 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CBANet: Towards Complexity and Bitrate Adaptive Deep Image Compression using a Single Network
May 26, 2021
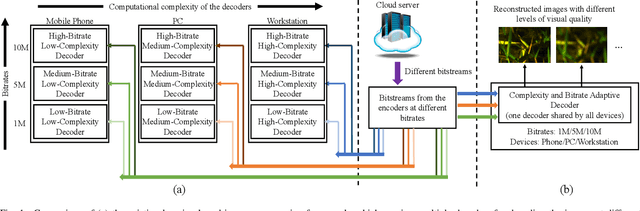
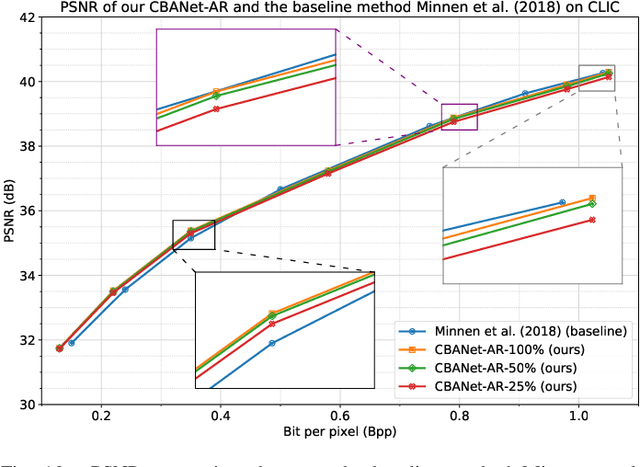
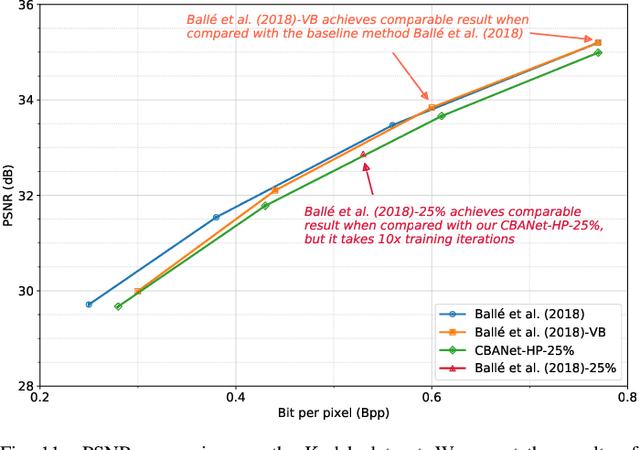
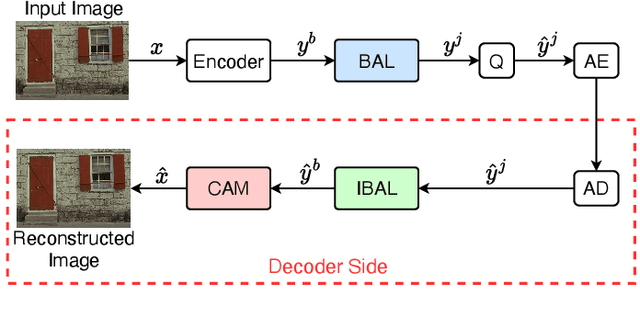
In this paper, we propose a new deep image compression framework called Complexity and Bitrate Adaptive Network (CBANet), which aims to learn one single network to support variable bitrate coding under different computational complexity constraints. In contrast to the existing state-of-the-art learning based image compression frameworks that only consider the rate-distortion trade-off without introducing any constraint related to the computational complexity, our CBANet considers the trade-off between the rate and distortion under dynamic computational complexity constraints. Specifically, to decode the images with one single decoder under various computational complexity constraints, we propose a new multi-branch complexity adaptive module, in which each branch only takes a small portion of the computational budget of the decoder. The reconstructed images with different visual qualities can be readily generated by using different numbers of branches. Furthermore, to achieve variable bitrate decoding with one single decoder, we propose a bitrate adaptive module to project the representation from a base bitrate to the expected representation at a target bitrate for transmission. Then it will project the transmitted representation at the target bitrate back to that at the base bitrate for the decoding process. The proposed bit adaptive module can significantly reduce the storage requirement for deployment platforms. As a result, our CBANet enables one single codec to support multiple bitrate decoding under various computational complexity constraints. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of our CBANet for deep image compression.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022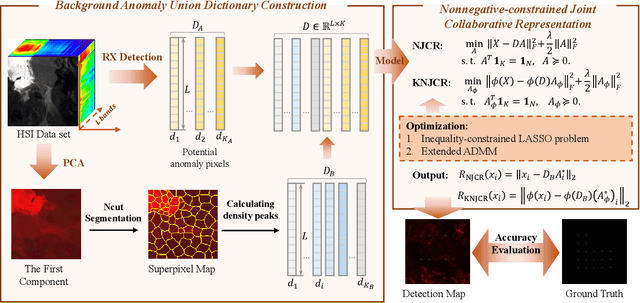
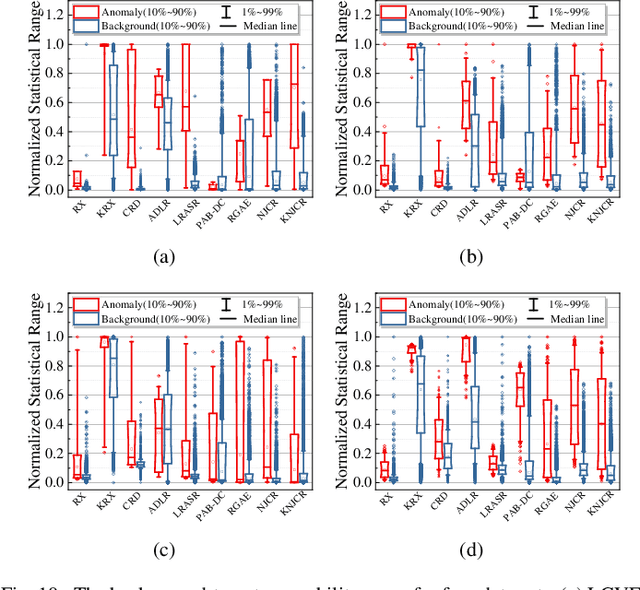
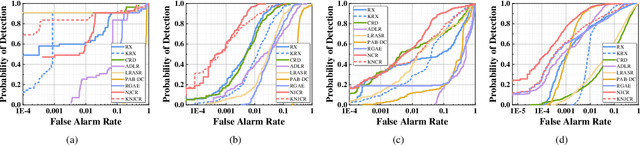
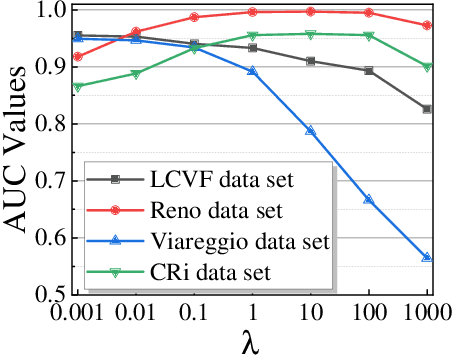
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.
Complete identification of complex salt-geometries from inaccurate migrated images using Deep Learning
Apr 22, 2022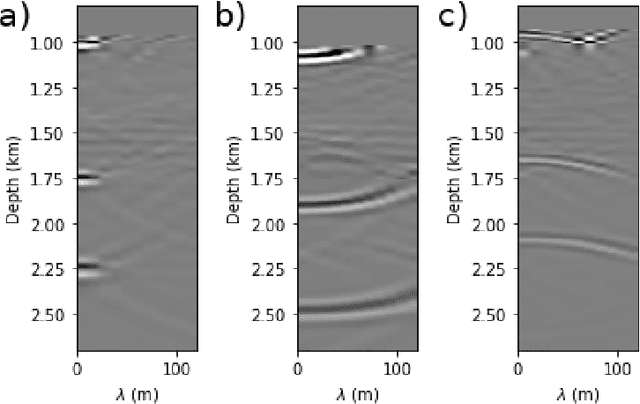
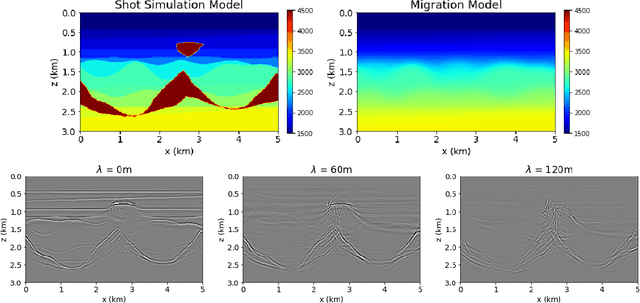
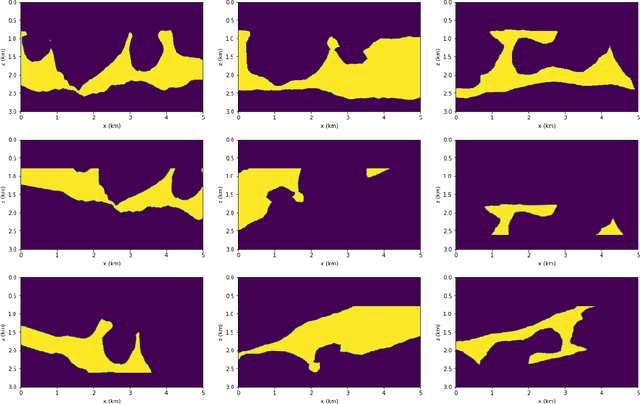
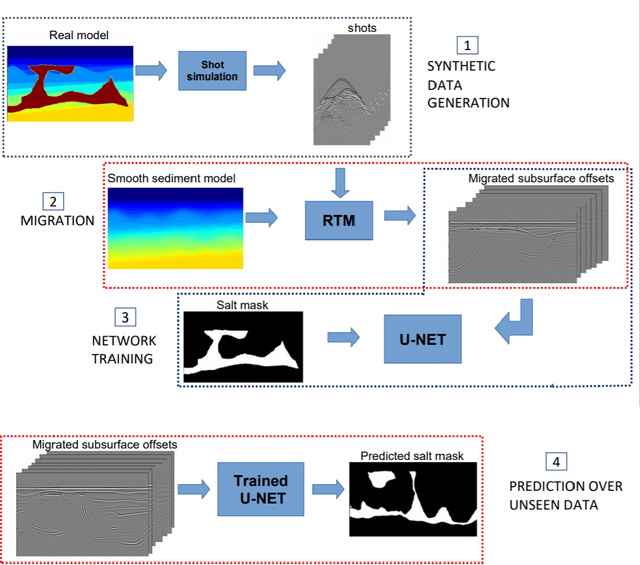
Delimiting salt inclusions from migrated images is a time-consuming activity that relies on highly human-curated analysis and is subject to interpretation errors or limitations of the methods available. We propose to use migrated images produced from an inaccurate velocity model (with a reasonable approximation of sediment velocity, but without salt inclusions) to predict the correct salt inclusions shape using a Convolutional Neural Network (CNN). Our approach relies on subsurface Common Image Gathers to focus the sediments' reflections around the zero offset and to spread the energy of salt reflections over large offsets. Using synthetic data, we trained a U-Net to use common-offset subsurface images as input channels for the CNN and the correct salt-masks as network output. The network learned to predict the salt inclusions masks with high accuracy; moreover, it also performed well when applied to synthetic benchmark data sets that were not previously introduced. Our training process tuned the U-Net to successfully learn the shape of complex salt bodies from partially focused subsurface offset images.
Segmentation-Renormalized Deep Feature Modulation for Unpaired Image Harmonization
Feb 11, 2021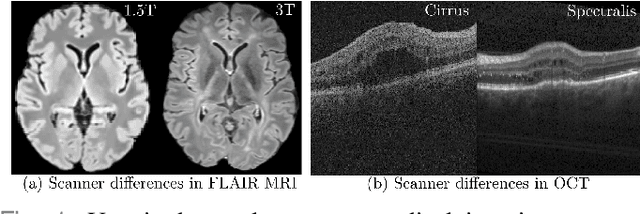
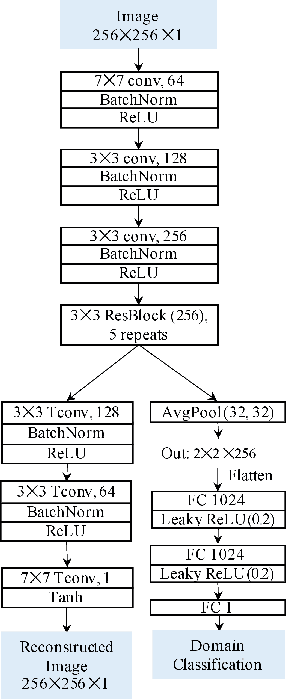
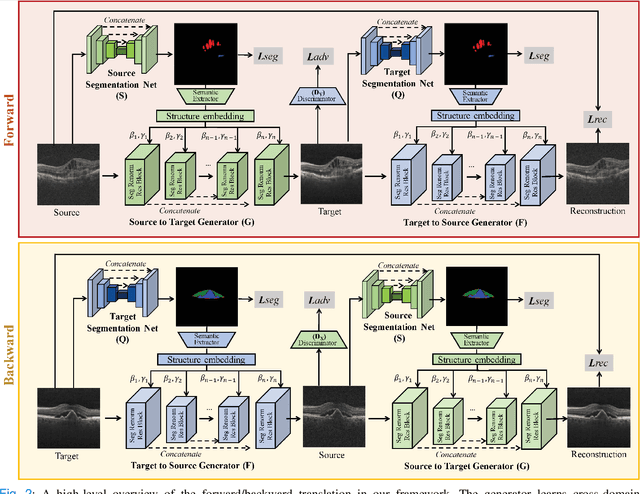
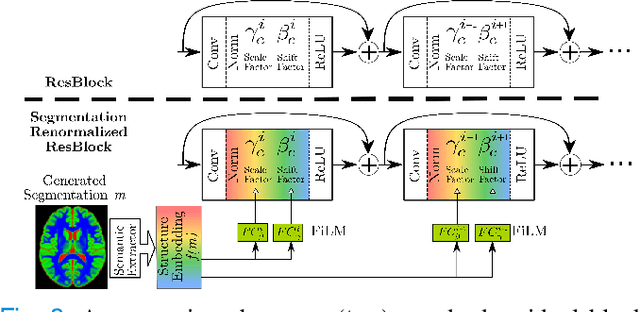
Deep networks are now ubiquitous in large-scale multi-center imaging studies. However, the direct aggregation of images across sites is contraindicated for downstream statistical and deep learning-based image analysis due to inconsistent contrast, resolution, and noise. To this end, in the absence of paired data, variations of Cycle-consistent Generative Adversarial Networks have been used to harmonize image sets between a source and target domain. Importantly, these methods are prone to instability, contrast inversion, intractable manipulation of pathology, and steganographic mappings which limit their reliable adoption in real-world medical imaging. In this work, based on an underlying assumption that morphological shape is consistent across imaging sites, we propose a segmentation-renormalized image translation framework to reduce inter-scanner heterogeneity while preserving anatomical layout. We replace the affine transformations used in the normalization layers within generative networks with trainable scale and shift parameters conditioned on jointly learned anatomical segmentation embeddings to modulate features at every level of translation. We evaluate our methodologies against recent baselines across several imaging modalities (T1w MRI, FLAIR MRI, and OCT) on datasets with and without lesions. Segmentation-renormalization for translation GANs yields superior image harmonization as quantified by Inception distances, demonstrates improved downstream utility via post-hoc segmentation accuracy, and improved robustness to translation perturbation and self-adversarial attacks.
Combating COVID-19 using Generative Adversarial Networks and Artificial Intelligence for Medical Images: A Scoping Review
May 15, 2022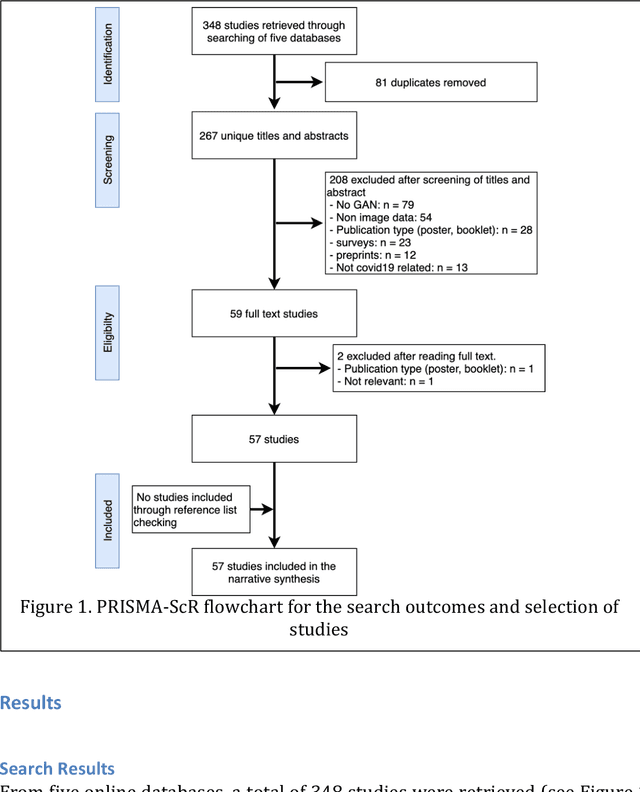
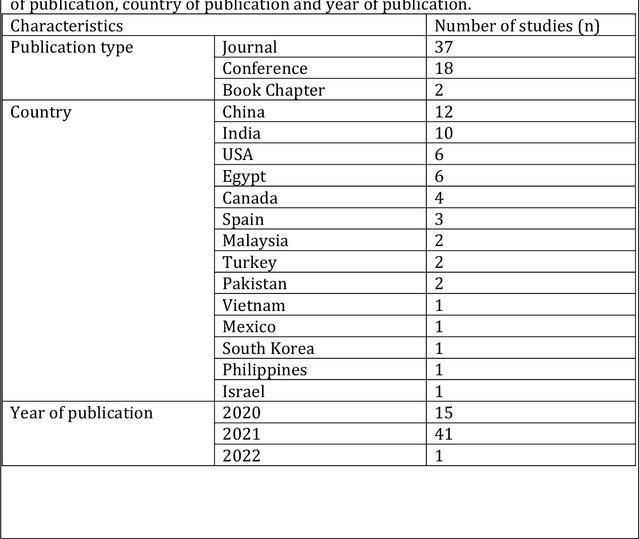
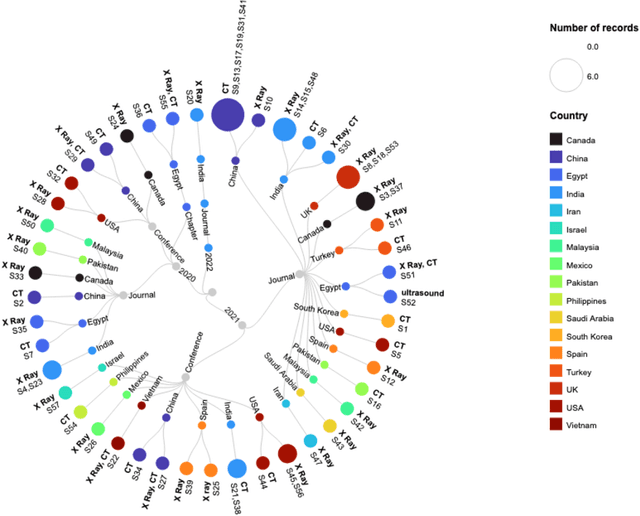
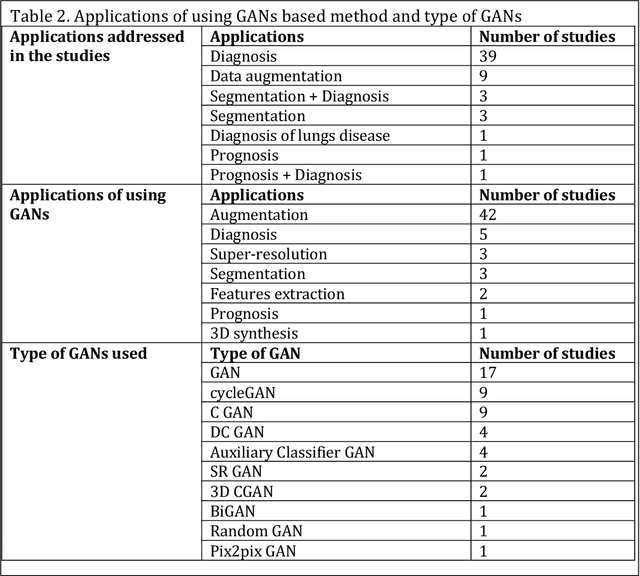
This review presents a comprehensive study on the role of GANs in addressing the challenges related to COVID-19 data scarcity and diagnosis. It is the first review that summarizes the different GANs methods and the lungs images datasets for COVID-19. It attempts to answer the questions related to applications of GANs, popular GAN architectures, frequently used image modalities, and the availability of source code. This review included 57 full-text studies that reported the use of GANs for different applications in COVID-19 lungs images data. Most of the studies (n=42) used GANs for data augmentation to enhance the performance of AI techniques for COVID-19 diagnosis. Other popular applications of GANs were segmentation of lungs and super-resolution of the lungs images. The cycleGAN and the conditional GAN were the most commonly used architectures used in nine studies each. 29 studies used chest X-Ray images while 21 studies used CT images for the training of GANs. For majority of the studies (n=47), the experiments were done and results were reported using publicly available data. A secondary evaluation of the results by radiologists/clinicians was reported by only two studies. Conclusion: Studies have shown that GANs have great potential to address the data scarcity challenge for lungs images of COVID-19. Data synthesized with GANs have been helpful to improve the training of the Convolutional Neural Network (CNN) models trained for the diagnosis of COVID-19. Besides, GANs have also contributed to enhancing the CNNs performance through the super-resolution of the images and segmentation. This review also identified key limitations of the potential transformation of GANs based methods in clinical applications.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022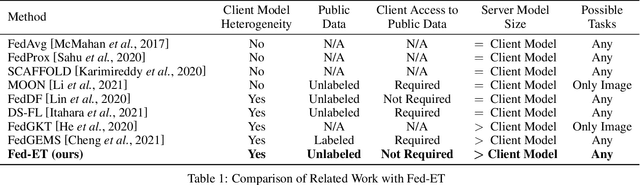
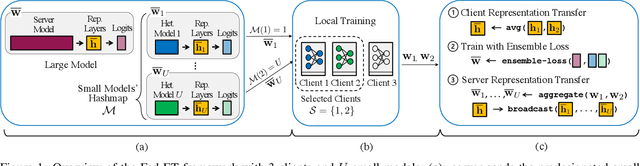
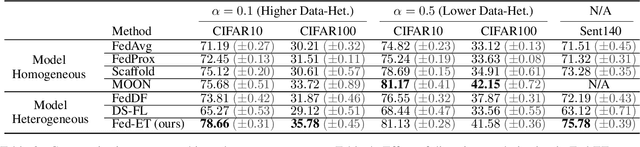
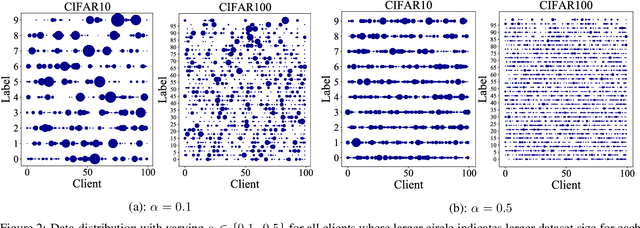
Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
Unsupervised Anomaly Detection in Medical Images with a Memory-augmented Multi-level Cross-attentional Masked Autoencoder
Mar 22, 2022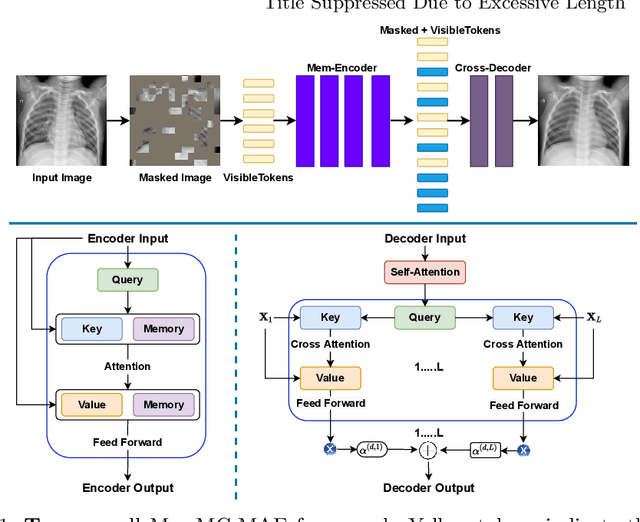



Unsupervised anomaly detection (UAD) aims to find anomalous images by optimising a detector using a training set that contains only normal images. UAD approaches can be based on reconstruction methods, self-supervised approaches, and Imagenet pre-trained models. Reconstruction methods, which detect anomalies from image reconstruction errors, are advantageous because they do not rely on the design of problem-specific pretext tasks needed by self-supervised approaches, and on the unreliable translation of models pre-trained from non-medical datasets. However, reconstruction methods may fail because they can have low reconstruction errors even for anomalous images. In this paper, we introduce a new reconstruction-based UAD approach that addresses this low-reconstruction error issue for anomalous images. Our UAD approach, the memory-augmented multi-level cross-attentional masked autoencoder (MemMC-MAE), is a transformer-based approach, consisting of a novel memory-augmented self-attention operator for the encoder and a new multi-level cross-attention operator for the decoder. MemMC-MAE masks large parts of the input image during its reconstruction, reducing the risk that it will produce low reconstruction errors because anomalies are likely to be masked and cannot be reconstructed. However, when the anomaly is not masked, then the normal patterns stored in the encoder's memory combined with the decoder's multi-level cross-attention will constrain the accurate reconstruction of the anomaly. We show that our method achieves SOTA anomaly detection and localisation on colonoscopy and Covid-19 Chest X-ray datasets.
Pixel VQ-VAEs for Improved Pixel Art Representation
Mar 23, 2022
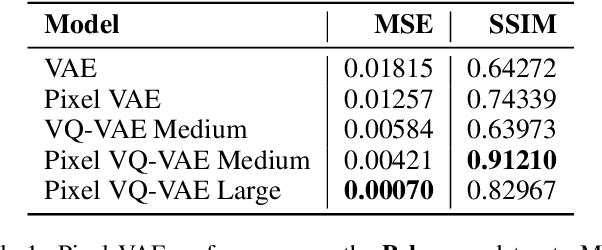
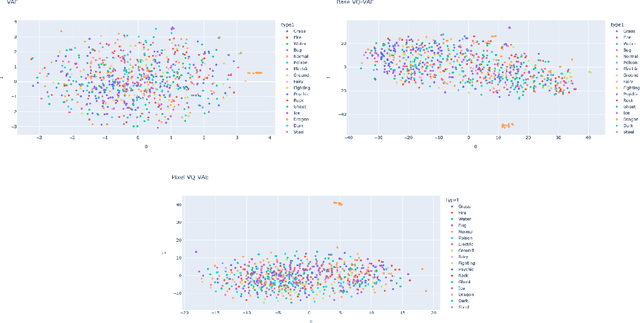

Machine learning has had a great deal of success in image processing. However, the focus of this work has largely been on realistic images, ignoring more niche art styles such as pixel art. Additionally, many traditional machine learning models that focus on groups of pixels do not work well with pixel art, where individual pixels are important. We propose the Pixel VQ-VAE, a specialized VQ-VAE model that learns representations of pixel art. We show that it outperforms other models in both the quality of embeddings as well as performance on downstream tasks.
Improving the Transferability of Adversarial Examples with Restructure Embedded Patches
Apr 27, 2022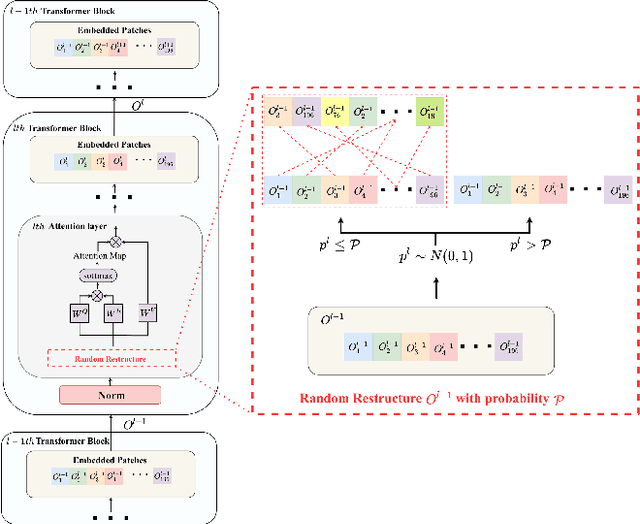
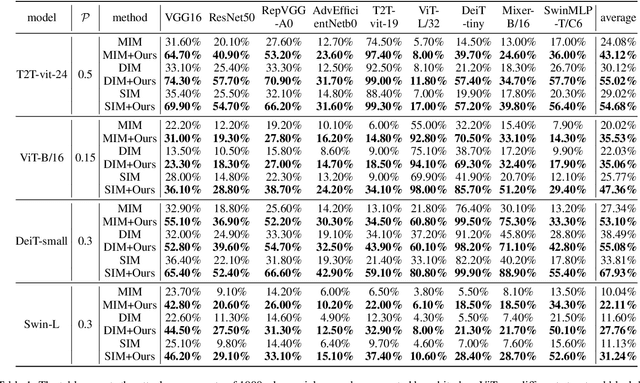

Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.
RecursiveMix: Mixed Learning with History
Mar 14, 2022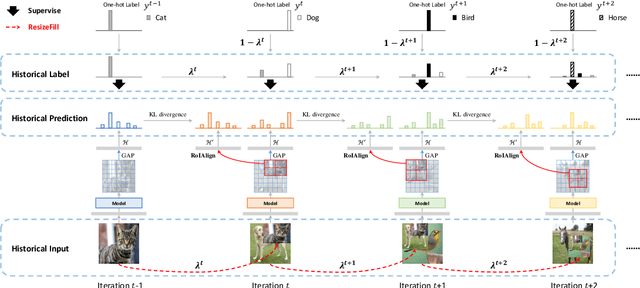
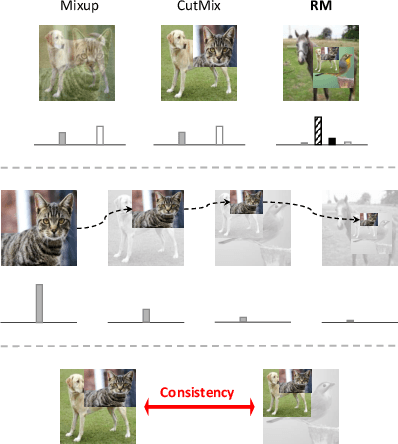
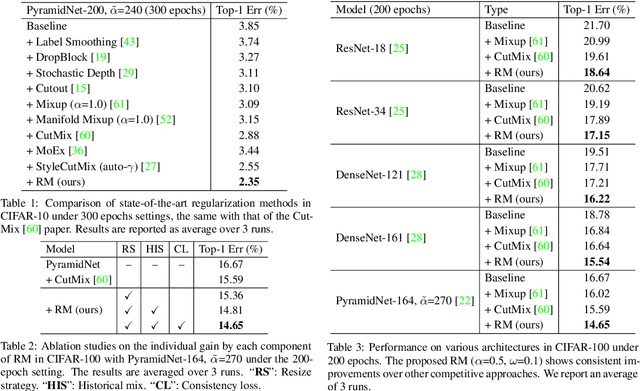
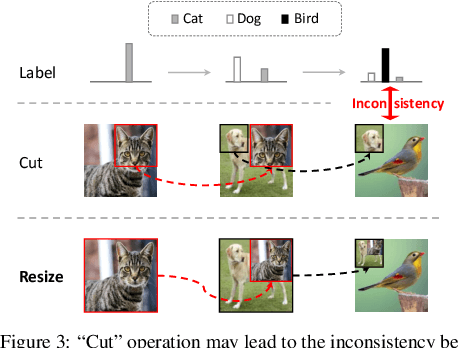
Mix-based augmentation has been proven fundamental to the generalization of deep vision models. However, current augmentations only mix samples at the current data batch during training, which ignores the possible knowledge accumulated in the learning history. In this paper, we propose a recursive mixed-sample learning paradigm, termed "RecursiveMix" (RM), by exploring a novel training strategy that leverages the historical input-prediction-label triplets. More specifically, we iteratively resize the input image batch from the previous iteration and paste it into the current batch while their labels are fused proportionally to the area of the operated patches. Further, a consistency loss is introduced to align the identical image semantics across the iterations, which helps the learning of scale-invariant feature representations. Based on ResNet-50, RM largely improves classification accuracy by $\sim$3.2\% on CIFAR100 and $\sim$2.8\% on ImageNet with negligible extra computation/storage costs. In the downstream object detection task, the RM pretrained model outperforms the baseline by 2.1 AP points and surpasses CutMix by 1.4 AP points under the ATSS detector on COCO. In semantic segmentation, RM also surpasses the baseline and CutMix by 1.9 and 1.1 mIoU points under UperNet on ADE20K, respectively. Codes and pretrained models are available at \url{https://github.com/megvii-research/RecursiveMix}.