 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022
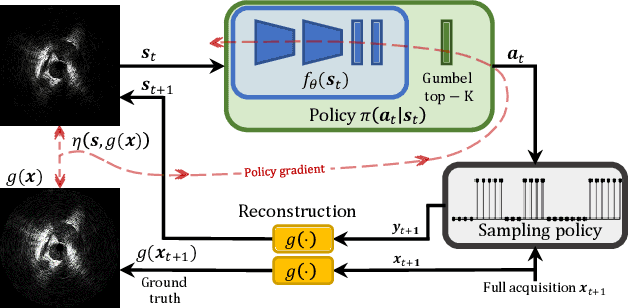
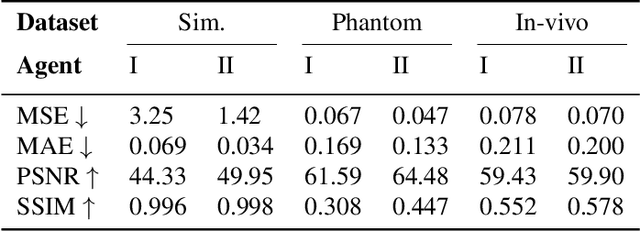

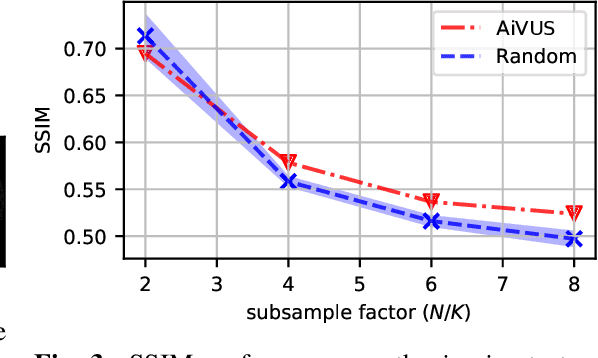
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022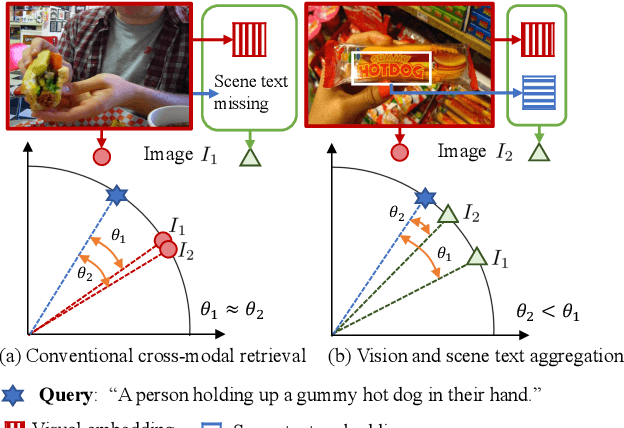

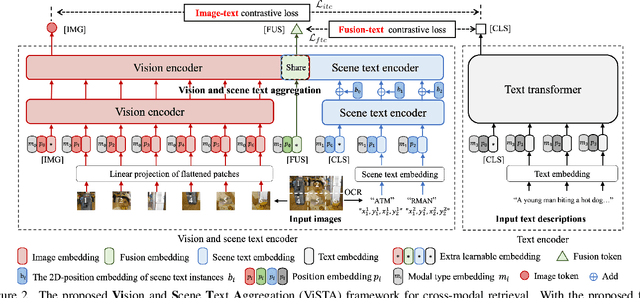

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.
M2FN: Multi-step Modality Fusion for Advertisement Image Assessment
Feb 09, 2021
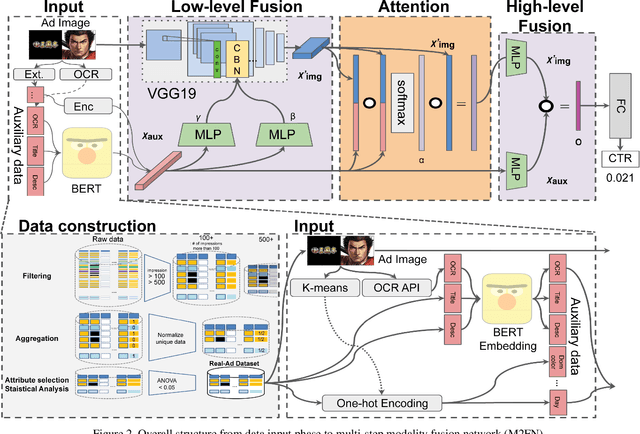
Assessing advertisements, specifically on the basis of user preferences and ad quality, is crucial to the marketing industry. Although recent studies have attempted to use deep neural networks for this purpose, these studies have not utilized image-related auxiliary attributes, which include embedded text frequently found in ad images. We, therefore, investigated the influence of these attributes on ad image preferences. First, we analyzed large-scale real-world ad log data and, based on our findings, proposed a novel multi-step modality fusion network (M2FN) that determines advertising images likely to appeal to user preferences. Our method utilizes auxiliary attributes through multiple steps in the network, which include conditional batch normalization-based low-level fusion and attention-based high-level fusion. We verified M2FN on the AVA dataset, which is widely used for aesthetic image assessment, and then demonstrated that M2FN can achieve state-of-the-art performance in preference prediction using a real-world ad dataset with rich auxiliary attributes.
Indoor Navigation Assistance for Visually Impaired People via Dynamic SLAM and Panoptic Segmentation with an RGB-D Sensor
Apr 03, 2022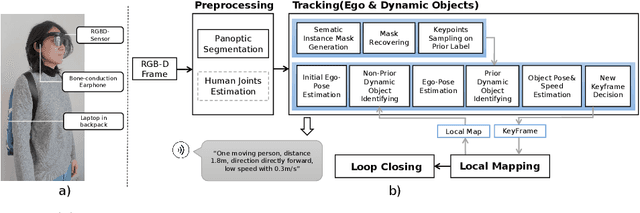
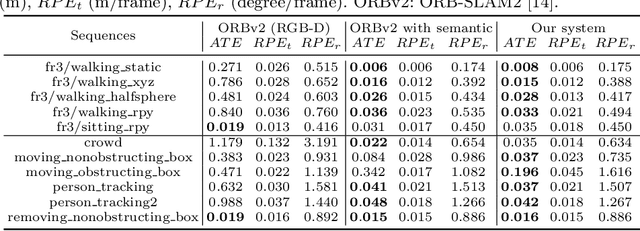


Exploring an unfamiliar indoor environment and avoiding obstacles is challenging for visually impaired people. Currently, several approaches achieve the avoidance of static obstacles based on the mapping of indoor scenes. To solve the issue of distinguishing dynamic obstacles, we propose an assistive system with an RGB-D sensor to detect dynamic information of a scene. Once the system captures an image, panoptic segmentation is performed to obtain the prior dynamic object information. With sparse feature points extracted from images and the depth information, poses of the user can be estimated. After the ego-motion estimation, the dynamic object can be identified and tracked. Then, poses and speed of tracked dynamic objects can be estimated, which are passed to the users through acoustic feedback.
Crowd counting with segmentation attention convolutional neural network
Apr 15, 2022

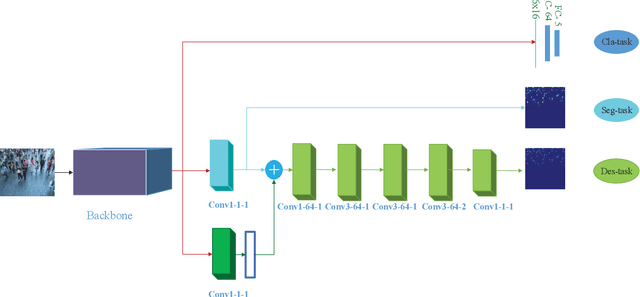
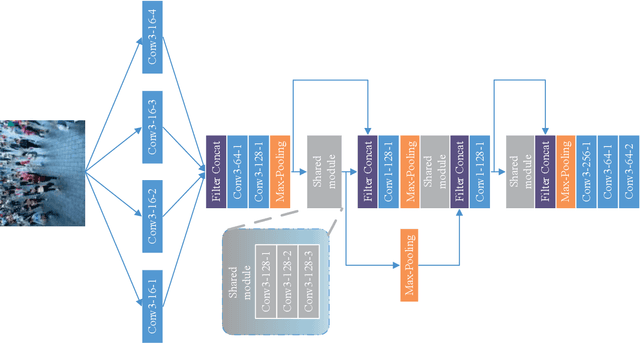
Deep learning occupies an undisputed dominance in crowd counting. In this paper, we propose a novel convolutional neural network (CNN) architecture called SegCrowdNet. Despite the complex background in crowd scenes, the proposeSegCrowdNet still adaptively highlights the human head region and suppresses the non-head region by segmentation. With the guidance of an attention mechanism, the proposed SegCrowdNet pays more attention to the human head region and automatically encodes the highly refined density map. The crowd count can be obtained by integrating the density map. To adapt the variation of crowd counts, SegCrowdNet intelligently classifies the crowd count of each image into several groups. In addition, the multi-scale features are learned and extracted in the proposed SegCrowdNet to overcome the scale variations of the crowd. To verify the effectiveness of our proposed method, extensive experiments are conducted on four challenging datasets. The results demonstrate that our proposed SegCrowdNet achieves excellent performance compared with the state-of-the-art methods.
* Accepted by IET Image Processing
2D Image Relighting with Image-to-Image Translation
Jun 14, 2020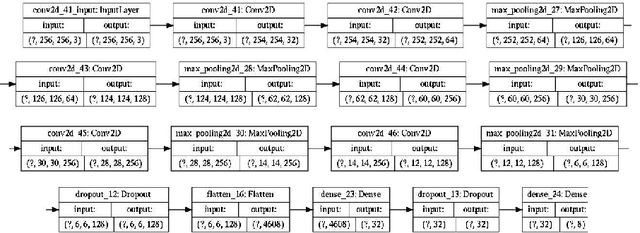
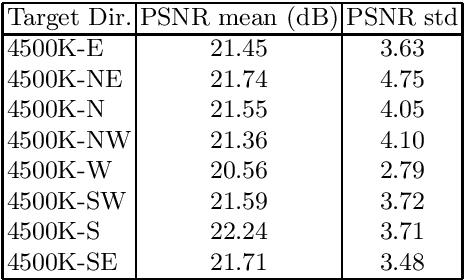
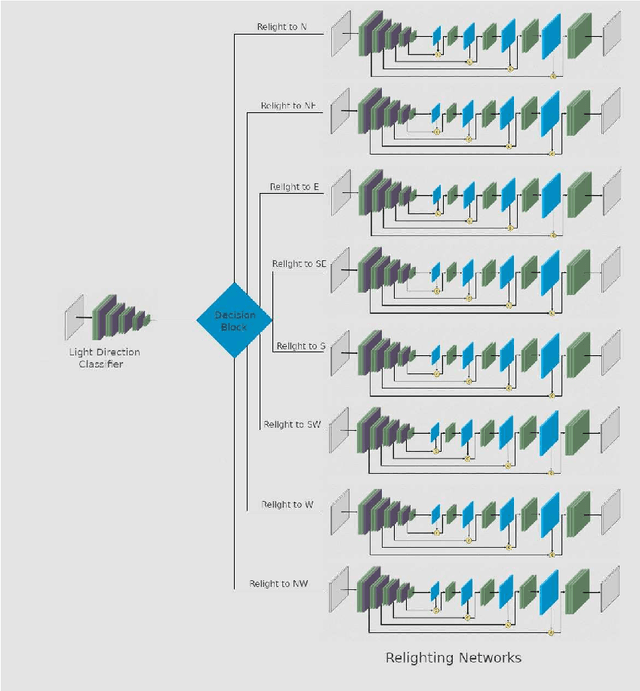
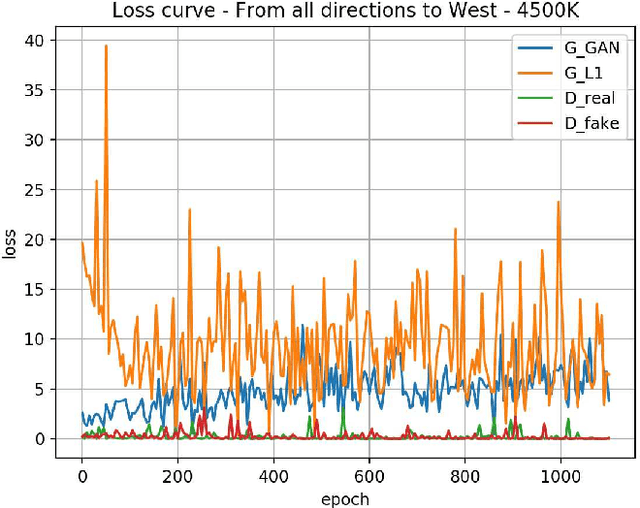
With the advent of Generative Adversarial Networks (GANs), a finer level of control in manipulating various features of an image has become possible. One example of such fine manipulation is changing the position of the light source in a scene. This is fundamentally an ill-posed problem, since it requires understanding the scene geometry to generate proper lighting effects. This problem is not a trivial one and can become even more complicated if we want to change the direction of the light source from any direction to a specific one. Here we provide our attempt to solve this problem using GANs. Specifically, pix2pix [arXiv:1611.07004] trained with the dataset VIDIT [arXiv:2005.05460] which contains images of the same scene with different types of light temperature and 8 different light source positions (N, NE, E, SE, S, SW, W, NW). The results are 8 neural networks trained to be able to change the direction of the light source from any direction to one of the 8 previously mentioned. Additionally, we provide, as a tool, a simple CNN trained to identify the direction of the light source in an image.
3D Object Detection from Images for Autonomous Driving: A Survey
Feb 07, 2022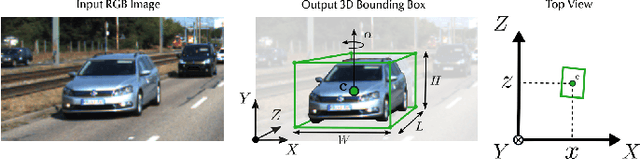
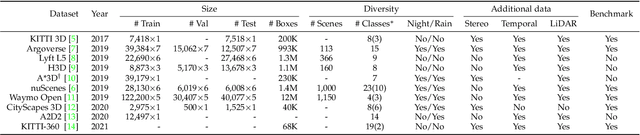
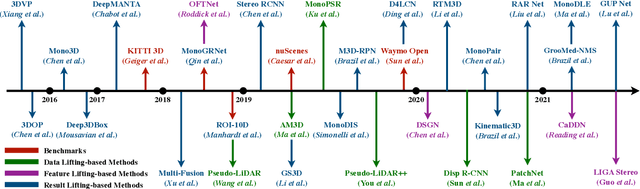
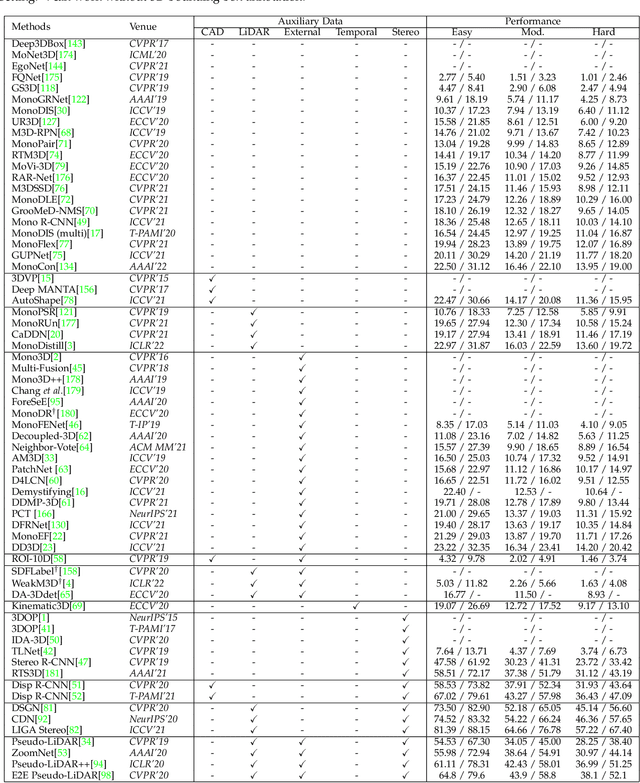
3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. Additionally, we also propose two new taxonomies to organize the state-of-the-art methods into different categories, with the intent of providing a more systematic review of existing methods and facilitating fair comparisons with future works. In retrospect of what has been achieved so far, we also analyze the current challenges in the field and discuss future directions for image-based 3D detection research.
Conditional Autoregressors are Interpretable Classifiers
Mar 31, 2022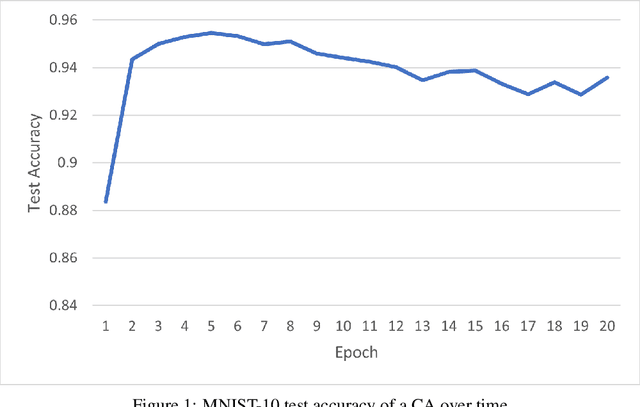
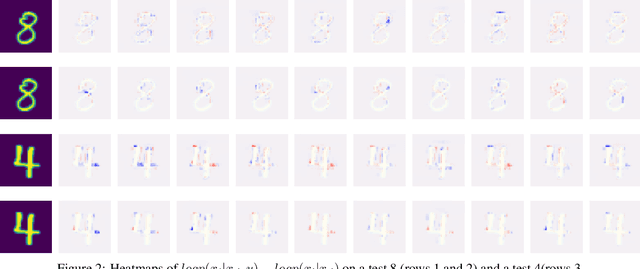
We explore the use of class-conditional autoregressive (CA) models to perform image classification on MNIST-10. Autoregressive models assign probability to an entire input by combining probabilities from each individual feature; hence classification decisions made by a CA can be readily decomposed into contributions from each each input feature. That is to say, CA are inherently locally interpretable. Our experiments show that naively training a CA achieves much worse accuracy compared to a standard classifier, however this is due to over-fitting and not a lack of expressive power. Using knowledge distillation from a standard classifier, a student CA can be trained to match the performance of the teacher while still being interpretable.
All Grains, One Scheme (AGOS): Learning Multi-grain Instance Representation for Aerial Scene Classification
May 06, 2022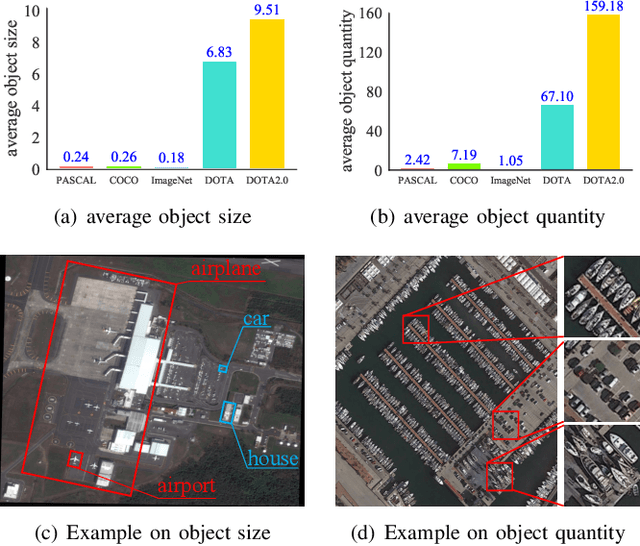
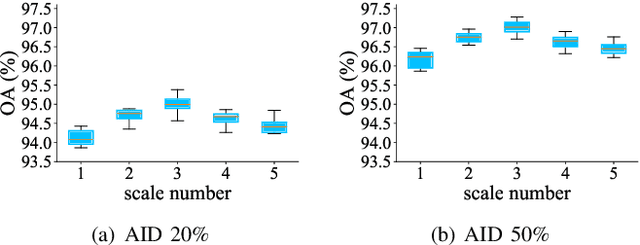
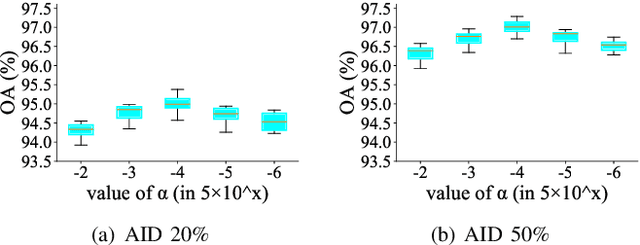
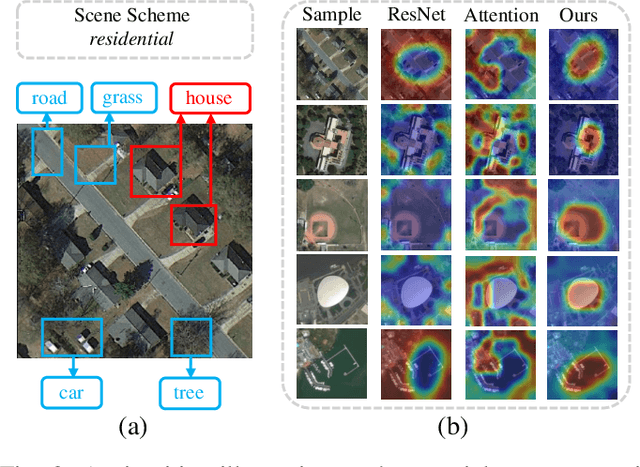
Aerial scene classification remains challenging as: 1) the size of key objects in determining the scene scheme varies greatly; 2) many objects irrelevant to the scene scheme are often flooded in the image. Hence, how to effectively perceive the region of interests (RoIs) from a variety of sizes and build more discriminative representation from such complicated object distribution is vital to understand an aerial scene. In this paper, we propose a novel all grains, one scheme (AGOS) framework to tackle these challenges. To the best of our knowledge, it is the first work to extend the classic multiple instance learning into multi-grain formulation. Specially, it consists of a multi-grain perception module (MGP), a multi-branch multi-instance representation module (MBMIR) and a self-aligned semantic fusion (SSF) module. Firstly, our MGP preserves the differential dilated convolutional features from the backbone, which magnifies the discriminative information from multi-grains. Then, our MBMIR highlights the key instances in the multi-grain representation under the MIL formulation. Finally, our SSF allows our framework to learn the same scene scheme from multi-grain instance representations and fuses them, so that the entire framework is optimized as a whole. Notably, our AGOS is flexible and can be easily adapted to existing CNNs in a plug-and-play manner. Extensive experiments on UCM, AID and NWPU benchmarks demonstrate that our AGOS achieves a comparable performance against the state-of-the-art methods.
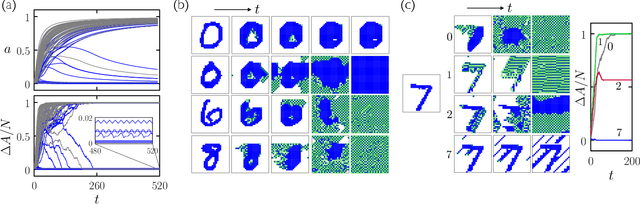
Cellular automata can classify data by inducing trajectory phase coexistence
Apr 06, 2022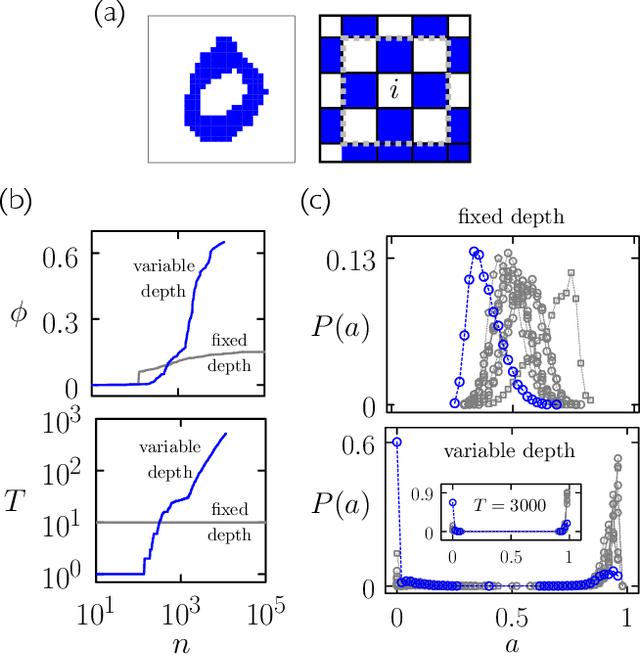
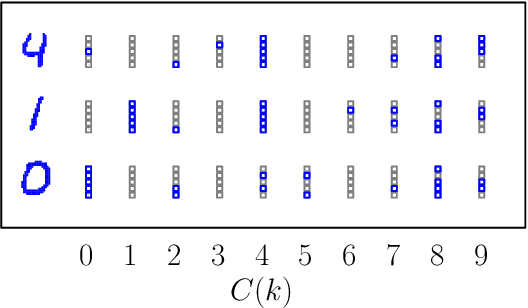
We show that cellular automata can classify data by inducing a form of dynamical phase coexistence. We use Monte Carlo methods to search for general two-dimensional deterministic automata that classify images on the basis of activity, the number of state changes that occur in a trajectory initiated from the image. When the depth of the automaton is a trainable parameter, the search scheme identifies automata that generate a population of dynamical trajectories displaying high or low activity, depending on initial conditions. Automata of this nature behave as nonlinear activation functions with an output that is effectively binary, resembling an emergent version of a spiking neuron. Our work connects machine learning and reservoir computing to phenomena conceptually similar to those seen in physical systems such as magnets and glasses.