves the base object detector by 3.09 mAP, outperforming alternative external memories designed for VOD and Semantic Mapping. Our method also shows a significant improvement of 16.90 mAP relative to baselines that perform embodied object detection without first training on language-image data, and is robust to sensor noise and domain shift experienced in real-world deployment.
Trustworthy SR: Resolving Ambiguity in Image Super-resolution via Diffusion Models and Human Feedback
Feb 12, 2024Super-resolution (SR) is an ill-posed inverse problem with a large set of feasible solutions that are consistent with a given low-resolution image. Various deterministic algorithms aim to find a single solution that balances fidelity and perceptual quality; however, this trade-off often causes visual artifacts that bring ambiguity in information-centric applications. On the other hand, diffusion models (DMs) excel in generating a diverse set of feasible SR images that span the solution space. The challenge is then how to determine the most likely solution among this set in a trustworthy manner. We observe that quantitative measures, such as PSNR, LPIPS, DISTS, are not reliable indicators to resolve ambiguous cases. To this effect, we propose employing human feedback, where we ask human subjects to select a small number of likely samples and we ensemble the averages of selected samples. This strategy leverages the high-quality image generation capabilities of DMs, while recognizing the importance of obtaining a single trustworthy solution, especially in use cases, such as identification of specific digits or letters, where generating multiple feasible solutions may not lead to a reliable outcome. Experimental results demonstrate that our proposed strategy provides more trustworthy solutions when compared to state-of-the art SR methods.
A SAM-guided Two-stream Lightweight Model for Anomaly Detection
Feb 29, 2024In industrial anomaly detection, model efficiency and mobile-friendliness become the primary concerns in real-world applications. Simultaneously, the impressive generalization capabilities of Segment Anything (SAM) have garnered broad academic attention, making it an ideal choice for localizing unseen anomalies and diverse real-world patterns. In this paper, considering these two critical factors, we propose a SAM-guided Two-stream Lightweight Model for unsupervised anomaly detection (STLM) that not only aligns with the two practical application requirements but also harnesses the robust generalization capabilities of SAM. We employ two lightweight image encoders, i.e., our two-stream lightweight module, guided by SAM's knowledge. To be specific, one stream is trained to generate discriminative and general feature representations in both normal and anomalous regions, while the other stream reconstructs the same images without anomalies, which effectively enhances the differentiation of two-stream representations when facing anomalous regions. Furthermore, we employ a shared mask decoder and a feature aggregation module to generate anomaly maps. Our experiments conducted on MVTec AD benchmark show that STLM, with about 16M parameters and achieving an inference time in 20ms, competes effectively with state-of-the-art methods in terms of performance, 98.26% on pixel-level AUC and 94.92% on PRO. We further experiment on more difficult datasets, e.g., VisA and DAGM, to demonstrate the effectiveness and generalizability of STLM.
Graph Convolutional Neural Networks for Automated Echocardiography View Recognition: A Holistic Approach
Feb 29, 2024To facilitate diagnosis on cardiac ultrasound (US), clinical practice has established several standard views of the heart, which serve as reference points for diagnostic measurements and define viewports from which images are acquired. Automatic view recognition involves grouping those images into classes of standard views. Although deep learning techniques have been successful in achieving this, they still struggle with fully verifying the suitability of an image for specific measurements due to factors like the correct location, pose, and potential occlusions of cardiac structures. Our approach goes beyond view classification and incorporates a 3D mesh reconstruction of the heart that enables several more downstream tasks, like segmentation and pose estimation. In this work, we explore learning 3D heart meshes via graph convolutions, using similar techniques to learn 3D meshes in natural images, such as human pose estimation. As the availability of fully annotated 3D images is limited, we generate synthetic US images from 3D meshes by training an adversarial denoising diffusion model. Experiments were conducted on synthetic and clinical cases for view recognition and structure detection. The approach yielded good performance on synthetic images and, despite being exclusively trained on synthetic data, it already showed potential when applied to clinical images. With this proof-of-concept, we aim to demonstrate the benefits of graphs to improve cardiac view recognition that can ultimately lead to better efficiency in cardiac diagnosis.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024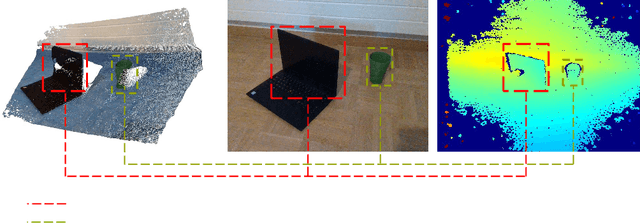



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Feb 07, 2024Diffusion models have enabled remarkably high-quality medical image generation, which can help mitigate the expenses of acquiring and annotating new images by supplementing small or imbalanced datasets, along with other applications. However, these are hampered by the challenge of enforcing global anatomical realism in generated images. To this end, we propose a diffusion model for anatomically-controlled medical image generation. Our model follows a multi-class anatomical segmentation mask at each sampling step and incorporates a \textit{random mask ablation} training algorithm, to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. This also improves the network's learning of anatomical realism for the completely unconditional (unconstrained generation) case. Comparative evaluation on breast MRI and abdominal/neck-to-pelvis CT datasets demonstrates superior anatomical realism and input mask faithfulness over state-of-the-art models. We also offer an accessible codebase and release a dataset of generated paired breast MRIs. Our approach facilitates diverse applications, including pre-registered image generation, counterfactual scenarios, and others.
Tables as Images? Exploring the Strengths and Limitations of LLMs on Multimodal Representations of Tabular Data
Feb 23, 2024In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analysis extends across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the influence of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.