 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Servoing for Pose Control of Soft Continuum Arm in a Structured Environment
Feb 10, 2022

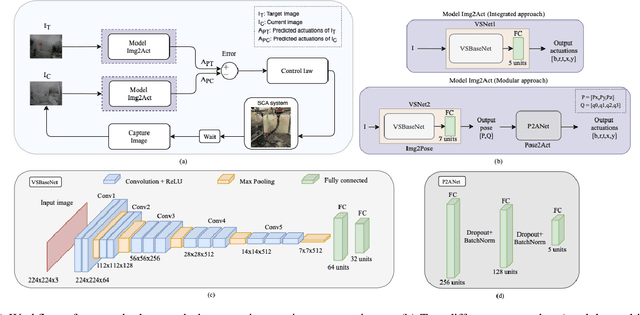

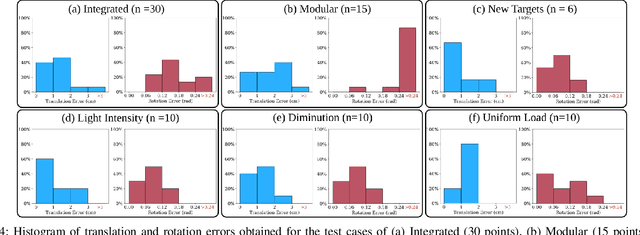
For soft continuum arms, visual servoing is a popular control strategy that relies on visual feedback to close the control loop. However, robust visual servoing is challenging as it requires reliable feature extraction from the image, accurate control models and sensors to perceive the shape of the arm, both of which can be hard to implement in a soft robot. This letter circumvents these challenges by presenting a deep neural network-based method to perform smooth and robust 3D positioning tasks on a soft arm by visual servoing using a camera mounted at the distal end of the arm. A convolutional neural network is trained to predict the actuations required to achieve the desired pose in a structured environment. Integrated and modular approaches for estimating the actuations from the image are proposed and are experimentally compared. A proportional control law is implemented to reduce the error between the desired and current image as seen by the camera. The model together with the proportional feedback control makes the described approach robust to several variations such as new targets, lighting, loads, and diminution of the soft arm. Furthermore, the model lends itself to be transferred to a new environment with minimal effort.
SLIP: Self-supervision meets Language-Image Pre-training
Dec 23, 2021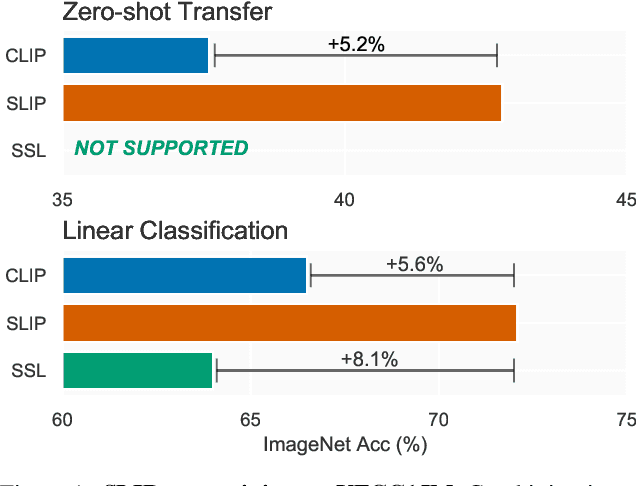
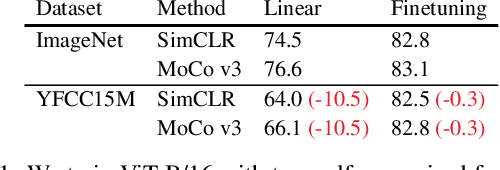
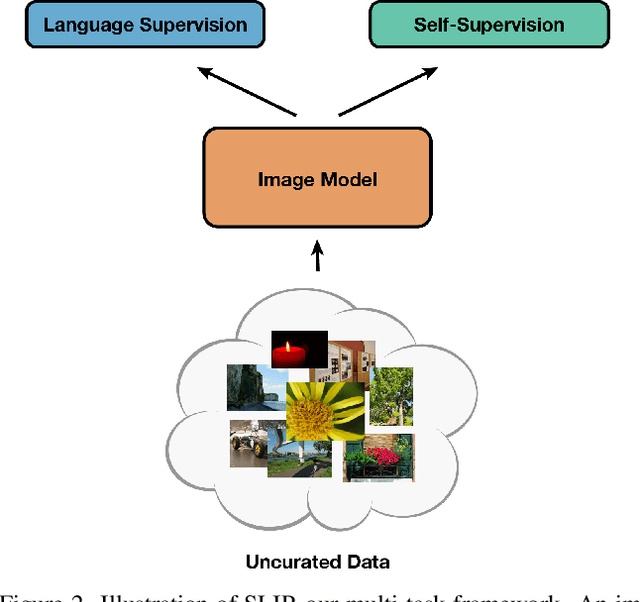
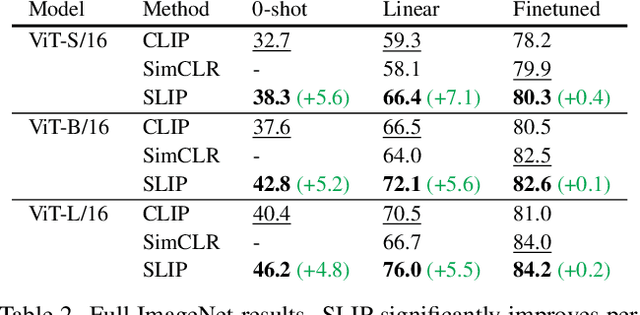
Recent work has shown that self-supervised pre-training leads to improvements over supervised learning on challenging visual recognition tasks. CLIP, an exciting new approach to learning with language supervision, demonstrates promising performance on a wide variety of benchmarks. In this work, we explore whether self-supervised learning can aid in the use of language supervision for visual representation learning. We introduce SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. After pre-training with Vision Transformers, we thoroughly evaluate representation quality and compare performance to both CLIP and self-supervised learning under three distinct settings: zero-shot transfer, linear classification, and end-to-end finetuning. Across ImageNet and a battery of additional datasets, we find that SLIP improves accuracy by a large margin. We validate our results further with experiments on different model sizes, training schedules, and pre-training datasets. Our findings show that SLIP enjoys the best of both worlds: better performance than self-supervision (+8.1% linear accuracy) and language supervision (+5.2% zero-shot accuracy).
News Image Steganography: A Novel Architecture Facilitates the Fake News Identification
Jan 03, 2021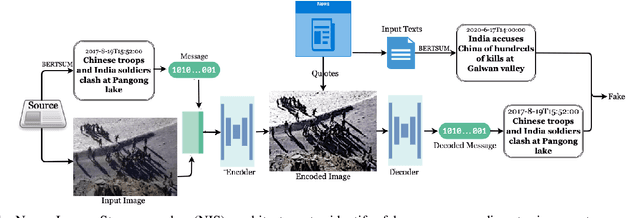

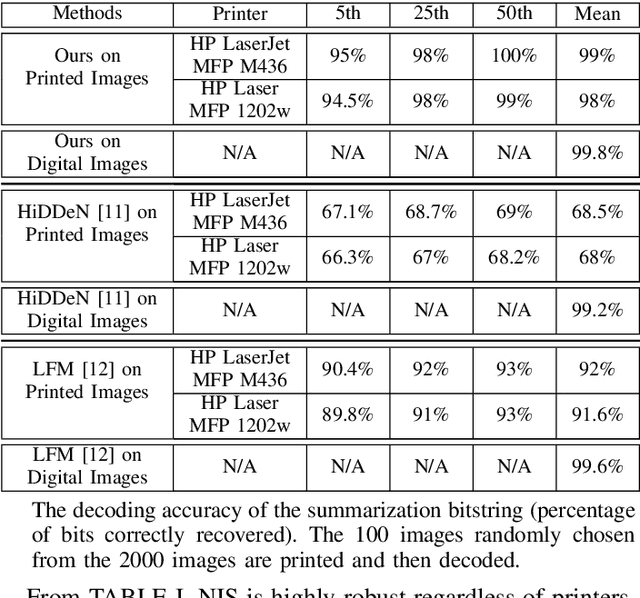
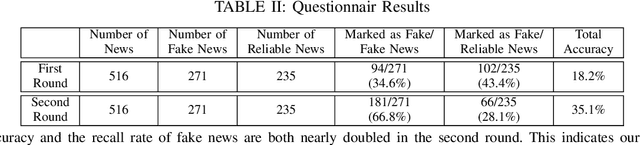
A larger portion of fake news quotes untampered images from other sources with ulterior motives rather than conducting image forgery. Such elaborate engraftments keep the inconsistency between images and text reports stealthy, thereby, palm off the spurious for the genuine. This paper proposes an architecture named News Image Steganography (NIS) to reveal the aforementioned inconsistency through image steganography based on GAN. Extractive summarization about a news image is generated based on its source texts, and a learned steganographic algorithm encodes and decodes the summarization of the image in a manner that approaches perceptual invisibility. Once an encoded image is quoted, its source summarization can be decoded and further presented as the ground truth to verify the quoting news. The pairwise encoder and decoder endow images of the capability to carry along their imperceptible summarization. Our NIS reveals the underlying inconsistency, thereby, according to our experiments and investigations, contributes to the identification accuracy of fake news that engrafts untampered images.
Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
May 07, 2022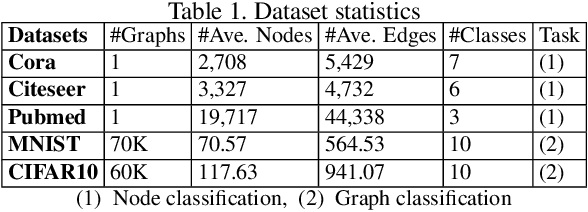
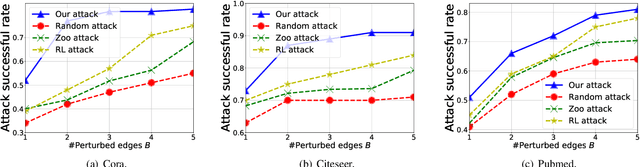
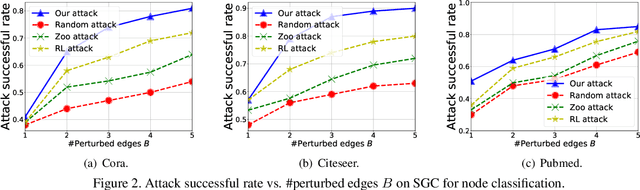
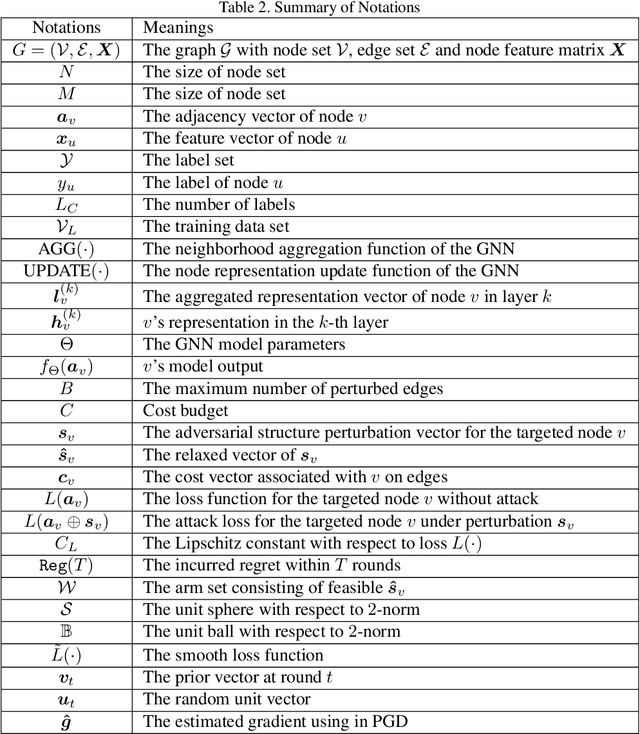
Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-based tasks such as node classification and graph classification. However, many recent works have demonstrated that an attacker can mislead GNN models by slightly perturbing the graph structure. Existing attacks to GNNs are either under the less practical threat model where the attacker is assumed to access the GNN model parameters, or under the practical black-box threat model but consider perturbing node features that are shown to be not enough effective. In this paper, we aim to bridge this gap and consider black-box attacks to GNNs with structure perturbation as well as with theoretical guarantees. We propose to address this challenge through bandit techniques. Specifically, we formulate our attack as an online optimization with bandit feedback. This original problem is essentially NP-hard due to the fact that perturbing the graph structure is a binary optimization problem. We then propose an online attack based on bandit optimization which is proven to be {sublinear} to the query number $T$, i.e., $\mathcal{O}(\sqrt{N}T^{3/4})$ where $N$ is the number of nodes in the graph. Finally, we evaluate our proposed attack by conducting experiments over multiple datasets and GNN models. The experimental results on various citation graphs and image graphs show that our attack is both effective and efficient. Source code is available at~\url{https://github.com/Metaoblivion/Bandit_GNN_Attack}
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-to-Video Synthesis
Feb 26, 2021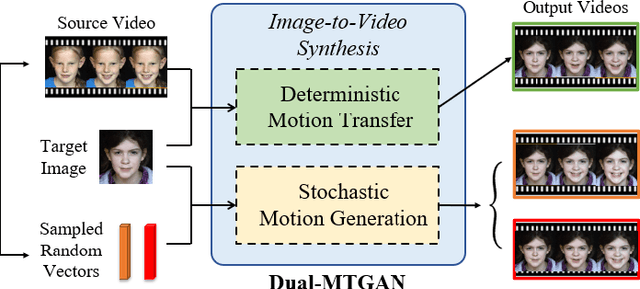
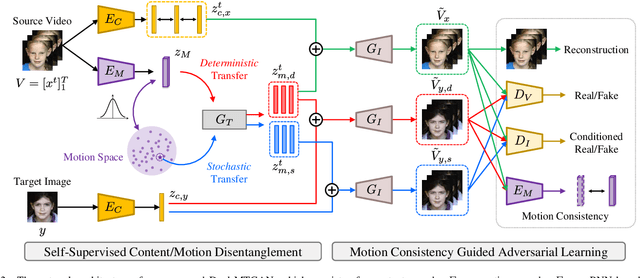


Generating videos with content and motion variations is a challenging task in computer vision. While the recent development of GAN allows video generation from latent representations, it is not easy to produce videos with particular content of motion patterns of interest. In this paper, we propose Dual Motion Transfer GAN (Dual-MTGAN), which takes image and video data as inputs while learning disentangled content and motion representations. Our Dual-MTGAN is able to perform deterministic motion transfer and stochastic motion generation. Based on a given image, the former preserves the input content and transfers motion patterns observed from another video sequence, and the latter directly produces videos with plausible yet diverse motion patterns based on the input image. The proposed model is trained in an end-to-end manner, without the need to utilize pre-defined motion features like pose or facial landmarks. Our quantitative and qualitative results would confirm the effectiveness and robustness of our model in addressing such conditioned image-to-video tasks.
Hephaestus: A large scale multitask dataset towards InSAR understanding
Apr 20, 2022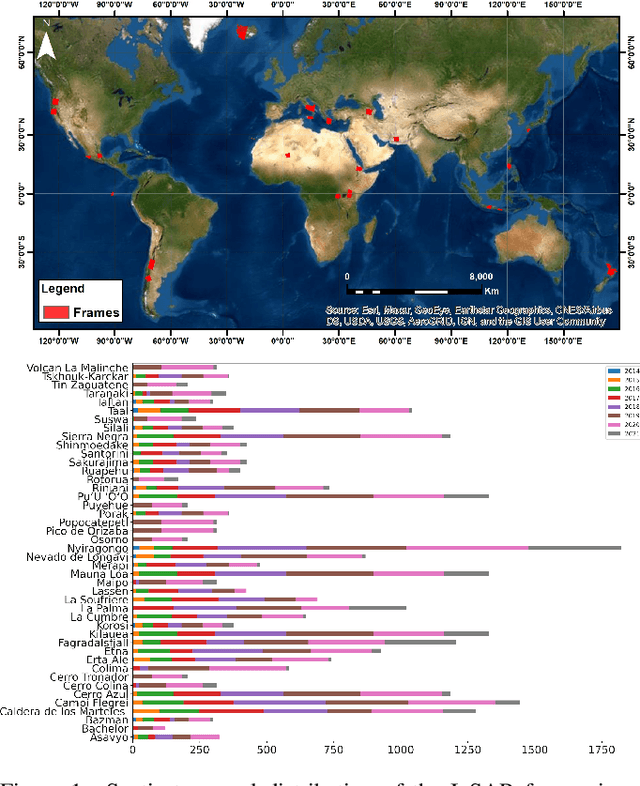
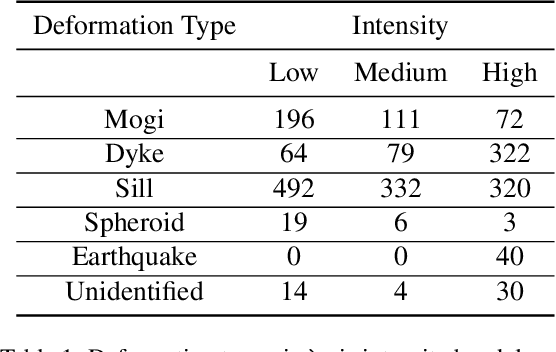
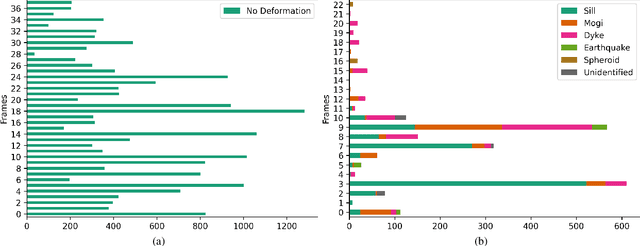
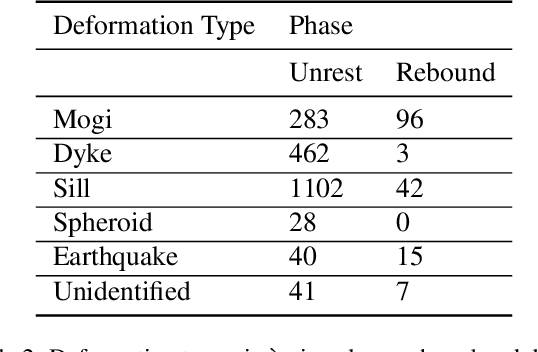
Synthetic Aperture Radar (SAR) data and Interferometric SAR (InSAR) products in particular, are one of the largest sources of Earth Observation data. InSAR provides unique information on diverse geophysical processes and geology, and on the geotechnical properties of man-made structures. However, there are only a limited number of applications that exploit the abundance of InSAR data and deep learning methods to extract such knowledge. The main barrier has been the lack of a large curated and annotated InSAR dataset, which would be costly to create and would require an interdisciplinary team of experts experienced on InSAR data interpretation. In this work, we put the effort to create and make available the first of its kind, manually annotated dataset that consists of 19,919 individual Sentinel-1 interferograms acquired over 44 different volcanoes globally, which are split into 216,106 InSAR patches. The annotated dataset is designed to address different computer vision problems, including volcano state classification, semantic segmentation of ground deformation, detection and classification of atmospheric signals in InSAR imagery, interferogram captioning, text to InSAR generation, and InSAR image quality assessment.
Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network
Apr 14, 2021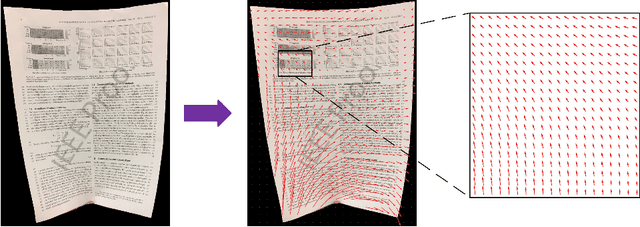

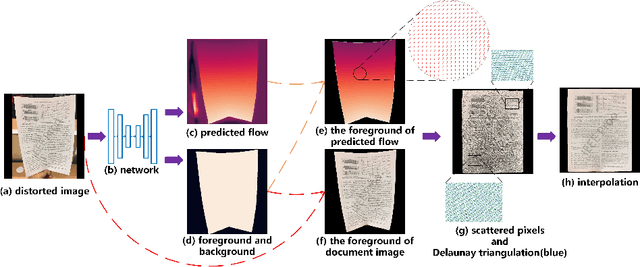
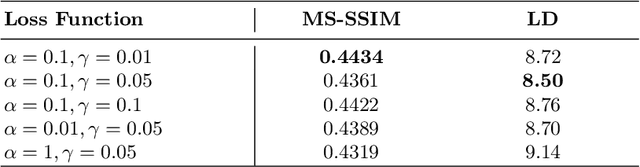
As camera-based documents are increasingly used, the rectification of distorted document images becomes a need to improve the recognition performance. In this paper, we propose a novel framework for both rectifying distorted document image and removing background finely, by estimating pixel-wise displacements using a fully convolutional network (FCN). The document image is rectified by transformation according to the displacements of pixels. The FCN is trained by regressing displacements of synthesized distorted documents, and to control the smoothness of displacements, we propose a Local Smooth Constraint (LSC) in regularization. Our approach is easy to implement and consumes moderate computing resource. Experiments proved that our approach can dewarp document images effectively under various geometric distortions, and has achieved the state-of-the-art performance in terms of local details and overall effect.
Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers
Apr 25, 2022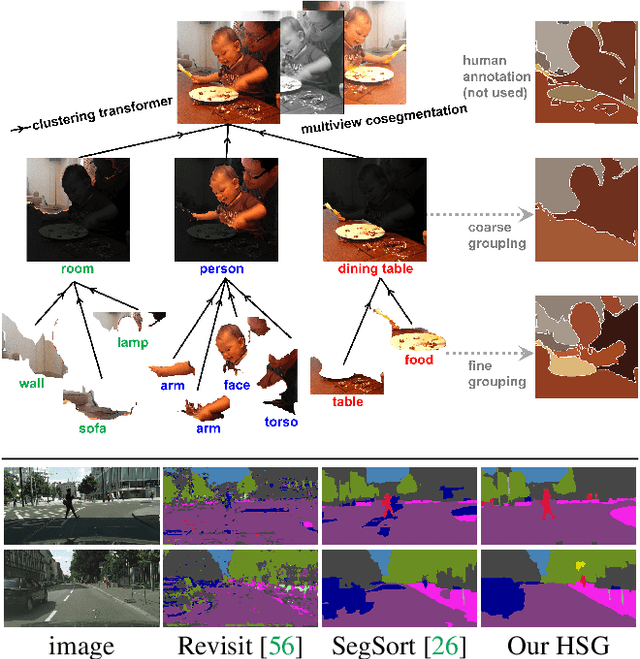
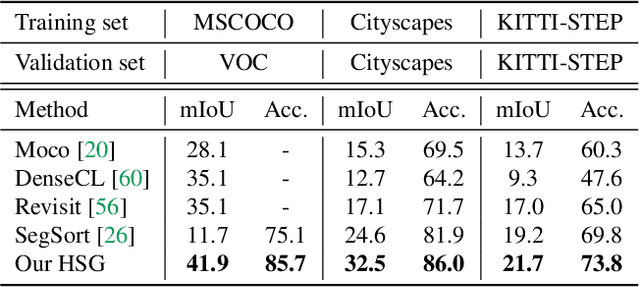
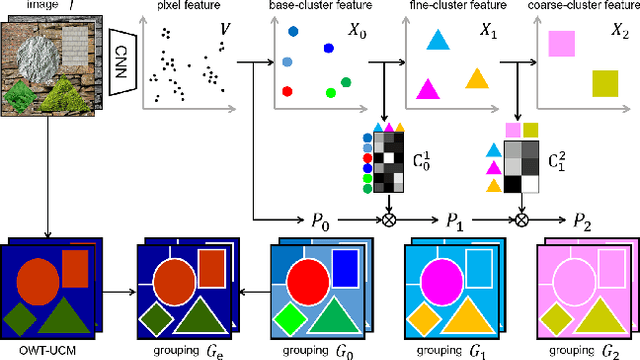
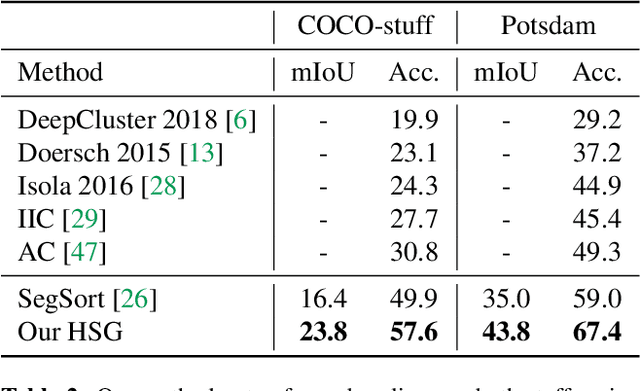
Unsupervised semantic segmentation aims to discover groupings within and across images that capture object and view-invariance of a category without external supervision. Grouping naturally has levels of granularity, creating ambiguity in unsupervised segmentation. Existing methods avoid this ambiguity and treat it as a factor outside modeling, whereas we embrace it and desire hierarchical grouping consistency for unsupervised segmentation. We approach unsupervised segmentation as a pixel-wise feature learning problem. Our idea is that a good representation shall reveal not just a particular level of grouping, but any level of grouping in a consistent and predictable manner. We enforce spatial consistency of grouping and bootstrap feature learning with co-segmentation among multiple views of the same image, and enforce semantic consistency across the grouping hierarchy with clustering transformers between coarse- and fine-grained features. We deliver the first data-driven unsupervised hierarchical semantic segmentation method called Hierarchical Segment Grouping (HSG). Capturing visual similarity and statistical co-occurrences, HSG also outperforms existing unsupervised segmentation methods by a large margin on five major object- and scene-centric benchmarks. Our code is publicly available at https://github.com/twke18/HSG .
Unsupervised Multimodal Image Registration with Adaptative Gradient Guidance
Nov 12, 2020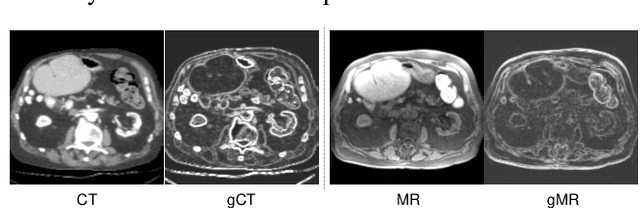
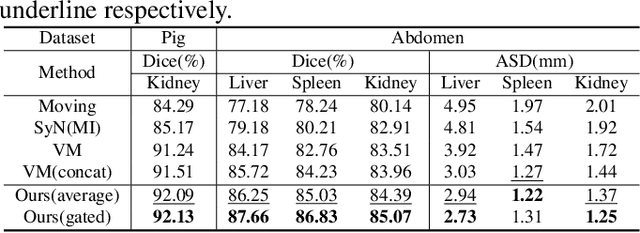
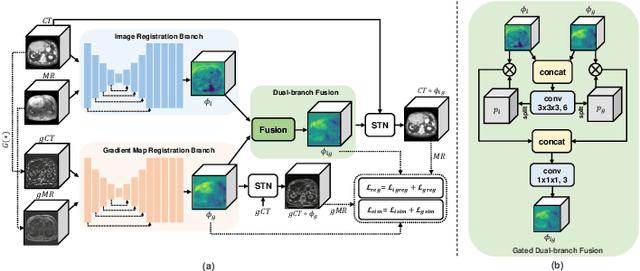

Multimodal image registration (MIR) is a fundamental procedure in many image-guided therapies. Recently, unsupervised learning-based methods have demonstrated promising performance over accuracy and efficiency in deformable image registration. However, the estimated deformation fields of the existing methods fully rely on the to-be-registered image pair. It is difficult for the networks to be aware of the mismatched boundaries, resulting in unsatisfactory organ boundary alignment. In this paper, we propose a novel multimodal registration framework, which leverages the deformation fields estimated from both: (i) the original to-be-registered image pair, (ii) their corresponding gradient intensity maps, and adaptively fuses them with the proposed gated fusion module. With the help of auxiliary gradient-space guidance, the network can concentrate more on the spatial relationship of the organ boundary. Experimental results on two clinically acquired CT-MRI datasets demonstrate the effectiveness of our proposed approach.
Crowd counting with segmentation attention convolutional neural network
Apr 15, 2022

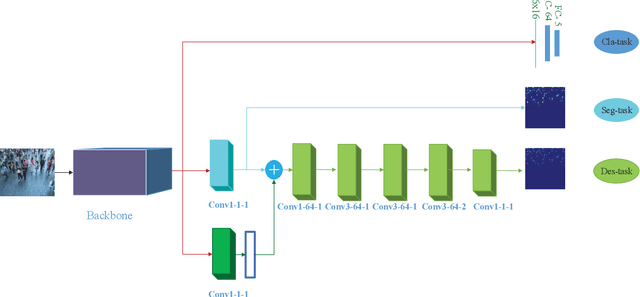
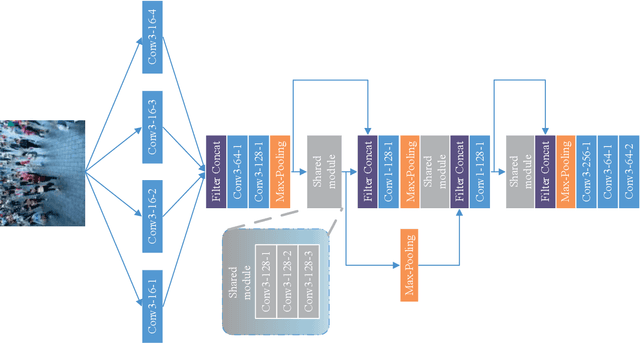
Deep learning occupies an undisputed dominance in crowd counting. In this paper, we propose a novel convolutional neural network (CNN) architecture called SegCrowdNet. Despite the complex background in crowd scenes, the proposeSegCrowdNet still adaptively highlights the human head region and suppresses the non-head region by segmentation. With the guidance of an attention mechanism, the proposed SegCrowdNet pays more attention to the human head region and automatically encodes the highly refined density map. The crowd count can be obtained by integrating the density map. To adapt the variation of crowd counts, SegCrowdNet intelligently classifies the crowd count of each image into several groups. In addition, the multi-scale features are learned and extracted in the proposed SegCrowdNet to overcome the scale variations of the crowd. To verify the effectiveness of our proposed method, extensive experiments are conducted on four challenging datasets. The results demonstrate that our proposed SegCrowdNet achieves excellent performance compared with the state-of-the-art methods.
* Accepted by IET Image Processing