 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Models for Counterfactual Explanations
Mar 29, 2022
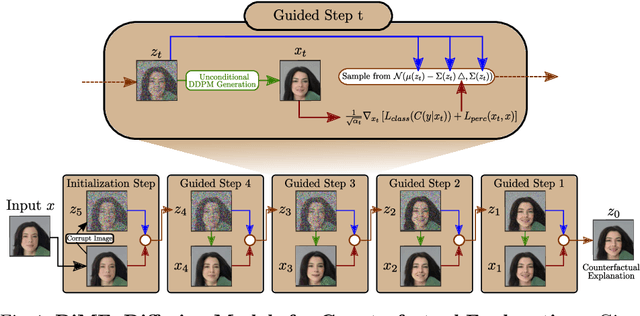
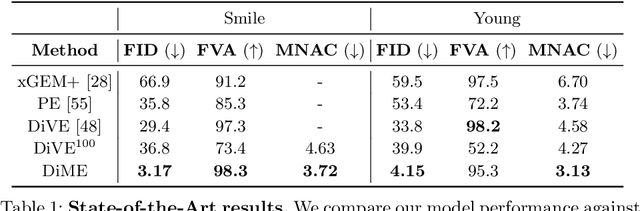

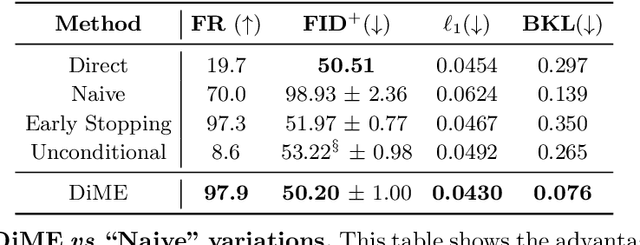
Counterfactual explanations have shown promising results as a post-hoc framework to make image classifiers more explainable. In this paper, we propose DiME, a method allowing the generation of counterfactual images using the recent diffusion models. By leveraging the guided generative diffusion process, our proposed methodology shows how to use the gradients of the target classifier to generate counterfactual explanations of input instances. Further, we analyze current approaches to evaluate spurious correlations and extend the evaluation measurements by proposing a new metric: Correlation Difference. Our experimental validations show that the proposed algorithm surpasses previous State-of-the-Art results on 5 out of 6 metrics on CelebA.
StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis
Apr 14, 2021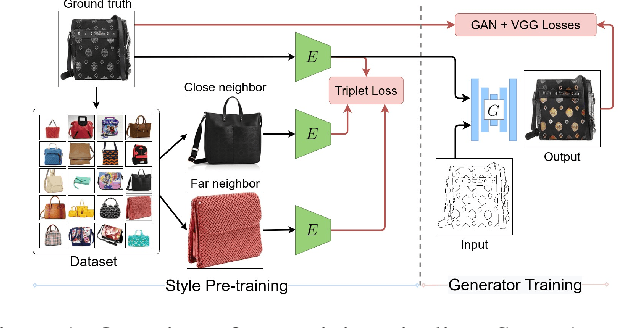
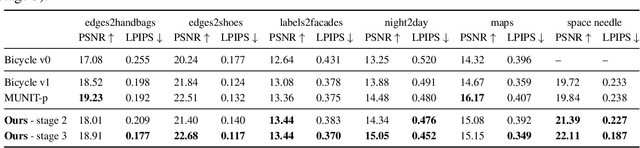

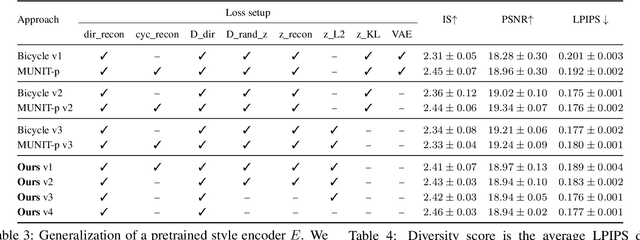
We propose a novel approach for multi-modal Image-to-image (I2I) translation. To tackle the one-to-many relationship between input and output domains, previous works use complex training objectives to learn a latent embedding, jointly with the generator, that models the variability of the output domain. In contrast, we directly model the style variability of images, independent of the image synthesis task. Specifically, we pre-train a generic style encoder using a novel proxy task to learn an embedding of images, from arbitrary domains, into a low-dimensional style latent space. The learned latent space introduces several advantages over previous traditional approaches to multi-modal I2I translation. First, it is not dependent on the target dataset, and generalizes well across multiple domains. Second, it learns a more powerful and expressive latent space, which improves the fidelity of style capture and transfer. The proposed style pre-training also simplifies the training objective and speeds up the training significantly. Furthermore, we provide a detailed study of the contribution of different loss terms to the task of multi-modal I2I translation, and propose a simple alternative to VAEs to enable sampling from unconstrained latent spaces. Finally, we achieve state-of-the-art results on six challenging benchmarks with a simple training objective that includes only a GAN loss and a reconstruction loss.
Reconstruction Task Finds Universal Winning Tickets
Feb 23, 2022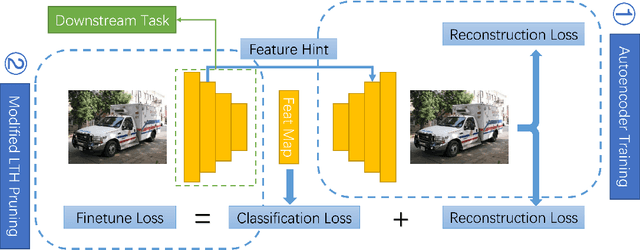
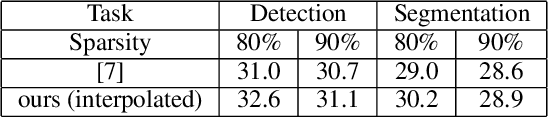
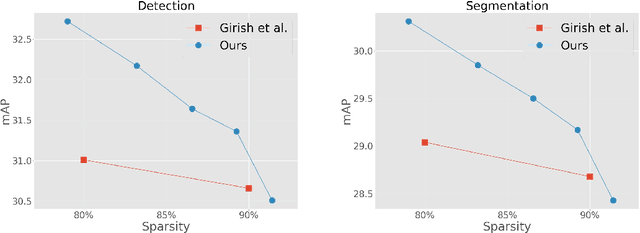
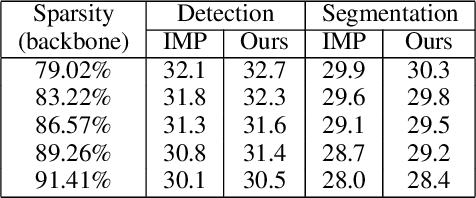
Pruning well-trained neural networks is effective to achieve a promising accuracy-efficiency trade-off in computer vision regimes. However, most of existing pruning algorithms only focus on the classification task defined on the source domain. Different from the strong transferability of the original model, a pruned network is hard to transfer to complicated downstream tasks such as object detection arXiv:arch-ive/2012.04643. In this paper, we show that the image-level pretrain task is not capable of pruning models for diverse downstream tasks. To mitigate this problem, we introduce image reconstruction, a pixel-level task, into the traditional pruning framework. Concretely, an autoencoder is trained based on the original model, and then the pruning process is optimized with both autoencoder and classification losses. The empirical study on benchmark downstream tasks shows that the proposed method can outperform state-of-the-art results explicitly.
Unlabeled Data Guided Semi-supervised Histopathology Image Segmentation
Dec 17, 2020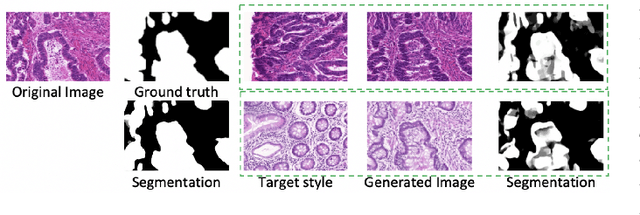
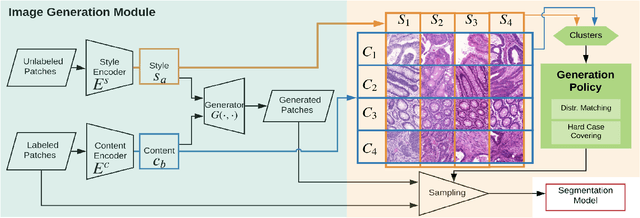
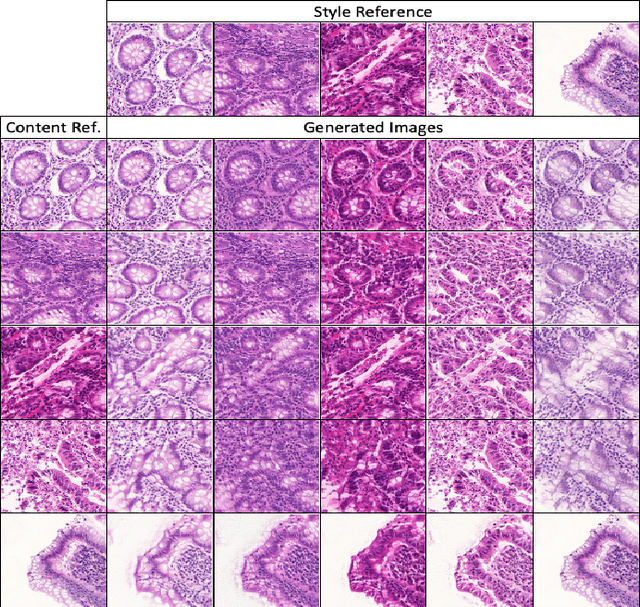
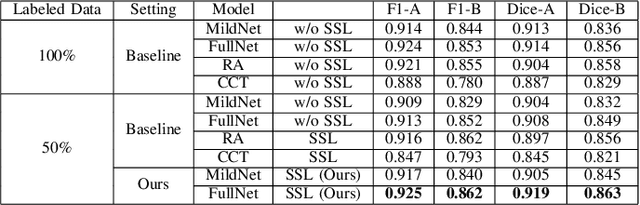
Automatic histopathology image segmentation is crucial to disease analysis. Limited available labeled data hinders the generalizability of trained models under the fully supervised setting. Semi-supervised learning (SSL) based on generative methods has been proven to be effective in utilizing diverse image characteristics. However, it has not been well explored what kinds of generated images would be more useful for model training and how to use such images. In this paper, we propose a new data guided generative method for histopathology image segmentation by leveraging the unlabeled data distributions. First, we design an image generation module. Image content and style are disentangled and embedded in a clustering-friendly space to utilize their distributions. New images are synthesized by sampling and cross-combining contents and styles. Second, we devise an effective data selection policy for judiciously sampling the generated images: (1) to make the generated training set better cover the dataset, the clusters that are underrepresented in the original training set are covered more; (2) to make the training process more effective, we identify and oversample the images of "hard cases" in the data for which annotated training data may be scarce. Our method is evaluated on glands and nuclei datasets. We show that under both the inductive and transductive settings, our SSL method consistently boosts the performance of common segmentation models and attains state-of-the-art results.
Analysis of Sparse Subspace Clustering: Experiments and Random Projection
Apr 01, 2022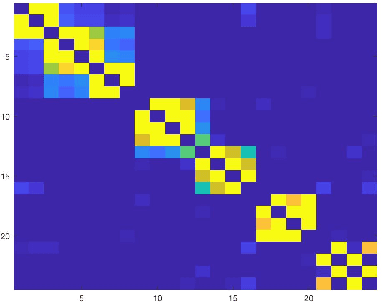
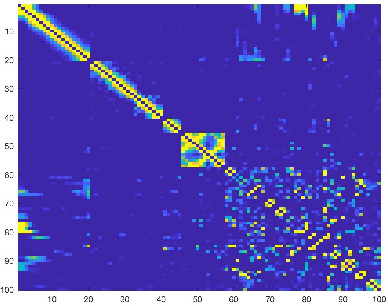
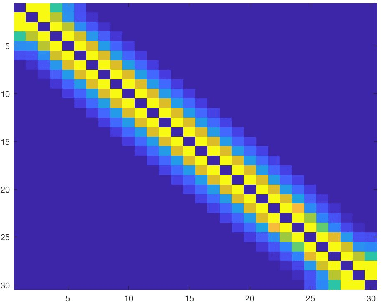

Clustering can be defined as the process of assembling objects into a number of groups whose elements are similar to each other in some manner. As a technique that is used in many domains, such as face clustering, plant categorization, image segmentation, document classification, clustering is considered one of the most important unsupervised learning problems. Scientists have surveyed this problem for years and developed different techniques that can solve it, such as k-means clustering. We analyze one of these techniques: a powerful clustering algorithm called Sparse Subspace Clustering. We demonstrate several experiments using this method and then introduce a new approach that can reduce the computational time required to perform sparse subspace clustering.
Multi-Stage Progressive Image Restoration
Feb 04, 2021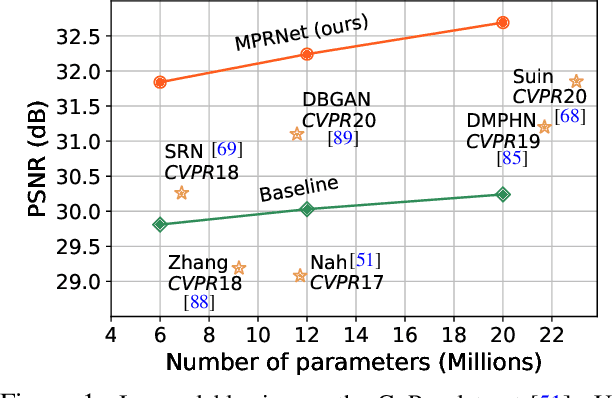

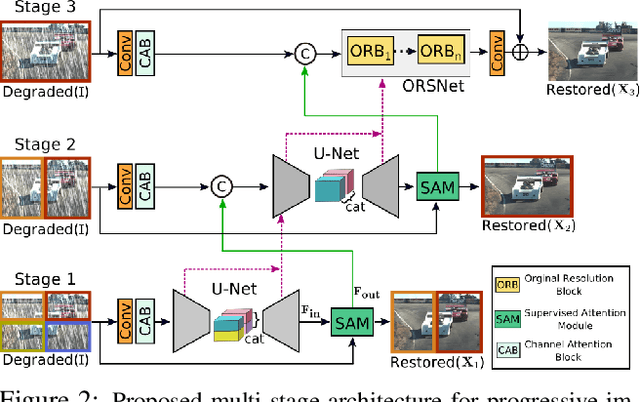
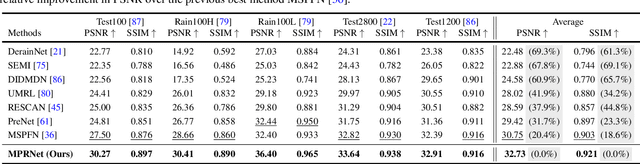
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Multi-modal learning for predicting the genotype of glioma
Mar 21, 2022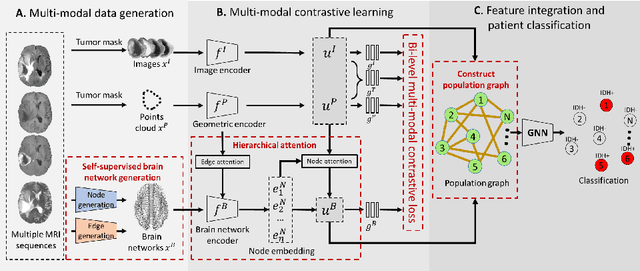

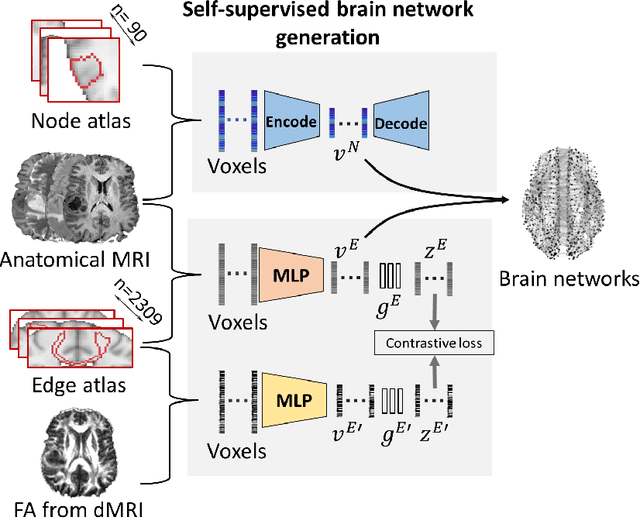

The isocitrate dehydrogenase (IDH) gene mutation is an essential biomarker for the diagnosis and prognosis of glioma. It is promising to better predict glioma genotype by integrating focal tumor image and geometric features with brain network features derived from MRI. Convolutions neural networks show reasonable performance in predicting IDH mutation, which, however, cannot learn from non-Euclidean data, e.g., geometric and network data. In this study, we propose a multi-modal learning framework using three separate encoders to extract features of focal tumor image, tumor geometrics and global brain networks. To mitigate the limited availability of diffusion MRI, we develop a self-supervised approach to generate brain networks from anatomical multi-sequence MRI. Moreover, to extract tumor-related features from the brain network, we design a hierarchical attention module for the brain network encoder. Further, we design a bi-level multi-modal contrastive loss to align the multi-modal features and tackle the domain gap at the focal tumor and global brain. Finally, we propose a weighted population graph to integrate the multi-modal features for genotype prediction. Experimental results on the testing set show that the proposed model outperforms the baseline deep learning models. The ablation experiments validate the performance of different components of the framework. The visualized interpretation corresponds to clinical knowledge with further validation. In conclusion, the proposed learning framework provides a novel approach for predicting the genotype of glioma.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022
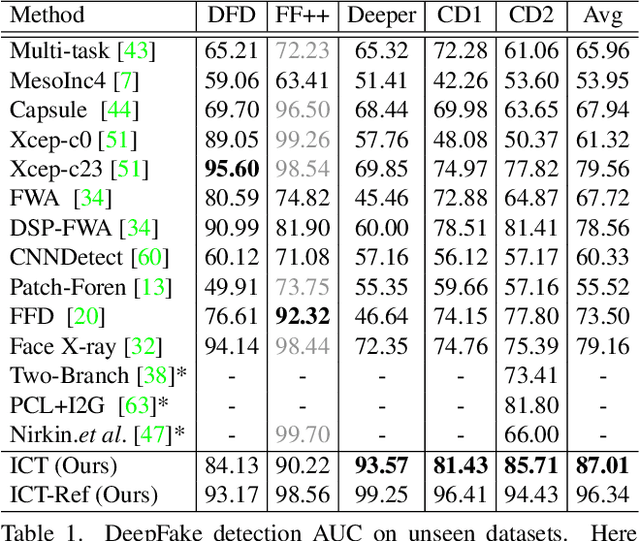

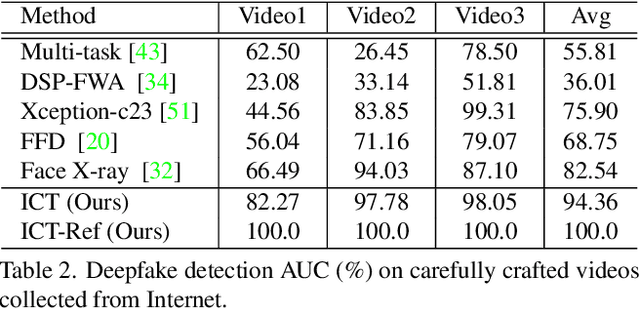
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Jan 16, 2021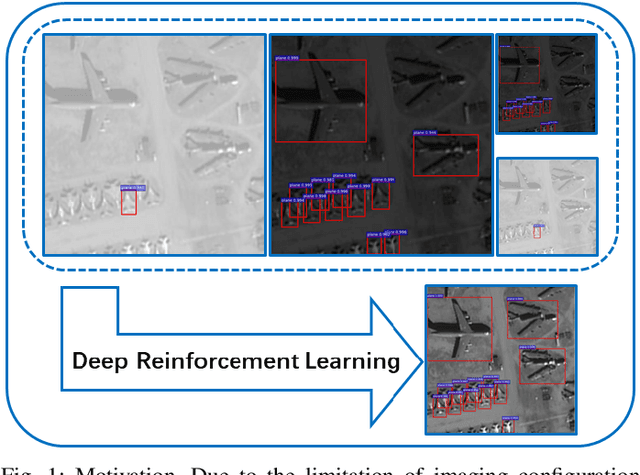
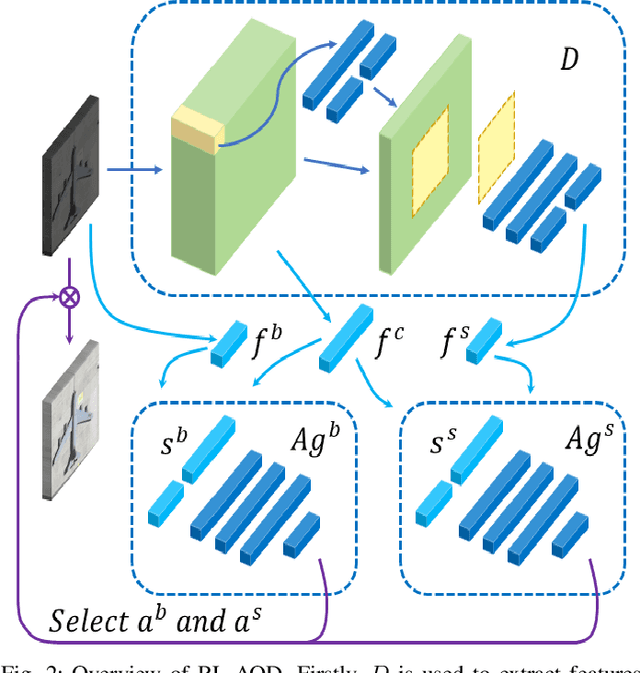
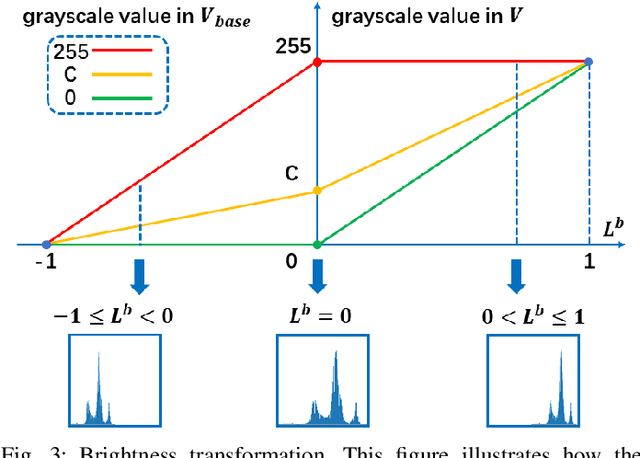
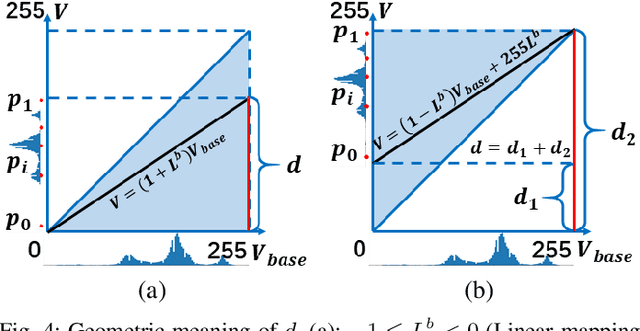
In recent years, deep learning methods bring incredible progress to the field of object detection. However, in the field of remote sensing image processing, existing methods neglect the relationship between imaging configuration and detection performance, and do not take into account the importance of detection performance feedback for improving image quality. Therefore, detection performance is limited by the passive nature of the conventional object detection framework. In order to solve the above limitations, this paper takes adaptive brightness adjustment and scale adjustment as examples, and proposes an active object detection method based on deep reinforcement learning. The goal of adaptive image attribute learning is to maximize the detection performance. With the help of active object detection and image attribute adjustment strategies, low-quality images can be converted into high-quality images, and the overall performance is improved without retraining the detector.
Blind Image Super-Resolution via Contrastive Representation Learning
Jul 01, 2021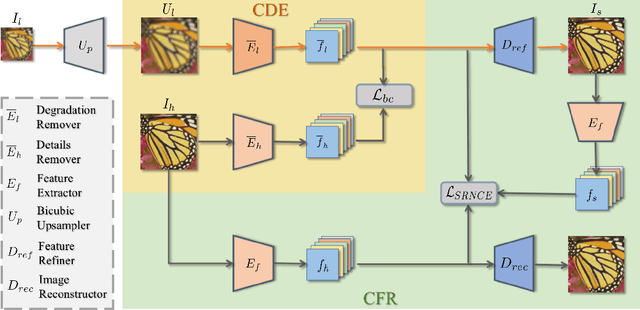

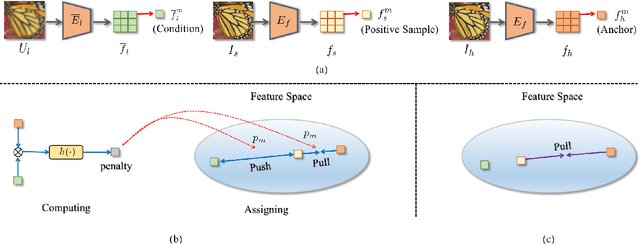
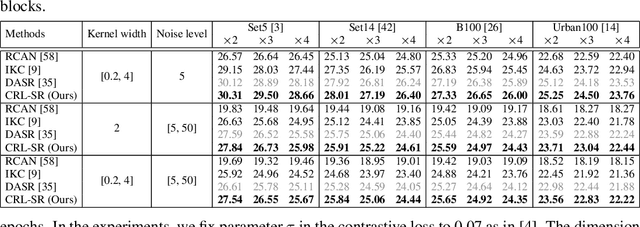
Image super-resolution (SR) research has witnessed impressive progress thanks to the advance of convolutional neural networks (CNNs) in recent years. However, most existing SR methods are non-blind and assume that degradation has a single fixed and known distribution (e.g., bicubic) which struggle while handling degradation in real-world data that usually follows a multi-modal, spatially variant, and unknown distribution. The recent blind SR studies address this issue via degradation estimation, but they do not generalize well to multi-source degradation and cannot handle spatially variant degradation. We design CRL-SR, a contrastive representation learning network that focuses on blind SR of images with multi-modal and spatially variant distributions. CRL-SR addresses the blind SR challenges from two perspectives. The first is contrastive decoupling encoding which introduces contrastive learning to extract resolution-invariant embedding and discard resolution-variant embedding under the guidance of a bidirectional contrastive loss. The second is contrastive feature refinement which generates lost or corrupted high-frequency details under the guidance of a conditional contrastive loss. Extensive experiments on synthetic datasets and real images show that the proposed CRL-SR can handle multi-modal and spatially variant degradation effectively under blind settings and it also outperforms state-of-the-art SR methods qualitatively and quantitatively.