 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FathomNet: A global underwater image training set for enabling artificial intelligence in the ocean
Sep 29, 2021

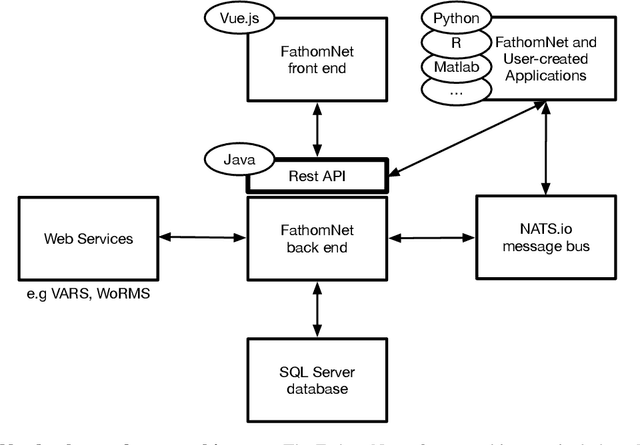
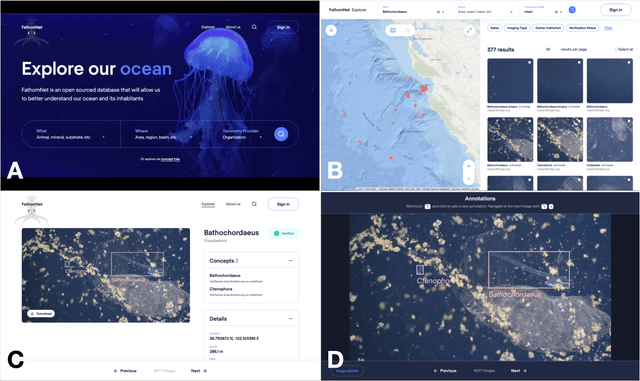
Ocean-going platforms are integrating high-resolution camera feeds for observation and navigation, producing a deluge of visual data. The volume and rate of this data collection can rapidly outpace researchers' abilities to process and analyze them. Recent advances in machine learning enable fast, sophisticated analysis of visual data, but have had limited success in the oceanographic world due to lack of dataset standardization, sparse annotation tools, and insufficient formatting and aggregation of existing, expertly curated imagery for use by data scientists. To address this need, we have built FathomNet, a public platform that makes use of existing (and future), expertly curated data. Initial efforts have leveraged MBARI's Video Annotation and Reference System and annotated deep sea video database, which has more than 7M annotations, 1M framegrabs, and 5k terms in the knowledgebase, with additional contributions by National Geographic Society (NGS) and NOAA's Office of Ocean Exploration and Research. FathomNet has over 100k localizations of 1k midwater and benthic classes, and contains iconic and non-iconic views of marine animals, underwater equipment, debris, etc. We will demonstrate how machine learning models trained on FathomNet data can be applied across different institutional video data, (e.g., NGS' Deep Sea Camera System and NOAA's ROV Deep Discoverer), and enable automated acquisition and tracking of midwater animals using MBARI's ROV MiniROV. As FathomNet continues to develop and incorporate more image data from other oceanographic community members, this effort will enable scientists, explorers, policymakers, storytellers, and the public to understand and care for our ocean.
Human-Centered Concept Explanations for Neural Networks
Feb 25, 2022
Understanding complex machine learning models such as deep neural networks with explanations is crucial in various applications. Many explanations stem from the model perspective, and may not necessarily effectively communicate why the model is making its predictions at the right level of abstraction. For example, providing importance weights to individual pixels in an image can only express which parts of that particular image are important to the model, but humans may prefer an explanation which explains the prediction by concept-based thinking. In this work, we review the emerging area of concept based explanations. We start by introducing concept explanations including the class of Concept Activation Vectors (CAV) which characterize concepts using vectors in appropriate spaces of neural activations, and discuss different properties of useful concepts, and approaches to measure the usefulness of concept vectors. We then discuss approaches to automatically extract concepts, and approaches to address some of their caveats. Finally, we discuss some case studies that showcase the utility of such concept-based explanations in synthetic settings and real world applications.
Unsupervised Manga Character Re-identification via Face-body and Spatial-temporal Associated Clustering
Apr 10, 2022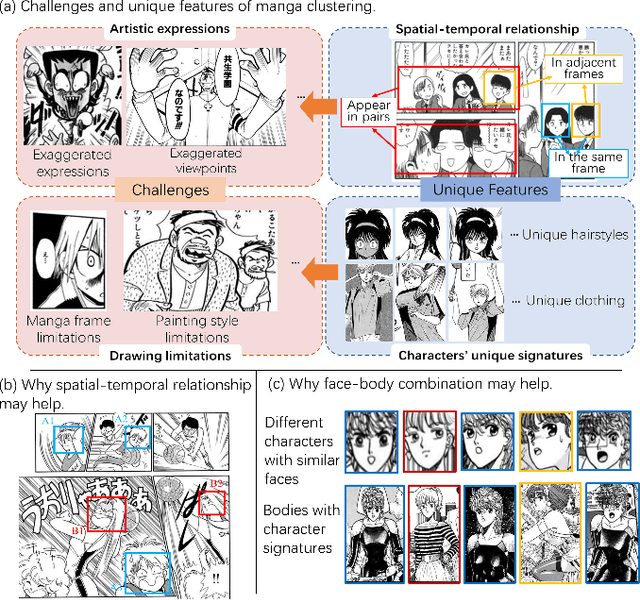

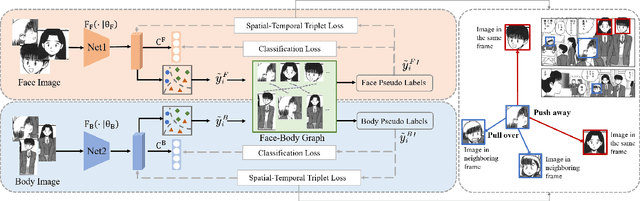

In the past few years, there has been a dramatic growth in e-manga (electronic Japanese-style comics). Faced with the booming demand for manga research and the large amount of unlabeled manga data, we raised a new task, called unsupervised manga character re-identification. However, the artistic expression and stylistic limitations of manga pose many challenges to the re-identification problem. Inspired by the idea that some content-related features may help clustering, we propose a Face-body and Spatial-temporal Associated Clustering method (FSAC). In the face-body combination module, a face-body graph is constructed to solve problems such as exaggeration and deformation in artistic creation by using the integrity of the image. In the spatial-temporal relationship correction module, we analyze the appearance features of characters and design a temporal-spatial-related triplet loss to fine-tune the clustering. Extensive experiments on a manga book dataset with 109 volumes validate the superiority of our method in unsupervised manga character re-identification.
2D LiDAR and Camera Fusion Using Motion Cues for Indoor Layout Estimation
Apr 24, 2022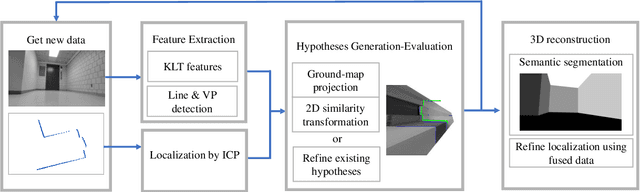
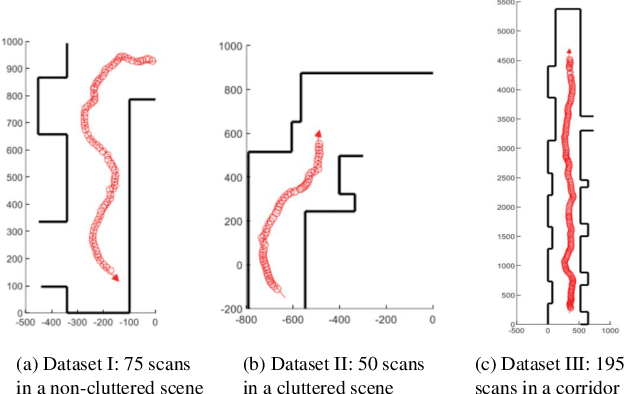


This paper presents a novel indoor layout estimation system based on the fusion of 2D LiDAR and intensity camera data. A ground robot explores an indoor space with a single floor and vertical walls, and collects a sequence of intensity images and 2D LiDAR datasets. The LiDAR provides accurate depth information, while the camera captures high-resolution data for semantic interpretation. The alignment of sensor outputs and image segmentation are computed jointly by aligning LiDAR points, as samples of the room contour, to ground-wall boundaries in the images. The alignment problem is decoupled into a top-down view projection and a 2D similarity transformation estimation, which can be solved according to the vertical vanishing point and motion of two sensors. The recursive random sample consensus algorithm is implemented to generate, evaluate and optimize multiple hypotheses with the sequential measurements. The system allows jointly analyzing the geometric interpretation from different sensors without offline calibration. The ambiguity in images for ground-wall boundary extraction is removed with the assistance of LiDAR observations, which improves the accuracy of semantic segmentation. The localization and mapping is refined using the fused data, which enables the system to work reliably in scenes with low texture or low geometric features.
Engineering deep learning methods on automatic detection of damage in infrastructure due to extreme events
May 01, 2022
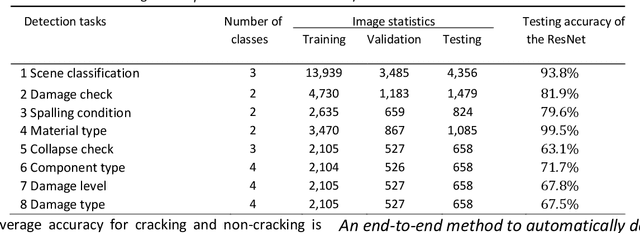

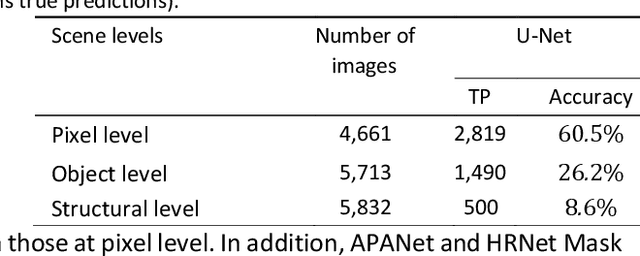
This paper presents a few comprehensive experimental studies for automated Structural Damage Detection (SDD) in extreme events using deep learning methods for processing 2D images. In the first study, a 152-layer Residual network (ResNet) is utilized to classify multiple classes in eight SDD tasks, which include identification of scene levels, damage levels, material types, etc. The proposed ResNet achieved high accuracy for each task while the positions of the damage are not identifiable. In the second study, the existing ResNet and a segmentation network (U-Net) are combined into a new pipeline, cascaded networks, for categorizing and locating structural damage. The results show that the accuracy of damage detection is significantly improved compared to only using a segmentation network. In the third and fourth studies, end-to-end networks are developed and tested as a new solution to directly detect cracks and spalling in the image collections of recent large earthquakes. One of the proposed networks can achieve an accuracy above 67.6% for all tested images at various scales and resolutions, and shows its robustness for these human-free detection tasks. As a preliminary field study, we applied the proposed method to detect damage in a concrete structure that was tested to study its progressive collapse performance. The experiments indicate that these solutions for automatic detection of structural damage using deep learning methods are feasible and promising. The training datasets and codes will be made available for the public upon the publication of this paper.
Manipulating Medical Image Translation with Manifold Disentanglement
Nov 27, 2020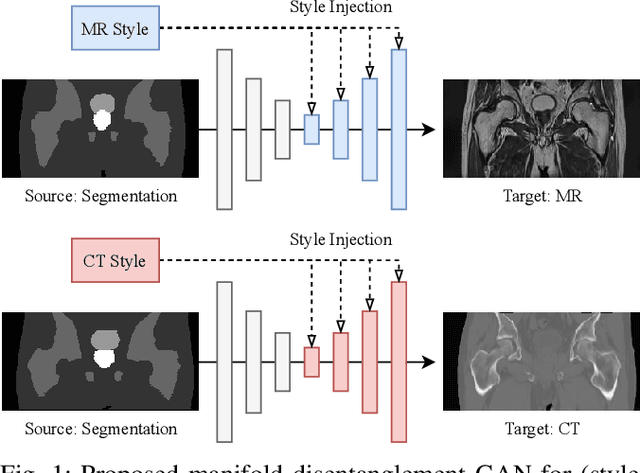
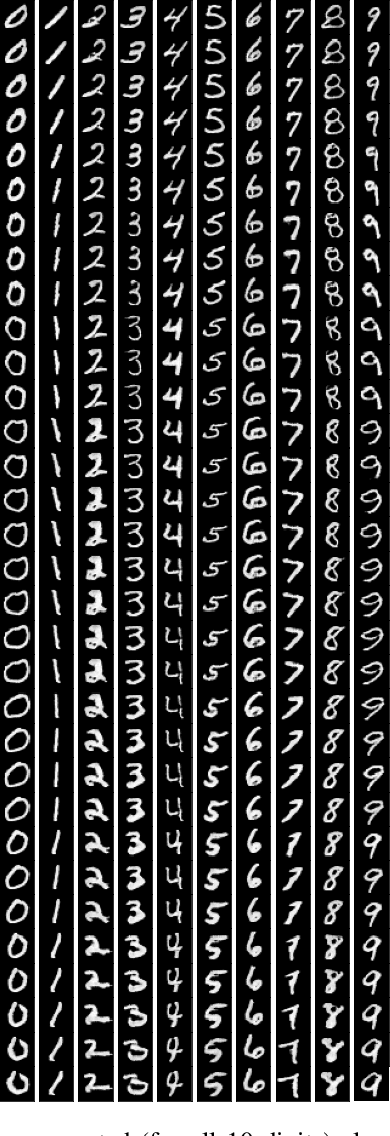
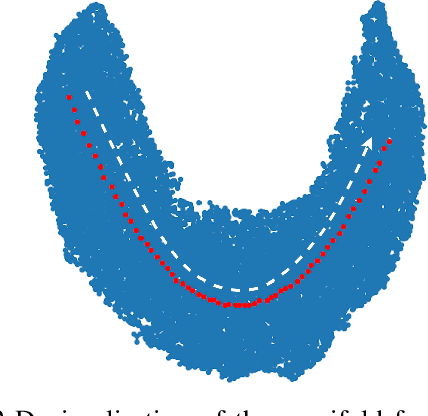

Medical image translation (e.g. CT to MR) is a challenging task as it requires I) faithful translation of domain-invariant features (e.g. shape information of anatomical structures) and II) realistic synthesis of target-domain features (e.g. tissue appearance in MR). In this work, we propose Manifold Disentanglement Generative Adversarial Network (MDGAN), a novel image translation framework that explicitly models these two types of features. It employs a fully convolutional generator to model domain-invariant features, and it uses style codes to separately model target-domain features as a manifold. This design aims to explicitly disentangle domain-invariant features and domain-specific features while gaining individual control of both. The image translation process is formulated as a stylisation task, where the input is "stylised" (translated) into diverse target-domain images based on style codes sampled from the learnt manifold. We test MDGAN for multi-modal medical image translation, where we create two domain-specific manifold clusters on the manifold to translate segmentation maps into pseudo-CT and pseudo-MR images, respectively. We show that by traversing a path across the MR manifold cluster, the target output can be manipulated while still retaining the shape information from the input.
Overparametrization of HyperNetworks at Fixed FLOP-Count Enables Fast Neural Image Enhancement
May 18, 2021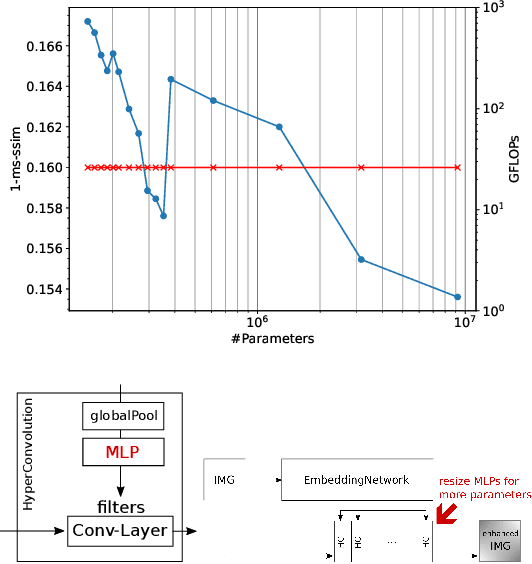
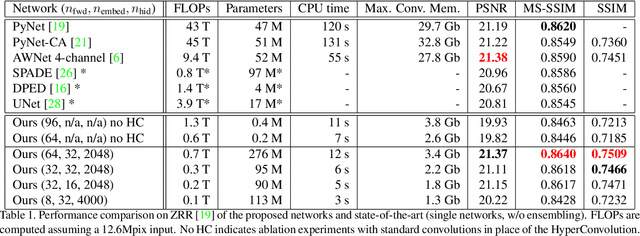
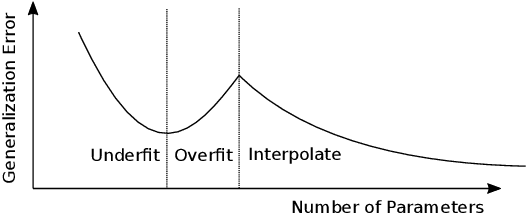

Deep convolutional neural networks can enhance images taken with small mobile camera sensors and excel at tasks like demoisaicing, denoising and super-resolution. However, for practical use on mobile devices these networks often require too many FLOPs and reducing the FLOPs of a convolution layer, also reduces its parameter count. This is problematic in view of the recent finding that heavily over-parameterized neural networks are often the ones that generalize best. In this paper we propose to use HyperNetworks to break the fixed ratio of FLOPs to parameters of standard convolutions. This allows us to exceed previous state-of-the-art architectures in SSIM and MS-SSIM on the Zurich RAW- to-DSLR (ZRR) data-set at > 10x reduced FLOP-count. On ZRR we further observe generalization curves consistent with 'double-descent' behavior at fixed FLOP-count, in the large image limit. Finally we demonstrate the same technique can be applied to an existing network (VDN) to reduce its computational cost while maintaining fidelity on the Smartphone Image Denoising Dataset (SIDD). Code for key functions is given in the appendix.
Image Captioning with Context-Aware Auxiliary Guidance
Dec 10, 2020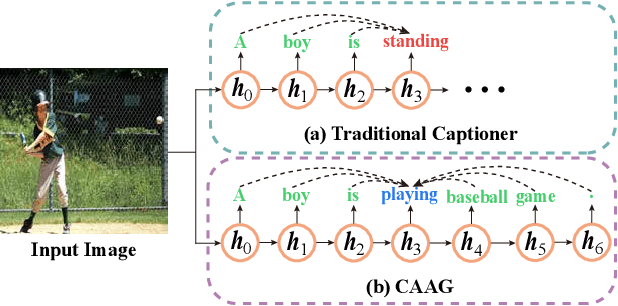
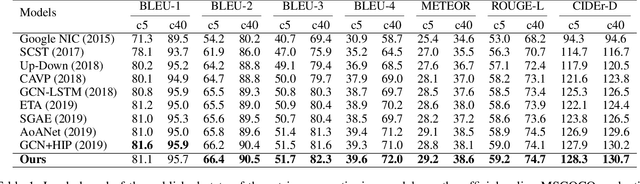
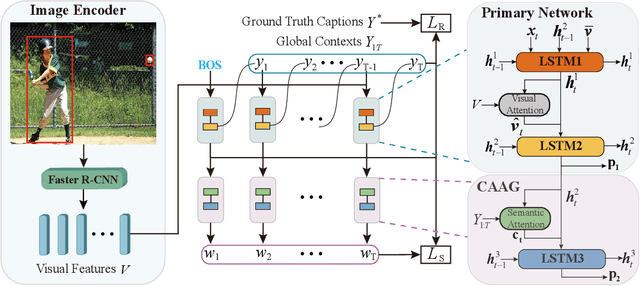
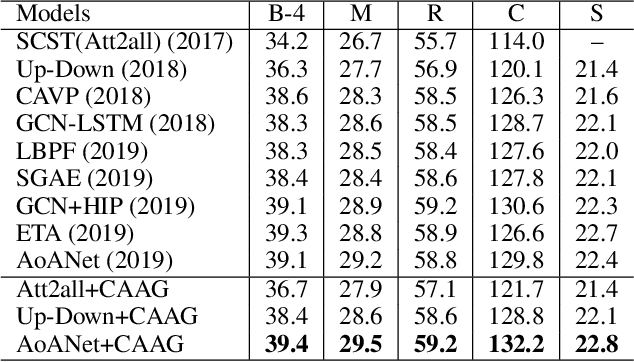
Image captioning is a challenging computer vision task, which aims to generate a natural language description of an image. Most recent researches follow the encoder-decoder framework which depends heavily on the previous generated words for the current prediction. Such methods can not effectively take advantage of the future predicted information to learn complete semantics. In this paper, we propose Context-Aware Auxiliary Guidance (CAAG) mechanism that can guide the captioning model to perceive global contexts. Upon the captioning model, CAAG performs semantic attention that selectively concentrates on useful information of the global predictions to reproduce the current generation. To validate the adaptability of the method, we apply CAAG to three popular captioners and our proposal achieves competitive performance on the challenging Microsoft COCO image captioning benchmark, e.g. 132.2 CIDEr-D score on Karpathy split and 130.7 CIDEr-D (c40) score on official online evaluation server.
Malaria detection in Segmented Blood Cell using Convolutional Neural Networks and Canny Edge Detection
Feb 21, 2022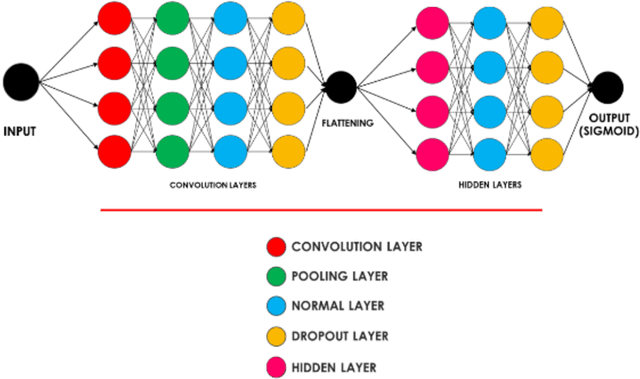

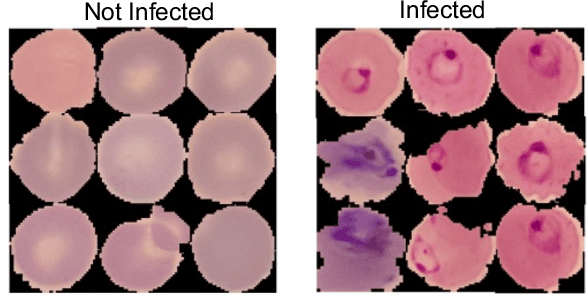
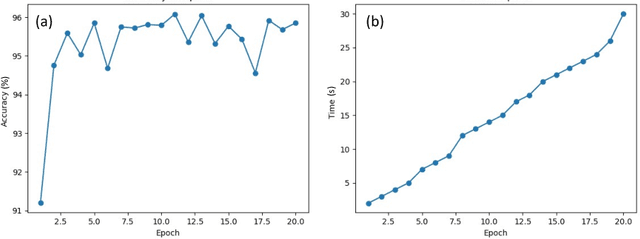
We apply convolutional neural networks to identify between malaria infected and non-infected segmented cells from the thin blood smear slide images. We optimize our model to find over 95% accuracy in malaria cell detection. We also apply Canny image processing to reduce training file size while maintaining comparable accuracy (~ 94%).
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 04, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work will be available at https://github.com/JUGGHM/PENet_ICRA2021.