 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crowd counting with crowd attention convolutional neural network
Apr 15, 2022
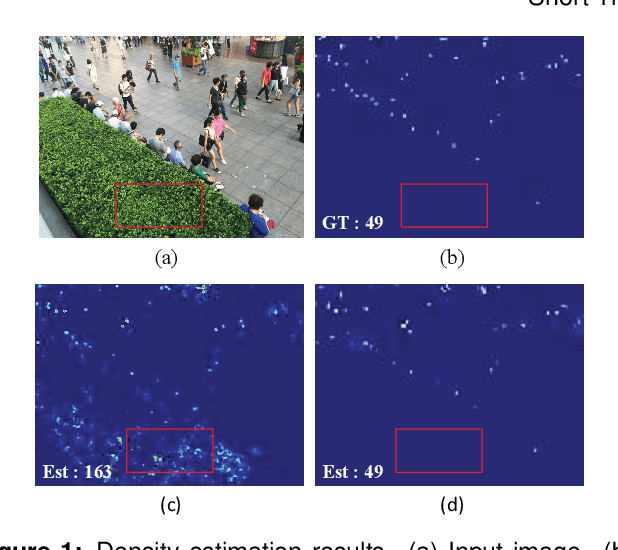

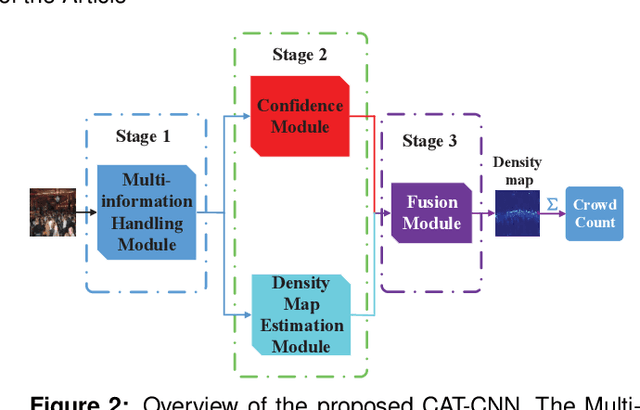
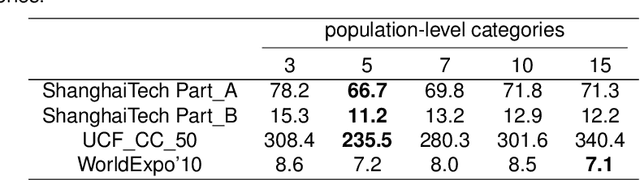
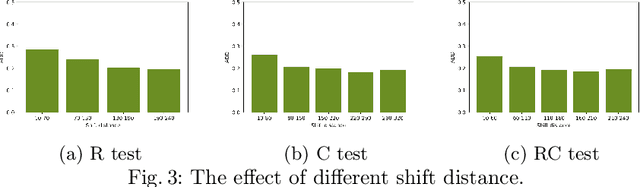
Crowd counting is a challenging problem due to the scene complexity and scale variation. Although deep learning has achieved great improvement in crowd counting, scene complexity affects the judgement of these methods and they usually regard some objects as people mistakenly; causing potentially enormous errors in the crowd counting result. To address the problem, we propose a novel end-to-end model called Crowd Attention Convolutional Neural Network (CAT-CNN). Our CAT-CNN can adaptively assess the importance of a human head at each pixel location by automatically encoding a confidence map. With the guidance of the confidence map, the position of human head in estimated density map gets more attention to encode the final density map, which can avoid enormous misjudgements effectively. The crowd count can be obtained by integrating the final density map. To encode a highly refined density map, the total crowd count of each image is classified in a designed classification task and we first explicitly map the prior of the population-level category to feature maps. To verify the efficiency of our proposed method, extensive experiments are conducted on three highly challenging datasets. Results establish the superiority of our method over many state-of-the-art methods.
* Accepted by Neurocomputing
Adversarial samples for deep monocular 6D object pose estimation
Mar 05, 2022


Estimating 6D object pose from an RGB image is important for many real-world applications such as autonomous driving and robotic grasping. Recent deep learning models have achieved significant progress on this task but their robustness received little research attention. In this work, for the first time, we study adversarial samples that can fool deep learning models with imperceptible perturbations to input image. In particular, we propose a Unified 6D pose estimation Attack, namely U6DA, which can successfully attack several state-of-the-art (SOTA) deep learning models for 6D pose estimation. The key idea of our U6DA is to fool the models to predict wrong results for object instance localization and shape that are essential for correct 6D pose estimation. Specifically, we explore a transfer-based black-box attack to 6D pose estimation. We design the U6DA loss to guide the generation of adversarial examples, the loss aims to shift the segmentation attention map away from its original position. We show that the generated adversarial samples are not only effective for direct 6D pose estimation models, but also are able to attack two-stage models regardless of their robust RANSAC modules. Extensive experiments were conducted to demonstrate the effectiveness, transferability, and anti-defense capability of our U6DA on large-scale public benchmarks. We also introduce a new U6DA-Linemod dataset for robustness study of the 6D pose estimation task. Our codes and dataset will be available at \url{https://github.com/cuge1995/U6DA}.
Improving Clinical Diagnosis Performance with Automated X-ray Scan Quality Enhancement Algorithms
Jan 17, 2022In clinical diagnosis, diagnostic images that are obtained from the scanning devices serve as preliminary evidence for further investigation in the process of delivering quality healthcare. However, often the medical image may contain fault artifacts, introduced due to noise, blur and faulty equipment. The reason for this may be the low-quality or older scanning devices, the test environment or technicians lack of training etc; however, the net result is that the process of fast and reliable diagnosis is hampered. Resolving these issues automatically can have a significant positive impact in a hospital clinical workflow, where often, there is no other way but to work with faulty/older equipment or inadequately qualified radiology technicians. In this paper, automated image quality improvement approaches for adapted and benchmarked for the task of medical image super-resolution. During experimental evaluation on standard open datasets, the observations showed that certain algorithms perform better and show significant improvement in the diagnostic quality of medical scans, thereby enabling better visualization for human diagnostic purposes.
* Presented and Accepted in International Conference on Advances in Systems, Control and Computing (AISCC-2020) at Malaviya National Institute of Technology, Jaipur, India, February 27-28, 2020
Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
Apr 16, 2021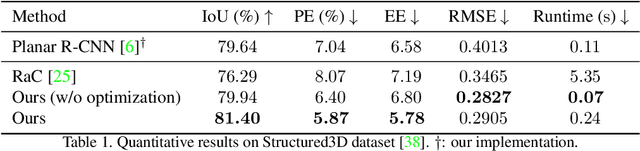
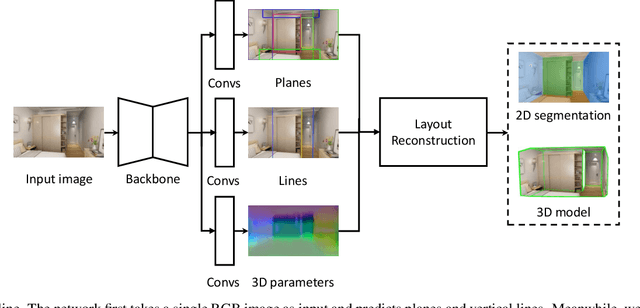
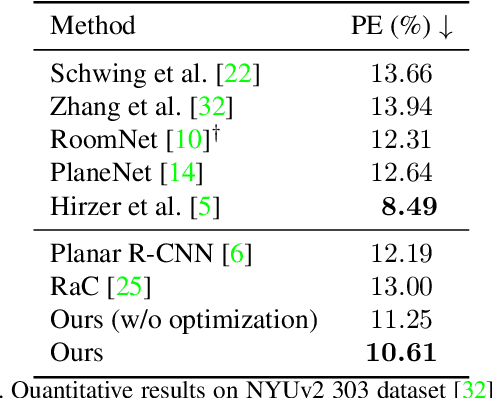

Single-image room layout reconstruction aims to reconstruct the enclosed 3D structure of a room from a single image. Most previous work relies on the cuboid-shape prior. This paper considers a more general indoor assumption, i.e., the room layout consists of a single ceiling, a single floor, and several vertical walls. To this end, we first employ Convolutional Neural Networks to detect planes and vertical lines between adjacent walls. Meanwhile, estimating the 3D parameters for each plane. Then, a simple yet effective geometric reasoning method is adopted to achieve room layout reconstruction. Furthermore, we optimize the 3D plane parameters to reconstruct a geometrically consistent room layout between planes and lines. The experimental results on public datasets validate the effectiveness and efficiency of our method.
A high-order tensor completion algorithm based on Fully-Connected Tensor Network weighted optimization
Apr 06, 2022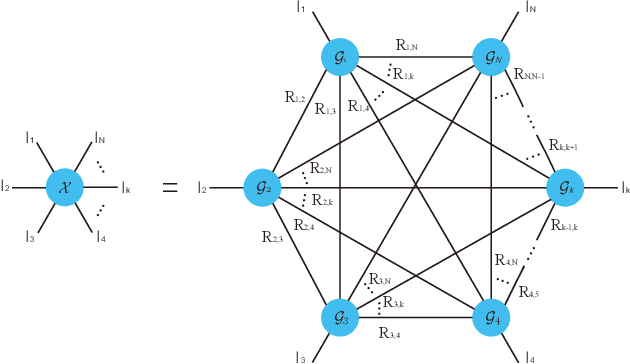
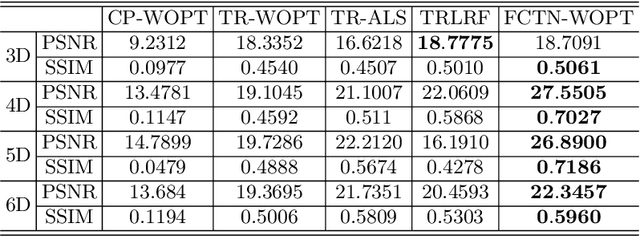
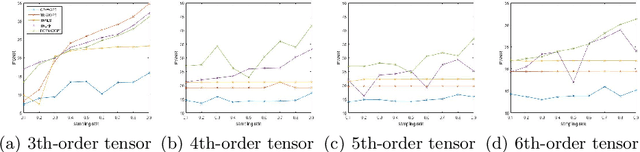

Tensor completion aimes at recovering missing data, and it is one of the popular concerns in deep learning and signal processing. Among the higher-order tensor decomposition algorithms, the recently proposed fully-connected tensor network decomposition (FCTN) algorithm is the most advanced. In this paper, by leveraging the superior expression of the fully-connected tensor network (FCTN) decomposition, we propose a new tensor completion method named the fully connected tensor network weighted optization(FCTN-WOPT). The algorithm performs a composition of the completed tensor by initialising the factors from the FCTN decomposition. We build a loss function with the weight tensor, the completed tensor and the incomplete tensor together, and then update the completed tensor using the lbfgs gradient descent algorithm to reduce the spatial memory occupation and speed up iterations. Finally we test the completion with synthetic data and real data (both image data and video data) and the results show the advanced performance of our FCTN-WOPT when it is applied to higher-order tensor completion.
Seeing without Looking: Analysis Pipeline for Child Sexual Abuse Datasets
Apr 29, 2022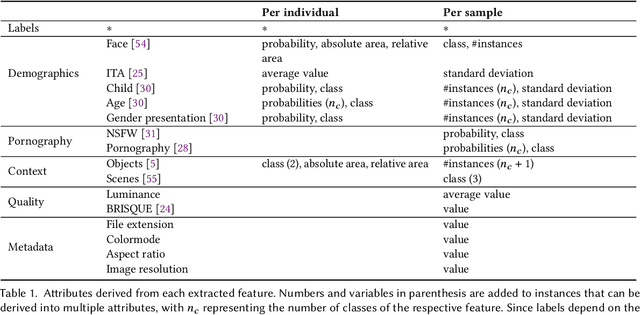
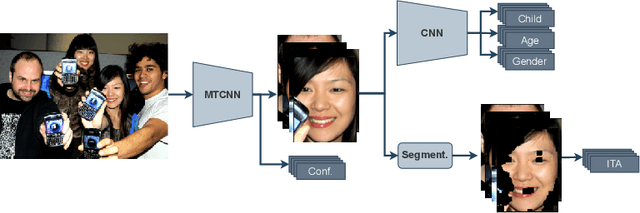
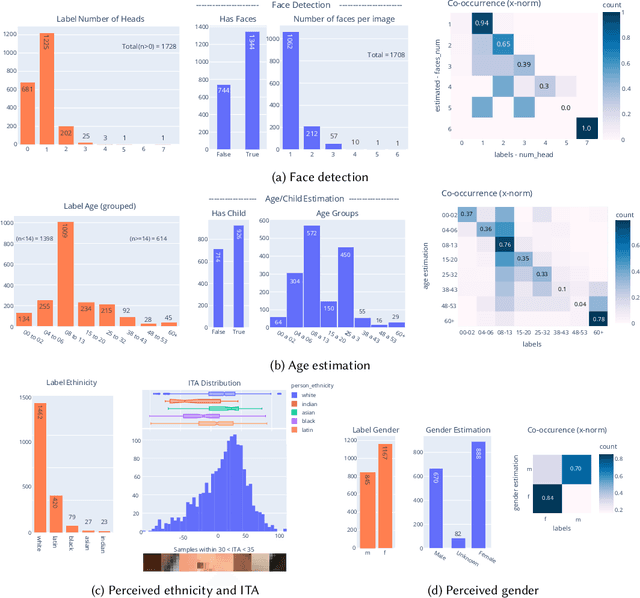
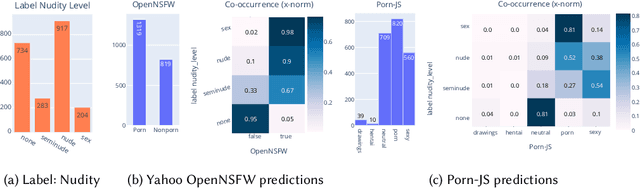
The online sharing and viewing of Child Sexual Abuse Material (CSAM) are growing fast, such that human experts can no longer handle the manual inspection. However, the automatic classification of CSAM is a challenging field of research, largely due to the inaccessibility of target data that is - and should forever be - private and in sole possession of law enforcement agencies. To aid researchers in drawing insights from unseen data and safely providing further understanding of CSAM images, we propose an analysis template that goes beyond the statistics of the dataset and respective labels. It focuses on the extraction of automatic signals, provided both by pre-trained machine learning models, e.g., object categories and pornography detection, as well as image metrics such as luminance and sharpness. Only aggregated statistics of sparse signals are provided to guarantee the anonymity of children and adolescents victimized. The pipeline allows filtering the data by applying thresholds to each specified signal and provides the distribution of such signals within the subset, correlations between signals, as well as a bias evaluation. We demonstrated our proposal on the Region-based annotated Child Pornography Dataset (RCPD), one of the few CSAM benchmarks in the literature, composed of over 2000 samples among regular and CSAM images, produced in partnership with Brazil's Federal Police. Although noisy and limited in several senses, we argue that automatic signals can highlight important aspects of the overall distribution of data, which is valuable for databases that can not be disclosed. Our goal is to safely publicize the characteristics of CSAM datasets, encouraging researchers to join the field and perhaps other institutions to provide similar reports on their benchmarks.
CFPNet-M: A Light-Weight Encoder-Decoder Based Network for Multimodal Biomedical Image Real-Time Segmentation
May 30, 2021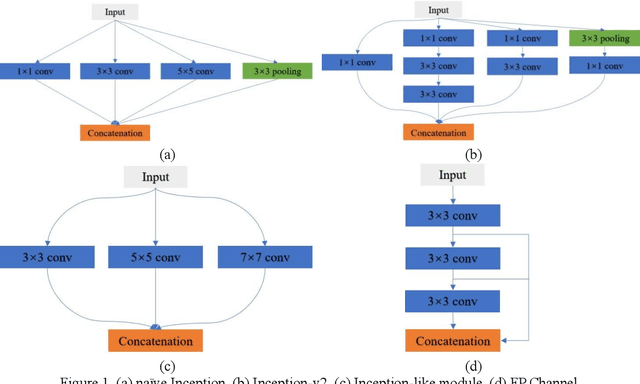
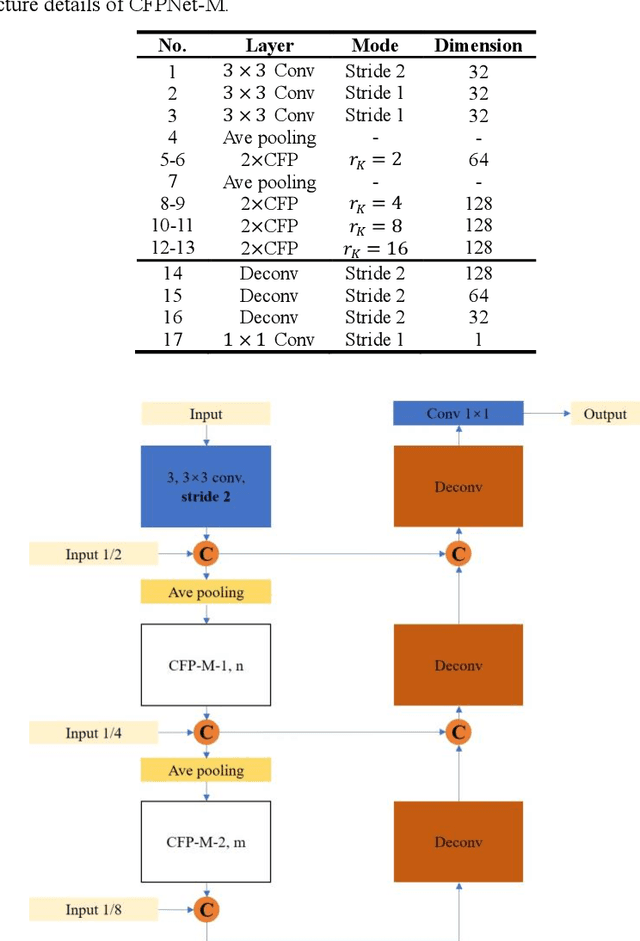
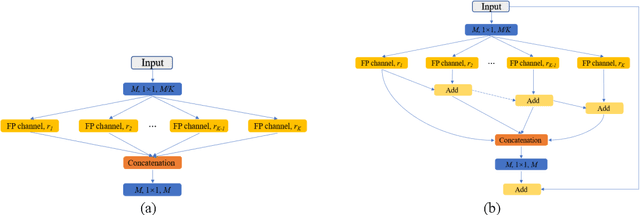

Currently, developments of deep learning techniques are providing instrumental to identify, classify, and quantify patterns in medical images. Segmentation is one of the important applications in medical image analysis. In this regard, U-Net is the predominant approach to medical image segmentation tasks. However, we found that those U-Net based models have limitations in several aspects, for example, millions of parameters in the U-Net consuming considerable computation resource and memory, lack of global information, and missing some tough objects. Therefore, we applied two modifications to improve the U-Net model: 1) designed and added the dilated channel-wise CNN module, 2) simplified the U shape network. Based on these two modifications, we proposed a novel light-weight architecture -- Channel-wise Feature Pyramid Network for Medicine (CFPNet-M). To evaluate our method, we selected five datasets with different modalities: thermography, electron microscopy, endoscopy, dermoscopy, and digital retinal images. And we compared its performance with several models having different parameter scales. This paper also involves our previous studies of DC-UNet and some commonly used light-weight neural networks. We applied the Tanimoto similarity instead of the Jaccard index for gray-level image measurements. By comparison, CFPNet-M achieves comparable segmentation results on all five medical datasets with only 0.65 million parameters, which is about 2% of U-Net, and 8.8 MB memory. Meanwhile, the inference speed can reach 80 FPS on a single RTX 2070Ti GPU with the 256 by 192 pixels input size.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022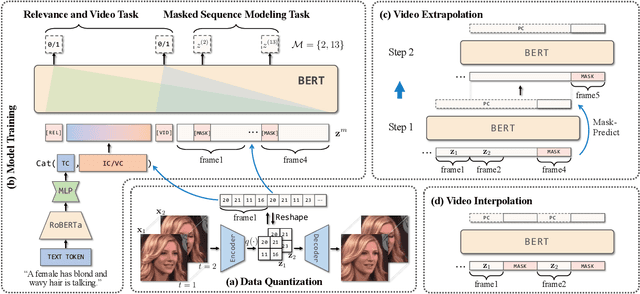
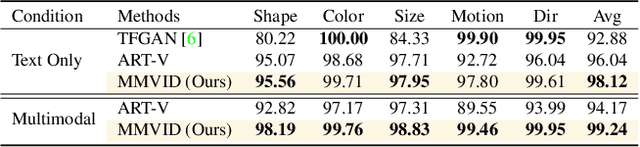


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
Color and Edge-Aware Adversarial Image Perturbations
Aug 28, 2020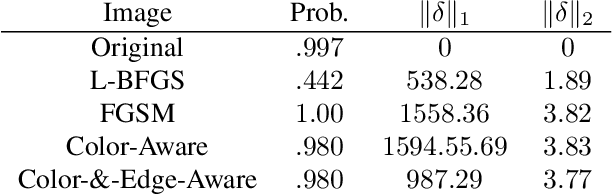



Adversarial perturbation of images, in which a source image is deliberately modified with the intent of causing a classifier to misclassify the image, provides important insight into the robustness of image classifiers. In this work we develop two new methods for constructing adversarial perturbations, both of which are motivated by minimizing human ability to detect changes between the perturbed and source image. The first of these, the Edge-Aware method, reduces the magnitude of perturbations permitted in smooth regions of an image where changes are more easily detected. Our second method, the Color-Aware method, performs the perturbation in a color space which accurately captures human ability to distinguish differences in colors, thus reducing the perceived change. The Color-Aware and Edge-Aware methods can also be implemented simultaneously, resulting in image perturbations which account for both human color perception and sensitivity to changes in homogeneous regions. Though Edge-Aware and Color-Aware modifications exist for many image perturbations techniques, we focus on easily computed perturbations. We empirically demonstrate that the Color-Aware and Edge-Aware perturbations we consider effectively cause misclassification, are less distinguishable to human perception, and are as easy to compute as the most efficient image perturbation techniques. Code and demo available at https://github.com/rbassett3/Color-and-Edge-Aware-Perturbations
Similarity Reasoning and Filtration for Image-Text Matching
Jan 05, 2021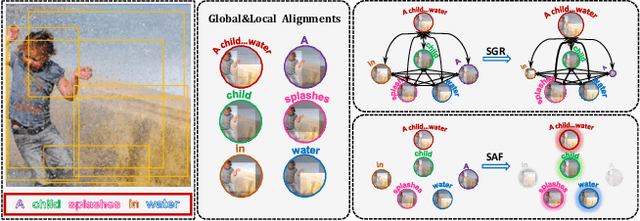
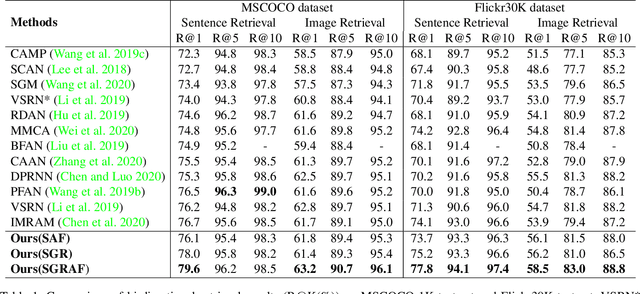
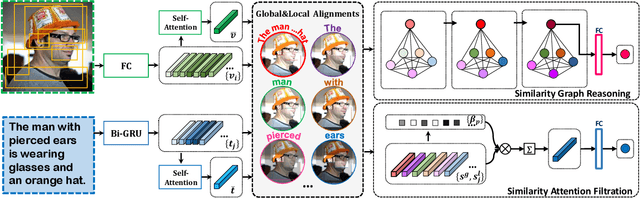
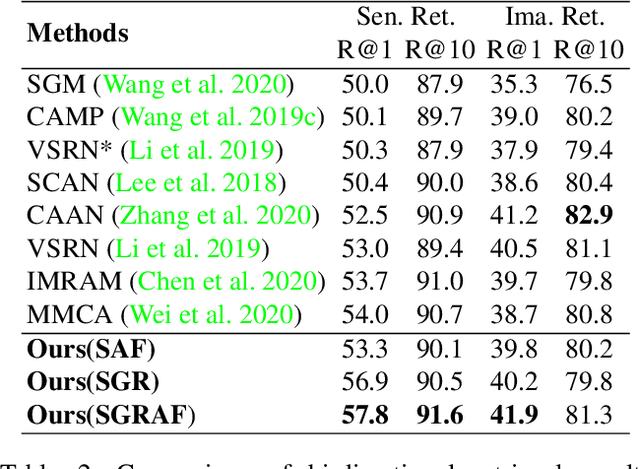
Image-text matching plays a critical role in bridging the vision and language, and great progress has been made by exploiting the global alignment between image and sentence, or local alignments between regions and words. However, how to make the most of these alignments to infer more accurate matching scores is still underexplored. In this paper, we propose a novel Similarity Graph Reasoning and Attention Filtration (SGRAF) network for image-text matching. Specifically, the vector-based similarity representations are firstly learned to characterize the local and global alignments in a more comprehensive manner, and then the Similarity Graph Reasoning (SGR) module relying on one graph convolutional neural network is introduced to infer relation-aware similarities with both the local and global alignments. The Similarity Attention Filtration (SAF) module is further developed to integrate these alignments effectively by selectively attending on the significant and representative alignments and meanwhile casting aside the interferences of non-meaningful alignments. We demonstrate the superiority of the proposed method with achieving state-of-the-art performances on the Flickr30K and MSCOCO datasets, and the good interpretability of SGR and SAF modules with extensive qualitative experiments and analyses.