 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Resource-Constrained Neural Architecture Search on Tabular Datasets
Apr 15, 2022
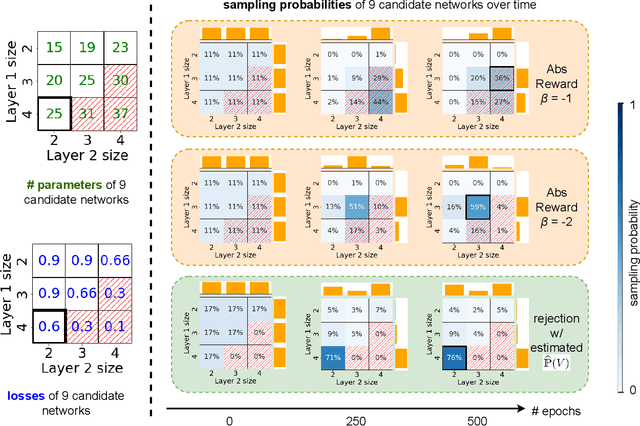
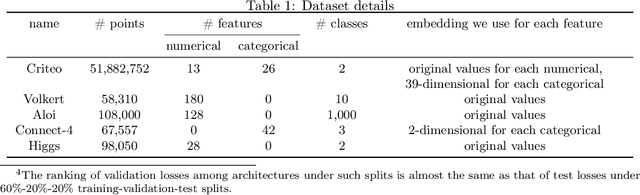
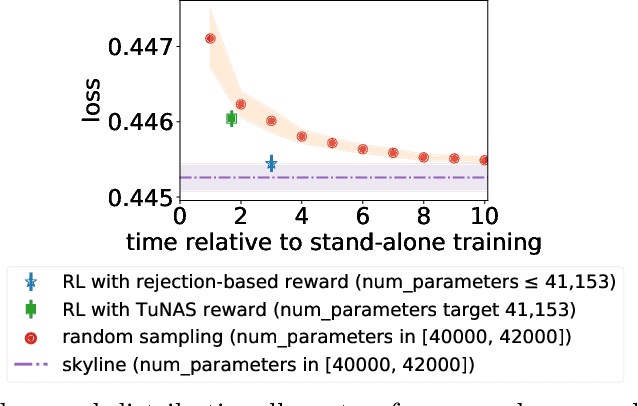
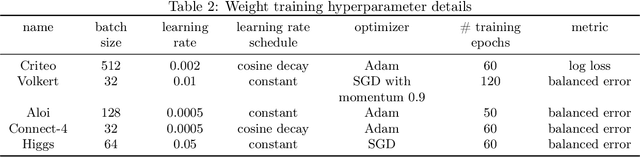
The best neural architecture for a given machine learning problem depends on many factors: not only the complexity and structure of the dataset, but also on resource constraints including latency, compute, energy consumption, etc. Neural architecture search (NAS) for tabular datasets is an important but under-explored problem. Previous NAS algorithms designed for image search spaces incorporate resource constraints directly into the reinforcement learning rewards. In this paper, we argue that search spaces for tabular NAS pose considerable challenges for these existing reward-shaping methods, and propose a new reinforcement learning (RL) controller to address these challenges. Motivated by rejection sampling, when we sample candidate architectures during a search, we immediately discard any architecture that violates our resource constraints. We use a Monte-Carlo-based correction to our RL policy gradient update to account for this extra filtering step. Results on several tabular datasets show TabNAS, the proposed approach, efficiently finds high-quality models that satisfy the given resource constraints.
$Υ$-Net: A Spatiospectral Network for Retinal OCT Segmentation
Apr 15, 2022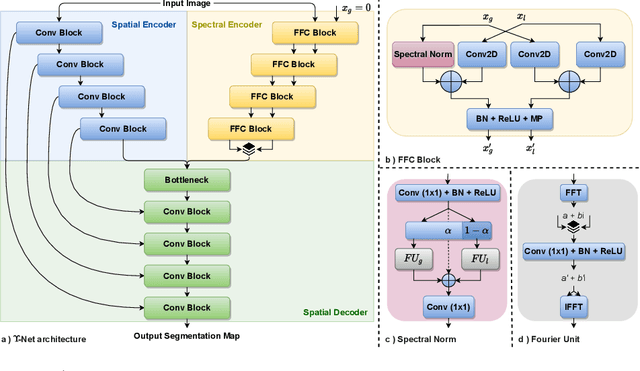
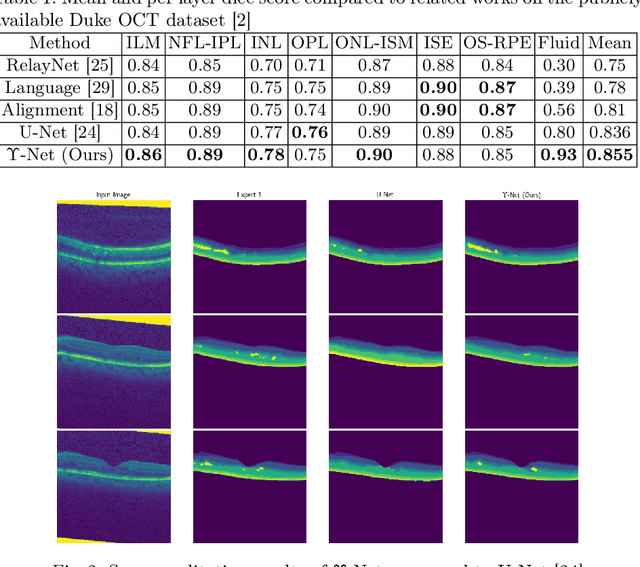
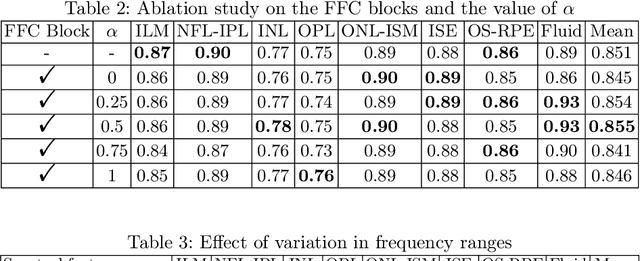
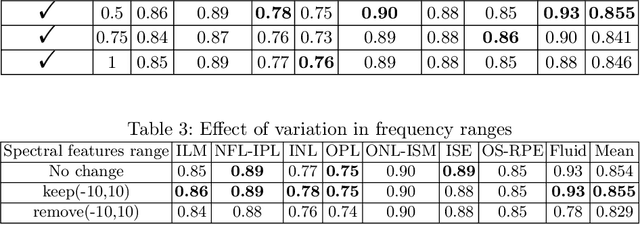
Automated segmentation of retinal optical coherence tomography (OCT) images has become an important recent direction in machine learning for medical applications. We hypothesize that the anatomic structure of layers and their high-frequency variation in OCT images make retinal OCT a fitting choice for extracting spectral-domain features and combining them with spatial domain features. In this work, we present $\Upsilon$-Net, an architecture that combines the frequency domain features with the image domain to improve the segmentation performance of OCT images. The results of this work demonstrate that the introduction of two branches, one for spectral and one for spatial domain features, brings a very significant improvement in fluid segmentation performance and allows outperformance as compared to the well-known U-Net model. Our improvement was 13% on the fluid segmentation dice score and 1.9% on the average dice score. Finally, removing selected frequency ranges in the spectral domain demonstrates the impact of these features on the fluid segmentation outperformance.
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022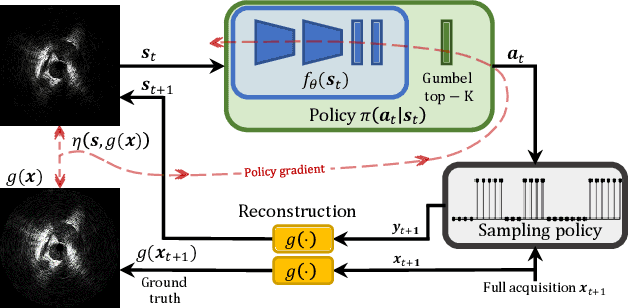
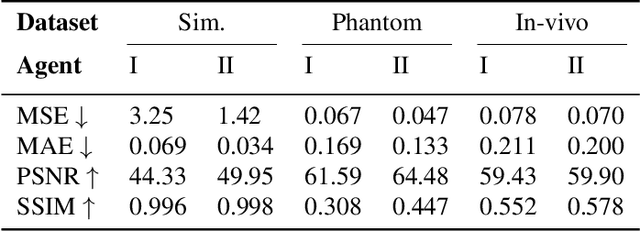

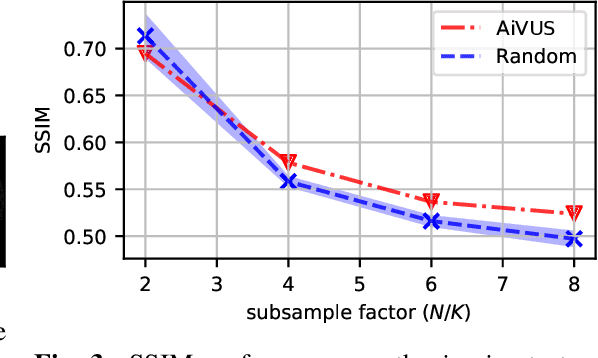
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference
Diverse Semantic Image Synthesis via Probability Distribution Modeling
Mar 11, 2021
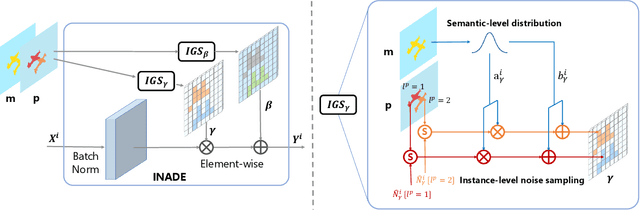
Semantic image synthesis, translating semantic layouts to photo-realistic images, is a one-to-many mapping problem. Though impressive progress has been recently made, diverse semantic synthesis that can efficiently produce semantic-level multimodal results, still remains a challenge. In this paper, we propose a novel diverse semantic image synthesis framework from the perspective of semantic class distributions, which naturally supports diverse generation at semantic or even instance level. We achieve this by modeling class-level conditional modulation parameters as continuous probability distributions instead of discrete values, and sampling per-instance modulation parameters through instance-adaptive stochastic sampling that is consistent across the network. Moreover, we propose prior noise remapping, through linear perturbation parameters encoded from paired references, to facilitate supervised training and exemplar-based instance style control at test time. Extensive experiments on multiple datasets show that our method can achieve superior diversity and comparable quality compared to state-of-the-art methods. Code will be available at \url{https://github.com/tzt101/INADE.git}
Free-breathing motion compensated 4D (3D+respiration) T2-weighted turbo spin-echo MRI for body imaging
Feb 07, 2022Purpose: To develop and evaluate a free-breathing respiratory motion compensated 4D (3D+respiration) $T_2$-weighted turbo spin echo sequence with application to radiology and MR-guided radiotherapy. Methods: k-space data are continuously acquired using a rewound Cartesian acquisition with spiral profile ordering (rCASPR) to provide matching contrast to the conventional linear phase encode ordering and to sort data into multiple respiratory phases. Low-resolution respiratory-correlated 4D images were reconstructed with compressed sensing and used to estimate non-rigid deformation vector fields, which were subsequently used for a motion compensated image reconstruction. rCASPR sampling was compared to linear and CASPR sampling in terms of point-spread-function (PSF) and image contrast with in silico, phantom and in vivo experiments. Reconstruction parameters for low-resolution 4D-MRI (spatial resolution and temporal regularization) were determined using a grid search. The proposed motion compensated rCASPR was evaluated in eight healthy volunteers and compared to free-breathing scans with linear sampling. Image quality was compared based on visual inspection and quantitatively by means of the gradient entropy. Results: rCASPR provided a superior PSF (similar in ky and narrower in kz) and showed no considerable differences in images contrast compared to linear sampling. The optimal 4D-MRI reconstruction parameters were spatial resolution=$4.5 mm^3$ and $\lambda_t=10^{-4}$. The groupwise average gradient entropy was 22.31 for linear, 22.20 for rCASPR, 22.14 for soft-gated rCASPR and 22.02 for motion compensated rCASPR. Conclusion: The proposed motion compensated rCASPR enables high quality free-breathing T2-TSE with minimal changes in image contrast and scan time. The proposed method therefore enables direct transfer of clinically used 3D TSE sequences to free-breathing.
Towards Practical Certifiable Patch Defense with Vision Transformer
Mar 16, 2022

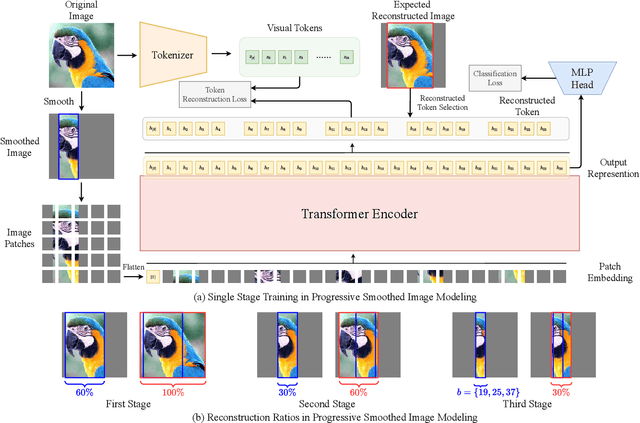
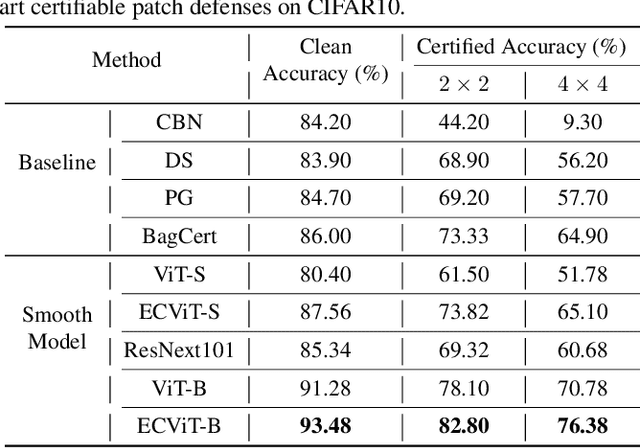
Patch attacks, one of the most threatening forms of physical attack in adversarial examples, can lead networks to induce misclassification by modifying pixels arbitrarily in a continuous region. Certifiable patch defense can guarantee robustness that the classifier is not affected by patch attacks. Existing certifiable patch defenses sacrifice the clean accuracy of classifiers and only obtain a low certified accuracy on toy datasets. Furthermore, the clean and certified accuracy of these methods is still significantly lower than the accuracy of normal classification networks, which limits their application in practice. To move towards a practical certifiable patch defense, we introduce Vision Transformer (ViT) into the framework of Derandomized Smoothing (DS). Specifically, we propose a progressive smoothed image modeling task to train Vision Transformer, which can capture the more discriminable local context of an image while preserving the global semantic information. For efficient inference and deployment in the real world, we innovatively reconstruct the global self-attention structure of the original ViT into isolated band unit self-attention. On ImageNet, under 2% area patch attacks our method achieves 41.70% certified accuracy, a nearly 1-fold increase over the previous best method (26.00%). Simultaneously, our method achieves 78.58% clean accuracy, which is quite close to the normal ResNet-101 accuracy. Extensive experiments show that our method obtains state-of-the-art clean and certified accuracy with inferring efficiently on CIFAR-10 and ImageNet.
Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
May 07, 2022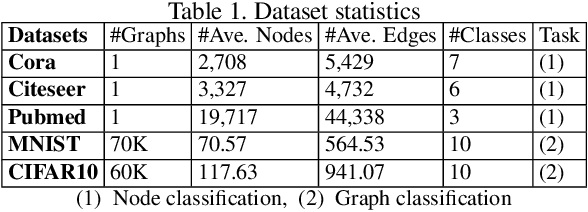
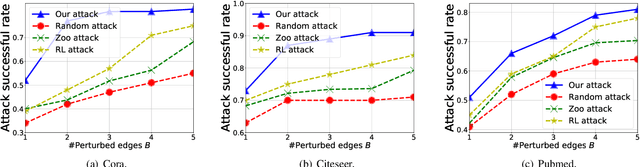
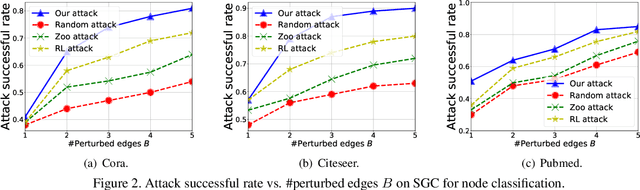
Graph neural networks (GNNs) have achieved state-of-the-art performance in many graph-based tasks such as node classification and graph classification. However, many recent works have demonstrated that an attacker can mislead GNN models by slightly perturbing the graph structure. Existing attacks to GNNs are either under the less practical threat model where the attacker is assumed to access the GNN model parameters, or under the practical black-box threat model but consider perturbing node features that are shown to be not enough effective. In this paper, we aim to bridge this gap and consider black-box attacks to GNNs with structure perturbation as well as with theoretical guarantees. We propose to address this challenge through bandit techniques. Specifically, we formulate our attack as an online optimization with bandit feedback. This original problem is essentially NP-hard due to the fact that perturbing the graph structure is a binary optimization problem. We then propose an online attack based on bandit optimization which is proven to be {sublinear} to the query number $T$, i.e., $\mathcal{O}(\sqrt{N}T^{3/4})$ where $N$ is the number of nodes in the graph. Finally, we evaluate our proposed attack by conducting experiments over multiple datasets and GNN models. The experimental results on various citation graphs and image graphs show that our attack is both effective and efficient. Source code is available at~\url{https://github.com/Metaoblivion/Bandit_GNN_Attack}
Complete identification of complex salt-geometries from inaccurate migrated images using Deep Learning
Apr 20, 2022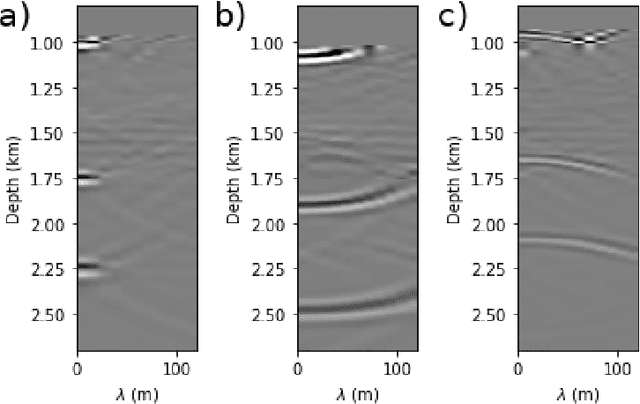
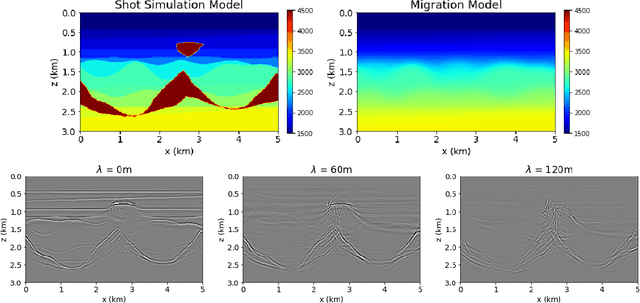
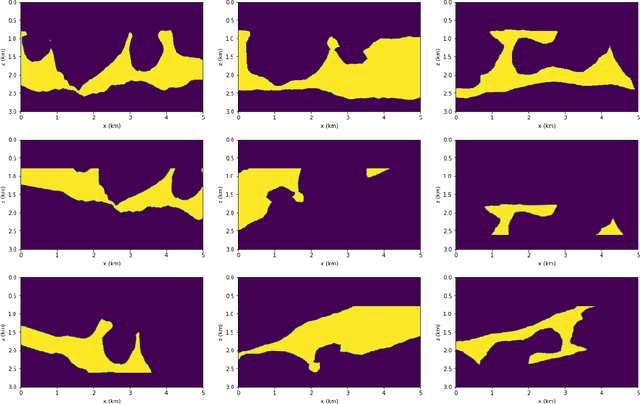
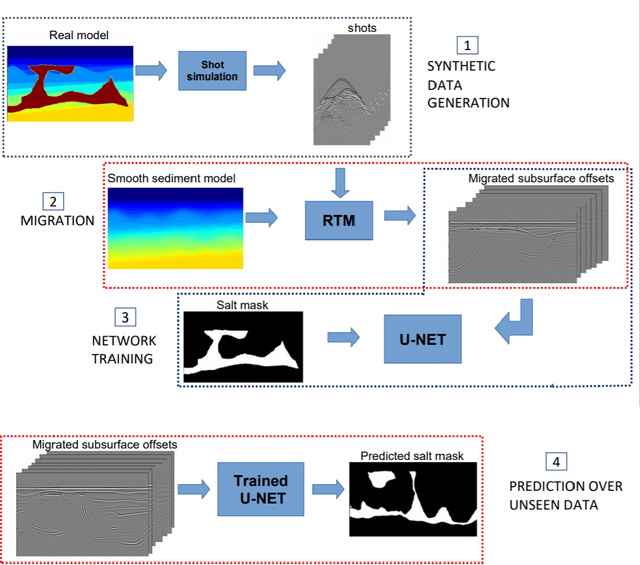
Delimiting salt inclusions from migrated images is a time-consuming activity that relies on highly human-curated analysis and is subject to interpretation errors or limitations of the methods available. We propose to use migrated images produced from an inaccurate velocity model (with a reasonable approximation of sediment velocity, but without salt inclusions) to predict the correct salt inclusions shape using a Convolutional Neural Network (CNN). Our approach relies on subsurface Common Image Gathers to focus the sediments' reflections around the zero offset and to spread the energy of salt reflections over large offsets. Using synthetic data, we trained a U-Net to use common-offset subsurface images as input channels for the CNN and the correct salt-masks as network output. The network learned to predict the salt inclusions masks with high accuracy; moreover, it also performed well when applied to synthetic benchmark data sets that were not previously introduced. Our training process tuned the U-Net to successfully learn the shape of complex salt bodies from partially focused subsurface offset images.
Interpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020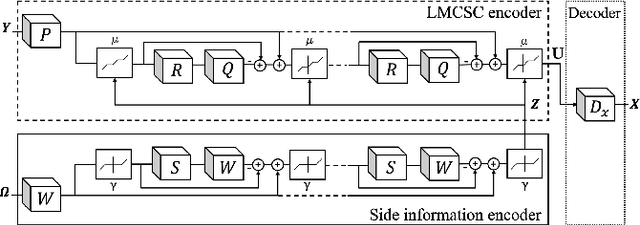
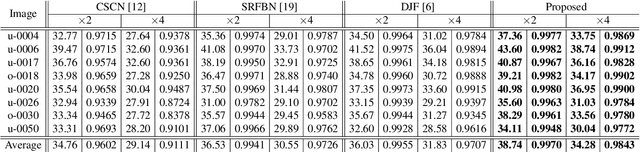

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
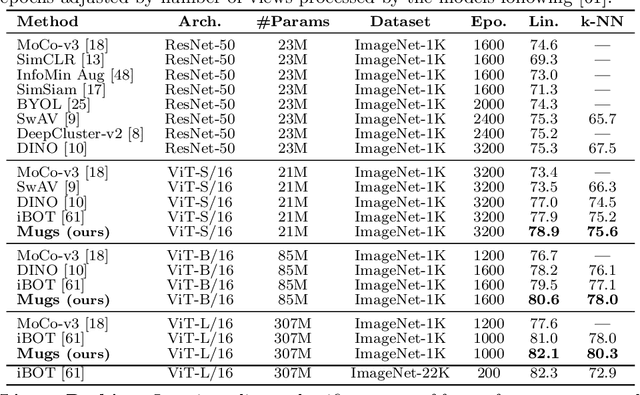
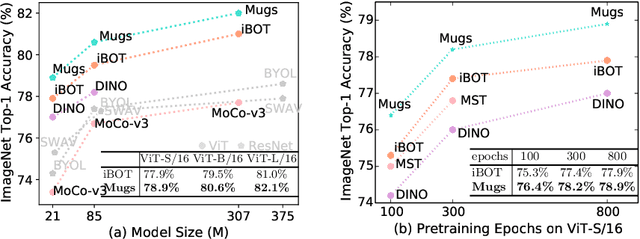
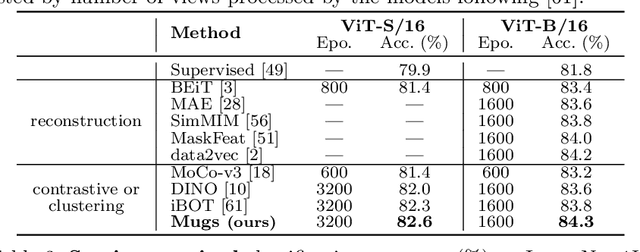
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.