 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Length-Controllable Image Captioning
Jul 19, 2020
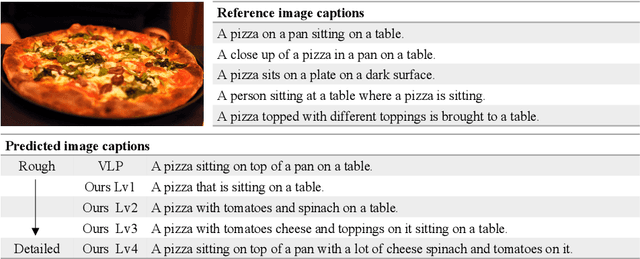
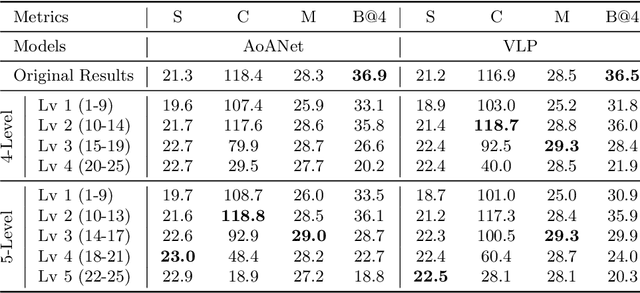
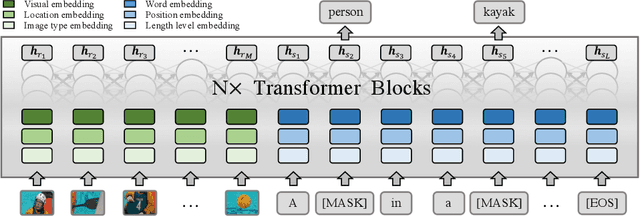

The last decade has witnessed remarkable progress in the image captioning task; however, most existing methods cannot control their captions, \emph{e.g.}, choosing to describe the image either roughly or in detail. In this paper, we propose to use a simple length level embedding to endow them with this ability. Moreover, due to their autoregressive nature, the computational complexity of existing models increases linearly as the length of the generated captions grows. Thus, we further devise a non-autoregressive image captioning approach that can generate captions in a length-irrelevant complexity. We verify the merit of the proposed length level embedding on three models: two state-of-the-art (SOTA) autoregressive models with different types of decoder, as well as our proposed non-autoregressive model, to show its generalization ability. In the experiments, our length-controllable image captioning models not only achieve SOTA performance on the challenging MS COCO dataset but also generate length-controllable and diverse image captions. Specifically, our non-autoregressive model outperforms the autoregressive baselines in terms of controllability and diversity, and also significantly improves the decoding efficiency for long captions. Our code and models are released at \textcolor{magenta}{\texttt{https://github.com/bearcatt/LaBERT}}.
Formulating Robustness Against Unforeseen Attacks
Apr 28, 2022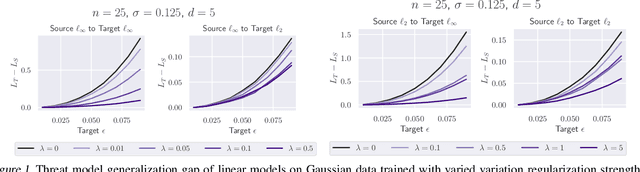
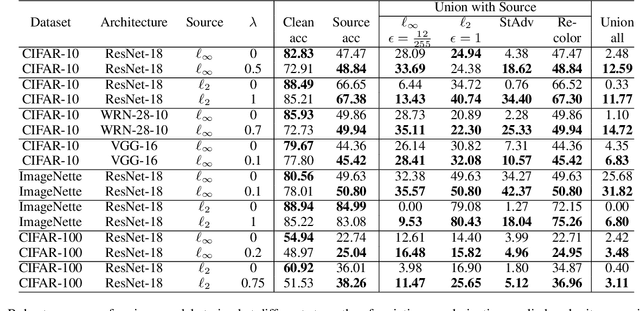
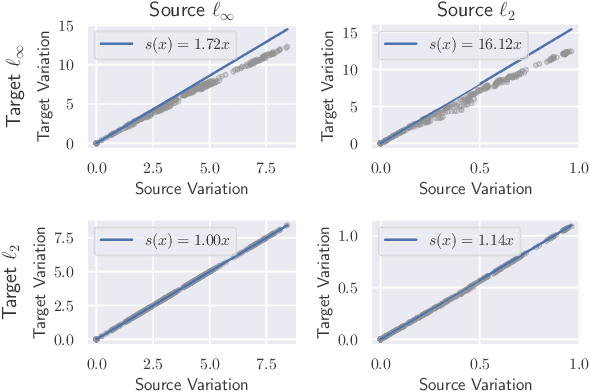
Existing defenses against adversarial examples such as adversarial training typically assume that the adversary will conform to a specific or known threat model, such as $\ell_p$ perturbations within a fixed budget. In this paper, we focus on the scenario where there is a mismatch in the threat model assumed by the defense during training, and the actual capabilities of the adversary at test time. We ask the question: if the learner trains against a specific "source" threat model, when can we expect robustness to generalize to a stronger unknown "target" threat model during test-time? Our key contribution is to formally define the problem of learning and generalization with an unforeseen adversary, which helps us reason about the increase in adversarial risk from the conventional perspective of a known adversary. Applying our framework, we derive a generalization bound which relates the generalization gap between source and target threat models to variation of the feature extractor, which measures the expected maximum difference between extracted features across a given threat model. Based on our generalization bound, we propose adversarial training with variation regularization (AT-VR) which reduces variation of the feature extractor across the source threat model during training. We empirically demonstrate that AT-VR can lead to improved generalization to unforeseen attacks during test-time compared to standard adversarial training on Gaussian and image datasets.
Satellite Image Semantic Segmentation
Oct 12, 2021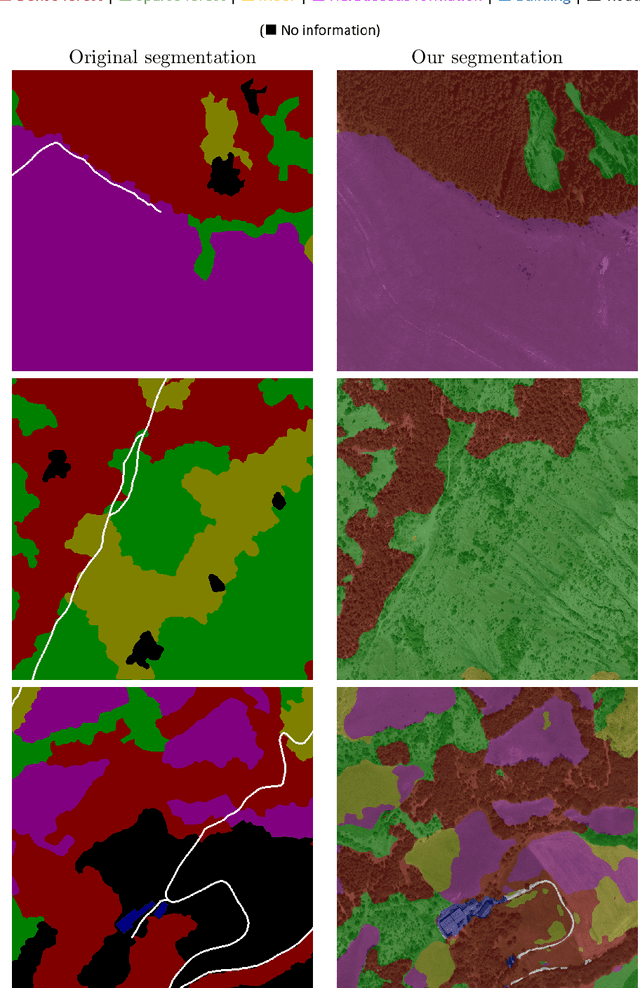
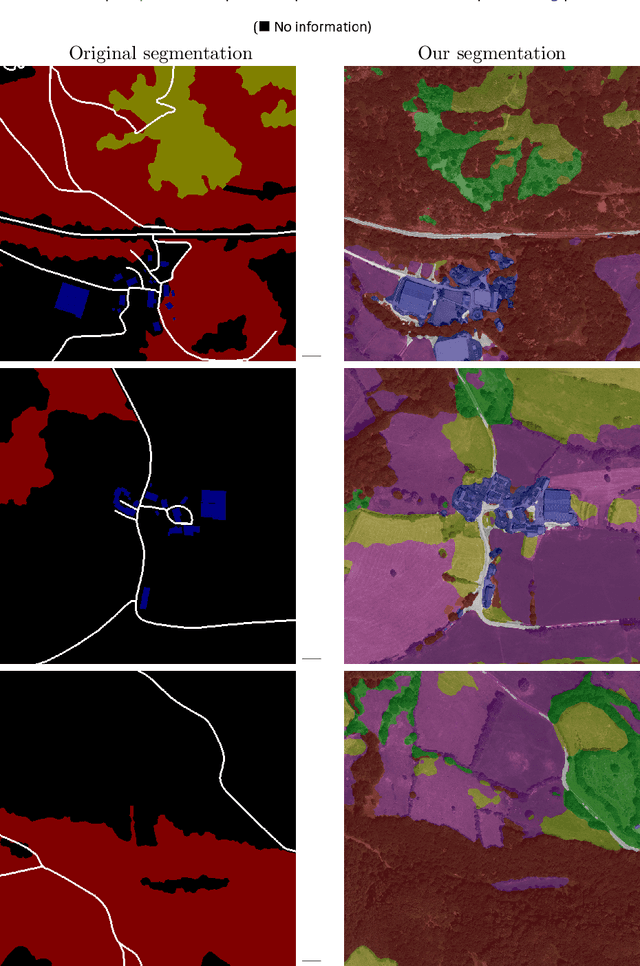

In this paper, we propose a method for the automatic semantic segmentation of satellite images into six classes (sparse forest, dense forest, moor, herbaceous formation, building, and road). We rely on Swin Transformer architecture and build the dataset from IGN open data. We report quantitative and qualitative segmentation results on this dataset and discuss strengths and limitations. The dataset and the trained model are made publicly available.
AFINet: Attentive Feature Integration Networks for Image Classification
May 10, 2021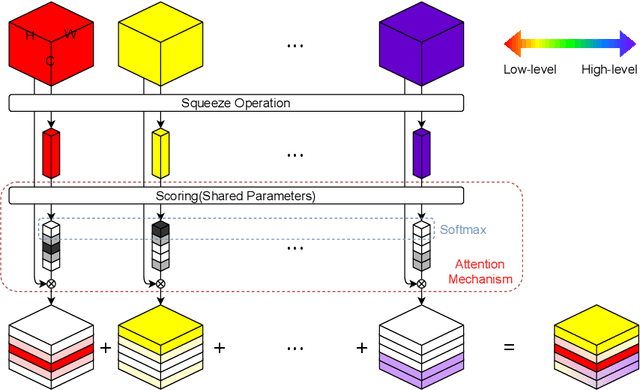
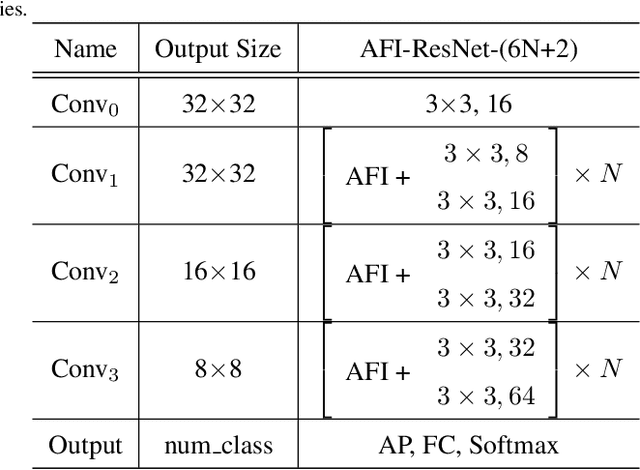

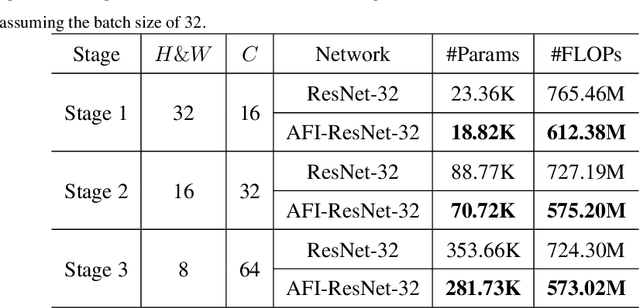
Convolutional Neural Networks (CNNs) have achieved tremendous success in a number of learning tasks including image classification. Recent advanced models in CNNs, such as ResNets, mainly focus on the skip connection to avoid gradient vanishing. DenseNet designs suggest creating additional bypasses to transfer features as an alternative strategy in network design. In this paper, we design Attentive Feature Integration (AFI) modules, which are widely applicable to most recent network architectures, leading to new architectures named AFI-Nets. AFI-Nets explicitly model the correlations among different levels of features and selectively transfer features with a little overhead.AFI-ResNet-152 obtains a 1.24% relative improvement on the ImageNet dataset while decreases the FLOPs by about 10% and the number of parameters by about 9.2% compared to ResNet-152.
Revealing unforeseen diagnostic image features with deep learning by detecting cardiovascular diseases from apical four-chamber ultrasounds
Oct 25, 2021
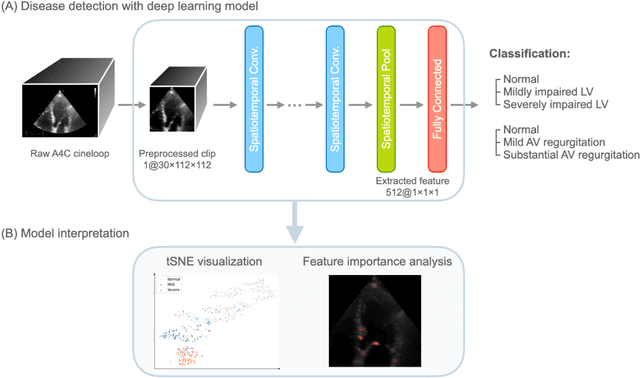
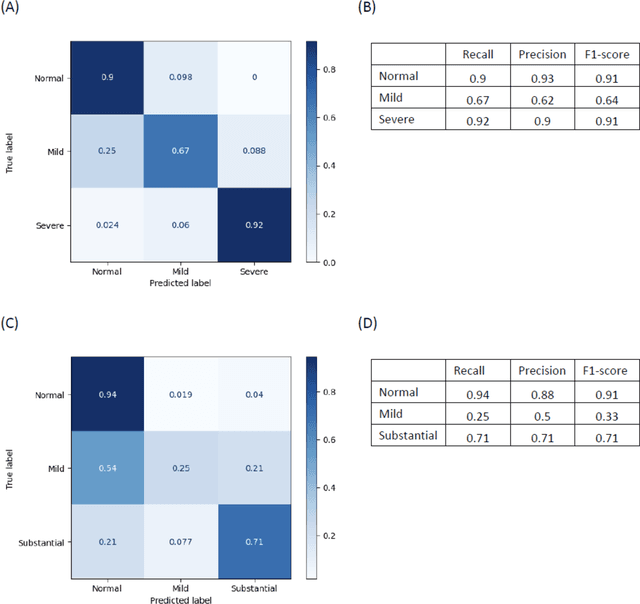
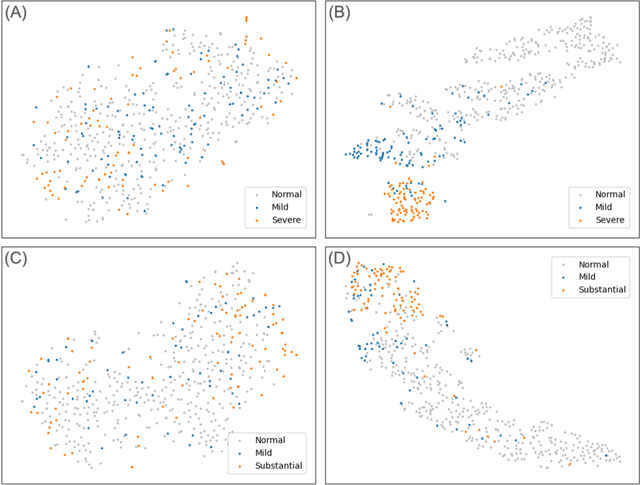
Background. With the rise of highly portable, wireless, and low-cost ultrasound devices and automatic ultrasound acquisition techniques, an automated interpretation method requiring only a limited set of views as input could make preliminary cardiovascular disease diagnoses more accessible. In this study, we developed a deep learning (DL) method for automated detection of impaired left ventricular (LV) function and aortic valve (AV) regurgitation from apical four-chamber (A4C) ultrasound cineloops and investigated which anatomical structures or temporal frames provided the most relevant information for the DL model to enable disease classification. Methods and Results. A4C ultrasounds were extracted from 3,554 echocardiograms of patients with either impaired LV function (n=928), AV regurgitation (n=738), or no significant abnormalities (n=1,888). Two convolutional neural networks (CNNs) were trained separately to classify the respective disease cases against normal cases. The overall classification accuracy of the impaired LV function detection model was 86%, and that of the AV regurgitation detection model was 83%. Feature importance analyses demonstrated that the LV myocardium and mitral valve were important for detecting impaired LV function, while the tip of the mitral valve anterior leaflet, during opening, was considered important for detecting AV regurgitation. Conclusion. The proposed method demonstrated the feasibility of a 3D CNN approach in detection of impaired LV function and AV regurgitation using A4C ultrasound cineloops. The current research shows that DL methods can exploit large training data to detect diseases in a different way than conventionally agreed upon methods, and potentially reveal unforeseen diagnostic image features.
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022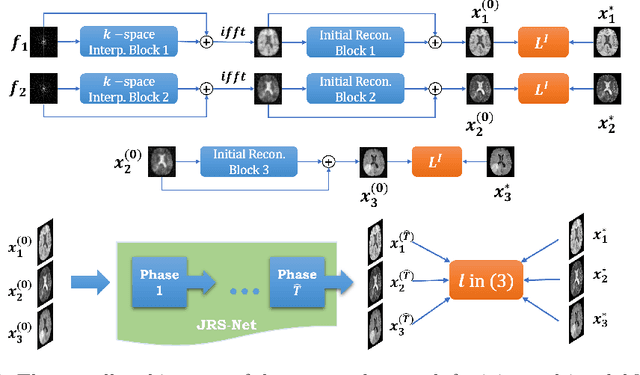

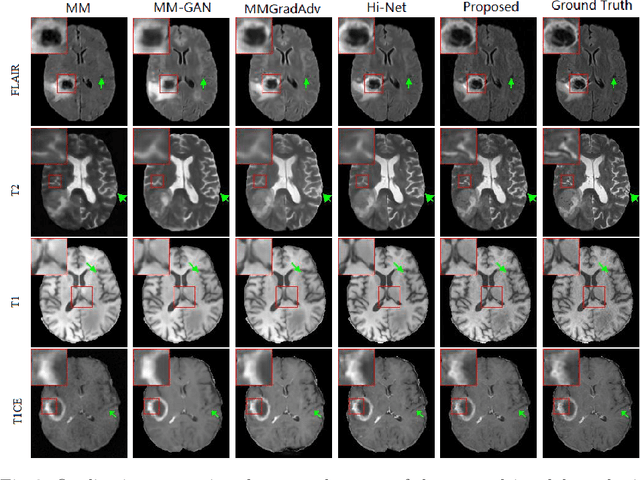
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.
Noise2Sim -- Similarity-based Self-Learning for Image Denoising
Nov 11, 2020


The key idea behind denoising methods is to perform a mean/averaging operation, either locally or non-locally. An observation on classic denoising methods is that non-local mean (NLM) outcomes are typically superior to locally denoised results. Despite achieving the best performance in image denoising, the supervised deep denoising methods require paired noise-clean data which are often unavailable. To address this challenge, Noise2Noise methods are based on the fact that paired noise-clean images can be replaced by paired noise-noise images which are easier to collect. However, in many scenarios the collection of paired noise-noise images are still impractical. To bypass labeled images, Noise2Void methods predict masked pixels from their surroundings in a single noisy image only. It is pitiful that neither Noise2Noise nor Noise2Void methods utilize self-similarities in an image as NLM methods do, while self-similarities/symmetries play a critical role in modern sciences. Here we propose Noise2Sim, an NLM-inspired self-learning method for image denoising. Specifically, Noise2Sim leverages self-similarities of image patches and learns to map between the center pixels of similar patches for self-consistent image denoising. Our statistical analysis shows that Noise2Sim tends to be equivalent to Noise2Noise under mild conditions. To accelerate the process of finding similar image patches, we design an efficient two-step procedure to provide data for Noise2Sim training, which can be iteratively conducted if needed. Extensive experiments demonstrate the superiority of Noise2Sim over Noise2Noise and Noise2Void on common benchmark datasets.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 04, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work will be available at https://github.com/JUGGHM/PENet_ICRA2021.
Context-Aware Layout to Image Generation with Enhanced Object Appearance
Mar 22, 2021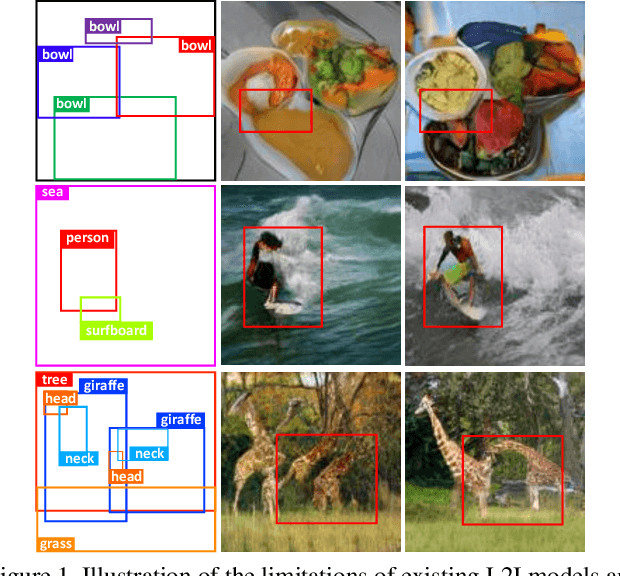
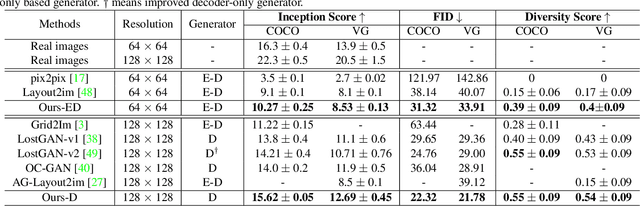
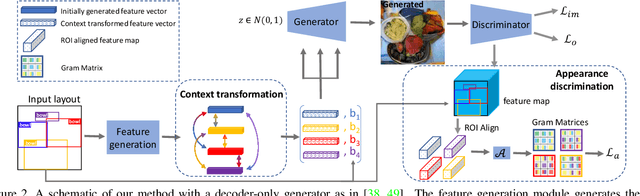

A layout to image (L2I) generation model aims to generate a complicated image containing multiple objects (things) against natural background (stuff), conditioned on a given layout. Built upon the recent advances in generative adversarial networks (GANs), existing L2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) the object-to-object as well as object-to-stuff relations are often broken and (2) each object's appearance is typically distorted lacking the key defining characteristics associated with the object class. We argue that these are caused by the lack of context-aware object and stuff feature encoding in their generators, and location-sensitive appearance representation in their discriminators. To address these limitations, two new modules are proposed in this work. First, a context-aware feature transformation module is introduced in the generator to ensure that the generated feature encoding of either object or stuff is aware of other co-existing objects/stuff in the scene. Second, instead of feeding location-insensitive image features to the discriminator, we use the Gram matrix computed from the feature maps of the generated object images to preserve location-sensitive information, resulting in much enhanced object appearance. Extensive experiments show that the proposed method achieves state-of-the-art performance on the COCO-Thing-Stuff and Visual Genome benchmarks.
An AutoML-based Approach to Multimodal Image Sentiment Analysis
Feb 16, 2021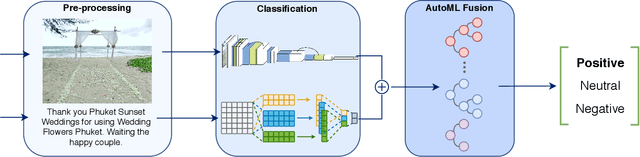

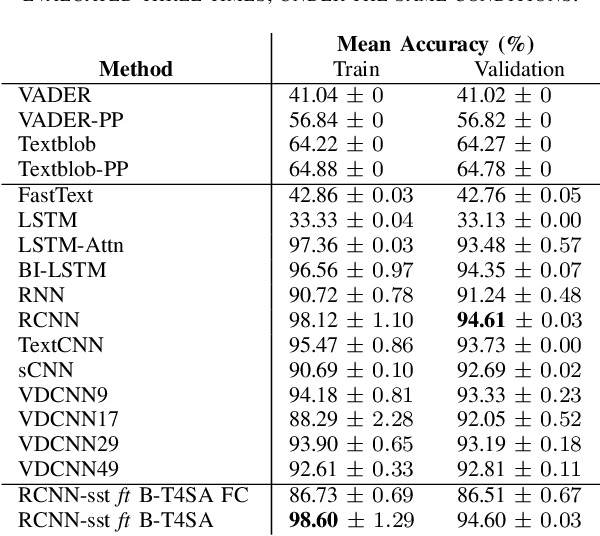
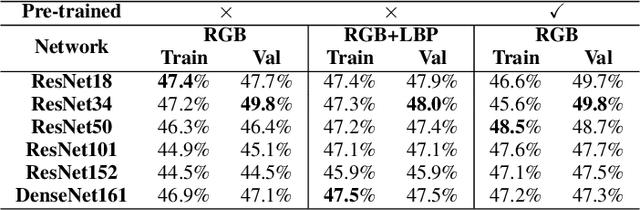
Sentiment analysis is a research topic focused on analysing data to extract information related to the sentiment that it causes. Applications of sentiment analysis are wide, ranging from recommendation systems, and marketing to customer satisfaction. Recent approaches evaluate textual content using Machine Learning techniques that are trained over large corpora. However, as social media grown, other data types emerged in large quantities, such as images. Sentiment analysis in images has shown to be a valuable complement to textual data since it enables the inference of the underlying message polarity by creating context and connections. Multimodal sentiment analysis approaches intend to leverage information of both textual and image content to perform an evaluation. Despite recent advances, current solutions still flounder in combining both image and textual information to classify social media data, mainly due to subjectivity, inter-class homogeneity and fusion data differences. In this paper, we propose a method that combines both textual and image individual sentiment analysis into a final fused classification based on AutoML, that performs a random search to find the best model. Our method achieved state-of-the-art performance in the B-T4SA dataset, with 95.19% accuracy.