 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tomographic Muon Imaging of the Great Pyramid of Giza
Feb 16, 2022
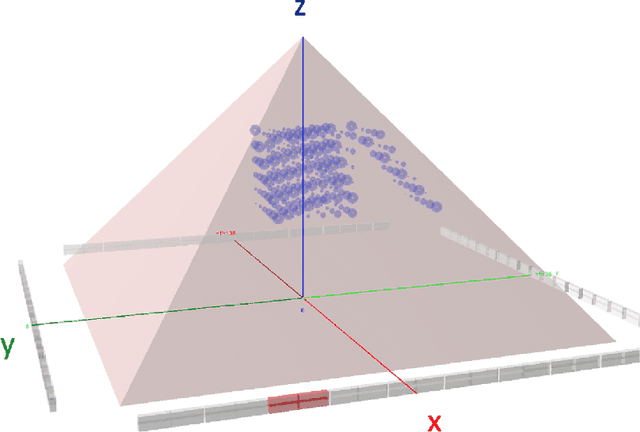
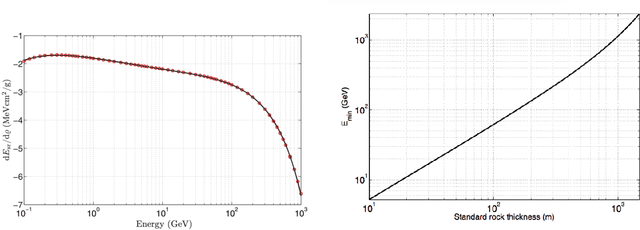
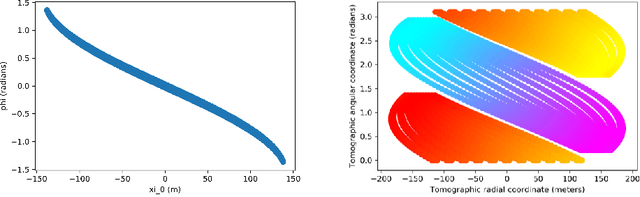
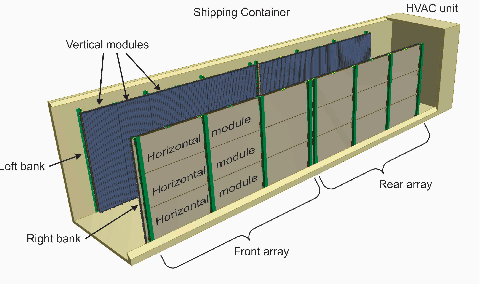
The pyramids of the Giza plateau have fascinated visitors since ancient times and are the last of the Seven Wonders of the ancient world still standing. It has been half a century since Luiz Alvarez and his team used cosmic-ray muon imaging to look for hidden chambers in Khafres Pyramid. Advances in instrumentation for High-Energy Physics (HEP) allowed a new survey, ScanPyramids, to make important new discoveries at the Great Pyramid (Khufu) utilizing the same basic technique that the Alvarez team used, but now with modern instrumentation. The Exploring the Great Pyramid Mission plans to field a very-large muon telescope system that will be transformational with respect to the field of cosmic-ray muon imaging. We plan to field a telescope system that has upwards of 100 times the sensitivity of the equipment that has recently been used at the Great Pyramid, will image muons from nearly all angles and will, for the first time, produce a true tomographic image of such a large structure.
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Feb 21, 2022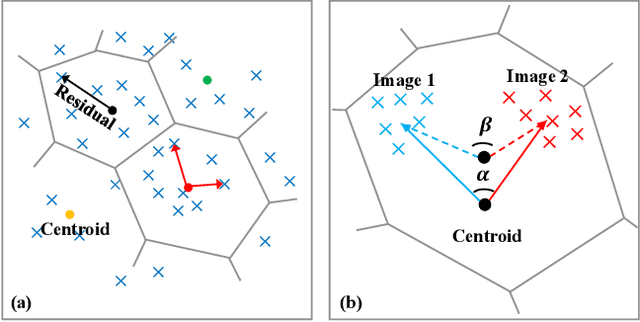
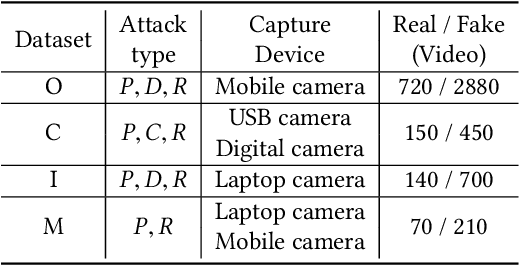
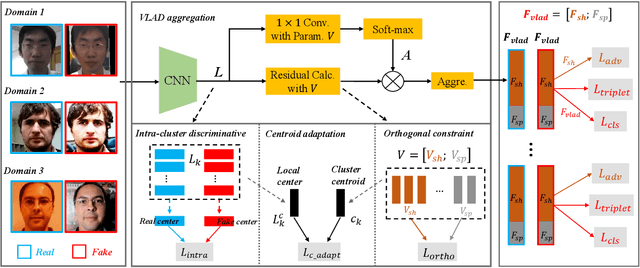
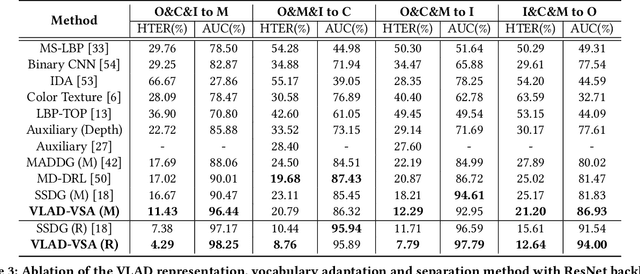
For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.
Feature robustness and sex differences in medical imaging: a case study in MRI-based Alzheimer's disease detection
Apr 12, 2022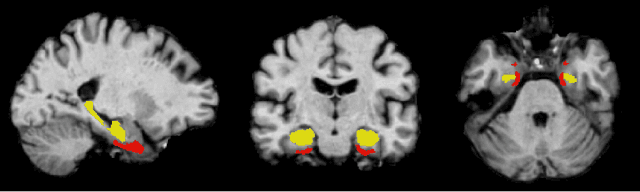

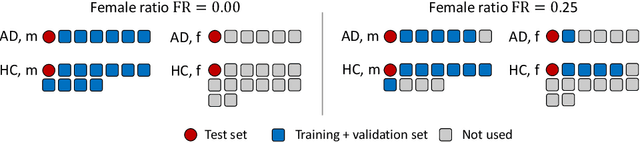
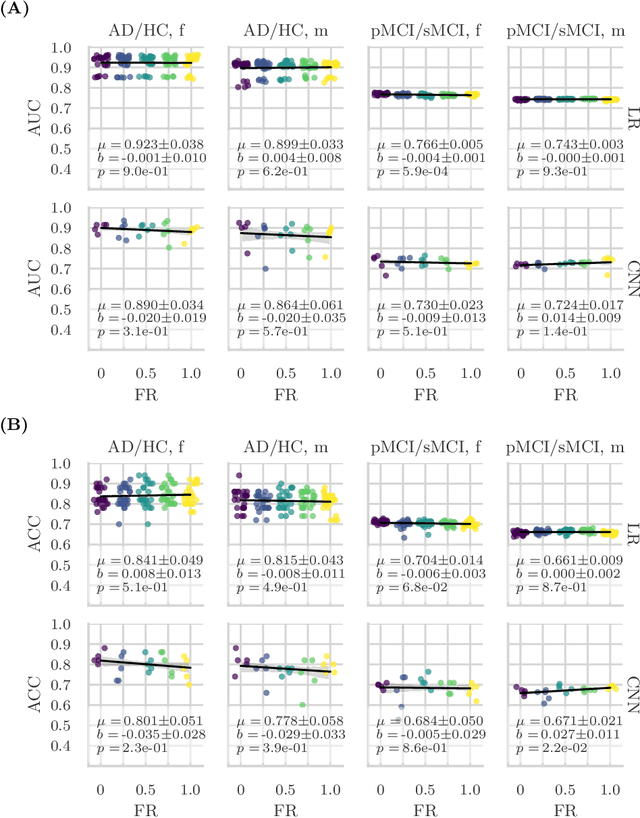
Convolutional neural networks have enabled significant improvements in medical image-based disease classification. It has, however, become increasingly clear that these models are susceptible to performance degradation due to spurious correlations and dataset shifts, which may lead to underperformance on underrepresented patient groups, among other problems. In this paper, we compare two classification schemes on the ADNI MRI dataset: a very simple logistic regression model that uses manually selected volumetric features as inputs, and a convolutional neural network trained on 3D MRI data. We assess the robustness of the trained models in the face of varying dataset splits, training set sex composition, and stage of disease. In contrast to earlier work on diagnosing lung diseases based on chest x-ray data, we do not find a strong dependence of model performance for male and female test subjects on the sex composition of the training dataset. Moreover, in our analysis, the low-dimensional model with manually selected features outperforms the 3D CNN, thus emphasizing the need for automatic robust feature extraction methods and the value of manual feature specification (based on prior knowledge) for robustness.
Generating Scientific Articles with Machine Learning
Mar 30, 2022
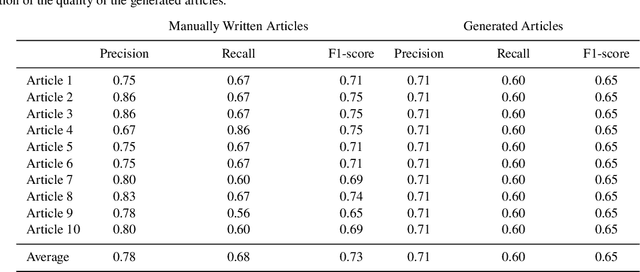
In recent years, the field of machine learning has seen rapid growth, with applications in a variety of domains, including image recognition, natural language processing, and predictive modeling. In this paper, we explore the application of machine learning to the generation of scientific articles. We present a method for using machine learning to generate scientific articles based on a data set of scientific papers. The method uses a machine-learning algorithm to learn the structure of a scientific article and a set of training data consisting of scientific papers. The machine-learning algorithm is used to generate a scientific article based on the data set of scientific papers. We evaluate the performance of the method by comparing the generated article to a set of manually written articles. The results show that the machine-generated article is of similar quality to the manually written articles.
Learning Instance-Specific Adaptation for Cross-Domain Segmentation
Mar 30, 2022
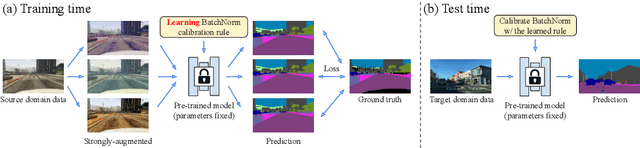
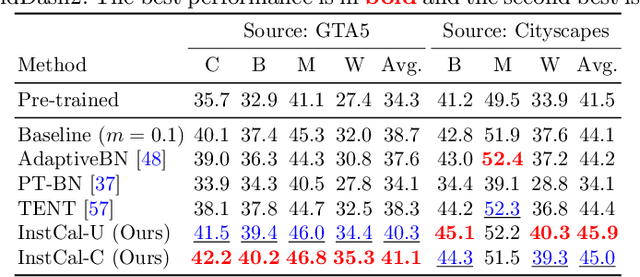

We propose a test-time adaptation method for cross-domain image segmentation. Our method is simple: Given a new unseen instance at test time, we adapt a pre-trained model by conducting instance-specific BatchNorm (statistics) calibration. Our approach has two core components. First, we replace the manually designed BatchNorm calibration rule with a learnable module. Second, we leverage strong data augmentation to simulate random domain shifts for learning the calibration rule. In contrast to existing domain adaptation methods, our method does not require accessing the target domain data at training time or conducting computationally expensive test-time model training/optimization. Equipping our method with models trained by standard recipes achieves significant improvement, comparing favorably with several state-of-the-art domain generalization and one-shot unsupervised domain adaptation approaches. Combining our method with the domain generalization methods further improves performance, reaching a new state of the art.
Collaborative Transformers for Grounded Situation Recognition
Mar 30, 2022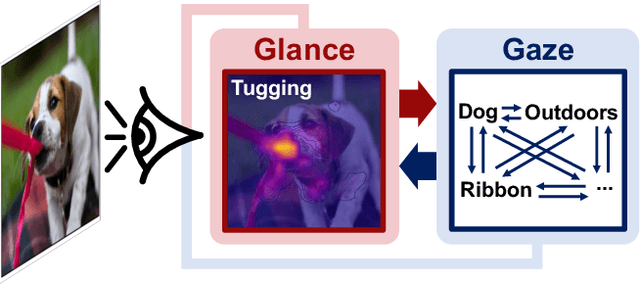
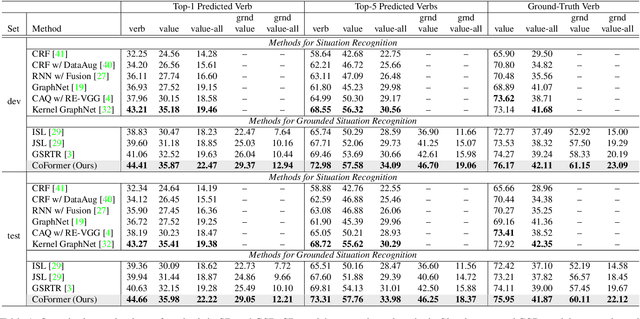
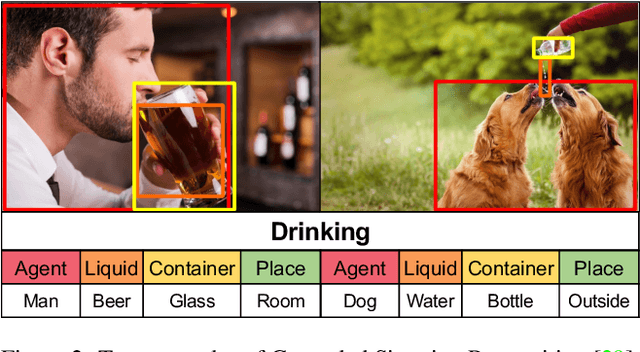
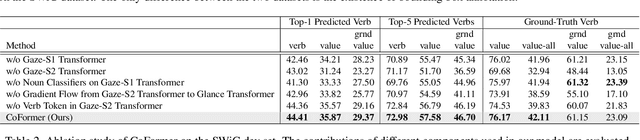
Grounded situation recognition is the task of predicting the main activity, entities playing certain roles within the activity, and bounding-box groundings of the entities in the given image. To effectively deal with this challenging task, we introduce a novel approach where the two processes for activity classification and entity estimation are interactive and complementary. To implement this idea, we propose Collaborative Glance-Gaze TransFormer (CoFormer) that consists of two modules: Glance transformer for activity classification and Gaze transformer for entity estimation. Glance transformer predicts the main activity with the help of Gaze transformer that analyzes entities and their relations, while Gaze transformer estimates the grounded entities by focusing only on the entities relevant to the activity predicted by Glance transformer. Our CoFormer achieves the state of the art in all evaluation metrics on the SWiG dataset. Training code and model weights are available at https://github.com/jhcho99/CoFormer.
Chordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks
Apr 02, 2022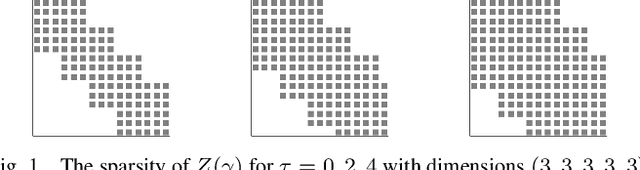
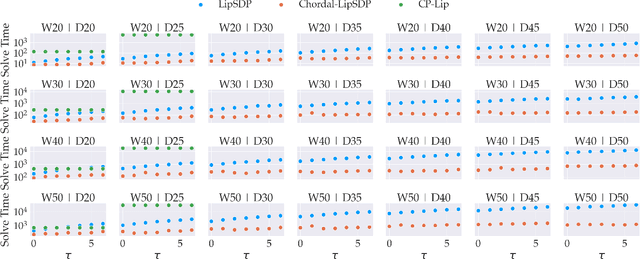
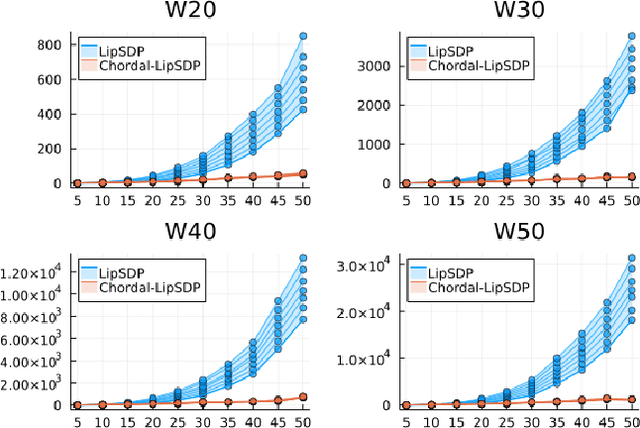
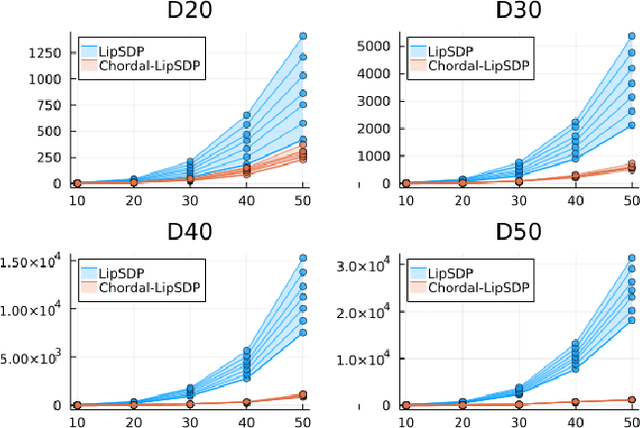
Lipschitz constants of neural networks allow for guarantees of robustness in image classification, safety in controller design, and generalizability beyond the training data. As calculating Lipschitz constants is NP-hard, techniques for estimating Lipschitz constants must navigate the trade-off between scalability and accuracy. In this work, we significantly push the scalability frontier of a semidefinite programming technique known as LipSDP while achieving zero accuracy loss. We first show that LipSDP has chordal sparsity, which allows us to derive a chordally sparse formulation that we call Chordal-LipSDP. The key benefit is that the main computational bottleneck of LipSDP, a large semidefinite constraint, is now decomposed into an equivalent collection of smaller ones: allowing Chordal-LipSDP to outperform LipSDP particularly as the network depth grows. Moreover, our formulation uses a tunable sparsity parameter that enables one to gain tighter estimates without incurring a significant computational cost. We illustrate the scalability of our approach through extensive numerical experiments.
Unitary rotation of pixellated polychromatic images
Mar 11, 2022
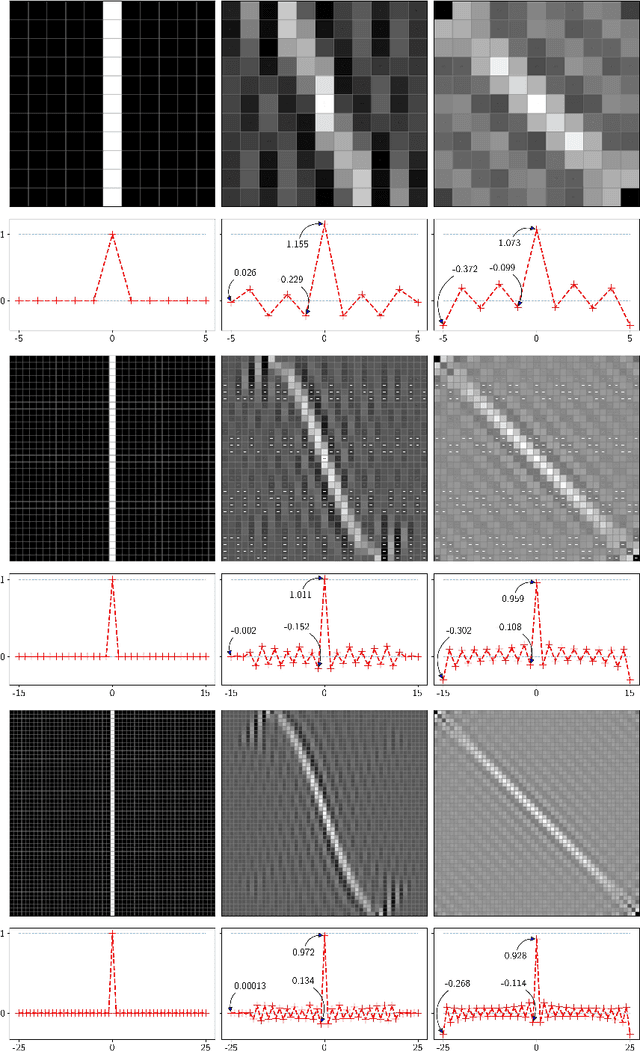
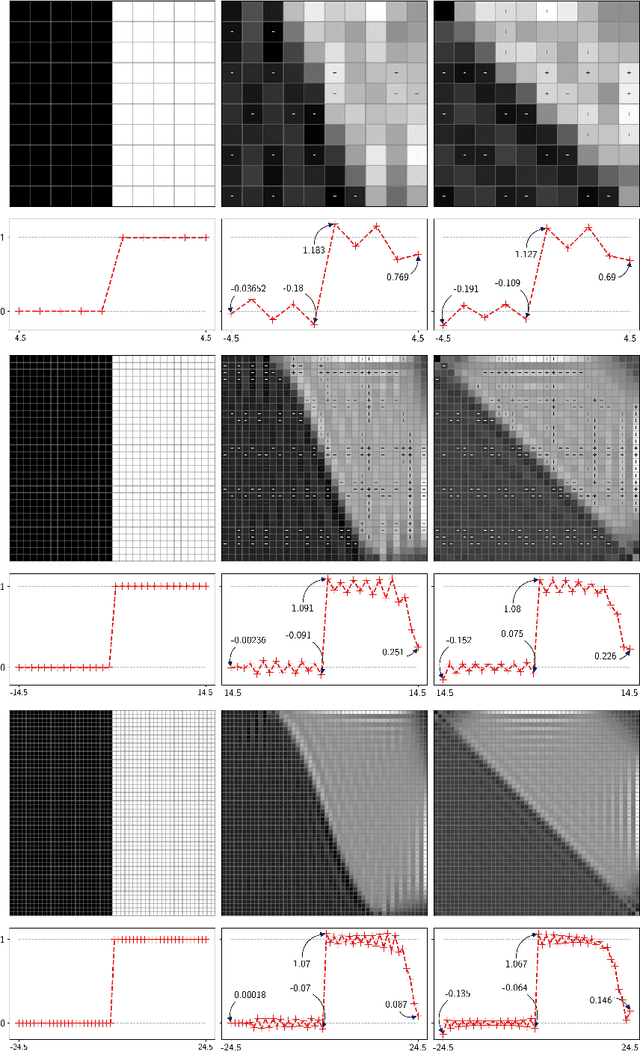

Unitary rotations of polychromatic images on finite two-dimensional pixellated screens provide invertibility, group composition, and thus conservation of information. Rotations have been applied on monochromatic image data sets, where we now examine closer the Gibbs-like oscillations that appear due to discrete "discontinuities" of the input images under unitary transformations. Extended to three-color images we examine here the display of color at the pixels where, due to the oscillations, some pixel color values may fall outside their required common numerical range [0, 1], between absence and saturation of the red, green, and blue formant color images.
Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
Oct 08, 2021
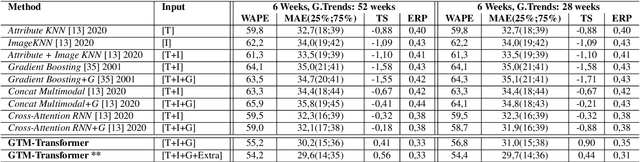
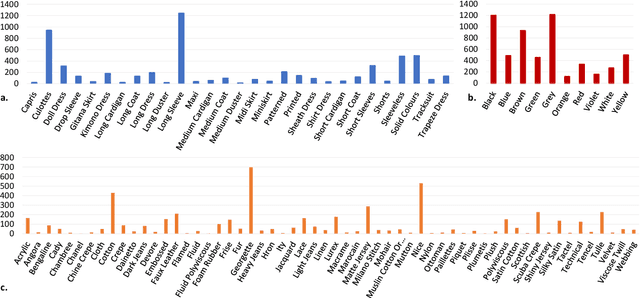
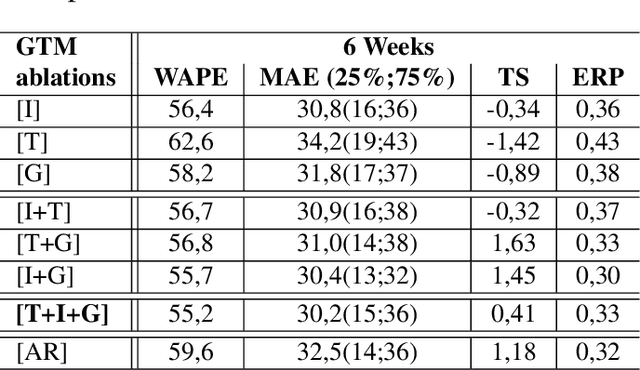
This paper investigates the effectiveness of systematically probing Google Trendsagainst textual translations of visual aspects as exogenous knowledge to predict the sales of brand-new fashion items, where past sales data is not available, but only an image and few metadata are available. In particular, we propose GTM-Transformer, standing for Google Trends Multimodal Transformer, whose encoder works on the representation of the exogenous time series, while the decoder forecasts the sales using the Google Trends encoding, and the available visual and metadata information. Our model works in a non-autoregressive manner, avoiding the compounding effect of the first-step errors. As a second contribution, we present the VISUELLE dataset, which is the first publicly available dataset for the task of new fashion product sales forecasting, containing the sales of 5577 new products sold between 2016-2019, derived from genuine historical data ofNunalie, an Italian fast-fashion company. Our dataset is equipped with images of products, metadata, related sales, and associated Google Trends. We use VISUELLE to compare our approach against state-of-the-art alternatives and numerous baselines, showing that GTM-Transformer is the most accurate in terms of both percentage and absolute error. It is worth noting that the addition of exogenous knowledge boosts the forecasting accuracy by 1.5% WAPE wise, showing the importance of exploiting Google Trends. The code and dataset are both available at https://github.com/HumaticsLAB/GTM-Transformer.
A Novel Upsampling and Context Convolution for Image Semantic Segmentation
Mar 20, 2021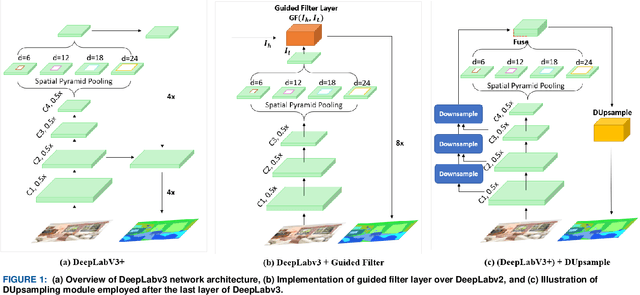
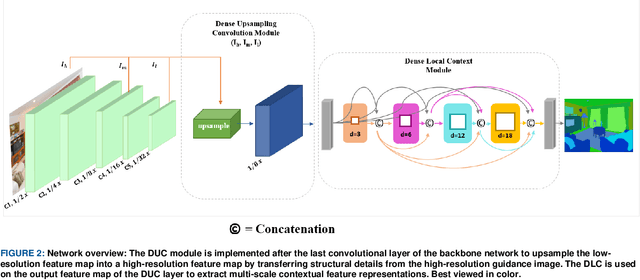
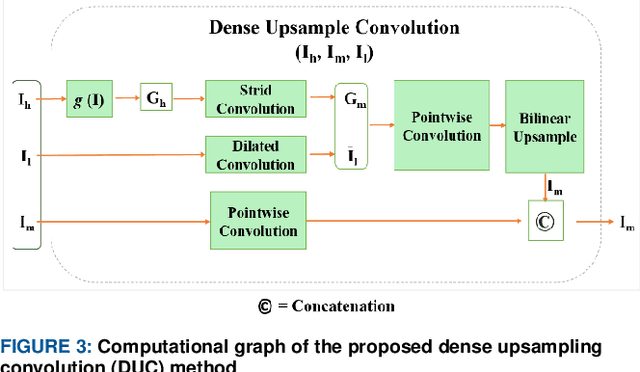
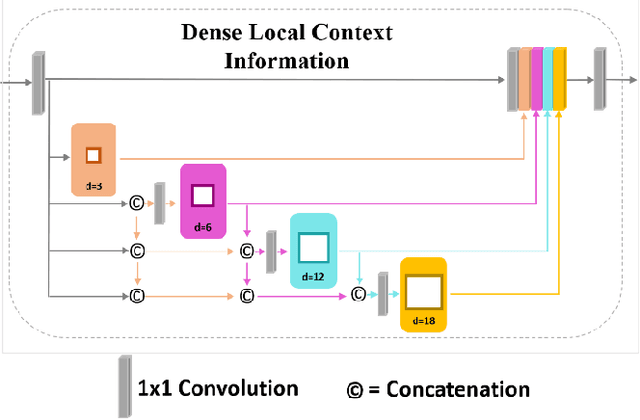
Semantic segmentation, which refers to pixel-wise classification of an image, is a fundamental topic in computer vision owing to its growing importance in robot vision and autonomous driving industries. It provides rich information about objects in the scene such as object boundary, category, and location. Recent methods for semantic segmentation often employ an encoder-decoder structure using deep convolutional neural networks. The encoder part extracts feature of the image using several filters and pooling operations, whereas the decoder part gradually recovers the low-resolution feature maps of the encoder into a full input resolution feature map for pixel-wise prediction. However, the encoder-decoder variants for semantic segmentation suffer from severe spatial information loss, caused by pooling operations or convolutions with stride, and does not consider the context in the scene. In this paper, we propose a dense upsampling convolution method based on guided filtering to effectively preserve the spatial information of the image in the network. We further propose a novel local context convolution method that not only covers larger-scale objects in the scene but covers them densely for precise object boundary delineation. Theoretical analyses and experimental results on several benchmark datasets verify the effectiveness of our method. Qualitatively, our approach delineates object boundaries at a level of accuracy that is beyond the current excellent methods. Quantitatively, we report a new record of 82.86% and 81.62% of pixel accuracy on ADE20K and Pascal-Context benchmark datasets, respectively. In comparison with the state-of-the-art methods, the proposed method offers promising improvements.
* 11 pages, published in sensors journal