 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multi-Task Cross-Task Learning Architecture for Ad-hoc Uncertainty Estimation in 3D Cardiac MRI Image Segmentation
Oct 03, 2021
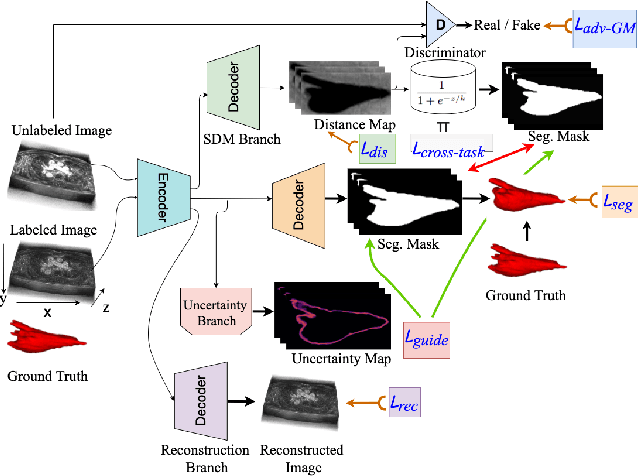

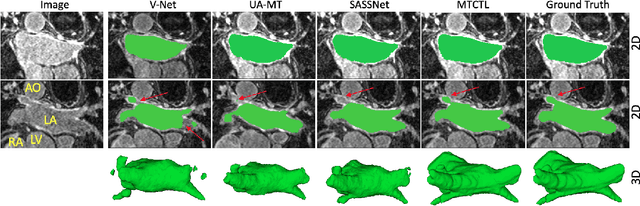
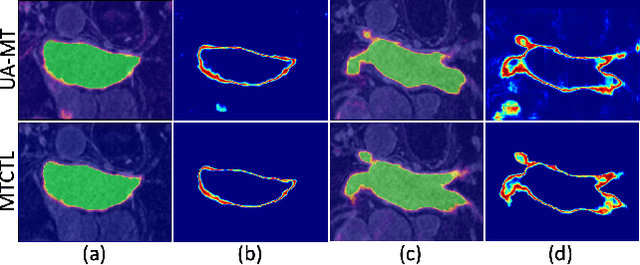
Medical image segmentation has significantly benefitted thanks to deep learning architectures. Furthermore, semi-supervised learning (SSL) has recently been a growing trend for improving a model's overall performance by leveraging abundant unlabeled data. Moreover, learning multiple tasks within the same model further improves model generalizability. To generate smoother and accurate segmentation masks from 3D cardiac MR images, we present a Multi-task Cross-task learning consistency approach to enforce the correlation between the pixel-level (segmentation) and the geometric-level (distance map) tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justifies the effectiveness of our model for the segmentation of the left atrial cavity from Gadolinium-enhanced magnetic resonance (GE-MR) images. With the incorporation of uncertainty estimates to detect failures in the segmentation masks generated by CNNs, our study further showcases the potential of our model to flag low-quality segmentation from a given model.
Semantic Distillation Guided Salient Object Detection
Mar 08, 2022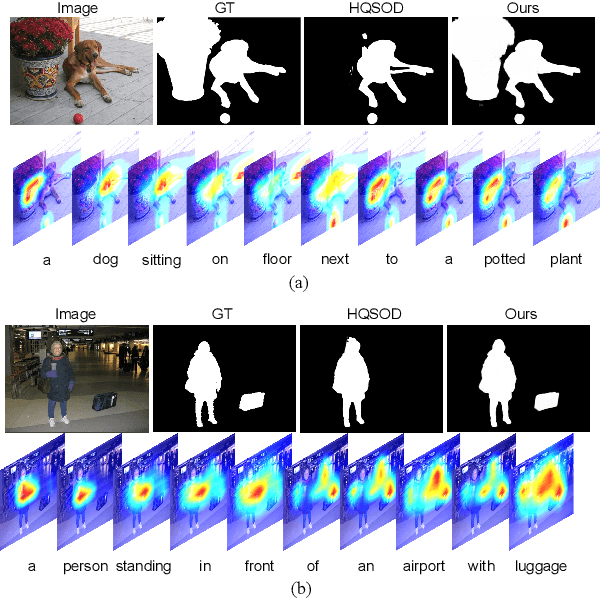
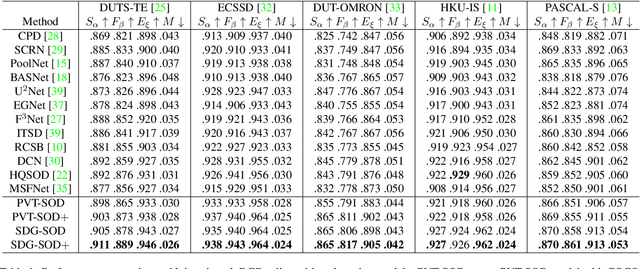
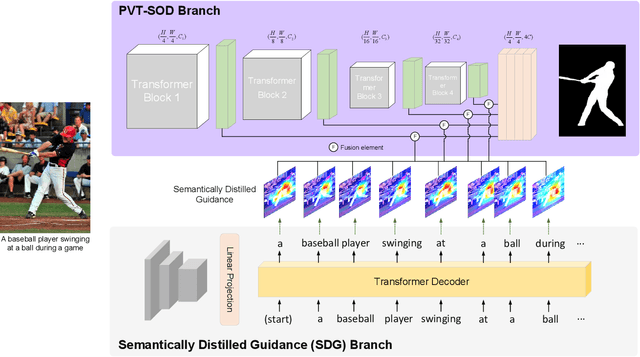
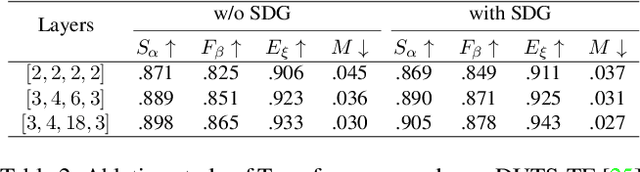
Most existing CNN-based salient object detection methods can identify local segmentation details like hair and animal fur, but often misinterpret the real saliency due to the lack of global contextual information caused by the subjectiveness of the SOD task and the locality of convolution layers. Moreover, due to the unrealistically expensive labeling costs, the current existing SOD datasets are insufficient to cover the real data distribution. The limitation and bias of the training data add additional difficulty to fully exploring the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a semantic distillation guided SOD (SDG-SOD) method that produces accurate results by fusing semantically distilled knowledge from generated image captioning into the Vision-Transformer-based SOD framework. SDG-SOD can better uncover inter-objects and object-to-environment saliency and cover the gap between the subjective nature of SOD and its expensive labeling. Comprehensive experiments on five benchmark datasets demonstrate that the SDG-SOD outperforms the state-of-the-art approaches on four evaluation metrics, and largely improves the model performance on DUTS, ECSSD, DUT, HKU-IS, and PASCAL-S datasets.
Analyzing General-Purpose Deep-Learning Detection and Segmentation Models with Images from a Lidar as a Camera Sensor
Mar 08, 2022


Over the last decade, robotic perception algorithms have significantly benefited from the rapid advances in deep learning (DL). Indeed, a significant amount of the autonomy stack of different commercial and research platforms relies on DL for situational awareness, especially vision sensors. This work explores the potential of general-purpose DL perception algorithms, specifically detection and segmentation neural networks, for processing image-like outputs of advanced lidar sensors. Rather than processing the three-dimensional point cloud data, this is, to the best of our knowledge, the first work to focus on low-resolution images with 360\textdegree field of view obtained with lidar sensors by encoding either depth, reflectivity, or near-infrared light in the image pixels. We show that with adequate preprocessing, general-purpose DL models can process these images, opening the door to their usage in environmental conditions where vision sensors present inherent limitations. We provide both a qualitative and quantitative analysis of the performance of a variety of neural network architectures. We believe that using DL models built for visual cameras offers significant advantages due to the much wider availability and maturity compared to point cloud-based perception.
FathomNet: A global underwater image training set for enabling artificial intelligence in the ocean
Oct 02, 2021
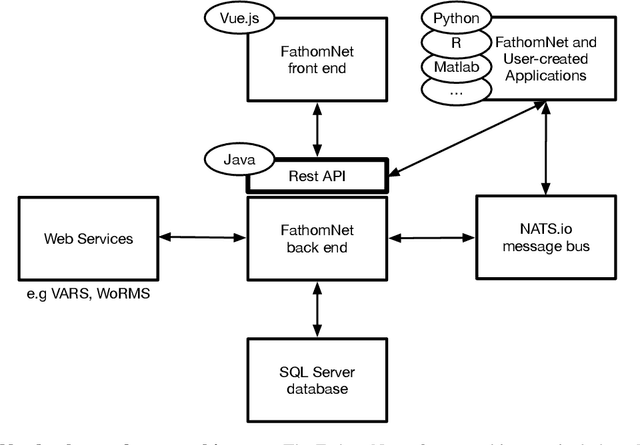
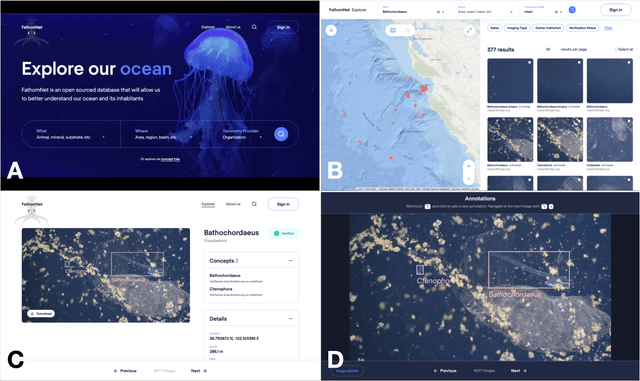
Ocean-going platforms are integrating high-resolution camera feeds for observation and navigation, producing a deluge of visual data. The volume and rate of this data collection can rapidly outpace researchers' abilities to process and analyze them. Recent advances in machine learning enable fast, sophisticated analysis of visual data, but have had limited success in the ocean due to lack of data set standardization, insufficient formatting, and aggregation of existing, expertly curated imagery for use by data scientists. To address this need, we have built FathomNet, a public platform that makes use of existing, expertly curated data. Initial efforts have leveraged MBARI's Video Annotation and Reference System and annotated deep sea video database, which has more than 7M annotations, 1M frame grabs, and 5k terms in the knowledgebase, with additional contributions by National Geographic Society (NGS) and NOAA's Office of Ocean Exploration and Research. FathomNet has over 160k localizations of 1.4k midwater and benthic classes, and contains more than 70k iconic and non-iconic views of marine animals, underwater equipment, debris, etc. We demonstrate how machine learning models trained on FathomNet data can be applied across different institutional video data, and enable automated acquisition and tracking of midwater animals using a remotely operated vehicle. As FathomNet continues to develop and incorporate more image data from other oceanographic community members, this effort will enable scientists, explorers, policymakers, storytellers, and the public to understand and care for our ocean.
Analysis of Sparse Subspace Clustering: Experiments and Random Projection
Apr 01, 2022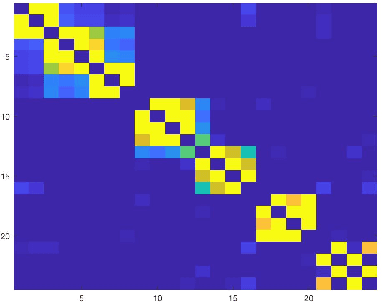
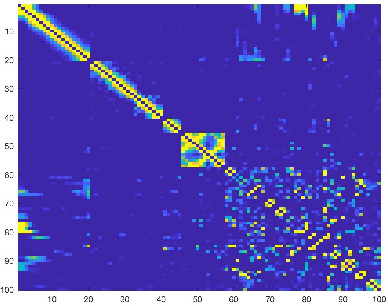
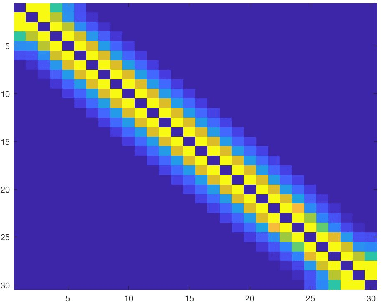

Clustering can be defined as the process of assembling objects into a number of groups whose elements are similar to each other in some manner. As a technique that is used in many domains, such as face clustering, plant categorization, image segmentation, document classification, clustering is considered one of the most important unsupervised learning problems. Scientists have surveyed this problem for years and developed different techniques that can solve it, such as k-means clustering. We analyze one of these techniques: a powerful clustering algorithm called Sparse Subspace Clustering. We demonstrate several experiments using this method and then introduce a new approach that can reduce the computational time required to perform sparse subspace clustering.
Personalized visual encoding model construction with small data
Feb 04, 2022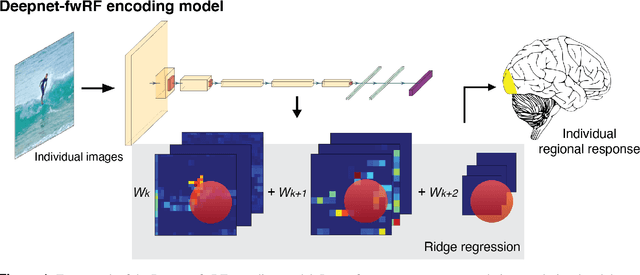
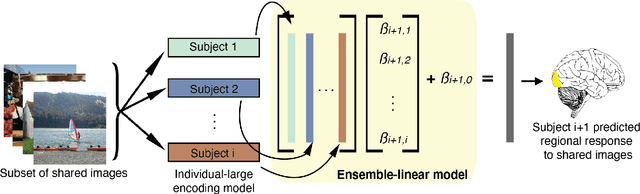
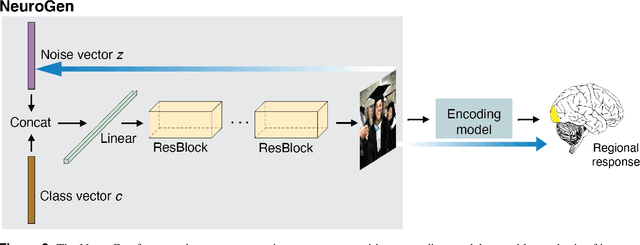
Encoding models that predict brain response patterns to stimuli are one way to capture this relationship between variability in bottom-up neural systems and individual's behavior or pathological state. However, they generally need a large amount of training data to achieve optimal accuracy. Here, we propose and test an alternative personalized ensemble encoding model approach to utilize existing encoding models, to create encoding models for novel individuals with relatively little stimuli-response data. We show that these personalized ensemble encoding models trained with small amounts of data for a specific individual, i.e. ~400 image-response pairs, achieve accuracy not different from models trained on ~24,000 image-response pairs for the same individual. Importantly, the personalized ensemble encoding models preserve patterns of inter-individual variability in the image-response relationship. Additionally, we use our personalized ensemble encoding model within the recently developed NeuroGen framework to generate optimal stimuli designed to maximize specific regions' activations for a specific individual. We show that the inter-individual differences in face area responses to images of dog vs human faces observed previously is replicated using NeuroGen with the ensemble encoding model. Finally, and most importantly, we show the proposed approach is robust against domain shift by validating on a prospectively collected set of image-response data in novel individuals with a different scanner and experimental setup. Our approach shows the potential to use previously collected, deeply sampled data to efficiently create accurate, personalized encoding models and, subsequently, personalized optimal synthetic images for new individuals scanned under different experimental conditions.
Augmentation-Interpolative AutoEncoders for Unsupervised Few-Shot Image Generation
Nov 25, 2020
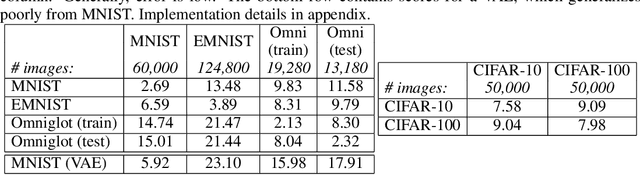

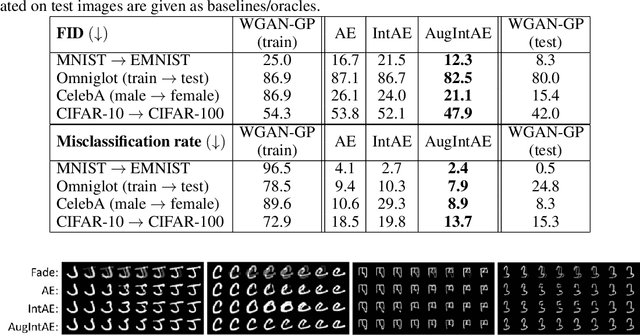
We aim to build image generation models that generalize to new domains from few examples. To this end, we first investigate the generalization properties of classic image generators, and discover that autoencoders generalize extremely well to new domains, even when trained on highly constrained data. We leverage this insight to produce a robust, unsupervised few-shot image generation algorithm, and introduce a novel training procedure based on recovering an image from data augmentations. Our Augmentation-Interpolative AutoEncoders synthesize realistic images of novel objects from only a few reference images, and outperform both prior interpolative models and supervised few-shot image generators. Our procedure is simple and lightweight, generalizes broadly, and requires no category labels or other supervision during training.
Deep Unsupervised Image Hashing by Maximizing Bit Entropy
Dec 22, 2020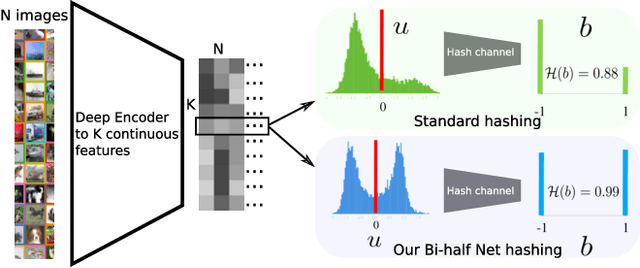
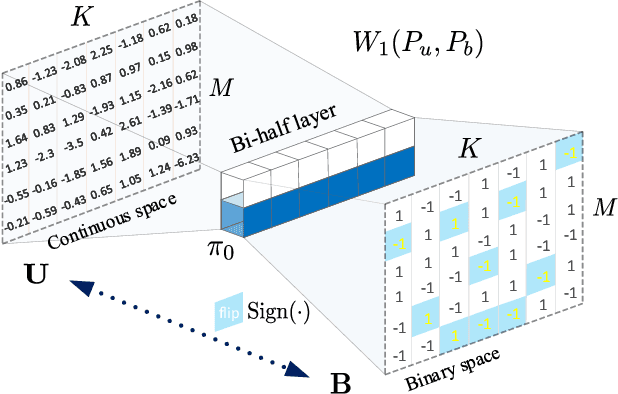
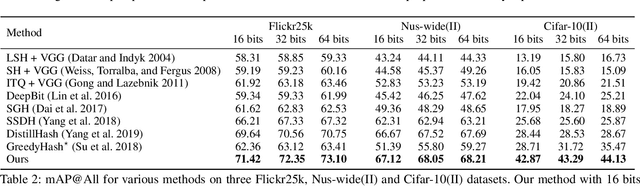
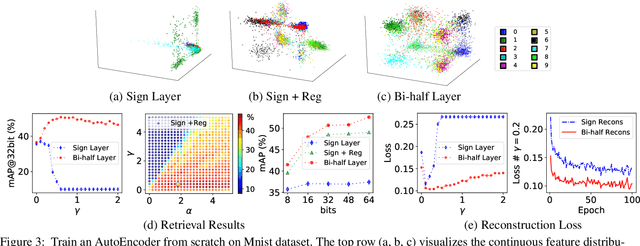
Unsupervised hashing is important for indexing huge image or video collections without having expensive annotations available. Hashing aims to learn short binary codes for compact storage and efficient semantic retrieval. We propose an unsupervised deep hashing layer called Bi-half Net that maximizes entropy of the binary codes. Entropy is maximal when both possible values of the bit are uniformly (half-half) distributed. To maximize bit entropy, we do not add a term to the loss function as this is difficult to optimize and tune. Instead, we design a new parameter-free network layer to explicitly force continuous image features to approximate the optimal half-half bit distribution. This layer is shown to minimize a penalized term of the Wasserstein distance between the learned continuous image features and the optimal half-half bit distribution. Experimental results on the image datasets Flickr25k, Nus-wide, Cifar-10, Mscoco, Mnist and the video datasets Ucf-101 and Hmdb-51 show that our approach leads to compact codes and compares favorably to the current state-of-the-art.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022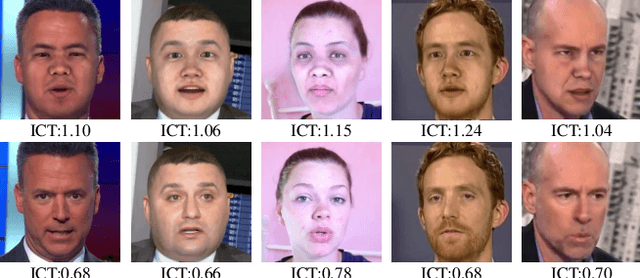
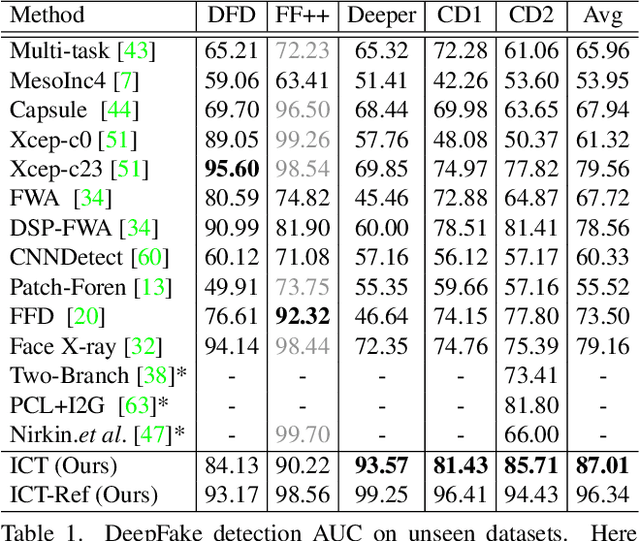

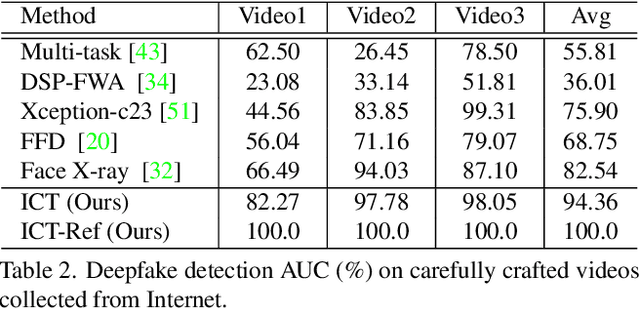
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
DeepI2P: Image-to-Point Cloud Registration via Deep Classification
Apr 08, 2021

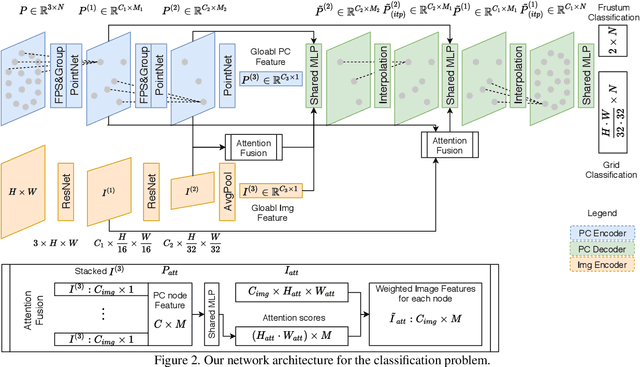
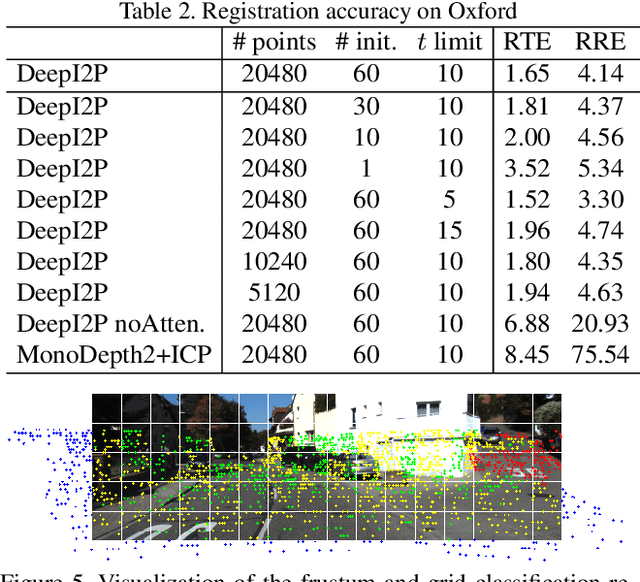
This paper presents DeepI2P: a novel approach for cross-modality registration between an image and a point cloud. Given an image (e.g. from a rgb-camera) and a general point cloud (e.g. from a 3D Lidar scanner) captured at different locations in the same scene, our method estimates the relative rigid transformation between the coordinate frames of the camera and Lidar. Learning common feature descriptors to establish correspondences for the registration is inherently challenging due to the lack of appearance and geometric correlations across the two modalities. We circumvent the difficulty by converting the registration problem into a classification and inverse camera projection optimization problem. A classification neural network is designed to label whether the projection of each point in the point cloud is within or beyond the camera frustum. These labeled points are subsequently passed into a novel inverse camera projection solver to estimate the relative pose. Extensive experimental results on Oxford Robotcar and KITTI datasets demonstrate the feasibility of our approach. Our source code is available at https://github.com/lijx10/DeepI2P