 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Similarity Reasoning and Filtration for Image-Text Matching
Jan 05, 2021
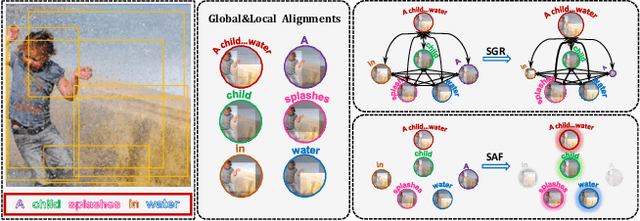
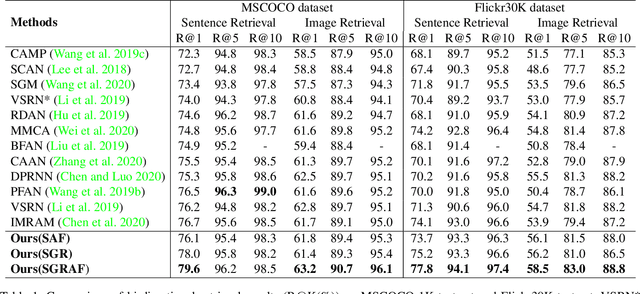
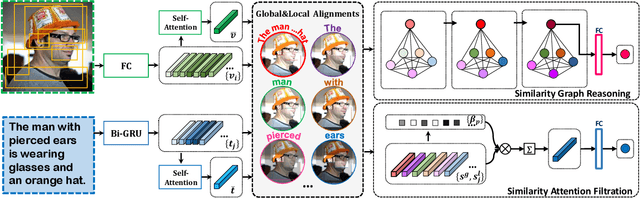
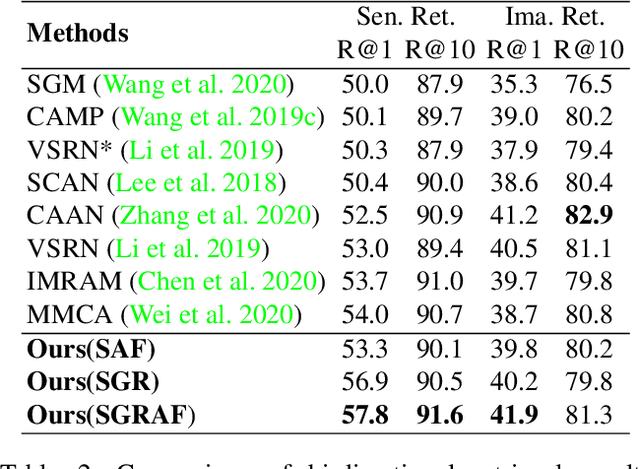
Image-text matching plays a critical role in bridging the vision and language, and great progress has been made by exploiting the global alignment between image and sentence, or local alignments between regions and words. However, how to make the most of these alignments to infer more accurate matching scores is still underexplored. In this paper, we propose a novel Similarity Graph Reasoning and Attention Filtration (SGRAF) network for image-text matching. Specifically, the vector-based similarity representations are firstly learned to characterize the local and global alignments in a more comprehensive manner, and then the Similarity Graph Reasoning (SGR) module relying on one graph convolutional neural network is introduced to infer relation-aware similarities with both the local and global alignments. The Similarity Attention Filtration (SAF) module is further developed to integrate these alignments effectively by selectively attending on the significant and representative alignments and meanwhile casting aside the interferences of non-meaningful alignments. We demonstrate the superiority of the proposed method with achieving state-of-the-art performances on the Flickr30K and MSCOCO datasets, and the good interpretability of SGR and SAF modules with extensive qualitative experiments and analyses.
Troubleshooting Blind Image Quality Models in the Wild
May 14, 2021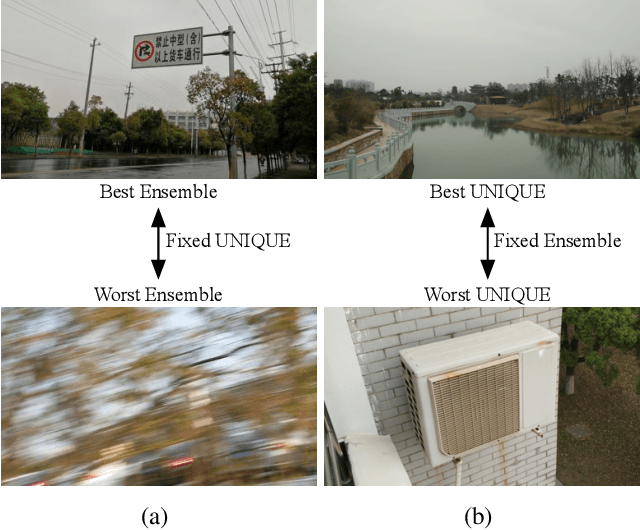
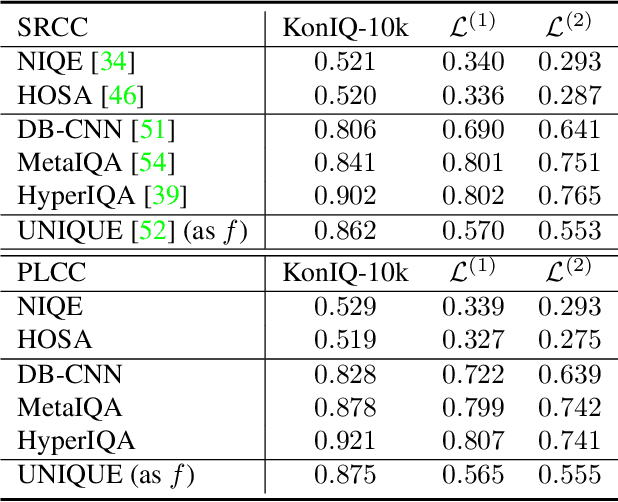
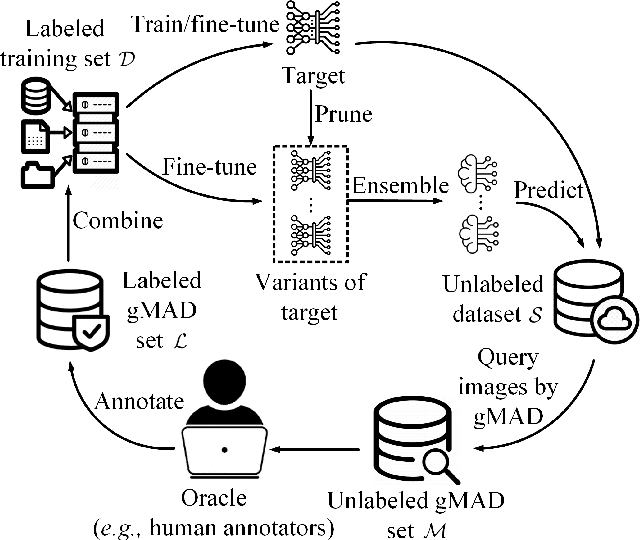

Recently, the group maximum differentiation competition (gMAD) has been used to improve blind image quality assessment (BIQA) models, with the help of full-reference metrics. When applying this type of approach to troubleshoot "best-performing" BIQA models in the wild, we are faced with a practical challenge: it is highly nontrivial to obtain stronger competing models for efficient failure-spotting. Inspired by recent findings that difficult samples of deep models may be exposed through network pruning, we construct a set of "self-competitors," as random ensembles of pruned versions of the target model to be improved. Diverse failures can then be efficiently identified via self-gMAD competition. Next, we fine-tune both the target and its pruned variants on the human-rated gMAD set. This allows all models to learn from their respective failures, preparing themselves for the next round of self-gMAD competition. Experimental results demonstrate that our method efficiently troubleshoots BIQA models in the wild with improved generalizability.
Physically Disentangled Representations
Apr 11, 2022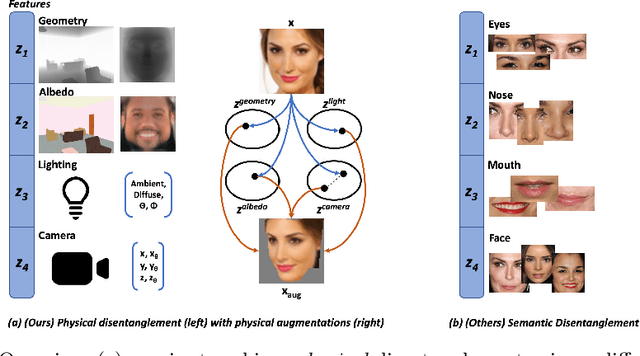
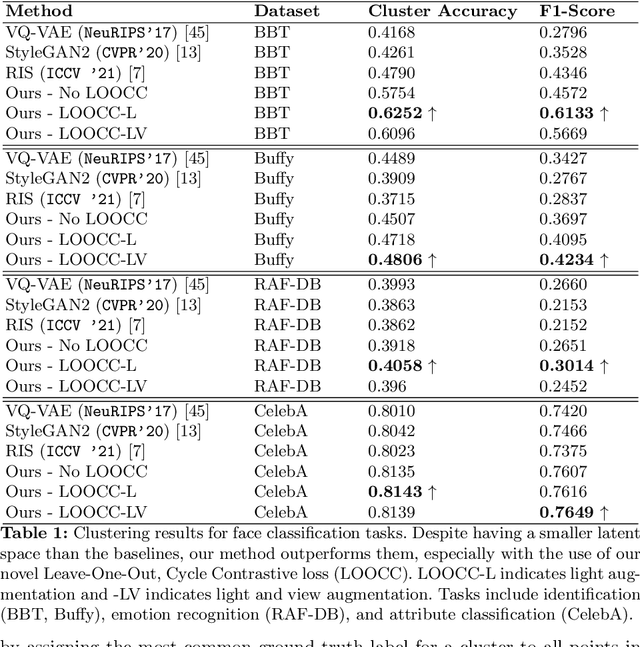
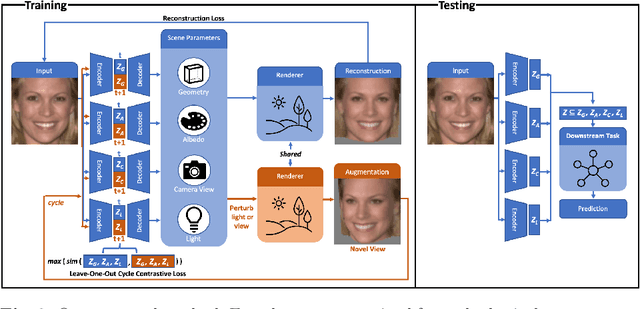
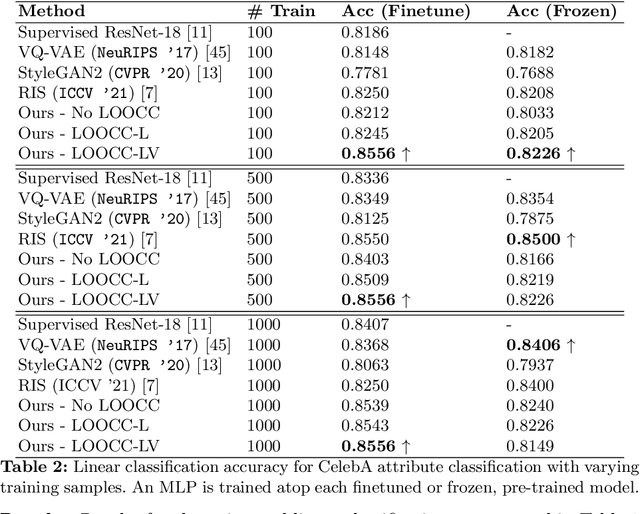
State-of-the-art methods in generative representation learning yield semantic disentanglement, but typically do not consider physical scene parameters, such as geometry, albedo, lighting, or camera. We posit that inverse rendering, a way to reverse the rendering process to recover scene parameters from an image, can also be used to learn physically disentangled representations of scenes without supervision. In this paper, we show the utility of inverse rendering in learning representations that yield improved accuracy on downstream clustering, linear classification, and segmentation tasks with the help of our novel Leave-One-Out, Cycle Contrastive loss (LOOCC), which improves disentanglement of scene parameters and robustness to out-of-distribution lighting and viewpoints. We perform a comparison of our method with other generative representation learning methods across a variety of downstream tasks, including face attribute classification, emotion recognition, identification, face segmentation, and car classification. Our physically disentangled representations yield higher accuracy than semantically disentangled alternatives across all tasks and by as much as 18%. We hope that this work will motivate future research in applying advances in inverse rendering and 3D understanding to representation learning.
On Representation Learning with Feedback
Feb 15, 2022
This note complements the author's recent paper "Robust representation learning with feedback for single image deraining" by providing heuristically theoretical explanations on the mechanism of representation learning with feedback, namely an essential merit of the works presented in this recent article. This note facilitates understanding of key points in the mechanism of representation learning with feedback.
Two-Stream Appearance Transfer Network for Person Image Generation
Nov 09, 2020
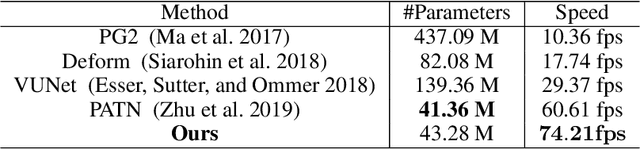
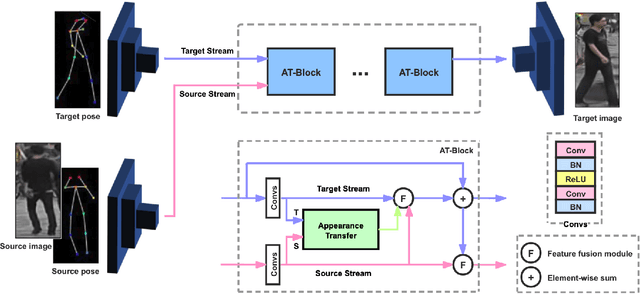

Pose guided person image generation means to generate a photo-realistic person image conditioned on an input person image and a desired pose. This task requires spatial manipulation of the source image according to the target pose. However, the generative adversarial networks (GANs) widely used for image generation and translation rely on spatially local and translation equivariant operators, i.e., convolution, pooling and unpooling, which cannot handle large image deformation. This paper introduces a novel two-stream appearance transfer network (2s-ATN) to address this challenge. It is a multi-stage architecture consisting of a source stream and a target stream. Each stage features an appearance transfer module and several two-stream feature fusion modules. The former finds the dense correspondence between the two-stream feature maps and then transfers the appearance information from the source stream to the target stream. The latter exchange local information between the two streams and supplement the non-local appearance transfer. Both quantitative and qualitative results indicate the proposed 2s-ATN can effectively handle large spatial deformation and occlusion while retaining the appearance details. It outperforms prior states of the art on two widely used benchmarks.
CFPNet-M: A Light-Weight Encoder-Decoder Based Network for Multimodal Biomedical Image Real-Time Segmentation
May 30, 2021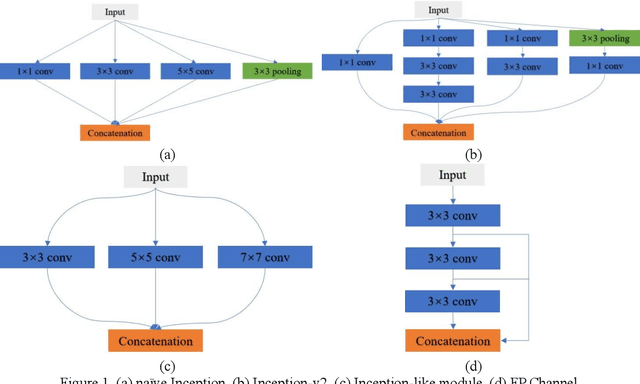
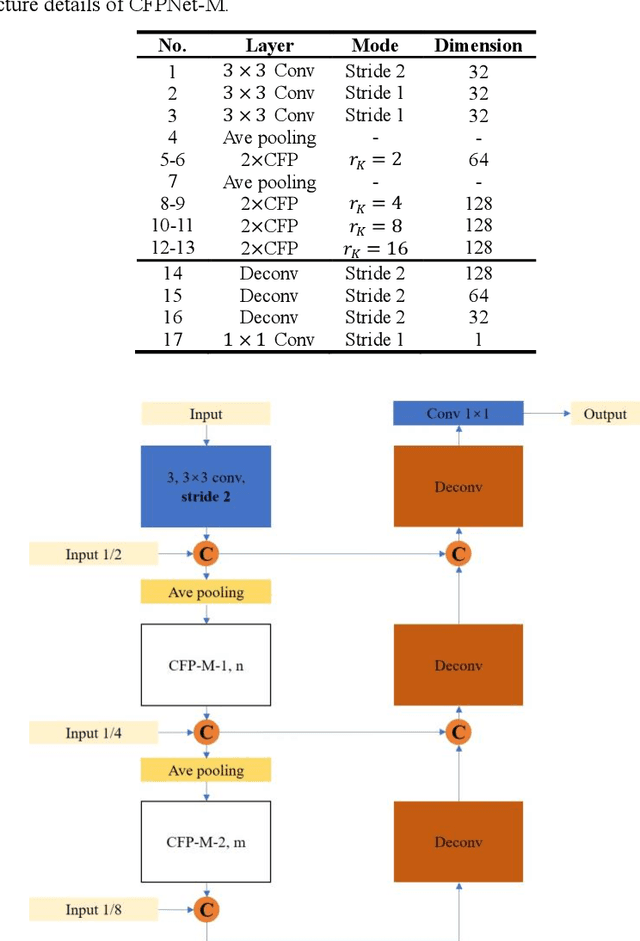
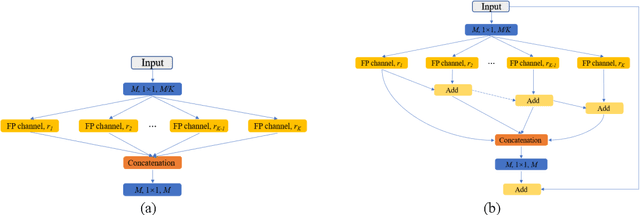

Currently, developments of deep learning techniques are providing instrumental to identify, classify, and quantify patterns in medical images. Segmentation is one of the important applications in medical image analysis. In this regard, U-Net is the predominant approach to medical image segmentation tasks. However, we found that those U-Net based models have limitations in several aspects, for example, millions of parameters in the U-Net consuming considerable computation resource and memory, lack of global information, and missing some tough objects. Therefore, we applied two modifications to improve the U-Net model: 1) designed and added the dilated channel-wise CNN module, 2) simplified the U shape network. Based on these two modifications, we proposed a novel light-weight architecture -- Channel-wise Feature Pyramid Network for Medicine (CFPNet-M). To evaluate our method, we selected five datasets with different modalities: thermography, electron microscopy, endoscopy, dermoscopy, and digital retinal images. And we compared its performance with several models having different parameter scales. This paper also involves our previous studies of DC-UNet and some commonly used light-weight neural networks. We applied the Tanimoto similarity instead of the Jaccard index for gray-level image measurements. By comparison, CFPNet-M achieves comparable segmentation results on all five medical datasets with only 0.65 million parameters, which is about 2% of U-Net, and 8.8 MB memory. Meanwhile, the inference speed can reach 80 FPS on a single RTX 2070Ti GPU with the 256 by 192 pixels input size.
Improving Clinical Diagnosis Performance with Automated X-ray Scan Quality Enhancement Algorithms
Jan 17, 2022In clinical diagnosis, diagnostic images that are obtained from the scanning devices serve as preliminary evidence for further investigation in the process of delivering quality healthcare. However, often the medical image may contain fault artifacts, introduced due to noise, blur and faulty equipment. The reason for this may be the low-quality or older scanning devices, the test environment or technicians lack of training etc; however, the net result is that the process of fast and reliable diagnosis is hampered. Resolving these issues automatically can have a significant positive impact in a hospital clinical workflow, where often, there is no other way but to work with faulty/older equipment or inadequately qualified radiology technicians. In this paper, automated image quality improvement approaches for adapted and benchmarked for the task of medical image super-resolution. During experimental evaluation on standard open datasets, the observations showed that certain algorithms perform better and show significant improvement in the diagnostic quality of medical scans, thereby enabling better visualization for human diagnostic purposes.
* Presented and Accepted in International Conference on Advances in Systems, Control and Computing (AISCC-2020) at Malaviya National Institute of Technology, Jaipur, India, February 27-28, 2020
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022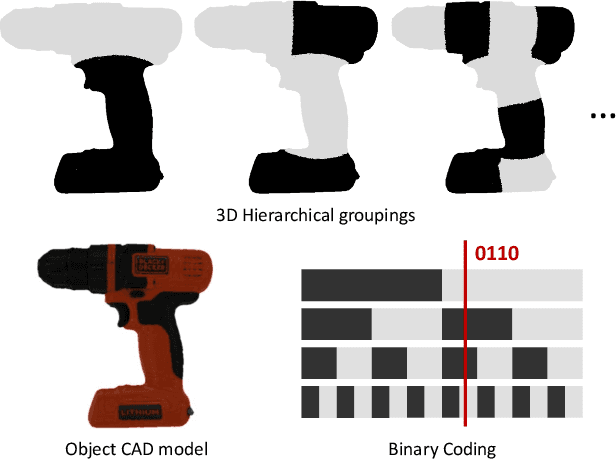
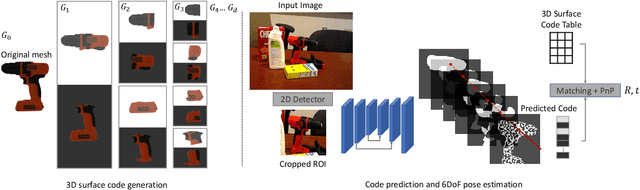

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
Calibrated Hyperspectral Image Reconstruction via Graph-based Self-Tuning Network
Dec 31, 2021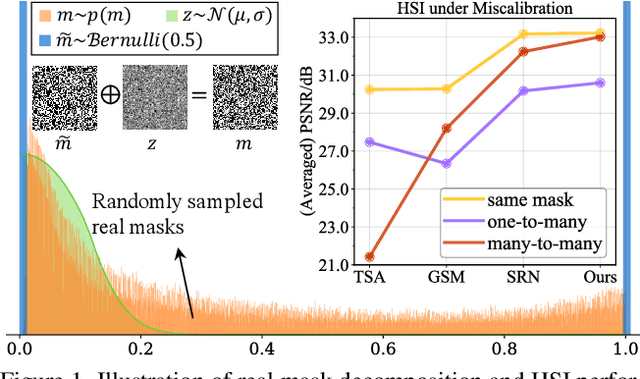
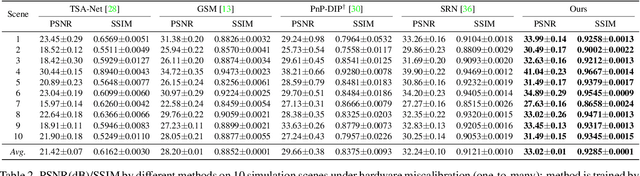
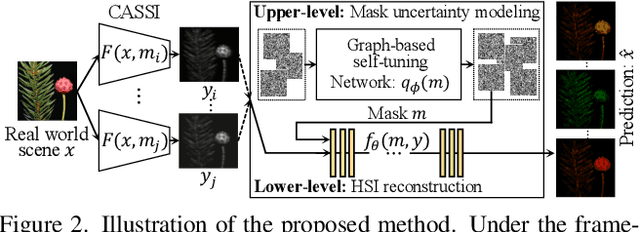
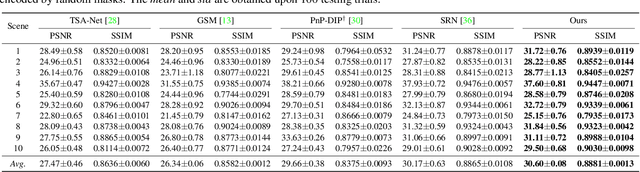
Recently, hyperspectral imaging (HSI) has attracted increasing research attention, especially for the ones based on a coded aperture snapshot spectral imaging (CASSI) system. Existing deep HSI reconstruction models are generally trained on paired data to retrieve original signals upon 2D compressed measurements given by a particular optical hardware mask in CASSI, during which the mask largely impacts the reconstruction performance and could work as a "model hyperparameter" governing on data augmentations. This mask-specific training style will lead to a hardware miscalibration issue, which sets up barriers to deploying deep HSI models among different hardware and noisy environments. To address this challenge, we introduce mask uncertainty for HSI with a complete variational Bayesian learning treatment and explicitly model it through a mask decomposition inspired by real hardware. Specifically, we propose a novel Graph-based Self-Tuning (GST) network to reason uncertainties adapting to varying spatial structures of masks among different hardware. Moreover, we develop a bilevel optimization framework to balance HSI reconstruction and uncertainty estimation, accounting for the hyperparameter property of masks. Extensive experimental results and model discussions validate the effectiveness (over 33/30 dB) of the proposed GST method under two miscalibration scenarios and demonstrate a highly competitive performance compared with the state-of-the-art well-calibrated methods. Our code and pre-trained model are available at https://github.com/Jiamian Wang/mask_uncertainty_spectral_SCI
Autoencoder for Synthetic to Real Generalization: From Simple to More Complex Scenes
Apr 01, 2022

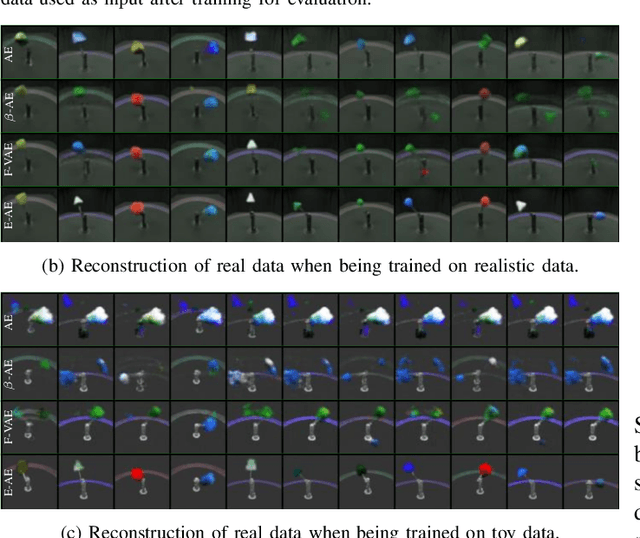
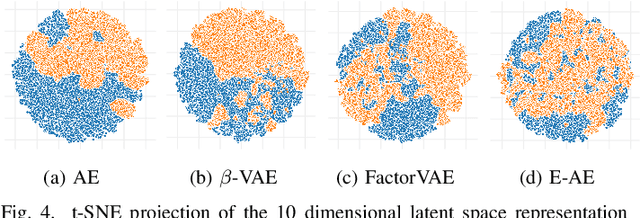
Learning on synthetic data and transferring the resulting properties to their real counterparts is an important challenge for reducing costs and increasing safety in machine learning. In this work, we focus on autoencoder architectures and aim at learning latent space representations that are invariant to inductive biases caused by the domain shift between simulated and real images showing the same scenario. We train on synthetic images only, present approaches to increase generalizability and improve the preservation of the semantics to real datasets of increasing visual complexity. We show that pre-trained feature extractors (e.g. VGG) can be sufficient for generalization on images of lower complexity, but additional improvements are required for visually more complex scenes. To this end, we demonstrate a new sampling technique, which matches semantically important parts of the image, while randomizing the other parts, leads to salient feature extraction and a neglection of unimportant parts. This helps the generalization to real data and we further show that our approach outperforms fine-tuned classification models.