 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022
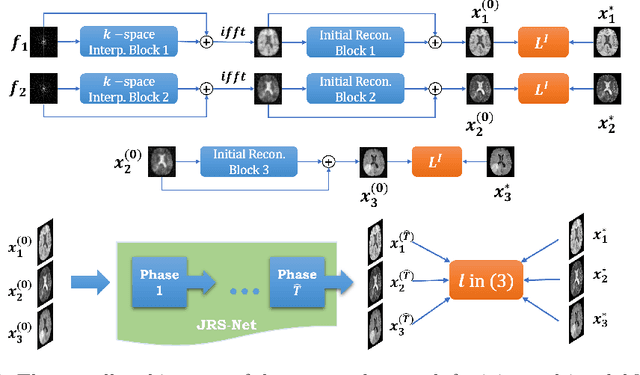
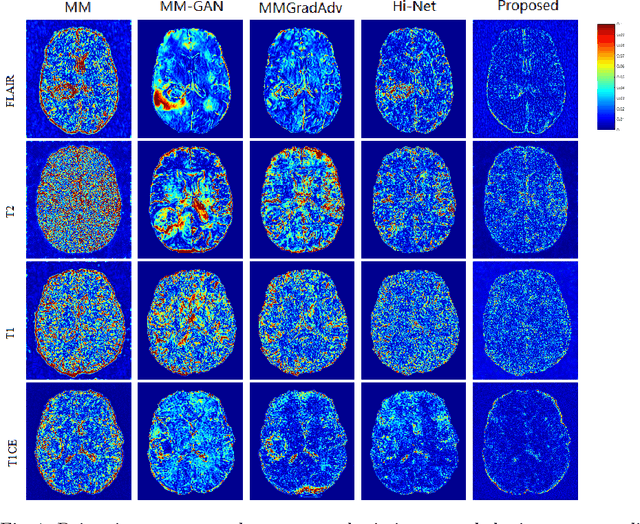

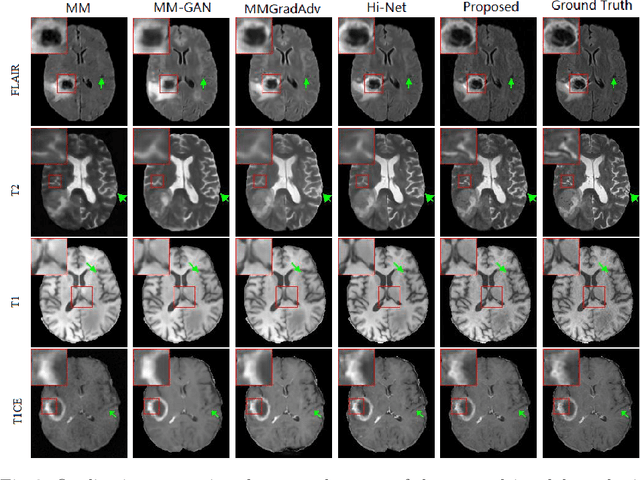
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-to-Video Synthesis
Feb 26, 2021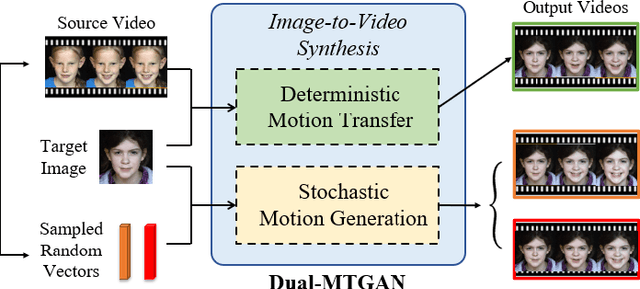
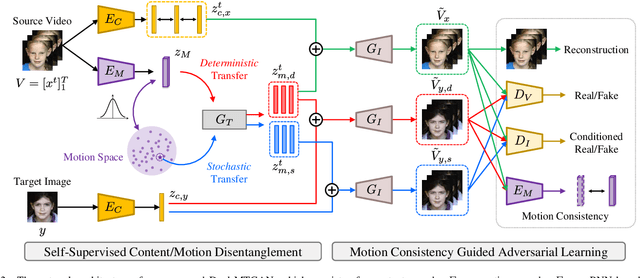


Generating videos with content and motion variations is a challenging task in computer vision. While the recent development of GAN allows video generation from latent representations, it is not easy to produce videos with particular content of motion patterns of interest. In this paper, we propose Dual Motion Transfer GAN (Dual-MTGAN), which takes image and video data as inputs while learning disentangled content and motion representations. Our Dual-MTGAN is able to perform deterministic motion transfer and stochastic motion generation. Based on a given image, the former preserves the input content and transfers motion patterns observed from another video sequence, and the latter directly produces videos with plausible yet diverse motion patterns based on the input image. The proposed model is trained in an end-to-end manner, without the need to utilize pre-defined motion features like pose or facial landmarks. Our quantitative and qualitative results would confirm the effectiveness and robustness of our model in addressing such conditioned image-to-video tasks.
Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization
Apr 20, 2022

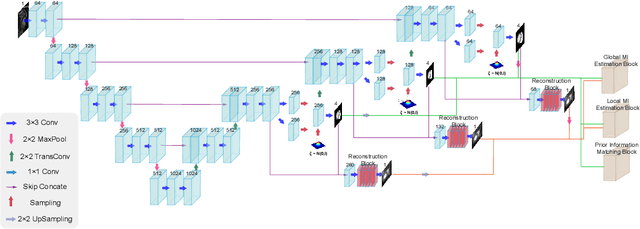
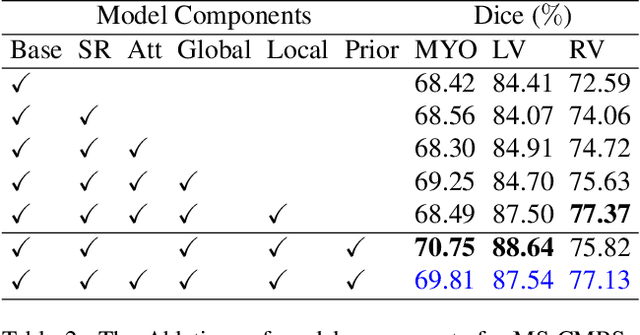
Unsupervised domain adaptation approaches have recently succeeded in various medical image segmentation tasks. The reported works often tackle the domain shift problem by aligning the domain-invariant features and minimizing the domain-specific discrepancies. That strategy works well when the difference between a specific domain and between different domains is slight. However, the generalization ability of these models on diverse imaging modalities remains a significant challenge. This paper introduces UDA-VAE++, an unsupervised domain adaptation framework for cardiac segmentation with a compact loss function lower bound. To estimate this new lower bound, we develop a novel Structure Mutual Information Estimation (SMIE) block with a global estimator, a local estimator, and a prior information matching estimator to maximize the mutual information between the reconstruction and segmentation tasks. Specifically, we design a novel sequential reparameterization scheme that enables information flow and variance correction from the low-resolution latent space to the high-resolution latent space. Comprehensive experiments on benchmark cardiac segmentation datasets demonstrate that our model outperforms previous state-of-the-art qualitatively and quantitatively. The code is available at https://github.com/LOUEY233/Toward-Mutual-Information}{https://github.com/LOUEY233/Toward-Mutual-Information
Learning the sampling density in 2D SPARKLING MRI acquisition for optimized image reconstruction
Mar 05, 2021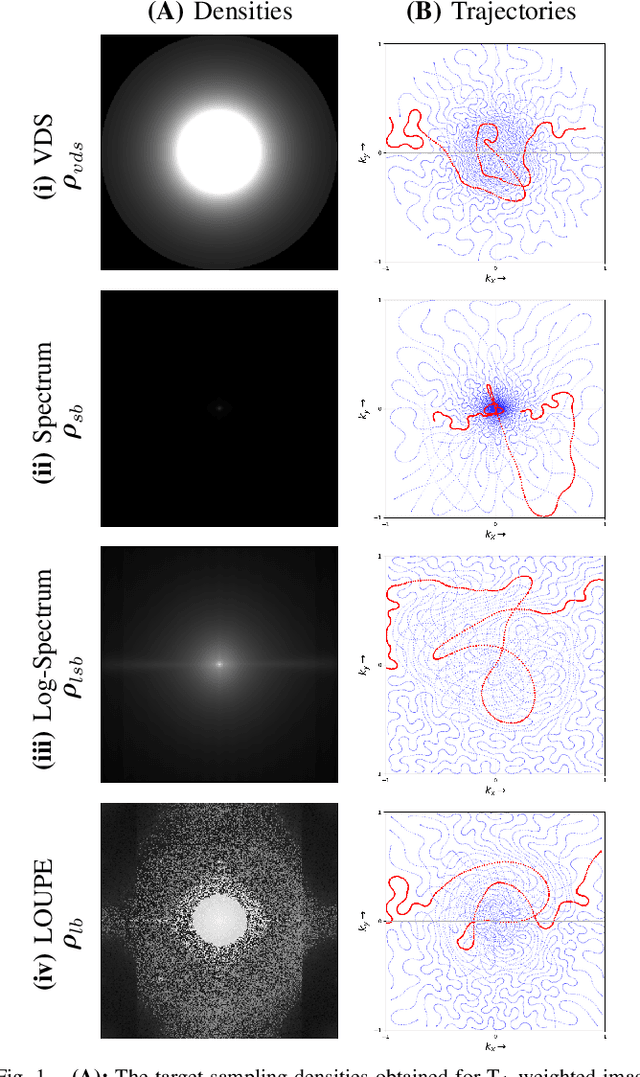
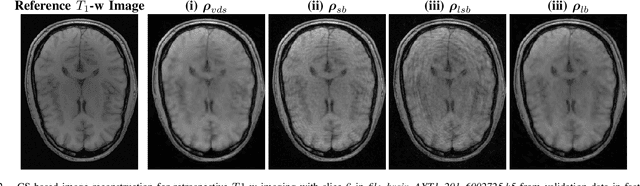
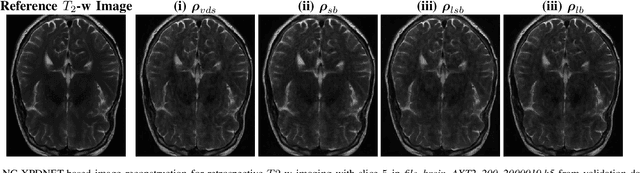
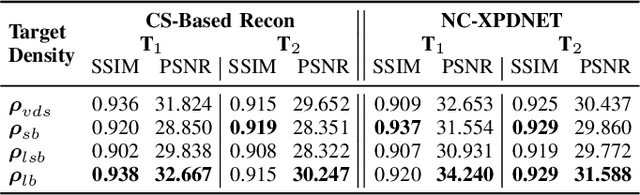
The SPARKLING algorithm was originally developed for accelerated 2D magnetic resonance imaging (MRI) in the compressed sensing (CS) context. It yields non-Cartesian sampling trajectories that jointly fulfill a target sampling density while each individual trajectory complies with MR hardware constraints. However, the two main limitations of SPARKLING are first that the optimal target sampling density is unknown and thus a user-defined parameter and second that this sampling pattern generation remains disconnected from MR image reconstruction thus from the optimization of image quality. Recently, datadriven learning schemes such as LOUPE have been proposed to learn a discrete sampling pattern, by jointly optimizing the whole pipeline from data acquisition to image reconstruction. In this work, we merge these methods with a state-of-the-art deep neural network for image reconstruction, called XPDNET, to learn the optimal target sampling density. Next, this density is used as input parameter to SPARKLING to obtain 20x accelerated non-Cartesian trajectories. These trajectories are tested on retrospective compressed sensing (CS) studies and show superior performance in terms of image quality with both deep learning (DL) and conventional CS reconstruction schemes.
Parametric Reshaping of Portraits in Videos
May 05, 2022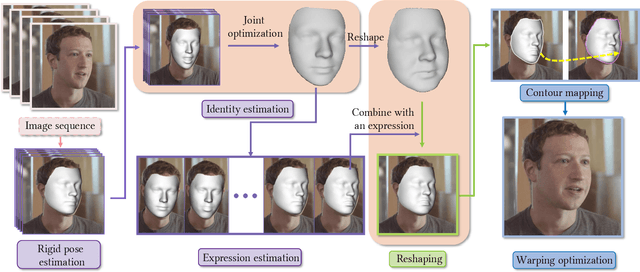

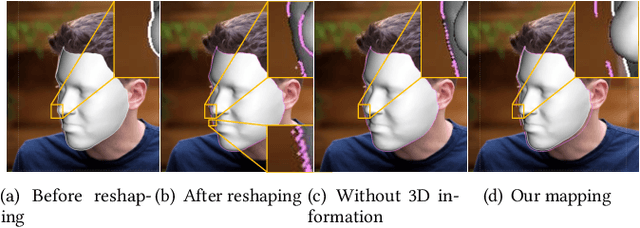

Sharing short personalized videos to various social media networks has become quite popular in recent years. This raises the need for digital retouching of portraits in videos. However, applying portrait image editing directly on portrait video frames cannot generate smooth and stable video sequences. To this end, we present a robust and easy-to-use parametric method to reshape the portrait in a video to produce smooth retouched results. Given an input portrait video, our method consists of two main stages: stabilized face reconstruction, and continuous video reshaping. In the first stage, we start by estimating face rigid pose transformations across video frames. Then we jointly optimize multiple frames to reconstruct an accurate face identity, followed by recovering face expressions over the entire video. In the second stage, we first reshape the reconstructed 3D face using a parametric reshaping model reflecting the weight change of the face, and then utilize the reshaped 3D face to guide the warping of video frames. We develop a novel signed distance function based dense mapping method for the warping between face contours before and after reshaping, resulting in stable warped video frames with minimum distortions. In addition, we use the 3D structure of the face to correct the dense mapping to achieve temporal consistency. We generate the final result by minimizing the background distortion through optimizing a content-aware warping mesh. Extensive experiments show that our method is able to create visually pleasing results by adjusting a simple reshaping parameter, which facilitates portrait video editing for social media and visual effects.
Patch-wise Contrastive Style Learning for Instagram Filter Removal
Apr 15, 2022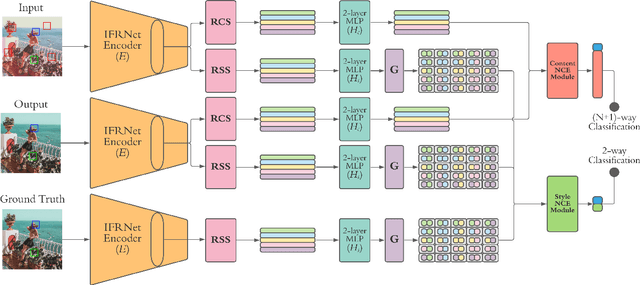
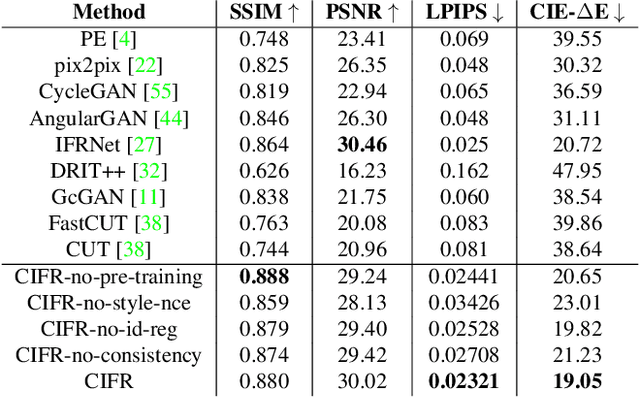
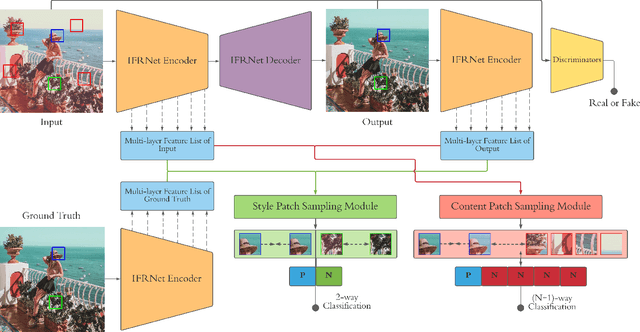
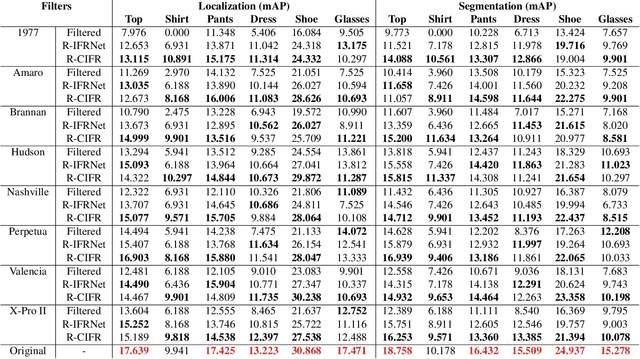
Image-level corruptions and perturbations degrade the performance of CNNs on different downstream vision tasks. Social media filters are one of the most common resources of various corruptions and perturbations for real-world visual analysis applications. The negative effects of these distractive factors can be alleviated by recovering the original images with their pure style for the inference of the downstream vision tasks. Assuming these filters substantially inject a piece of additional style information to the social media images, we can formulate the problem of recovering the original versions as a reverse style transfer problem. We introduce Contrastive Instagram Filter Removal Network (CIFR), which enhances this idea for Instagram filter removal by employing a novel multi-layer patch-wise contrastive style learning mechanism. Experiments show our proposed strategy produces better qualitative and quantitative results than the previous studies. Moreover, we present the results of our additional experiments for proposed architecture within different settings. Finally, we present the inference outputs and quantitative comparison of filtered and recovered images on localization and segmentation tasks to encourage the main motivation for this problem.
ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022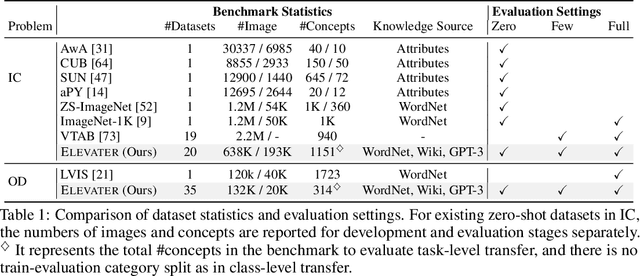

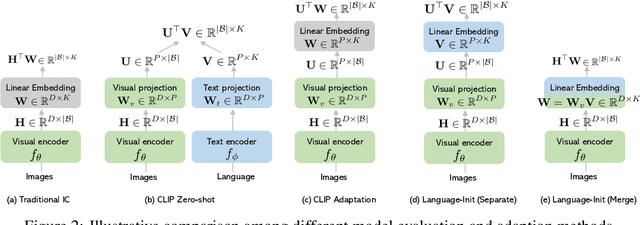
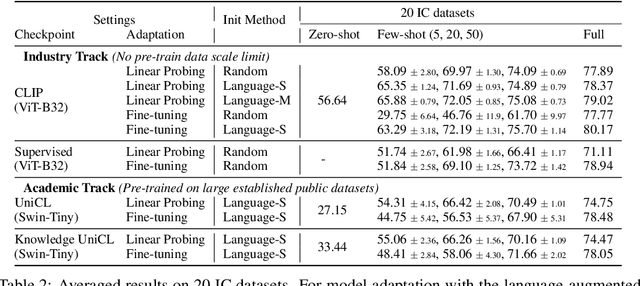
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.
ORCNet: A context-based network to simultaneously segment the ocular region components
Apr 15, 2022
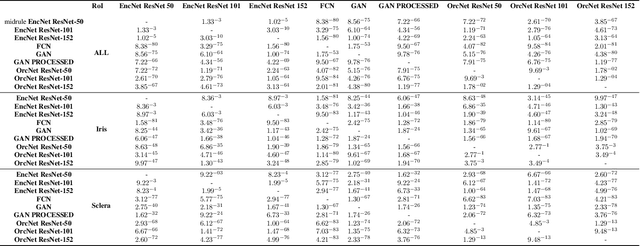
Accurate extraction of the Region of Interest is critical for successful ocular region-based biometrics. In this direction, we propose a new context-based segmentation approach, entitled Ocular Region Context Network (ORCNet), introducing a specific loss function, i.e., he Punish Context Loss (PC-Loss). The PC-Loss punishes the segmentation losses of a network by using a percentage difference value between the ground truth and the segmented masks. We obtain the percentage difference by taking into account Biederman's semantic relationship concepts, in which we use three contexts (semantic, spatial, and scale) to evaluate the relationships of the objects in an image. Our proposal achieved promising results in the evaluated scenarios: iris, sclera, and ALL (iris + sclera) segmentations, utperforming the literature baseline techniques. The ORCNet with ResNet-152 outperforms the best baseline (EncNet with ResNet-152) on average by 2.27%, 28.26% and 6.43% in terms of F-Score, Error Rate and Intersection Over Union, respectively. We also provide (for research purposes) 3,191 manually labeled masks for the MICHE-I database, as another contribution of our work.
OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
Apr 07, 2022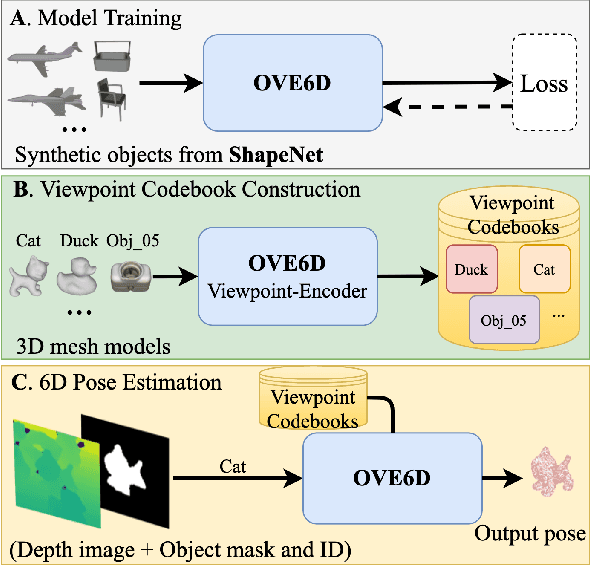
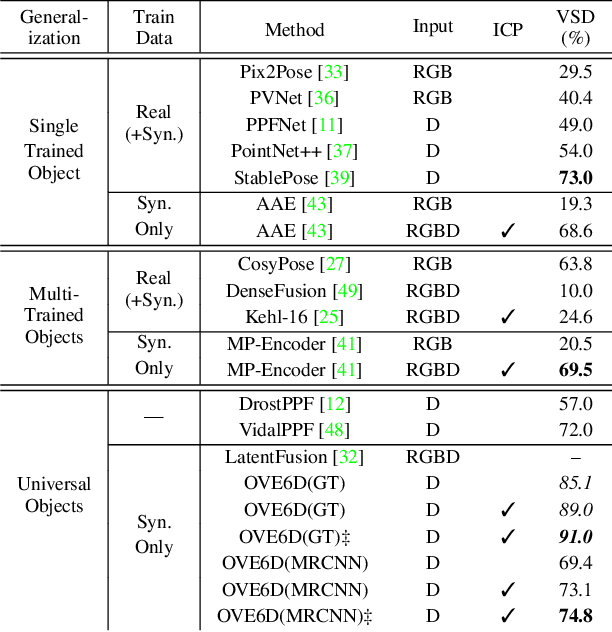
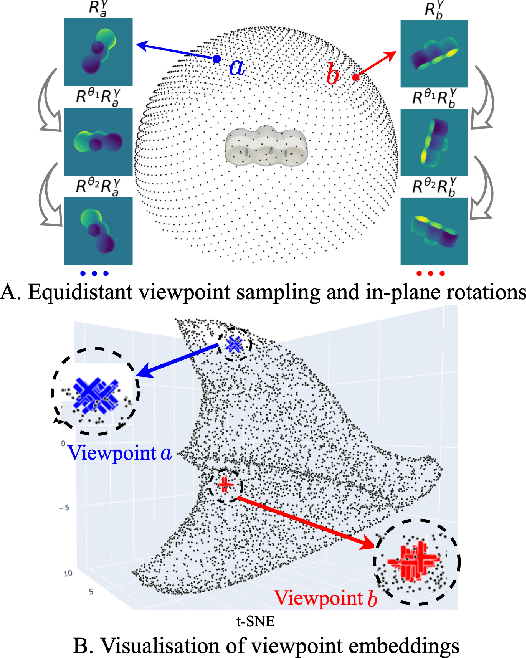
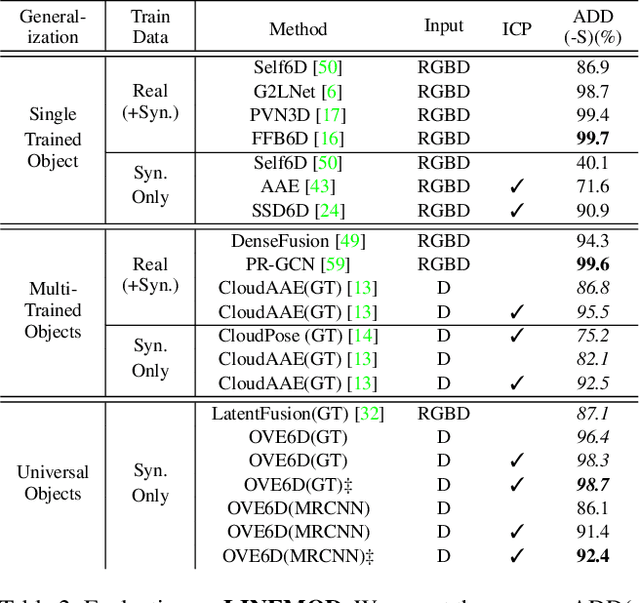
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data. The implementation and the pre-trained model will be made publicly available.
A Real-time Junk Food Recognition System based on Machine Learning
Mar 22, 2022



$ $As a result of bad eating habits, humanity may be destroyed. People are constantly on the lookout for tasty foods, with junk foods being the most common source. As a consequence, our eating patterns are shifting, and we're gravitating toward junk food more than ever, which is bad for our health and increases our risk of acquiring health problems. Machine learning principles are applied in every aspect of our lives, and one of them is object recognition via image processing. However, because foods vary in nature, this procedure is crucial, and traditional methods like ANN, SVM, KNN, PLS etc., will result in a low accuracy rate. All of these issues were defeated by the Deep Neural Network. In this work, we created a fresh dataset of 10,000 data points from 20 junk food classifications to try to recognize junk foods. All of the data in the data set was gathered using the Google search engine, which is thought to be one-of-a-kind in every way. The goal was achieved using Convolution Neural Network (CNN) technology, which is well-known for image processing. We achieved a 98.05\% accuracy rate throughout the research, which was satisfactory. In addition, we conducted a test based on a real-life event, and the outcome was extraordinary. Our goal is to advance this research to the next level, so that it may be applied to a future study. Our ultimate goal is to create a system that would encourage people to avoid eating junk food and to be health-conscious. \keywords{ Machine Learning \and junk food \and object detection \and YOLOv3 \and custom food dataset.}