 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022
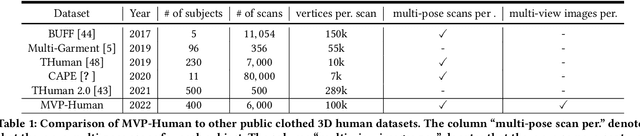
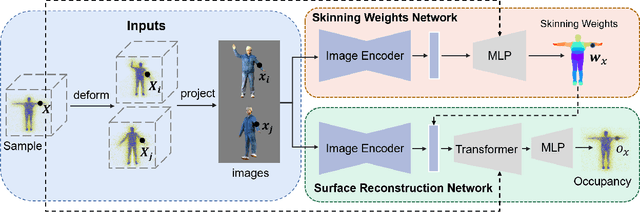
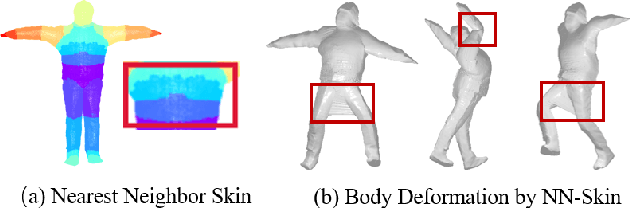
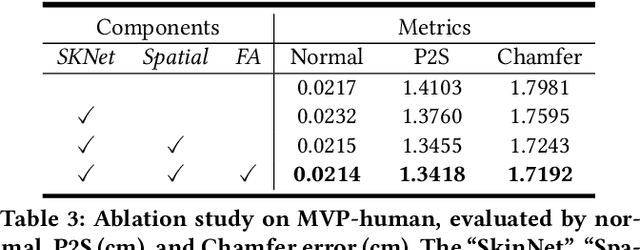
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
Focal Length and Object Pose Estimation via Render and Compare
Apr 11, 2022

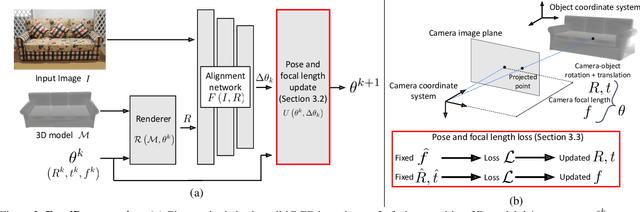
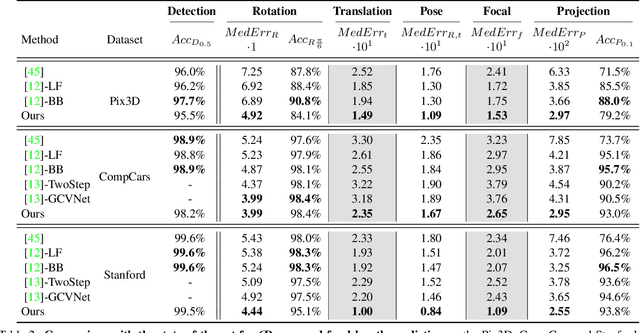
We introduce FocalPose, a neural render-and-compare method for jointly estimating the camera-object 6D pose and camera focal length given a single RGB input image depicting a known object. The contributions of this work are twofold. First, we derive a focal length update rule that extends an existing state-of-the-art render-and-compare 6D pose estimator to address the joint estimation task. Second, we investigate several different loss functions for jointly estimating the object pose and focal length. We find that a combination of direct focal length regression with a reprojection loss disentangling the contribution of translation, rotation, and focal length leads to improved results. We show results on three challenging benchmark datasets that depict known 3D models in uncontrolled settings. We demonstrate that our focal length and 6D pose estimates have lower error than the existing state-of-the-art methods.
Rethinking Gradient Operator for Exposing AI-enabled Face Forgeries
May 02, 2022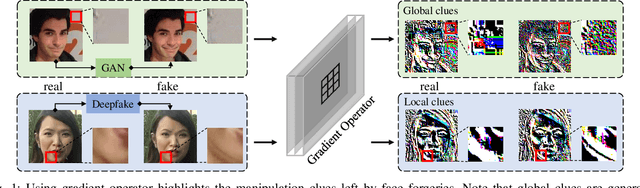
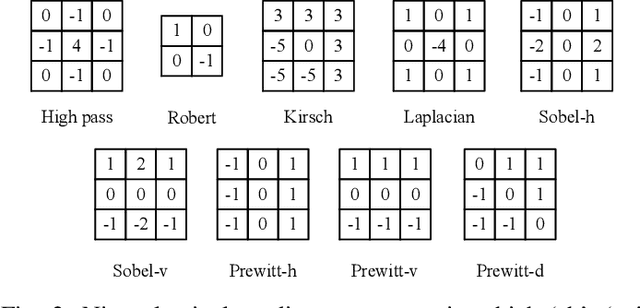
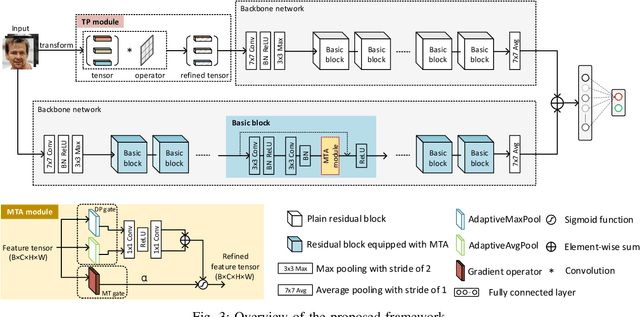

For image forensics, convolutional neural networks (CNNs) tend to learn content features rather than subtle manipulation traces, which limits forensic performance. Existing methods predominantly solve the above challenges by following a general pipeline, that is, subtracting the original pixel value from the predicted pixel value to make CNNs pay attention to the manipulation traces. However, due to the complicated learning mechanism, these methods may bring some unnecessary performance losses. In this work, we rethink the advantages of gradient operator in exposing face forgery, and design two plug-and-play modules by combining gradient operator with CNNs, namely tensor pre-processing (TP) and manipulation trace attention (MTA) module. Specifically, TP module refines the feature tensor of each channel in the network by gradient operator to highlight the manipulation traces and improve the feature representation. Moreover, MTA module considers two dimensions, namely channel and manipulation traces, to force the network to learn the distribution of manipulation traces. These two modules can be seamlessly integrated into CNNs for end-to-end training. Experiments show that the proposed network achieves better results than prior works on five public datasets. Especially, TP module greatly improves the accuracy by at least 4.60% compared with the existing pre-processing module only via simple tensor refinement. The code is available at: https://github.com/EricGzq/GocNet-pytorch.
Embodied vision for learning object representations
May 12, 2022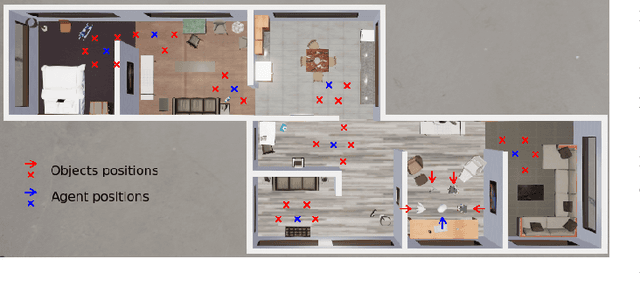


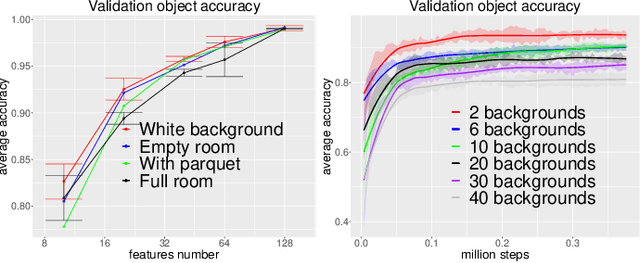
Recent time-contrastive learning approaches manage to learn invariant object representations without supervision. This is achieved by mapping successive views of an object onto close-by internal representations. When considering this learning approach as a model of the development of human object recognition, it is important to consider what visual input a toddler would typically observe while interacting with objects. First, human vision is highly foveated, with high resolution only available in the central region of the field of view. Second, objects may be seen against a blurry background due to infants' limited depth of field. Third, during object manipulation a toddler mostly observes close objects filling a large part of the field of view due to their rather short arms. Here, we study how these effects impact the quality of visual representations learnt through time-contrastive learning. To this end, we let a visually embodied agent "play" with objects in different locations of a near photo-realistic flat. During each play session the agent views an object in multiple orientations before turning its body to view another object. The resulting sequence of views feeds a time-contrastive learning algorithm. Our results show that visual statistics mimicking those of a toddler improve object recognition accuracy in both familiar and novel environments. We argue that this effect is caused by the reduction of features extracted in the background, a neural network bias for large features in the image and a greater similarity between novel and familiar background regions. We conclude that the embodied nature of visual learning may be crucial for understanding the development of human object perception.
Multi-scale Attention Guided Pose Transfer
Feb 14, 2022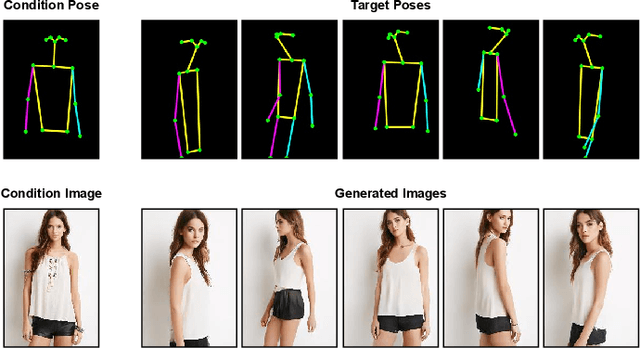
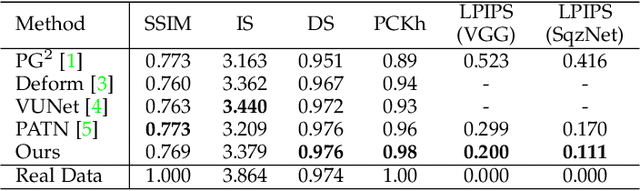
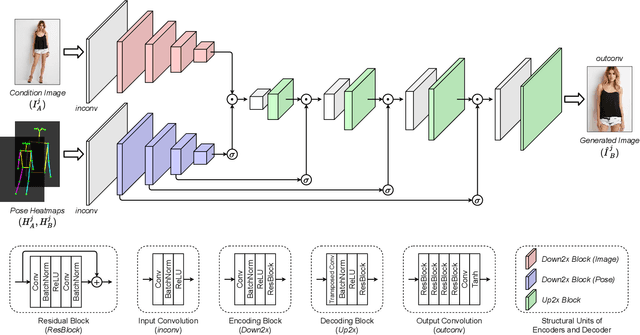
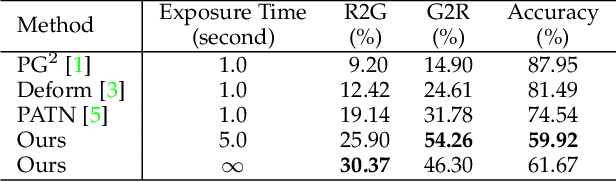
Pose transfer refers to the probabilistic image generation of a person with a previously unseen novel pose from another image of that person having a different pose. Due to potential academic and commercial applications, this problem is extensively studied in recent years. Among the various approaches to the problem, attention guided progressive generation is shown to produce state-of-the-art results in most cases. In this paper, we present an improved network architecture for pose transfer by introducing attention links at every resolution level of the encoder and decoder. By utilizing such dense multi-scale attention guided approach, we are able to achieve significant improvement over the existing methods both visually and analytically. We conclude our findings with extensive qualitative and quantitative comparisons against several existing methods on the DeepFashion dataset.
Deep Learning Based Classification System For Recognizing Local Spinach
Jan 06, 2022
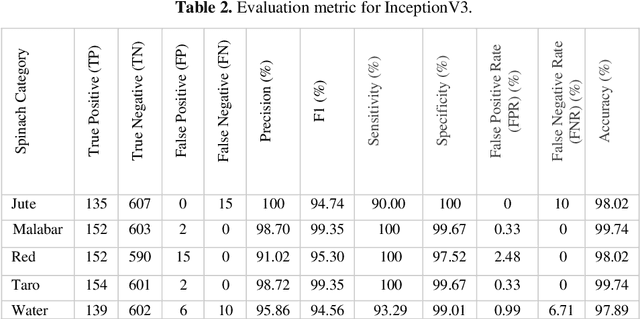
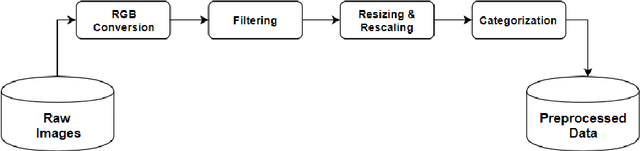
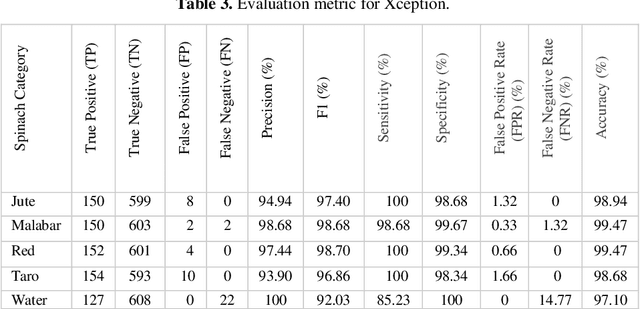
A deep learning model gives an incredible result for image processing by studying from the trained dataset. Spinach is a leaf vegetable that contains vitamins and nutrients. In our research, a Deep learning method has been used that can automatically identify spinach and this method has a dataset of a total of five species of spinach that contains 3785 images. Four Convolutional Neural Network (CNN) models were used to classify our spinach. These models give more accurate results for image classification. Before applying these models there is some preprocessing of the image data. For the preprocessing of data, some methods need to happen. Those are RGB conversion, filtering, resize & rescaling, and categorization. After applying these methods image data are pre-processed and ready to be used in the classifier algorithms. The accuracy of these classifiers is in between 98.68% - 99.79%. Among those models, VGG16 achieved the highest accuracy of 99.79%.
Multi-domain Integrative Swin Transformer network for Sparse-View Tomographic Reconstruction
Dec 10, 2021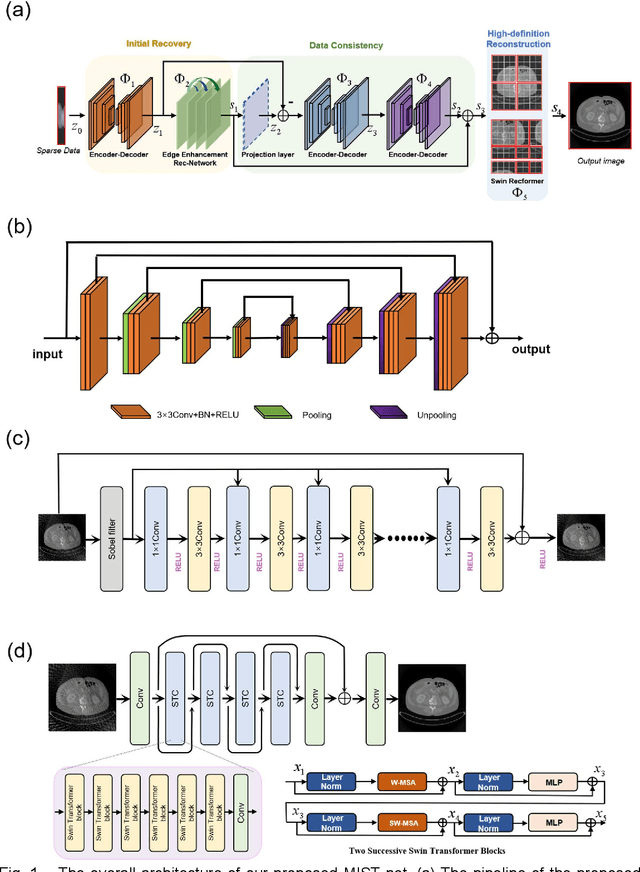
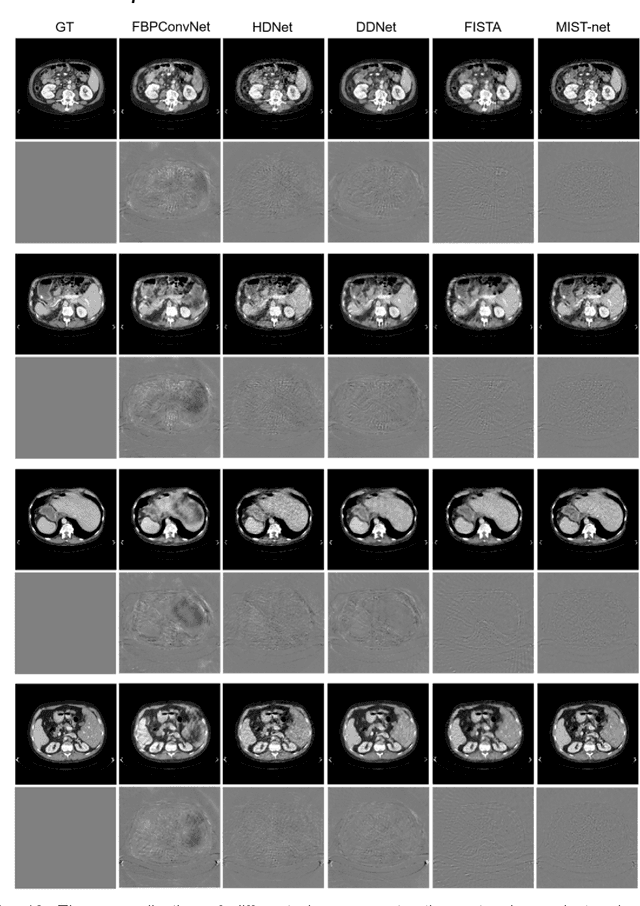
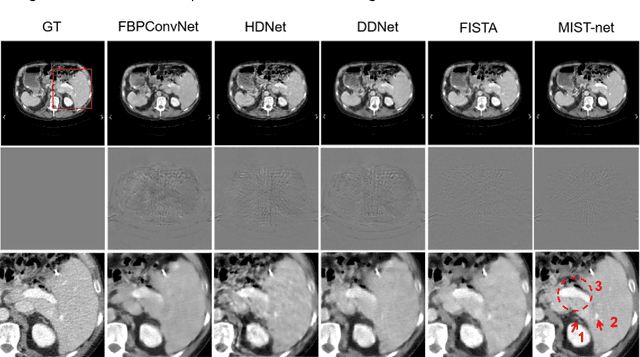
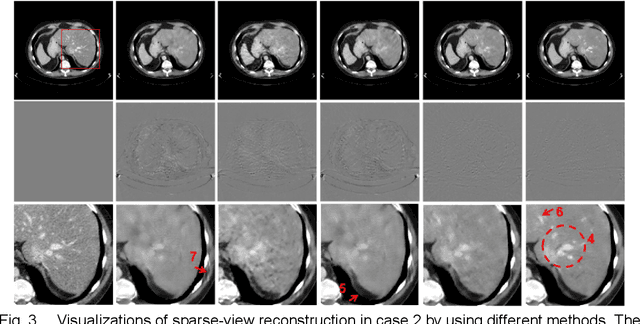
The deep learning-based tomographic image reconstruction methods have been attracting much attention among these years. The sparse-view data reconstruction is one of typical underdetermined inverse problems, how to reconstruct high-quality CT images from dozens of projections is still a challenge in practice. To address this challenge, in this article we proposed a Multi-domain Integrative Swin Transformer network (MIST-net). First, the proposed MIST-net incorporated lavish domain features from data, residual-data, image, and residual-image using flexible network architectures. Here, the residual-data and residual-image domains network components can be considered as data consistency module to eliminate interpolation errors in both residual data and image domains, and then further retain image details. Second, to detect image features and further protect image edge, the trainable edge enhancement filter was incorporated into sub-network to improve encode-decode ability. Third, with classical Swin Transformer, we further designed a high-quality reconstruction transformer (i.e., Recformer) to improve reconstruction performance. Recformer inherited the power of Swin transformer to capture global and local features of reconstructed image. The experiments on numerical datasets with 48 views demonstrated our proposed MIST-net provided higher reconstructed image quality with small feature recovery and edge protection than other competitors including advanced unrolled networks. The trained network was transferred to real cardiac CT dataset to further validate the advantages as well as good robustness of our MIST-net in clinical applications.
Deep Learning for Underwater Fish-Habitat Monitoring: A Survey
Mar 14, 2022
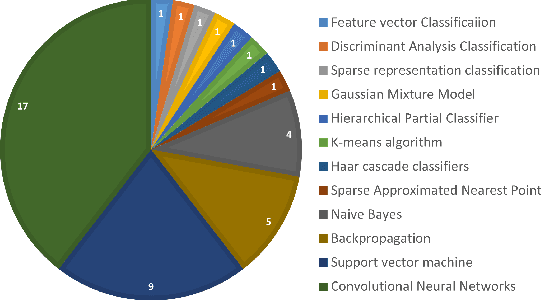
Marine scientists use remote underwater video recording to survey fish species in their natural habitats. This helps them understand and predict how fish respond to climate change, habitat degradation, and fishing pressure. This information is essential for developing sustainable fisheries for human consumption, and for preserving the environment. However, the enormous volume of collected videos makes extracting useful information a daunting and time-consuming task for a human. A promising method to address this problem is the cutting-edge Deep Learning (DL) technology.DL can help marine scientists parse large volumes of video promptly and efficiently, unlocking niche information that cannot be obtained using conventional manual monitoring methods. In this paper, we provide an overview of the key concepts of DL, while presenting a survey of literature on fish habitat monitoring with a focus on underwater fish classification. We also discuss the main challenges faced when developing DL for underwater image processing and propose approaches to address them. Finally, we provide insights into the marine habitat monitoring research domain and shed light on what the future of DL for underwater image processing may hold. This paper aims to inform a wide range of readers from marine scientists who would like to apply DL in their research to computer scientists who would like to survey state-of-the-art DL-based underwater fish habitat monitoring literature.
POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
Apr 08, 2022
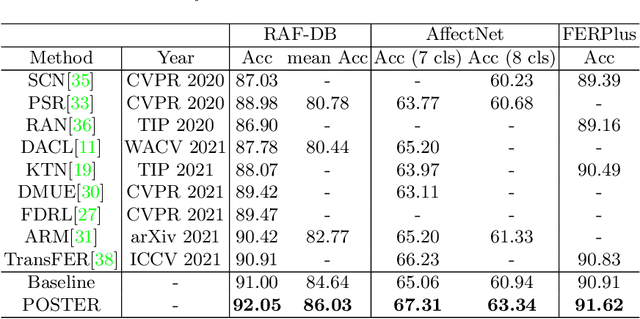
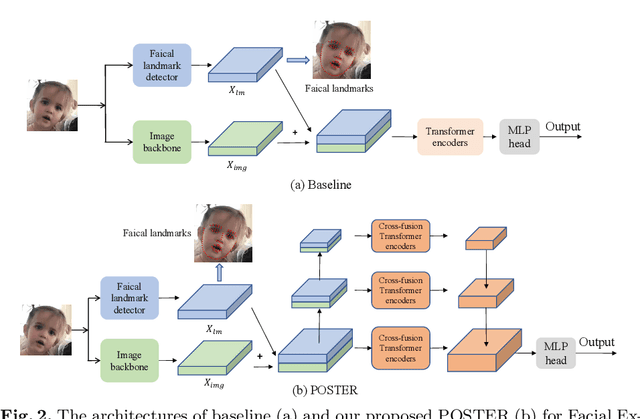
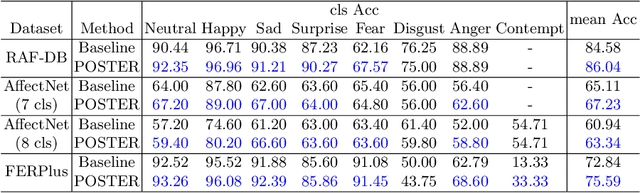
Facial Expression Recognition (FER) has received increasing interest in the computer vision community. As a challenging task, there are three key issues especially prevalent in FER: inter-class similarity, intra-class discrepancy, and scale sensitivity. Existing methods typically address some of these issues, but do not tackle them all in a unified framework. Therefore, in this paper, we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) that aims to holistically solve these issues. Specifically, we design a transformer-based cross-fusion paradigm that enables effective collaboration of facial landmark and direct image features to maximize proper attention to salient facial regions. Furthermore, POSTER employs a pyramid structure to promote scale invariance. Extensive experimental results demonstrate that our POSTER outperforms SOTA methods on RAF-DB with 92.05%, FERPlus with 91.62%, AffectNet (7 cls) with 67.31%, and AffectNet (8 cls) with 63.34%, respectively.
GiraffeDet: A Heavy-Neck Paradigm for Object Detection
Feb 09, 2022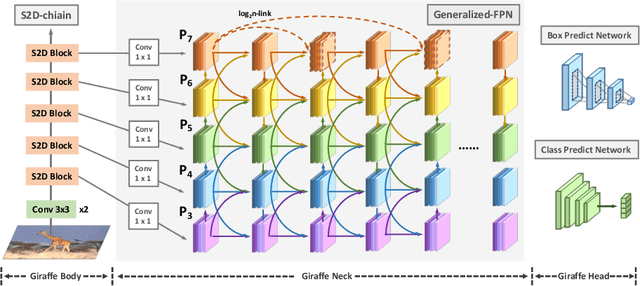
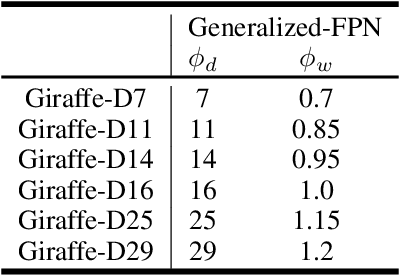
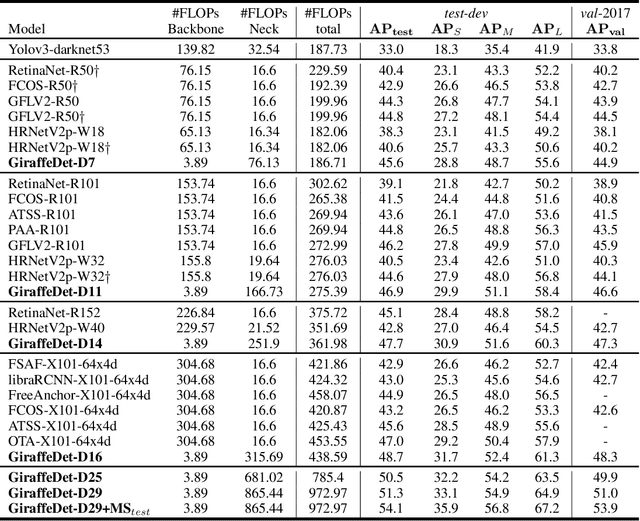
In conventional object detection frameworks, a backbone body inherited from image recognition models extracts deep latent features and then a neck module fuses these latent features to capture information at different scales. As the resolution in object detection is much larger than in image recognition, the computational cost of the backbone often dominates the total inference cost. This heavy-backbone design paradigm is mostly due to the historical legacy when transferring image recognition models to object detection rather than an end-to-end optimized design for object detection. In this work, we show that such paradigm indeed leads to sub-optimal object detection models. To this end, we propose a novel heavy-neck paradigm, GiraffeDet, a giraffe-like network for efficient object detection. The GiraffeDet uses an extremely lightweight backbone and a very deep and large neck module which encourages dense information exchange among different spatial scales as well as different levels of latent semantics simultaneously. This design paradigm allows detectors to process the high-level semantic information and low-level spatial information at the same priority even in the early stage of the network, making it more effective in detection tasks. Numerical evaluations on multiple popular object detection benchmarks show that GiraffeDet consistently outperforms previous SOTA models across a wide spectrum of resource constraints.