 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Reference Quality Monitoring of Digital Images using Gradient Statistics and Feedforward Neural Networks
Dec 27, 2021
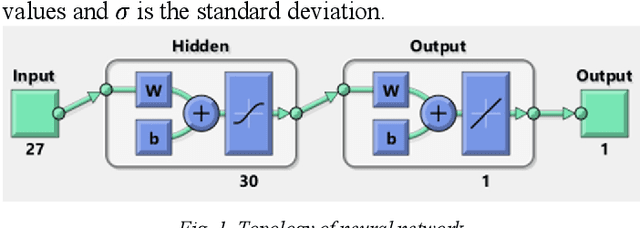
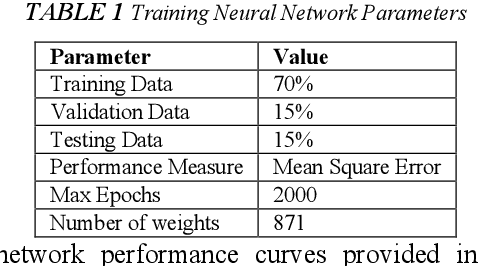
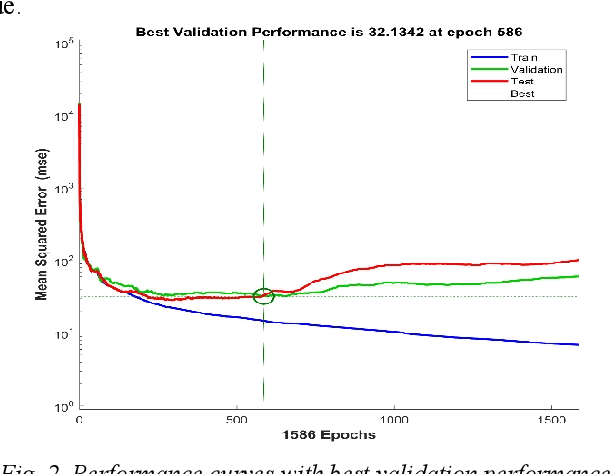
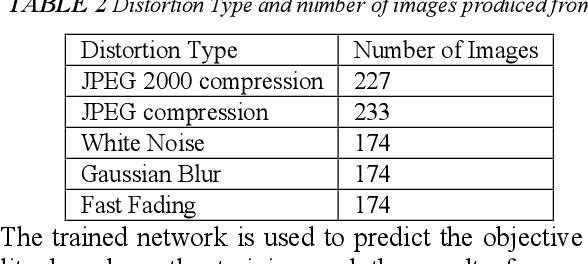
Digital images contain a lot of redundancies, therefore, compressions are applied to reduce the image size without the loss of reasonable image quality. The same become more prominent in the case of videos that contains image sequences and higher compression ratios are achieved in low throughput networks. Assessment of the quality of images in such scenarios becomes of particular interest. Subjective evaluation in most of the scenarios becomes infeasible so objective evaluation is preferred. Among the three objective quality measures, full-reference and reduced-reference methods require an original image in some form to calculate the quality score which is not feasible in scenarios such as broadcasting or IP video. Therefore, a non-reference quality metric is proposed to assess the quality of digital images which calculates luminance and multiscale gradient statistics along with mean subtracted contrast normalized products as features to train a Feedforward Neural Network with Scaled Conjugate Gradient. The trained network has provided good regression and R2 measures and further testing on LIVE Image Quality Assessment database release-2 has shown promising results. Pearson, Kendall, and Spearman's correlation are calculated between predicted and actual quality scores and their results are comparable to the state-of-the-art systems. Moreover, the proposed metric is computationally faster than its counterparts and can be used for the quality assessment of image sequences.
Deep Facial Synthesis: A New Challenge
Jan 07, 2022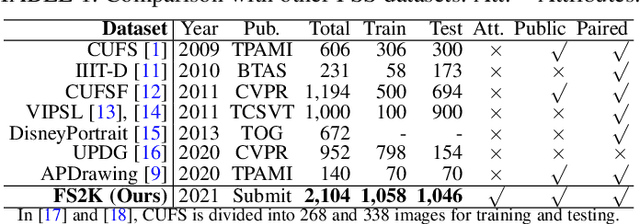


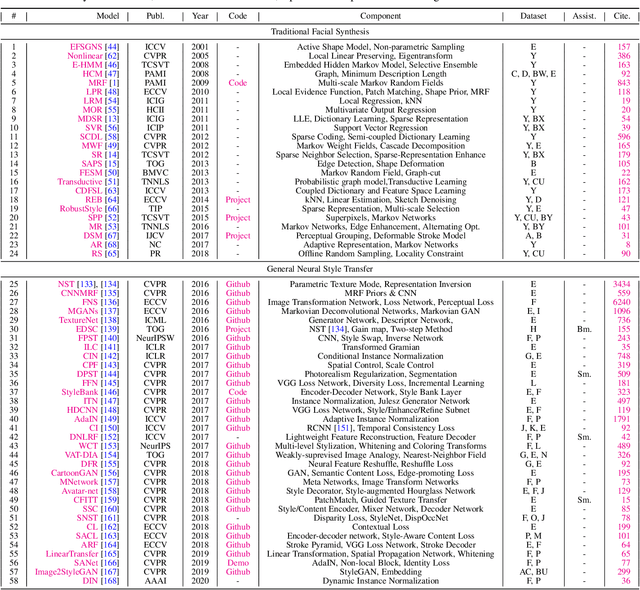
The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
Quantum Compressive Sensing: Mathematical Machinery, Quantum Algorithms, and Quantum Circuitry
Apr 27, 2022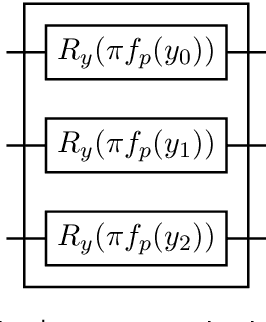
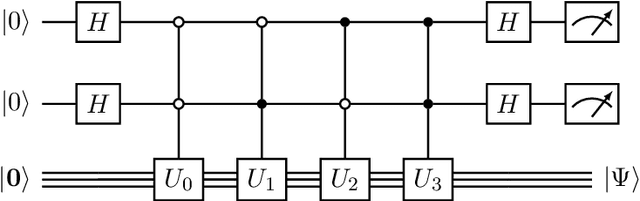
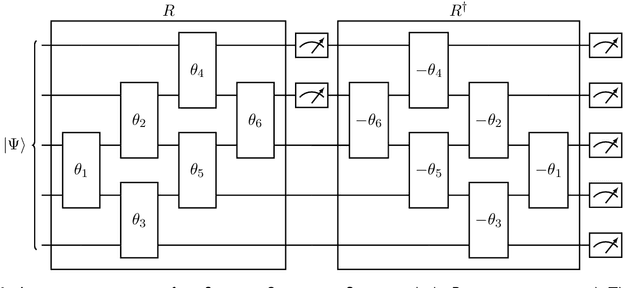
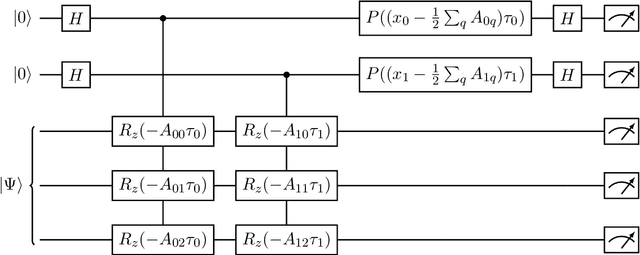
Compressive sensing is a sensing protocol that facilitates reconstruction of large signals from relatively few measurements by exploiting known structures of signals of interest, typically manifested as signal sparsity. Compressive sensing's vast repertoire of applications in areas such as communications and image reconstruction stems from the traditional approach of utilizing non-linear optimization to exploit the sparsity assumption by selecting the lowest-weight (i.e. maximum sparsity) signal consistent with all acquired measurements. Recent efforts in the literature consider instead a data-driven approach, training tensor networks to learn the structure of signals of interest. The trained tensor network is updated to "project" its state onto one consistent with the measurements taken, and is then sampled site by site to "guess" the original signal. In this paper, we take advantage of this computing protocol by formulating an alternative "quantum" protocol, in which the state of the tensor network is a quantum state over a set of entangled qubits. Accordingly, we present the associated algorithms and quantum circuits required to implement the training, projection, and sampling steps on a quantum computer. We supplement our theoretical results by simulating the proposed circuits with a small, qualitative model of LIDAR imaging of earth forests. Our results indicate that a quantum, data-driven approach to compressive sensing, may have significant promise as quantum technology continues to make new leaps.
DeiT III: Revenge of the ViT
Apr 14, 2022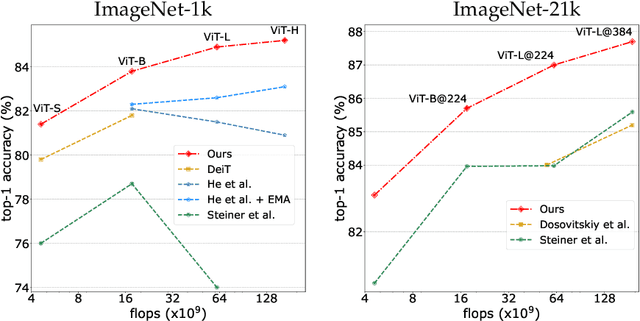



A Vision Transformer (ViT) is a simple neural architecture amenable to serve several computer vision tasks. It has limited built-in architectural priors, in contrast to more recent architectures that incorporate priors either about the input data or of specific tasks. Recent works show that ViTs benefit from self-supervised pre-training, in particular BerT-like pre-training like BeiT. In this paper, we revisit the supervised training of ViTs. Our procedure builds upon and simplifies a recipe introduced for training ResNet-50. It includes a new simple data-augmentation procedure with only 3 augmentations, closer to the practice in self-supervised learning. Our evaluations on Image classification (ImageNet-1k with and without pre-training on ImageNet-21k), transfer learning and semantic segmentation show that our procedure outperforms by a large margin previous fully supervised training recipes for ViT. It also reveals that the performance of our ViT trained with supervision is comparable to that of more recent architectures. Our results could serve as better baselines for recent self-supervised approaches demonstrated on ViT.
GlassNet: Label Decoupling-based Three-stream Neural Network for Robust Image Glass Detection
Aug 25, 2021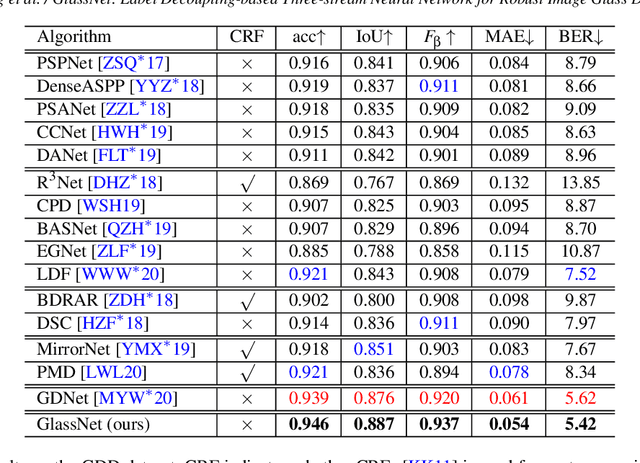

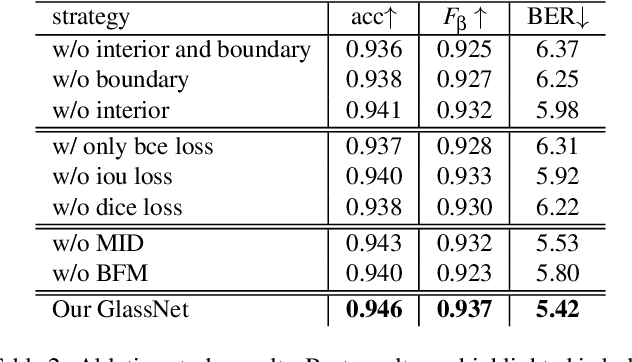

Most of the existing object detection methods generate poor glass detection results, due to the fact that the transparent glass shares the same appearance with arbitrary objects behind it in an image. Different from traditional deep learning-based wisdoms that simply use the object boundary as auxiliary supervision, we exploit label decoupling to decompose the original labeled ground-truth (GT) map into an interior-diffusion map and a boundary-diffusion map. The GT map in collaboration with the two newly generated maps breaks the imbalanced distribution of the object boundary, leading to improved glass detection quality. We have three key contributions to solve the transparent glass detection problem: (1) We propose a three-stream neural network (call GlassNet for short) to fully absorb beneficial features in the three maps. (2) We design a multi-scale interactive dilation module to explore a wider range of contextual information. (3) We develop an attention-based boundary-aware feature Mosaic module to integrate multi-modal information. Extensive experiments on the benchmark dataset exhibit clear improvements of our method over SOTAs, in terms of both the overall glass detection accuracy and boundary clearness.
A Real World Dataset for Multi-view 3D Reconstruction
Mar 22, 2022
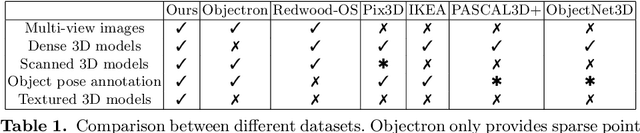
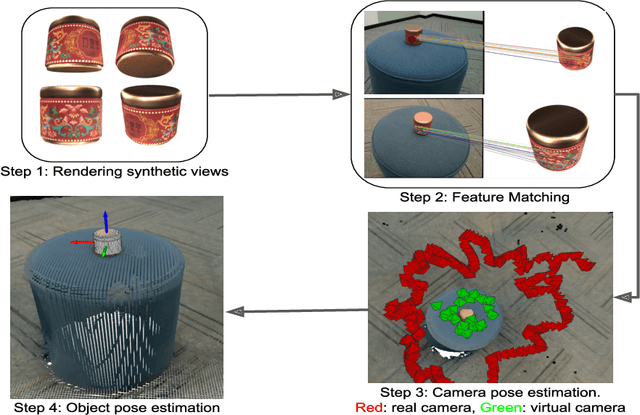
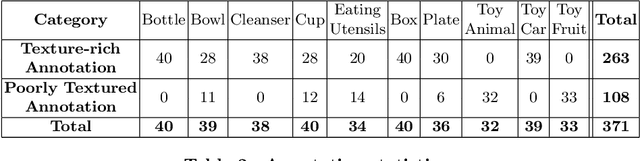
We present a dataset of 371 3D models of everyday tabletop objects along with their 320,000 real world RGB and depth images. Accurate annotations of camera poses and object poses for each image are performed in a semi-automated fashion to facilitate the use of the dataset for myriad 3D applications like shape reconstruction, object pose estimation, shape retrieval etc. We primarily focus on learned multi-view 3D reconstruction due to the lack of appropriate real world benchmark for the task and demonstrate that our dataset can fill that gap. The entire annotated dataset along with the source code for the annotation tools and evaluation baselines will be made publicly available.
Self-Supervised Nonlinear Transform-Based Tensor Nuclear Norm for Multi-Dimensional Image Recovery
May 29, 2021
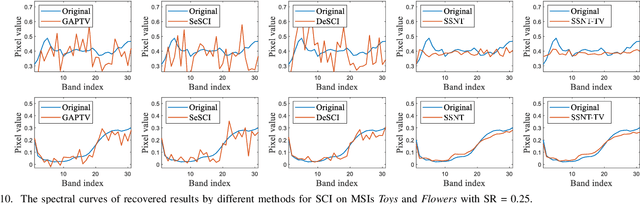

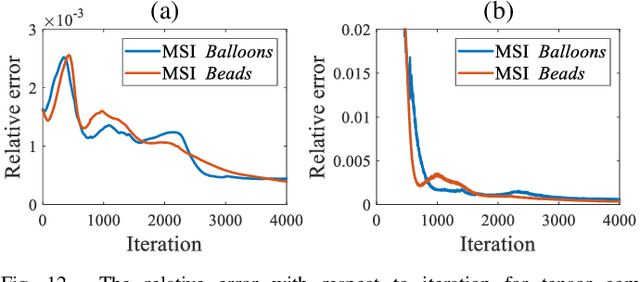
In this paper, we study multi-dimensional image recovery. Recently, transform-based tensor nuclear norm minimization methods are considered to capture low-rank tensor structures to recover third-order tensors in multi-dimensional image processing applications. The main characteristic of such methods is to perform the linear transform along the third mode of third-order tensors, and then compute tensor nuclear norm minimization on the transformed tensor so that the underlying low-rank tensors can be recovered. The main aim of this paper is to propose a nonlinear multilayer neural network to learn a nonlinear transform via the observed tensor data under self-supervision. The proposed network makes use of low-rank representation of transformed tensors and data-fitting between the observed tensor and the reconstructed tensor to construct the nonlinear transformation. Extensive experimental results on tensor completion, background subtraction, robust tensor completion, and snapshot compressive imaging are presented to demonstrate that the performance of the proposed method is better than that of state-of-the-art methods.
DiNTS: Differentiable Neural Network Topology Search for 3D Medical Image Segmentation
Mar 29, 2021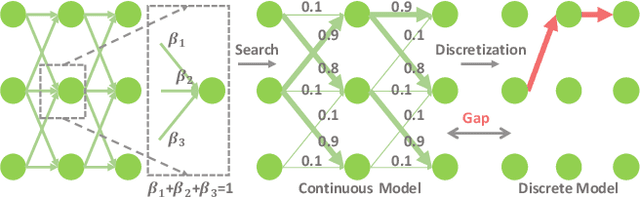
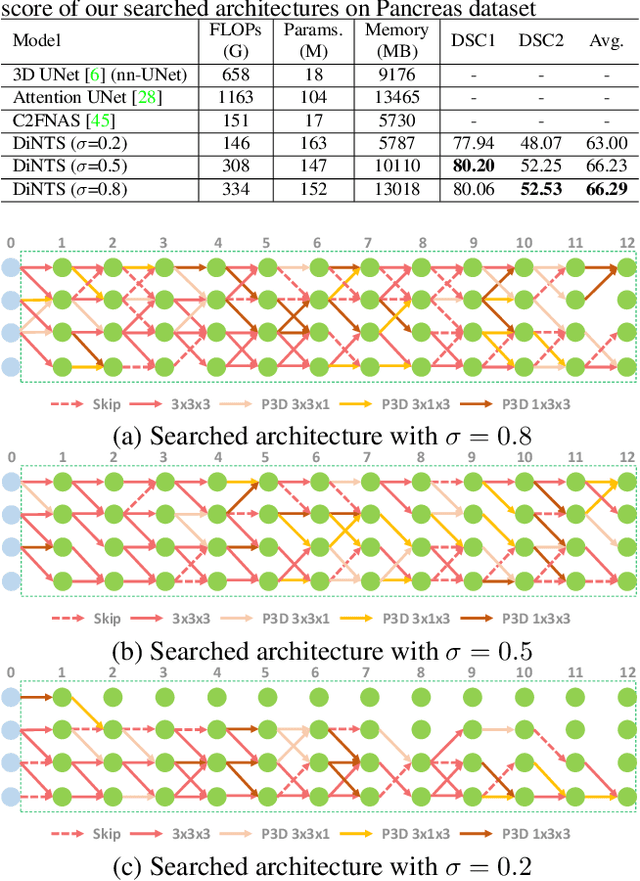
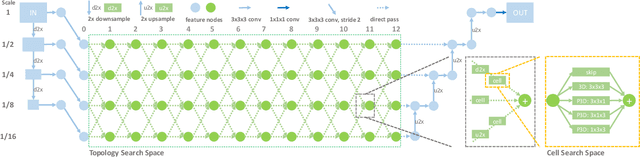
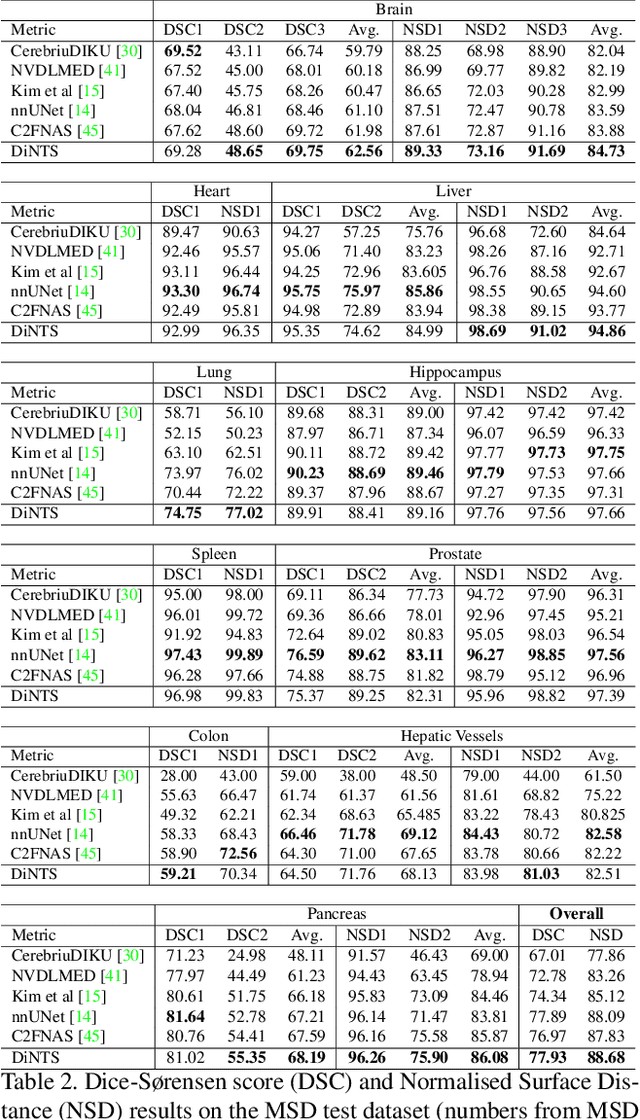
Recently, neural architecture search (NAS) has been applied to automatically search high-performance networks for medical image segmentation. The NAS search space usually contains a network topology level (controlling connections among cells with different spatial scales) and a cell level (operations within each cell). Existing methods either require long searching time for large-scale 3D image datasets, or are limited to pre-defined topologies (such as U-shaped or single-path). In this work, we focus on three important aspects of NAS in 3D medical image segmentation: flexible multi-path network topology, high search efficiency, and budgeted GPU memory usage. A novel differentiable search framework is proposed to support fast gradient-based search within a highly flexible network topology search space. The discretization of the searched optimal continuous model in differentiable scheme may produce a sub-optimal final discrete model (discretization gap). Therefore, we propose a topology loss to alleviate this problem. In addition, the GPU memory usage for the searched 3D model is limited with budget constraints during search. Our Differentiable Network Topology Search scheme (DiNTS) is evaluated on the Medical Segmentation Decathlon (MSD) challenge, which contains ten challenging segmentation tasks. Our method achieves the state-of-the-art performance and the top ranking on the MSD challenge leaderboard.
RadioTransformer: A Cascaded Global-Focal Transformer for Visual Attention-guided Disease Classification
Feb 23, 2022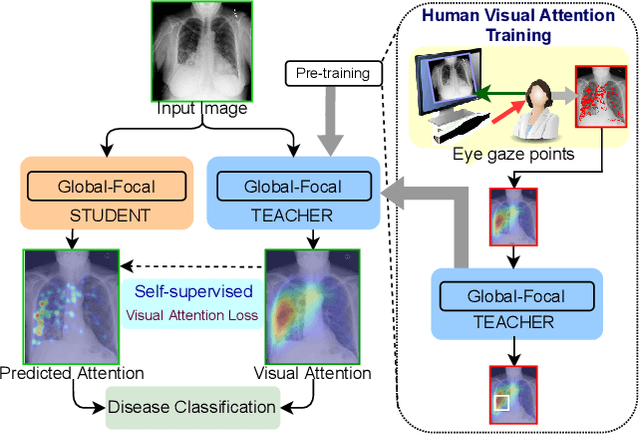

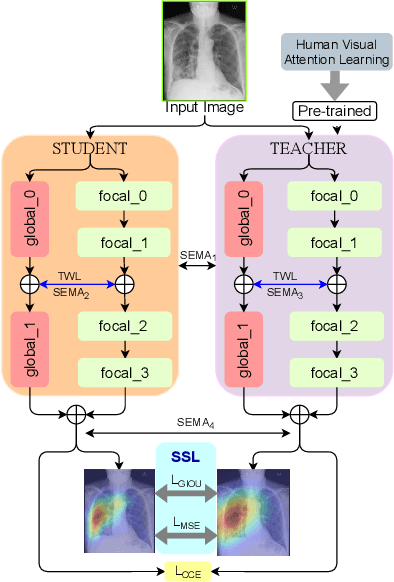
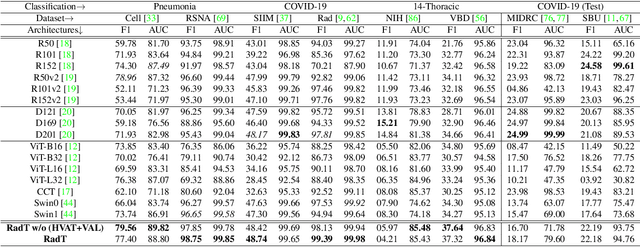
In this work, we present RadioTransformer, a novel visual attention-driven transformer framework, that leverages radiologists' gaze patterns and models their visuo-cognitive behavior for disease diagnosis on chest radiographs. Domain experts, such as radiologists, rely on visual information for medical image interpretation. On the other hand, deep neural networks have demonstrated significant promise in similar tasks even where visual interpretation is challenging. Eye-gaze tracking has been used to capture the viewing behavior of domain experts, lending insights into the complexity of visual search. However, deep learning frameworks, even those that rely on attention mechanisms, do not leverage this rich domain information. RadioTransformer fills this critical gap by learning from radiologists' visual search patterns, encoded as 'human visual attention regions' in a cascaded global-focal transformer framework. The overall 'global' image characteristics and the more detailed 'local' features are captured by the proposed global and focal modules, respectively. We experimentally validate the efficacy of our student-teacher approach for 8 datasets involving different disease classification tasks where eye-gaze data is not available during the inference phase.
BOAT: Bilateral Local Attention Vision Transformer
Jan 31, 2022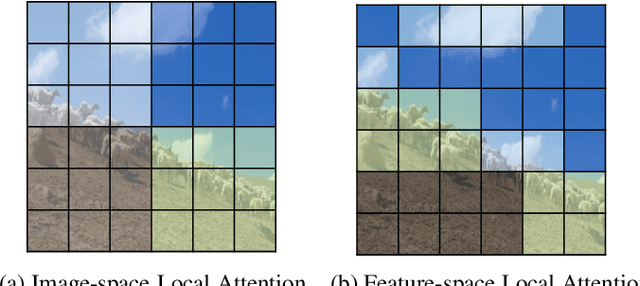
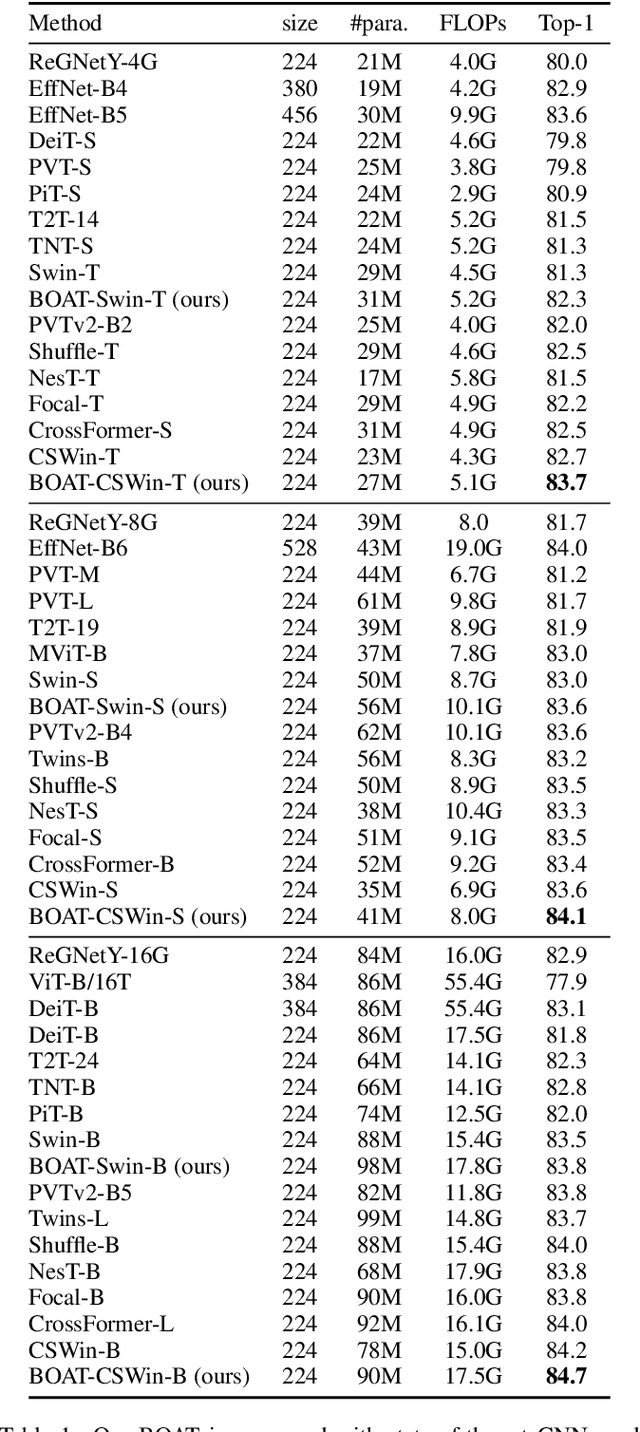

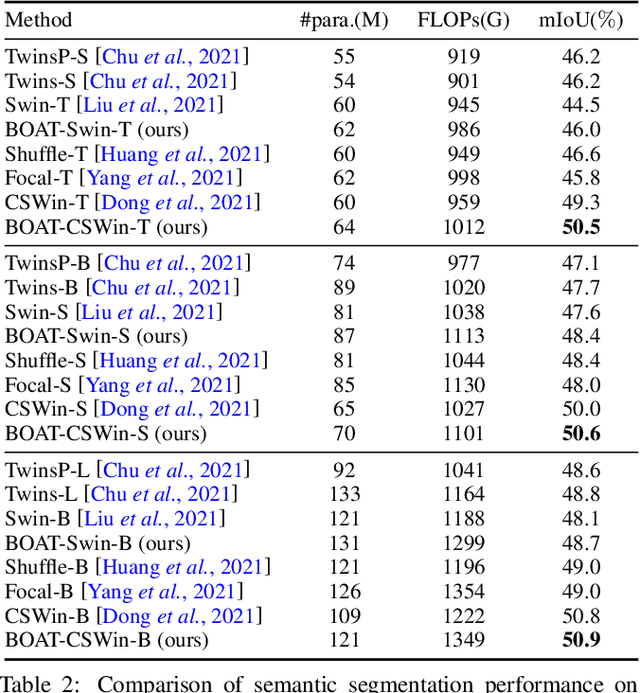
Vision Transformers achieved outstanding performance in many computer vision tasks. Early Vision Transformers such as ViT and DeiT adopt global self-attention, which is computationally expensive when the number of patches is large. To improve efficiency, recent Vision Transformers adopt local self-attention mechanisms, where self-attention is computed within local windows. Despite the fact that window-based local self-attention significantly boosts efficiency, it fails to capture the relationships between distant but similar patches in the image plane. To overcome this limitation of image-space local attention, in this paper, we further exploit the locality of patches in the feature space. We group the patches into multiple clusters using their features, and self-attention is computed within every cluster. Such feature-space local attention effectively captures the connections between patches across different local windows but still relevant. We propose a Bilateral lOcal Attention vision Transformer (BOAT), which integrates feature-space local attention with image-space local attention. We further integrate BOAT with both Swin and CSWin models, and extensive experiments on several benchmark datasets demonstrate that our BOAT-CSWin model clearly and consistently outperforms existing state-of-the-art CNN models and vision Transformers.