 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot Control
Mar 11, 2022
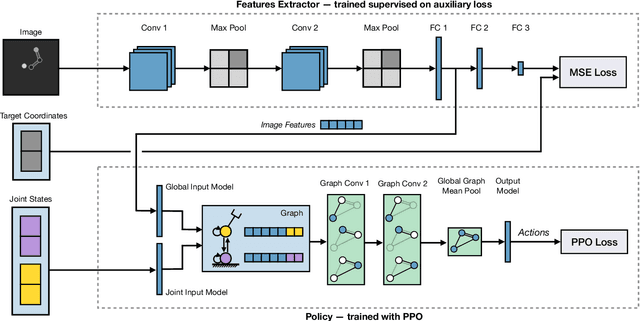
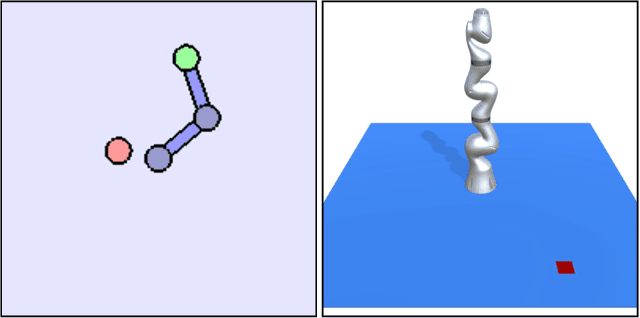
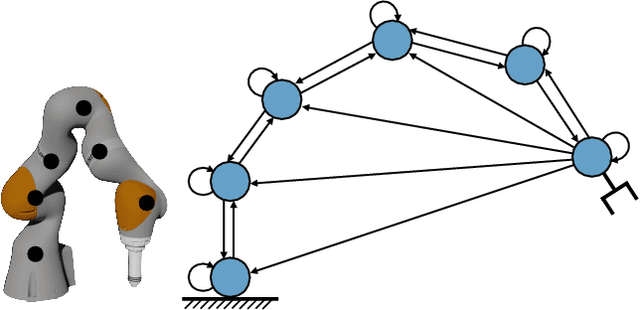
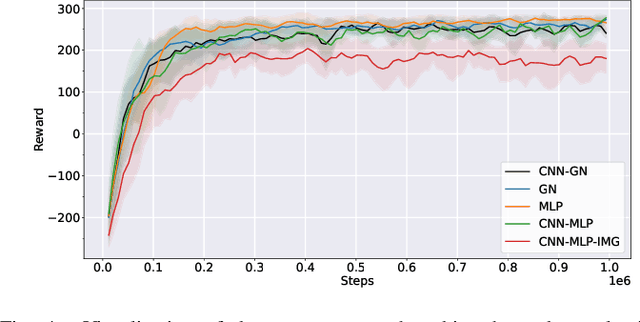
State-of-the-art reinforcement learning algorithms predominantly learn a policy from either a numerical state vector or images. Both approaches generally do not take structural knowledge of the task into account, which is especially prevalent in robotic applications and can benefit learning if exploited. This work introduces a neural network architecture that combines relational inductive bias and visual feedback to learn an efficient position control policy for robotic manipulation. We derive a graph representation that models the physical structure of the manipulator and combines the robot's internal state with a low-dimensional description of the visual scene generated by an image encoding network. On this basis, a graph neural network trained with reinforcement learning predicts joint velocities to control the robot. We further introduce an asymmetric approach of training the image encoder separately from the policy using supervised learning. Experimental results demonstrate that, for a 2-DoF planar robot in a geometrically simplistic 2D environment, a learned representation of the visual scene can replace access to the explicit coordinates of the reaching target without compromising on the quality and sample efficiency of the policy. We further show the ability of the model to improve sample efficiency for a 6-DoF robot arm in a visually realistic 3D environment.
Learning to Generate Synthetic Training Data using Gradient Matching and Implicit Differentiation
Mar 16, 2022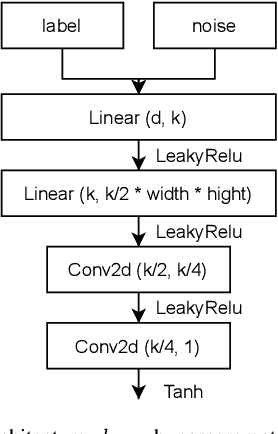
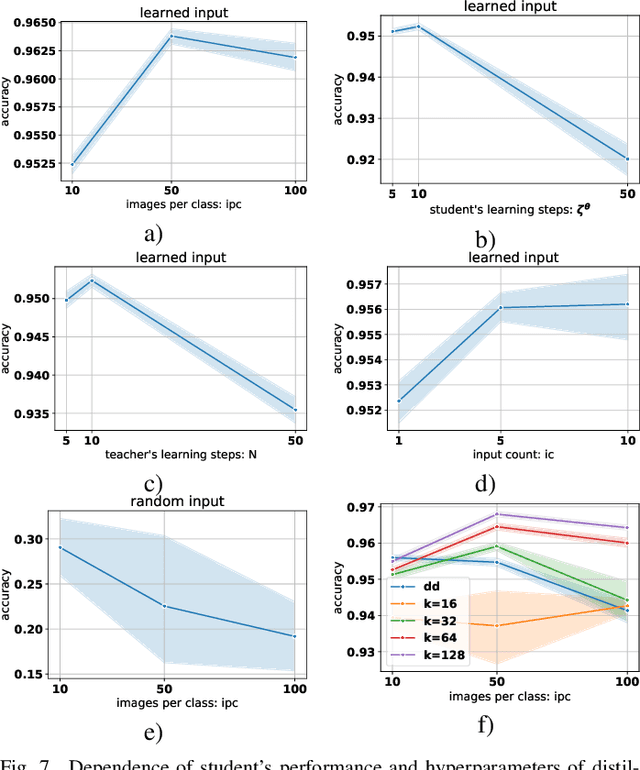
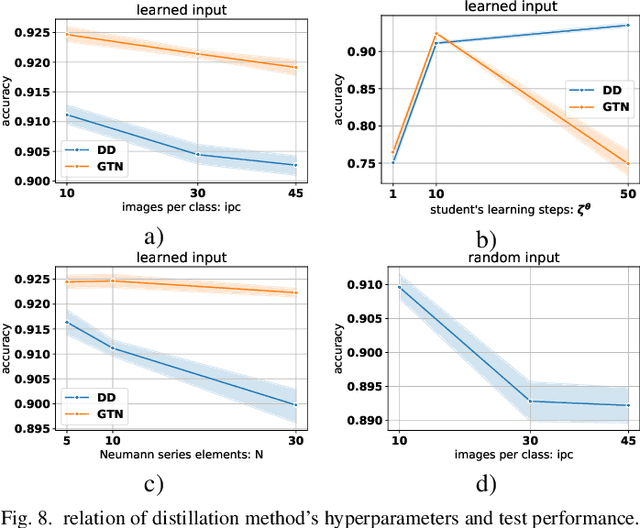

Using huge training datasets can be costly and inconvenient. This article explores various data distillation techniques that can reduce the amount of data required to successfully train deep networks. Inspired by recent ideas, we suggest new data distillation techniques based on generative teaching networks, gradient matching, and the Implicit Function Theorem. Experiments with the MNIST image classification problem show that the new methods are computationally more efficient than previous ones and allow to increase the performance of models trained on distilled data.
Discover the Unknown Biased Attribute of an Image Classifier
Apr 29, 2021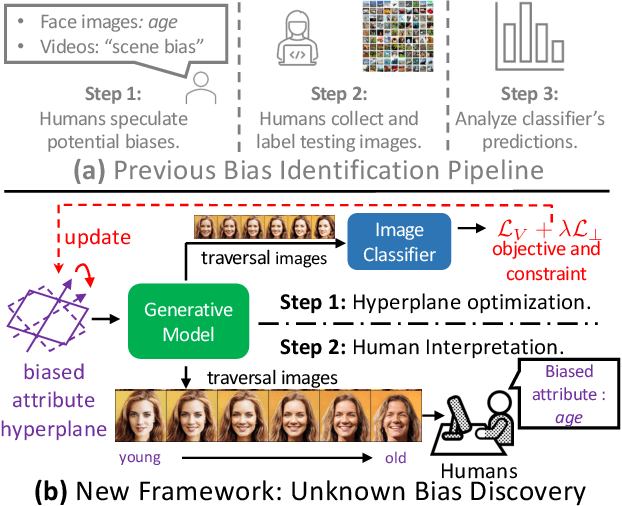
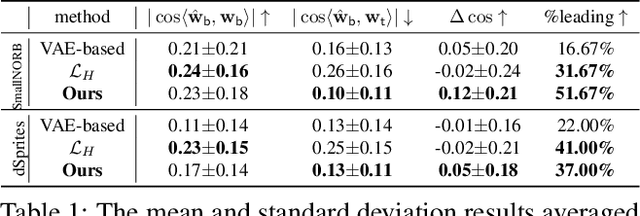
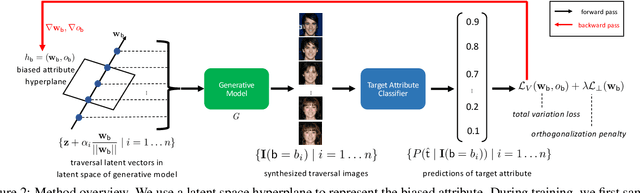
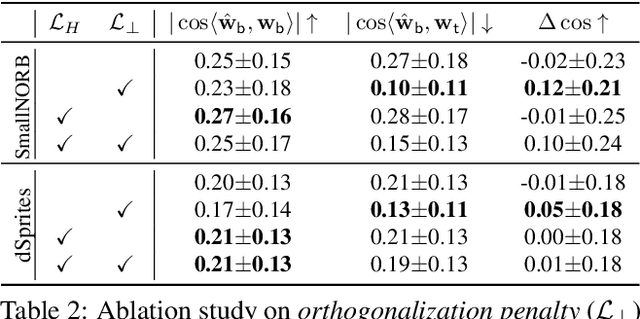
Recent works find that AI algorithms learn biases from data. Therefore, it is urgent and vital to identify biases in AI algorithms. However, the previous bias identification pipeline overly relies on human experts to conjecture potential biases (e.g., gender), which may neglect other underlying biases not realized by humans. To help human experts better find the AI algorithms' biases, we study a new problem in this work -- for a classifier that predicts a target attribute of the input image, discover its unknown biased attribute. To solve this challenging problem, we use a hyperplane in the generative model's latent space to represent an image attribute; thus, the original problem is transformed to optimizing the hyperplane's normal vector and offset. We propose a novel total-variation loss within this framework as the objective function and a new orthogonalization penalty as a constraint. The latter prevents trivial solutions in which the discovered biased attribute is identical with the target or one of the known-biased attributes. Extensive experiments on both disentanglement datasets and real-world datasets show that our method can discover biased attributes and achieve better disentanglement w.r.t. target attributes. Furthermore, the qualitative results show that our method can discover unnoticeable biased attributes for various object and scene classifiers, proving our method's generalizability for detecting biased attributes in diverse domains of images. The code is available at https://git.io/J3kMh.
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022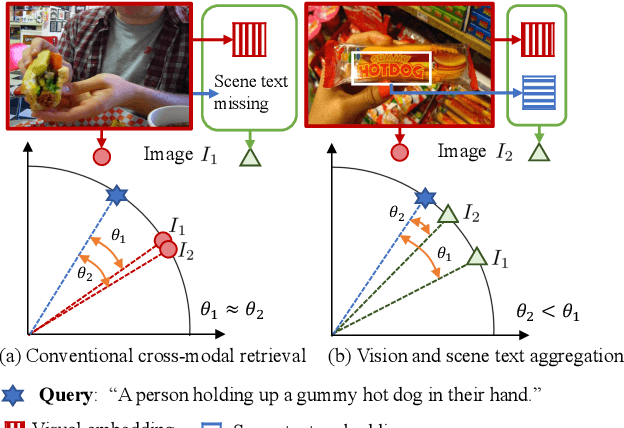

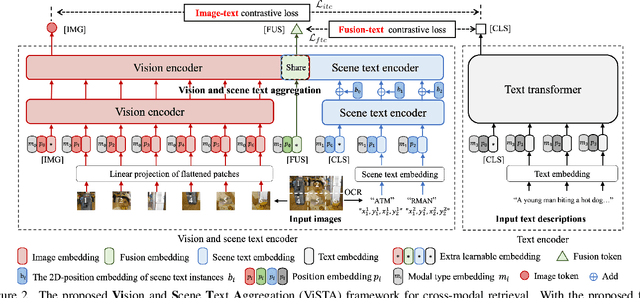

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.
VC-GPT: Visual Conditioned GPT for End-to-End Generative Vision-and-Language Pre-training
Feb 06, 2022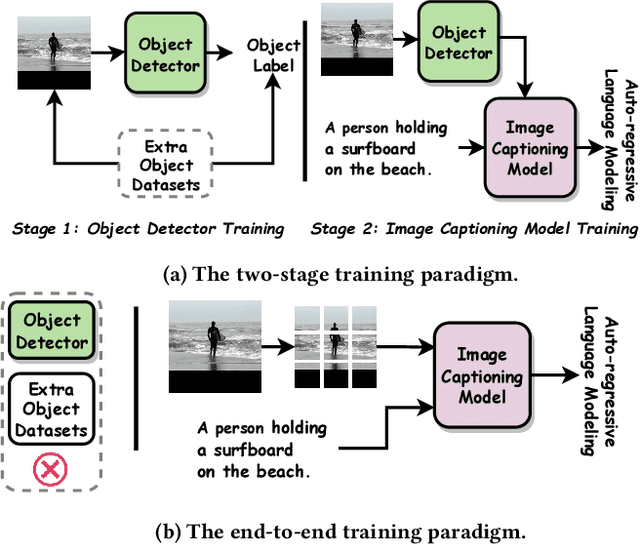
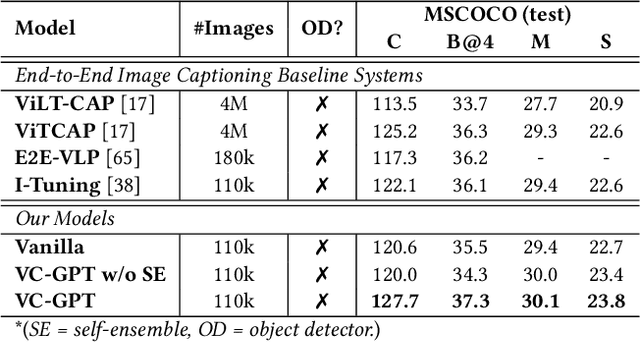
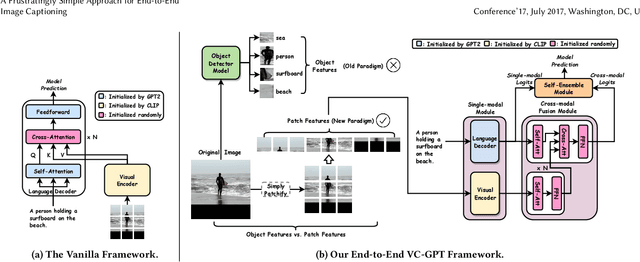
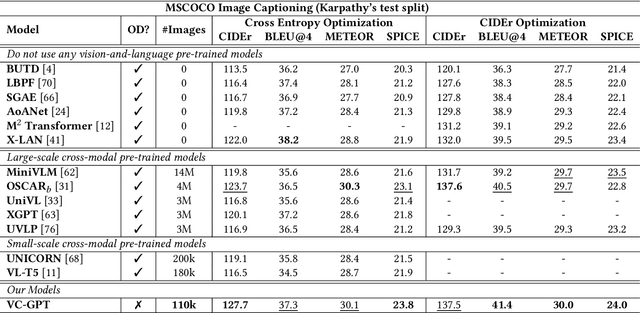
Vision-and-language pre-trained models (VLMs) have achieved tremendous success in the cross-modal area, but most of them require a large amount of parallel image-caption data for pre-training. Collating such data is expensive and labor-intensive. In this work, we focus on reducing such need for generative vision-and-language pre-training (G-VLP) by taking advantage of the visual pre-trained model (CLIP-ViT) as encoder and language pre-trained model (GPT2) as decoder. Unfortunately, GPT2 lacks a necessary cross-attention module, which hinders the direct connection of CLIP-ViT and GPT2. To remedy such defects, we conduct extensive experiments to empirically investigate how to design and pre-train our model. Based on our experimental results, we propose a novel G-VLP framework, Visual Conditioned GPT (VC-GPT), and pre-train it with a small-scale image-caption corpus (Visual Genome, only 110k distinct images). Evaluating on the image captioning downstream tasks (MSCOCO and Flickr30k Captioning), VC-GPT achieves either the best or the second-best performance across all evaluation metrics over the previous works which consume around 30 times more distinct images during cross-modal pre-training.
Indoor Navigation Assistance for Visually Impaired People via Dynamic SLAM and Panoptic Segmentation with an RGB-D Sensor
Apr 03, 2022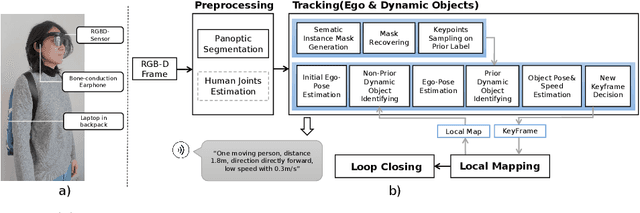
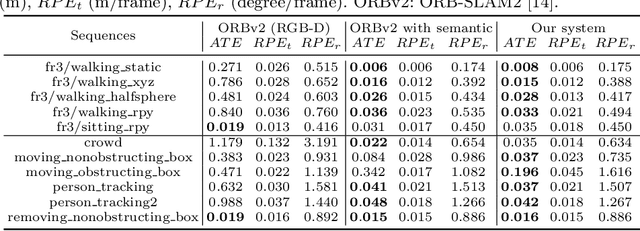


Exploring an unfamiliar indoor environment and avoiding obstacles is challenging for visually impaired people. Currently, several approaches achieve the avoidance of static obstacles based on the mapping of indoor scenes. To solve the issue of distinguishing dynamic obstacles, we propose an assistive system with an RGB-D sensor to detect dynamic information of a scene. Once the system captures an image, panoptic segmentation is performed to obtain the prior dynamic object information. With sparse feature points extracted from images and the depth information, poses of the user can be estimated. After the ego-motion estimation, the dynamic object can be identified and tracked. Then, poses and speed of tracked dynamic objects can be estimated, which are passed to the users through acoustic feedback.
Conditional Autoregressors are Interpretable Classifiers
Mar 31, 2022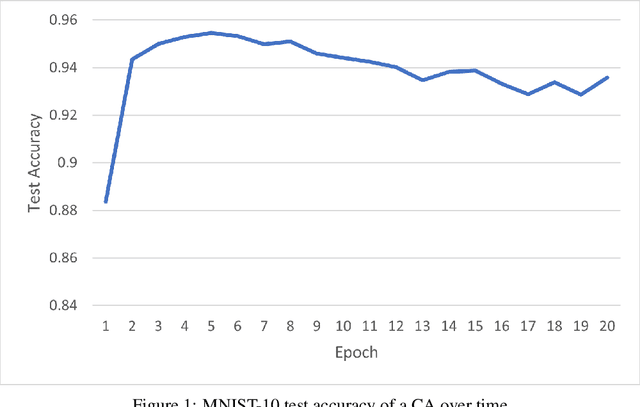
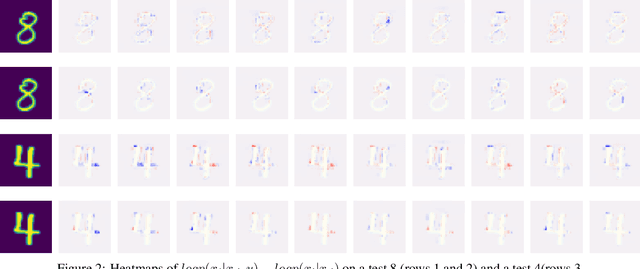
We explore the use of class-conditional autoregressive (CA) models to perform image classification on MNIST-10. Autoregressive models assign probability to an entire input by combining probabilities from each individual feature; hence classification decisions made by a CA can be readily decomposed into contributions from each each input feature. That is to say, CA are inherently locally interpretable. Our experiments show that naively training a CA achieves much worse accuracy compared to a standard classifier, however this is due to over-fitting and not a lack of expressive power. Using knowledge distillation from a standard classifier, a student CA can be trained to match the performance of the teacher while still being interpretable.
Visual Servoing for Pose Control of Soft Continuum Arm in a Structured Environment
Feb 10, 2022
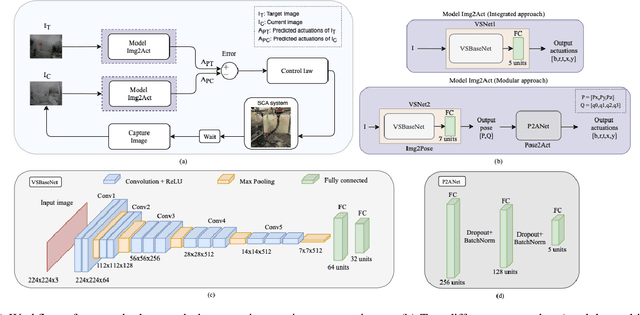

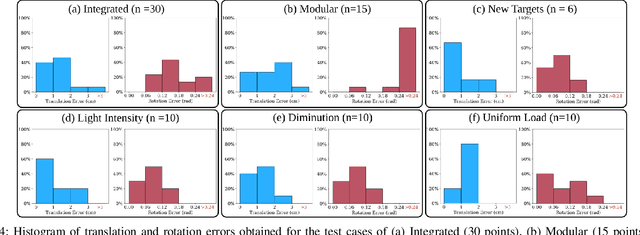
For soft continuum arms, visual servoing is a popular control strategy that relies on visual feedback to close the control loop. However, robust visual servoing is challenging as it requires reliable feature extraction from the image, accurate control models and sensors to perceive the shape of the arm, both of which can be hard to implement in a soft robot. This letter circumvents these challenges by presenting a deep neural network-based method to perform smooth and robust 3D positioning tasks on a soft arm by visual servoing using a camera mounted at the distal end of the arm. A convolutional neural network is trained to predict the actuations required to achieve the desired pose in a structured environment. Integrated and modular approaches for estimating the actuations from the image are proposed and are experimentally compared. A proportional control law is implemented to reduce the error between the desired and current image as seen by the camera. The model together with the proportional feedback control makes the described approach robust to several variations such as new targets, lighting, loads, and diminution of the soft arm. Furthermore, the model lends itself to be transferred to a new environment with minimal effort.
Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
May 07, 2022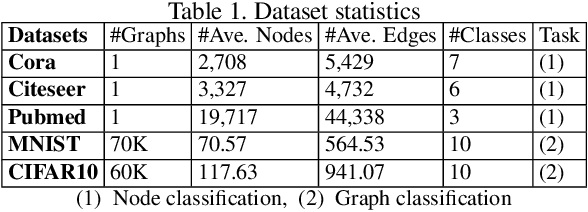
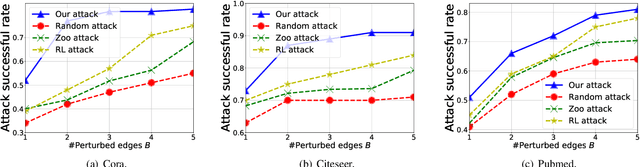
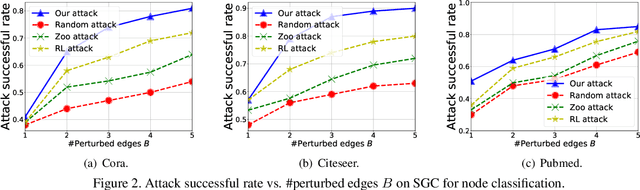
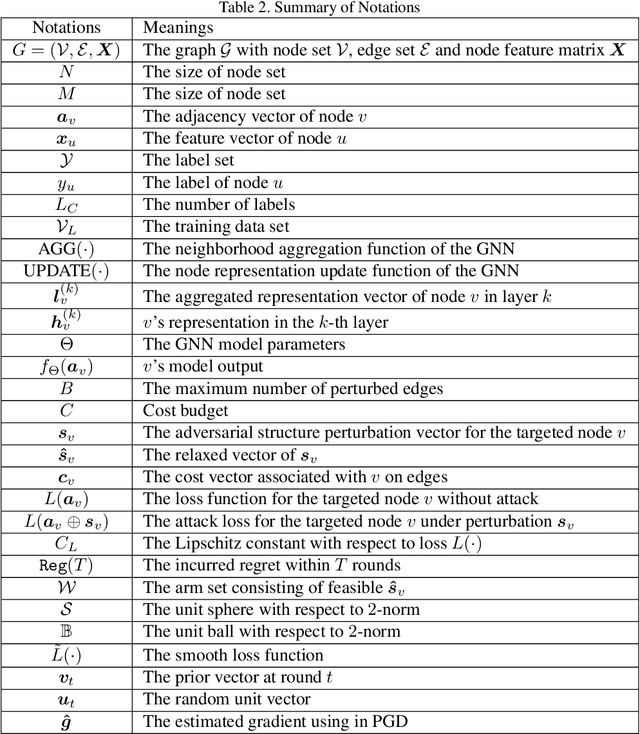
Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-based tasks such as node classification and graph classification. However, many recent works have demonstrated that an attacker can mislead GNN models by slightly perturbing the graph structure. Existing attacks to GNNs are either under the less practical threat model where the attacker is assumed to access the GNN model parameters, or under the practical black-box threat model but consider perturbing node features that are shown to be not enough effective. In this paper, we aim to bridge this gap and consider black-box attacks to GNNs with structure perturbation as well as with theoretical guarantees. We propose to address this challenge through bandit techniques. Specifically, we formulate our attack as an online optimization with bandit feedback. This original problem is essentially NP-hard due to the fact that perturbing the graph structure is a binary optimization problem. We then propose an online attack based on bandit optimization which is proven to be {sublinear} to the query number $T$, i.e., $\mathcal{O}(\sqrt{N}T^{3/4})$ where $N$ is the number of nodes in the graph. Finally, we evaluate our proposed attack by conducting experiments over multiple datasets and GNN models. The experimental results on various citation graphs and image graphs show that our attack is both effective and efficient. Source code is available at~\url{https://github.com/Metaoblivion/Bandit_GNN_Attack}
WideCaps: A Wide Attention based Capsule Network for Image Classification
Aug 14, 2021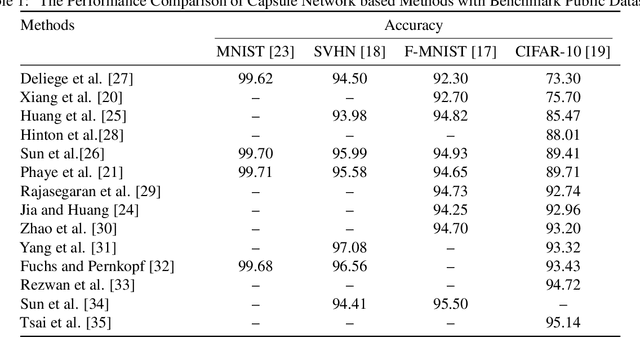
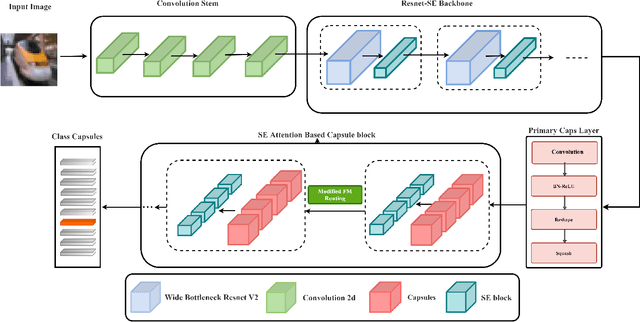
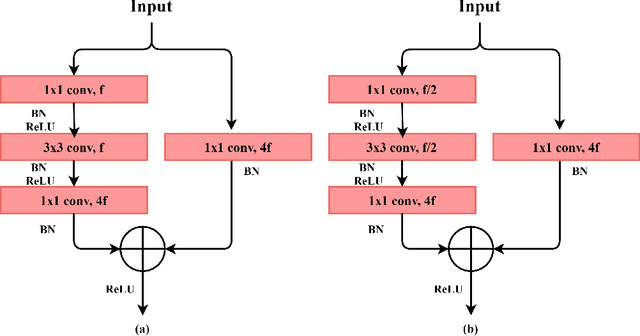

The capsule network is a distinct and promising segment of the neural network family that drew attention due to its unique ability to maintain the equivariance property by preserving the spatial relationship amongst the features. The capsule network has attained unprecedented success over image classification tasks with datasets such as MNIST and affNIST by encoding the characteristic features into the capsules and building the parse-tree structure. However, on the datasets involving complex foreground and background regions such as CIFAR-10, the performance of the capsule network is sub-optimal due to its naive data routing policy and incompetence towards extracting complex features. This paper proposes a new design strategy for capsule network architecture for efficiently dealing with complex images. The proposed method incorporates wide bottleneck residual modules and the Squeeze and Excitation attention blocks upheld by the modified FM routing algorithm to address the defined problem. A wide bottleneck residual module facilitates extracting complex features followed by the squeeze and excitation attention block to enable channel-wise attention by suppressing the trivial features. This setup allows channel inter-dependencies at almost no computational cost, thereby enhancing the representation ability of capsules on complex images. We extensively evaluate the performance of the proposed model on three publicly available datasets, namely CIFAR-10, Fashion MNIST, and SVHN, to outperform the top-5 performance on CIFAR-10 and Fashion MNIST with highly competitive performance on the SVHN dataset.