 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021

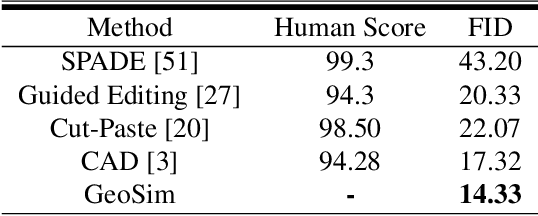
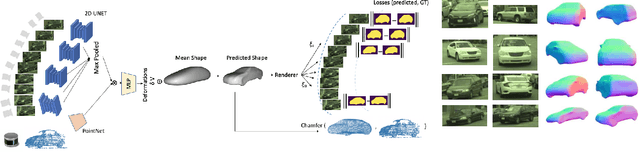

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.
Semi-supervised Meta-learning with Disentanglement for Domain-generalised Medical Image Segmentation
Jun 24, 2021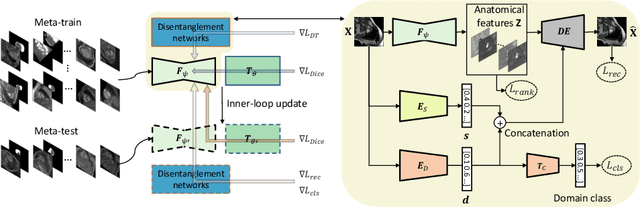
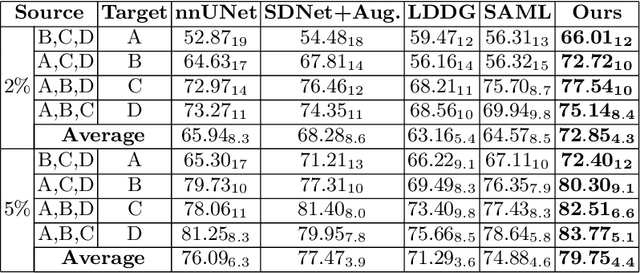
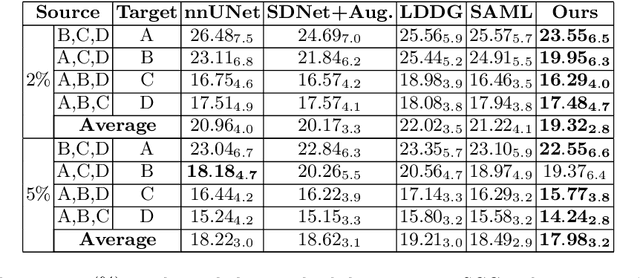
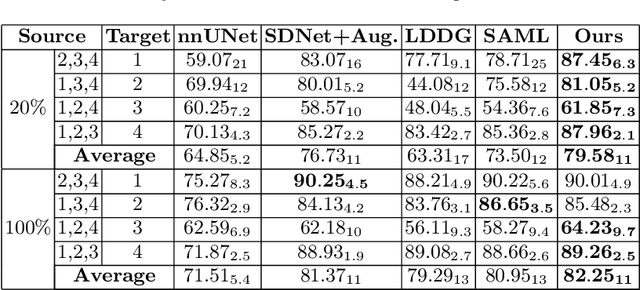
Generalising deep models to new data from new centres (termed here domains) remains a challenge. This is largely attributed to shifts in data statistics (domain shifts) between source and unseen domains. Recently, gradient-based meta-learning approaches where the training data are split into meta-train and meta-test sets to simulate and handle the domain shifts during training have shown improved generalisation performance. However, the current fully supervised meta-learning approaches are not scalable for medical image segmentation, where large effort is required to create pixel-wise annotations. Meanwhile, in a low data regime, the simulated domain shifts may not approximate the true domain shifts well across source and unseen domains. To address this problem, we propose a novel semi-supervised meta-learning framework with disentanglement. We explicitly model the representations related to domain shifts. Disentangling the representations and combining them to reconstruct the input image allows unlabeled data to be used to better approximate the true domain shifts for meta-learning. Hence, the model can achieve better generalisation performance, especially when there is a limited amount of labeled data. Experiments show that the proposed method is robust on different segmentation tasks and achieves state-of-the-art generalisation performance on two public benchmarks.
Bridging Gap between Image Pixels and Semantics via Supervision: A Survey
Jul 29, 2021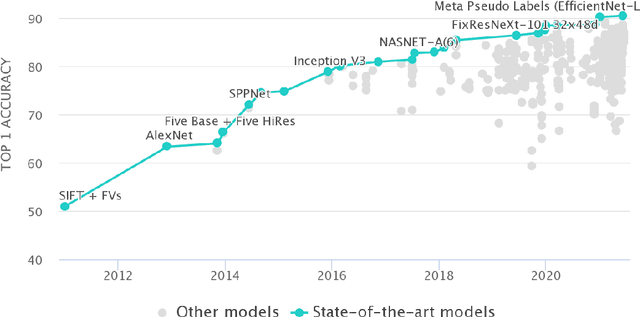
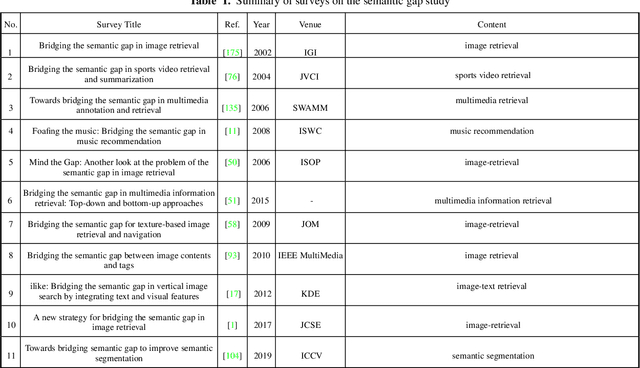

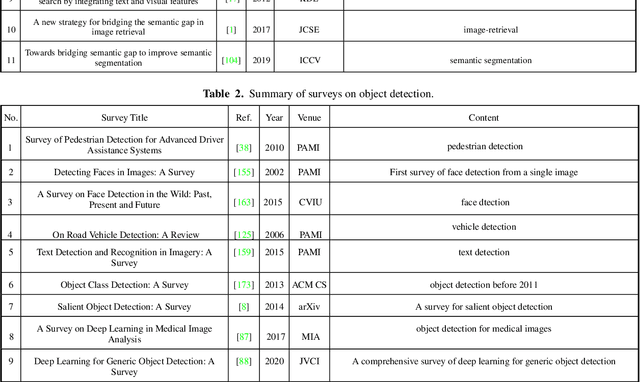
The fact that there exists a gap between low-level features and semantic meanings of images, called the semantic gap, is known for decades. Resolution of the semantic gap is a long standing problem. The semantic gap problem is reviewed and a survey on recent efforts in bridging the gap is made in this work. Most importantly, we claim that the semantic gap is primarily bridged through supervised learning today. Experiences are drawn from two application domains to illustrate this point: 1) object detection and 2) metric learning for content-based image retrieval (CBIR). To begin with, this paper offers a historical retrospective on supervision, makes a gradual transition to the modern data-driven methodology and introduces commonly used datasets. Then, it summarizes various supervision methods to bridge the semantic gap in the context of object detection and metric learning.
Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
Mar 29, 2022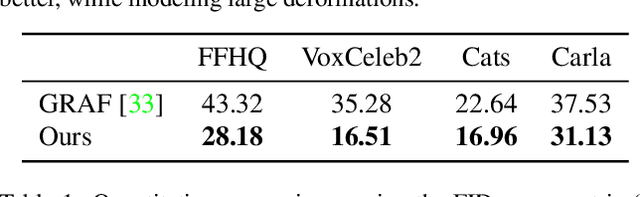
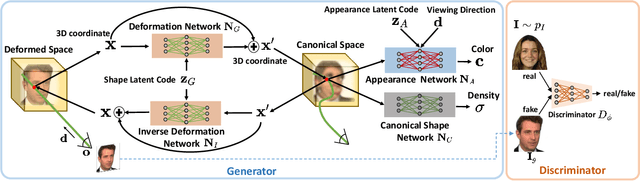


Learning 3D generative models from a dataset of monocular images enables self-supervised 3D reasoning and controllable synthesis. State-of-the-art 3D generative models are GANs which use neural 3D volumetric representations for synthesis. Images are synthesized by rendering the volumes from a given camera. These models can disentangle the 3D scene from the camera viewpoint in any generated image. However, most models do not disentangle other factors of image formation, such as geometry and appearance. In this paper, we design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. This is achieved using a novel non-rigid deformable scene formulation. A 3D volume which represents an object instance is computed as a non-rigidly deformed canonical 3D volume. Our method learns the canonical volume, as well as its deformations, jointly during training. This formulation also helps us improve the disentanglement between the 3D scene and the camera viewpoints using a novel pose regularization loss defined on the 3D deformation field. In addition, we further model the inverse deformations, enabling the computation of dense correspondences between images generated by our model. Finally, we design an approach to embed real images into the latent space of our disentangled generative model, enabling editing of real images.
Neural Optimal Transport
Jan 28, 2022

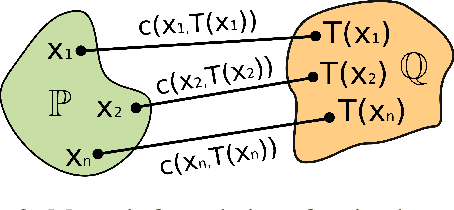
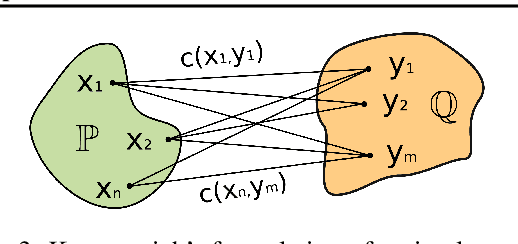
We present a novel neural-networks-based algorithm to compute optimal transport maps and plans for strong and weak transport costs. To justify the usage of neural networks, we prove that they are universal approximators of transport plans between probability distributions. We evaluate the performance of our optimal transport algorithm on toy examples and on the unpaired image-to-image style translation task.
Weighted Intersection over Union (wIoU): A New Evaluation Metric for Image Segmentation
Jul 21, 2021

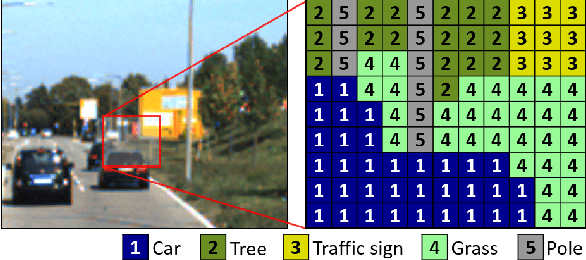
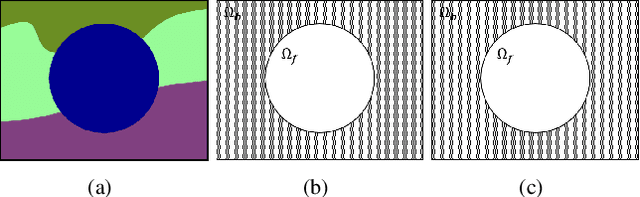
In this paper, we propose a novel evaluation metric for performance evaluation of semantic segmentation. In recent years, many studies have tried to train pixel-level classifiers on large-scale image datasets to perform accurate semantic segmentation. The goal of semantic segmentation is to assign a class label of each pixel in the scene. It has various potential applications in computer vision fields e.g., object detection, classification, scene understanding and Etc. To validate the proposed wIoU evaluation metric, we tested state-of-the art methods on public benchmark datasets (e.g., KITTI) based on the proposed wIoU metric and compared with other conventional evaluation metrics.
Identifying outliers in astronomical images with unsupervised machine learning
May 19, 2022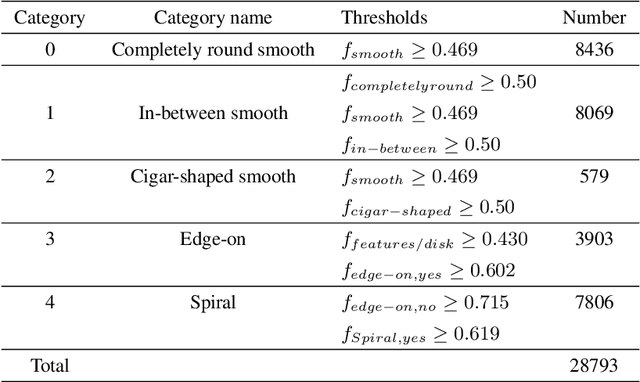
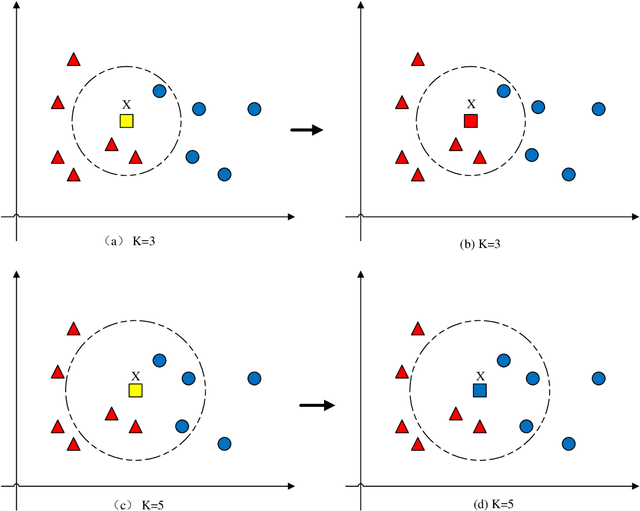
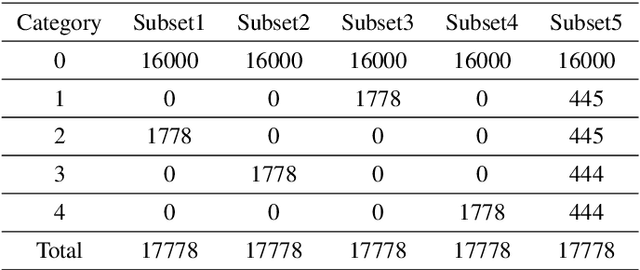
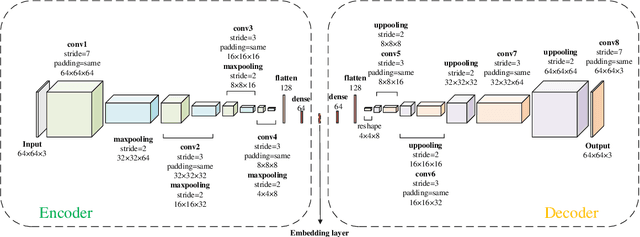
Astronomical outliers, such as unusual, rare or unknown types of astronomical objects or phenomena, constantly lead to the discovery of genuinely unforeseen knowledge in astronomy. More unpredictable outliers will be uncovered in principle with the increment of the coverage and quality of upcoming survey data. However, it is a severe challenge to mine rare and unexpected targets from enormous data with human inspection due to a significant workload. Supervised learning is also unsuitable for this purpose since designing proper training sets for unanticipated signals is unworkable. Motivated by these challenges, we adopt unsupervised machine learning approaches to identify outliers in the data of galaxy images to explore the paths for detecting astronomical outliers. For comparison, we construct three methods, which are built upon the k-nearest neighbors (KNN), Convolutional Auto-Encoder (CAE)+ KNN, and CAE + KNN + Attention Mechanism (attCAE KNN) separately. Testing sets are created based on the Galaxy Zoo image data published online to evaluate the performance of the above methods. Results show that attCAE KNN achieves the best recall (78%), which is 53% higher than the classical KNN method and 22% higher than CAE+KNN. The efficiency of attCAE KNN (10 minutes) is also superior to KNN (4 hours) and equal to CAE+KNN(10 minutes) for accomplishing the same task. Thus, we believe it is feasible to detect astronomical outliers in the data of galaxy images in an unsupervised manner. Next, we will apply attCAE KNN to available survey datasets to assess its applicability and reliability.
Image/Video Deep Anomaly Detection: A Survey
Mar 02, 2021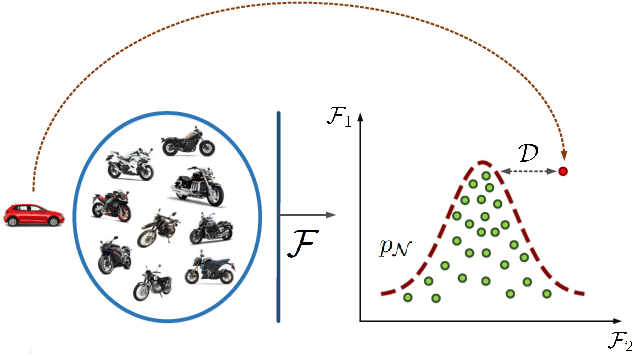
The considerable significance of Anomaly Detection (AD) problem has recently drawn the attention of many researchers. Consequently, the number of proposed methods in this research field has been increased steadily. AD strongly correlates with the important computer vision and image processing tasks such as image/video anomaly, irregularity and sudden event detection. More recently, Deep Neural Networks (DNNs) offer a high performance set of solutions, but at the expense of a heavy computational cost. However, there is a noticeable gap between the previously proposed methods and an applicable real-word approach. Regarding the raised concerns about AD as an ongoing challenging problem, notably in images and videos, the time has come to argue over the pitfalls and prospects of methods have attempted to deal with visual AD tasks. Hereupon, in this survey we intend to conduct an in-depth investigation into the images/videos deep learning based AD methods. We also discuss current challenges and future research directions thoroughly.
Transformers in 3D Point Clouds: A Survey
May 16, 2022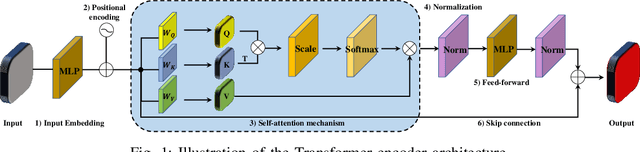
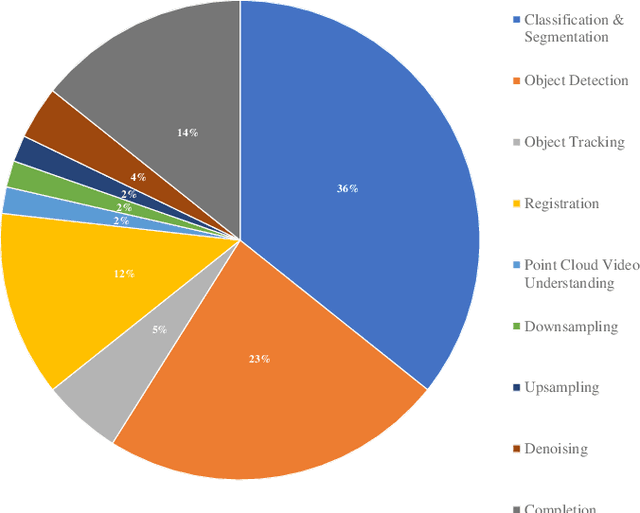
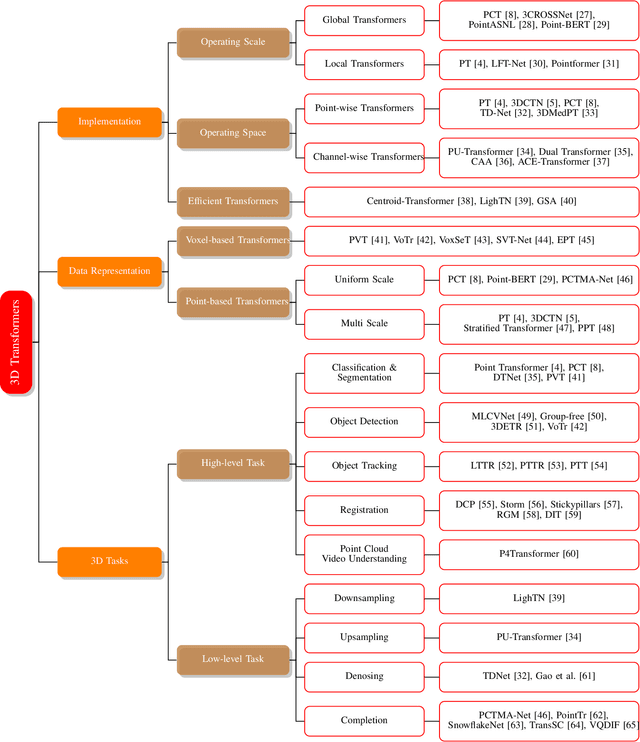
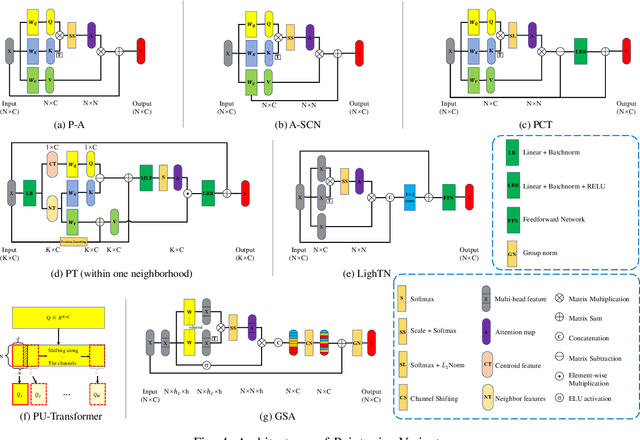
In recent years, Transformer models have been proven to have the remarkable ability of long-range dependencies modeling. They have achieved satisfactory results both in Natural Language Processing (NLP) and image processing. This significant achievement sparks great interest among researchers in 3D point cloud processing to apply them to various 3D tasks. Due to the inherent permutation invariance and strong global feature learning ability, 3D Transformers are well suited for point cloud processing and analysis. They have achieved competitive or even better performance compared to the state-of-the-art non-Transformer algorithms. This survey aims to provide a comprehensive overview of 3D Transformers designed for various tasks (e.g. point cloud classification, segmentation, object detection, and so on). We start by introducing the fundamental components of the general Transformer and providing a brief description of its application in 2D and 3D fields. Then, we present three different taxonomies (i.e., Transformer implementation-based taxonomy, data representation-based taxonomy, and task-based taxonomy) for method classification, which allows us to analyze involved methods from multiple perspectives. Furthermore, we also conduct an investigation of 3D self-attention mechanism variants designed for performance improvement. To demonstrate the superiority of 3D Transformers, we compare the performance of Transformer-based algorithms in terms of point cloud classification, segmentation, and object detection. Finally, we point out three potential future research directions, expecting to provide some benefit references for the development of 3D Transformers.
Deep Aesthetic Assessment and Retrieval of Breast Cancer Treatment Outcomes
May 25, 2022Treatments for breast cancer have continued to evolve and improve in recent years, resulting in a substantial increase in survival rates, with approximately 80\% of patients having a 10-year survival period. Given the serious impact that breast cancer treatments can have on a patient's body image, consequently affecting her self-confidence and sexual and intimate relationships, it is paramount to ensure that women receive the treatment that optimizes both survival and aesthetic outcomes. Currently, there is no gold standard for evaluating the aesthetic outcome of breast cancer treatment. In addition, there is no standard way to show patients the potential outcome of surgery. The presentation of similar cases from the past would be extremely important to manage women's expectations of the possible outcome. In this work, we propose a deep neural network to perform the aesthetic evaluation. As a proof-of-concept, we focus on a binary aesthetic evaluation. Besides its use for classification, this deep neural network can also be used to find the most similar past cases by searching for nearest neighbours in the highly semantic space before classification. We performed the experiments on a dataset consisting of 143 photos of women after conservative treatment for breast cancer. The results for accuracy and balanced accuracy showed the superior performance of our proposed model compared to the state of the art in aesthetic evaluation of breast cancer treatments. In addition, the model showed a good ability to retrieve similar previous cases, with the retrieved cases having the same or adjacent class (in the 4-class setting) and having similar types of asymmetry. Finally, a qualitative interpretability assessment was also performed to analyse the robustness and trustworthiness of the model.