 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Plug-and-Play Methods for Integrating Physical and Learned Models in Computational Imaging
Mar 31, 2022



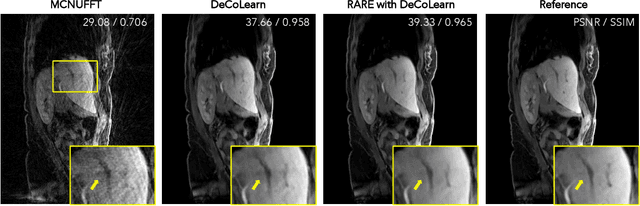
Plug-and-Play Priors (PnP) is one of the most widely-used frameworks for solving computational imaging problems through the integration of physical models and learned models. PnP leverages high-fidelity physical sensor models and powerful machine learning methods for prior modeling of data to provide state-of-the-art reconstruction algorithms. PnP algorithms alternate between minimizing a data-fidelity term to promote data consistency and imposing a learned regularizer in the form of an image denoiser. Recent highly-successful applications of PnP algorithms include bio-microscopy, computerized tomography, magnetic resonance imaging, and joint ptycho-tomography. This article presents a unified and principled review of PnP by tracing its roots, describing its major variations, summarizing main results, and discussing applications in computational imaging. We also point the way towards further developments by discussing recent results on equilibrium equations that formulate the problem associated with PnP algorithms.
Tomographic Muon Imaging of the Great Pyramid of Giza
Feb 16, 2022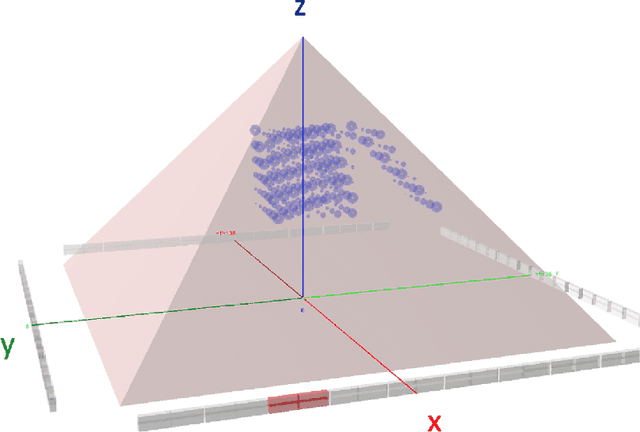
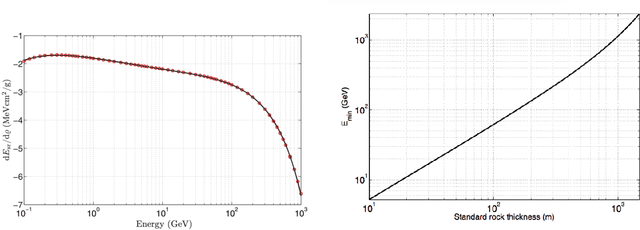
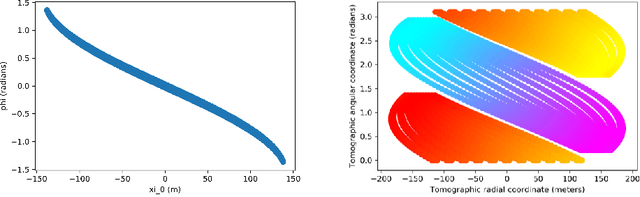
The pyramids of the Giza plateau have fascinated visitors since ancient times and are the last of the Seven Wonders of the ancient world still standing. It has been half a century since Luiz Alvarez and his team used cosmic-ray muon imaging to look for hidden chambers in Khafres Pyramid. Advances in instrumentation for High-Energy Physics (HEP) allowed a new survey, ScanPyramids, to make important new discoveries at the Great Pyramid (Khufu) utilizing the same basic technique that the Alvarez team used, but now with modern instrumentation. The Exploring the Great Pyramid Mission plans to field a very-large muon telescope system that will be transformational with respect to the field of cosmic-ray muon imaging. We plan to field a telescope system that has upwards of 100 times the sensitivity of the equipment that has recently been used at the Great Pyramid, will image muons from nearly all angles and will, for the first time, produce a true tomographic image of such a large structure.
Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
Apr 16, 2021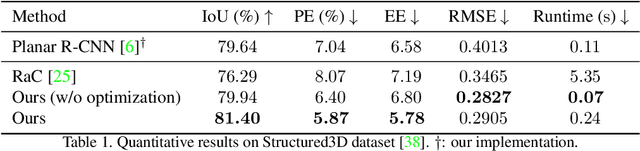
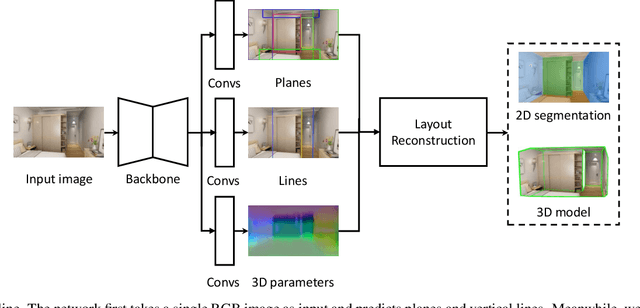
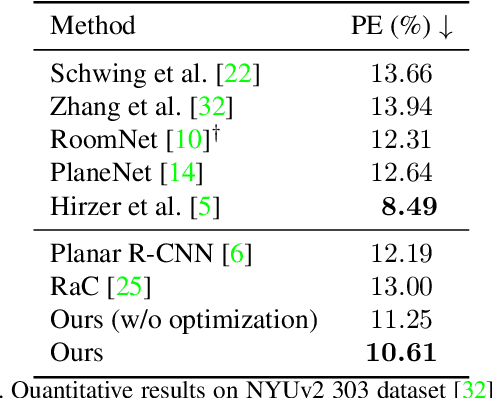

Single-image room layout reconstruction aims to reconstruct the enclosed 3D structure of a room from a single image. Most previous work relies on the cuboid-shape prior. This paper considers a more general indoor assumption, i.e., the room layout consists of a single ceiling, a single floor, and several vertical walls. To this end, we first employ Convolutional Neural Networks to detect planes and vertical lines between adjacent walls. Meanwhile, estimating the 3D parameters for each plane. Then, a simple yet effective geometric reasoning method is adopted to achieve room layout reconstruction. Furthermore, we optimize the 3D plane parameters to reconstruct a geometrically consistent room layout between planes and lines. The experimental results on public datasets validate the effectiveness and efficiency of our method.
Class-Incremental Learning for Action Recognition in Videos
Mar 25, 2022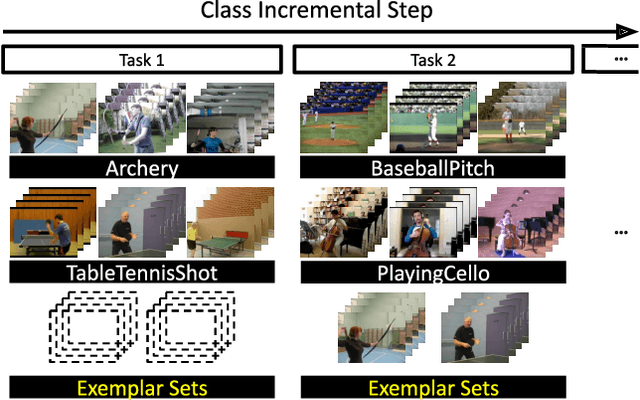
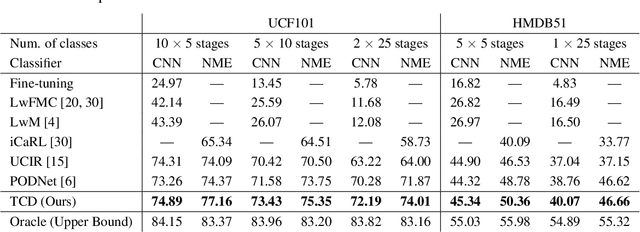

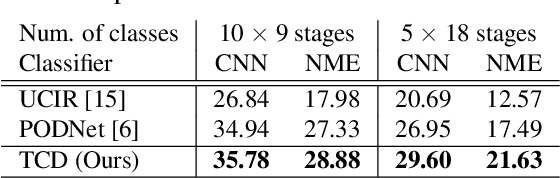
We tackle catastrophic forgetting problem in the context of class-incremental learning for video recognition, which has not been explored actively despite the popularity of continual learning. Our framework addresses this challenging task by introducing time-channel importance maps and exploiting the importance maps for learning the representations of incoming examples via knowledge distillation. We also incorporate a regularization scheme in our objective function, which encourages individual features obtained from different time steps in a video to be uncorrelated and eventually improves accuracy by alleviating catastrophic forgetting. We evaluate the proposed approach on brand-new splits of class-incremental action recognition benchmarks constructed upon the UCF101, HMDB51, and Something-Something V2 datasets, and demonstrate the effectiveness of our algorithm in comparison to the existing continual learning methods that are originally designed for image data.
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Feb 21, 2022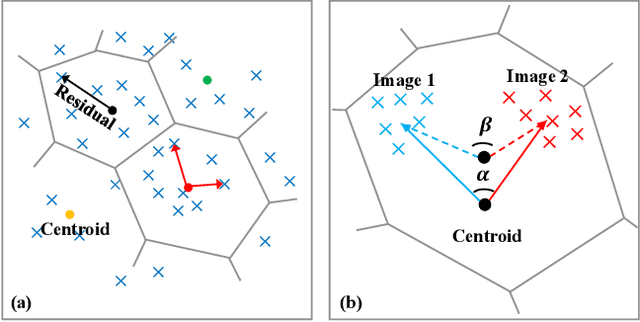
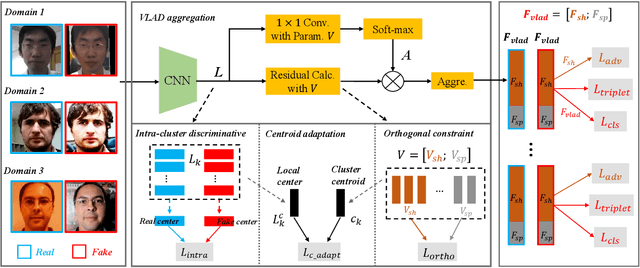
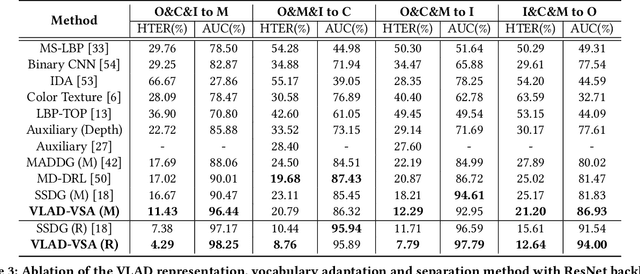
For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.
Image reconstruction in light-sheet microscopy: spatially varying deconvolution and mixed noise
Aug 08, 2021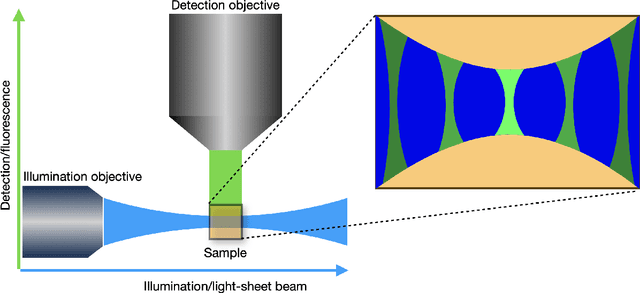
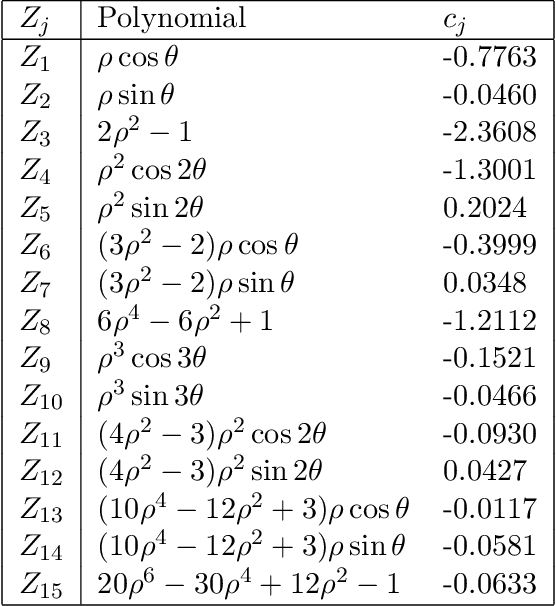

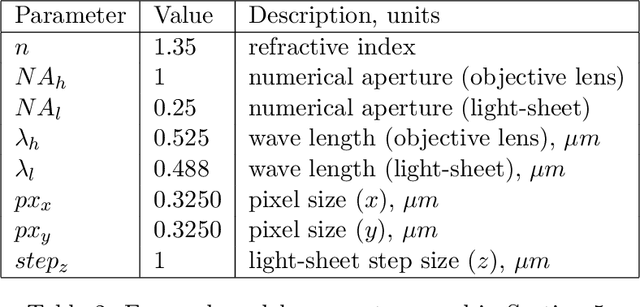
We study the problem of deconvolution for light-sheet microscopy, where the data is corrupted by spatially varying blur and a combination of Poisson and Gaussian noise. The spatial variation of the point spread function (PSF) of a light-sheet microscope is determined by the interaction between the excitation sheet and the detection objective PSF. First, we introduce a model of the image formation process that incorporates this interaction, therefore capturing the main characteristics of this imaging modality. Then, we formulate a variational model that accounts for the combination of Poisson and Gaussian noise through a data fidelity term consisting of the infimal convolution of the single noise fidelities, first introduced in L. Calatroni et al. "Infimal convolution of data discrepancies for mixed noise removal", SIAM Journal on Imaging Sciences 10.3 (2017), 1196-1233. We establish convergence rates in a Bregman distance under a source condition for the infimal convolution fidelity and a discrepancy principle for choosing the value of the regularisation parameter. The inverse problem is solved by applying the primal-dual hybrid gradient (PDHG) algorithm in a novel way. Finally, numerical experiments performed on both simulated and real data show superior reconstruction results in comparison with other methods.
Troubleshooting Blind Image Quality Models in the Wild
May 14, 2021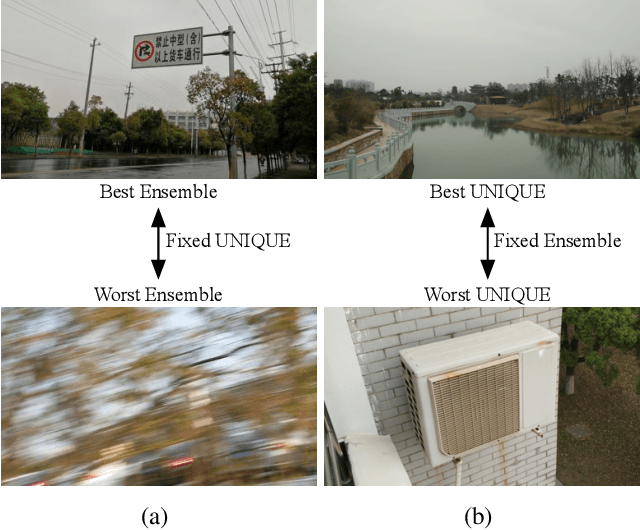
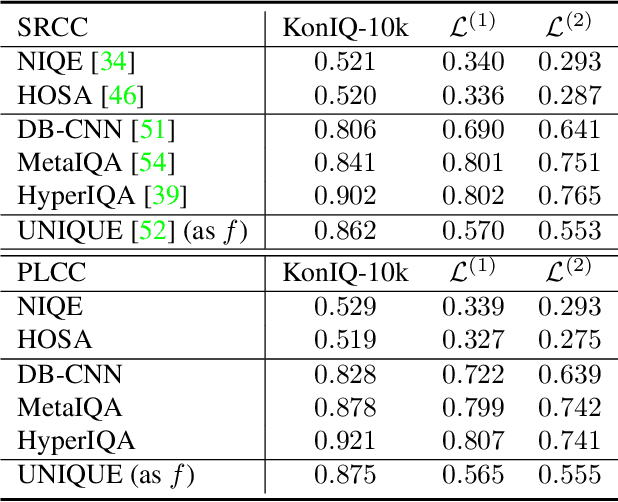
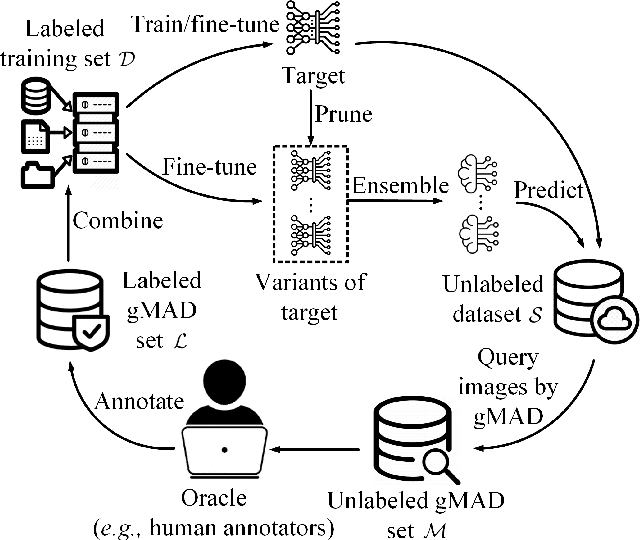

Recently, the group maximum differentiation competition (gMAD) has been used to improve blind image quality assessment (BIQA) models, with the help of full-reference metrics. When applying this type of approach to troubleshoot "best-performing" BIQA models in the wild, we are faced with a practical challenge: it is highly nontrivial to obtain stronger competing models for efficient failure-spotting. Inspired by recent findings that difficult samples of deep models may be exposed through network pruning, we construct a set of "self-competitors," as random ensembles of pruned versions of the target model to be improved. Diverse failures can then be efficiently identified via self-gMAD competition. Next, we fine-tune both the target and its pruned variants on the human-rated gMAD set. This allows all models to learn from their respective failures, preparing themselves for the next round of self-gMAD competition. Experimental results demonstrate that our method efficiently troubleshoots BIQA models in the wild with improved generalizability.
Revisiting Consistency Regularization for Semi-supervised Change Detection in Remote Sensing Images
Apr 21, 2022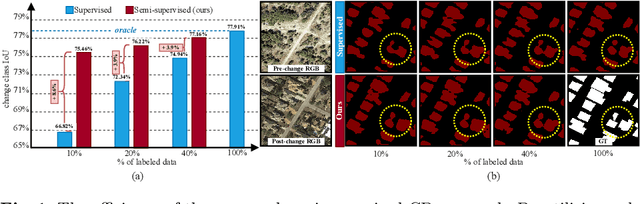
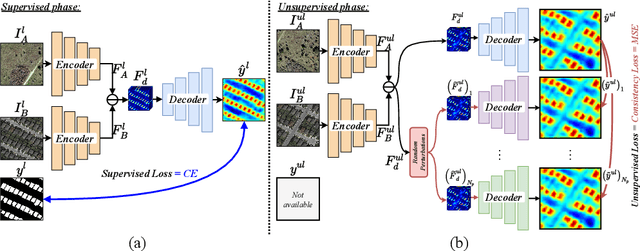
Remote-sensing (RS) Change Detection (CD) aims to detect "changes of interest" from co-registered bi-temporal images. The performance of existing deep supervised CD methods is attributed to the large amounts of annotated data used to train the networks. However, annotating large amounts of remote sensing images is labor-intensive and expensive, particularly with bi-temporal images, as it requires pixel-wise comparisons by a human expert. On the other hand, we often have access to unlimited unlabeled multi-temporal RS imagery thanks to ever-increasing earth observation programs. In this paper, we propose a simple yet effective way to leverage the information from unlabeled bi-temporal images to improve the performance of CD approaches. More specifically, we propose a semi-supervised CD model in which we formulate an unsupervised CD loss in addition to the supervised Cross-Entropy (CE) loss by constraining the output change probability map of a given unlabeled bi-temporal image pair to be consistent under the small random perturbations applied on the deep feature difference map that is obtained by subtracting their latent feature representations. Experiments conducted on two publicly available CD datasets show that the proposed semi-supervised CD method can reach closer to the performance of supervised CD even with access to as little as 10% of the annotated training data. Code available at https://github.com/wgcban/SemiCD
SuperNet in Neural Architecture Search: A Taxonomic Survey
Apr 08, 2022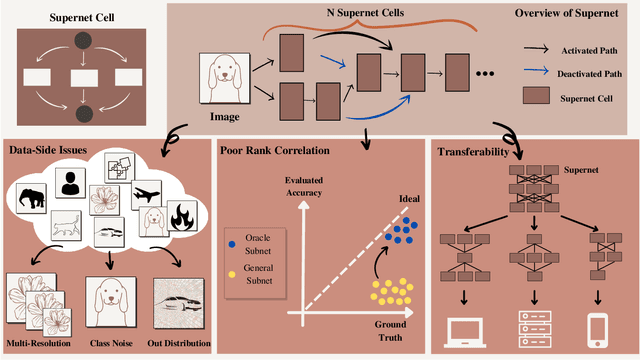
Deep Neural Networks (DNN) have made significant progress in a wide range of visual recognition tasks such as image classification, object detection, and semantic segmentation. The evolution of convolutional architectures has led to better performance by incurring expensive computational costs. In addition, network design has become a difficult task, which is labor-intensive and requires a high level of domain knowledge. To mitigate such issues, there have been studies for a variety of neural architecture search methods that automatically search for optimal architectures, achieving models with impressive performance that outperform human-designed counterparts. This survey aims to provide an overview of existing works in this field of research and specifically focus on the supernet optimization that builds a neural network that assembles all the architectures as its sub models by using weight sharing. We aim to accomplish that by categorizing supernet optimization by proposing them as solutions to the common challenges found in the literature: data-side optimization, poor rank correlation alleviation, and transferable NAS for a number of deployment scenarios.
Picosecond Hyperspectral Fringe Pattern Projection for 3D Surface Measurement
Mar 18, 2022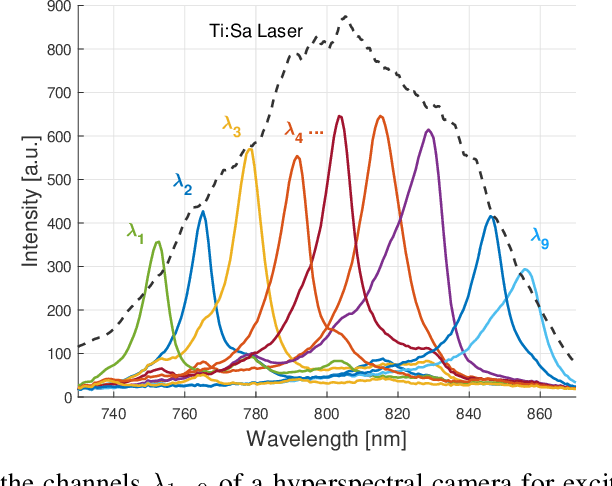
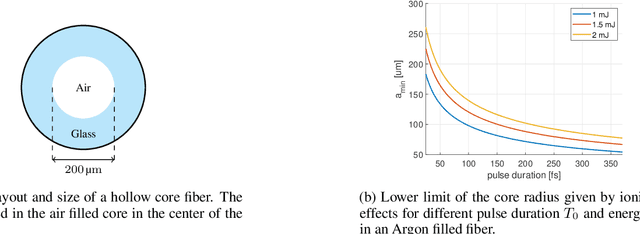
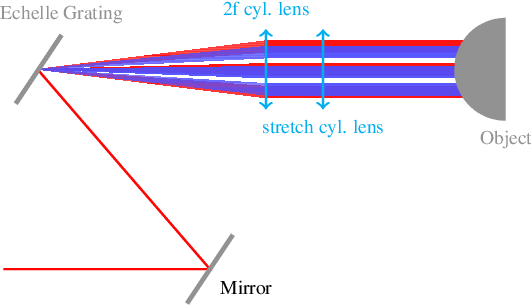

Active stereovision systems for the 3D measurement of surfaces rely on the sequential projection of different fringe patterns onto the scene to robustly and accurately generate 3D surface data. This limits the temporal resolution to the time by which a sufficiently high number of patterns can be projected and recorded. By encoding patterns spectrally and recording them with a hyperspectral imager, it is possible to record several patterns in a single image, limiting the temporal resolution to only the duration of the illumination. A picosecond 3D surface measurement was demonstrated using a high pulse energy femtosecond Ti:Sa laser, spectrally broadened in a hollow core fiber, and two hyperspectral cameras recording the patterns generated by diffraction at an Echelle grating.