 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revealing unforeseen diagnostic image features with deep learning by detecting cardiovascular diseases from apical four-chamber ultrasounds
Oct 25, 2021
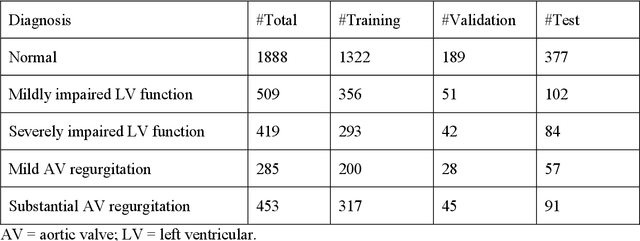
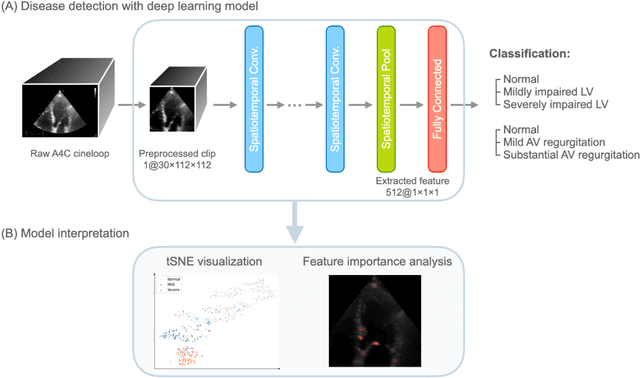
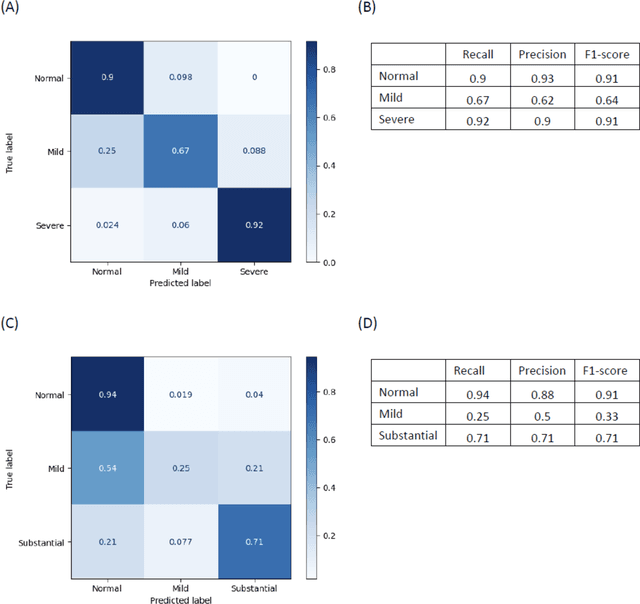
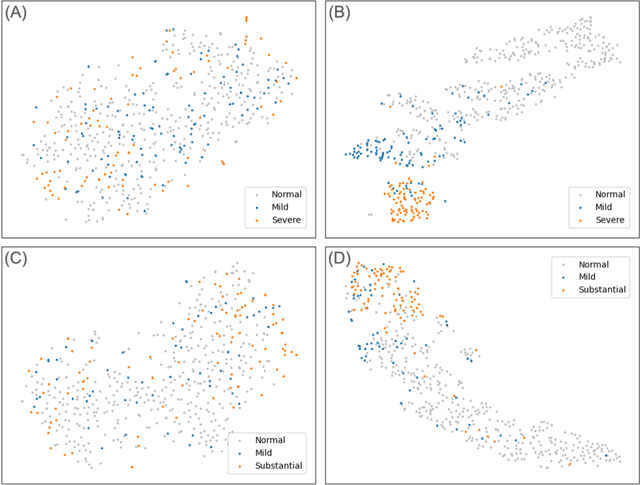
Background. With the rise of highly portable, wireless, and low-cost ultrasound devices and automatic ultrasound acquisition techniques, an automated interpretation method requiring only a limited set of views as input could make preliminary cardiovascular disease diagnoses more accessible. In this study, we developed a deep learning (DL) method for automated detection of impaired left ventricular (LV) function and aortic valve (AV) regurgitation from apical four-chamber (A4C) ultrasound cineloops and investigated which anatomical structures or temporal frames provided the most relevant information for the DL model to enable disease classification. Methods and Results. A4C ultrasounds were extracted from 3,554 echocardiograms of patients with either impaired LV function (n=928), AV regurgitation (n=738), or no significant abnormalities (n=1,888). Two convolutional neural networks (CNNs) were trained separately to classify the respective disease cases against normal cases. The overall classification accuracy of the impaired LV function detection model was 86%, and that of the AV regurgitation detection model was 83%. Feature importance analyses demonstrated that the LV myocardium and mitral valve were important for detecting impaired LV function, while the tip of the mitral valve anterior leaflet, during opening, was considered important for detecting AV regurgitation. Conclusion. The proposed method demonstrated the feasibility of a 3D CNN approach in detection of impaired LV function and AV regurgitation using A4C ultrasound cineloops. The current research shows that DL methods can exploit large training data to detect diseases in a different way than conventionally agreed upon methods, and potentially reveal unforeseen diagnostic image features.
Temporally and Spatially variant-resolution illumination patterns in computational ghost imaging
May 05, 2022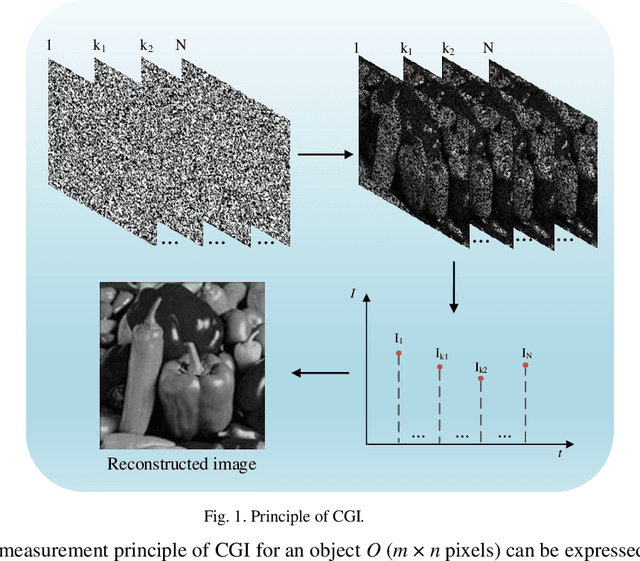
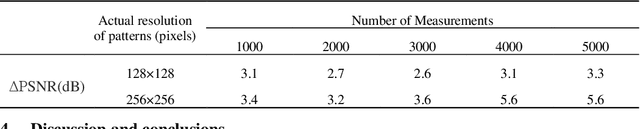
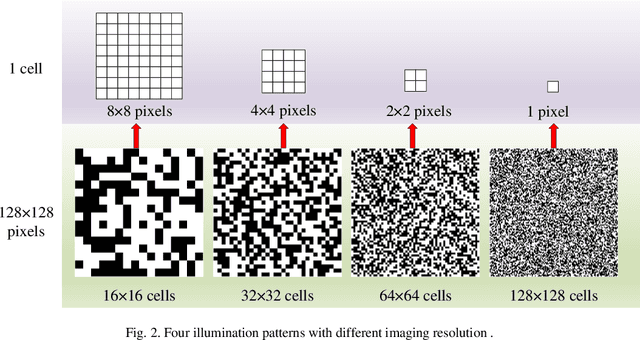
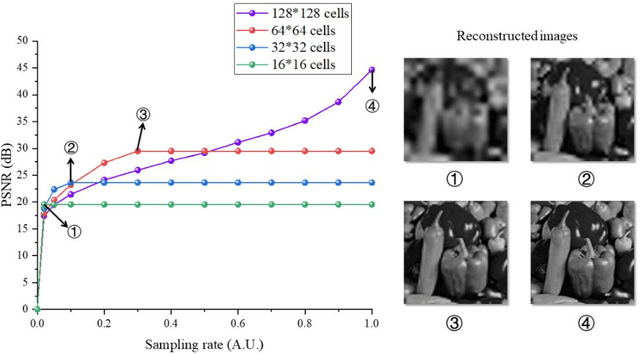
Conventional computational ghost imaging (CGI) uses light carrying a sequence of patterns with uniform-resolution to illuminate the object, then performs correlation calculation based on the light intensity value reflected by the target and the preset patterns to obtain object image. It requires a large number of measurements to obtain high-quality images, especially if high-resolution images are to be obtained. To solve this problem, we developed temporally variable-resolution illumination patterns, replacing the conventional uniform-resolution illumination patterns with a sequence of patterns of different imaging resolutions. In addition, we propose to combine temporally variable-resolution illumination patterns and spatially variable-resolution structure to develop temporally and spatially variable-resolution (TSV) illumination patterns, which not only improve the imaging quality of the region of interest (ROI) but also improve the robustness to noise. The methods using proposed illumination patterns are verified by simulations and experiments compared with CGI. For the same number of measurements, the method using temporally variable-resolution illumination patterns has better imaging quality than CGI, but it is less robust to noise. The method using TSV illumination patterns has better imaging quality in ROI than the method using temporally variable-resolution illumination patterns and CGI under the same number of measurements. We also experimentally verify that the method using TSV patterns have better imaging performance when applied to higher resolution imaging. The proposed methods are expected to solve the current computational ghost imaging that is difficult to achieve high-resolution and high-quality imaging.
Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization
Apr 20, 2022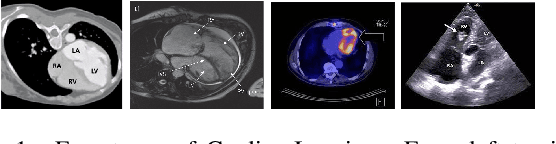

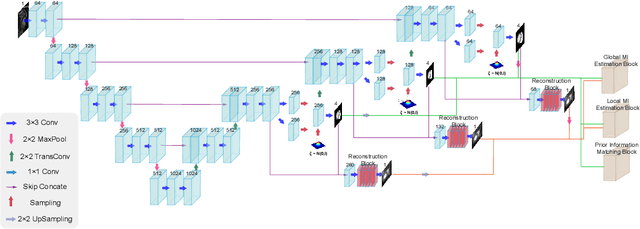
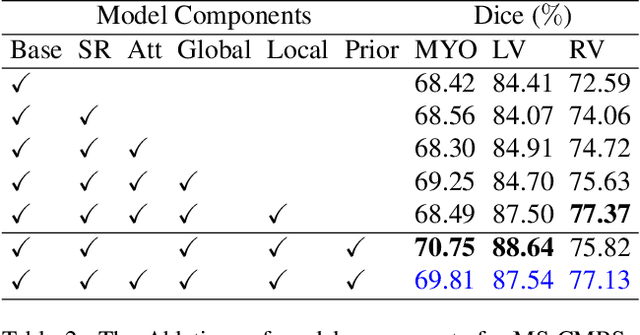
Unsupervised domain adaptation approaches have recently succeeded in various medical image segmentation tasks. The reported works often tackle the domain shift problem by aligning the domain-invariant features and minimizing the domain-specific discrepancies. That strategy works well when the difference between a specific domain and between different domains is slight. However, the generalization ability of these models on diverse imaging modalities remains a significant challenge. This paper introduces UDA-VAE++, an unsupervised domain adaptation framework for cardiac segmentation with a compact loss function lower bound. To estimate this new lower bound, we develop a novel Structure Mutual Information Estimation (SMIE) block with a global estimator, a local estimator, and a prior information matching estimator to maximize the mutual information between the reconstruction and segmentation tasks. Specifically, we design a novel sequential reparameterization scheme that enables information flow and variance correction from the low-resolution latent space to the high-resolution latent space. Comprehensive experiments on benchmark cardiac segmentation datasets demonstrate that our model outperforms previous state-of-the-art qualitatively and quantitatively. The code is available at https://github.com/LOUEY233/Toward-Mutual-Information}{https://github.com/LOUEY233/Toward-Mutual-Information
Image Classification with Classic and Deep Learning Techniques
May 11, 2021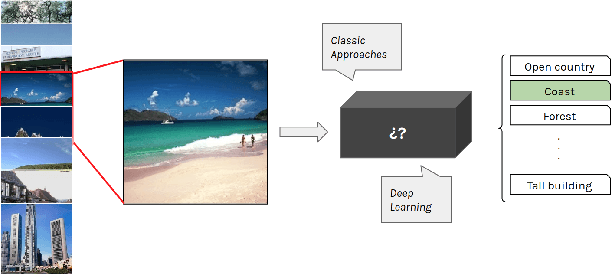
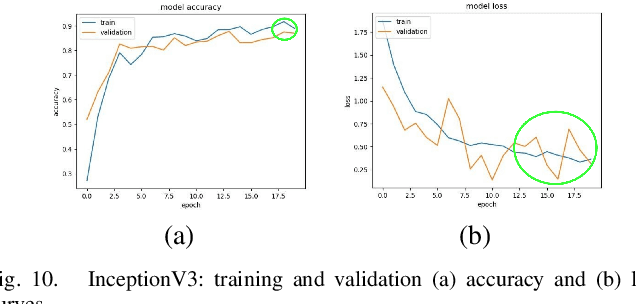
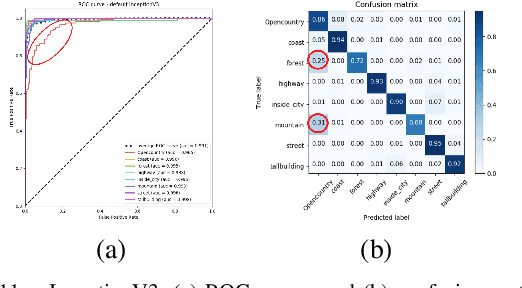
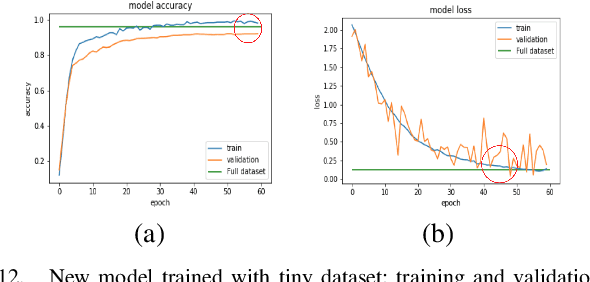
To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning techniques. Specifically, we study the performance of a Bag of Visual Words classifier using Support Vector Machines, a Multilayer Perceptron, an existing architecture named InceptionV3 and our own CNN, TinyNet, designed from scratch. We evaluate each of the cases in terms of accuracy and loss, and we obtain results that vary between 0.6 and 0.96 depending on the model and configuration used.
Hyper-Convolution Networks for Biomedical Image Segmentation
May 21, 2021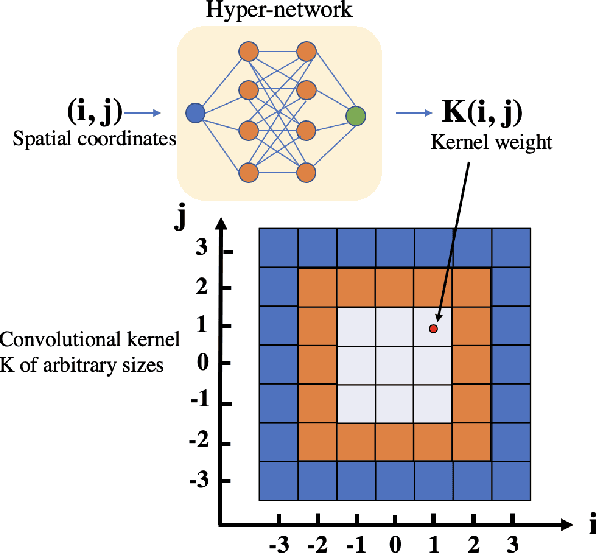
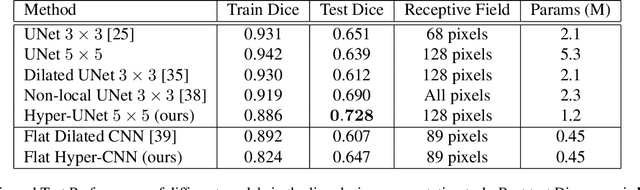
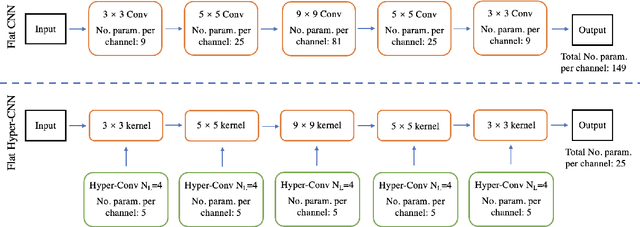
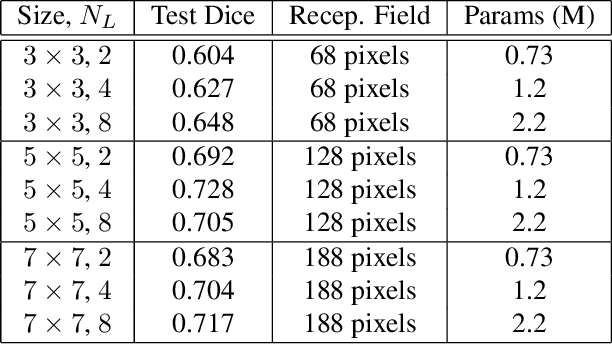
The convolution operation is a central building block of neural network architectures widely used in computer vision. The size of the convolution kernels determines both the expressiveness of convolutional neural networks (CNN), as well as the number of learnable parameters. Increasing the network capacity to capture rich pixel relationships requires increasing the number of learnable parameters, often leading to overfitting and/or lack of robustness. In this paper, we propose a powerful novel building block, the hyper-convolution, which implicitly represents the convolution kernel as a function of kernel coordinates. Hyper-convolutions enable decoupling the kernel size, and hence its receptive field, from the number of learnable parameters. In our experiments, focused on challenging biomedical image segmentation tasks, we demonstrate that replacing regular convolutions with hyper-convolutions leads to more efficient architectures that achieve improved accuracy. Our analysis also shows that learned hyper-convolutions are naturally regularized, which can offer better generalization performance. We believe that hyper-convolutions can be a powerful building block in future neural network architectures solving computer vision tasks.
PaddleSeg: A High-Efficient Development Toolkit for Image Segmentation
Jan 15, 2021
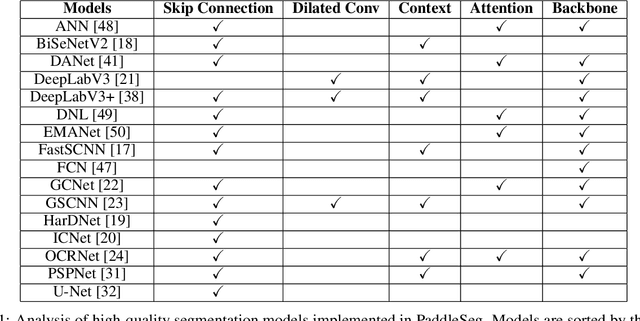

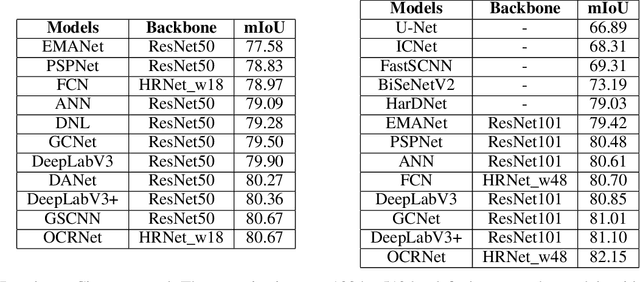
Image Segmentation plays an essential role in computer vision and image processing with various applications from medical diagnosis to autonomous car driving. A lot of segmentation algorithms have been proposed for addressing specific problems. In recent years, the success of deep learning techniques has tremendously influenced a wide range of computer vision areas, and the modern approaches of image segmentation based on deep learning are becoming prevalent. In this article, we introduce a high-efficient development toolkit for image segmentation, named PaddleSeg. The toolkit aims to help both developers and researchers in the whole process of designing segmentation models, training models, optimizing performance and inference speed, and deploying models. Currently, PaddleSeg supports around 20 popular segmentation models and more than 50 pre-trained models from real-time and high-accuracy levels. With modular components and backbone networks, users can easily build over one hundred models for different requirements. Furthermore, we provide comprehensive benchmarks and evaluations to show that these segmentation algorithms trained on our toolkit have more competitive accuracy. Also, we provide various real industrial applications and practical cases based on PaddleSeg. All codes and examples of PaddleSeg are available at https://github.com/PaddlePaddle/PaddleSeg.
Perception Consistency Ultrasound Image Super-resolution via Self-supervised CycleGAN
Dec 28, 2020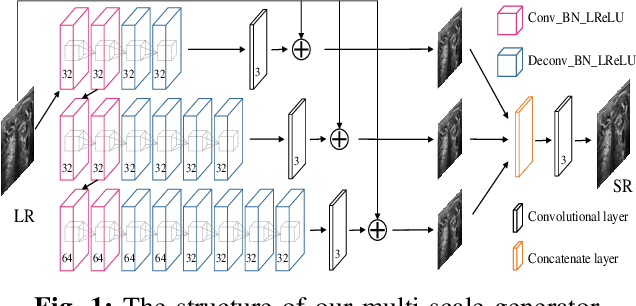
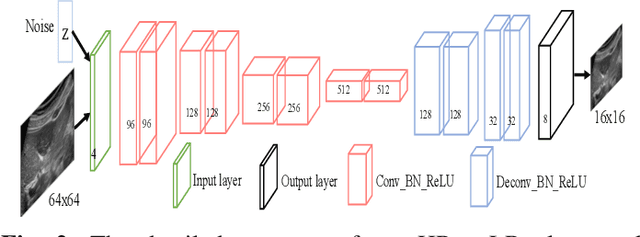
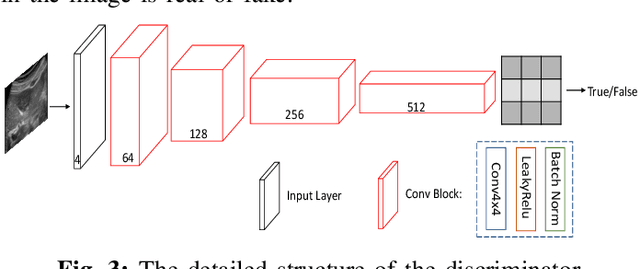
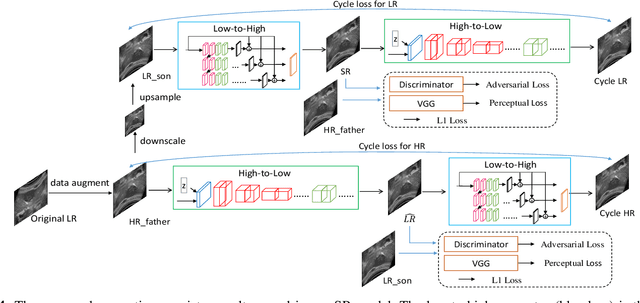
Due to the limitations of sensors, the transmission medium and the intrinsic properties of ultrasound, the quality of ultrasound imaging is always not ideal, especially its low spatial resolution. To remedy this situation, deep learning networks have been recently developed for ultrasound image super-resolution (SR) because of the powerful approximation capability. However, most current supervised SR methods are not suitable for ultrasound medical images because the medical image samples are always rare, and usually, there are no low-resolution (LR) and high-resolution (HR) training pairs in reality. In this work, based on self-supervision and cycle generative adversarial network (CycleGAN), we propose a new perception consistency ultrasound image super-resolution (SR) method, which only requires the LR ultrasound data and can ensure the re-degenerated image of the generated SR one to be consistent with the original LR image, and vice versa. We first generate the HR fathers and the LR sons of the test ultrasound LR image through image enhancement, and then make full use of the cycle loss of LR-SR-LR and HR-LR-SR and the adversarial characteristics of the discriminator to promote the generator to produce better perceptually consistent SR results. The evaluation of PSNR/IFC/SSIM, inference efficiency and visual effects under the benchmark CCA-US and CCA-US datasets illustrate our proposed approach is effective and superior to other state-of-the-art methods.
Patch-wise Contrastive Style Learning for Instagram Filter Removal
Apr 15, 2022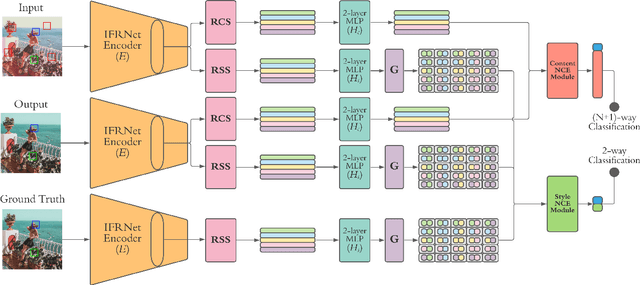
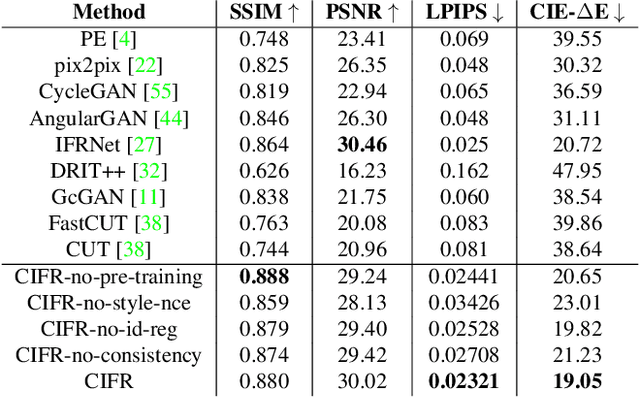
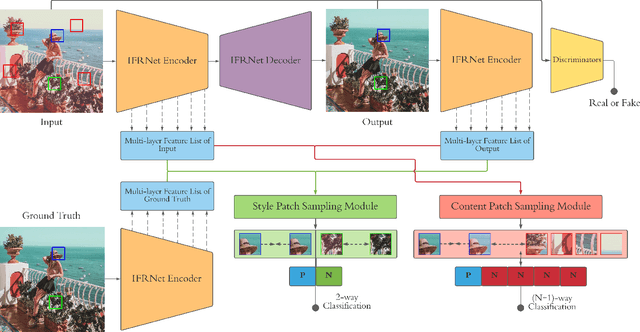
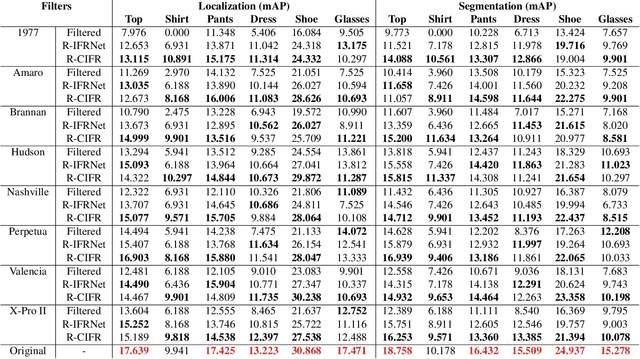
Image-level corruptions and perturbations degrade the performance of CNNs on different downstream vision tasks. Social media filters are one of the most common resources of various corruptions and perturbations for real-world visual analysis applications. The negative effects of these distractive factors can be alleviated by recovering the original images with their pure style for the inference of the downstream vision tasks. Assuming these filters substantially inject a piece of additional style information to the social media images, we can formulate the problem of recovering the original versions as a reverse style transfer problem. We introduce Contrastive Instagram Filter Removal Network (CIFR), which enhances this idea for Instagram filter removal by employing a novel multi-layer patch-wise contrastive style learning mechanism. Experiments show our proposed strategy produces better qualitative and quantitative results than the previous studies. Moreover, we present the results of our additional experiments for proposed architecture within different settings. Finally, we present the inference outputs and quantitative comparison of filtered and recovered images on localization and segmentation tasks to encourage the main motivation for this problem.
ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022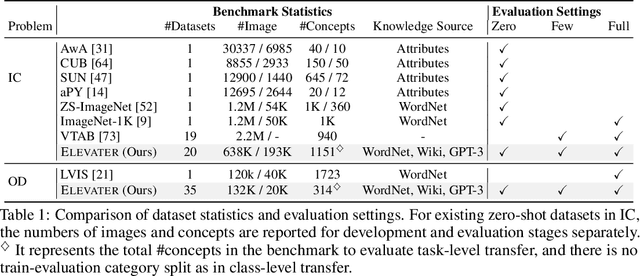

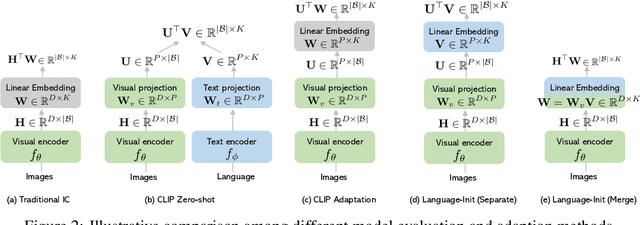
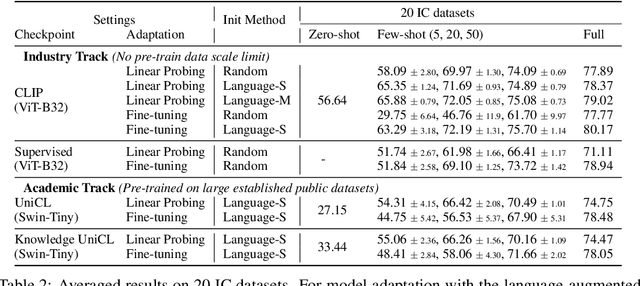
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.
ORCNet: A context-based network to simultaneously segment the ocular region components
Apr 15, 2022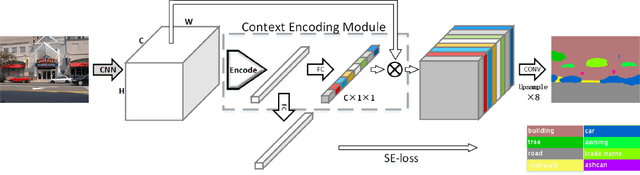
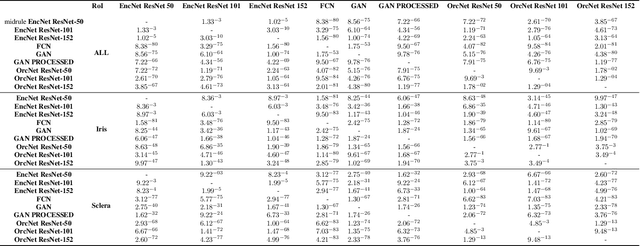
Accurate extraction of the Region of Interest is critical for successful ocular region-based biometrics. In this direction, we propose a new context-based segmentation approach, entitled Ocular Region Context Network (ORCNet), introducing a specific loss function, i.e., he Punish Context Loss (PC-Loss). The PC-Loss punishes the segmentation losses of a network by using a percentage difference value between the ground truth and the segmented masks. We obtain the percentage difference by taking into account Biederman's semantic relationship concepts, in which we use three contexts (semantic, spatial, and scale) to evaluate the relationships of the objects in an image. Our proposal achieved promising results in the evaluated scenarios: iris, sclera, and ALL (iris + sclera) segmentations, utperforming the literature baseline techniques. The ORCNet with ResNet-152 outperforms the best baseline (EncNet with ResNet-152) on average by 2.27%, 28.26% and 6.43% in terms of F-Score, Error Rate and Intersection Over Union, respectively. We also provide (for research purposes) 3,191 manually labeled masks for the MICHE-I database, as another contribution of our work.