 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A survey in Adversarial Defences and Robustness in NLP
Apr 12, 2022
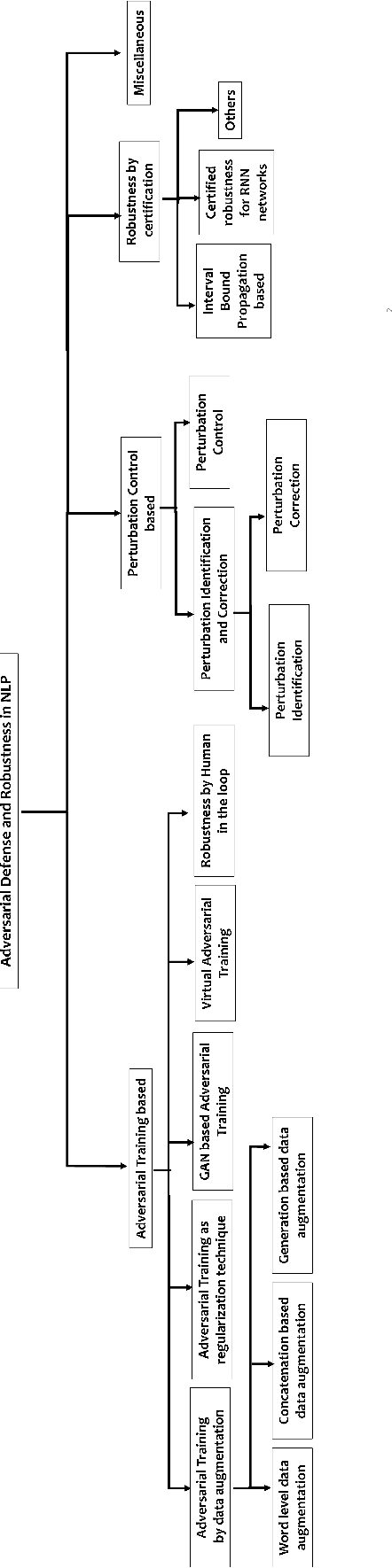
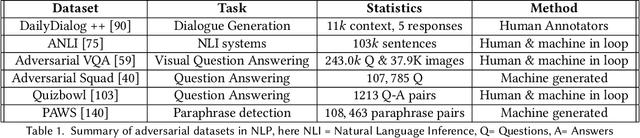
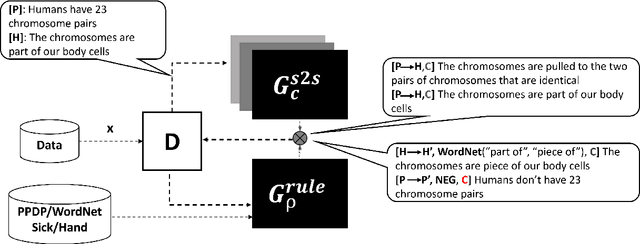

In recent years, it has been seen that deep neural networks are lacking robustness and are likely to break in case of adversarial perturbations in input data. Strong adversarial attacks are proposed by various authors for computer vision and Natural Language Processing (NLP). As a counter-effort, several defense mechanisms are also proposed to save these networks from failing. In contrast with image data, generating adversarial attacks and defending these models is not easy in NLP because of the discrete nature of the text data. However, numerous methods for adversarial defense are proposed of late, for different NLP tasks such as text classification, named entity recognition, natural language inferencing, etc. These methods are not just used for defending neural networks from adversarial attacks, but also used as a regularization mechanism during training, saving the model from overfitting. The proposed survey is an attempt to review different methods proposed for adversarial defenses in NLP in the recent past by proposing a novel taxonomy. This survey also highlights the fragility of the advanced deep neural networks in NLP and the challenges in defending them.
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
Jan 14, 2021
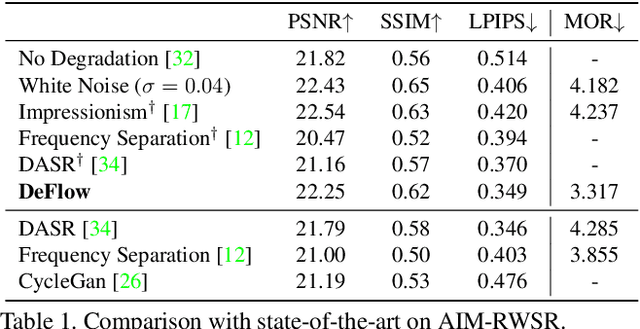
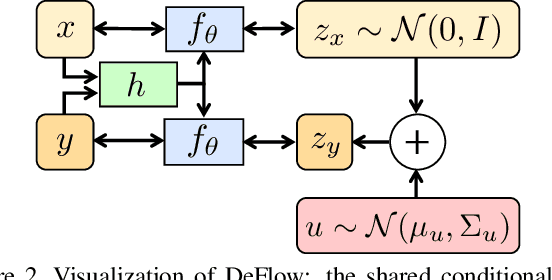
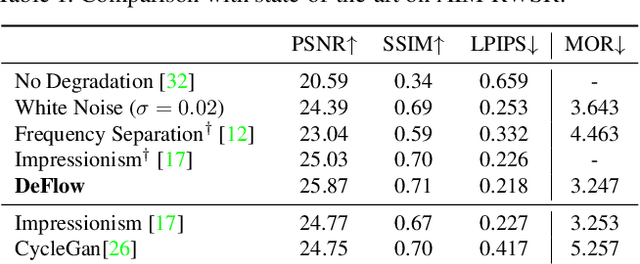
The difficulty of obtaining paired data remains a major bottleneck for learning image restoration and enhancement models for real-world applications. Current strategies aim to synthesize realistic training data by modeling noise and degradations that appear in real-world settings. We propose DeFlow, a method for learning stochastic image degradations from unpaired data. Our approach is based on a novel unpaired learning formulation for conditional normalizing flows. We model the degradation process in the latent space of a shared flow encoder-decoder network. This allows us to learn the conditional distribution of a noisy image given the clean input by solely minimizing the negative log-likelihood of the marginal distributions. We validate our DeFlow formulation on the task of joint image restoration and super-resolution. The models trained with the synthetic data generated by DeFlow outperform previous learnable approaches on all three datasets.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022
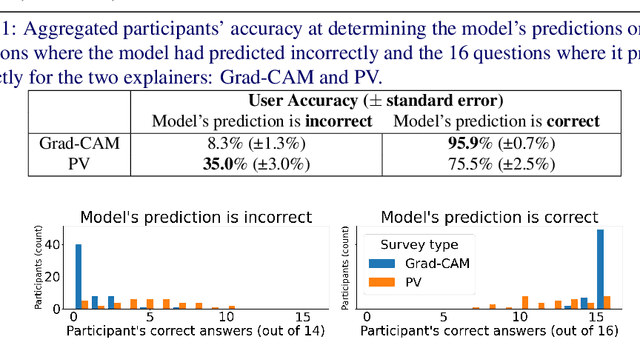

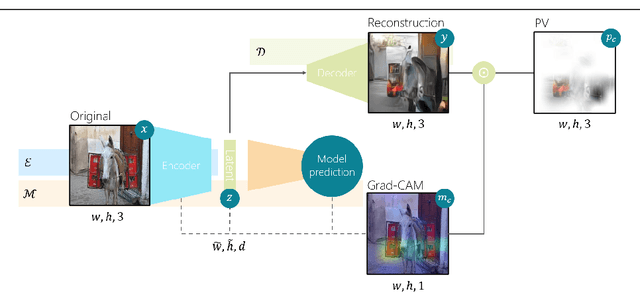
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.
Contrastive Visual Semantic Pretraining Magnifies the Semantics of Natural Language Representations
Mar 14, 2022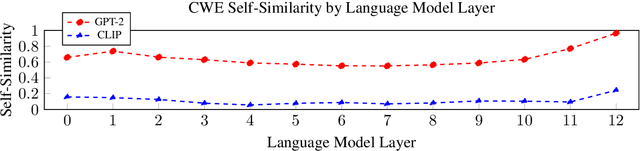
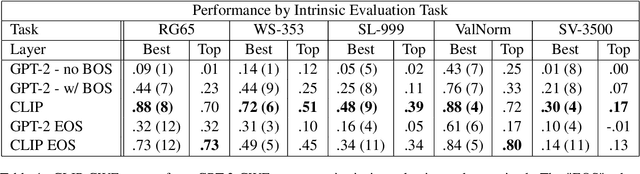
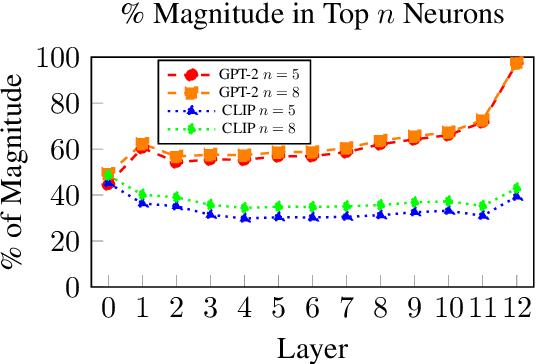
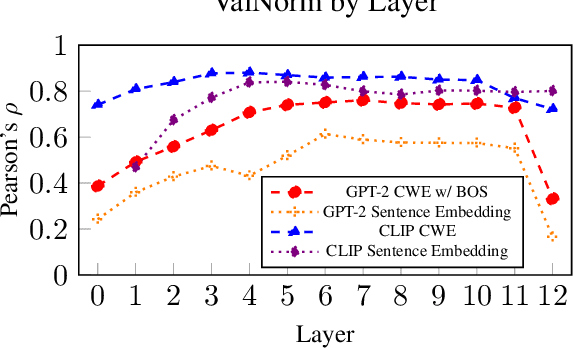
We examine the effects of contrastive visual semantic pretraining by comparing the geometry and semantic properties of contextualized English language representations formed by GPT-2 and CLIP, a zero-shot multimodal image classifier which adapts the GPT-2 architecture to encode image captions. We find that contrastive visual semantic pretraining significantly mitigates the anisotropy found in contextualized word embeddings from GPT-2, such that the intra-layer self-similarity (mean pairwise cosine similarity) of CLIP word embeddings is under .25 in all layers, compared to greater than .95 in the top layer of GPT-2. CLIP word embeddings outperform GPT-2 on word-level semantic intrinsic evaluation tasks, and achieve a new corpus-based state of the art for the RG65 evaluation, at .88. CLIP also forms fine-grained semantic representations of sentences, and obtains Spearman's rho = .73 on the SemEval-2017 Semantic Textual Similarity Benchmark with no fine-tuning, compared to no greater than rho = .45 in any layer of GPT-2. Finally, intra-layer self-similarity of CLIP sentence embeddings decreases as the layer index increases, finishing at .25 in the top layer, while the self-similarity of GPT-2 sentence embeddings formed using the EOS token increases layer-over-layer and never falls below .97. Our results indicate that high anisotropy is not an inevitable consequence of contextualization, and that visual semantic pretraining is beneficial not only for ordering visual representations, but also for encoding useful semantic representations of language, both on the word level and the sentence level.
PhysioGAN: Training High Fidelity Generative Model for Physiological Sensor Readings
Apr 25, 2022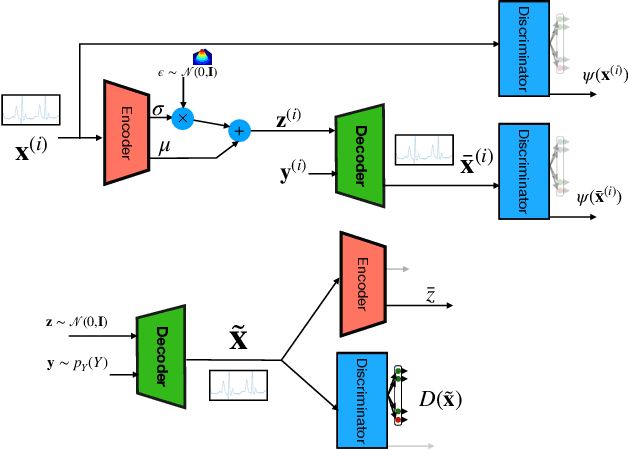
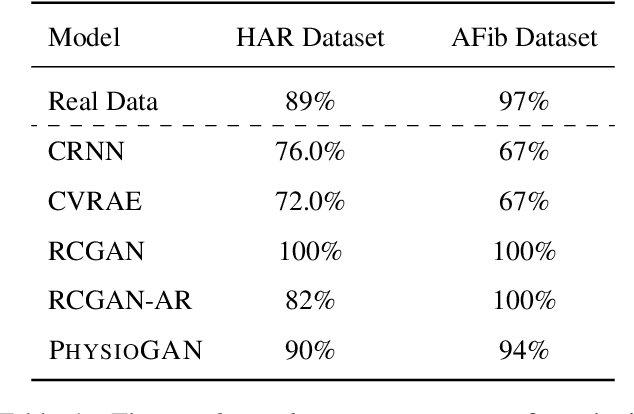
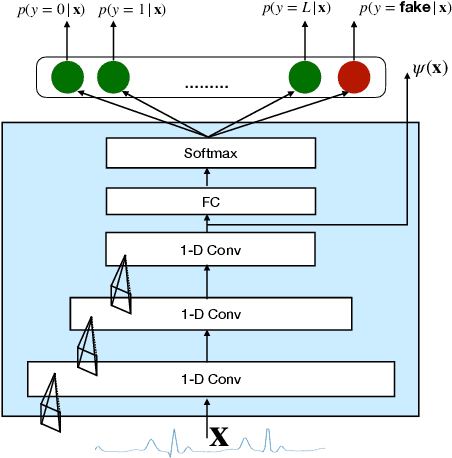
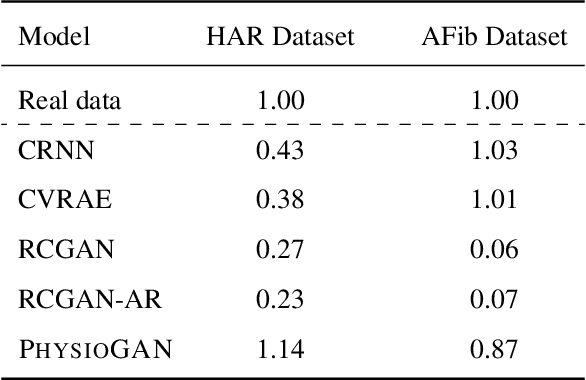
Generative models such as the variational autoencoder (VAE) and the generative adversarial networks (GAN) have proven to be incredibly powerful for the generation of synthetic data that preserves statistical properties and utility of real-world datasets, especially in the context of image and natural language text. Nevertheless, until now, there has no successful demonstration of how to apply either method for generating useful physiological sensory data. The state-of-the-art techniques in this context have achieved only limited success. We present PHYSIOGAN, a generative model to produce high fidelity synthetic physiological sensor data readings. PHYSIOGAN consists of an encoder, decoder, and a discriminator. We evaluate PHYSIOGAN against the state-of-the-art techniques using two different real-world datasets: ECG classification and activity recognition from motion sensors datasets. We compare PHYSIOGAN to the baseline models not only the accuracy of class conditional generation but also the sample diversity and sample novelty of the synthetic datasets. We prove that PHYSIOGAN generates samples with higher utility than other generative models by showing that classification models trained on only synthetic data generated by PHYSIOGAN have only 10% and 20% decrease in their classification accuracy relative to classification models trained on the real data. Furthermore, we demonstrate the use of PHYSIOGAN for sensor data imputation in creating plausible results.
Learning semantic Image attributes using Image recognition and knowledge graph embeddings
Sep 12, 2020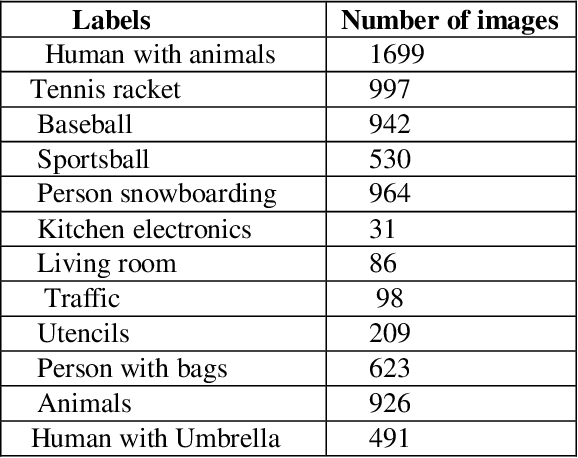
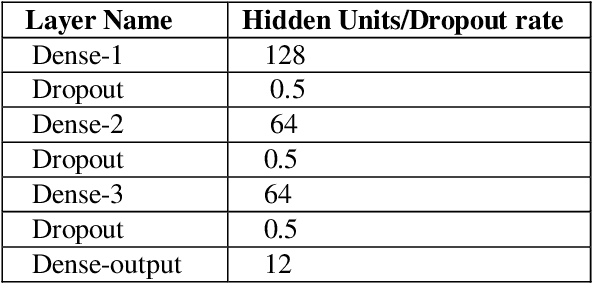
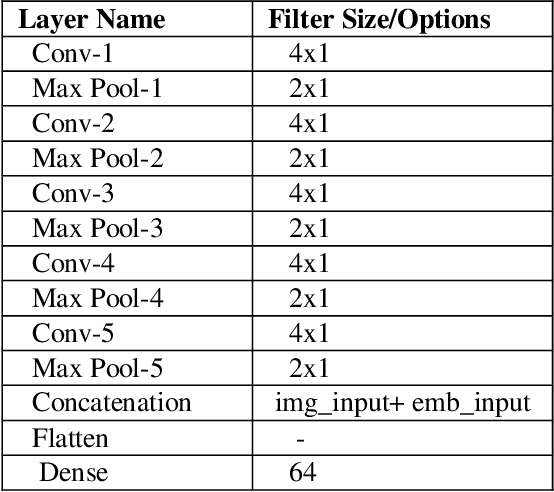
Extracting structured knowledge from texts has traditionally been used for knowledge base generation. However, other sources of information, such as images can be leveraged into this process to build more complete and richer knowledge bases. Structured semantic representation of the content of an image and knowledge graph embeddings can provide a unique representation of semantic relationships between image entities. Linking known entities in knowledge graphs and learning open-world images using language models has attracted lots of interest over the years. In this paper, we propose a shared learning approach to learn semantic attributes of images by combining a knowledge graph embedding model with the recognized attributes of images. The proposed model premises to help us understand the semantic relationship between the entities of an image and implicitly provide a link for the extracted entities through a knowledge graph embedding model. Under the limitation of using a custom user-defined knowledge base with limited data, the proposed model presents significant accuracy and provides a new alternative to the earlier approaches. The proposed approach is a step towards bridging the gap between frameworks which learn from large amounts of data and frameworks which use a limited set of predicates to infer new knowledge.
ALA: Adversarial Lightness Attack via Naturalness-aware Regularizations
Jan 16, 2022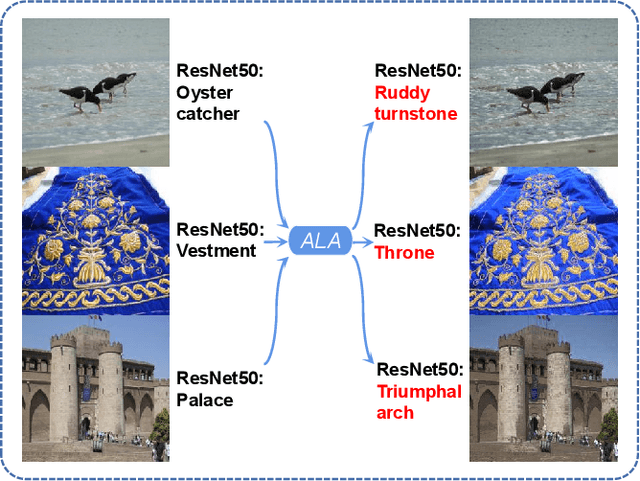
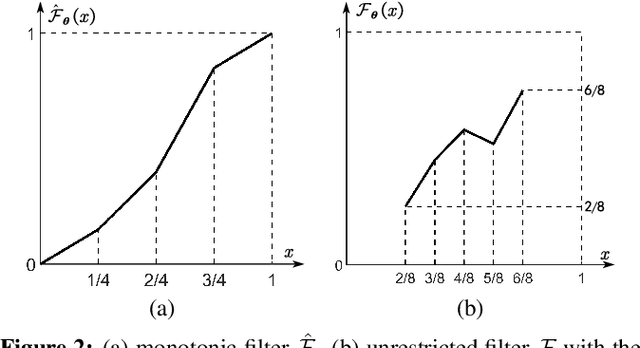
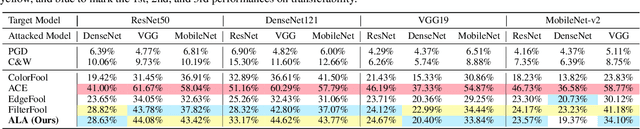
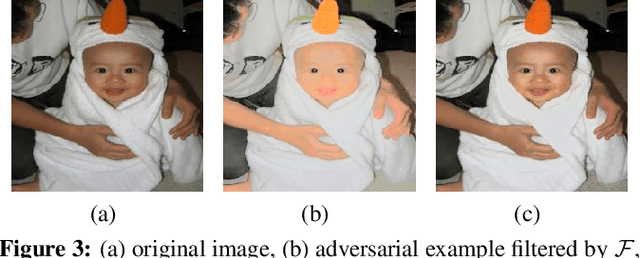
Most researchers have tried to enhance the robustness of deep neural networks (DNNs) by revealing and repairing the vulnerability of DNNs with specialized adversarial examples. Parts of the attack examples have imperceptible perturbations restricted by Lp norm. However, due to their high-frequency property, the adversarial examples usually have poor transferability and can be defensed by denoising methods. To avoid the defects, some works make the perturbations unrestricted to gain better robustness and transferability. However, these examples usually look unnatural and alert the guards. To generate unrestricted adversarial examples with high image quality and good transferability, in this paper, we propose Adversarial Lightness Attack (ALA), a white-box unrestricted adversarial attack that focuses on modifying the lightness of the images. The shape and color of the samples, which are crucial to human perception, are barely influenced. To obtain adversarial examples with high image quality, we craft a naturalness-aware regularization. To achieve stronger transferability, we propose random initialization and non-stop attack strategy in the attack procedure. We verify the effectiveness of ALA on two popular datasets for different tasks (i.e., ImageNet for image classification and Places-365 for scene recognition). The experiments show that the generated adversarial examples have both strong transferability and high image quality. Besides, the adversarial examples can also help to improve the standard trained ResNet50 on defending lightness corruption.
Neural network processing of holographic images
Mar 18, 2022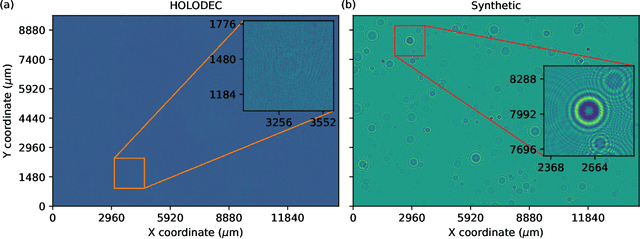
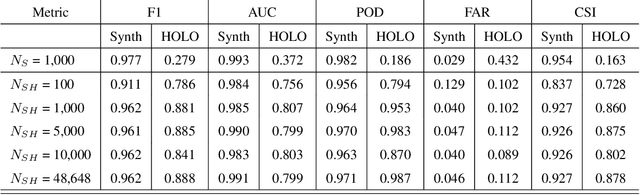
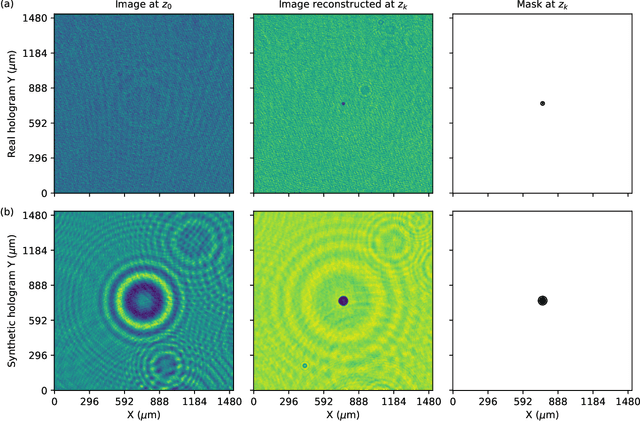
HOLODEC, an airborne cloud particle imager, captures holographic images of a fixed volume of cloud to characterize the types and sizes of cloud particles, such as water droplets and ice crystals. Cloud particle properties include position, diameter, and shape. We present a hologram processing algorithm, HolodecML, that utilizes a neural segmentation model, GPUs, and computational parallelization. HolodecML is trained using synthetically generated holograms based on a model of the instrument, and predicts masks around particles found within reconstructed images. From these masks, the position and size of the detected particles can be characterized in three dimensions. In order to successfully process real holograms, we find we must apply a series of image corrupting transformations and noise to the synthetic images used in training. In this evaluation, HolodecML had comparable position and size estimation performance to the standard processing method, but improved particle detection by nearly 20\% on several thousand manually labeled HOLODEC images. However, the improvement only occurred when image corruption was performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe. The trained model also learned to differentiate artifacts and other impurities in the HOLODEC images from the particles, even though no such objects were present in the training data set, while the standard processing method struggled to separate particles from artifacts. The novelty of the training approach, which leveraged noise as a means for parameterizing non-ideal aspects of the HOLODEC detector, could be applied in other domains where the theoretical model is incapable of fully describing the real-world operation of the instrument and accurate truth data required for supervised learning cannot be obtained from real-world observations.
Generating Data Augmentation samples for Semantic Segmentation of Salt Bodies in a Synthetic Seismic Image Dataset
Jun 17, 2021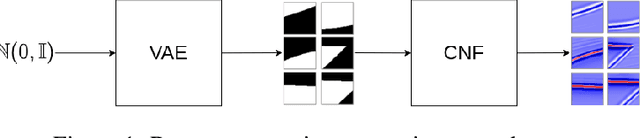
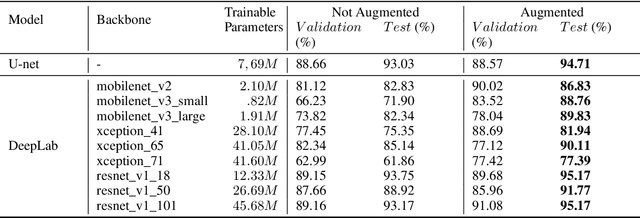
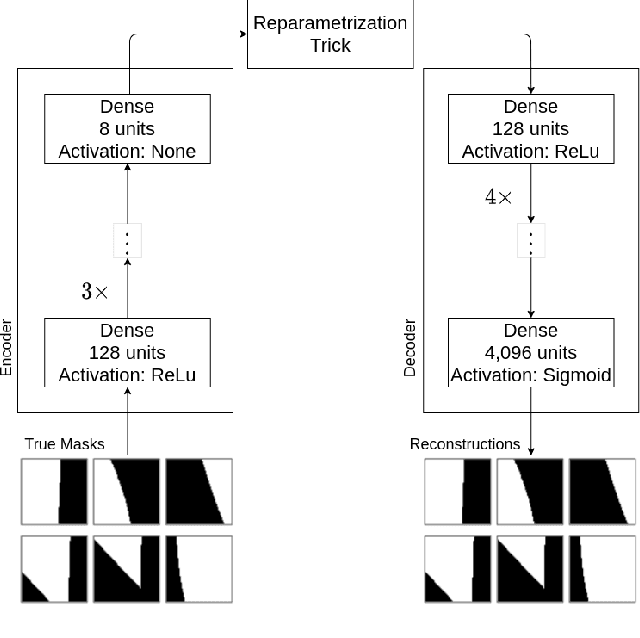
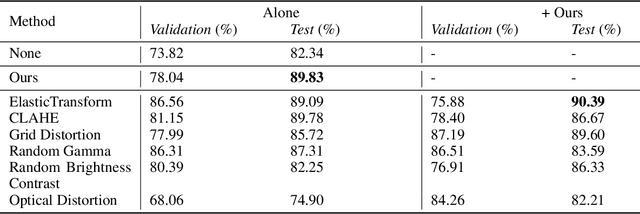
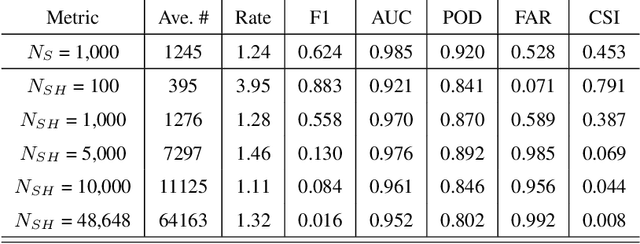
Nowadays, subsurface salt body localization and delineation, also called semantic segmentation of salt bodies, are among the most challenging geophysicist tasks. Thus, identifying large salt bodies is notoriously tricky and is crucial for identifying hydrocarbon reservoirs and drill path planning. This work proposes a Data Augmentation method based on training two generative models to augment the number of samples in a seismic image dataset for the semantic segmentation of salt bodies. Our method uses deep learning models to generate pairs of seismic image patches and their respective salt masks for the Data Augmentation. The first model is a Variational Autoencoder and is responsible for generating patches of salt body masks. The second is a Conditional Normalizing Flow model, which receives the generated masks as inputs and generates the associated seismic image patches. We evaluate the proposed method by comparing the performance of ten distinct state-of-the-art models for semantic segmentation, trained with and without the generated augmentations, in a dataset from two synthetic seismic images. The proposed methodology yields an average improvement of 8.57% in the IoU metric across all compared models. The best result is achieved by a DeeplabV3+ model variant, which presents an IoU score of 95.17% when trained with our augmentations. Additionally, our proposal outperformed six selected data augmentation methods, and the most significant improvement in the comparison, of 9.77%, is achieved by composing our DA with augmentations from an elastic transformation. At last, we show that the proposed method is adaptable for a larger context size by achieving results comparable to the obtained on the smaller context size.
Neuro-Inspired Deep Neural Networks with Sparse, Strong Activations
Apr 12, 2022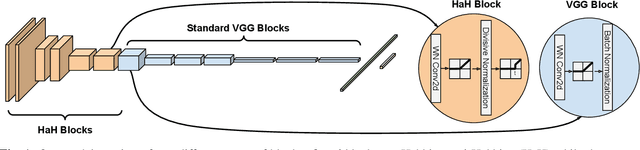

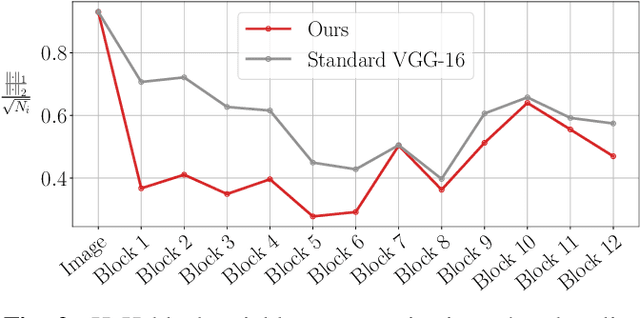
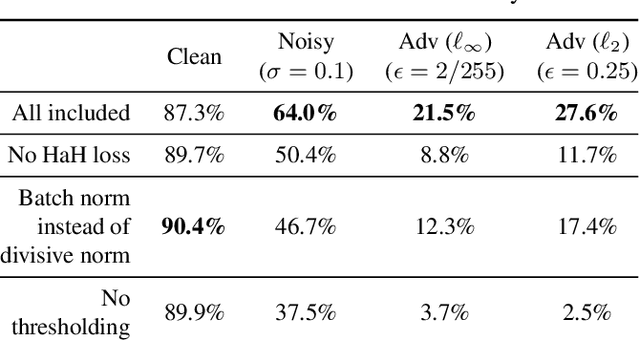
While end-to-end training of Deep Neural Networks (DNNs) yields state of the art performance in an increasing array of applications, it does not provide insight into, or control over, the features being extracted. We report here on a promising neuro-inspired approach to DNNs with sparser and stronger activations. We use standard stochastic gradient training, supplementing the end-to-end discriminative cost function with layer-wise costs promoting Hebbian ("fire together," "wire together") updates for highly active neurons, and anti-Hebbian updates for the remaining neurons. Instead of batch norm, we use divisive normalization of activations (suppressing weak outputs using strong outputs), along with implicit $\ell_2$ normalization of neuronal weights. Experiments with standard image classification tasks on CIFAR-10 demonstrate that, relative to baseline end-to-end trained architectures, our proposed architecture (a) leads to sparser activations (with only a slight compromise on accuracy), (b) exhibits more robustness to noise (without being trained on noisy data), (c) exhibits more robustness to adversarial perturbations (without adversarial training).