 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Masked Spectrogram Prediction For Self-Supervised Audio Pre-Training
Apr 27, 2022
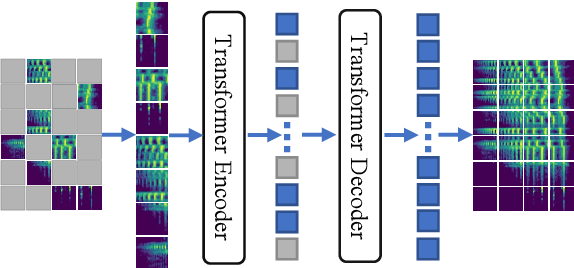
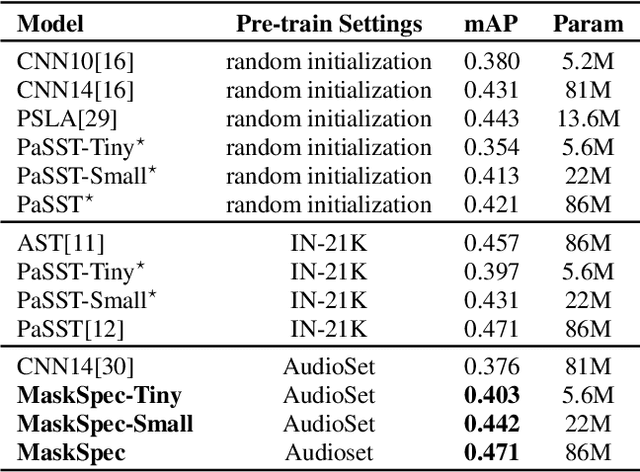
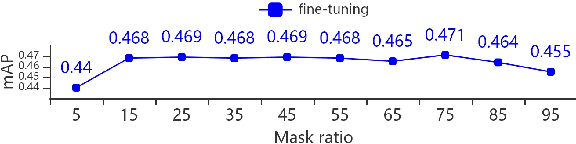
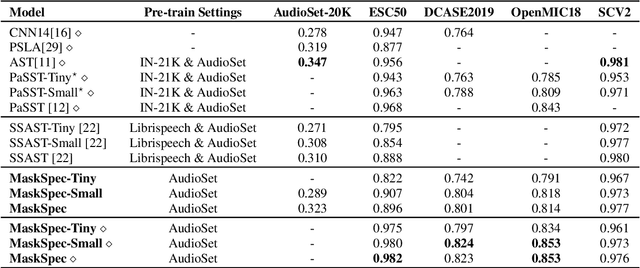
Transformer-based models attain excellent results and generalize well when trained on sufficient amounts of data. However, constrained by the limited data available in the audio domain, most transformer-based models for audio tasks are finetuned from pre-trained models in other domains (e.g. image), which has a notable gap with the audio domain. Other methods explore the self-supervised learning approaches directly in the audio domain but currently do not perform well in the downstream tasks. In this paper, we present a novel self-supervised learning method for transformer-based audio models, called masked spectrogram prediction (MaskSpec), to learn powerful audio representations from unlabeled audio data (AudioSet used in this paper). Our method masks random patches of the input spectrogram and reconstructs the masked regions with an encoder-decoder architecture. Without using extra model weights or supervision, experimental results on multiple downstream datasets demonstrate MaskSpec achieves a significant performance gain against the supervised methods and outperforms the previous pre-trained models. In particular, our best model reaches the performance of 0.471 (mAP) on AudioSet, 0.854 (mAP) on OpenMIC2018, 0.982 (accuracy) on ESC-50, 0.976 (accuracy) on SCV2, and 0.823 (accuracy) on DCASE2019 Task1A respectively.
Complete identification of complex salt-geometries from inaccurate migrated images using Deep Learning
Apr 22, 2022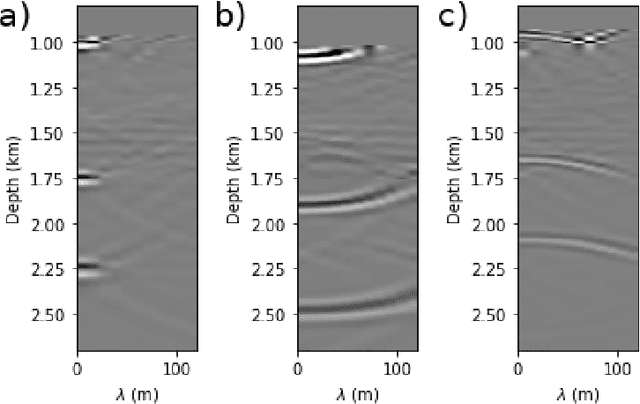
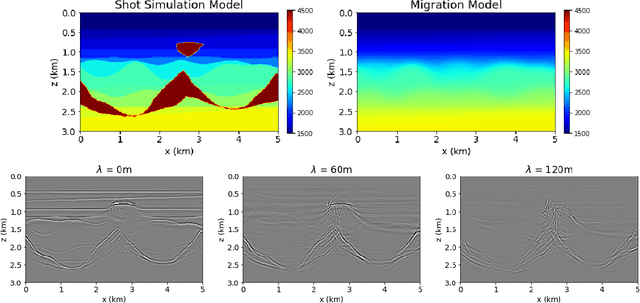
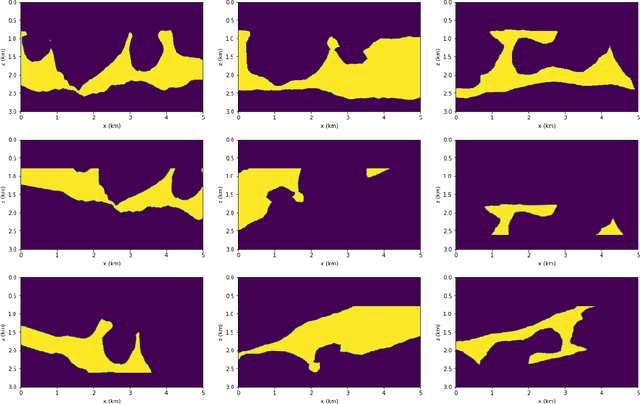
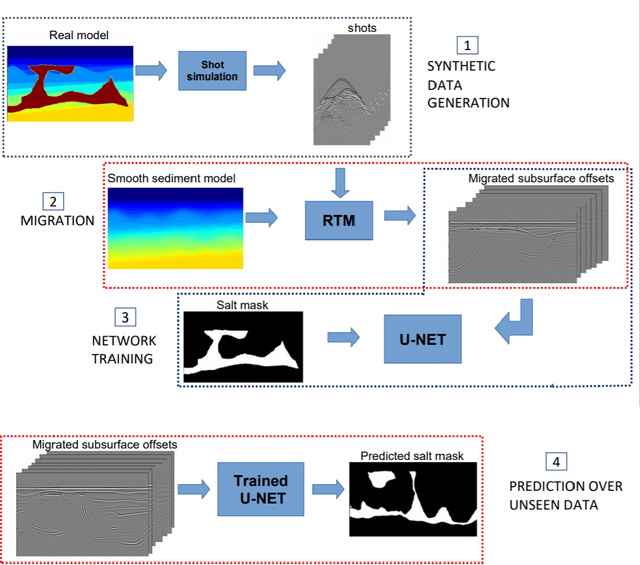
Delimiting salt inclusions from migrated images is a time-consuming activity that relies on highly human-curated analysis and is subject to interpretation errors or limitations of the methods available. We propose to use migrated images produced from an inaccurate velocity model (with a reasonable approximation of sediment velocity, but without salt inclusions) to predict the correct salt inclusions shape using a Convolutional Neural Network (CNN). Our approach relies on subsurface Common Image Gathers to focus the sediments' reflections around the zero offset and to spread the energy of salt reflections over large offsets. Using synthetic data, we trained a U-Net to use common-offset subsurface images as input channels for the CNN and the correct salt-masks as network output. The network learned to predict the salt inclusions masks with high accuracy; moreover, it also performed well when applied to synthetic benchmark data sets that were not previously introduced. Our training process tuned the U-Net to successfully learn the shape of complex salt bodies from partially focused subsurface offset images.
Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
Apr 12, 2021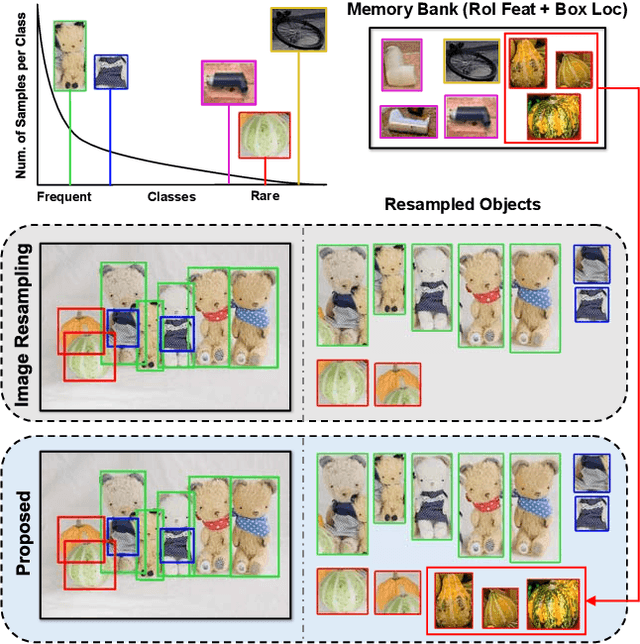
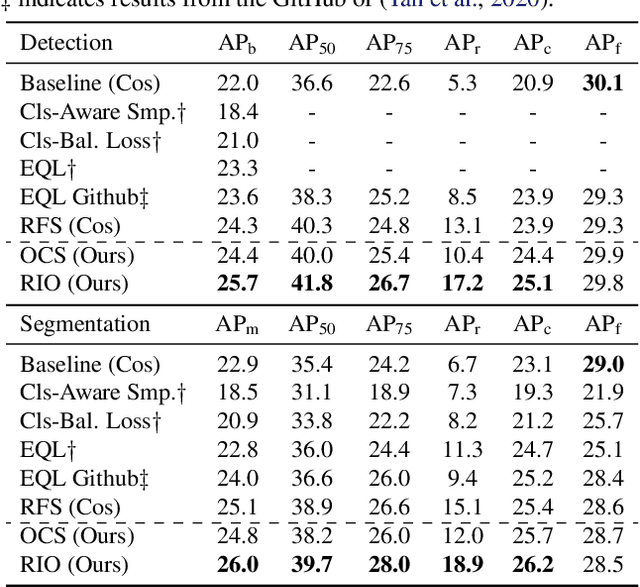

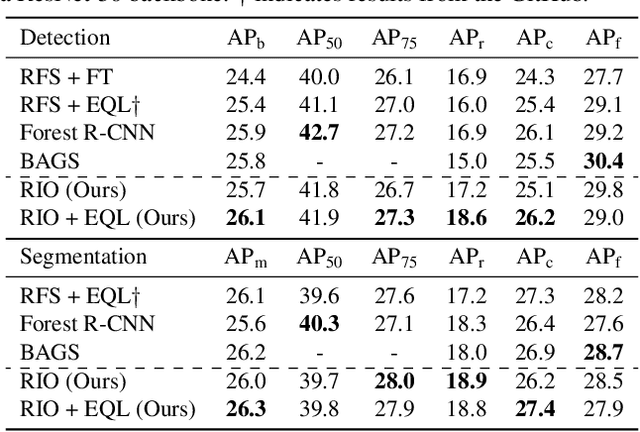
Training on datasets with long-tailed distributions has been challenging for major recognition tasks such as classification and detection. To deal with this challenge, image resampling is typically introduced as a simple but effective approach. However, we observe that long-tailed detection differs from classification since multiple classes may be present in one image. As a result, image resampling alone is not enough to yield a sufficiently balanced distribution at the object level. We address object-level resampling by introducing an object-centric memory replay strategy based on dynamic, episodic memory banks. Our proposed strategy has two benefits: 1) convenient object-level resampling without significant extra computation, and 2) implicit feature-level augmentation from model updates. We show that image-level and object-level resamplings are both important, and thus unify them with a joint resampling strategy (RIO). Our method outperforms state-of-the-art long-tailed detection and segmentation methods on LVIS v0.5 across various backbones.
Augmentation-Interpolative AutoEncoders for Unsupervised Few-Shot Image Generation
Nov 25, 2020
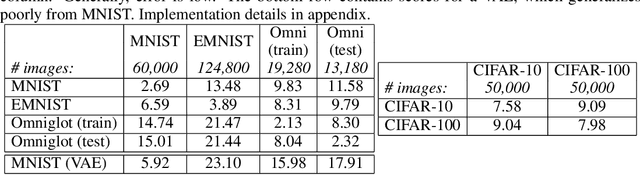

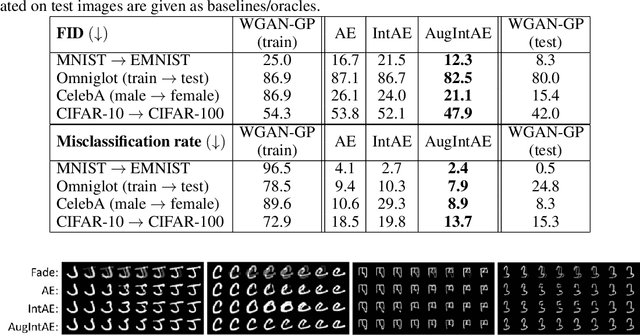
We aim to build image generation models that generalize to new domains from few examples. To this end, we first investigate the generalization properties of classic image generators, and discover that autoencoders generalize extremely well to new domains, even when trained on highly constrained data. We leverage this insight to produce a robust, unsupervised few-shot image generation algorithm, and introduce a novel training procedure based on recovering an image from data augmentations. Our Augmentation-Interpolative AutoEncoders synthesize realistic images of novel objects from only a few reference images, and outperform both prior interpolative models and supervised few-shot image generators. Our procedure is simple and lightweight, generalizes broadly, and requires no category labels or other supervision during training.
Few-shot Unsupervised Domain Adaptation for Multi-modal Cardiac Image Segmentation
Jan 28, 2022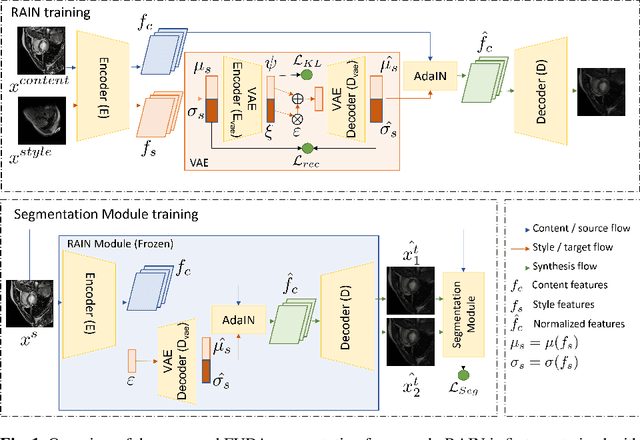
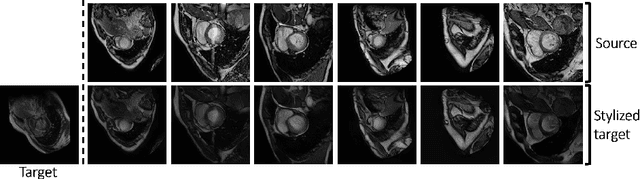

Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by using unlabeled target domain and labeled source domain data, however, in the medical domain, target domain data may not always be easily available, and acquiring new samples is generally time-consuming. This restricts the development of UDA methods for new domains. In this paper, we explore the potential of UDA in a more challenging while realistic scenario where only one unlabeled target patient sample is available. We call it Few-shot Unsupervised Domain adaptation (FUDA). We first generate target-style images from source images and explore diverse target styles from a single target patient with Random Adaptive Instance Normalization (RAIN). Then, a segmentation network is trained in a supervised manner with the generated target images. Our experiments demonstrate that FUDA improves the segmentation performance by 0.33 of Dice score on the target domain compared with the baseline, and it also gives 0.28 of Dice score improvement in a more rigorous one-shot setting. Our code is available at \url{https://github.com/MingxuanGu/Few-shot-UDA}.
Deep Unsupervised Image Hashing by Maximizing Bit Entropy
Dec 22, 2020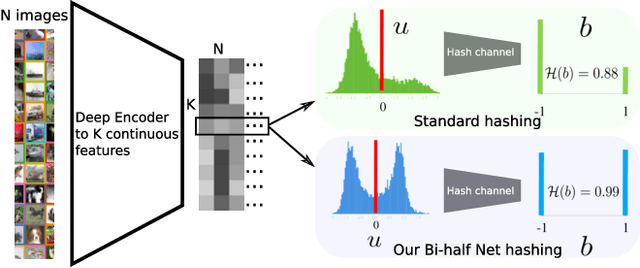
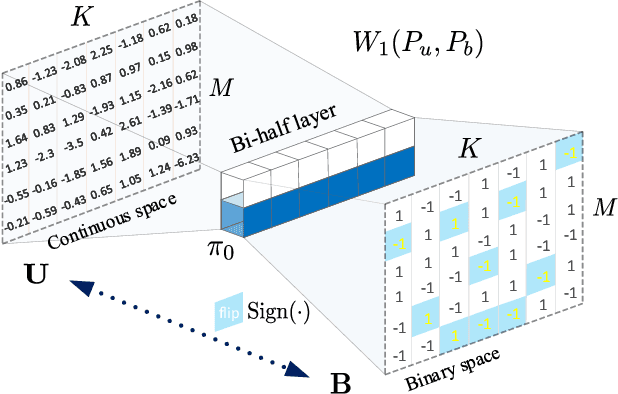
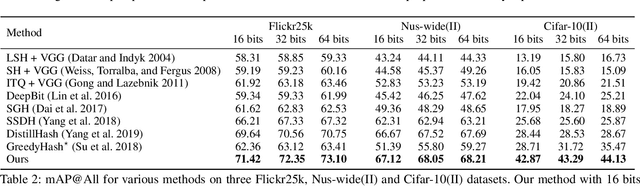
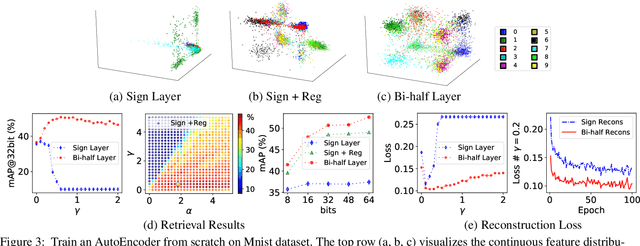
Unsupervised hashing is important for indexing huge image or video collections without having expensive annotations available. Hashing aims to learn short binary codes for compact storage and efficient semantic retrieval. We propose an unsupervised deep hashing layer called Bi-half Net that maximizes entropy of the binary codes. Entropy is maximal when both possible values of the bit are uniformly (half-half) distributed. To maximize bit entropy, we do not add a term to the loss function as this is difficult to optimize and tune. Instead, we design a new parameter-free network layer to explicitly force continuous image features to approximate the optimal half-half bit distribution. This layer is shown to minimize a penalized term of the Wasserstein distance between the learned continuous image features and the optimal half-half bit distribution. Experimental results on the image datasets Flickr25k, Nus-wide, Cifar-10, Mscoco, Mnist and the video datasets Ucf-101 and Hmdb-51 show that our approach leads to compact codes and compares favorably to the current state-of-the-art.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022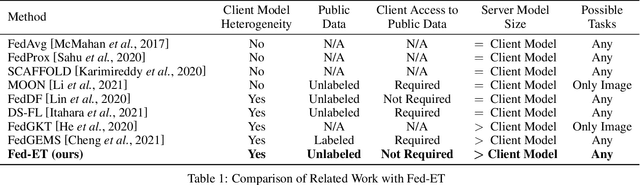
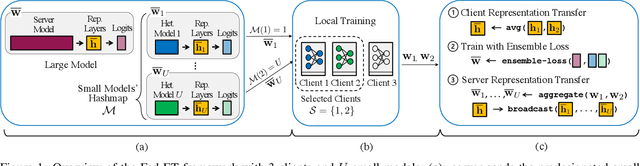
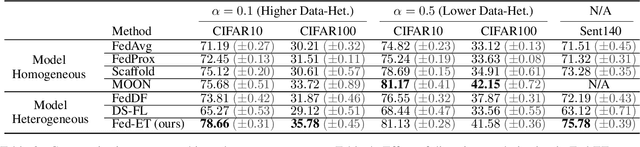
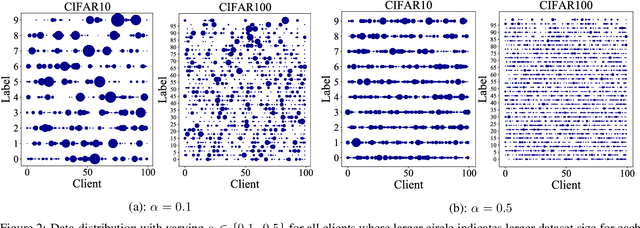
Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
DeepI2P: Image-to-Point Cloud Registration via Deep Classification
Apr 08, 2021

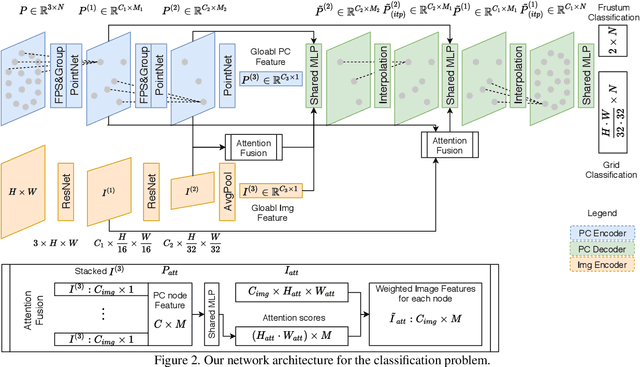
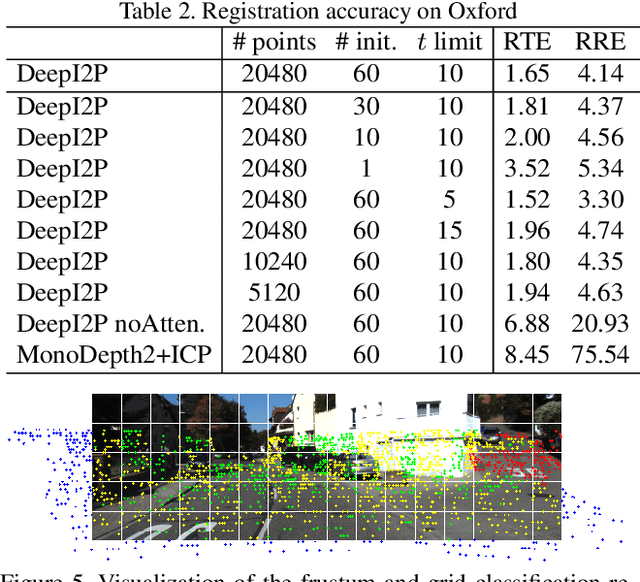
This paper presents DeepI2P: a novel approach for cross-modality registration between an image and a point cloud. Given an image (e.g. from a rgb-camera) and a general point cloud (e.g. from a 3D Lidar scanner) captured at different locations in the same scene, our method estimates the relative rigid transformation between the coordinate frames of the camera and Lidar. Learning common feature descriptors to establish correspondences for the registration is inherently challenging due to the lack of appearance and geometric correlations across the two modalities. We circumvent the difficulty by converting the registration problem into a classification and inverse camera projection optimization problem. A classification neural network is designed to label whether the projection of each point in the point cloud is within or beyond the camera frustum. These labeled points are subsequently passed into a novel inverse camera projection solver to estimate the relative pose. Extensive experimental results on Oxford Robotcar and KITTI datasets demonstrate the feasibility of our approach. Our source code is available at https://github.com/lijx10/DeepI2P
Improving the Transferability of Adversarial Examples with Restructure Embedded Patches
Apr 27, 2022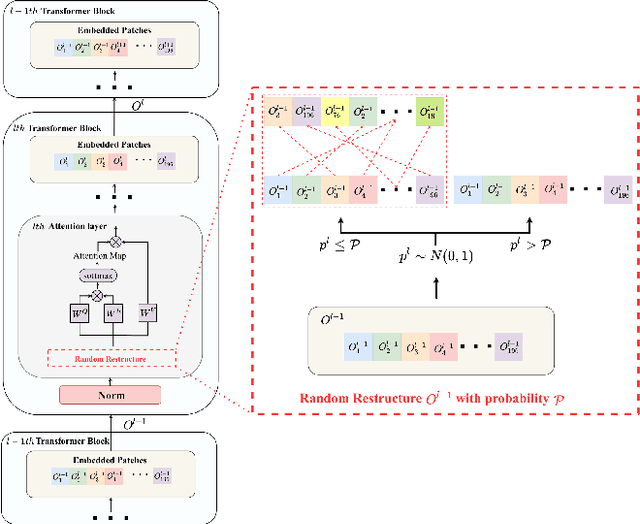
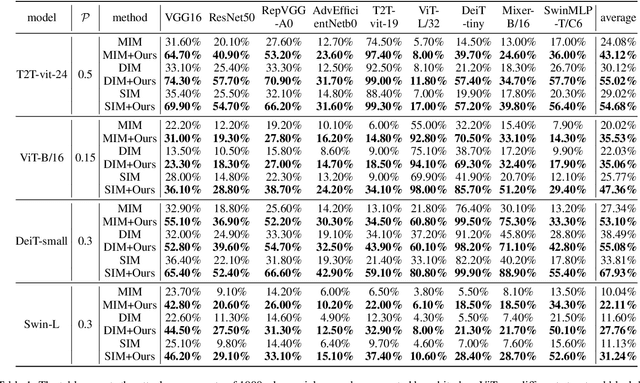

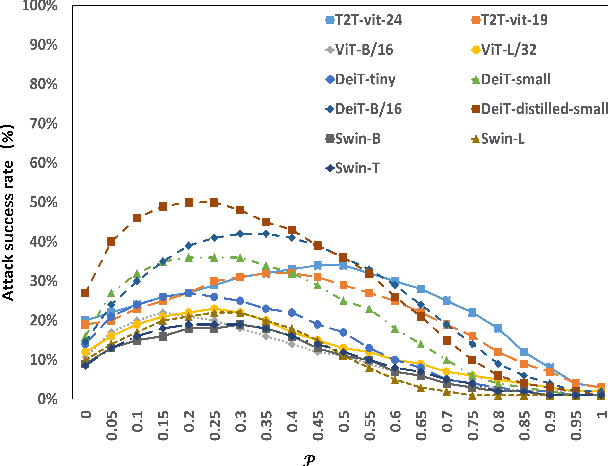
Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.
A Multi-Task Cross-Task Learning Architecture for Ad-hoc Uncertainty Estimation in 3D Cardiac MRI Image Segmentation
Oct 03, 2021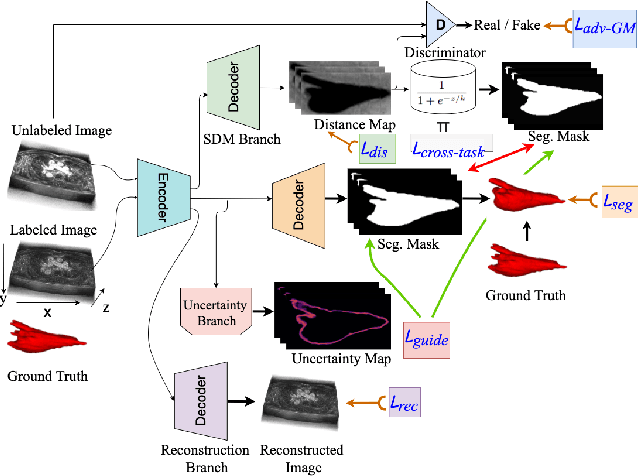

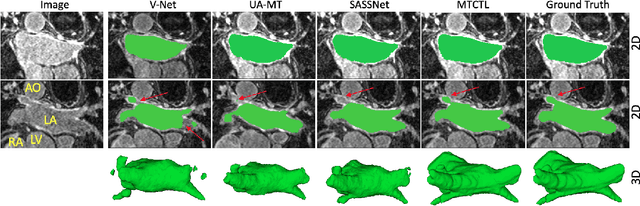
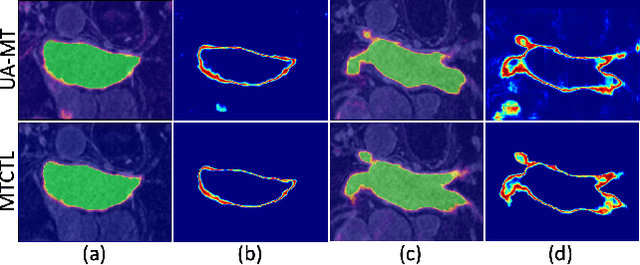
Medical image segmentation has significantly benefitted thanks to deep learning architectures. Furthermore, semi-supervised learning (SSL) has recently been a growing trend for improving a model's overall performance by leveraging abundant unlabeled data. Moreover, learning multiple tasks within the same model further improves model generalizability. To generate smoother and accurate segmentation masks from 3D cardiac MR images, we present a Multi-task Cross-task learning consistency approach to enforce the correlation between the pixel-level (segmentation) and the geometric-level (distance map) tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justifies the effectiveness of our model for the segmentation of the left atrial cavity from Gadolinium-enhanced magnetic resonance (GE-MR) images. With the incorporation of uncertainty estimates to detect failures in the segmentation masks generated by CNNs, our study further showcases the potential of our model to flag low-quality segmentation from a given model.