 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust image stitching with multiple registrations
Nov 23, 2020

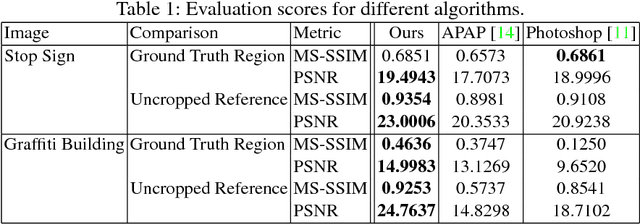


Panorama creation is one of the most widely deployed techniques in computer vision. In addition to industry applications such as Google Street View, it is also used by millions of consumers in smartphones and other cameras. Traditionally, the problem is decomposed into three phases: registration, which picks a single transformation of each source image to align it to the other inputs, seam finding, which selects a source image for each pixel in the final result, and blending, which fixes minor visual artifacts. Here, we observe that the use of a single registration often leads to errors, especially in scenes with significant depth variation or object motion. We propose instead the use of multiple registrations, permitting regions of the image at different depths to be captured with greater accuracy. MRF inference techniques naturally extend to seam finding over multiple registrations, and we show here that their energy functions can be readily modified with new terms that discourage duplication and tearing, common problems that are exacerbated by the use of multiple registrations. Our techniques are closely related to layer-based stereo, and move image stitching closer to explicit scene modeling. Experimental evidence demonstrates that our techniques often generate significantly better panoramas when there is substantial motion or parallax.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 09, 2022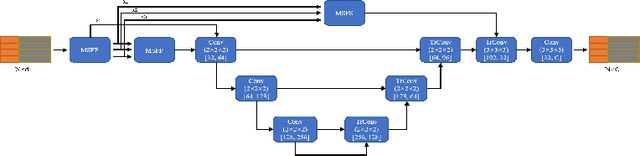
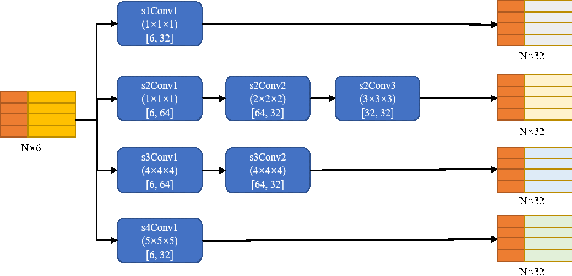
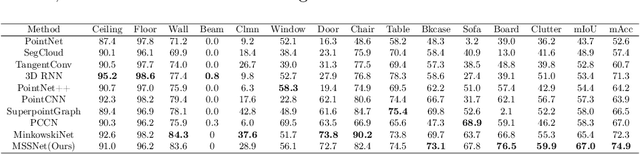
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.
Adaptive Clustering of Robust Semantic Representations for Adversarial Image Purification
Apr 07, 2021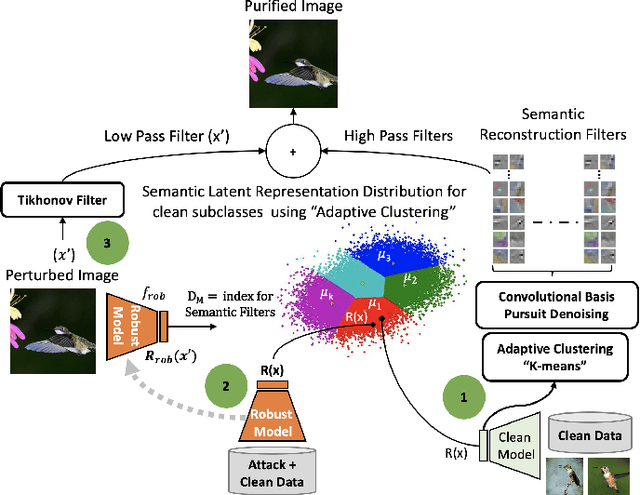
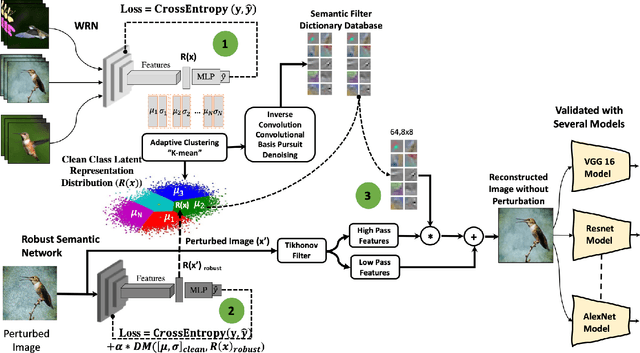


Deep Learning models are highly susceptible to adversarial manipulations that can lead to catastrophic consequences. One of the most effective methods to defend against such disturbances is adversarial training but at the cost of generalization of unseen attacks and transferability across models. In this paper, we propose a robust defense against adversarial attacks, which is model agnostic and generalizable to unseen adversaries. Initially, with a baseline model, we extract the latent representations for each class and adaptively cluster the latent representations that share a semantic similarity. We obtain the distributions for the clustered latent representations and from their originating images, we learn semantic reconstruction dictionaries (SRD). We adversarially train a new model constraining the latent space representation to minimize the distance between the adversarial latent representation and the true cluster distribution. To purify the image, we decompose the input into low and high-frequency components. The high-frequency component is reconstructed based on the most adequate SRD from the clean dataset. In order to evaluate the most adequate SRD, we rely on the distance between robust latent representations and semantic cluster distributions. The output is a purified image with no perturbation. Image purification on CIFAR-10 and ImageNet-10 using our proposed method improved the accuracy by more than 10% compared to state-of-the-art results.
Diffusion and Volume Maximization-Based Clustering of Highly Mixed Hyperspectral Images
Mar 26, 2022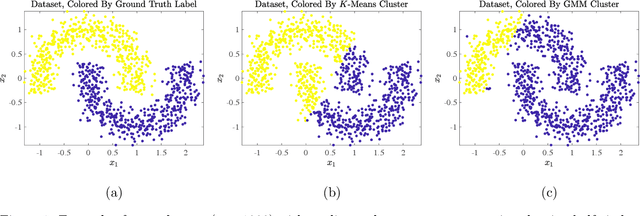
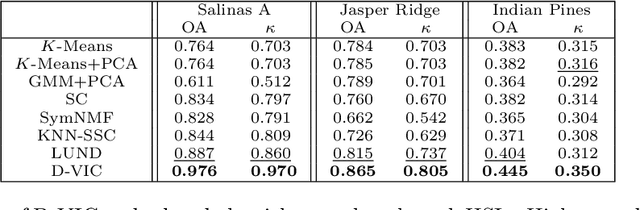
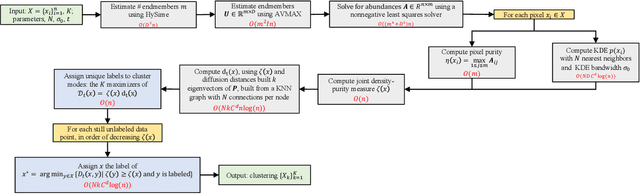
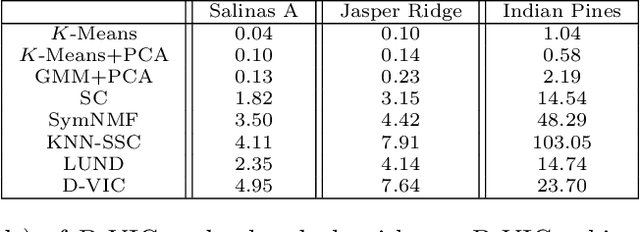
Hyperspectral images of a scene or object are a rich data source, often encoding a hundred or more spectral bands of reflectance at each pixel. Despite being very high-dimensional, these images typically encode latent low-dimensional structure that can be exploited for material discrimination. However, due to an inherent trade-off between spectral and spatial resolution, many hyperspectral images are generated at a coarse spatial scale, and single pixels may correspond to spatial regions containing multiple materials. This article introduces the Diffusion and Volume maximization-based Image Clustering (D-VIC) algorithm for unsupervised material discrimination. D-VIC locates cluster modes - high-density, high-purity pixels in the hyperspectral image that are far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels - and assigns these pixels unique labels, as these points are meant to exemplify underlying material structure. Non-modal pixels are labeled according to their diffusion distance nearest neighbor of higher density and purity that is already labeled. By directly incorporating pixel purity into its modal and non-modal labeling, D-VIC upweights pixels that correspond to a spatial region containing just a single material, yielding more interpretable clusterings. D-VIC is shown to outperform baseline and comparable state-of-the-art methods in extensive numerical experiments on a range of hyperspectral images, implying that it is well-equipped for material discrimination and clustering of these data.
Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling
Jan 06, 2022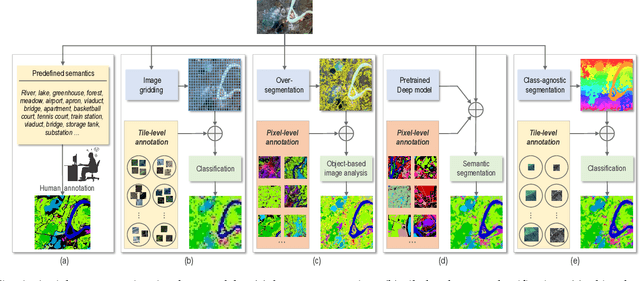
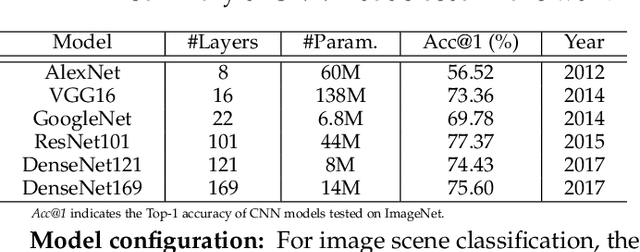
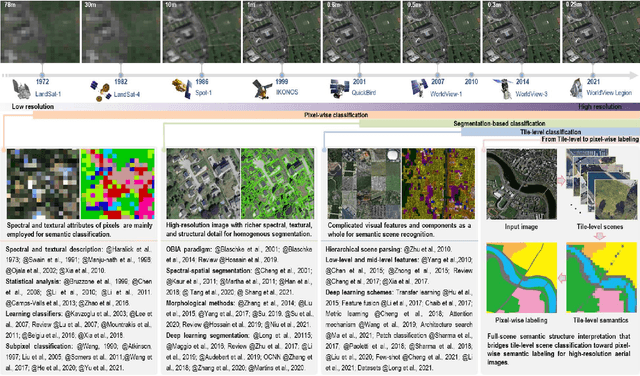

Given an aerial image, aerial scene parsing (ASP) targets to interpret the semantic structure of the image content, e.g., by assigning a semantic label to every pixel of the image. With the popularization of data-driven methods, the past decades have witnessed promising progress on ASP by approaching the problem with the schemes of tile-level scene classification or segmentation-based image analysis, when using high-resolution aerial images. However, the former scheme often produces results with tile-wise boundaries, while the latter one needs to handle the complex modeling process from pixels to semantics, which often requires large-scale and well-annotated image samples with pixel-wise semantic labels. In this paper, we address these issues in ASP, with perspectives from tile-level scene classification to pixel-wise semantic labeling. Specifically, we first revisit aerial image interpretation by a literature review. We then present a large-scale scene classification dataset that contains one million aerial images termed Million-AID. With the presented dataset, we also report benchmarking experiments using classical convolutional neural networks (CNNs). Finally, we perform ASP by unifying the tile-level scene classification and object-based image analysis to achieve pixel-wise semantic labeling. Intensive experiments show that Million-AID is a challenging yet useful dataset, which can serve as a benchmark for evaluating newly developed algorithms. When transferring knowledge from Million-AID, fine-tuning CNN models pretrained on Million-AID perform consistently better than those pretrained ImageNet for aerial scene classification. Moreover, our designed hierarchical multi-task learning method achieves the state-of-the-art pixel-wise classification on the challenging GID, bridging the tile-level scene classification toward pixel-wise semantic labeling for aerial image interpretation.
Good Artists Copy, Great Artists Steal: Model Extraction Attacks Against Image Translation Generative Adversarial Networks
Apr 26, 2021
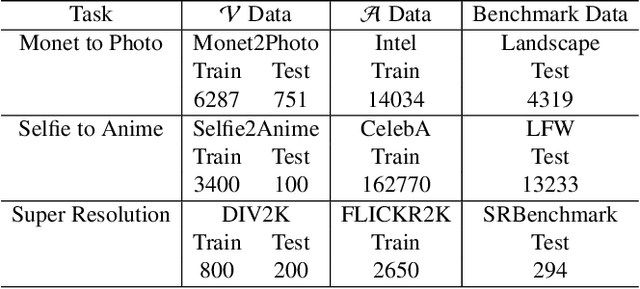

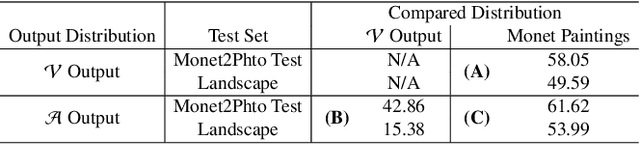
Machine learning models are typically made available to potential client users via inference APIs. Model extraction attacks occur when a malicious client uses information gleaned from queries to the inference API of a victim model $F_V$ to build a surrogate model $F_A$ that has comparable functionality. Recent research has shown successful model extraction attacks against image classification, and NLP models. In this paper, we show the first model extraction attack against real-world generative adversarial network (GAN) image translation models. We present a framework for conducting model extraction attacks against image translation models, and show that the adversary can successfully extract functional surrogate models. The adversary is not required to know $F_V$'s architecture or any other information about it beyond its intended image translation task, and queries $F_V$'s inference interface using data drawn from the same domain as the training data for $F_V$. We evaluate the effectiveness of our attacks using three different instances of two popular categories of image translation: (1) Selfie-to-Anime and (2) Monet-to-Photo (image style transfer), and (3) Super-Resolution (super resolution). Using standard performance metrics for GANs, we show that our attacks are effective in each of the three cases -- the differences between $F_V$ and $F_A$, compared to the target are in the following ranges: Selfie-to-Anime: FID $13.36-68.66$, Monet-to-Photo: FID $3.57-4.40$, and Super-Resolution: SSIM: $0.06-0.08$ and PSNR: $1.43-4.46$. Furthermore, we conducted a large scale (125 participants) user study on Selfie-to-Anime and Monet-to-Photo to show that human perception of the images produced by the victim and surrogate models can be considered equivalent, within an equivalence bound of Cohen's $d=0.3$.
Simple black-box universal adversarial attacks on medical image classification based on deep neural networks
Aug 11, 2021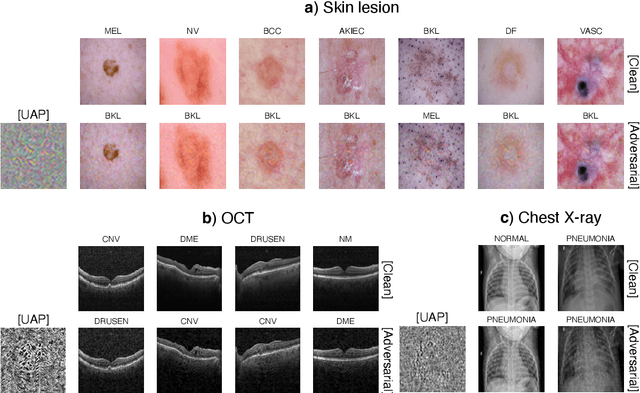
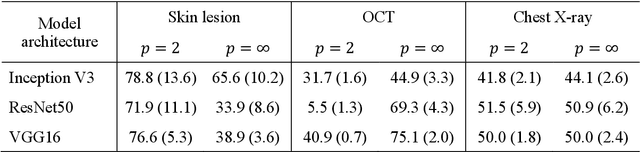
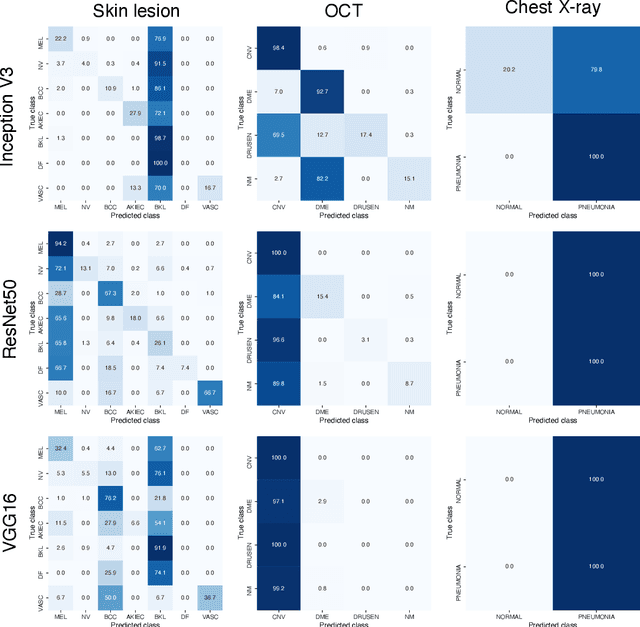
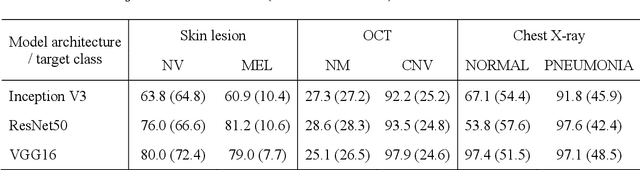
Universal adversarial attacks, which hinder most deep neural network (DNN) tasks using only a small single perturbation called a universal adversarial perturbation (UAP), is a realistic security threat to the practical application of a DNN. In particular, such attacks cause serious problems in medical imaging. Given that computer-based systems are generally operated under a black-box condition in which only queries on inputs are allowed and outputs are accessible, the impact of UAPs seems to be limited because well-used algorithms for generating UAPs are limited to a white-box condition in which adversaries can access the model weights and loss gradients. Nevertheless, we demonstrate that UAPs are easily generatable using a relatively small dataset under black-box conditions. In particular, we propose a method for generating UAPs using a simple hill-climbing search based only on DNN outputs and demonstrate the validity of the proposed method using representative DNN-based medical image classifications. Black-box UAPs can be used to conduct both non-targeted and targeted attacks. Overall, the black-box UAPs showed high attack success rates (40% to 90%), although some of them had relatively low success rates because the method only utilizes limited information to generate UAPs. The vulnerability of black-box UAPs was observed in several model architectures. The results indicate that adversaries can also generate UAPs through a simple procedure under the black-box condition to foil or control DNN-based medical image diagnoses, and that UAPs are a more realistic security threat.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022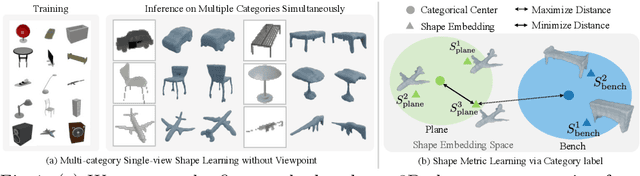

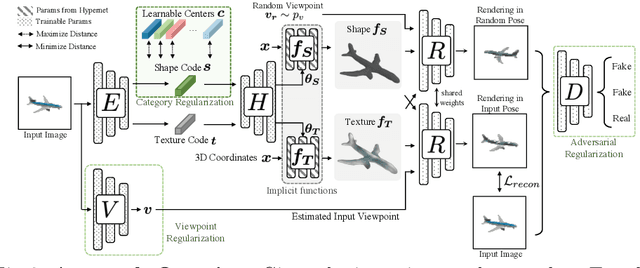
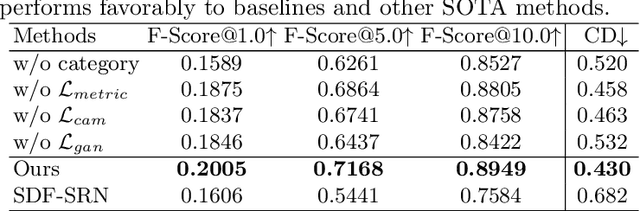
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
SAR Image Despeckling Based on Convolutional Denoising Autoencoder
Nov 30, 2020
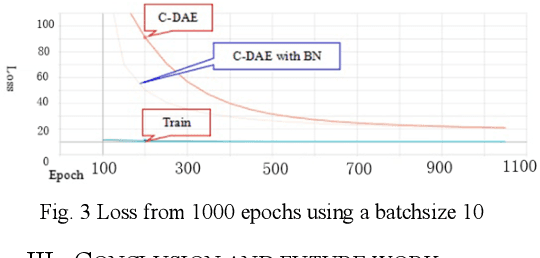
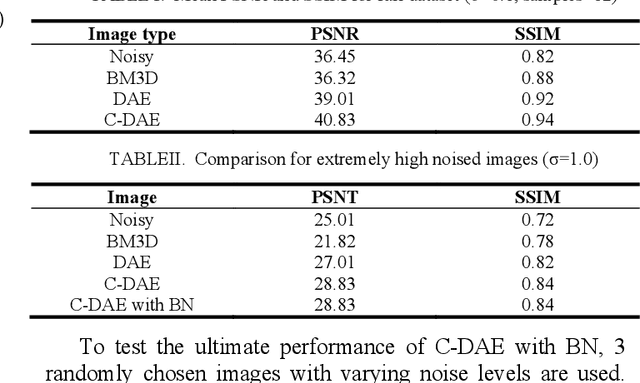
In Synthetic Aperture Radar (SAR) imaging, despeckling is very important for image analysis,whereas speckle is known as a kind of multiplicative noise caused by the coherent imaging system. During the past three decades, various algorithms have been proposed to denoise the SAR image. Generally, the BM3D is considered as the state of art technique to despeckle the speckle noise with excellent performance. More recently, deep learning make a success in image denoising and achieved a improvement over conventional method where large train dataset is required. Unlike most of the images SAR image despeckling approach, the proposed approach learns the speckle from corrupted images directly. In this paper, the limited scale of dataset make a efficient exploration by using convolutioal denoising autoencoder (C-DAE) to reconstruct the speckle-free SAR images. Batch normalization strategy is integrated with C- DAE to speed up the train time. Moreover, we compute image quality in standard metrics, PSNR and SSIM. It is revealed that our approach perform well than some others.
GAN-based Matrix Factorization for Recommender Systems
Jan 20, 2022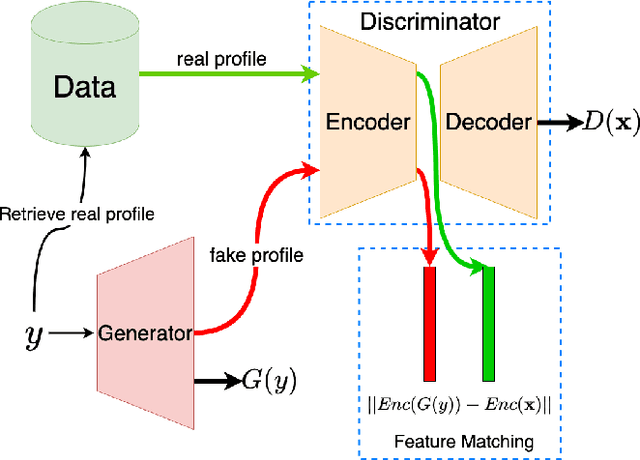
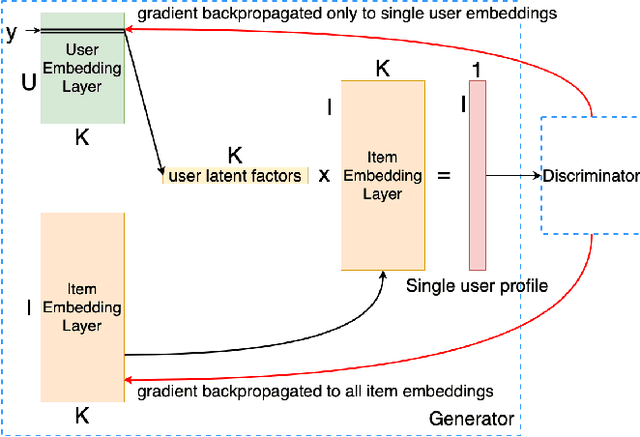
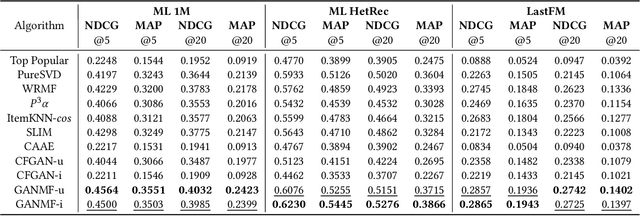
Proposed in 2014, Generative Adversarial Networks (GAN) initiated a fresh interest in generative modelling. They immediately achieved state-of-the-art in image synthesis, image-to-image translation, text-to-image generation, image inpainting and have been used in sciences ranging from medicine to high-energy particle physics. Despite their popularity and ability to learn arbitrary distributions, GAN have not been widely applied in recommender systems (RS). Moreover, only few of the techniques that have introduced GAN in RS have employed them directly as a collaborative filtering (CF) model. In this work we propose a new GAN-based approach that learns user and item latent factors in a matrix factorization setting for the generic top-N recommendation problem. Following the vector-wise GAN training approach for RS introduced by CFGAN, we identify 2 unique issues when utilizing GAN for CF. We propose solutions for both of them by using an autoencoder as discriminator and incorporating an additional loss function for the generator. We evaluate our model, GANMF, through well-known datasets in the RS community and show improvements over traditional CF approaches and GAN-based models. Through an ablation study on the components of GANMF we aim to understand the effects of our architectural choices. Finally, we provide a qualitative evaluation of the matrix factorization performance of GANMF.