 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020

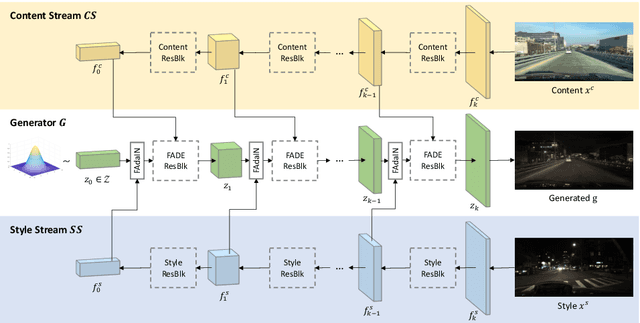
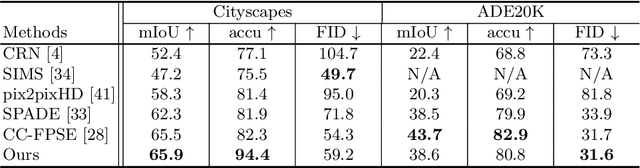
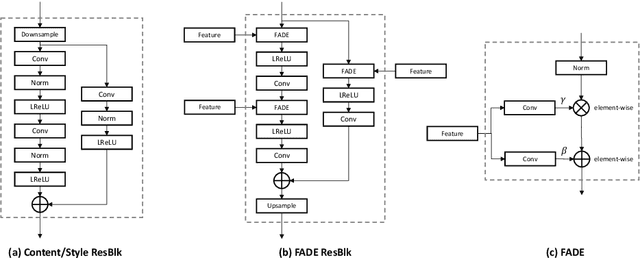
We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.
Learning a Weight Map for Weakly-Supervised Localization
Nov 28, 2021
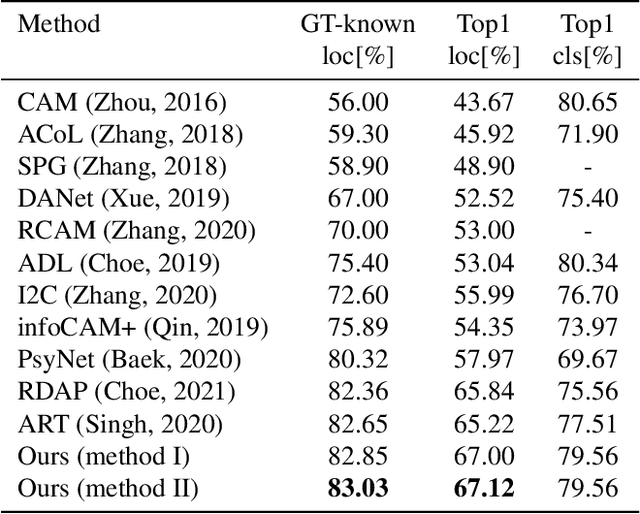
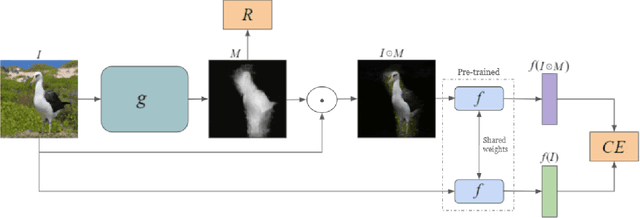
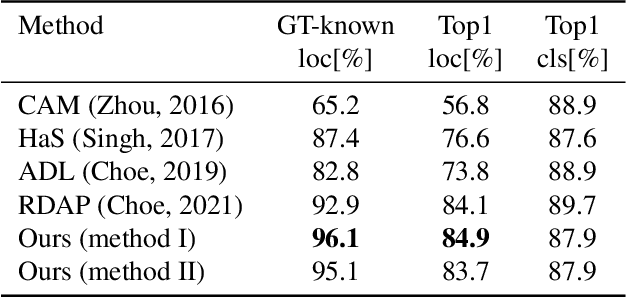
In the weakly supervised localization setting, supervision is given as an image-level label. We propose to employ an image classifier $f$ and to train a generative network $g$ that outputs, given the input image, a per-pixel weight map that indicates the location of the object within the image. Network $g$ is trained by minimizing the discrepancy between the output of the classifier $f$ on the original image and its output given the same image weighted by the output of $g$. The scheme requires a regularization term that ensures that $g$ does not provide a uniform weight, and an early stopping criterion in order to prevent $g$ from over-segmenting the image. Our results indicate that the method outperforms existing localization methods by a sizable margin on the challenging fine-grained classification datasets, as well as a generic image recognition dataset. Additionally, the obtained weight map is also state-of-the-art in weakly supervised segmentation in fine-grained categorization datasets.
StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Apr 30, 2021
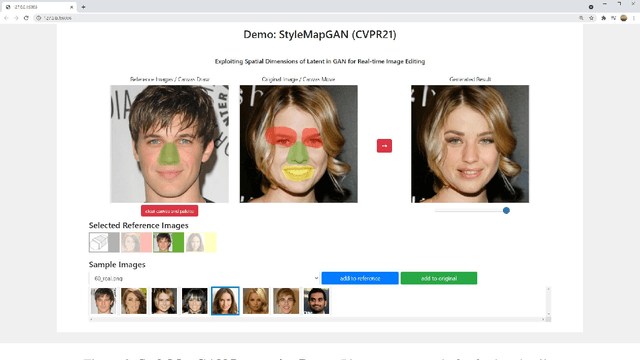
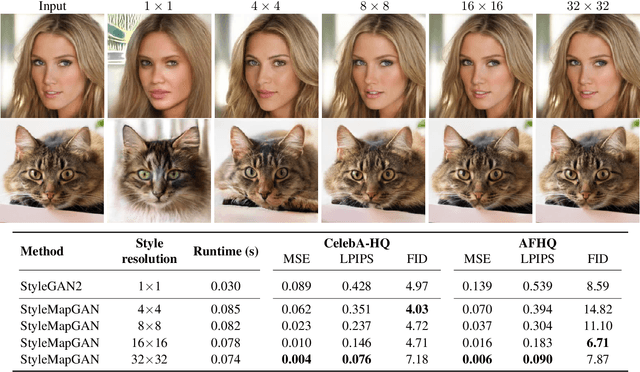
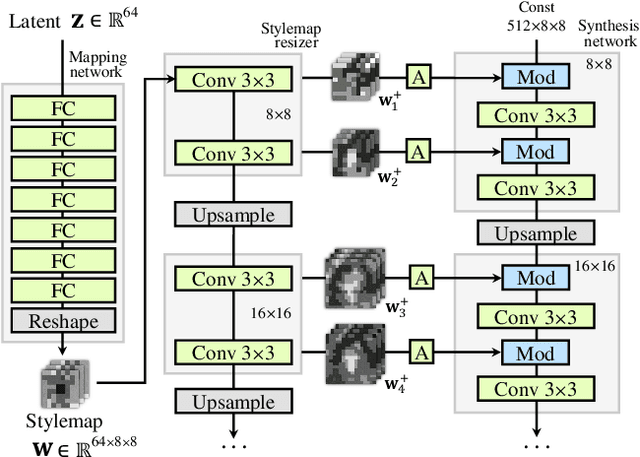
Generative adversarial networks (GANs) synthesize realistic images from random latent vectors. Although manipulating the latent vectors controls the synthesized outputs, editing real images with GANs suffers from i) time-consuming optimization for projecting real images to the latent vectors, ii) or inaccurate embedding through an encoder. We propose StyleMapGAN: the intermediate latent space has spatial dimensions, and a spatially variant modulation replaces AdaIN. It makes the embedding through an encoder more accurate than existing optimization-based methods while maintaining the properties of GANs. Experimental results demonstrate that our method significantly outperforms state-of-the-art models in various image manipulation tasks such as local editing and image interpolation. Last but not least, conventional editing methods on GANs are still valid on our StyleMapGAN. Source code is available at https://github.com/naver-ai/StyleMapGAN.
Compositional Learning of Image-Text Query for Image Retrieval
Jun 19, 2020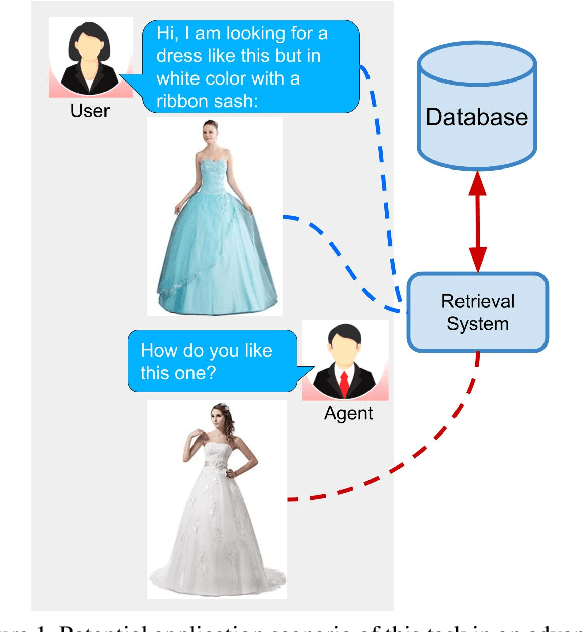
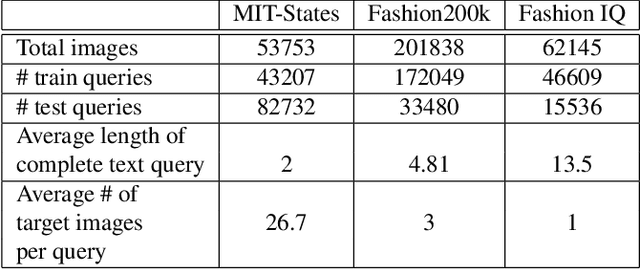
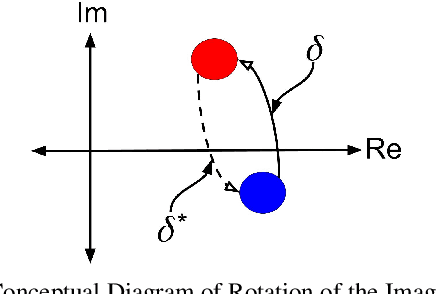
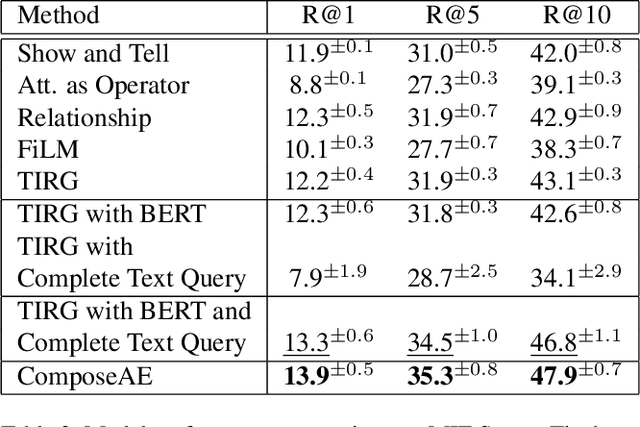
In this paper, we investigate the problem of retrieving images from a database based on a multi-modal (image-text) query. Specifically, the query text prompts some modification in the query image and the task is to retrieve images with the desired modifications. For instance, a user of an E-Commerce platform is interested in buying a dress, which should look similar to her friend's dress, but the dress should be of white color with a ribbon sash. In this case, we would like the algorithm to retrieve some dresses with desired modifications in the query dress. We propose an autoencoder based model, ComposeAE, to learn the composition of image and text query for retrieving images. We adopt a deep metric learning approach and learn a metric that pushes composition of source image and text query closer to the target images. We also propose a rotational symmetry constraint on the optimization problem. Our approach is able to outperform the state-of-the-art method TIRG \cite{TIRG} on three benchmark datasets, namely: MIT-States, Fashion200k and Fashion IQ. In order to ensure fair comparison, we introduce strong baselines by enhancing TIRG method. To ensure reproducibility of the results, we publish our code here: \url{https://anonymous.4open.science/r/d1babc3c-0e72-448a-8594-b618bae876dc/}.
RelViT: Concept-guided Vision Transformer for Visual Relational Reasoning
Apr 24, 2022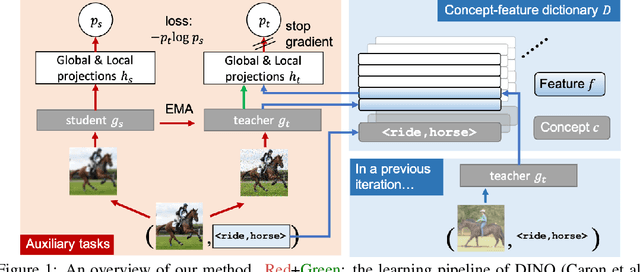
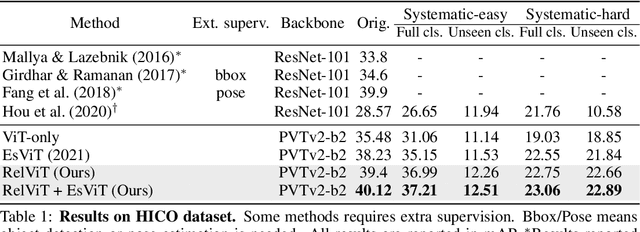
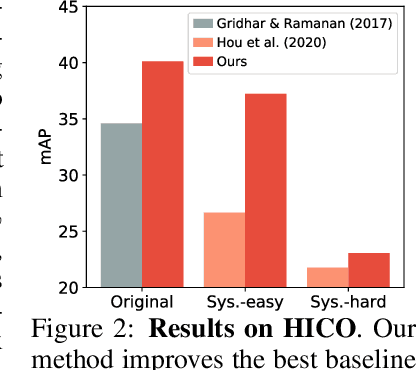

Reasoning about visual relationships is central to how humans interpret the visual world. This task remains challenging for current deep learning algorithms since it requires addressing three key technical problems jointly: 1) identifying object entities and their properties, 2) inferring semantic relations between pairs of entities, and 3) generalizing to novel object-relation combinations, i.e., systematic generalization. In this work, we use vision transformers (ViTs) as our base model for visual reasoning and make better use of concepts defined as object entities and their relations to improve the reasoning ability of ViTs. Specifically, we introduce a novel concept-feature dictionary to allow flexible image feature retrieval at training time with concept keys. This dictionary enables two new concept-guided auxiliary tasks: 1) a global task for promoting relational reasoning, and 2) a local task for facilitating semantic object-centric correspondence learning. To examine the systematic generalization of visual reasoning models, we introduce systematic splits for the standard HICO and GQA benchmarks. We show the resulting model, Concept-guided Vision Transformer (or RelViT for short) significantly outperforms prior approaches on HICO and GQA by 16% and 13% in the original split, and by 43% and 18% in the systematic split. Our ablation analyses also reveal our model's compatibility with multiple ViT variants and robustness to hyper-parameters.
Self-Organized Residual Blocks for Image Super-Resolution
May 31, 2021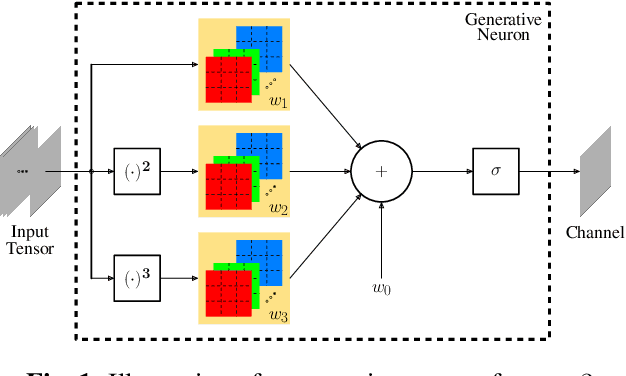
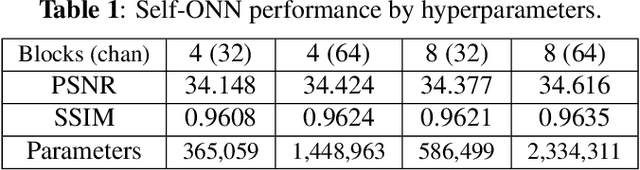
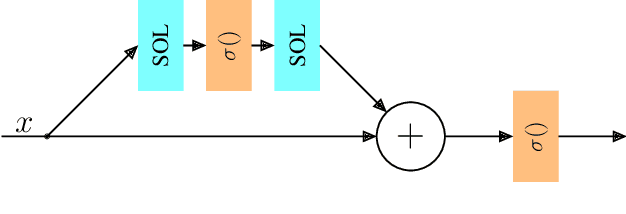
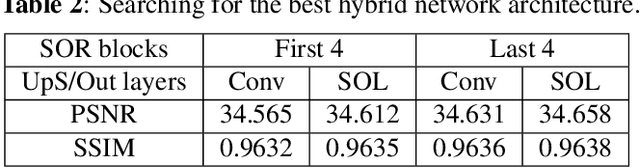
It has become a standard practice to use the convolutional networks (ConvNet) with RELU non-linearity in image restoration and super-resolution (SR). Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks (ONNs) that choose the best non-linearity from a set of alternatives, and their "self-organized" variants (Self-ONN) that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this paper, we propose the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results demonstrate that the~proposed architectures yield performance improvements in both PSNR and perceptual metrics.
On Hyperbolic Embeddings in 2D Object Detection
Mar 18, 2022



Object detection, for the most part, has been formulated in the euclidean space, where euclidean or spherical geodesic distances measure the similarity of an image region to an object class prototype. In this work, we study whether a hyperbolic geometry better matches the underlying structure of the object classification space. We incorporate a hyperbolic classifier in two-stage, keypoint-based, and transformer-based object detection architectures and evaluate them on large-scale, long-tailed, and zero-shot object detection benchmarks. In our extensive experimental evaluations, we observe categorical class hierarchies emerging in the structure of the classification space, resulting in lower classification errors and boosting the overall object detection performance.
Robustness Testing of Data and Knowledge Driven Anomaly Detection in Cyber-Physical Systems
Apr 20, 2022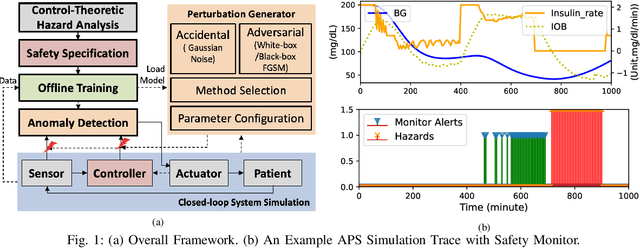
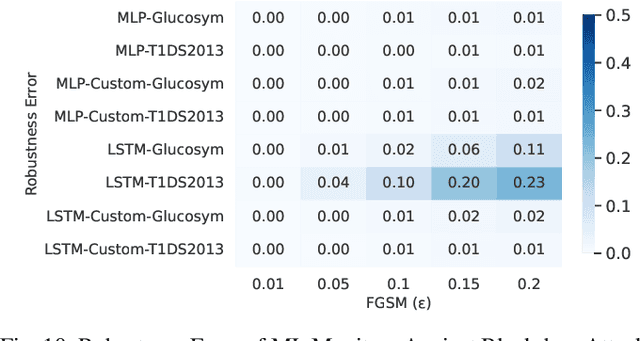
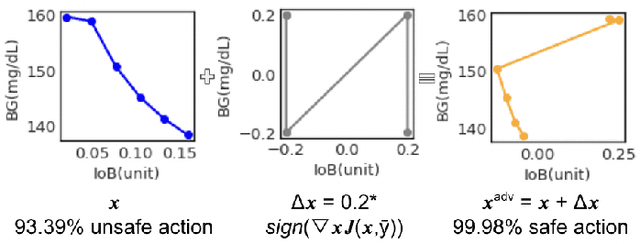
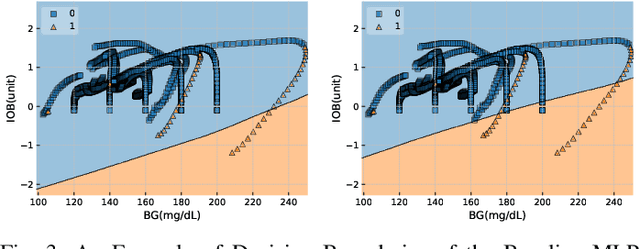
The growing complexity of Cyber-Physical Systems (CPS) and challenges in ensuring safety and security have led to the increasing use of deep learning methods for accurate and scalable anomaly detection. However, machine learning (ML) models often suffer from low performance in predicting unexpected data and are vulnerable to accidental or malicious perturbations. Although robustness testing of deep learning models has been extensively explored in applications such as image classification and speech recognition, less attention has been paid to ML-driven safety monitoring in CPS. This paper presents the preliminary results on evaluating the robustness of ML-based anomaly detection methods in safety-critical CPS against two types of accidental and malicious input perturbations, generated using a Gaussian-based noise model and the Fast Gradient Sign Method (FGSM). We test the hypothesis of whether integrating the domain knowledge (e.g., on unsafe system behavior) with the ML models can improve the robustness of anomaly detection without sacrificing accuracy and transparency. Experimental results with two case studies of Artificial Pancreas Systems (APS) for diabetes management show that ML-based safety monitors trained with domain knowledge can reduce on average up to 54.2% of robustness error and keep the average F1 scores high while improving transparency.
The Geometry of Deep Generative Image Models and its Applications
Jan 15, 2021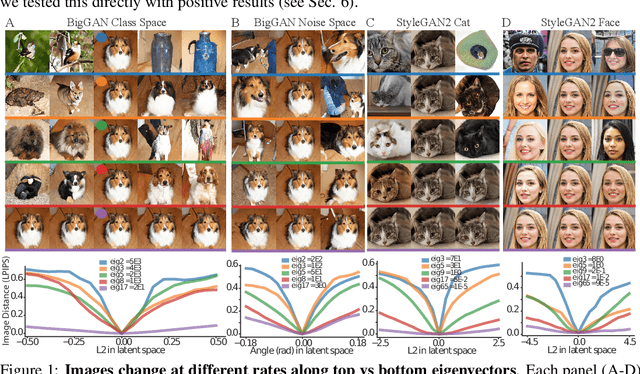
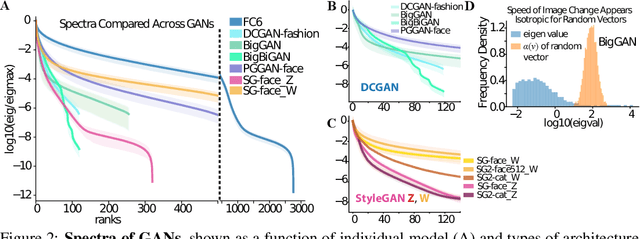
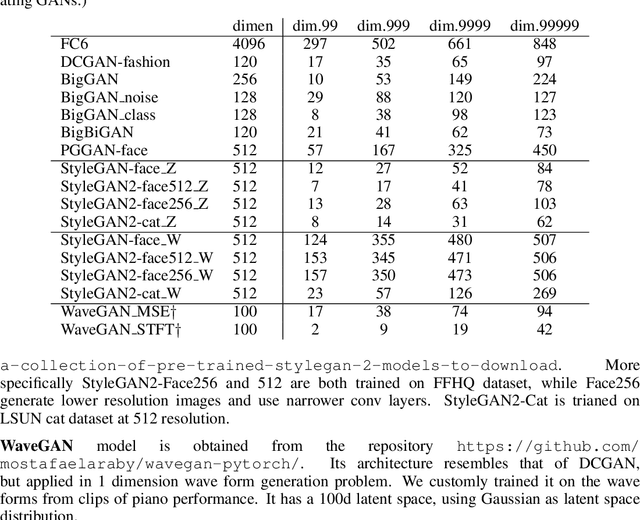
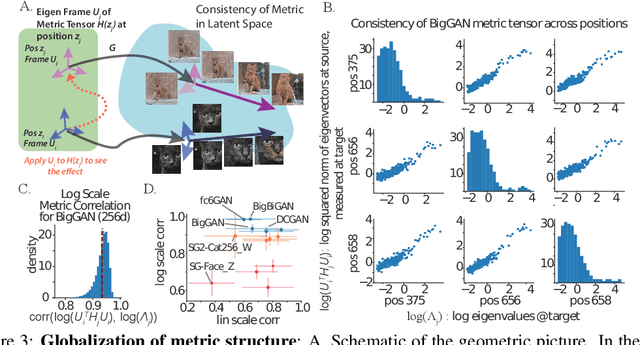
Generative adversarial networks (GANs) have emerged as a powerful unsupervised method to model the statistical patterns of real-world data sets, such as natural images. These networks are trained to map random inputs in their latent space to new samples representative of the learned data. However, the structure of the latent space is hard to intuit due to its high dimensionality and the non-linearity of the generator, which limits the usefulness of the models. Understanding the latent space requires a way to identify input codes for existing real-world images (inversion), and a way to identify directions with known image transformations (interpretability). Here, we use a geometric framework to address both issues simultaneously. We develop an architecture-agnostic method to compute the Riemannian metric of the image manifold created by GANs. The eigen-decomposition of the metric isolates axes that account for different levels of image variability. An empirical analysis of several pretrained GANs shows that image variation around each position is concentrated along surprisingly few major axes (the space is highly anisotropic) and the directions that create this large variation are similar at different positions in the space (the space is homogeneous). We show that many of the top eigenvectors correspond to interpretable transforms in the image space, with a substantial part of eigenspace corresponding to minor transforms which could be compressed out. This geometric understanding unifies key previous results related to GAN interpretability. We show that the use of this metric allows for more efficient optimization in the latent space (e.g. GAN inversion) and facilitates unsupervised discovery of interpretable axes. Our results illustrate that defining the geometry of the GAN image manifold can serve as a general framework for understanding GANs.
ALA: Adversarial Lightness Attack via Naturalness-aware Regularizations
Jan 16, 2022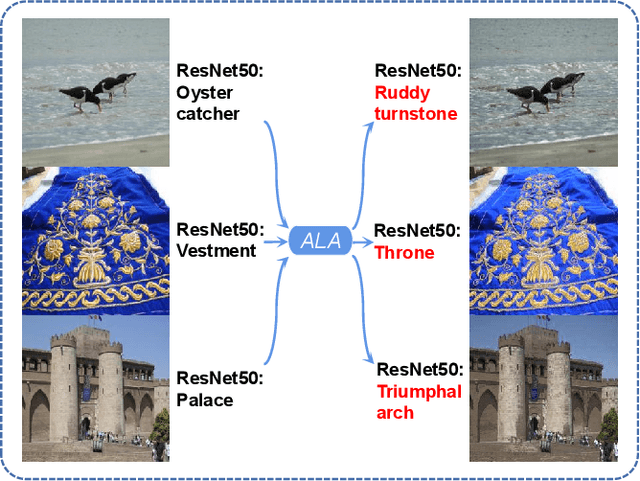
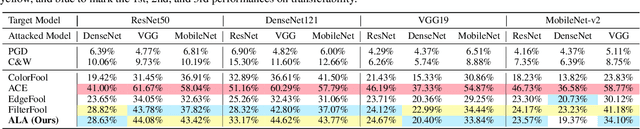
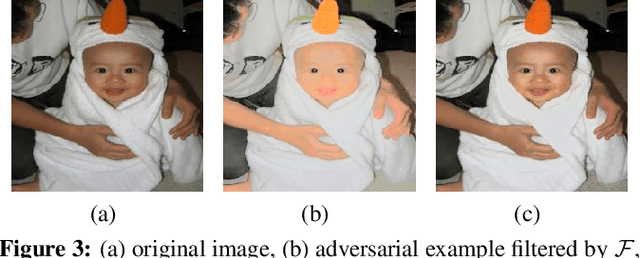
Most researchers have tried to enhance the robustness of deep neural networks (DNNs) by revealing and repairing the vulnerability of DNNs with specialized adversarial examples. Parts of the attack examples have imperceptible perturbations restricted by Lp norm. However, due to their high-frequency property, the adversarial examples usually have poor transferability and can be defensed by denoising methods. To avoid the defects, some works make the perturbations unrestricted to gain better robustness and transferability. However, these examples usually look unnatural and alert the guards. To generate unrestricted adversarial examples with high image quality and good transferability, in this paper, we propose Adversarial Lightness Attack (ALA), a white-box unrestricted adversarial attack that focuses on modifying the lightness of the images. The shape and color of the samples, which are crucial to human perception, are barely influenced. To obtain adversarial examples with high image quality, we craft a naturalness-aware regularization. To achieve stronger transferability, we propose random initialization and non-stop attack strategy in the attack procedure. We verify the effectiveness of ALA on two popular datasets for different tasks (i.e., ImageNet for image classification and Places-365 for scene recognition). The experiments show that the generated adversarial examples have both strong transferability and high image quality. Besides, the adversarial examples can also help to improve the standard trained ResNet50 on defending lightness corruption.