 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022


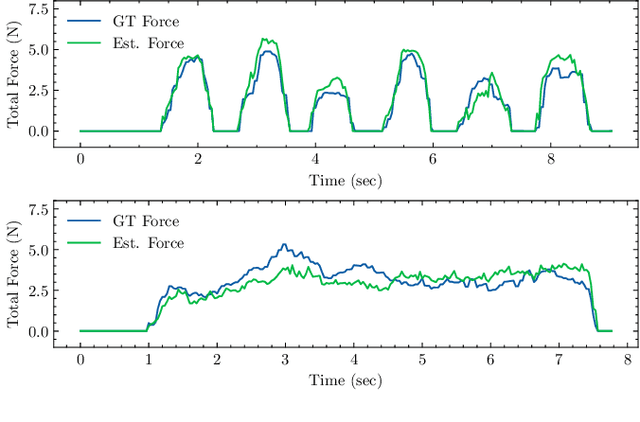
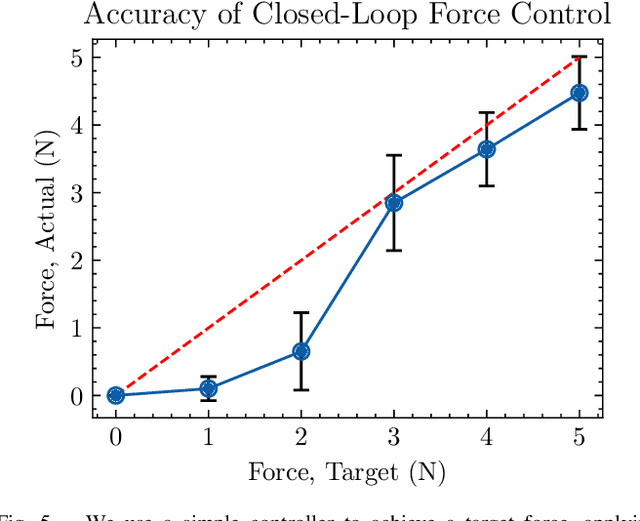
Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
Visual Servoing for Pose Control of Soft Continuum Arm in a Structured Environment
Feb 11, 2022
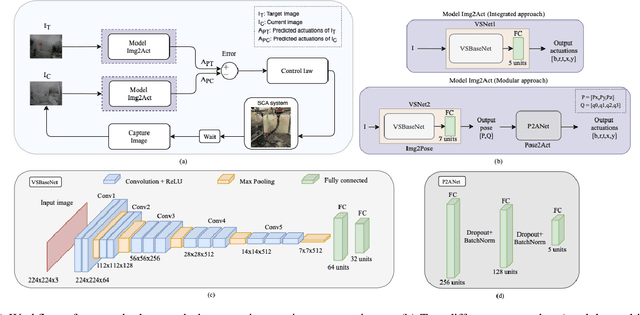

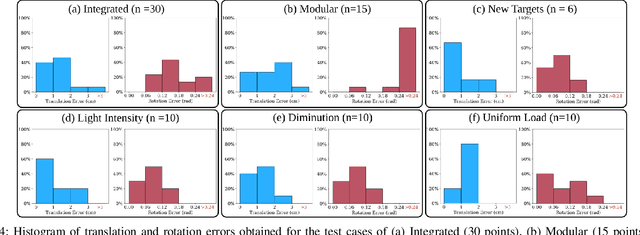
For soft continuum arms, visual servoing is a popular control strategy that relies on visual feedback to close the control loop. However, robust visual servoing is challenging as it requires reliable feature extraction from the image, accurate control models and sensors to perceive the shape of the arm, both of which can be hard to implement in a soft robot. This letter circumvents these challenges by presenting a deep neural network-based method to perform smooth and robust 3D positioning tasks on a soft arm by visual servoing using a camera mounted at the distal end of the arm. A convolutional neural network is trained to predict the actuations required to achieve the desired pose in a structured environment. Integrated and modular approaches for estimating the actuations from the image are proposed and are experimentally compared. A proportional control law is implemented to reduce the error between the desired and current image as seen by the camera. The model together with the proportional feedback control makes the described approach robust to several variations such as new targets, lighting, loads, and diminution of the soft arm. Furthermore, the model lends itself to be transferred to a new environment with minimal effort.
DeepI2P: Image-to-Point Cloud Registration via Deep Classification
Apr 08, 2021

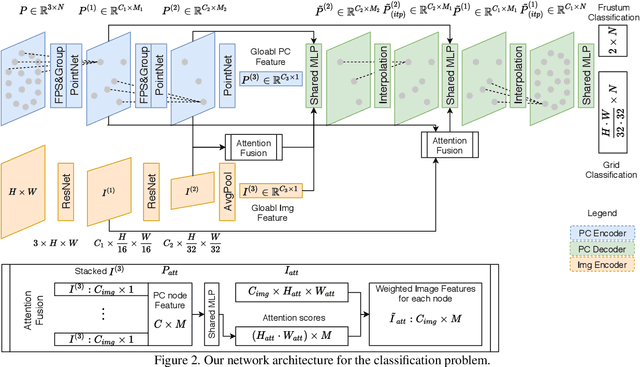
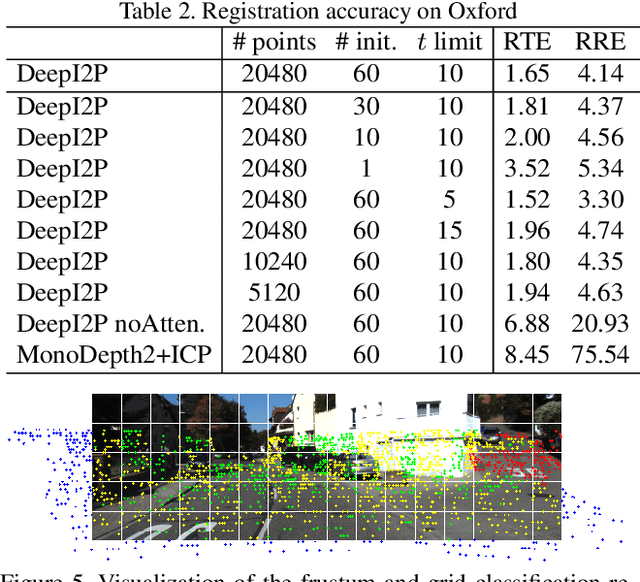
This paper presents DeepI2P: a novel approach for cross-modality registration between an image and a point cloud. Given an image (e.g. from a rgb-camera) and a general point cloud (e.g. from a 3D Lidar scanner) captured at different locations in the same scene, our method estimates the relative rigid transformation between the coordinate frames of the camera and Lidar. Learning common feature descriptors to establish correspondences for the registration is inherently challenging due to the lack of appearance and geometric correlations across the two modalities. We circumvent the difficulty by converting the registration problem into a classification and inverse camera projection optimization problem. A classification neural network is designed to label whether the projection of each point in the point cloud is within or beyond the camera frustum. These labeled points are subsequently passed into a novel inverse camera projection solver to estimate the relative pose. Extensive experimental results on Oxford Robotcar and KITTI datasets demonstrate the feasibility of our approach. Our source code is available at https://github.com/lijx10/DeepI2P
Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
Apr 12, 2021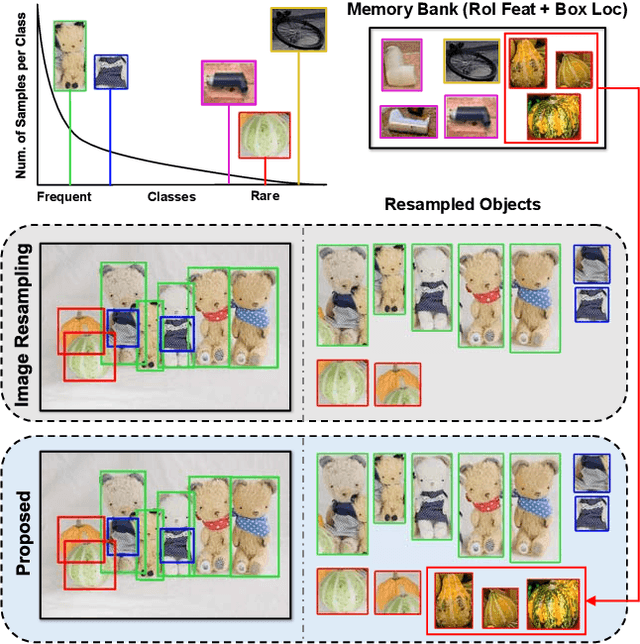
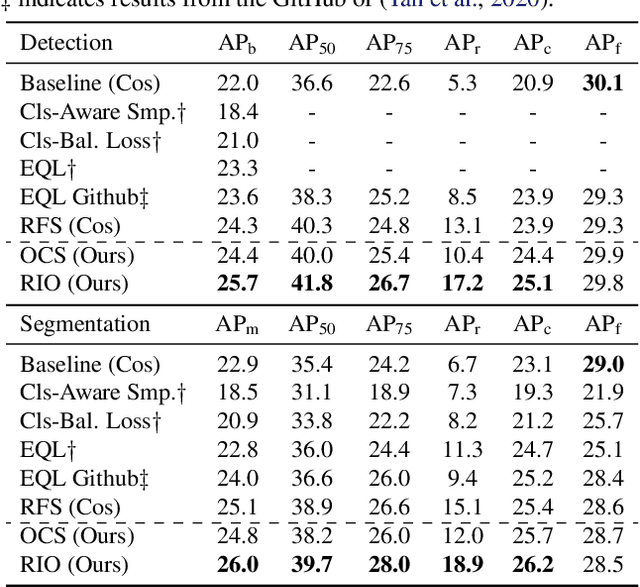

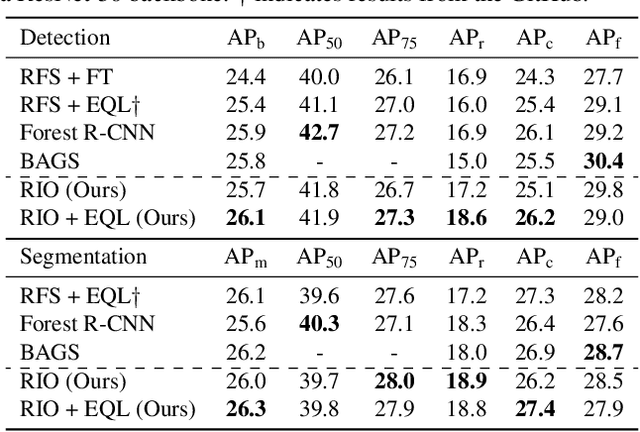
Training on datasets with long-tailed distributions has been challenging for major recognition tasks such as classification and detection. To deal with this challenge, image resampling is typically introduced as a simple but effective approach. However, we observe that long-tailed detection differs from classification since multiple classes may be present in one image. As a result, image resampling alone is not enough to yield a sufficiently balanced distribution at the object level. We address object-level resampling by introducing an object-centric memory replay strategy based on dynamic, episodic memory banks. Our proposed strategy has two benefits: 1) convenient object-level resampling without significant extra computation, and 2) implicit feature-level augmentation from model updates. We show that image-level and object-level resamplings are both important, and thus unify them with a joint resampling strategy (RIO). Our method outperforms state-of-the-art long-tailed detection and segmentation methods on LVIS v0.5 across various backbones.
Imposing Consistency for Optical Flow Estimation
Apr 14, 2022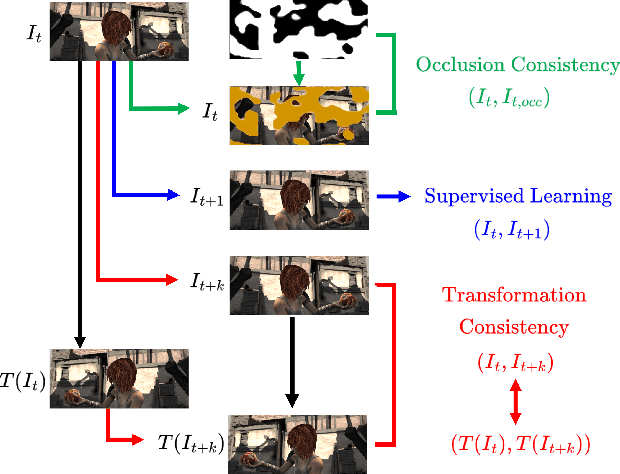
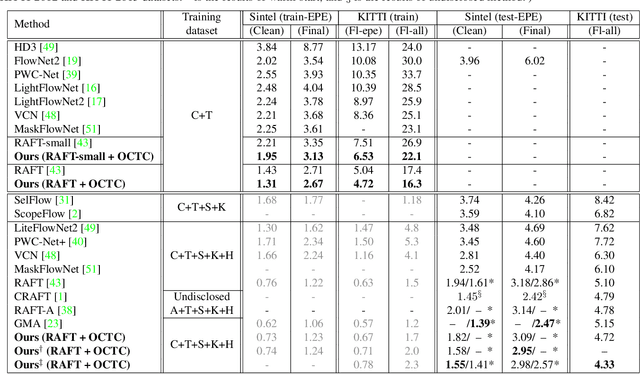

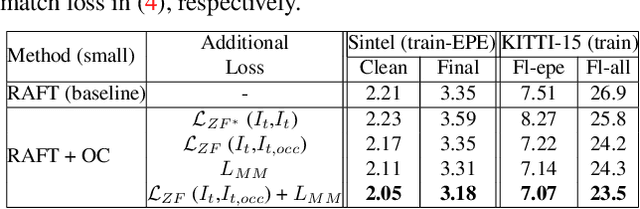
Imposing consistency through proxy tasks has been shown to enhance data-driven learning and enable self-supervision in various tasks. This paper introduces novel and effective consistency strategies for optical flow estimation, a problem where labels from real-world data are very challenging to derive. More specifically, we propose occlusion consistency and zero forcing in the forms of self-supervised learning and transformation consistency in the form of semi-supervised learning. We apply these consistency techniques in a way that the network model learns to describe pixel-level motions better while requiring no additional annotations. We demonstrate that our consistency strategies applied to a strong baseline network model using the original datasets and labels provide further improvements, attaining the state-of-the-art results on the KITTI-2015 scene flow benchmark in the non-stereo category. Our method achieves the best foreground accuracy (4.33% in Fl-all) over both the stereo and non-stereo categories, even though using only monocular image inputs.
RCMNet: A deep learning model assists CAR-T therapy for leukemia
May 06, 2022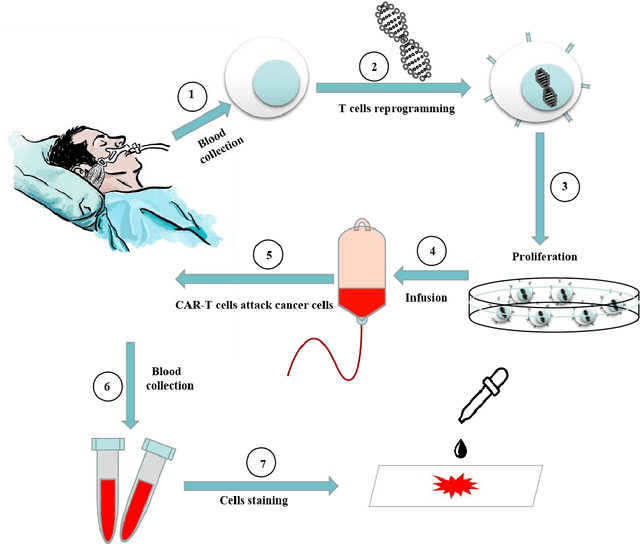
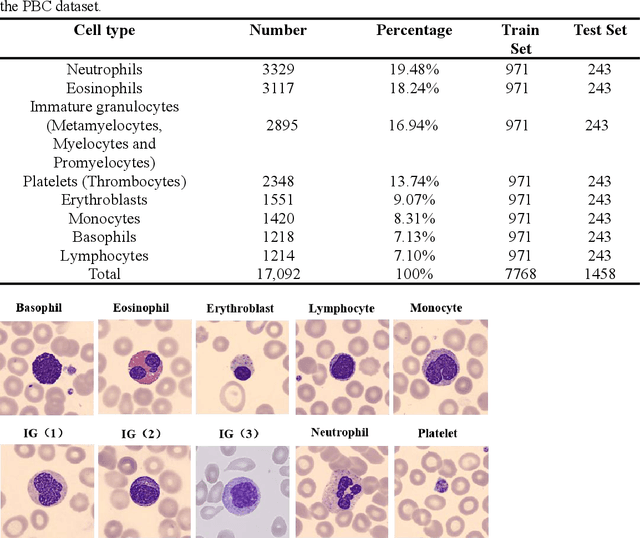
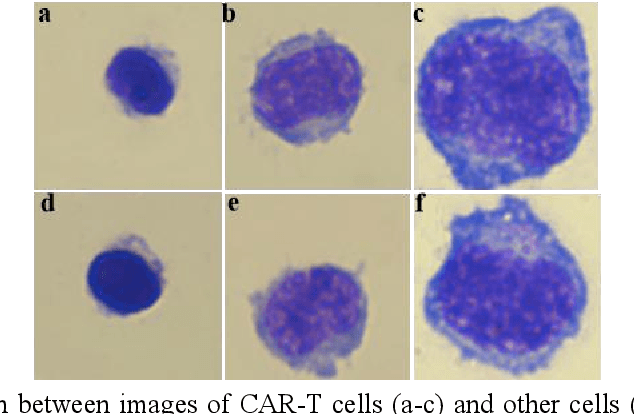

Acute leukemia is a type of blood cancer with a high mortality rate. Current therapeutic methods include bone marrow transplantation, supportive therapy, and chemotherapy. Although a satisfactory remission of the disease can be achieved, the risk of recurrence is still high. Therefore, novel treatments are demanding. Chimeric antigen receptor-T (CAR-T) therapy has emerged as a promising approach to treat and cure acute leukemia. To harness the therapeutic potential of CAR-T cell therapy for blood diseases, reliable cell morphological identification is crucial. Nevertheless, the identification of CAR-T cells is a big challenge posed by their phenotypic similarity with other blood cells. To address this substantial clinical challenge, herein we first construct a CAR-T dataset with 500 original microscopy images after staining. Following that, we create a novel integrated model called RCMNet (ResNet18 with CBAM and MHSA) that combines the convolutional neural network (CNN) and Transformer. The model shows 99.63% top-1 accuracy on the public dataset. Compared with previous reports, our model obtains satisfactory results for image classification. Although testing on the CAR-T cells dataset, a decent performance is observed, which is attributed to the limited size of the dataset. Transfer learning is adapted for RCMNet and a maximum of 83.36% accuracy has been achieved, which is higher than other SOTA models. The study evaluates the effectiveness of RCMNet on a big public dataset and translates it to a clinical dataset for diagnostic applications.
SLIP: Self-supervision meets Language-Image Pre-training
Dec 23, 2021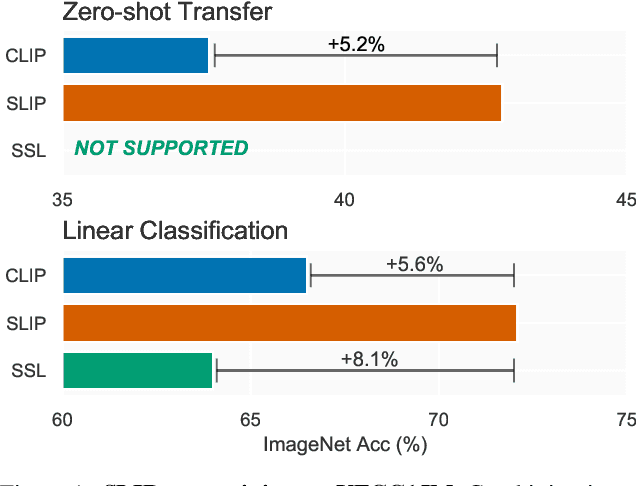
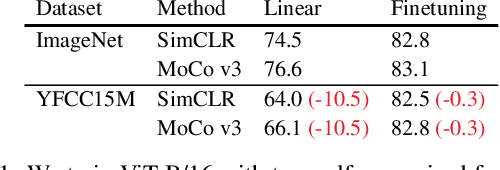
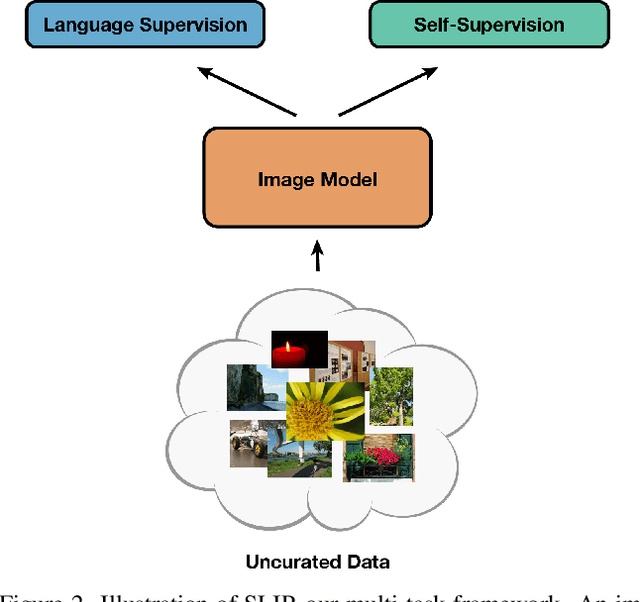
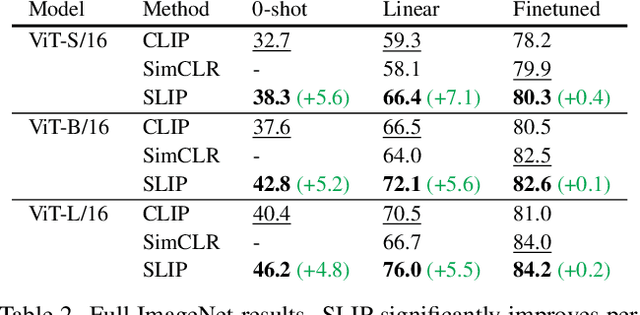
Recent work has shown that self-supervised pre-training leads to improvements over supervised learning on challenging visual recognition tasks. CLIP, an exciting new approach to learning with language supervision, demonstrates promising performance on a wide variety of benchmarks. In this work, we explore whether self-supervised learning can aid in the use of language supervision for visual representation learning. We introduce SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. After pre-training with Vision Transformers, we thoroughly evaluate representation quality and compare performance to both CLIP and self-supervised learning under three distinct settings: zero-shot transfer, linear classification, and end-to-end finetuning. Across ImageNet and a battery of additional datasets, we find that SLIP improves accuracy by a large margin. We validate our results further with experiments on different model sizes, training schedules, and pre-training datasets. Our findings show that SLIP enjoys the best of both worlds: better performance than self-supervision (+8.1% linear accuracy) and language supervision (+5.2% zero-shot accuracy).
Structured DropConnect for Uncertainty Inference in Image Classification
Jun 16, 2021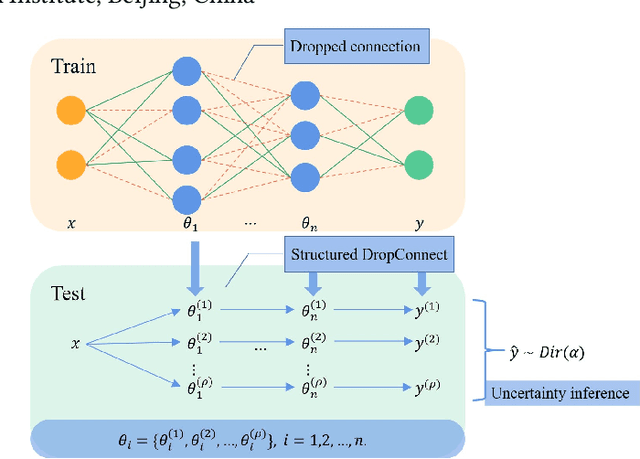


With the complexity of the network structure, uncertainty inference has become an important task to improve the classification accuracy for artificial intelligence systems. For image classification tasks, we propose a structured DropConnect (SDC) framework to model the output of a deep neural network by a Dirichlet distribution. We introduce a DropConnect strategy on weights in the fully connected layers during training. In test, we split the network into several sub-networks, and then model the Dirichlet distribution by match its moments with the mean and variance of the outputs of these sub-networks. The entropy of the estimated Dirichlet distribution is finally utilized for uncertainty inference. In this paper, this framework is implemented on LeNet$5$ and VGG$16$ models for misclassification detection and out-of-distribution detection on MNIST and CIFAR-$10$ datasets. Experimental results show that the performance of the proposed SDC can be comparable to other uncertainty inference methods. Furthermore, the SDC is adapted well to different network structures with certain generalization capabilities and research prospects.
Rate Distortion Characteristic Modeling for Neural Image Compression
Jun 24, 2021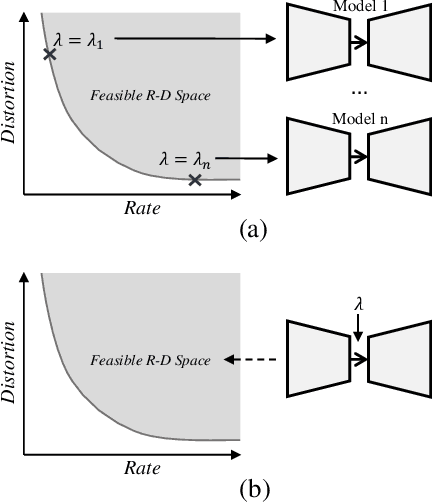

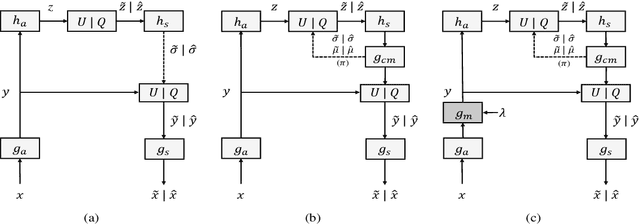
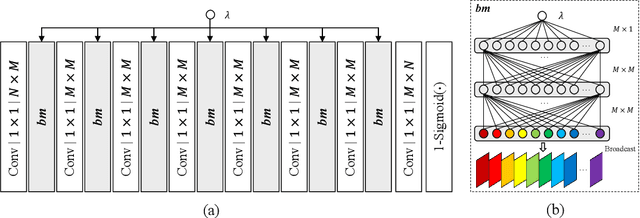
End-to-end optimization capability offers neural image compression (NIC) superior lossy compression performance. However, distinct models are required to be trained to reach different points in the rate-distortion (R-D) space. In this paper, we consider the problem of R-D characteristic analysis and modeling for NIC. We make efforts to formulate the essential mathematical functions to describe the R-D behavior of NIC using deep network and statistical modeling. Thus continuous bit-rate points could be elegantly realized by leveraging such model via a single trained network. In this regard, we propose a plugin-in module to learn the relationship between the target bit-rate and the binary representation for the latent variable of auto-encoder. Furthermore, we model the rate and distortion characteristic of NIC as a function of the coding parameter $\lambda$ respectively. Our experiments show our proposed method is easy to adopt and obtains competitive coding performance with fixed-rate coding approaches, which would benefit the practical deployment of NIC. In addition, the proposed model could be applied to NIC rate control with limited bit-rate error using a single network.
Test-Time Training Can Close the Natural Distribution Shift Performance Gap in Deep Learning Based Compressed Sensing
Apr 14, 2022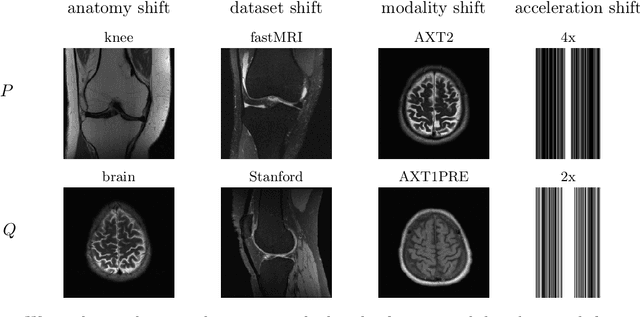
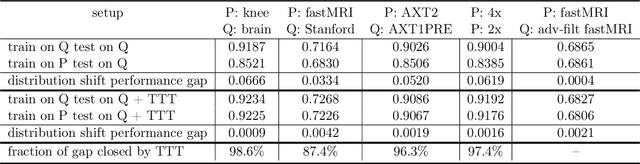

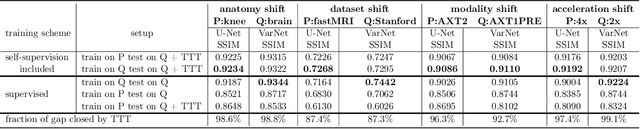
Deep learning based image reconstruction methods outperform traditional methods in accuracy and runtime. However, neural networks suffer from a performance drop when applied to images from a different distribution than the training images. For example, a model trained for reconstructing knees in accelerated magnetic resonance imaging (MRI) does not reconstruct brains well, even though the same network trained on brains reconstructs brains perfectly well. Thus there is a distribution shift performance gap for a given neural network, defined as the difference in performance when training on a distribution $P$ and training on another distribution $Q$, and evaluating both models on $Q$. In this work, we propose a domain adaptation method for deep learning based compressive sensing that relies on self-supervision during training paired with test-time training at inference. We show that for four natural distribution shifts, this method essentially closes the distribution shift performance gap for state-of-the-art architectures for accelerated MRI.