 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Memory-Augmented Reinforcement Learning for Image-Goal Navigation
Jan 13, 2021
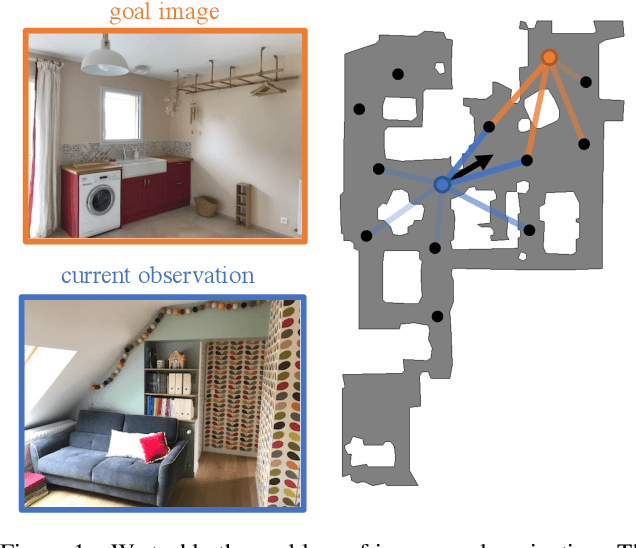
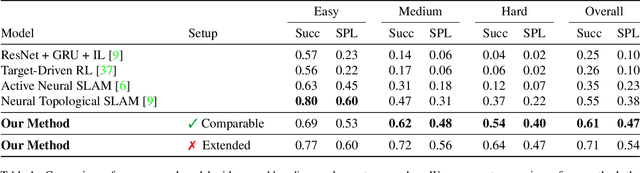
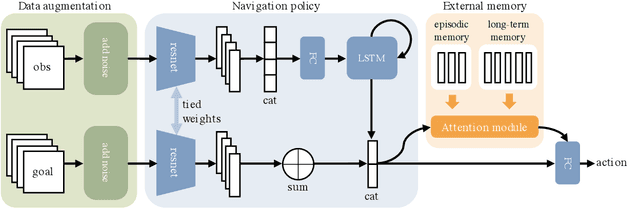
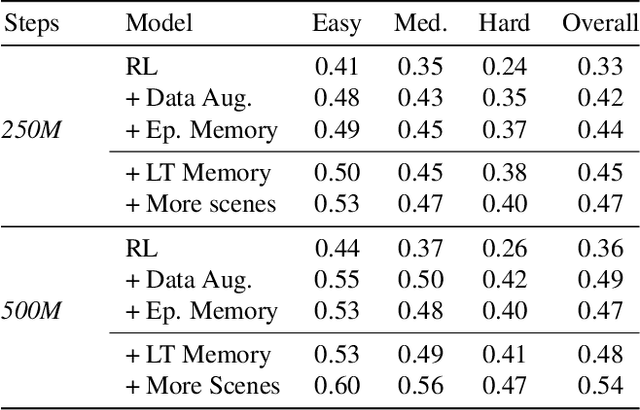
In this work, we address the problem of image-goal navigation in the context of visually-realistic 3D environments. This task involves navigating to a location indicated by a target image in a previously unseen environment. Earlier attempts, including RL-based and SLAM-based approaches, have either shown poor generalization performance, or are heavily-reliant on pose/depth sensors. We present a novel method that leverages a cross-episode memory to learn to navigate. We first train a state-embedding network in a self-supervised fashion, and then use it to embed previously-visited states into a memory. In order to avoid overfitting, we propose to use data augmentation on the RGB input during training. We validate our approach through extensive evaluations, showing that our data-augmented memory-based model establishes a new state of the art on the image-goal navigation task in the challenging Gibson dataset. We obtain this competitive performance from RGB input only, without access to additional sensors such as position or depth.
3D Object Detection from Images for Autonomous Driving: A Survey
Feb 07, 2022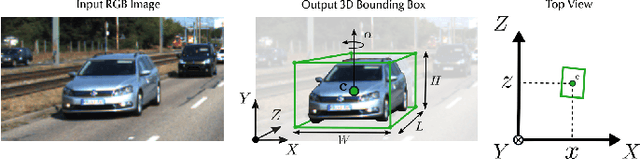
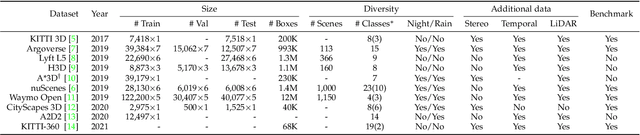
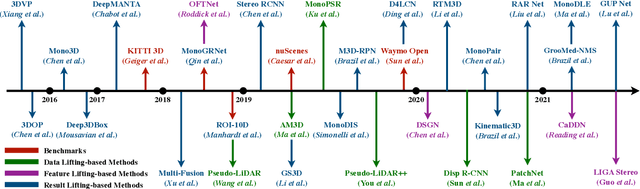
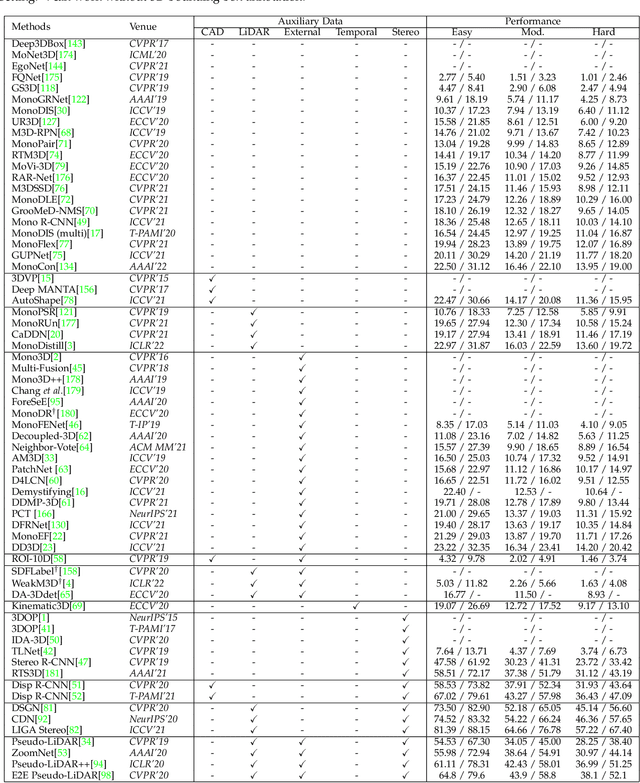
3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. Additionally, we also propose two new taxonomies to organize the state-of-the-art methods into different categories, with the intent of providing a more systematic review of existing methods and facilitating fair comparisons with future works. In retrospect of what has been achieved so far, we also analyze the current challenges in the field and discuss future directions for image-based 3D detection research.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021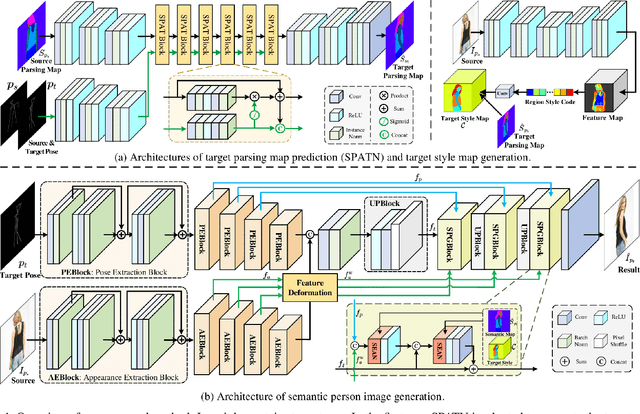
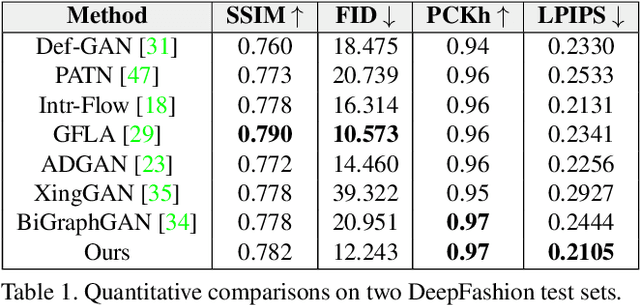
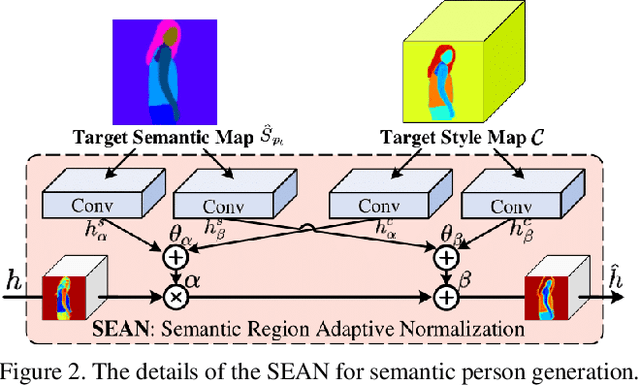

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
Comparison of Depth Estimation Setups from Stereo Endoscopy and Optical Tracking for Point Measurements
Jan 26, 2022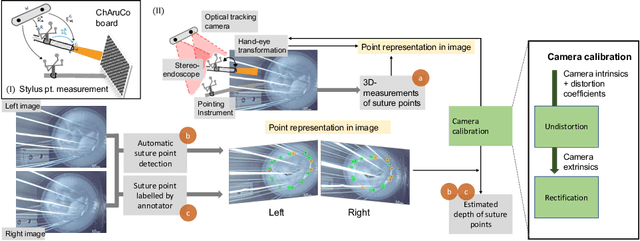


To support minimally-invasive intraoperative mitral valve repair, quantitative measurements from the valve can be obtained using an infra-red tracked stylus. It is desirable to view such manually measured points together with the endoscopic image for further assistance. Therefore, hand-eye calibration is required that links both coordinate systems and is a prerequisite to project the points onto the image plane. A complementary approach to this is to use a vision-based endoscopic stereo-setup to detect and triangulate points of interest, to obtain the 3D coordinates. In this paper, we aim to compare both approaches on a rigid phantom and two patient-individual silicone replica which resemble the intraoperative scenario. The preliminary results indicate that 3D landmark estimation, either labeled manually or through partly automated detection with a deep learning approach, provides more accurate triangulated depth measurements when performed with a tailored image-based method than with stylus measurements.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 04, 2022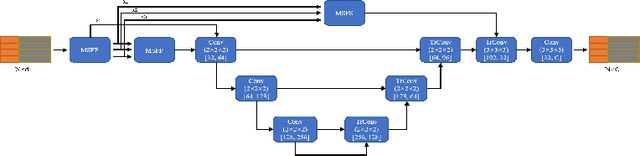
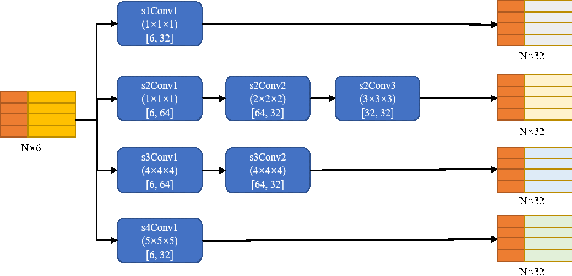
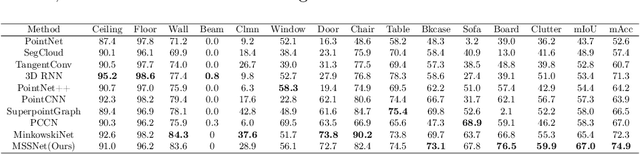
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.
Perceptual Image Restoration with High-Quality Priori and Degradation Learning
Mar 04, 2021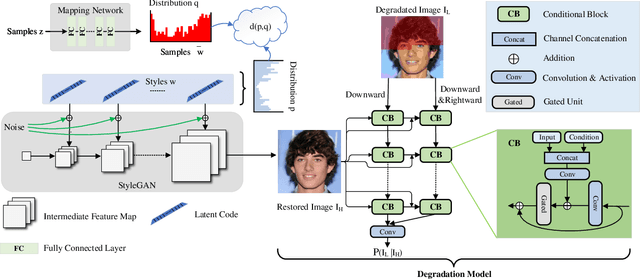

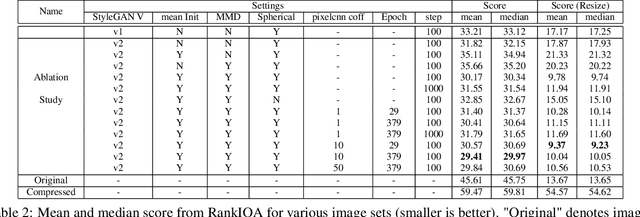
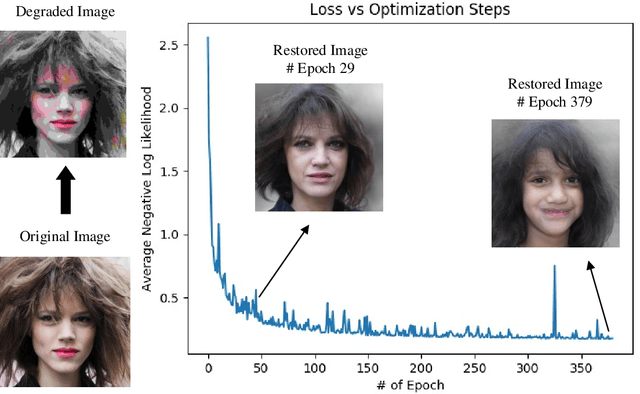
Perceptual image restoration seeks for high-fidelity images that most likely degrade to given images. For better visual quality, previous work proposed to search for solutions within the natural image manifold, by exploiting the latent space of a generative model. However, the quality of generated images are only guaranteed when latent embedding lies close to the prior distribution. In this work, we propose to restrict the feasible region within the prior manifold. This is accomplished with a non-parametric metric for two distributions: the Maximum Mean Discrepancy (MMD). Moreover, we model the degradation process directly as a conditional distribution. We show that our model performs well in measuring the similarity between restored and degraded images. Instead of optimizing the long criticized pixel-wise distance over degraded images, we rely on such model to find visual pleasing images with high probability. Our simultaneous restoration and enhancement framework generalizes well to real-world complicated degradation types. The experimental results on perceptual quality and no-reference image quality assessment (NR-IQA) demonstrate the superior performance of our method.
Declipping of Speech Signals Using Frequency Selective Extrapolation
Apr 07, 2022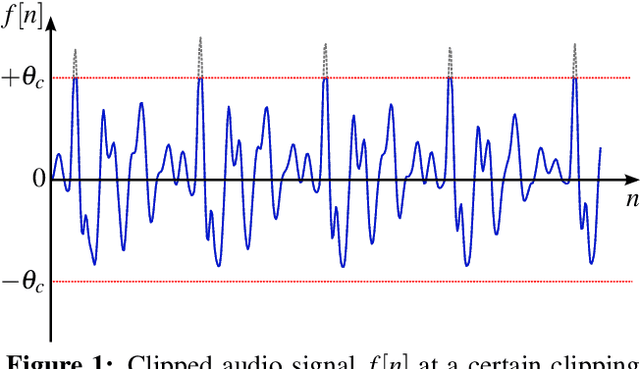

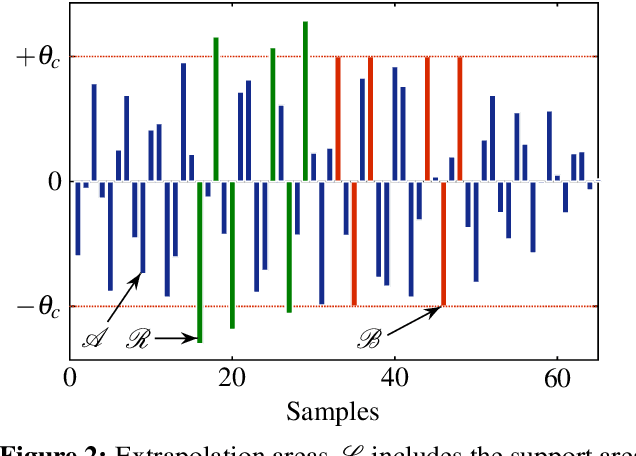
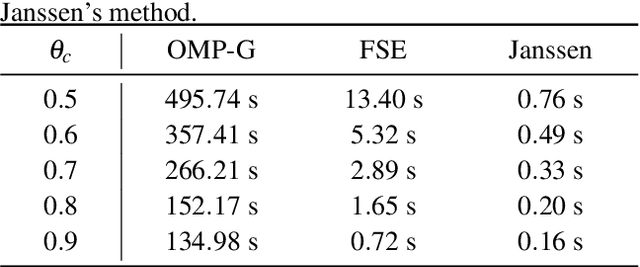
The reconstruction of clipped speech signals is an important task in audio signal processing to achieve an enhanced audio quality for further processing. In this paper, Frequency Selective Extrapolation (FSE), which is commonly used for error concealment or the reconstruction of incomplete image data, is adapted to be able to restore audio signals which are distorted from clipping. For this, FSE generates a model of the signal as an iterative superposition of Fourier basis functions. Clipped samples can then be replaced by estimated samples from the model. The performance of the proposed algorithm is evaluated by using different speech test data sets. Compared to other state-of-the-art declipping algorithms, this leads to a maximum gain in SNR of up to 3:5 dB and an average gain of 1 dB.
AutoCaption: Image Captioning with Neural Architecture Search
Dec 16, 2020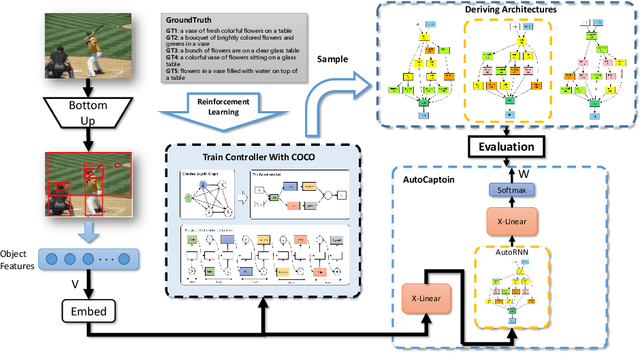

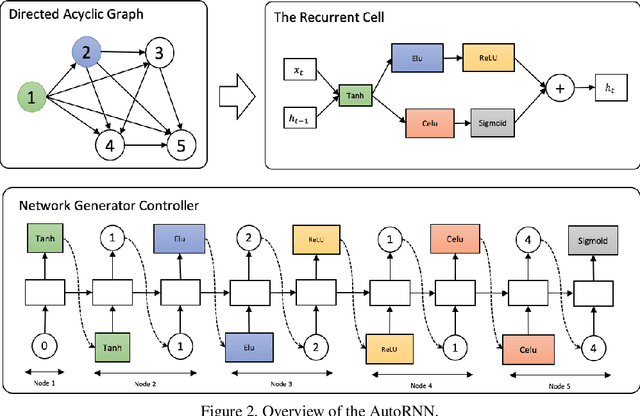
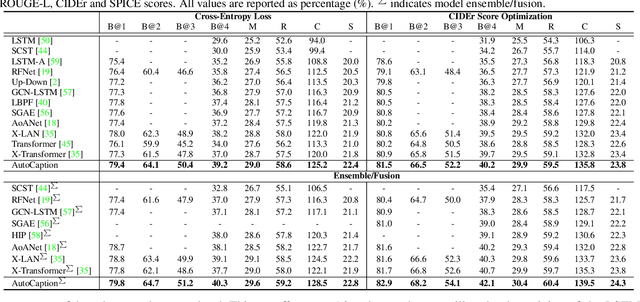
Image captioning transforms complex visual information into abstract natural language for representation, which can help computers understanding the world quickly. However, due to the complexity of the real environment, it needs to identify key objects and realize their connections, and further generate natural language. The whole process involves a visual understanding module and a language generation module, which brings more challenges to the design of deep neural networks than other tasks. Neural Architecture Search (NAS) has shown its important role in a variety of image recognition tasks. Besides, RNN plays an essential role in the image captioning task. We introduce a AutoCaption method to better design the decoder module of the image captioning where we use the NAS to design the decoder module called AutoRNN automatically. We use the reinforcement learning method based on shared parameters for automatic design the AutoRNN efficiently. The search space of the AutoCaption includes connections between the layers and the operations in layers both, and it can make AutoRNN express more architectures. In particular, RNN is equivalent to a subset of our search space. Experiments on the MSCOCO datasets show that our AutoCaption model can achieve better performance than traditional hand-design methods. Our AutoCaption obtains the best published CIDEr performance of 135.8% on COCO Karpathy test split. When further using ensemble technology, CIDEr is boosted up to 139.5%.
A State-of-the-art Survey of Object Detection Techniques in Microorganism Image Analysis: from Traditional Image Processing and Classical Machine Learning to Current Deep Convolutional Neural Networks and Potential Visual Transformers
May 07, 2021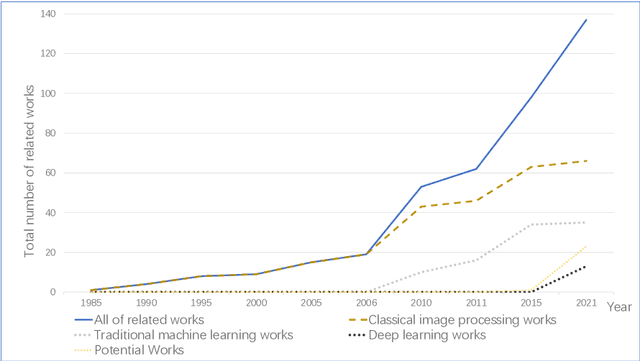
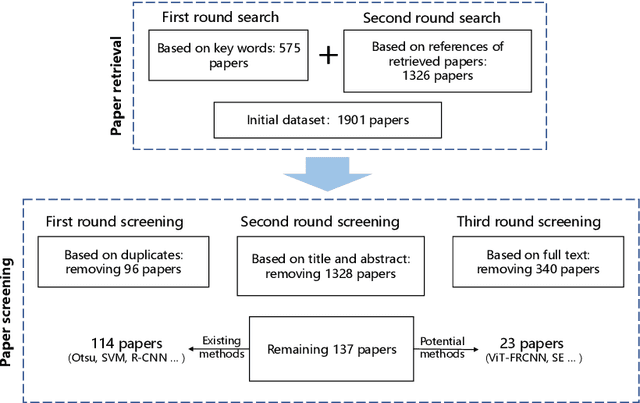

Microorganisms play a vital role in human life. Therefore, microorganism detection is of great significance to human beings. However, the traditional manual microscopic detection methods have the disadvantages of long detection cycle, low detection accuracy in large orders, and great difficulty in detecting uncommon microorganisms. Therefore, it is meaningful to apply computer image analysis technology to the field of microorganism detection. Computer image analysis can realize high-precision and high-efficiency detection of microorganisms. In this review, first,we analyse the existing microorganism detection methods in chronological order, from traditional image processing and traditional machine learning to deep learning methods. Then, we analyze and summarize these existing methods and introduce some potential methods, including visual transformers. In the end, the future development direction and challenges of microorganism detection are discussed. In general, we have summarized 137 related technical papers from 1985 to the present. This review will help researchers have a more comprehensive understanding of the development process, research status, and future trends in the field of microorganism detection and provide a reference for researchers in other fields.
An Efficient End-to-End Deep Neural Network for Interstitial Lung Disease Recognition and Classification
Apr 21, 2022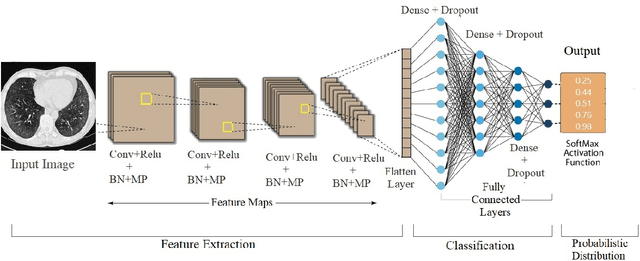
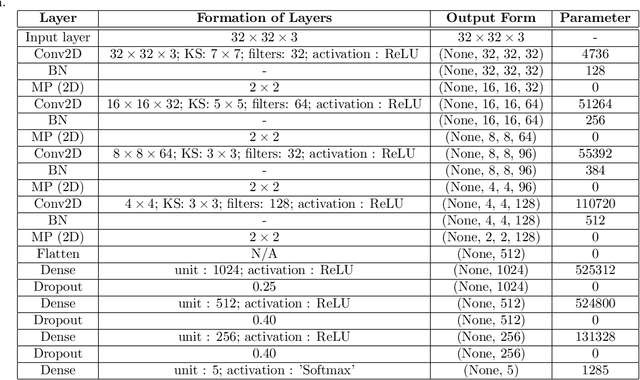
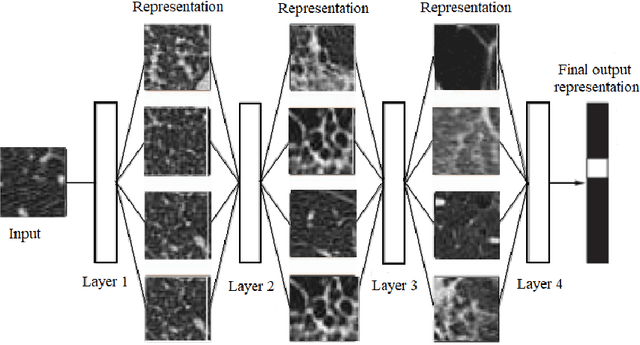
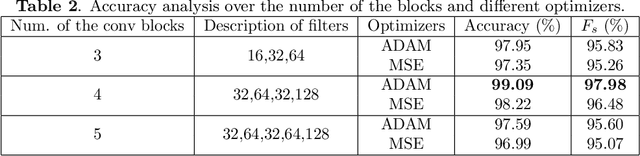
The automated Interstitial Lung Diseases (ILDs) classification technique is essential for assisting clinicians during the diagnosis process. Detecting and classifying ILDs patterns is a challenging problem. This paper introduces an end-to-end deep convolution neural network (CNN) for classifying ILDs patterns. The proposed model comprises four convolutional layers with different kernel sizes and Rectified Linear Unit (ReLU) activation function, followed by batch normalization and max-pooling with a size equal to the final feature map size well as four dense layers. We used the ADAM optimizer to minimize categorical cross-entropy. A dataset consisting of 21328 image patches of 128 CT scans with five classes is taken to train and assess the proposed model. A comparison study showed that the presented model outperformed pre-trained CNNs and five-fold cross-validation on the same dataset. For ILDs pattern classification, the proposed approach achieved the accuracy scores of 99.09% and the average F score of 97.9%, outperforming three pre-trained CNNs. These outcomes show that the proposed model is relatively state-of-the-art in precision, recall, f score, and accuracy.