 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Copy Motion From One to Another: Fake Motion Video Generation
May 03, 2022
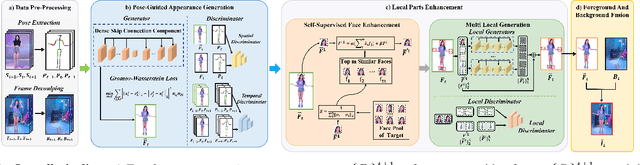
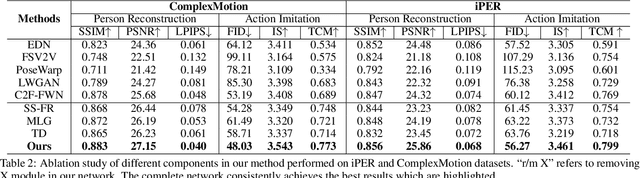
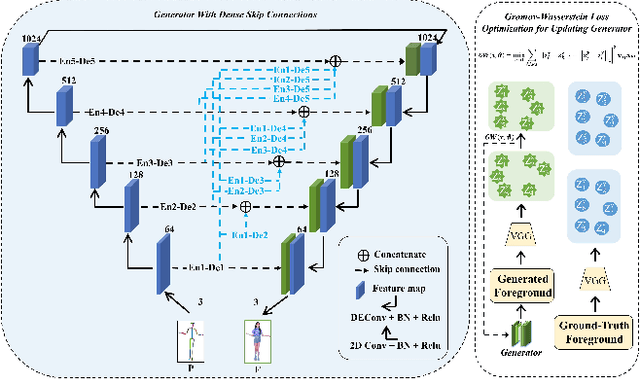
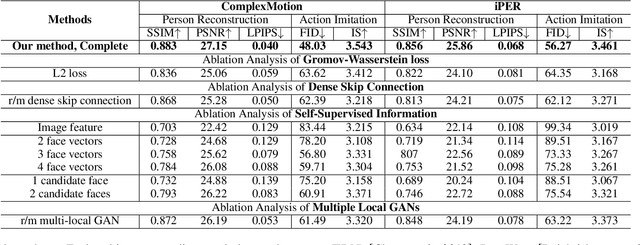
One compelling application of artificial intelligence is to generate a video of a target person performing arbitrary desired motion (from a source person). While the state-of-the-art methods are able to synthesize a video demonstrating similar broad stroke motion details, they are generally lacking in texture details. A pertinent manifestation appears as distorted face, feet, and hands, and such flaws are very sensitively perceived by human observers. Furthermore, current methods typically employ GANs with a L2 loss to assess the authenticity of the generated videos, inherently requiring a large amount of training samples to learn the texture details for adequate video generation. In this work, we tackle these challenges from three aspects: 1) We disentangle each video frame into foreground (the person) and background, focusing on generating the foreground to reduce the underlying dimension of the network output. 2) We propose a theoretically motivated Gromov-Wasserstein loss that facilitates learning the mapping from a pose to a foreground image. 3) To enhance texture details, we encode facial features with geometric guidance and employ local GANs to refine the face, feet, and hands. Extensive experiments show that our method is able to generate realistic target person videos, faithfully copying complex motions from a source person. Our code and datasets are released at https://github.com/Sifann/FakeMotion
Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers
Apr 25, 2022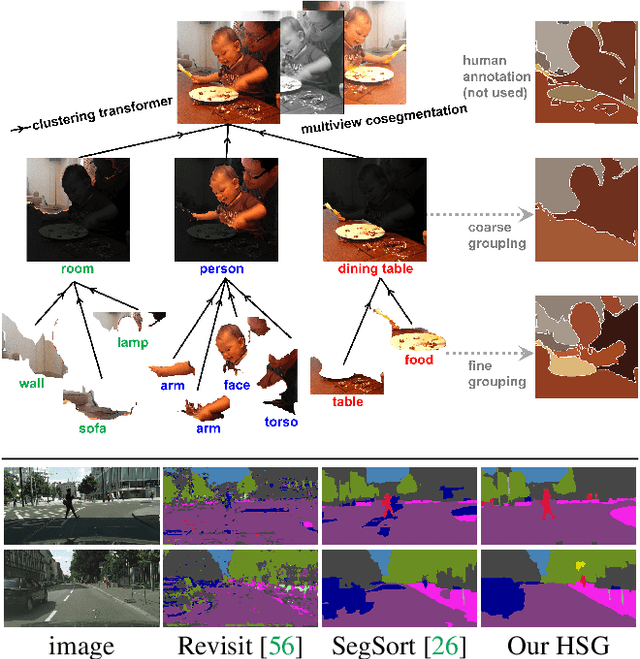
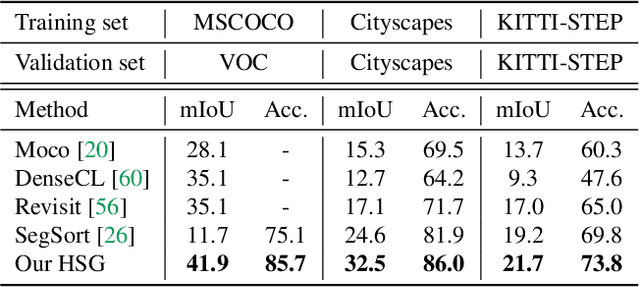
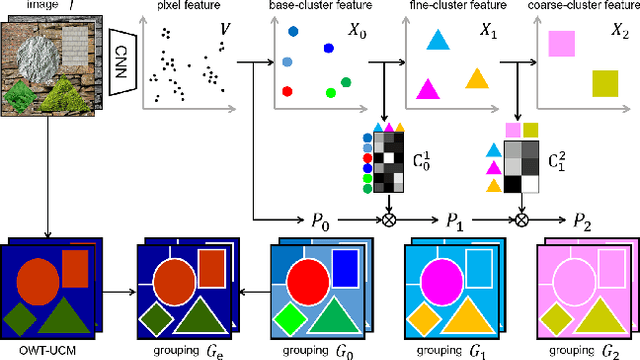
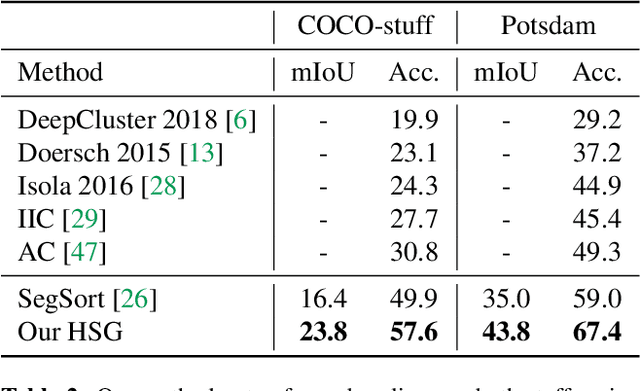
Unsupervised semantic segmentation aims to discover groupings within and across images that capture object and view-invariance of a category without external supervision. Grouping naturally has levels of granularity, creating ambiguity in unsupervised segmentation. Existing methods avoid this ambiguity and treat it as a factor outside modeling, whereas we embrace it and desire hierarchical grouping consistency for unsupervised segmentation. We approach unsupervised segmentation as a pixel-wise feature learning problem. Our idea is that a good representation shall reveal not just a particular level of grouping, but any level of grouping in a consistent and predictable manner. We enforce spatial consistency of grouping and bootstrap feature learning with co-segmentation among multiple views of the same image, and enforce semantic consistency across the grouping hierarchy with clustering transformers between coarse- and fine-grained features. We deliver the first data-driven unsupervised hierarchical semantic segmentation method called Hierarchical Segment Grouping (HSG). Capturing visual similarity and statistical co-occurrences, HSG also outperforms existing unsupervised segmentation methods by a large margin on five major object- and scene-centric benchmarks. Our code is publicly available at https://github.com/twke18/HSG .
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Dec 04, 2020
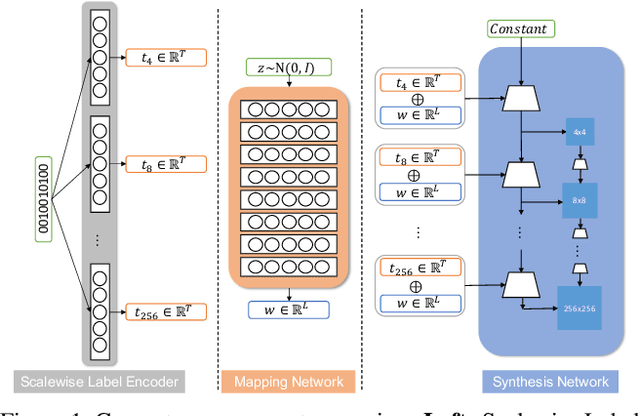
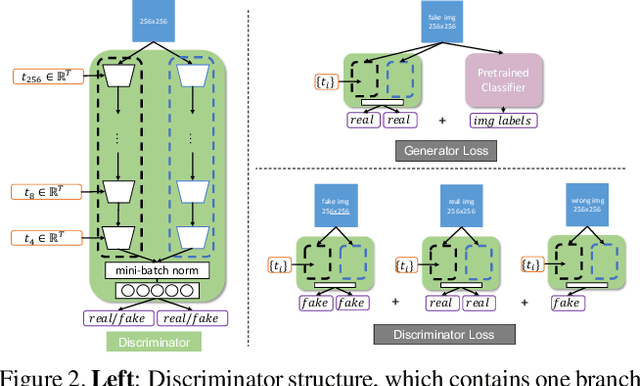
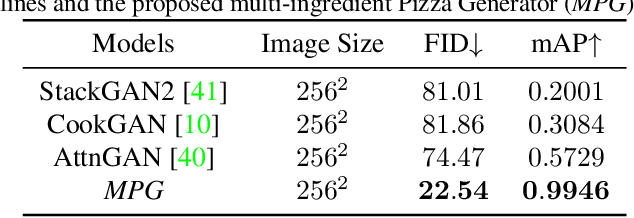
Multilabel conditional image generation is a challenging problem in computer vision. In this work we propose Multi-ingredient Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing multilabel images. We design MPG based on a state-of-the-art GAN structure called StyleGAN2, in which we develop a new conditioning technique by enforcing intermediate feature maps to learn scalewise label information. Because of the complex nature of the multilabel image generation problem, we also regularize synthetic image by predicting the corresponding ingredients as well as encourage the discriminator to distinguish between matched image and mismatched image. To verify the efficacy of MPG, we test it on Pizza10, which is a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realist pizza images with desired ingredients. The framework can be easily extend to other multilabel image generation scenarios.
Generating High Fidelity Data from Low-density Regions using Diffusion Models
Mar 31, 2022
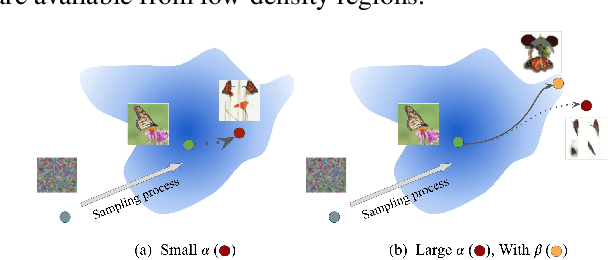

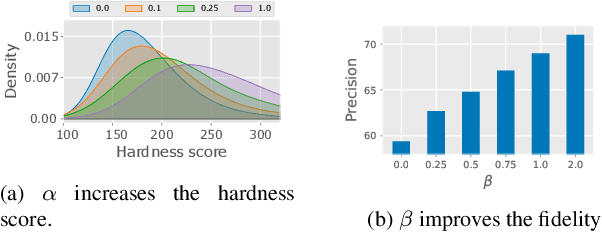
Our work focuses on addressing sample deficiency from low-density regions of data manifold in common image datasets. We leverage diffusion process based generative models to synthesize novel images from low-density regions. We observe that uniform sampling from diffusion models predominantly samples from high-density regions of the data manifold. Therefore, we modify the sampling process to guide it towards low-density regions while simultaneously maintaining the fidelity of synthetic data. We rigorously demonstrate that our process successfully generates novel high fidelity samples from low-density regions. We further examine generated samples and show that the model does not memorize low-density data and indeed learns to generate novel samples from low-density regions.
Free-breathing motion compensated 4D (3D+respiration) T2-weighted turbo spin-echo MRI for body imaging
Feb 07, 2022Purpose: To develop and evaluate a free-breathing respiratory motion compensated 4D (3D+respiration) $T_2$-weighted turbo spin echo sequence with application to radiology and MR-guided radiotherapy. Methods: k-space data are continuously acquired using a rewound Cartesian acquisition with spiral profile ordering (rCASPR) to provide matching contrast to the conventional linear phase encode ordering and to sort data into multiple respiratory phases. Low-resolution respiratory-correlated 4D images were reconstructed with compressed sensing and used to estimate non-rigid deformation vector fields, which were subsequently used for a motion compensated image reconstruction. rCASPR sampling was compared to linear and CASPR sampling in terms of point-spread-function (PSF) and image contrast with in silico, phantom and in vivo experiments. Reconstruction parameters for low-resolution 4D-MRI (spatial resolution and temporal regularization) were determined using a grid search. The proposed motion compensated rCASPR was evaluated in eight healthy volunteers and compared to free-breathing scans with linear sampling. Image quality was compared based on visual inspection and quantitatively by means of the gradient entropy. Results: rCASPR provided a superior PSF (similar in ky and narrower in kz) and showed no considerable differences in images contrast compared to linear sampling. The optimal 4D-MRI reconstruction parameters were spatial resolution=$4.5 mm^3$ and $\lambda_t=10^{-4}$. The groupwise average gradient entropy was 22.31 for linear, 22.20 for rCASPR, 22.14 for soft-gated rCASPR and 22.02 for motion compensated rCASPR. Conclusion: The proposed motion compensated rCASPR enables high quality free-breathing T2-TSE with minimal changes in image contrast and scan time. The proposed method therefore enables direct transfer of clinically used 3D TSE sequences to free-breathing.
Exploiting Temporal Relations on Radar Perception for Autonomous Driving
Apr 03, 2022
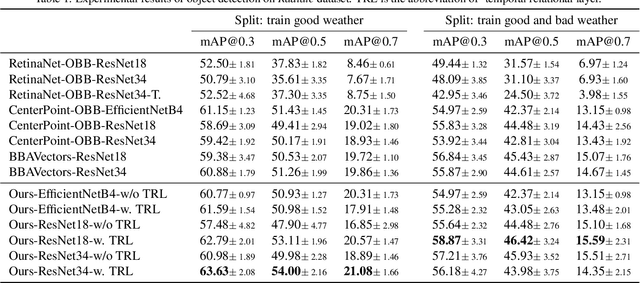
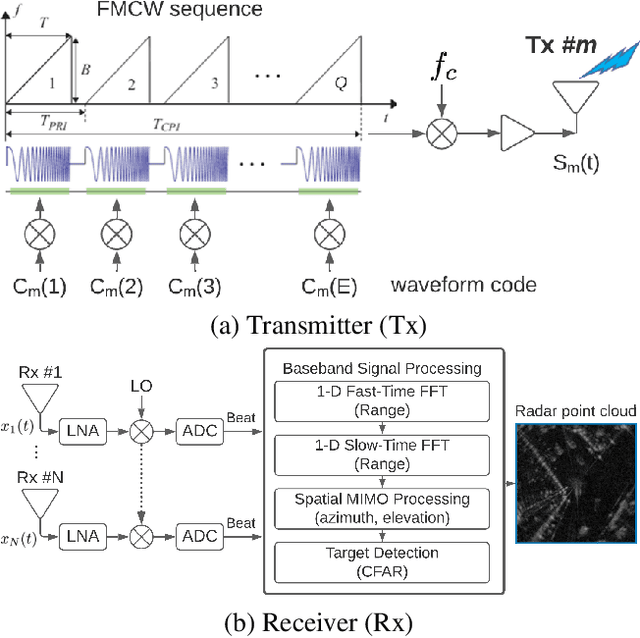

We consider the object recognition problem in autonomous driving using automotive radar sensors. Comparing to Lidar sensors, radar is cost-effective and robust in all-weather conditions for perception in autonomous driving. However, radar signals suffer from low angular resolution and precision in recognizing surrounding objects. To enhance the capacity of automotive radar, in this work, we exploit the temporal information from successive ego-centric bird-eye-view radar image frames for radar object recognition. We leverage the consistency of an object's existence and attributes (size, orientation, etc.), and propose a temporal relational layer to explicitly model the relations between objects within successive radar images. In both object detection and multiple object tracking, we show the superiority of our method compared to several baseline approaches.
Hephaestus: A large scale multitask dataset towards InSAR understanding
Apr 20, 2022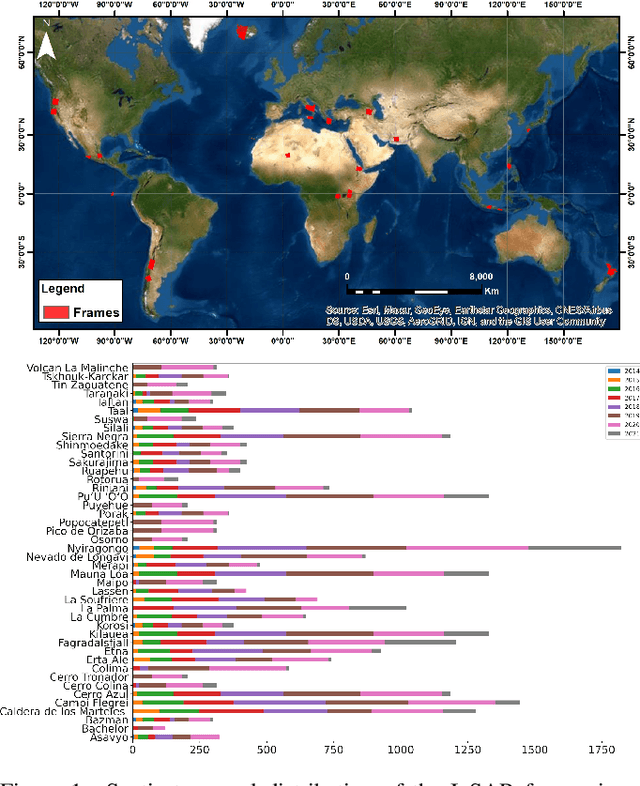
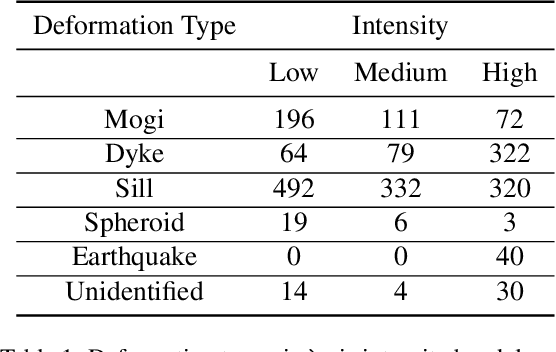
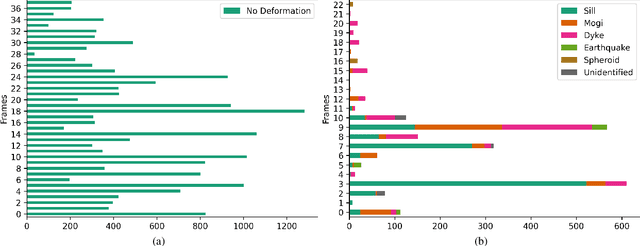
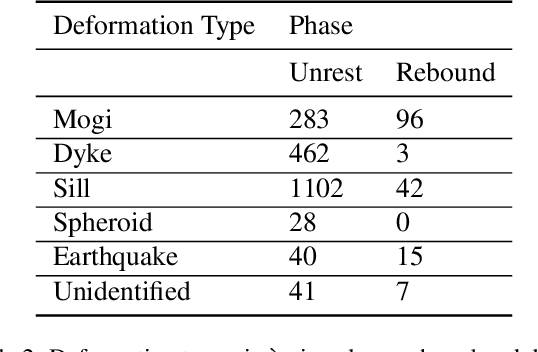
Synthetic Aperture Radar (SAR) data and Interferometric SAR (InSAR) products in particular, are one of the largest sources of Earth Observation data. InSAR provides unique information on diverse geophysical processes and geology, and on the geotechnical properties of man-made structures. However, there are only a limited number of applications that exploit the abundance of InSAR data and deep learning methods to extract such knowledge. The main barrier has been the lack of a large curated and annotated InSAR dataset, which would be costly to create and would require an interdisciplinary team of experts experienced on InSAR data interpretation. In this work, we put the effort to create and make available the first of its kind, manually annotated dataset that consists of 19,919 individual Sentinel-1 interferograms acquired over 44 different volcanoes globally, which are split into 216,106 InSAR patches. The annotated dataset is designed to address different computer vision problems, including volcano state classification, semantic segmentation of ground deformation, detection and classification of atmospheric signals in InSAR imagery, interferogram captioning, text to InSAR generation, and InSAR image quality assessment.
Learning the Regularization in DCE-MR Image Reconstruction for Functional Imaging of Kidneys
Sep 15, 2021
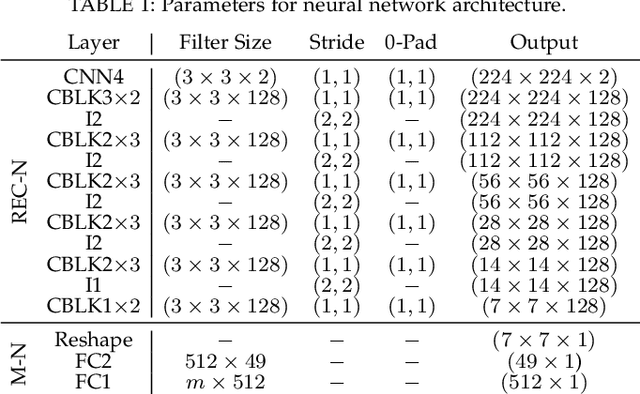
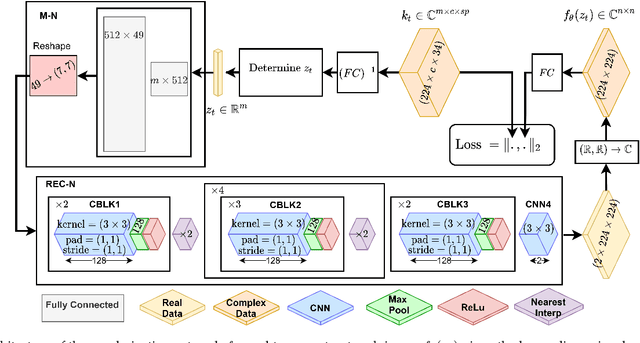
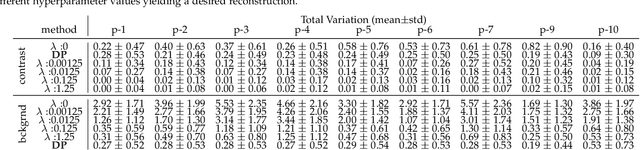
Kidney DCE-MRI aims at both qualitative assessment of kidney anatomy and quantitative assessment of kidney function by estimating the tracer kinetic (TK) model parameters. Accurate estimation of TK model parameters requires an accurate measurement of the arterial input function (AIF) with high temporal resolution. Accelerated imaging is used to achieve high temporal resolution, which yields under-sampling artifacts in the reconstructed images. Compressed sensing (CS) methods offer a variety of reconstruction options. Most commonly, sparsity of temporal differences is encouraged for regularization to reduce artifacts. Increasing regularization in CS methods removes the ambient artifacts but also over-smooths the signal temporally which reduces the parameter estimation accuracy. In this work, we propose a single image trained deep neural network to reduce MRI under-sampling artifacts without reducing the accuracy of functional imaging markers. Instead of regularizing with a penalty term in optimization, we promote regularization by generating images from a lower dimensional representation. In this manuscript we motivate and explain the lower dimensional input design. We compare our approach to CS reconstructions with multiple regularization weights. Proposed approach results in kidney biomarkers that are highly correlated with the ground truth markers estimated using the CS reconstruction which was optimized for functional analysis. At the same time, the proposed approach reduces the artifacts in the reconstructed images.
Interpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020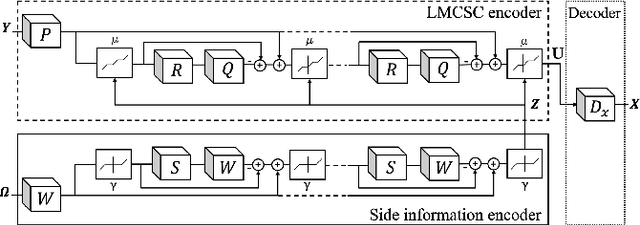
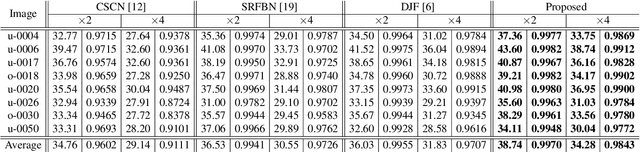

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022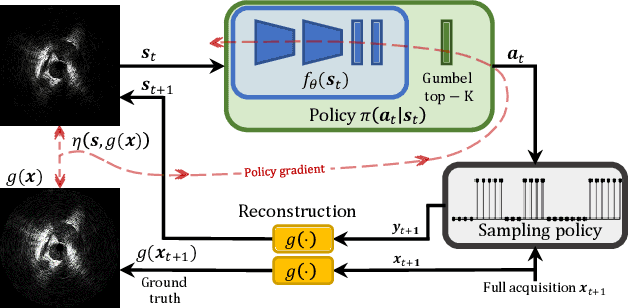
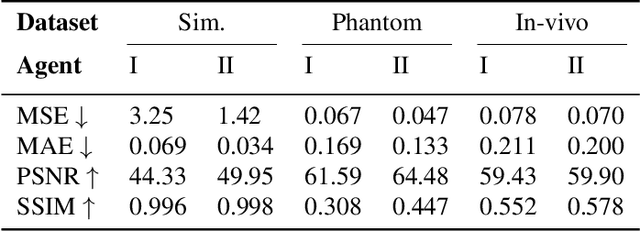

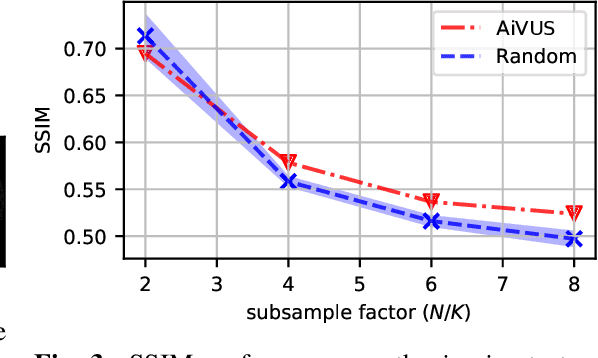
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference