 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OpticalDR: A Deep Optical Imaging Model for Privacy-Protective Depression Recognition
Feb 29, 2024
Depression Recognition (DR) poses a considerable challenge, especially in the context of the growing concerns surrounding privacy. Traditional automatic diagnosis of DR technology necessitates the use of facial images, undoubtedly expose the patient identity features and poses privacy risks. In order to mitigate the potential risks associated with the inappropriate disclosure of patient facial images, we design a new imaging system to erase the identity information of captured facial images while retain disease-relevant features. It is irreversible for identity information recovery while preserving essential disease-related characteristics necessary for accurate DR. More specifically, we try to record a de-identified facial image (erasing the identifiable features as much as possible) by a learnable lens, which is optimized in conjunction with the following DR task as well as a range of face analysis related auxiliary tasks in an end-to-end manner. These aforementioned strategies form our final Optical deep Depression Recognition network (OpticalDR). Experiments on CelebA, AVEC 2013, and AVEC 2014 datasets demonstrate that our OpticalDR has achieved state-of-the-art privacy protection performance with an average AUC of 0.51 on popular facial recognition models, and competitive results for DR with MAE/RMSE of 7.53/8.48 on AVEC 2013 and 7.89/8.82 on AVEC 2014, respectively.
Privacy-Preserving Autoencoder for Collaborative Object Detection
Feb 29, 2024Privacy is a crucial concern in collaborative machine vision where a part of a Deep Neural Network (DNN) model runs on the edge, and the rest is executed on the cloud. In such applications, the machine vision model does not need the exact visual content to perform its task. Taking advantage of this potential, private information could be removed from the data insofar as it does not significantly impair the accuracy of the machine vision system. In this paper, we present an autoencoder-style network integrated within an object detection pipeline, which generates a latent representation of the input image that preserves task-relevant information while removing private information. Our approach employs an adversarial training strategy that not only removes private information from the bottleneck of the autoencoder but also promotes improved compression efficiency for feature channels coded by conventional codecs like VVC-Intra. We assess the proposed system using a realistic evaluation framework for privacy, directly measuring face and license plate recognition accuracy. Experimental results show that our proposed method is able to reduce the bitrate significantly at the same object detection accuracy compared to coding the input images directly, while keeping the face and license plate recognition accuracy on the images recovered from the bottleneck features low, implying strong privacy protection.
Continuous Sign Language Recognition Based on Motor attention mechanism and frame-level Self-distillation
Feb 29, 2024Changes in facial expression, head movement, body movement and gesture movement are remarkable cues in sign language recognition, and most of the current continuous sign language recognition(CSLR) research methods mainly focus on static images in video sequences at the frame-level feature extraction stage, while ignoring the dynamic changes in the images. In this paper, we propose a novel motor attention mechanism to capture the distorted changes in local motion regions during sign language expression, and obtain a dynamic representation of image changes. And for the first time, we apply the self-distillation method to frame-level feature extraction for continuous sign language, which improves the feature expression without increasing the computational resources by self-distilling the features of adjacent stages and using the higher-order features as teachers to guide the lower-order features. The combination of the two constitutes our proposed holistic model of CSLR Based on motor attention mechanism and frame-level Self-Distillation (MAM-FSD), which improves the inference ability and robustness of the model. We conduct experiments on three publicly available datasets, and the experimental results show that our proposed method can effectively extract the sign language motion information in videos, improve the accuracy of CSLR and reach the state-of-the-art level.
Artwork Explanation in Large-scale Vision Language Models
Feb 29, 2024

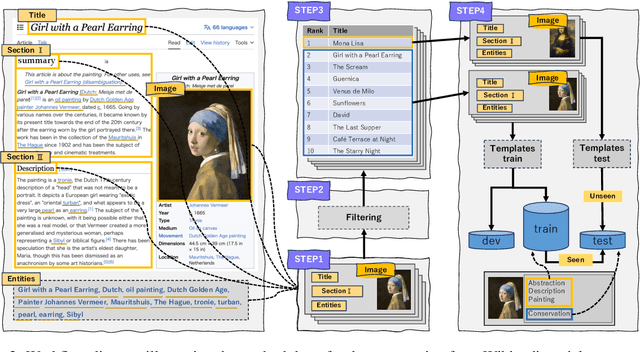
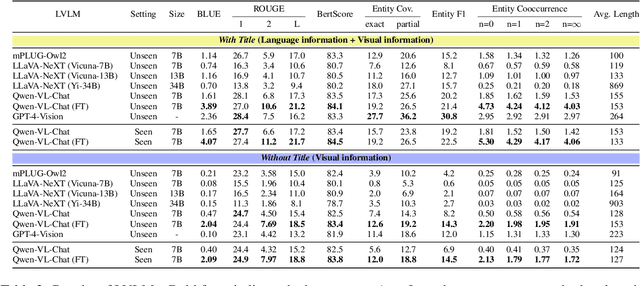
Large-scale vision-language models (LVLMs) output text from images and instructions, demonstrating advanced capabilities in text generation and comprehension. However, it has not been clarified to what extent LVLMs understand the knowledge necessary for explaining images, the complex relationships between various pieces of knowledge, and how they integrate these understandings into their explanations. To address this issue, we propose a new task: the artwork explanation generation task, along with its evaluation dataset and metric for quantitatively assessing the understanding and utilization of knowledge about artworks. This task is apt for image description based on the premise that LVLMs are expected to have pre-existing knowledge of artworks, which are often subjects of wide recognition and documented information. It consists of two parts: generating explanations from both images and titles of artworks, and generating explanations using only images, thus evaluating the LVLMs' language-based and vision-based knowledge. Alongside, we release a training dataset for LVLMs to learn explanations that incorporate knowledge about artworks. Our findings indicate that LVLMs not only struggle with integrating language and visual information but also exhibit a more pronounced limitation in acquiring knowledge from images alone. The datasets (ExpArt=Explain Artworks) are available at https://huggingface.co/datasets/naist-nlp/ExpArt.
Outline-Guided Object Inpainting with Diffusion Models
Feb 26, 2024Instance segmentation datasets play a crucial role in training accurate and robust computer vision models. However, obtaining accurate mask annotations to produce high-quality segmentation datasets is a costly and labor-intensive process. In this work, we show how this issue can be mitigated by starting with small annotated instance segmentation datasets and augmenting them to effectively obtain a sizeable annotated dataset. We achieve that by creating variations of the available annotated object instances in a way that preserves the provided mask annotations, thereby resulting in new image-mask pairs to be added to the set of annotated images. Specifically, we generate new images using a diffusion-based inpainting model to fill out the masked area with a desired object class by guiding the diffusion through the object outline. We show that the object outline provides a simple, but also reliable and convenient training-free guidance signal for the underlying inpainting model that is often sufficient to fill out the mask with an object of the correct class without further text guidance and preserve the correspondence between generated images and the mask annotations with high precision. Our experimental results reveal that our method successfully generates realistic variations of object instances, preserving their shape characteristics while introducing diversity within the augmented area. We also show that the proposed method can naturally be combined with text guidance and other image augmentation techniques.
BLO-SAM: Bi-level Optimization Based Overfitting-Preventing Finetuning of SAM
Feb 26, 2024The Segment Anything Model (SAM), a foundation model pretrained on millions of images and segmentation masks, has significantly advanced semantic segmentation, a fundamental task in computer vision. Despite its strengths, SAM encounters two major challenges. Firstly, it struggles with segmenting specific objects autonomously, as it relies on users to manually input prompts like points or bounding boxes to identify targeted objects. Secondly, SAM faces challenges in excelling at specific downstream tasks, like medical imaging, due to a disparity between the distribution of its pretraining data, which predominantly consists of general-domain images, and the data used in downstream tasks. Current solutions to these problems, which involve finetuning SAM, often lead to overfitting, a notable issue in scenarios with very limited data, like in medical imaging. To overcome these limitations, we introduce BLO-SAM, which finetunes SAM based on bi-level optimization (BLO). Our approach allows for automatic image segmentation without the need for manual prompts, by optimizing a learnable prompt embedding. Furthermore, it significantly reduces the risk of overfitting by training the model's weight parameters and the prompt embedding on two separate subsets of the training dataset, each at a different level of optimization. We apply BLO-SAM to diverse semantic segmentation tasks in general and medical domains. The results demonstrate BLO-SAM's superior performance over various state-of-the-art image semantic segmentation methods.
SynArtifact: Classifying and Alleviating Artifacts in Synthetic Images via Vision-Language Model
Feb 28, 2024In the rapidly evolving area of image synthesis, a serious challenge is the presence of complex artifacts that compromise perceptual realism of synthetic images. To alleviate artifacts and improve quality of synthetic images, we fine-tune Vision-Language Model (VLM) as artifact classifier to automatically identify and classify a wide range of artifacts and provide supervision for further optimizing generative models. Specifically, we develop a comprehensive artifact taxonomy and construct a dataset of synthetic images with artifact annotations for fine-tuning VLM, named SynArtifact-1K. The fine-tuned VLM exhibits superior ability of identifying artifacts and outperforms the baseline by 25.66%. To our knowledge, this is the first time such end-to-end artifact classification task and solution have been proposed. Finally, we leverage the output of VLM as feedback to refine the generative model for alleviating artifacts. Visualization results and user study demonstrate that the quality of images synthesized by the refined diffusion model has been obviously improved.
OccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
Feb 28, 2024This technical report presents our solution, "occTransformer" for the 3D occupancy prediction track in the autonomous driving challenge at CVPR 2023. Our method builds upon the strong baseline BEVFormer and improves its performance through several simple yet effective techniques. Firstly, we employed data augmentation to increase the diversity of the training data and improve the model's generalization ability. Secondly, we used a strong image backbone to extract more informative features from the input data. Thirdly, we incorporated a 3D unet head to better capture the spatial information of the scene. Fourthly, we added more loss functions to better optimize the model. Additionally, we used an ensemble approach with the occ model BevDet and SurroundOcc to further improve the performance. Most importantly, we integrated 3D detection model StreamPETR to enhance the model's ability to detect objects in the scene. Using these methods, our solution achieved 49.23 miou on the 3D occupancy prediction track in the autonomous driving challenge.
Downstream Task Guided Masking Learning in Masked Autoencoders Using Multi-Level Optimization
Feb 28, 2024Masked Autoencoder (MAE) is a notable method for self-supervised pretraining in visual representation learning. It operates by randomly masking image patches and reconstructing these masked patches using the unmasked ones. A key limitation of MAE lies in its disregard for the varying informativeness of different patches, as it uniformly selects patches to mask. To overcome this, some approaches propose masking based on patch informativeness. However, these methods often do not consider the specific requirements of downstream tasks, potentially leading to suboptimal representations for these tasks. In response, we introduce the Multi-level Optimized Mask Autoencoder (MLO-MAE), a novel framework that leverages end-to-end feedback from downstream tasks to learn an optimal masking strategy during pretraining. Our experimental findings highlight MLO-MAE's significant advancements in visual representation learning. Compared to existing methods, it demonstrates remarkable improvements across diverse datasets and tasks, showcasing its adaptability and efficiency. Our code is available at: https://github.com/Alexiland/MLOMAE
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Feb 06, 2024Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster