 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
Apr 08, 2022

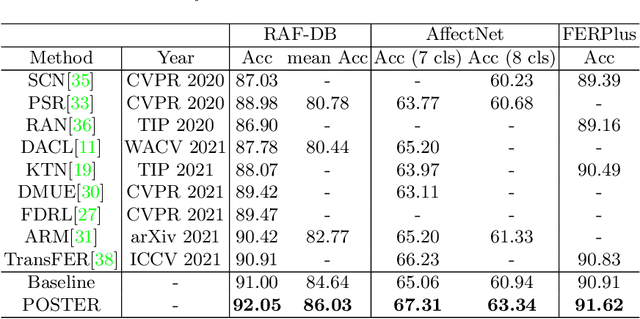
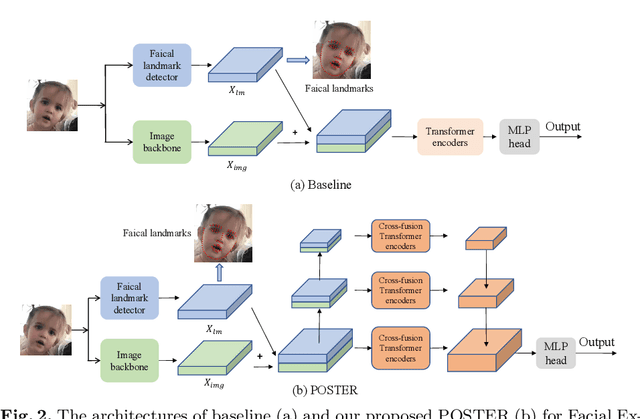
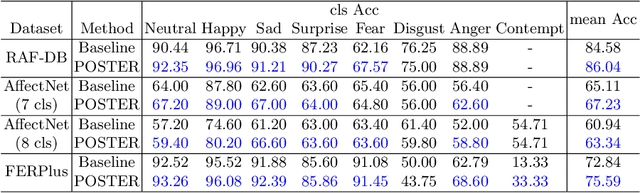
Facial Expression Recognition (FER) has received increasing interest in the computer vision community. As a challenging task, there are three key issues especially prevalent in FER: inter-class similarity, intra-class discrepancy, and scale sensitivity. Existing methods typically address some of these issues, but do not tackle them all in a unified framework. Therefore, in this paper, we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) that aims to holistically solve these issues. Specifically, we design a transformer-based cross-fusion paradigm that enables effective collaboration of facial landmark and direct image features to maximize proper attention to salient facial regions. Furthermore, POSTER employs a pyramid structure to promote scale invariance. Extensive experimental results demonstrate that our POSTER outperforms SOTA methods on RAF-DB with 92.05%, FERPlus with 91.62%, AffectNet (7 cls) with 67.31%, and AffectNet (8 cls) with 63.34%, respectively.
DS3-Net: Difficulty-perceived Common-to-T1ce Semi-Supervised Multimodal MRI Synthesis Network
Mar 14, 2022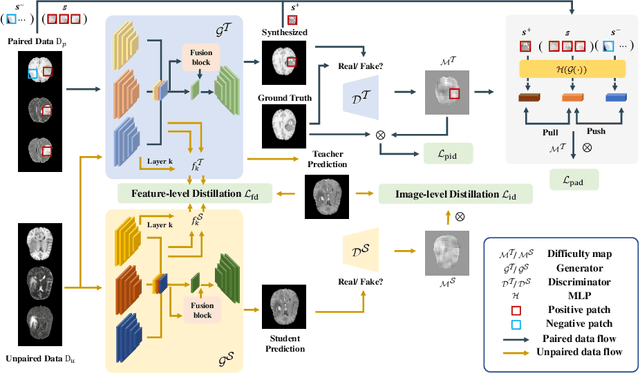
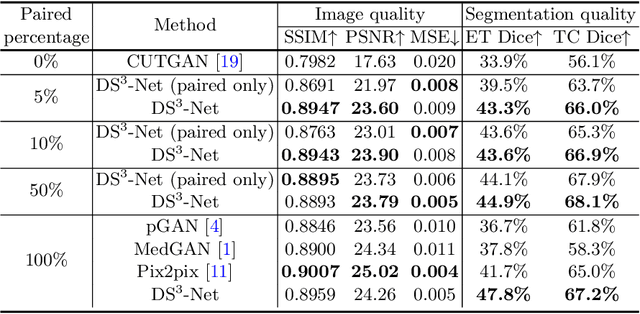

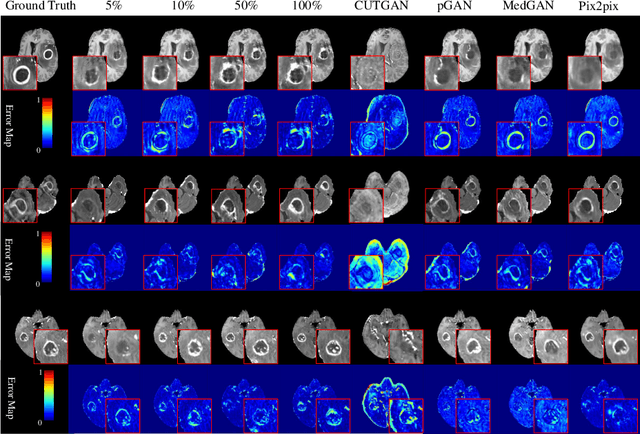
Contrast-enhanced T1 (T1ce) is one of the most essential magnetic resonance imaging (MRI) modalities for diagnosing and analyzing brain tumors, especially gliomas. In clinical practice, common MRI modalities such as T1, T2, and fluid attenuation inversion recovery are relatively easy to access while T1ce is more challenging considering the additional cost and potential risk of allergies to the contrast agent. Therefore, it is of great clinical necessity to develop a method to synthesize T1ce from other common modalities. Current paired image translation methods typically have the issue of requiring a large amount of paired data and do not focus on specific regions of interest, e.g., the tumor region, in the synthesization process. To address these issues, we propose a Difficulty-perceived common-to-T1ce Semi-Supervised multimodal MRI Synthesis network (DS3-Net), involving both paired and unpaired data together with dual-level knowledge distillation. DS3-Net predicts a difficulty map to progressively promote the synthesis task. Specifically, a pixelwise constraint and a patchwise contrastive constraint are guided by the predicted difficulty map. Through extensive experiments on the publiclyavailable BraTS2020 dataset, DS3-Net outperforms its supervised counterpart in each respect. Furthermore, with only 5% paired data, the proposed DS3-Net achieves competitive performance with state-of-theart image translation methods utilizing 100% paired data, delivering an average SSIM of 0.8947 and an average PSNR of 23.60.
Few-Shot Image Classification Along Sparse Graphs
Dec 07, 2021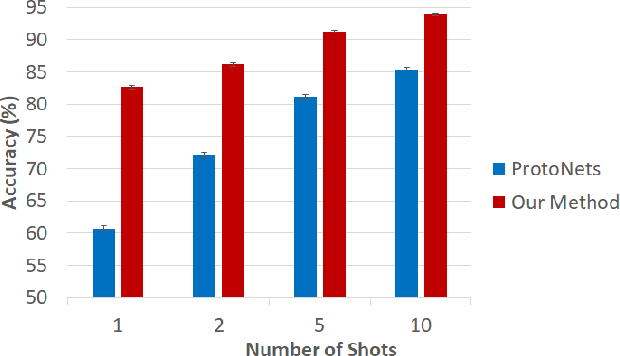
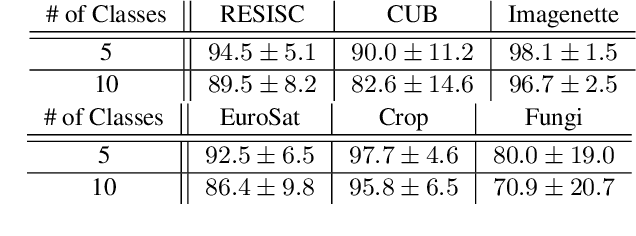
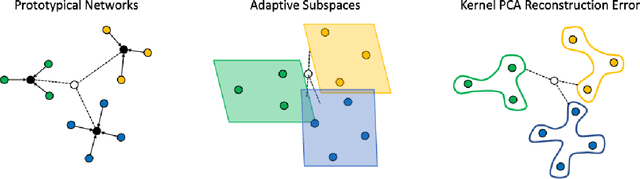
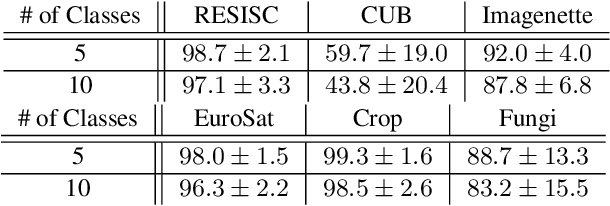
Few-shot learning remains a challenging problem, with unsatisfactory 1-shot accuracies for most real-world data. Here, we present a different perspective for data distributions in the feature space of a deep network and show how to exploit it for few-shot learning. First, we observe that nearest neighbors in the feature space are with high probability members of the same class while generally two random points from one class are not much closer to each other than points from different classes. This observation suggests that classes in feature space form sparse, loosely connected graphs instead of dense clusters. To exploit this property, we propose using a small amount of label propagation into the unlabeled space and then using a kernel PCA reconstruction error as decision boundary for the feature-space data distribution of each class. Using this method, which we call "K-Prop," we demonstrate largely improved few-shot learning performances (e.g., 83% accuracy for 1-shot 5-way classification on the RESISC45 satellite-images dataset) for datasets for which a backbone network can be trained with high within-class nearest-neighbor probabilities. We demonstrate this relationship using six different datasets.
Learning and Inference in Sparse Coding Models with Langevin Dynamics
Apr 23, 2022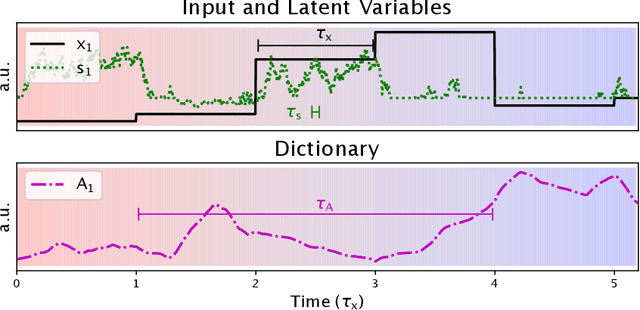
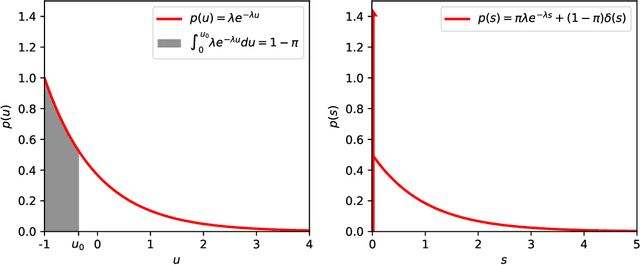

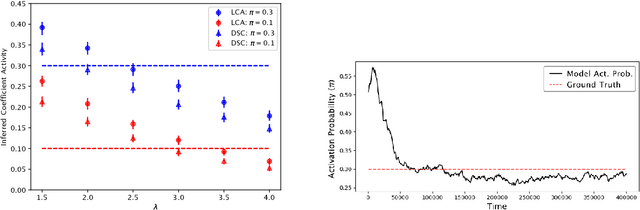
We describe a stochastic, dynamical system capable of inference and learning in a probabilistic latent variable model. The most challenging problem in such models - sampling the posterior distribution over latent variables - is proposed to be solved by harnessing natural sources of stochasticity inherent in electronic and neural systems. We demonstrate this idea for a sparse coding model by deriving a continuous-time equation for inferring its latent variables via Langevin dynamics. The model parameters are learned by simultaneously evolving according to another continuous-time equation, thus bypassing the need for digital accumulators or a global clock. Moreover we show that Langevin dynamics lead to an efficient procedure for sampling from the posterior distribution in the 'L0 sparse' regime, where latent variables are encouraged to be set to zero as opposed to having a small L1 norm. This allows the model to properly incorporate the notion of sparsity rather than having to resort to a relaxed version of sparsity to make optimization tractable. Simulations of the proposed dynamical system on both synthetic and natural image datasets demonstrate that the model is capable of probabilistically correct inference, enabling learning of the dictionary as well as parameters of the prior.
Interactive Attention AI to translate low light photos to captions for night scene understanding in women safety
Jan 04, 2022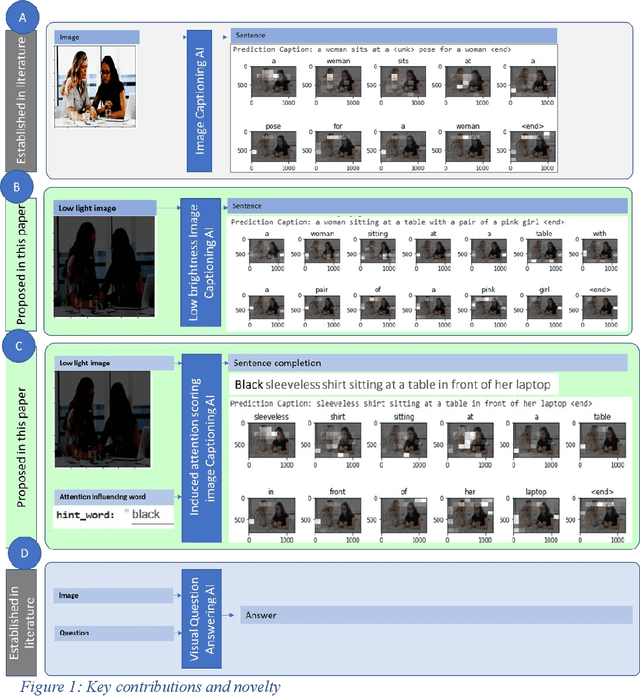
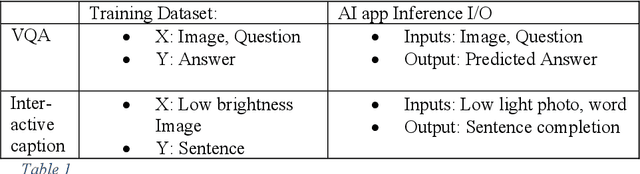
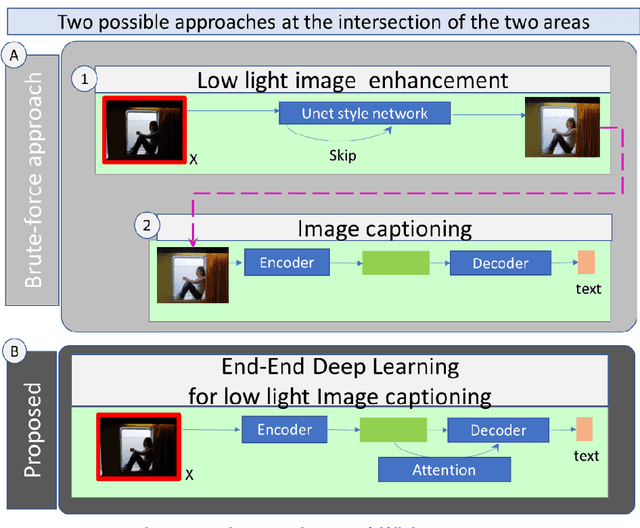
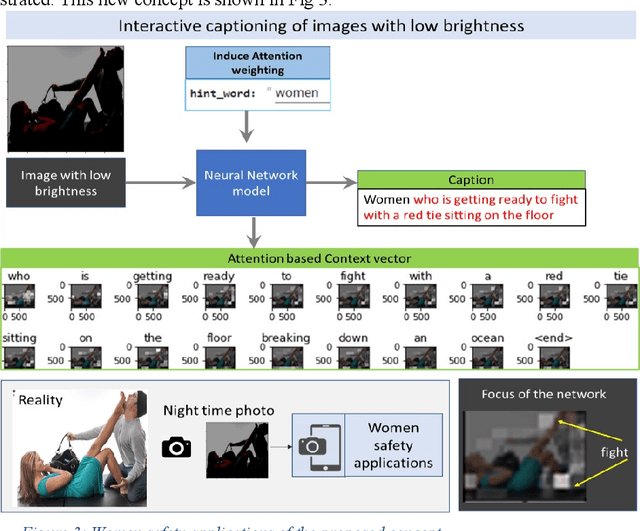
There is amazing progress in Deep Learning based models for Image captioning and Low Light image enhancement. For the first time in literature, this paper develops a Deep Learning model that translates night scenes to sentences, opening new possibilities for AI applications in the safety of visually impaired women. Inspired by Image Captioning and Visual Question Answering, a novel Interactive Image Captioning is developed. A user can make the AI focus on any chosen person of interest by influencing the attention scoring. Attention context vectors are computed from CNN feature vectors and user-provided start word. The Encoder-Attention-Decoder neural network learns to produce captions from low brightness images. This paper demonstrates how women safety can be enabled by researching a novel AI capability in the Interactive Vision-Language model for perception of the environment in the night.
View Generalization for Single Image Textured 3D Models
Jun 10, 2021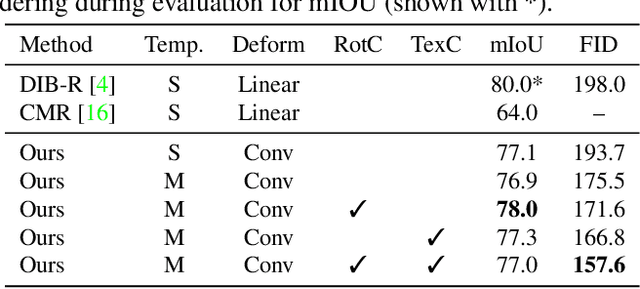

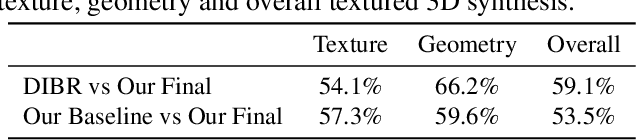
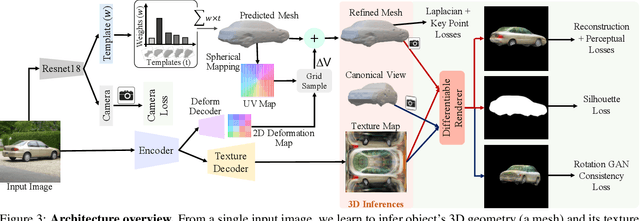
Humans can easily infer the underlying 3D geometry and texture of an object only from a single 2D image. Current computer vision methods can do this, too, but suffer from view generalization problems - the models inferred tend to make poor predictions of appearance in novel views. As for generalization problems in machine learning, the difficulty is balancing single-view accuracy (cf. training error; bias) with novel view accuracy (cf. test error; variance). We describe a class of models whose geometric rigidity is easily controlled to manage this tradeoff. We describe a cycle consistency loss that improves view generalization (roughly, a model from a generated view should predict the original view well). View generalization of textures requires that models share texture information, so a car seen from the back still has headlights because other cars have headlights. We describe a cycle consistency loss that encourages model textures to be aligned, so as to encourage sharing. We compare our method against the state-of-the-art method and show both qualitative and quantitative improvements.
Deep morphological recognition of kidney stones using intra-operative endoscopic digital videos
May 12, 2022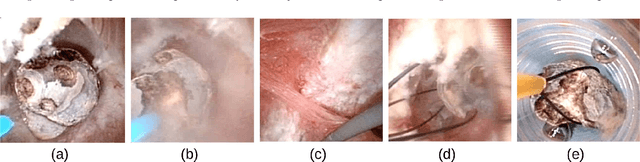

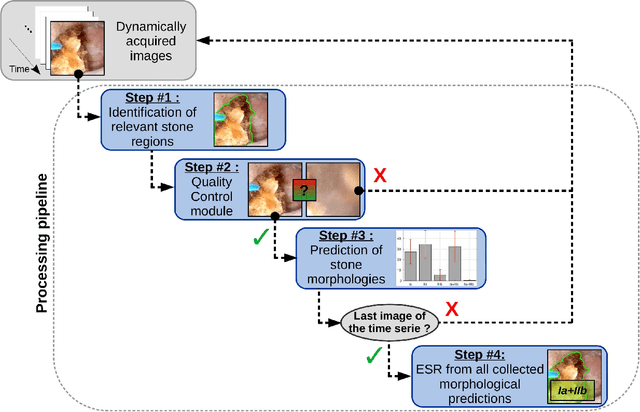
The collection and the analysis of kidney stone morphological criteria are essential for an aetiological diagnosis of stone disease. However, in-situ LASER-based fragmentation of urinary stones, which is now the most established chirurgical intervention, may destroy the morphology of the targeted stone. In the current study, we assess the performance and added value of processing complete digital endoscopic video sequences for the automatic recognition of stone morphological features during a standard-of-care intra-operative session. To this end, a computer-aided video classifier was developed to predict in-situ the morphology of stone using an intra-operative digital endoscopic video acquired in a clinical setting. The proposed technique was evaluated on pure (i.e. include one morphology) and mixed (i.e. include at least two morphologies) stones involving "Ia/Calcium Oxalate Monohydrate (COM)", "IIb/ Calcium Oxalate Dihydrate (COD)" and "IIIb/Uric Acid (UA)" morphologies. 71 digital endoscopic videos (50 exhibited only one morphological type and 21 displayed two) were analyzed using the proposed video classifier (56840 frames processed in total). Using the proposed approach, diagnostic performances (averaged over both pure and mixed stone types) were as follows: balanced accuracy=88%, sensitivity=80%, specificity=95%, precision=78% and F1-score=78%. The obtained results demonstrate that AI applied on digital endoscopic video sequences is a promising tool for collecting morphological information during the time-course of the stone fragmentation process without resorting to any human intervention for stone delineation or selection of good quality steady frames. To this end, irrelevant image information must be removed from the prediction process at both frame and pixel levels, which is now feasible thanks to the use of AI-dedicated networks.
InfinityGAN: Towards Infinite-Resolution Image Synthesis
Apr 08, 2021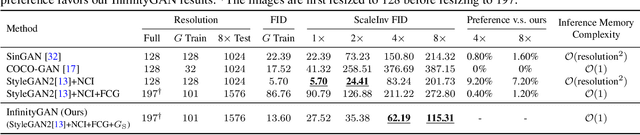
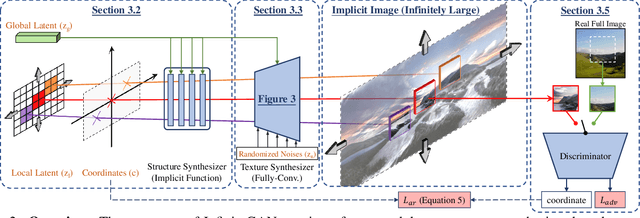
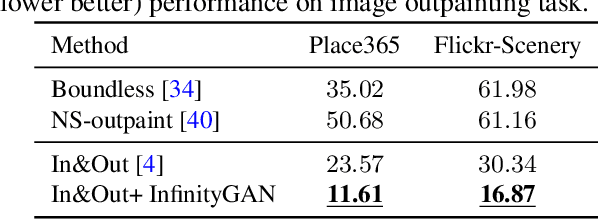
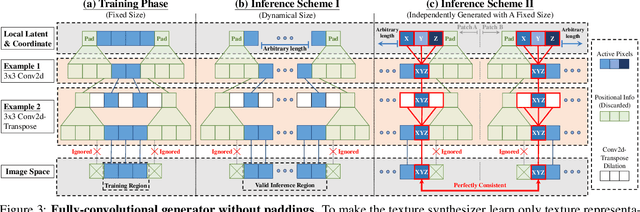
We present InfinityGAN, a method to generate arbitrary-resolution images. The problem is associated with several key challenges. First, scaling existing models to a high resolution is resource-constrained, both in terms of computation and availability of high-resolution training data. Infinity-GAN trains and infers patch-by-patch seamlessly with low computational resources. Second, large images should be locally and globally consistent, avoid repetitive patterns, and look realistic. To address these, InfinityGAN takes global appearance, local structure and texture into account.With this formulation, we can generate images with resolution and level of detail not attainable before. Experimental evaluation supports that InfinityGAN generates imageswith superior global structure compared to baselines at the same time featuring parallelizable inference. Finally, we how several applications unlocked by our approach, such as fusing styles spatially, multi-modal outpainting and image inbetweening at arbitrary input and output resolutions
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022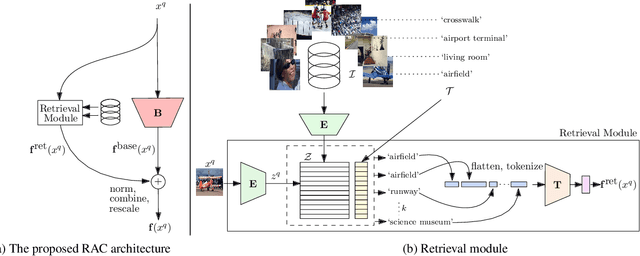
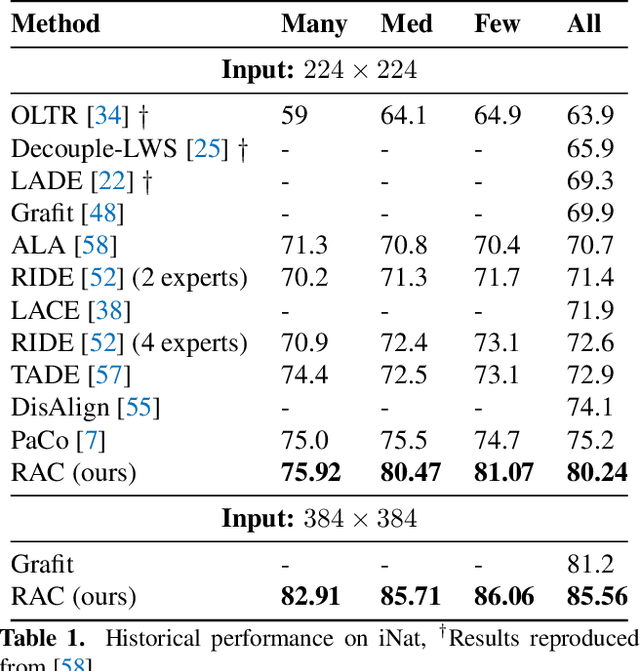
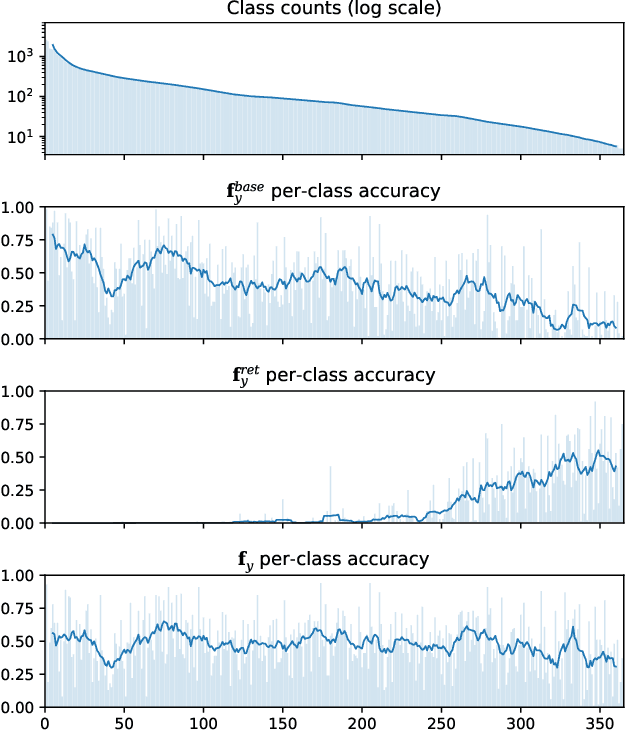
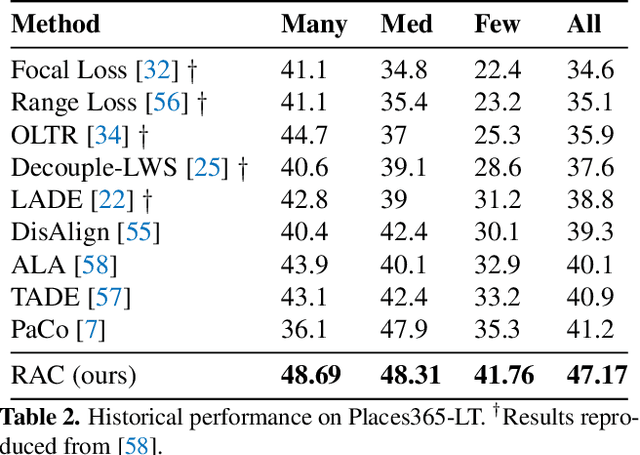
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 04, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work will be available at https://github.com/JUGGHM/PENet_ICRA2021.