 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Real-time Junk Food Recognition System based on Machine Learning
Mar 22, 2022



$ $As a result of bad eating habits, humanity may be destroyed. People are constantly on the lookout for tasty foods, with junk foods being the most common source. As a consequence, our eating patterns are shifting, and we're gravitating toward junk food more than ever, which is bad for our health and increases our risk of acquiring health problems. Machine learning principles are applied in every aspect of our lives, and one of them is object recognition via image processing. However, because foods vary in nature, this procedure is crucial, and traditional methods like ANN, SVM, KNN, PLS etc., will result in a low accuracy rate. All of these issues were defeated by the Deep Neural Network. In this work, we created a fresh dataset of 10,000 data points from 20 junk food classifications to try to recognize junk foods. All of the data in the data set was gathered using the Google search engine, which is thought to be one-of-a-kind in every way. The goal was achieved using Convolution Neural Network (CNN) technology, which is well-known for image processing. We achieved a 98.05\% accuracy rate throughout the research, which was satisfactory. In addition, we conducted a test based on a real-life event, and the outcome was extraordinary. Our goal is to advance this research to the next level, so that it may be applied to a future study. Our ultimate goal is to create a system that would encourage people to avoid eating junk food and to be health-conscious. \keywords{ Machine Learning \and junk food \and object detection \and YOLOv3 \and custom food dataset.}
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Dec 24, 2021


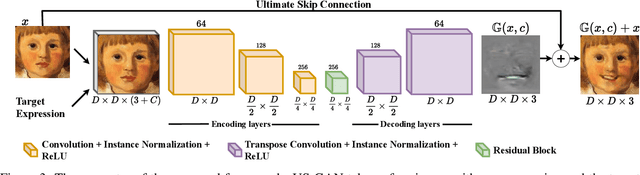
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.
Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization
Apr 20, 2022

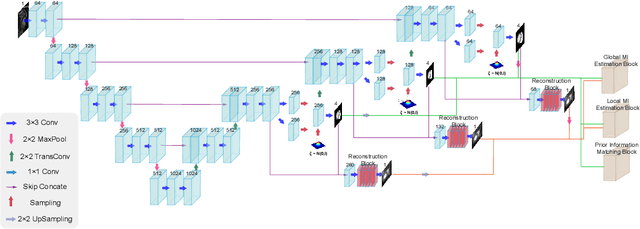
Unsupervised domain adaptation approaches have recently succeeded in various medical image segmentation tasks. The reported works often tackle the domain shift problem by aligning the domain-invariant features and minimizing the domain-specific discrepancies. That strategy works well when the difference between a specific domain and between different domains is slight. However, the generalization ability of these models on diverse imaging modalities remains a significant challenge. This paper introduces UDA-VAE++, an unsupervised domain adaptation framework for cardiac segmentation with a compact loss function lower bound. To estimate this new lower bound, we develop a novel Structure Mutual Information Estimation (SMIE) block with a global estimator, a local estimator, and a prior information matching estimator to maximize the mutual information between the reconstruction and segmentation tasks. Specifically, we design a novel sequential reparameterization scheme that enables information flow and variance correction from the low-resolution latent space to the high-resolution latent space. Comprehensive experiments on benchmark cardiac segmentation datasets demonstrate that our model outperforms previous state-of-the-art qualitatively and quantitatively. The code is available at https://github.com/LOUEY233/Toward-Mutual-Information}{https://github.com/LOUEY233/Toward-Mutual-Information
A Multi-Task Cross-Task Learning Architecture for Ad-hoc Uncertainty Estimation in 3D Cardiac MRI Image Segmentation
Sep 25, 2021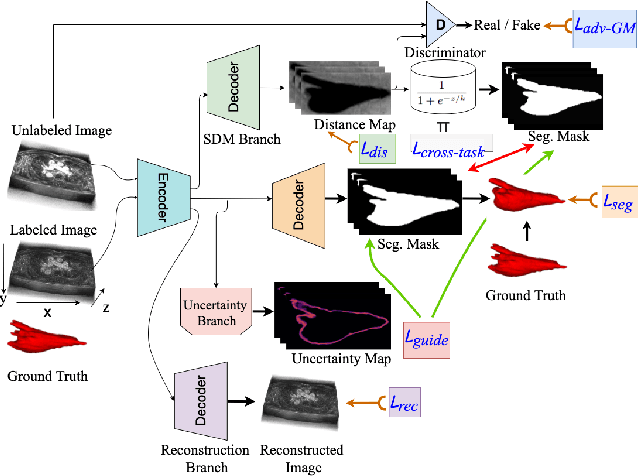

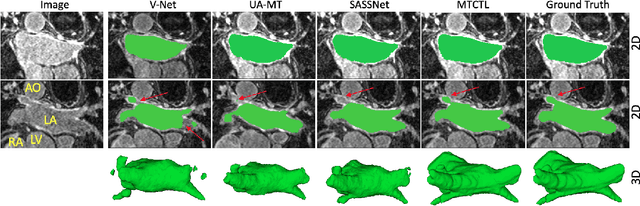
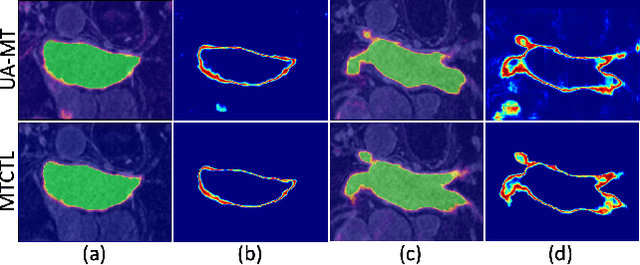
Medical image segmentation has significantly benefitted thanks to deep learning architectures. Furthermore, semi-supervised learning (SSL) has recently been a growing trend for improving a model's overall performance by leveraging abundant unlabeled data. Moreover, learning multiple tasks within the same model further improves model generalizability. To generate smoother and accurate segmentation masks from 3D cardiac MR images, we present a Multi-task Cross-task learning consistency approach to enforce the correlation between the pixel-level (segmentation) and the geometric-level (distance map) tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justifies the effectiveness of our model for the segmentation of the left atrial cavity from Gadolinium-enhanced magnetic resonance (GE-MR) images. With the incorporation of uncertainty estimates to detect failures in the segmentation masks generated by CNNs, our study further showcases the potential of our model to flag low-quality segmentation from a given model.
WideCaps: A Wide Attention based Capsule Network for Image Classification
Aug 08, 2021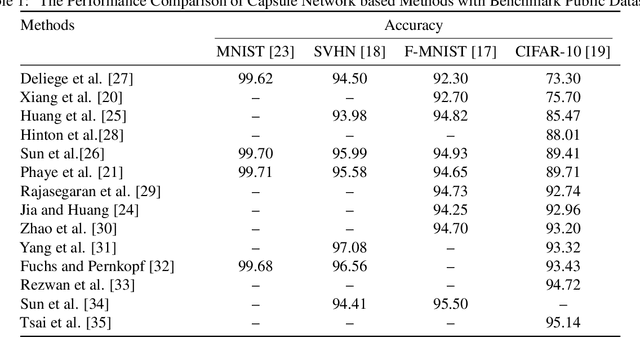
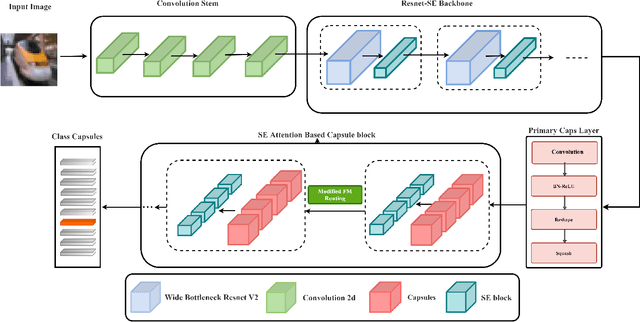
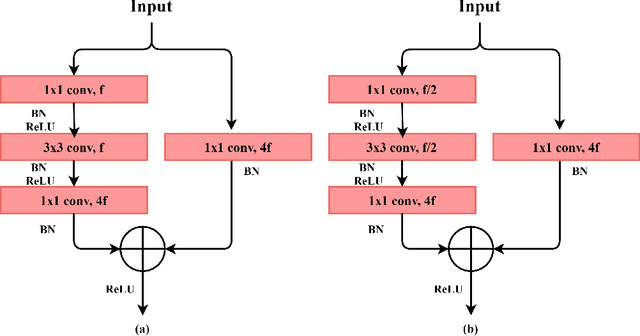

The capsule network is a distinct and promising segment of the neural network family that drew attention due to its unique ability to maintain the equivariance property by preserving the spatial relationship amongst the features. The capsule network has attained unprecedented success over image classification tasks with datasets such as MNIST and affNIST by encoding the characteristic features into the capsules and building the parse-tree structure. However, on the datasets involving complex foreground and background regions such as CIFAR-10, the performance of the capsule network is sub-optimal due to its naive data routing policy and incompetence towards extracting complex features. This paper proposes a new design strategy for capsule network architecture for efficiently dealing with complex images. The proposed method incorporates wide bottleneck residual modules and the Squeeze and Excitation attention blocks upheld by the modified FM routing algorithm to address the defined problem. A wide bottleneck residual module facilitates extracting complex features followed by the squeeze and excitation attention block to enable channel-wise attention by suppressing the trivial features. This setup allows channel inter-dependencies at almost no computational cost, thereby enhancing the representation ability of capsules on complex images. We extensively evaluate the performance of the proposed model on three publicly available datasets, namely CIFAR-10, Fashion MNIST, and SVHN, to outperform the top-5 performance on CIFAR-10 and Fashion MNIST with highly competitive performance on the SVHN dataset.
OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
Apr 07, 2022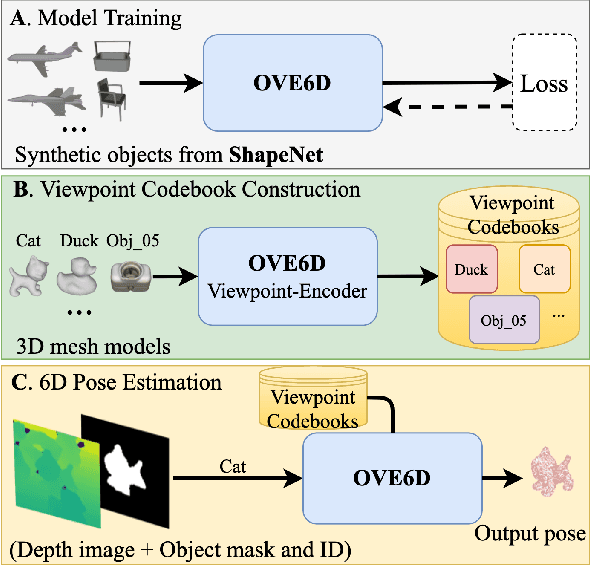
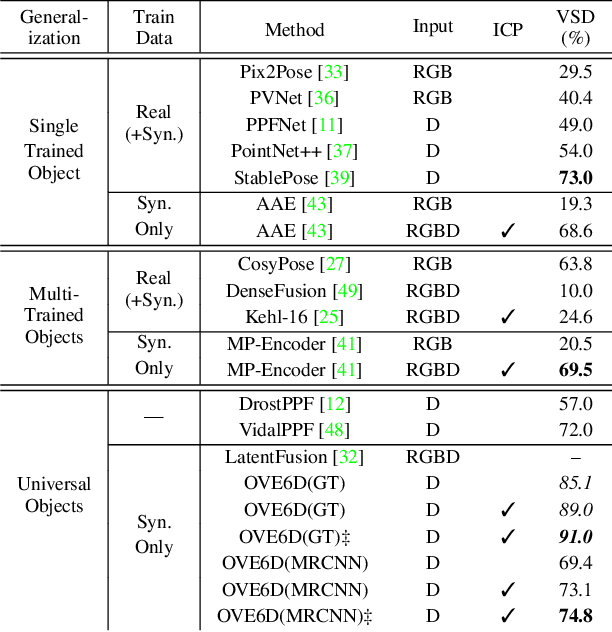
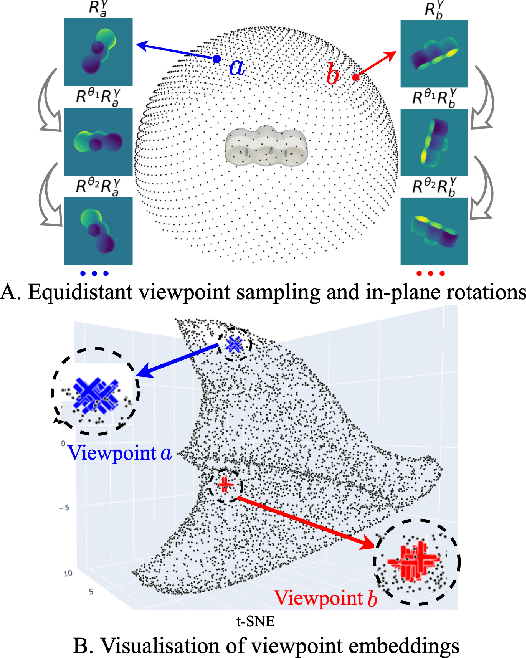
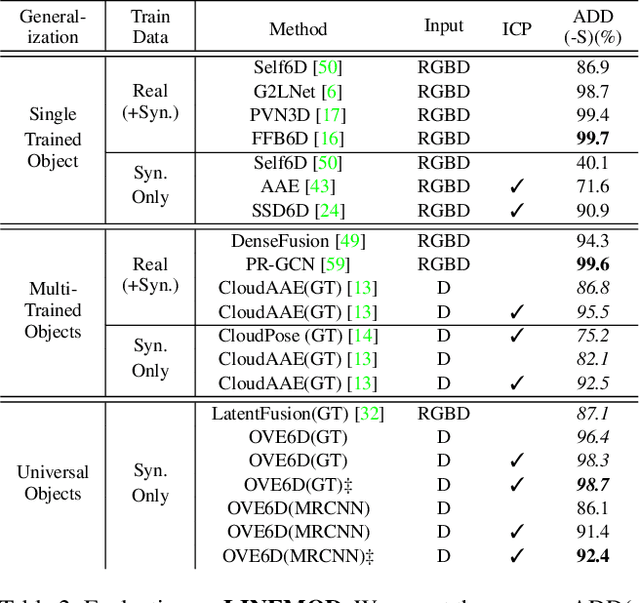
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data. The implementation and the pre-trained model will be made publicly available.
Patch-wise Contrastive Style Learning for Instagram Filter Removal
Apr 15, 2022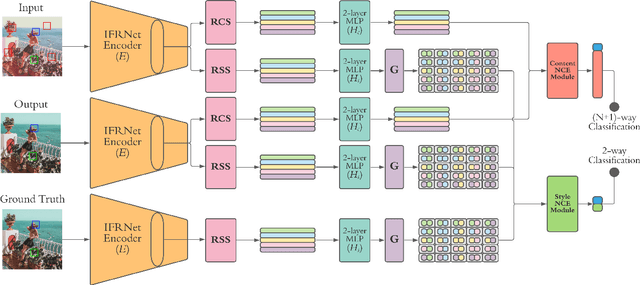
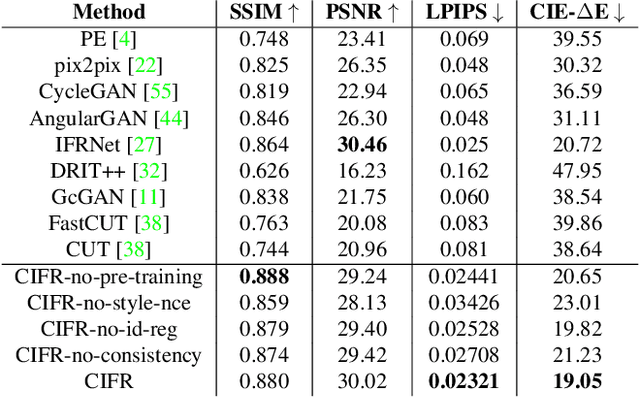
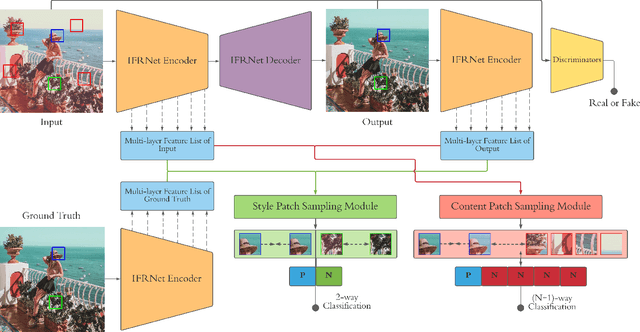
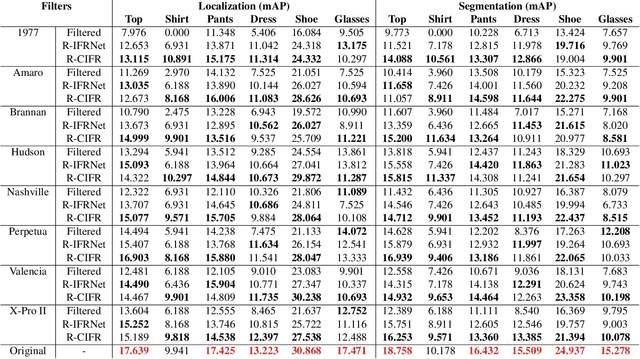
Image-level corruptions and perturbations degrade the performance of CNNs on different downstream vision tasks. Social media filters are one of the most common resources of various corruptions and perturbations for real-world visual analysis applications. The negative effects of these distractive factors can be alleviated by recovering the original images with their pure style for the inference of the downstream vision tasks. Assuming these filters substantially inject a piece of additional style information to the social media images, we can formulate the problem of recovering the original versions as a reverse style transfer problem. We introduce Contrastive Instagram Filter Removal Network (CIFR), which enhances this idea for Instagram filter removal by employing a novel multi-layer patch-wise contrastive style learning mechanism. Experiments show our proposed strategy produces better qualitative and quantitative results than the previous studies. Moreover, we present the results of our additional experiments for proposed architecture within different settings. Finally, we present the inference outputs and quantitative comparison of filtered and recovered images on localization and segmentation tasks to encourage the main motivation for this problem.
ORCNet: A context-based network to simultaneously segment the ocular region components
Apr 15, 2022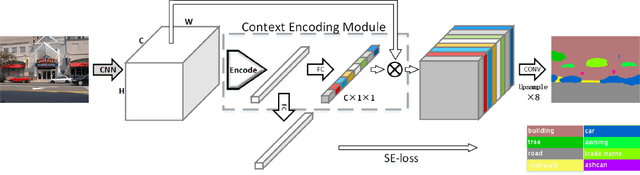
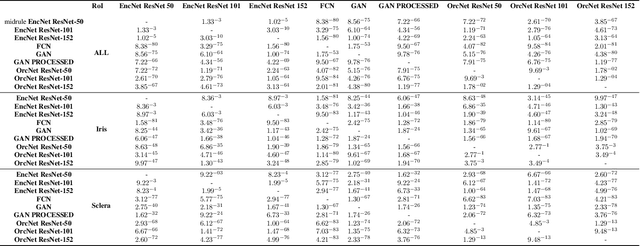
Accurate extraction of the Region of Interest is critical for successful ocular region-based biometrics. In this direction, we propose a new context-based segmentation approach, entitled Ocular Region Context Network (ORCNet), introducing a specific loss function, i.e., he Punish Context Loss (PC-Loss). The PC-Loss punishes the segmentation losses of a network by using a percentage difference value between the ground truth and the segmented masks. We obtain the percentage difference by taking into account Biederman's semantic relationship concepts, in which we use three contexts (semantic, spatial, and scale) to evaluate the relationships of the objects in an image. Our proposal achieved promising results in the evaluated scenarios: iris, sclera, and ALL (iris + sclera) segmentations, utperforming the literature baseline techniques. The ORCNet with ResNet-152 outperforms the best baseline (EncNet with ResNet-152) on average by 2.27%, 28.26% and 6.43% in terms of F-Score, Error Rate and Intersection Over Union, respectively. We also provide (for research purposes) 3,191 manually labeled masks for the MICHE-I database, as another contribution of our work.
Reverse-engineer the Distributional Structure of Infant Egocentric Views for Training Generalizable Image Classifiers
Jun 12, 2021
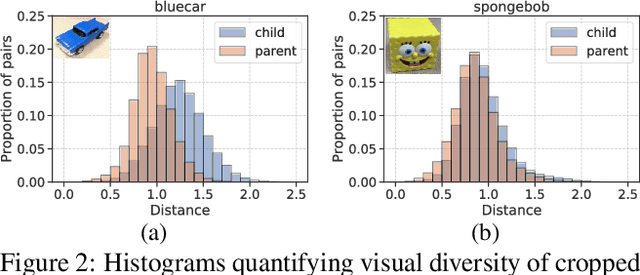
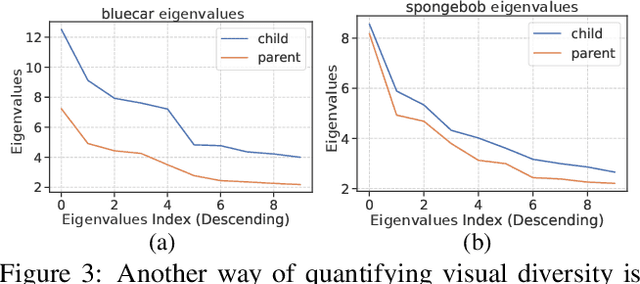
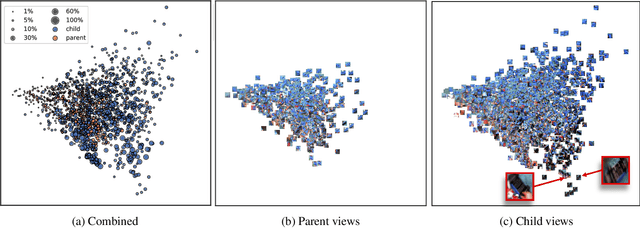
We analyze egocentric views of attended objects from infants. This paper shows 1) empirical evidence that children's egocentric views have more diverse distributions compared to adults' views, 2) we can computationally simulate the infants' distribution, and 3) the distribution is beneficial for training more generalized image classifiers not only for infant egocentric vision but for third-person computer vision.
Stochastic Image Denoising by Sampling from the Posterior Distribution
Jan 23, 2021
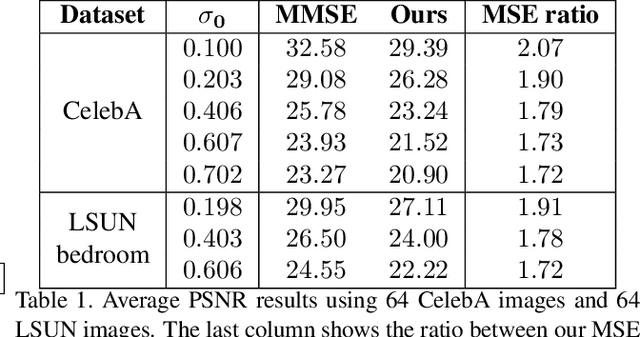


Image denoising is a well-known and well studied problem, commonly targeting a minimization of the mean squared error (MSE) between the outcome and the original image. Unfortunately, especially for severe noise levels, such Minimum MSE (MMSE) solutions may lead to blurry output images. In this work we propose a novel stochastic denoising approach that produces viable and high perceptual quality results, while maintaining a small MSE. Our method employs Langevin dynamics that relies on a repeated application of any given MMSE denoiser, obtaining the reconstructed image by effectively sampling from the posterior distribution. Due to its stochasticity, the proposed algorithm can produce a variety of high-quality outputs for a given noisy input, all shown to be legitimate denoising results. In addition, we present an extension of our algorithm for handling the inpainting problem, recovering missing pixels and removing noise from partially given noisy data.