 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Image Super-Resolution via Contrastive Representation Learning
Jul 01, 2021
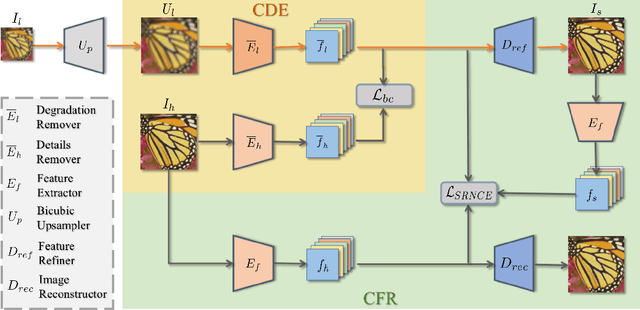

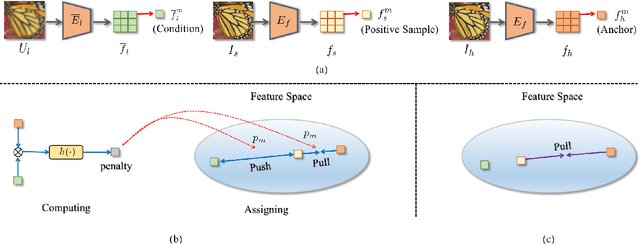
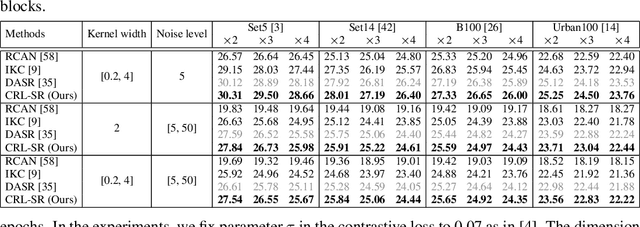
Image super-resolution (SR) research has witnessed impressive progress thanks to the advance of convolutional neural networks (CNNs) in recent years. However, most existing SR methods are non-blind and assume that degradation has a single fixed and known distribution (e.g., bicubic) which struggle while handling degradation in real-world data that usually follows a multi-modal, spatially variant, and unknown distribution. The recent blind SR studies address this issue via degradation estimation, but they do not generalize well to multi-source degradation and cannot handle spatially variant degradation. We design CRL-SR, a contrastive representation learning network that focuses on blind SR of images with multi-modal and spatially variant distributions. CRL-SR addresses the blind SR challenges from two perspectives. The first is contrastive decoupling encoding which introduces contrastive learning to extract resolution-invariant embedding and discard resolution-variant embedding under the guidance of a bidirectional contrastive loss. The second is contrastive feature refinement which generates lost or corrupted high-frequency details under the guidance of a conditional contrastive loss. Extensive experiments on synthetic datasets and real images show that the proposed CRL-SR can handle multi-modal and spatially variant degradation effectively under blind settings and it also outperforms state-of-the-art SR methods qualitatively and quantitatively.
Improving Point Cloud Based Place Recognition with Ranking-based Loss and Large Batch Training
Apr 07, 2022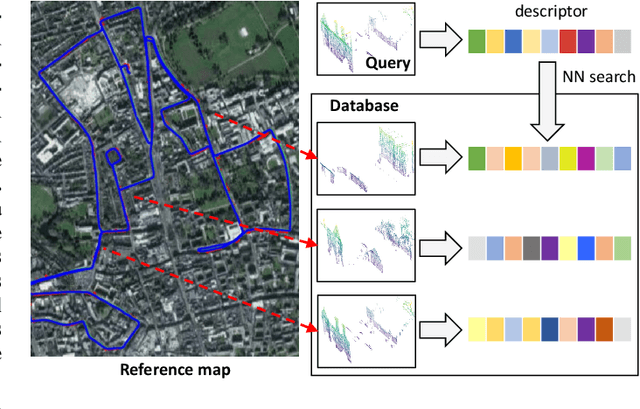
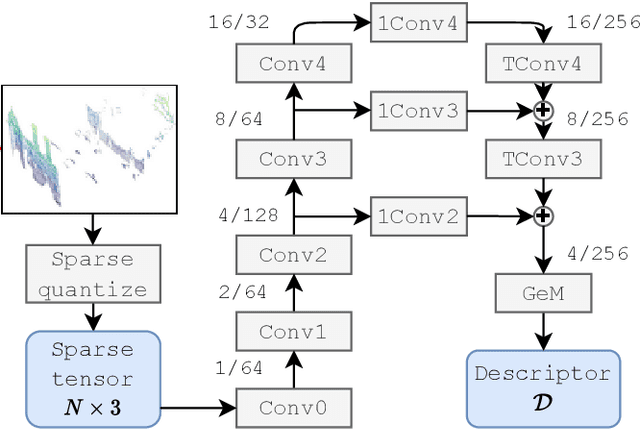
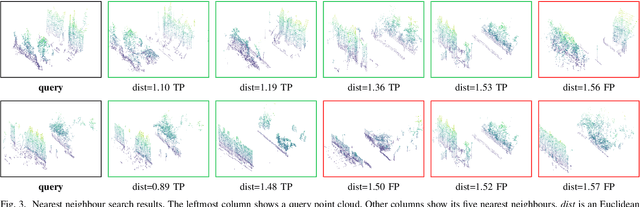
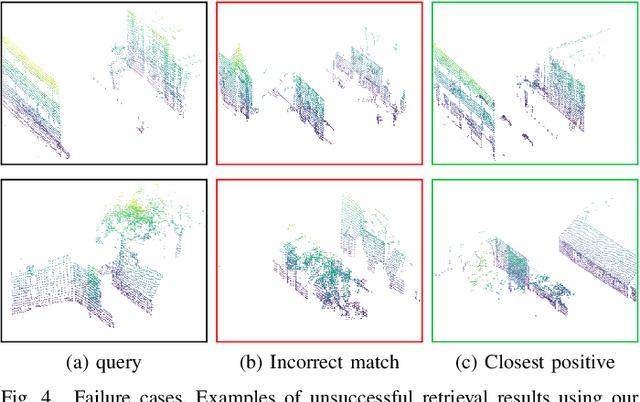
The paper presents a simple and effective learning-based method for computing a discriminative 3D point cloud descriptor for place recognition purposes. Recent state-of-the-art methods have relatively complex architectures such as multi-scale oyramid of point Transformers combined with a pyramid of feature aggregation modules. Our method uses a simple and efficient 3D convolutional feature extraction, based on a sparse voxelized representation, enhanced with channel attention blocks. We employ recent advances in image retrieval and propose a modified version of a loss function based on a differentiable average precision approximation. Such loss function requires training with very large batches for the best results. This is enabled by using multistaged backpropagation. Experimental evaluation on the popular benchmarks proves the effectiveness of our approach, with a consistent improvement over the state of the art
Multi-Stage Progressive Image Restoration
Feb 04, 2021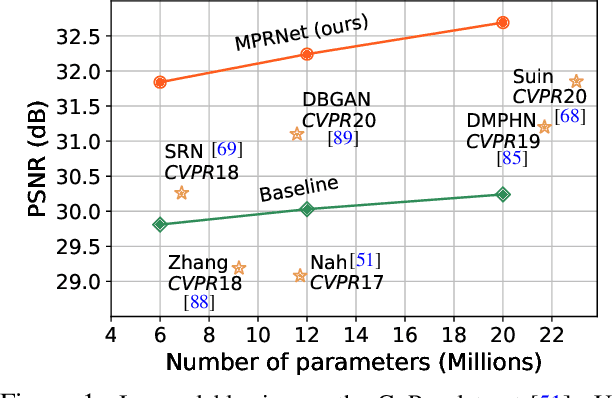

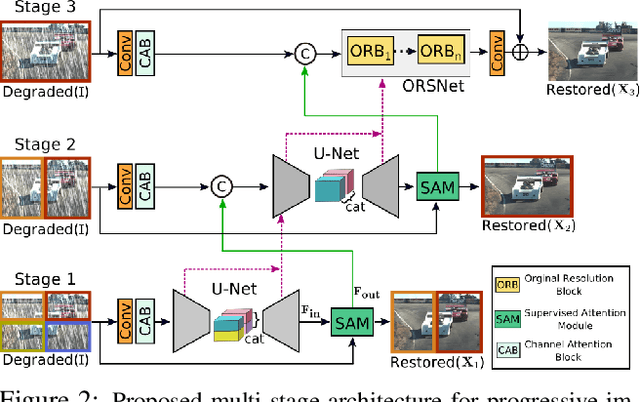
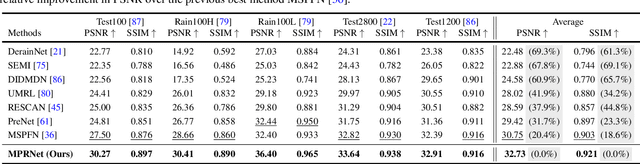
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022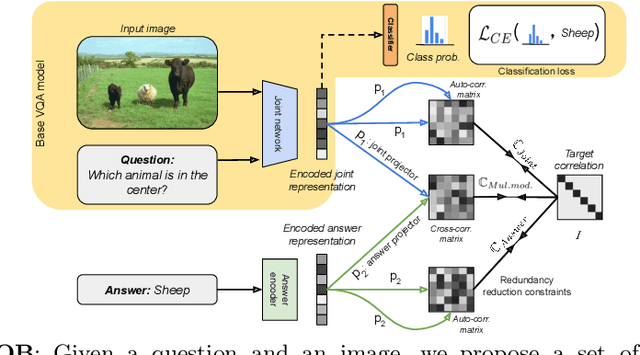
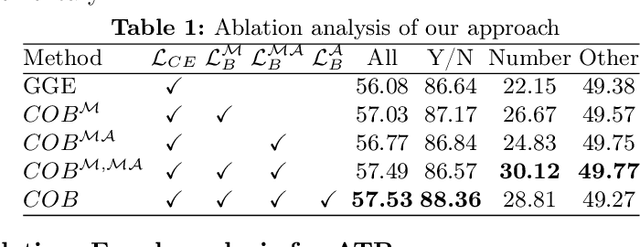
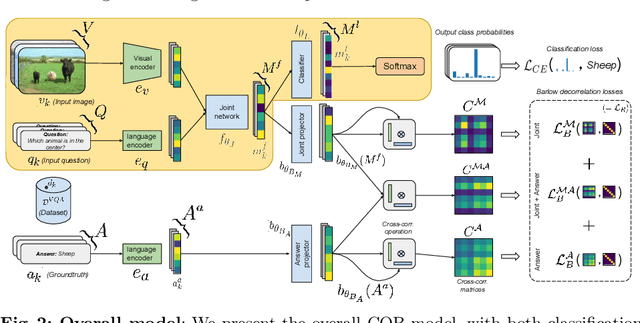
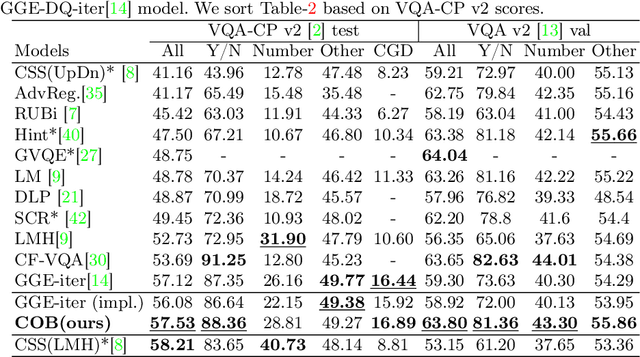
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.
Unlabeled Data Guided Semi-supervised Histopathology Image Segmentation
Dec 17, 2020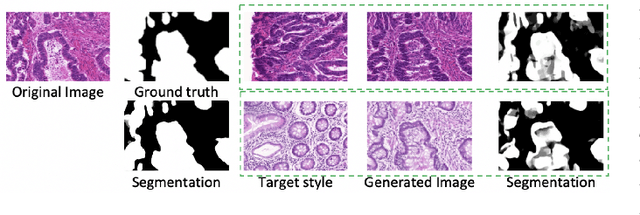
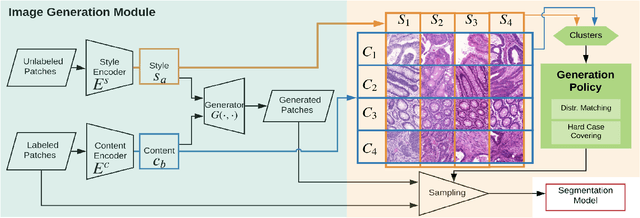
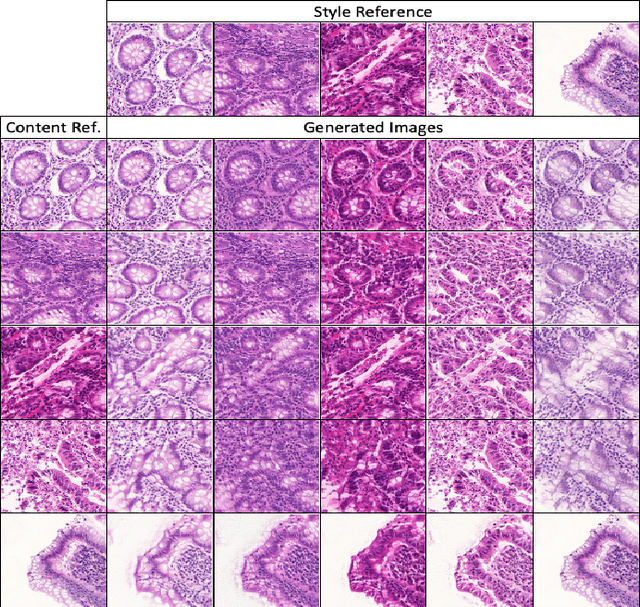
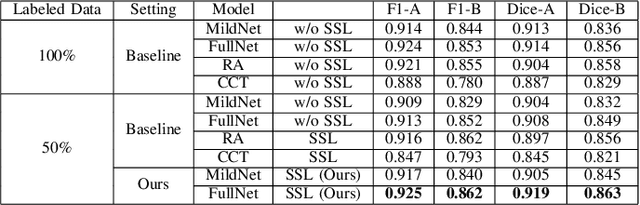
Automatic histopathology image segmentation is crucial to disease analysis. Limited available labeled data hinders the generalizability of trained models under the fully supervised setting. Semi-supervised learning (SSL) based on generative methods has been proven to be effective in utilizing diverse image characteristics. However, it has not been well explored what kinds of generated images would be more useful for model training and how to use such images. In this paper, we propose a new data guided generative method for histopathology image segmentation by leveraging the unlabeled data distributions. First, we design an image generation module. Image content and style are disentangled and embedded in a clustering-friendly space to utilize their distributions. New images are synthesized by sampling and cross-combining contents and styles. Second, we devise an effective data selection policy for judiciously sampling the generated images: (1) to make the generated training set better cover the dataset, the clusters that are underrepresented in the original training set are covered more; (2) to make the training process more effective, we identify and oversample the images of "hard cases" in the data for which annotated training data may be scarce. Our method is evaluated on glands and nuclei datasets. We show that under both the inductive and transductive settings, our SSL method consistently boosts the performance of common segmentation models and attains state-of-the-art results.
Free-breathing motion compensated 4D (3D+respiration) T2-weighted turbo spin-echo MRI for body imaging
Feb 07, 2022Purpose: To develop and evaluate a free-breathing respiratory motion compensated 4D (3D+respiration) $T_2$-weighted turbo spin echo sequence with application to radiology and MR-guided radiotherapy. Methods: k-space data are continuously acquired using a rewound Cartesian acquisition with spiral profile ordering (rCASPR) to provide matching contrast to the conventional linear phase encode ordering and to sort data into multiple respiratory phases. Low-resolution respiratory-correlated 4D images were reconstructed with compressed sensing and used to estimate non-rigid deformation vector fields, which were subsequently used for a motion compensated image reconstruction. rCASPR sampling was compared to linear and CASPR sampling in terms of point-spread-function (PSF) and image contrast with in silico, phantom and in vivo experiments. Reconstruction parameters for low-resolution 4D-MRI (spatial resolution and temporal regularization) were determined using a grid search. The proposed motion compensated rCASPR was evaluated in eight healthy volunteers and compared to free-breathing scans with linear sampling. Image quality was compared based on visual inspection and quantitatively by means of the gradient entropy. Results: rCASPR provided a superior PSF (similar in ky and narrower in kz) and showed no considerable differences in images contrast compared to linear sampling. The optimal 4D-MRI reconstruction parameters were spatial resolution=$4.5 mm^3$ and $\lambda_t=10^{-4}$. The groupwise average gradient entropy was 22.31 for linear, 22.20 for rCASPR, 22.14 for soft-gated rCASPR and 22.02 for motion compensated rCASPR. Conclusion: The proposed motion compensated rCASPR enables high quality free-breathing T2-TSE with minimal changes in image contrast and scan time. The proposed method therefore enables direct transfer of clinically used 3D TSE sequences to free-breathing.
Automated Grading of Radiographic Knee Osteoarthritis Severity Combined with Joint Space Narrowing
Mar 16, 2022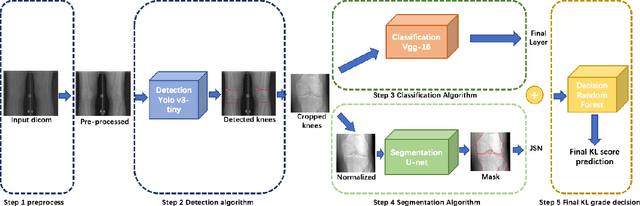
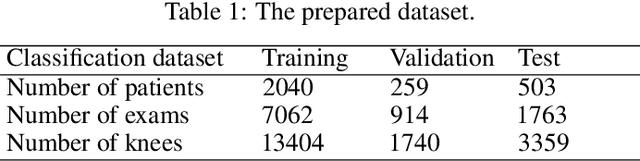
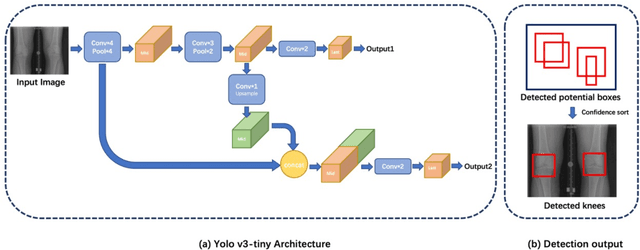
The assessment of knee osteoarthritis (KOA) severity on knee X-rays is a central criteria for the use of total knee arthroplasty. However, this assessment suffers from imprecise standards and a remarkably high inter-reader variability. An algorithmic, automated assessment of KOA severity could improve overall outcomes of knee replacement procedures by increasing the appropriateness of its use. We propose a novel deep learning-based five-step algorithm to automatically grade KOA from posterior-anterior (PA) views of radiographs: (1) image preprocessing (2) localization of knees joints in the image using the YOLO v3-Tiny model, (3) initial assessment of the severity of osteoarthritis using a convolutional neural network-based classifier, (4) segmentation of the joints and calculation of the joint space narrowing (JSN), and (5), a combination of the JSN and the initial assessment to determine a final Kellgren-Lawrence (KL) score. Furthermore, by displaying the segmentation masks used to make the assessment, our algorithm demonstrates a higher degree of transparency compared to typical "black box" deep learning classifiers. We perform a comprehensive evaluation using two public datasets and one dataset from our institution, and show that our algorithm reaches state-of-the art performance. Moreover, we also collected ratings from multiple radiologists at our institution and showed that our algorithm performs at the radiologist level. The software has been made publicly available at https://github.com/MaciejMazurowski/osteoarthritis-classification.
DocSegTr: An Instance-Level End-to-End Document Image Segmentation Transformer
Jan 27, 2022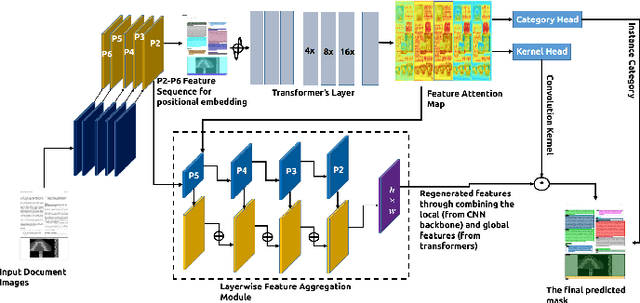

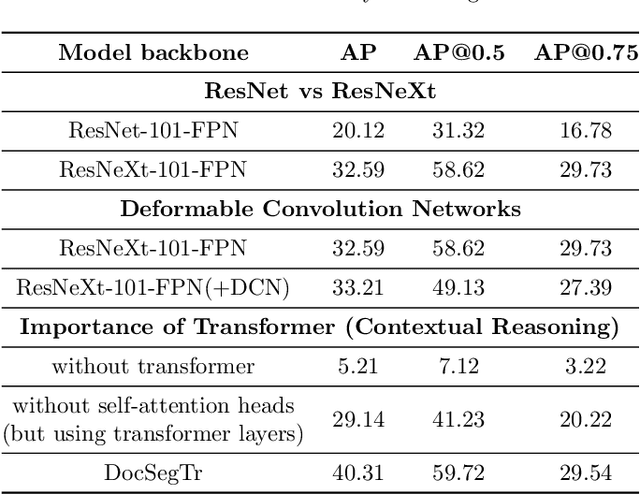
Understanding documents with rich layouts is an essential step towards information extraction. Business intelligence processes often require the extraction of useful semantic content from documents at a large scale for subsequent decision-making tasks. In this context, instance-level segmentation of different document objects(title, sections, figures, tables and so on) has emerged as an interesting problem for the document layout analysis community. To advance the research in this direction, we present a transformer-based model for end-to-end segmentation of complex layouts in document images. To our knowledge, this is the first work on transformer-based document segmentation. Extensive experimentation on the PubLayNet dataset shows that our model achieved comparable or better segmentation performance than the existing state-of-the-art approaches. We hope our simple and flexible framework could serve as a promising baseline for instance-level recognition tasks in document images.
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Jan 16, 2021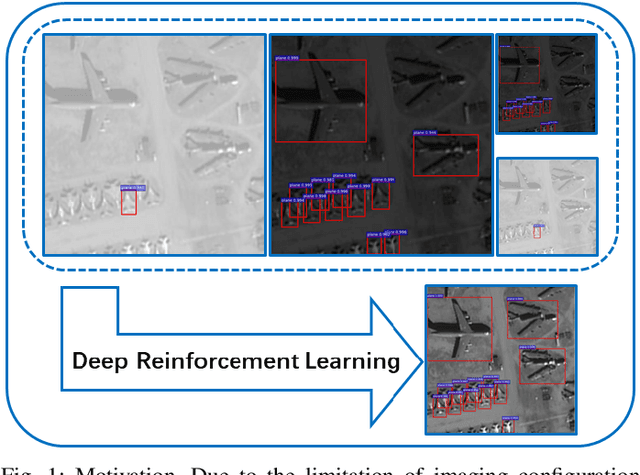
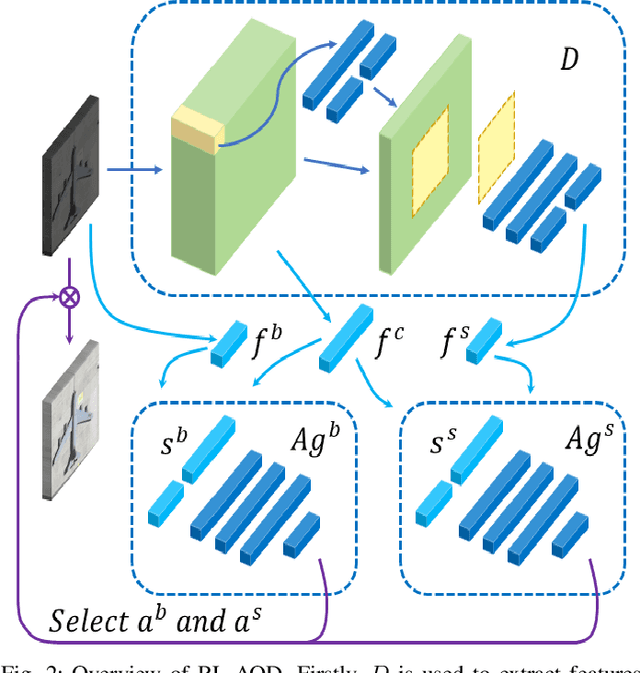
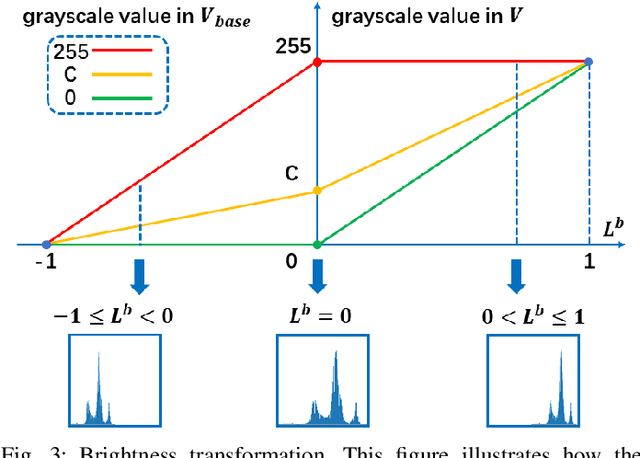
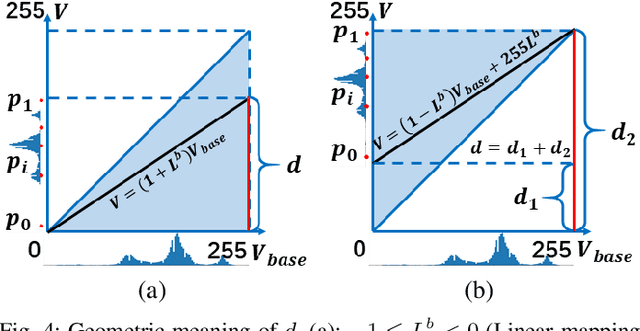
In recent years, deep learning methods bring incredible progress to the field of object detection. However, in the field of remote sensing image processing, existing methods neglect the relationship between imaging configuration and detection performance, and do not take into account the importance of detection performance feedback for improving image quality. Therefore, detection performance is limited by the passive nature of the conventional object detection framework. In order to solve the above limitations, this paper takes adaptive brightness adjustment and scale adjustment as examples, and proposes an active object detection method based on deep reinforcement learning. The goal of adaptive image attribute learning is to maximize the detection performance. With the help of active object detection and image attribute adjustment strategies, low-quality images can be converted into high-quality images, and the overall performance is improved without retraining the detector.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 04, 2022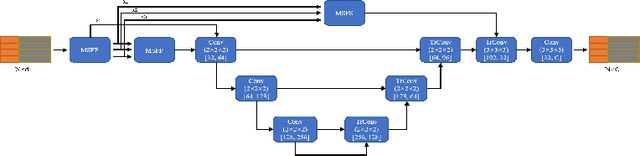
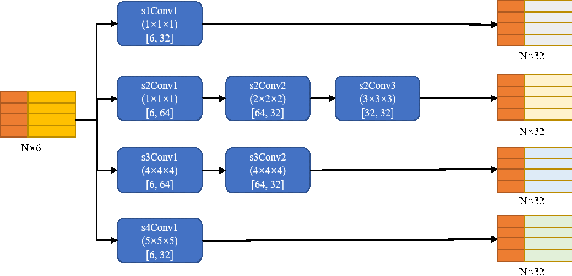
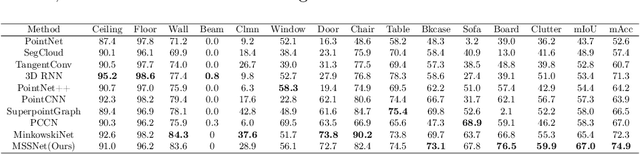
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.