 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Data-Free Model Stealing in a Hard Label Setting
Apr 23, 2022
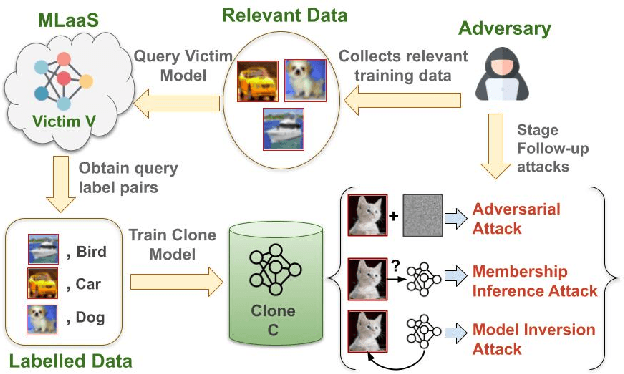
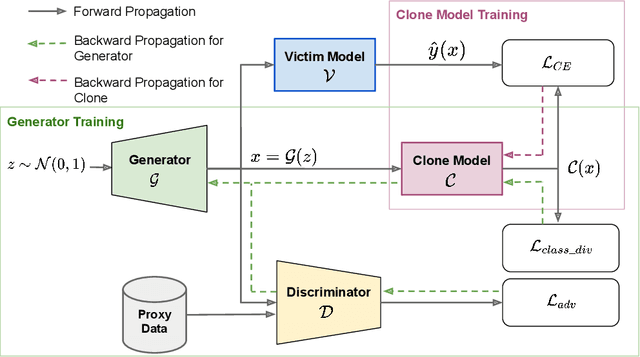

Machine learning models deployed as a service (MLaaS) are susceptible to model stealing attacks, where an adversary attempts to steal the model within a restricted access framework. While existing attacks demonstrate near-perfect clone-model performance using softmax predictions of the classification network, most of the APIs allow access to only the top-1 labels. In this work, we show that it is indeed possible to steal Machine Learning models by accessing only top-1 predictions (Hard Label setting) as well, without access to model gradients (Black-Box setting) or even the training dataset (Data-Free setting) within a low query budget. We propose a novel GAN-based framework that trains the student and generator in tandem to steal the model effectively while overcoming the challenge of the hard label setting by utilizing gradients of the clone network as a proxy to the victim's gradients. We propose to overcome the large query costs associated with a typical Data-Free setting by utilizing publicly available (potentially unrelated) datasets as a weak image prior. We additionally show that even in the absence of such data, it is possible to achieve state-of-the-art results within a low query budget using synthetically crafted samples. We are the first to demonstrate the scalability of Model Stealing in a restricted access setting on a 100 class dataset as well.
On the Pitfalls of Using the Residual Error as Anomaly Score
Feb 08, 2022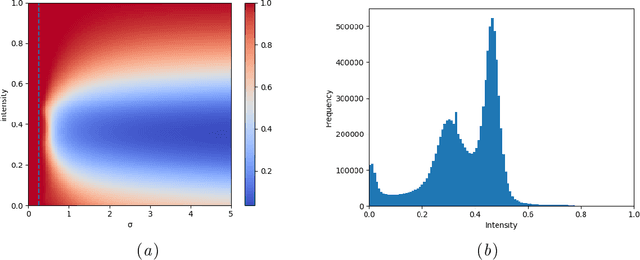
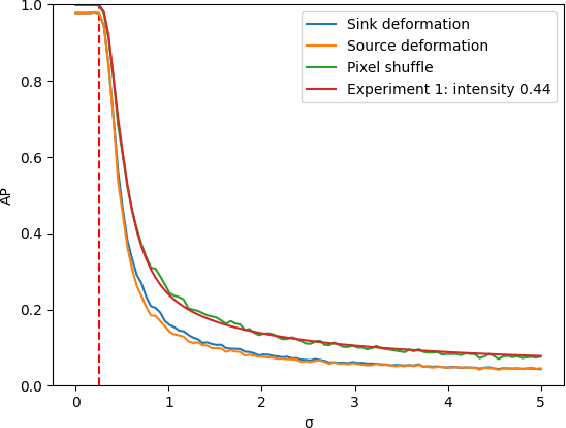
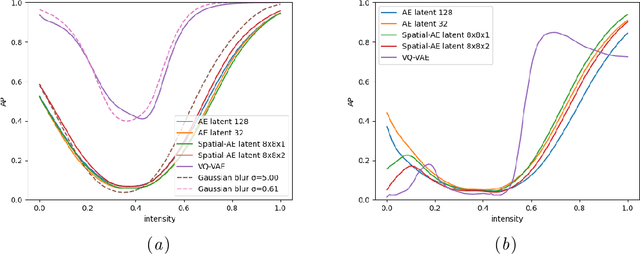
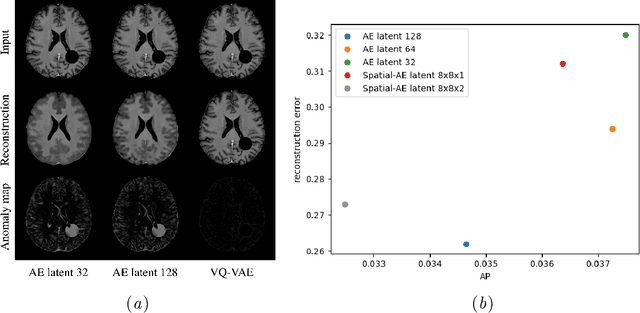
Many current state-of-the-art methods for anomaly localization in medical images rely on calculating a residual image between a potentially anomalous input image and its "healthy" reconstruction. As the reconstruction of the unseen anomalous region should be erroneous, this yields large residuals as a score to detect anomalies in medical images. However, this assumption does not take into account residuals resulting from imperfect reconstructions of the machine learning models used. Such errors can easily overshadow residuals of interest and therefore strongly question the use of residual images as scoring function. Our work explores this fundamental problem of residual images in detail. We theoretically define the problem and thoroughly evaluate the influence of intensity and texture of anomalies against the effect of imperfect reconstructions in a series of experiments. Code and experiments are available under https://github.com/FeliMe/residual-score-pitfalls
Diffractive all-optical computing for quantitative phase imaging
Jan 22, 2022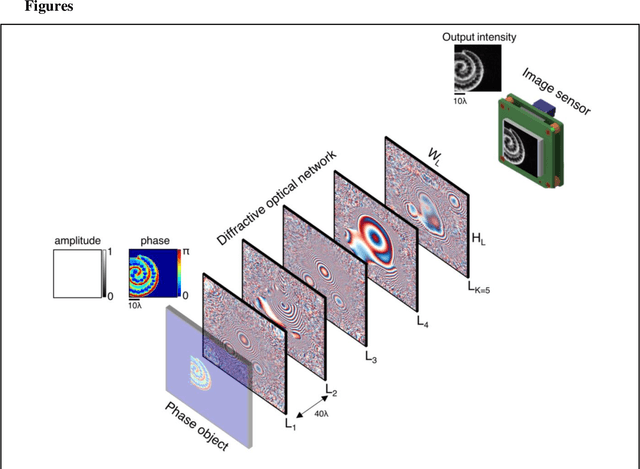

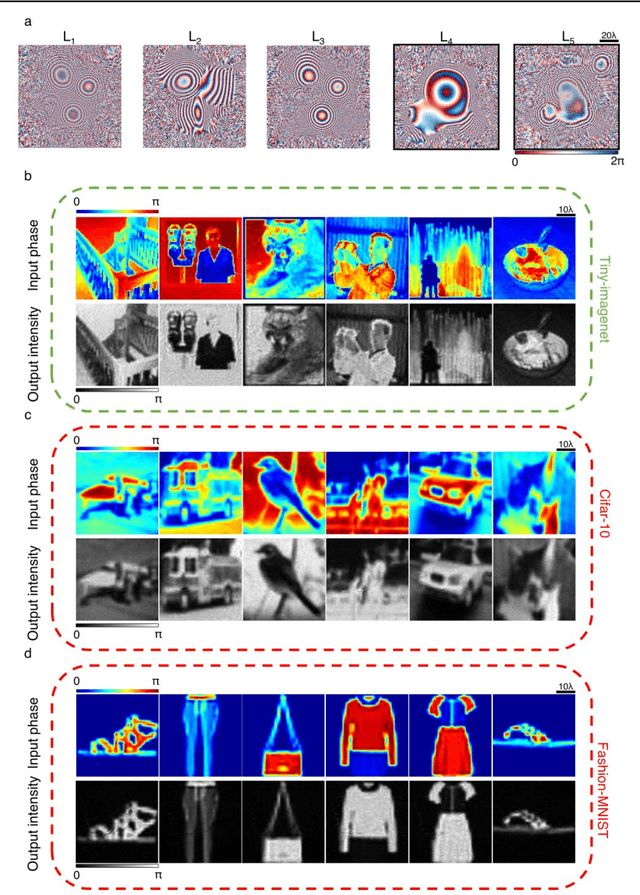
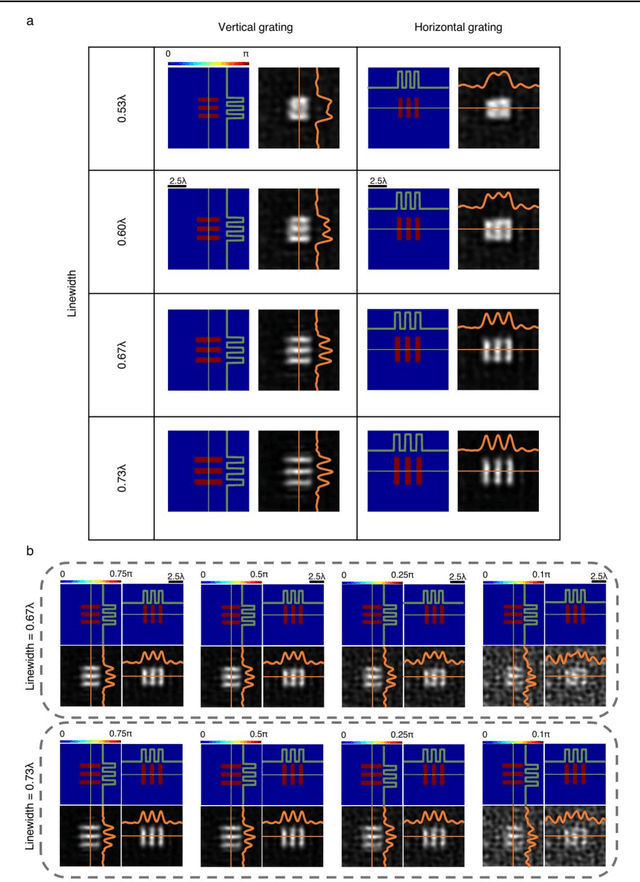
Quantitative phase imaging (QPI) is a label-free computational imaging technique that provides optical path length information of specimens. In modern implementations, the quantitative phase image of an object is reconstructed digitally through numerical methods running in a computer, often using iterative algorithms. Here, we demonstrate a diffractive QPI network that can synthesize the quantitative phase image of an object by converting the input phase information of a scene into intensity variations at the output plane. A diffractive QPI network is a specialized all-optical processor designed to perform a quantitative phase-to-intensity transformation through passive diffractive surfaces that are spatially engineered using deep learning and image data. Forming a compact, all-optical network that axially extends only ~200-300 times the illumination wavelength, this framework can replace traditional QPI systems and related digital computational burden with a set of passive transmissive layers. All-optical diffractive QPI networks can potentially enable power-efficient, high frame-rate and compact phase imaging systems that might be useful for various applications, including, e.g., on-chip microscopy and sensing.
SID-NISM: A Self-supervised Low-light Image Enhancement Framework
Dec 16, 2020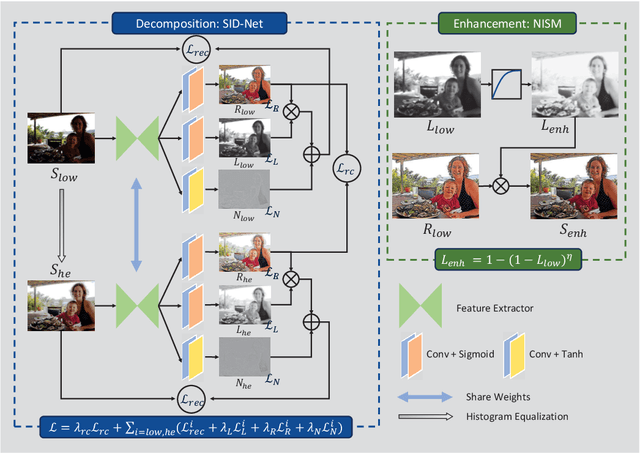
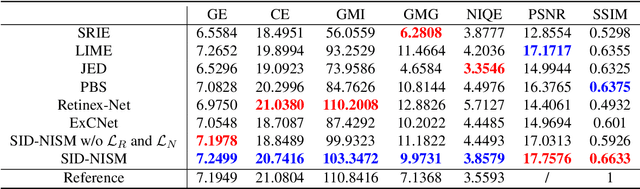
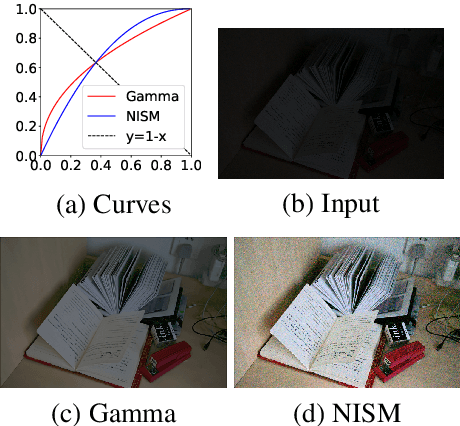
When capturing images in low-light conditions, the images often suffer from low visibility, which not only degrades the visual aesthetics of images, but also significantly degenerates the performance of many computer vision algorithms. In this paper, we propose a self-supervised low-light image enhancement framework (SID-NISM), which consists of two components, a Self-supervised Image Decomposition Network (SID-Net) and a Nonlinear Illumination Saturation Mapping function (NISM). As a self-supervised network, SID-Net could decompose the given low-light image into its reflectance, illumination and noise directly without any prior training or reference image, which distinguishes it from existing supervised-learning methods greatly. Then, the decomposed illumination map will be enhanced by NISM. Having the restored illumination map, the enhancement can be achieved accordingly. Experiments on several public challenging low-light image datasets reveal that the images enhanced by SID-NISM are more natural and have less unexpected artifacts.
Autoregressive 3D Shape Generation via Canonical Mapping
Apr 05, 2022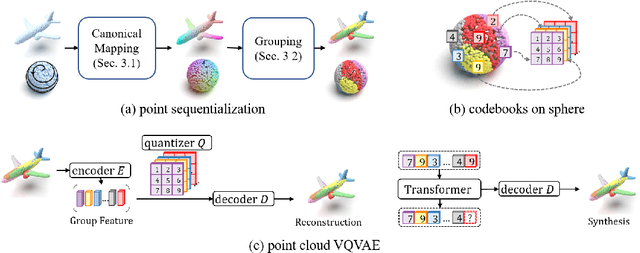
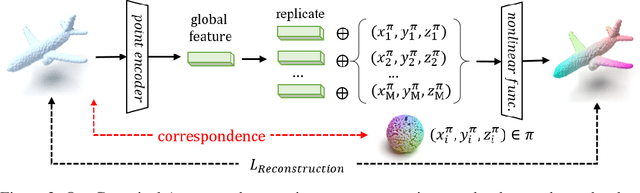
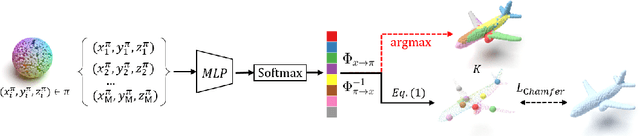
With the capacity of modeling long-range dependencies in sequential data, transformers have shown remarkable performances in a variety of generative tasks such as image, audio, and text generation. Yet, taming them in generating less structured and voluminous data formats such as high-resolution point clouds have seldom been explored due to ambiguous sequentialization processes and infeasible computation burden. In this paper, we aim to further exploit the power of transformers and employ them for the task of 3D point cloud generation. The key idea is to decompose point clouds of one category into semantically aligned sequences of shape compositions, via a learned canonical space. These shape compositions can then be quantized and used to learn a context-rich composition codebook for point cloud generation. Experimental results on point cloud reconstruction and unconditional generation show that our model performs favorably against state-of-the-art approaches. Furthermore, our model can be easily extended to multi-modal shape completion as an application for conditional shape generation.
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
Mar 05, 2022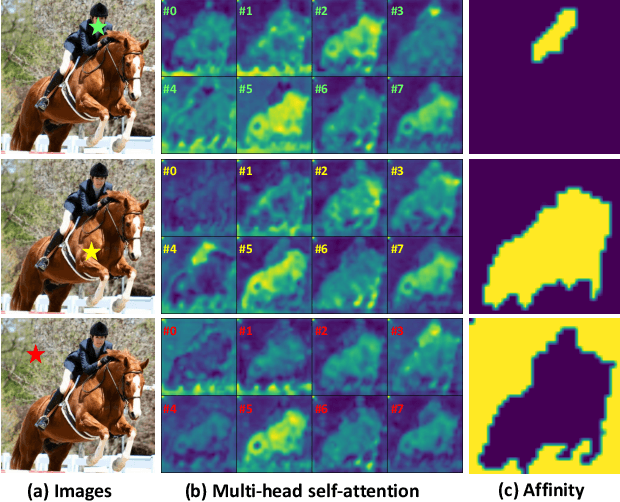


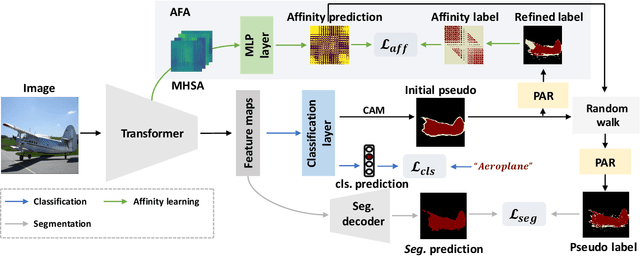
Weakly-supervised semantic segmentation (WSSS) with image-level labels is an important and challenging task. Due to the high training efficiency, end-to-end solutions for WSSS have received increasing attention from the community. However, current methods are mainly based on convolutional neural networks and fail to explore the global information properly, thus usually resulting in incomplete object regions. In this paper, to address the aforementioned problem, we introduce Transformers, which naturally integrate global information, to generate more integral initial pseudo labels for end-to-end WSSS. Motivated by the inherent consistency between the self-attention in Transformers and the semantic affinity, we propose an Affinity from Attention (AFA) module to learn semantic affinity from the multi-head self-attention (MHSA) in Transformers. The learned affinity is then leveraged to refine the initial pseudo labels for segmentation. In addition, to efficiently derive reliable affinity labels for supervising AFA and ensure the local consistency of pseudo labels, we devise a Pixel-Adaptive Refinement module that incorporates low-level image appearance information to refine the pseudo labels. We perform extensive experiments and our method achieves 66.0% and 38.9% mIoU on the PASCAL VOC 2012 and MS COCO 2014 datasets, respectively, significantly outperforming recent end-to-end methods and several multi-stage competitors. Code is available at https://github.com/rulixiang/afa.
Amortized Proximal Optimization
Feb 28, 2022
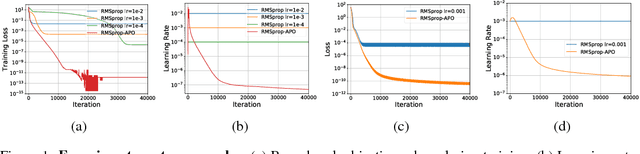
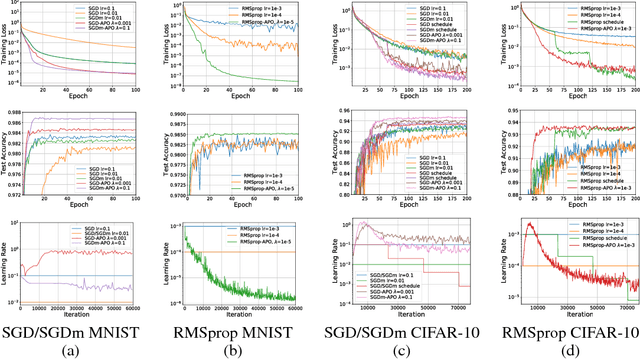

We propose a framework for online meta-optimization of parameters that govern optimization, called Amortized Proximal Optimization (APO). We first interpret various existing neural network optimizers as approximate stochastic proximal point methods which trade off the current-batch loss with proximity terms in both function space and weight space. The idea behind APO is to amortize the minimization of the proximal point objective by meta-learning the parameters of an update rule. We show how APO can be used to adapt a learning rate or a structured preconditioning matrix. Under appropriate assumptions, APO can recover existing optimizers such as natural gradient descent and KFAC. It enjoys low computational overhead and avoids expensive and numerically sensitive operations required by some second-order optimizers, such as matrix inverses. We empirically test APO for online adaptation of learning rates and structured preconditioning matrices for regression, image reconstruction, image classification, and natural language translation tasks. Empirically, the learning rate schedules found by APO generally outperform optimal fixed learning rates and are competitive with manually tuned decay schedules. Using APO to adapt a structured preconditioning matrix generally results in optimization performance competitive with second-order methods. Moreover, the absence of matrix inversion provides numerical stability, making it effective for low precision training.
C2N: Practical Generative Noise Modeling for Real-World Denoising
Feb 19, 2022
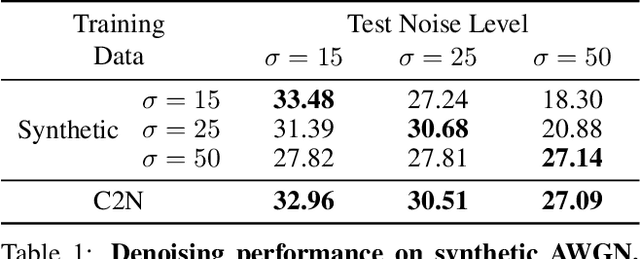
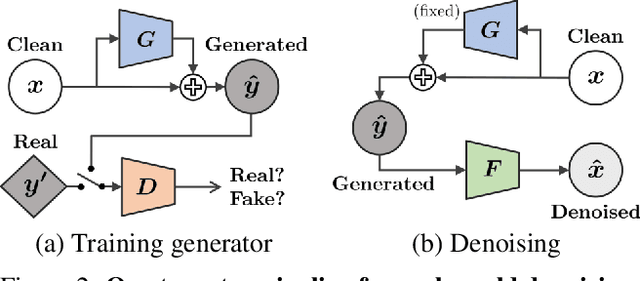

Learning-based image denoising methods have been bounded to situations where well-aligned noisy and clean images are given, or samples are synthesized from predetermined noise models, e.g., Gaussian. While recent generative noise modeling methods aim to simulate the unknown distribution of real-world noise, several limitations still exist. In a practical scenario, a noise generator should learn to simulate the general and complex noise distribution without using paired noisy and clean images. However, since existing methods are constructed on the unrealistic assumption of real-world noise, they tend to generate implausible patterns and cannot express complicated noise maps. Therefore, we introduce a Clean-to-Noisy image generation framework, namely C2N, to imitate complex real-world noise without using any paired examples. We construct the noise generator in C2N accordingly with each component of real-world noise characteristics to express a wide range of noise accurately. Combined with our C2N, conventional denoising CNNs can be trained to outperform existing unsupervised methods on challenging real-world benchmarks by a large margin.
Highdicom: A Python library for standardized encoding of image annotations and machine learning model outputs in pathology and radiology
Jun 14, 2021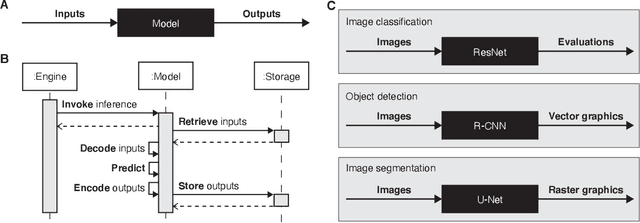
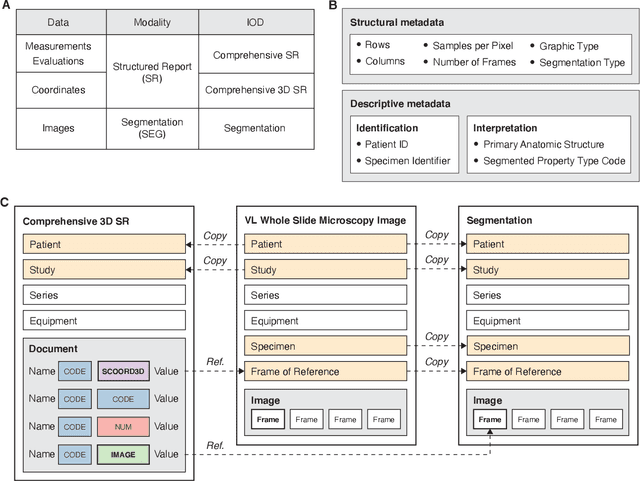
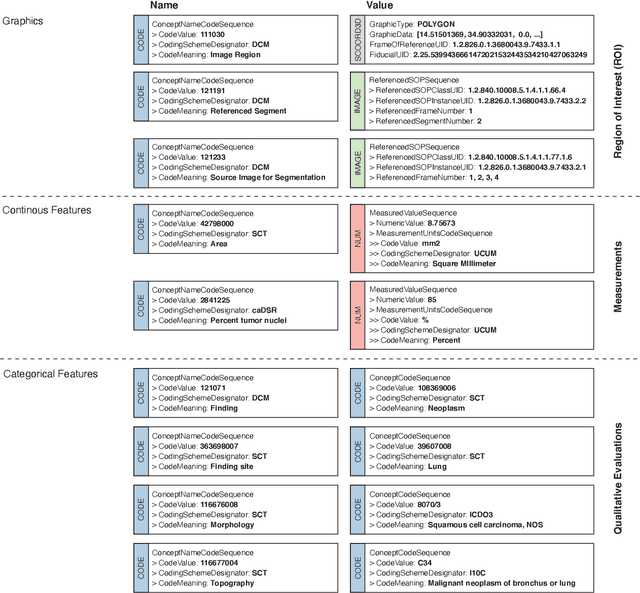
Machine learning is revolutionizing image-based diagnostics in pathology and radiology. ML models have shown promising results in research settings, but their lack of interoperability has been a major barrier for clinical integration and evaluation. The DICOM a standard specifies Information Object Definitions and Services for the representation and communication of digital images and related information, including image-derived annotations and analysis results. However, the complexity of the standard represents an obstacle for its adoption in the ML community and creates a need for software libraries and tools that simplify working with data sets in DICOM format. Here we present the highdicom library, which provides a high-level application programming interface for the Python programming language that abstracts low-level details of the standard and enables encoding and decoding of image-derived information in DICOM format in a few lines of Python code. The highdicom library ties into the extensive Python ecosystem for image processing and machine learning. Simultaneously, by simplifying creation and parsing of DICOM-compliant files, highdicom achieves interoperability with the medical imaging systems that hold the data used to train and run ML models, and ultimately communicate and store model outputs for clinical use. We demonstrate through experiments with slide microscopy and computed tomography imaging, that, by bridging these two ecosystems, highdicom enables developers to train and evaluate state-of-the-art ML models in pathology and radiology while remaining compliant with the DICOM standard and interoperable with clinical systems at all stages. To promote standardization of ML research and streamline the ML model development and deployment process, we made the library available free and open-source.
Attribute Descent: Simulating Object-Centric Datasets on the Content Level and Beyond
Feb 28, 2022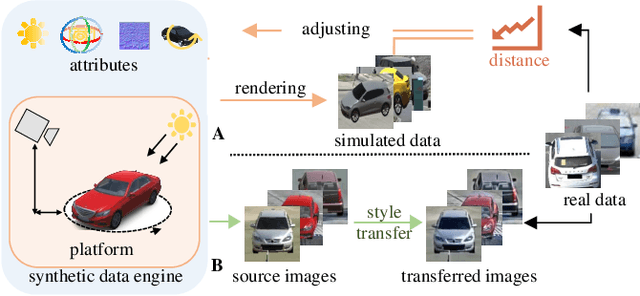
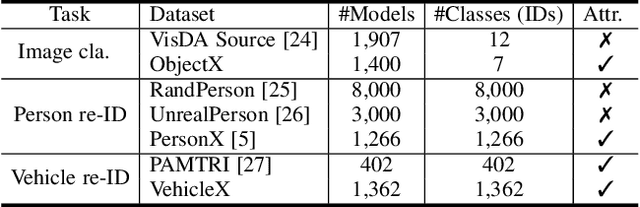

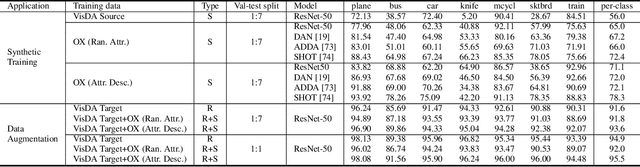
This article aims to use graphic engines to simulate a large number of training data that have free annotations and possibly strongly resemble to real-world data. Between synthetic and real, a two-level domain gap exists, involving content level and appearance level. While the latter is concerned with appearance style, the former problem arises from a different mechanism, i.e., content mismatch in attributes such as camera viewpoint, object placement and lighting conditions. In contrast to the widely-studied appearance-level gap, the content-level discrepancy has not been broadly studied. To address the content-level misalignment, we propose an attribute descent approach that automatically optimizes engine attributes to enable synthetic data to approximate real-world data. We verify our method on object-centric tasks, wherein an object takes up a major portion of an image. In these tasks, the search space is relatively small, and the optimization of each attribute yields sufficiently obvious supervision signals. We collect a new synthetic asset VehicleX, and reformat and reuse existing the synthetic assets ObjectX and PersonX. Extensive experiments on image classification and object re-identification confirm that adapted synthetic data can be effectively used in three scenarios: training with synthetic data only, training data augmentation and numerically understanding dataset content.