 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpreting Class Conditional GANs with Channel Awareness
Mar 21, 2022
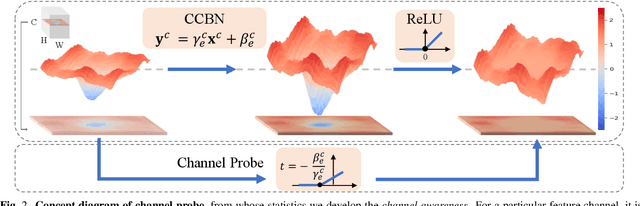
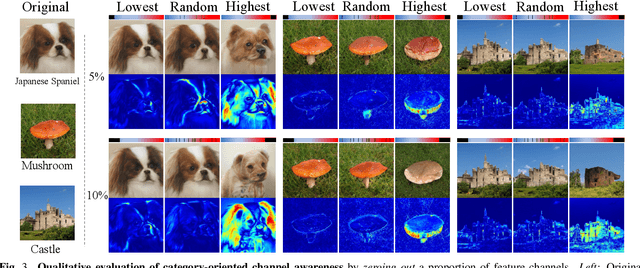
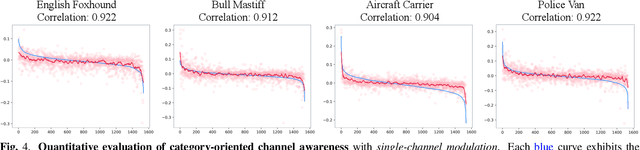
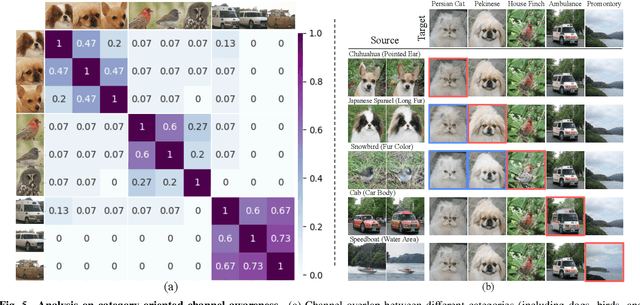
Understanding the mechanism of generative adversarial networks (GANs) helps us better use GANs for downstream applications. Existing efforts mainly target interpreting unconditional models, leaving it less explored how a conditional GAN learns to render images regarding various categories. This work fills in this gap by investigating how a class conditional generator unifies the synthesis of multiple classes. For this purpose, we dive into the widely used class-conditional batch normalization (CCBN), and observe that each feature channel is activated at varying degrees given different categorical embeddings. To describe such a phenomenon, we propose channel awareness, which quantitatively characterizes how a single channel contributes to the final synthesis. Extensive evaluations and analyses on the BigGAN model pre-trained on ImageNet reveal that only a subset of channels is primarily responsible for the generation of a particular category, similar categories (e.g., cat and dog) usually get related to some same channels, and some channels turn out to share information across all classes. For good measure, our algorithm enables several novel applications with conditional GANs. Concretely, we achieve (1) versatile image editing via simply altering a single channel and manage to (2) harmoniously hybridize two different classes. We further verify that the proposed channel awareness shows promising potential in (3) segmenting the synthesized image and (4) evaluating the category-wise synthesis performance.
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021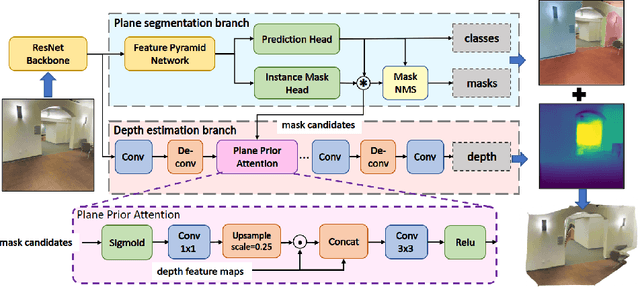

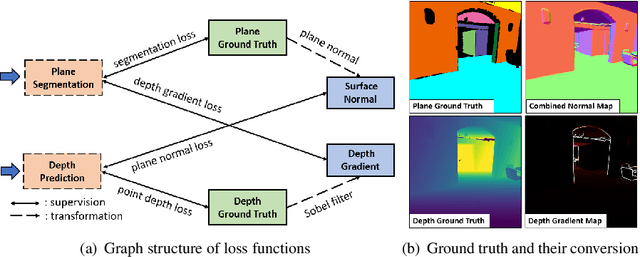

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.
Segmentation-Renormalized Deep Feature Modulation for Unpaired Image Harmonization
Feb 11, 2021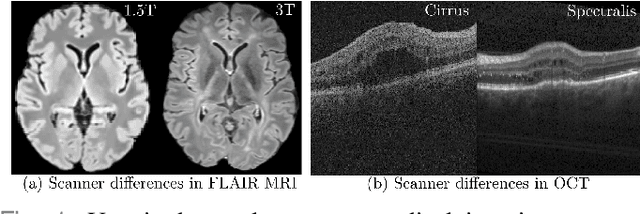
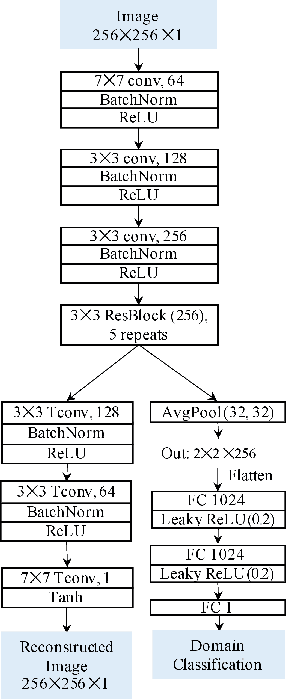
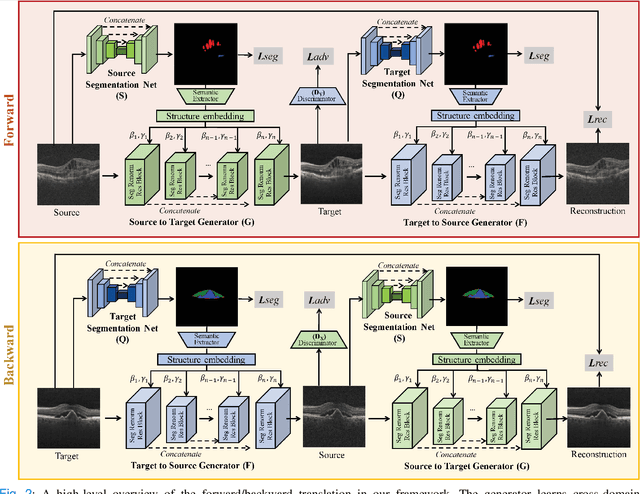
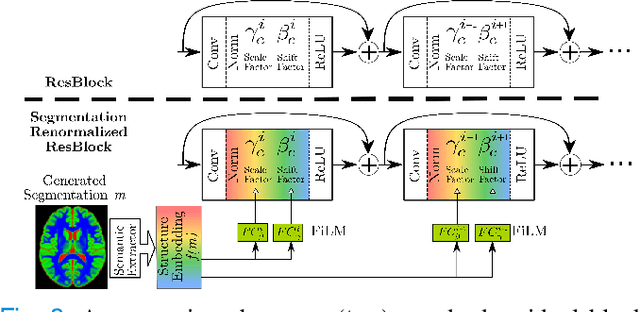
Deep networks are now ubiquitous in large-scale multi-center imaging studies. However, the direct aggregation of images across sites is contraindicated for downstream statistical and deep learning-based image analysis due to inconsistent contrast, resolution, and noise. To this end, in the absence of paired data, variations of Cycle-consistent Generative Adversarial Networks have been used to harmonize image sets between a source and target domain. Importantly, these methods are prone to instability, contrast inversion, intractable manipulation of pathology, and steganographic mappings which limit their reliable adoption in real-world medical imaging. In this work, based on an underlying assumption that morphological shape is consistent across imaging sites, we propose a segmentation-renormalized image translation framework to reduce inter-scanner heterogeneity while preserving anatomical layout. We replace the affine transformations used in the normalization layers within generative networks with trainable scale and shift parameters conditioned on jointly learned anatomical segmentation embeddings to modulate features at every level of translation. We evaluate our methodologies against recent baselines across several imaging modalities (T1w MRI, FLAIR MRI, and OCT) on datasets with and without lesions. Segmentation-renormalization for translation GANs yields superior image harmonization as quantified by Inception distances, demonstrates improved downstream utility via post-hoc segmentation accuracy, and improved robustness to translation perturbation and self-adversarial attacks.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 18, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work is available at https://github.com/JUGGHM/PENet_ICRA2021.
Learning to Bound: A Generative Cramér-Rao Bound
Mar 07, 2022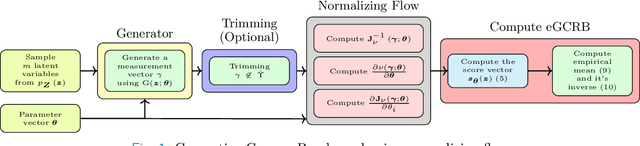


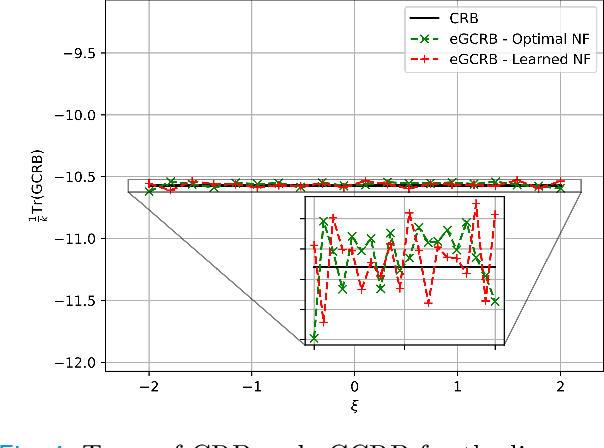
The Cram\'er-Rao bound (CRB), a well-known lower bound on the performance of any unbiased parameter estimator, has been used to study a wide variety of problems. However, to obtain the CRB, requires an analytical expression for the likelihood of the measurements given the parameters, or equivalently a precise and explicit statistical model for the data. In many applications, such a model is not available. Instead, this work introduces a novel approach to approximate the CRB using data-driven methods, which removes the requirement for an analytical statistical model. This approach is based on the recent success of deep generative models in modeling complex, high-dimensional distributions. Using a learned normalizing flow model, we model the distribution of the measurements and obtain an approximation of the CRB, which we call Generative Cram\'er-Rao Bound (GCRB). Numerical experiments on simple problems validate this approach, and experiments on two image processing tasks of image denoising and edge detection with a learned camera noise model demonstrate its power and benefits.
Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?
Mar 12, 2022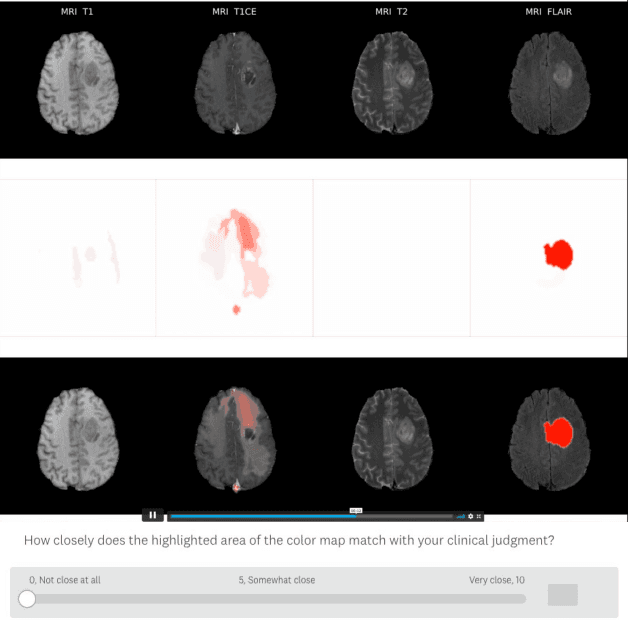
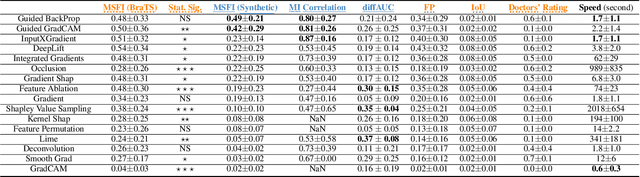
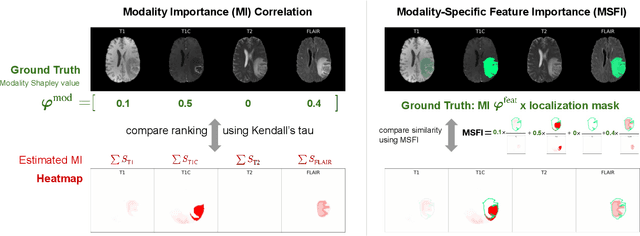
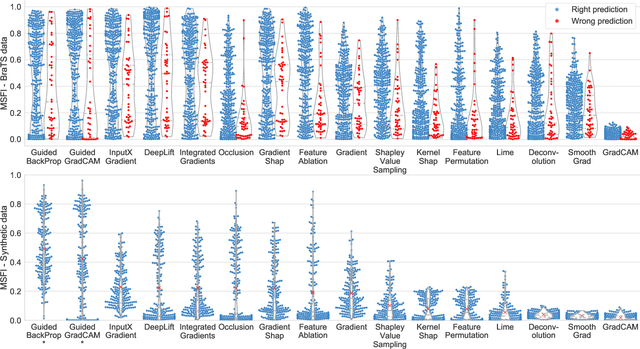
Being able to explain the prediction to clinical end-users is a necessity to leverage the power of artificial intelligence (AI) models for clinical decision support. For medical images, a feature attribution map, or heatmap, is the most common form of explanation that highlights important features for AI models' prediction. However, it is unknown how well heatmaps perform on explaining decisions on multi-modal medical images, where each image modality or channel visualizes distinct clinical information of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users' interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the modality-specific feature importance (MSFI) metric. It encodes clinical image and explanation interpretation patterns of modality prioritization and modality-specific feature localization. We conduct a clinical requirement-grounded, systematic evaluation using computational methods and a clinician user study. Results show that the examined 16 heatmap algorithms failed to fulfill clinical requirements to correctly indicate AI model decision process or decision quality. The evaluation and MSFI metric can guide the design and selection of XAI algorithms to meet clinical requirements on multi-modal explanation.
White Box Methods for Explanations of Convolutional Neural Networks in Image Classification Tasks
Apr 06, 2021
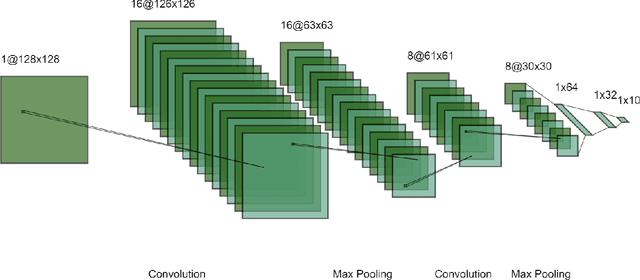
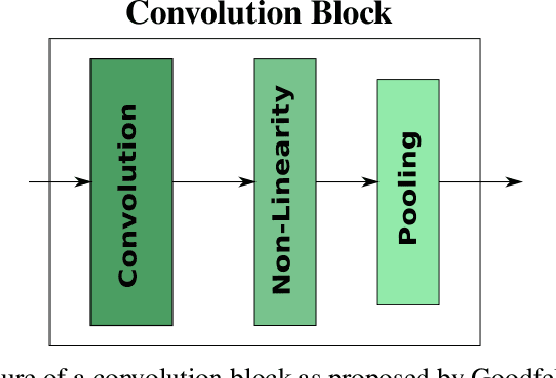

In recent years, deep learning has become prevalent to solve applications from multiple domains. Convolutional Neural Networks (CNNs) particularly have demonstrated state of the art performance for the task of image classification. However, the decisions made by these networks are not transparent and cannot be directly interpreted by a human. Several approaches have been proposed to explain to understand the reasoning behind a prediction made by a network. In this paper, we propose a topology of grouping these methods based on their assumptions and implementations. We focus primarily on white box methods that leverage the information of the internal architecture of a network to explain its decision. Given the task of image classification and a trained CNN, this work aims to provide a comprehensive and detailed overview of a set of methods that can be used to create explanation maps for a particular image, that assign an importance score to each pixel of the image based on its contribution to the decision of the network. We also propose a further classification of the white box methods based on their implementations to enable better comparisons and help researchers find methods best suited for different scenarios.
Unsupervised Lifelong Person Re-identification via Contrastive Rehearsal
Mar 12, 2022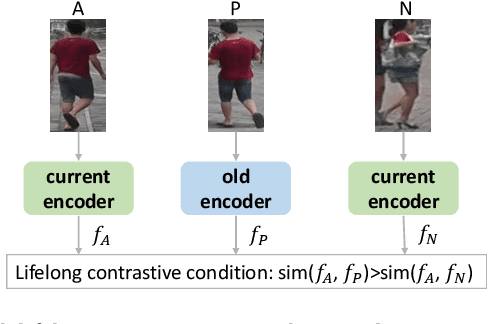
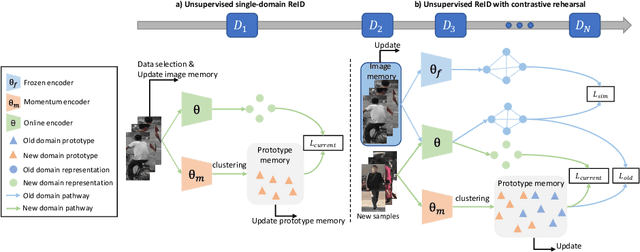
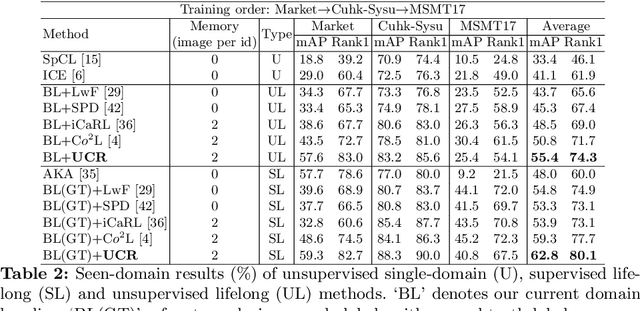
Existing unsupervised person re-identification (ReID) methods focus on adapting a model trained on a source domain to a fixed target domain. However, an adapted ReID model usually only works well on a certain target domain, but can hardly memorize the source domain knowledge and generalize to upcoming unseen data. In this paper, we propose unsupervised lifelong person ReID, which focuses on continuously conducting unsupervised domain adaptation on new domains without forgetting the knowledge learnt from old domains. To tackle unsupervised lifelong ReID, we conduct a contrastive rehearsal on a small number of stored old samples while sequentially adapting to new domains. We further set an image-to-image similarity constraint between old and new models to regularize the model updates in a way that suits old knowledge. We sequentially train our model on several large-scale datasets in an unsupervised manner and test it on all seen domains as well as several unseen domains to validate the generalizability of our method. Our proposed unsupervised lifelong method achieves strong generalizability, which significantly outperforms previous lifelong methods on both seen and unseen domains. Code will be made available at https://github.com/chenhao2345/UCR.
BronchoPose: an analysis of data and model configuration for vision-based bronchoscopy pose estimation
Apr 25, 2022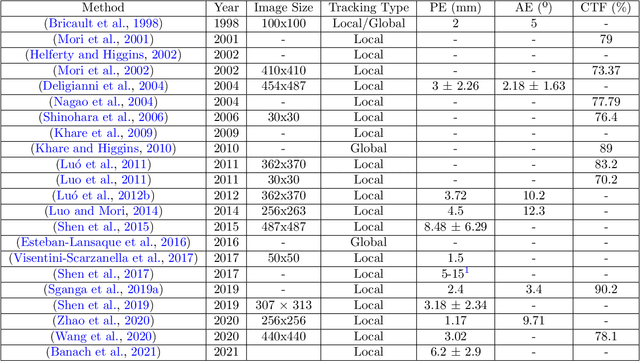
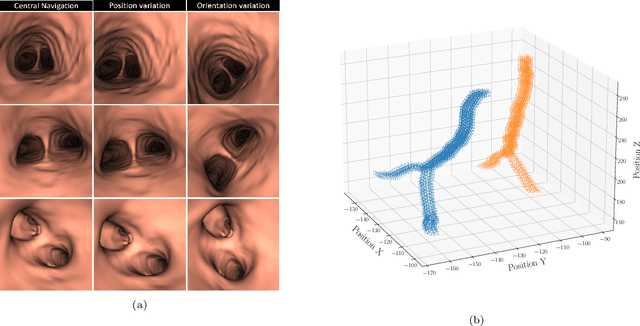
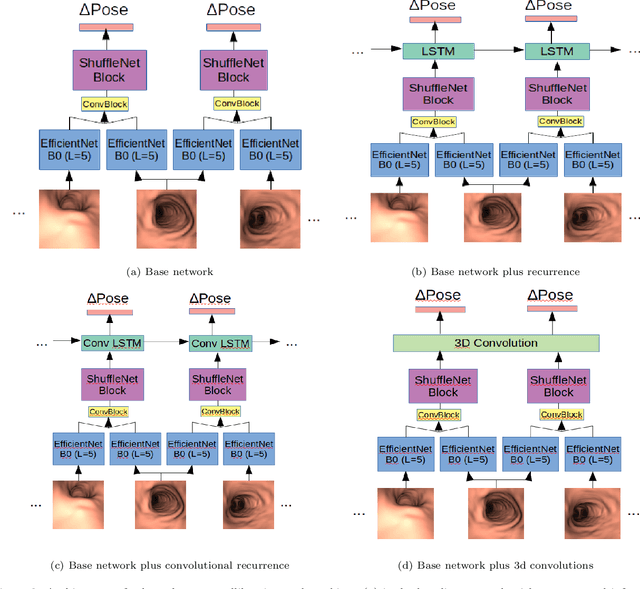
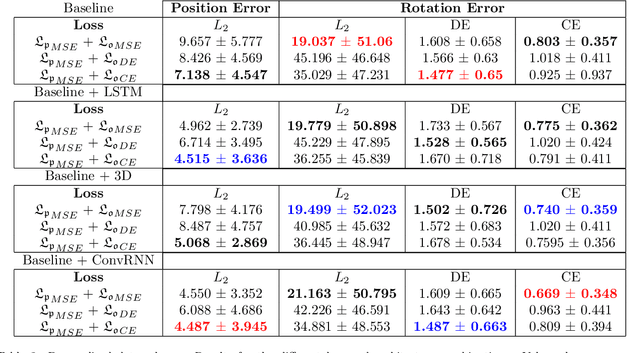
Vision-based bronchoscopy (VB) models require the registration of the virtual lung model with the frames from the video bronchoscopy to provide effective guidance during the biopsy. The registration can be achieved by either tracking the position and orientation of the bronchoscopy camera or by calibrating its deviation from the pose (position and orientation) simulated in the virtual lung model. Recent advances in neural networks and temporal image processing have provided new opportunities for guided bronchoscopy. However, such progress has been hindered by the lack of comparative experimental conditions. In the present paper, we share a novel synthetic dataset allowing for a fair comparison of methods. Moreover, this paper investigates several neural network architectures for the learning of temporal information at different levels of subject personalization. In order to improve orientation measurement, we also present a standardized comparison framework and a novel metric for camera orientation learning. Results on the dataset show that the proposed metric and architectures, as well as the standardized conditions, provide notable improvements to current state-of-the-art camera pose estimation in video bronchoscopy.
Robust Dual-Graph Regularized Moving Object Detection
Apr 25, 2022


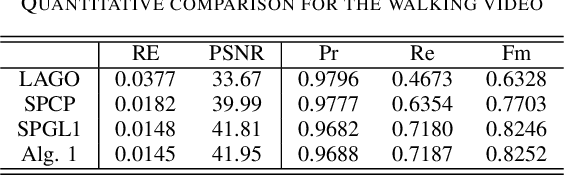
Moving object detection and its associated background-foreground separation have been widely used in a lot of applications, including computer vision, transportation and surveillance. Due to the presence of the static background, a video can be naturally decomposed into a low-rank background and a sparse foreground. Many regularization techniques, such as matrix nuclear norm, have been imposed on the background. In the meanwhile, sparsity or smoothness based regularizations, such as total variation and $\ell_1$, can be imposed on the foreground. Moreover, graph Laplacians are further imposed to capture the complicated geometry of background images. Recently, weighted regularization techniques including the weighted nuclear norm regularization have been proposed in the image processing community to promote adaptive sparsity while achieving efficient performance. In this paper, we propose a robust dual-graph regularized moving object detection model based on the weighted nuclear norm regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on body movement data sets have demonstrated the effectiveness of this method in separating moving objects from background, and the great potential in robotic applications.